机器学习萌新必备的三种优化算法 | 选型指南
作者 | Nasir Hemed
编译 | Rachel
出品 | AI科技大本营(id:rgznai100)
【导读】在本文中,作者对常用的三种机器学习优化算法(牛顿法、梯度下降法、最速下降法)进行了介绍和比较,并结合算法的数学原理和实际案例给出了优化算法选择的一些建议。
阅读本文的基础准备
线性代数
多变量微积分
对凸函数的基本知识
我们都知道,机器学习中最重要的内容之一就是优化问题。因此,找到一个能够对函数做合理优化的算法始终是我们关注的问题。当前,我们使用最多的优化算法之一是梯度下降算法。在本文中,我们会对梯度下降算法以及一些其他的优化算法进行介绍,并尝试从理论角度来理解它们。本文介绍的核心算法包括:
牛顿法(Newton’s Method)
最速下降法(Steep Descent)
梯度下降法(Gradient Descent)
如果想对这些算法有更多了解,你可以阅读斯坦福大学的《凸函数优化—:第三部分》教材。在本文中,我们主要关注二次函数和多项式函数。
对待优化函数的基本假设
一般而言,我们假设我们处理的函数的导数都是连续的(例如,f ∈ C¹)。对于牛顿法,我们还需要假设函数的二阶导数也是连续的(例如, f ∈ C²)。最后,我们还需要假设需要最小化的函数是凸函数。这样一来,如果我们的算法集中到一个点(一般称为局部最小值),我们就可以保证这个值是一个全局最优。
牛顿法
单变量函数的情况
x_n = starting pointx_n1 = x_n - (f'(x_n)/f''(x_n))while (f(x_n) != f(x_n1)): x_n = x_n1 x_n1 = x_n - (f'(x_n)/f''(x_n))
牛顿法的基本思想是,需要优化的函数f在局部可以近似表示为一个二次函数。我们只需要找到这个二次函数的最小值,并将该点的x值记录下来。之后重复这一步骤,直到最小值不再变化为止。
多变量函数的情况
对于单变量的情况,牛顿法比较可靠。但是在实际问题中,我们处理的单变量情形其实很少。大多数时候,我们需要优化的函数都包含很多变量(例如,定义在实数集ℝn的函数)。因此,这里我们需要对多变量的情形进行讨论。
假设x∈ ℝn,则有:
x_n = starting_pointx_n1 = x_n - inverse(hessian_matrix) (gradient(x_n))while (f(x_n) != f(x_n1)):x_n = x_n1 x_n1 = x_n - inverse(hessian_matrix) (gradient(x_n))
其中,gradient(x_n)是函数位于x_n点时的梯度向量,hessian_matrix是一个尺寸为 nxn 的黑塞矩阵(hessian matrix),其值是函数位于x_n的二阶导数。我们都知道,矩阵转换的算法复杂度是非常高的(O(n³)),因此牛顿法在这种情形下并不常用。
梯度下降
梯度下降是目前为止在机器学习和其他优化问题中使用的最多的优化算法。梯度算法的基本思想是,在每次迭代中向梯度方向走一小步。梯度算法还涉及一个恒定的alpha变量,该变量规定每次跨步的步长。下面是算法示例:
alpha = small_constantx_n = starting_pointx_n1 = x_n - alpha * gradient(x_n)while (f(x_n) != f(x_n1)): # May take a long time to convergex_n = x_n1x_n1 = x_n - alpha * gradient(x_n)
这里,alpha是在每次迭代中更新x_n时都需要使用的变量(一般称为超参数)。下面我们对alpha值的选择进行简单分析。
如果我们选择一个很大的alpha,我们很可能会越过最优点,并离最优点越来越远。事实上,如果alpha的值过大,我们甚至会完全偏离最优点。
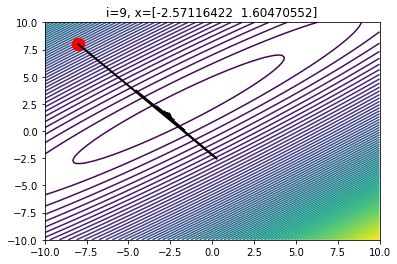
当alpha的值过大时,10次迭代后的梯度下降情况
另外,如果我们选择的alpha值过小,则可能需要经过非常多次迭代才能找到最优值。并且,当我们接近最优值时,梯度会接近于0。因此 ,如果alpha的值过小,我们有可能永远都无法到达最优点。
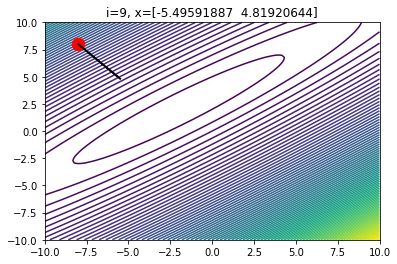
当alpha的值过小时,10次迭代后的梯度下降情况
因此,我们可能需要多尝试一些alpha的值,才能找到最优的选择。如果选择了一个合适的alpha值,我们在迭代时往往能节省很多时间。
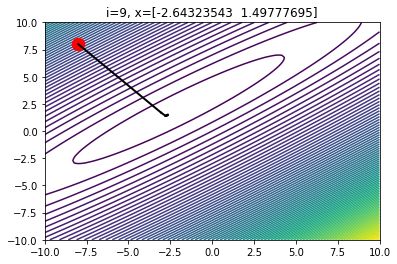
当alpha的值合理时,10次迭代后的梯度下降情况
最速下降法
最速下降法和梯度下降法非常相似,但是最速下降法对每次迭代时要求步长的值为最优。下面是最速下降法的算法示例:
x_n = starting_pointalpha_k = get_optimizer(f(x_n - alpha * gradient(x_n)))x_n1 = x_n - alpha_n * gradient(x_n)while (f(x_n) != f(x_n1)):x_n = x_n1alpha_k = get_optimizer(f(x_n - alpha * gradient(x_n)))x_n1 = x_n - alpha_n * gradient(x_n)
其中,x_n和x_n1是ℝn上的向量,是算法的输入,gradient是函数 f 在点x_n的梯度,alpha_k的数学表示如下:
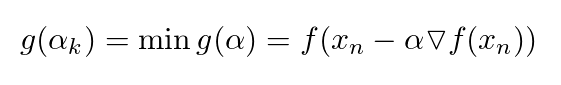
因此,在对原始函数进行优化时,我们需要在每一次迭代中对一个内部函数进行优化。这样做的优点是,这个内部优化函数是一个单变量函数,它的优化不会非常复杂(例如,我们可以使用牛顿法来作为这里的函数)。但是在更多情形下,在每一步中优化这个函数都会带来比较昂贵的花销。
二次式函数的特殊情形
对于均方误差函数:

其中,I 是单位矩阵,y=Qw + b 。为了简化讨论,这里我们只考虑寻找权重w最优值的情形(假设b是连续的)。将等式 y=Qw + b 带入上式并进行一定整理后,我们可以得到如下等式:
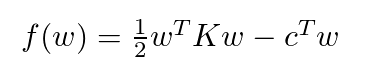
现在我们重新查看一下 g(α), 我们会发现,如果我们使用点 αk 处的梯度,由于其为最优值,该梯度应当为0。因此我们有如下等式:
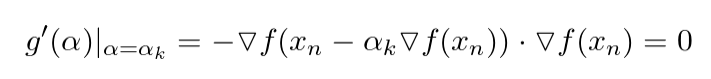
对上式进行简化,并将 f 的梯度带入后,我们可以得到对于 αk 的表示如下:
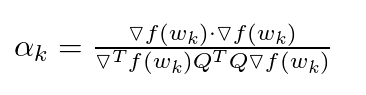
这就是在二次函数情形下 αk 的值。
对二次函数的收敛性分析
对于定义在 ℝ² 上的二次函数,最速下降法一般用来在非常接近最优值时使用,使用步数不超过十步。
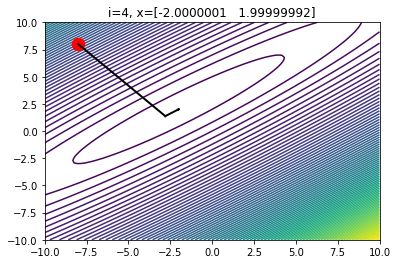
二维中的最速下降在4次迭代后的情形
在上图中,每一次迭代中的改变方向都是垂直的。在3到4次迭代后,我们可以发现导数的变化基本可以忽略不计了。
为什么最速下降法应用很少?
最速下降法算法远远满足了超参数调优的需求,并且保证能找到局部最小值。但是为什么该算法应用不多呢?最速下降法的问题在于,每一步都需要对 aplha_k 进行优化,这样做的成本相对高昂。
例如,对于二次函数,每次迭代都需要计算多次矩阵乘法以及向量点乘。但对于梯度下降,每一步只需要计算导数并更新值就可以了,这样做的成本远远低于最速下降算法。
最速下降算法的另一个问题是对于非凸函数的优化存在困难。对于非凸函数,aplha_k 可能没有固定的值。
对于梯度下降法和最速下降法的对比
在这一部分,我们对梯度下降法和最速下降法进行对比,并比较它们在时间代价上的差异。首先,我们对比了两种算法的时间花销。我们会创建一个二次函数:f:ℝ²⁰⁰⁰→ℝ (该函数为一个2000x2000的矩阵)。我们将对该函数进行优化,并限制迭代次数为1000次。之后,我们会对两种算法的时间花销进行对比,并查看 x_n 值与最优点的距离。
我们先来看一下最速下降法:
0 Diff: 117727672.56583363 alpha value: 8.032725864804974e-06 100 Diff: 9264.791000127792 alpha value: 1.0176428564615889e-05 200 Diff: 1641.154644548893 alpha value: 1.0236993350903281e-05 300 Diff: 590.5089467763901 alpha value: 1.0254560482036439e-05 400 Diff: 279.2355946302414 alpha value: 1.0263893422517941e-05 500 Diff: 155.43169915676117 alpha value: 1.0270028681773919e-05 600 Diff: 96.61812579631805 alpha value: 1.0274280663010468e-05 700 Diff: 64.87719237804413 alpha value: 1.027728512597358e-05 800 Diff: 46.03102707862854 alpha value: 1.0279461929697766e-05 900 Diff: 34.00975978374481 alpha value: 1.0281092917213468e-05 Optimizer found with x = [-1.68825261 5.31853629 -3.45322318 ... 1.59365232 -2.85114689 5.04026352] and f(x)=-511573479.5792374 in 1000 iterationsTotal time taken: 1min 28s
下面是梯度下降法的情况,其中 alpha = 0.000001:
0 Diff: 26206321.312622845 alpha value: 1e-06 100 Diff: 112613.38076114655 alpha value: 1e-06 200 Diff: 21639.659786581993 alpha value: 1e-06 300 Diff: 7891.810685873032 alpha value: 1e-06 400 Diff: 3793.90934664011 alpha value: 1e-06 500 Diff: 2143.767760157585 alpha value: 1e-06 600 Diff: 1348.4947955012321 alpha value: 1e-06 700 Diff: 914.9099299907684 alpha value: 1e-06 800 Diff: 655.9336211681366 alpha value: 1e-06 900 Diff: 490.05882585048676 alpha value: 1e-06 Optimizer found with x = [-1.80862488 4.66644055 -3.08228401 ... 2.46891076 -2.57581774 5.34672724] and f(x)=-511336392.26658595 in 1000 iterationsTotal time taken: 1min 16s
我们可以发现,梯度下降法的速度比最速下降法略快(几秒或几分钟)。但更重要的是,最速下降法采取的步长比梯度下降法更加合理,尽管梯度下降法的α的值并非最优。在上述示例中, 对于梯度下降算法,f(xprex) 和 f(curr) 在第900次迭代时的差为450。而最速下降法在很多次迭代前就已经达到这个值了(大约在第300次到第400次迭代之间)。
因此,我们尝试限制最速下降法的迭代次数为300,输出如下:
0 Diff: 118618752.30065191 alpha value: 8.569151292666038e-06 100 Diff: 8281.239207088947 alpha value: 1.1021416896567156e-05 200 Diff: 1463.1741587519646 alpha value: 1.1087402059869253e-05 300 Diff: 526.3014997839928 alpha value: 1.1106776689082503e-05 Optimizer found with x = [-1.33362899 5.89337889 -3.31827817 ... 1.77032789 -2.86779156 4.56444743] and f(x)=-511526291.3367646 in 400 iterationsTime taken: 35.8s
可以发现,最速下降法的速度实际更快。在此情形中,我们在每次迭代使用更少的步数就能逼近最优值。事实上,如果你的目标是估计最优值,最速下降法会比梯度下降法更合适。对于低维度的函数,10步的最速下降法就会比经过1000次迭代的梯度下降法更接近最优值。
下面这个例子中,我们使用了一个定义在 ℝ³⁰→ℝ 上的二次函数。10步后,最速下降法的得到函数值为 f(x) = -62434.18。而梯度下降法在1000步后得到的函数值为 f(x) = -61596.84。可以发现,最速下降法在10步后的结果就优于梯度下降法在1000步后的结果。
需要记住的是,这种情形仅在处理二次函数的时候适用。整体而言,在每次迭代中都找到 αk的最优值是较为困难的。对函数 g(α) 求最优值并不总能得到 αk 的最优值。通常,我们会使用迭代的算法来对优化函数求最小值。在这种情形下,最速下降法与梯度下降法相比就比较慢了。因此,最速下降法在实际应用中并不常见。
总结
在本文中,我们学习了三种下降算法:
牛顿法(Newton's method)
牛顿法提供了对函数的二阶近似,并在每一步都对函数进行优化。其最大的问题在于,在优化过程中需要进行矩阵转换,对于多变量情形花销过高(尤其是向量的特征较多的时候)。
梯度下降(Gradient Descent)
梯度下降是最常用的优化算法。由于该算法在每步只对导数进行计算,其花销较低,速度更快。但是在使用该算法时,需要对步长的超参数进行多次的猜测和尝试。
最速下降法(Steepest Descent)
最速下降法在每步都对函数的梯度向量寻找最优步长。它的问题在于,在每次迭代中需要对相关的函数进行优化,这会带来很多花销。对于二次函数的情形,尽管每步都涉及很多矩阵运算,最速下降法的效果仍然更优。
相关笔记可参阅:
https://colab.research.google.com/gist/nasirhemed/0026e5e6994d546b4debed8f1ed543c0/a-deeper-look-into-descent-algorithms.ipynb
原文链接:
https://towardsdatascience.com/a-deeper-look-at-descent-algorithms-13340b82db49
(本文为AI科技大本营编译文章,转载请微信联系1092722531)
代码就是力量,长三角的开发者联合起来!
加入「长三角开发者联盟」将获得以下权益
长三角地区明星企业内推岗位
CSDN独家技术与行业报告
CSDN线下活动优先参与权
CSDN线上分享活动优先参与权
我们希望你是:位于长三角地区(上海、江苏、浙江等)优秀开发者。
扫码添加联盟小助手,回复关键词“长三角4”,加入「长三角开发者联盟」。


推荐阅读:
特斯拉全新自动驾驶芯片最强?英伟达回怼,投资者用脚投票
用Python实现OpenCV特征提取与图像检索 | Demo
用Python做数据分析,这些基本数据分析技术你知道吗?
Jupyter/IPython笔记本集合 !(附大量资源链接)-上篇
西安奔驰女车主哭诉维权背后, 区块链究竟能否还消费者以尊严?
深入浅出Docker 镜像 | 技术头条
微软 GitHub 旗帜鲜明抵制 996!
源码泄露是裁员报复还是程序员反抗 996?
她说:为啥程序员都特想要机械键盘?这答案我服!

❤点击“阅读原文”,了解更多活动信息。
相关文章:

【MySQL】缩略语PK NN UQ BIN UN ZF AI G、基本操作语句
一、缩略语 PK:primary key 主键 NN:not null 非空 UQ:unique 唯一索引 BIN:binary 二进制数据 UN:unsigned 无符号整数(非负数) ZF:zero fill 填充0 例如字段内容是1 int(4), 则内…

C#(WPF)去除事件中注册的事件处理方法!
在WPF中,移除一个事件中已经注册的处理方法,看似简单,实际还是很痛苦的一件事情。因为C#的灵活性,定义事件的方法也是多种多样。我自己定义了一个事件: public event EventHandler TestEvent; 当我想注销这个事件上注册…

memcached图形界面的监控
wget http://livebookmark.net/memcachephp/memcachephp.zip 前提是已经安装了php和memcached 图形界面的监控是通过memcache.php来实现的, 1.把该php程序拷贝到nginx的html根目录 [rootcacti srv]# cd /usr/local/nginx/html 2. 更改相应的连接IP和端口…

薅百度GPU羊毛!PaddlePaddle大升级,比Google更懂中文,打响AI开发者争夺战
记者 | 阿司匹林出品 | AI科技大本营(ID: rgznai100)深度学习已经推动人工智能进入工业大生产阶段,而深度学习框架则是智能时代的操作系统。在4月23日下午的Wave Summit深度学习开发者峰会上,百度高级副总裁王海峰开场就为深度学习…
vue中axios如何实现token验证
title: vue中axios如何实现token验证 date: 2018-02-08 17:50:07 tags: [axios,vue] 继上篇实现Auth认证之后,然后每个跳转页面都会在后端验证token的存在 然后那天晚上通过模仿Auth发送请求,发送成功(上篇末尾的方式) 但是今天再继续写,发现每个页面请求都要发送token验证 就比…
【视频】视频方面大神博客总结
1、雷霄骅博客 [总结]视音频编解码技术零基础学习方法:雷神对音视频技术的总结,包括:视频播放器原理、流媒体协议、封装格式、视频编码、音频编码、网络视音频平台对比。首先对雷神的顶礼膜拜,学完这篇博客,就算跨入音…
IHttpHandler 在SharePoint中的应用
1. 一个文件名为VCChartHandler.ashx,其文件代码为: <% WebHandler Language"C#" Class"VCSharePoint.BL.VCHandler,VCSharePoint, Version1.0.0.0, Cultureneutral, PublicKeyToken0134fd28ed40d3b2"%>2. 另一个类为VCHandler.cs的文件…

普通人也能用AI拍出3D大片?这位清华博士后这么做
从《阿凡达》到《流浪地球》,从好莱坞科幻 3D 电影之最到中国科幻 3D 电影之最,从 2009 年到 2019 年,近十年的岁月,见证了中国 3D 影视制作的快速成长和繁盛,也刺激着赵天奇探索人工智能与影视制作结合应用的信心。影…
[asp.net core]SignalR一个例子
摘要 在一个后台管理的页面想实时监控一些操作的数据,想到用signalR。 一个例子 asp.net coresignalR 使用Nuget安装包:Microsoft.AspNetCore.SignalR 在StartUp中启用signalR // This method gets called by the runtime. Use this method to add serv…
【FFmpeg】截至ffmpeg4.2不推荐(Deprecate)继续使用的接口,以及代替它的接口汇总
1、问题描述 使用ffmpeg库写程序,编译时,经常报警告“xxx is deprecated” 查看源码时,该接口或结构体字段被标记attribute_deprecated,表示它已经过时,不推荐使用。 如: attribute_deprecated void avcodec_register(AVCodec *codec);attribute_deprecated void avcod…

Asp.net开发过程中,我们会遇到很多Exception
在Asp.net开发过程中,我们会遇到很多Exception,不处理这些Exception的话会出现很难看的页面。还有一些我们未预料到的Exception,当发生Exception时,我们也必须进行记录具体位置,以便我们修正错误。asp.net异常处理的位…
【经验】对一个合格C++高级工程师(音视频方向)的要求
1、C高级工程师 经过查看招聘网站上对“C高级工程师”这个职位的招聘要求,只总结了技术、能力要求,不涉及工作年限、学历 具体要求如下: 精通C面向对象程序设计; 熟悉设计模式; 敏捷开发经验; 扎实数据结…

马云:腾讯不是阿里要打败的对手,是同为社会创造价值的伴侣
整理 | 琥珀出品 | AI科技大本营(ID:rgznai100)近日,在甘肃敦煌举办的 2019 年中国绿公司年会上,阿里巴巴创始人、董事局主席马云谈及企业间的竞争时,提到了与腾讯的关系。他表示,没有腾讯,阿里…
Win10 | Mac 在server上统一办公
一个非常实际的问题,通常我们主要有三个工作的地点:1,server,用于大型数据的分析和处理;2,办公室的电脑,正式办公;3.自己的电脑,偶尔加班。 不同的工作平台之间很难同步&…
JDK5.0新特性系列---目录
JDK5.0新特性系列---目录 JDK5.0新特性系列---1.自动装箱和拆箱 JDK5.0新特性系列---2.新的for循环 JDK5.0新特性系列---3.枚举类型 JDK5.0新特性系列---4.静态导入 JDK5.0新特性系列---5.可变长参数Varargs JDK5.0新特性系列---6.格式化输出 JDK5.0新特性系列---7.使用Proce…
怎样搞定分类表格数据?有人用TF2.0构建了一套神经网络 | 技术头条
作者 | 王树义来源 | 玉树芝兰(ID:nkwangshuyi)以客户流失数据为例,看 Tensorflow 2.0 版本如何帮助我们快速构建表格(结构化)数据的神经网络分类模型。变化表格数据,你应该并不陌生。毕竟&…
【FFmpeg】Hello World!尝试如何编译FFmpeg程序
1、说明 下面的例子只演示,编译FFmpeg时用的头文件和库,不涉及编解码,只调用一个可以打印编译FFmpeg库的配置项的接口:avcodec_configuration() 2、avCfg.c #include <stdio.h> #include <libavcodec/avcodec.h>int main(int argc,char *argv[]
x-pack watch邮件报警配置
参考网址: https://www.cnblogs.com/reboot51/p/8328720.html https://www.elastic.co/guide/en/x-pack/5.6/actions-email.html #邮件设置 elasticsearch 配置 xpack.notification.email.account:exchange_account:profile: outlookemail_defaults:from: infomail.…

虚拟桌面的备份恢复最佳实践 第一部分
摘要 VMware View 是目前虚拟桌面市场的旗舰产品。借助它,企业可以将办公系统、应用和基础架构以高性能、高度可扩展的集中式托管服务形式交付给用户。View 还可提供保护它所支持的系统和应用以及相关用户数据所需的功能。它支持方便地备份和还原存档数据。 通常&…
Python程序员Debug利器,和Print说再见 | 技术头条
整理 | Rachel责编 | Jane出品 | Python大本营(id:pythonnews)【导语】程序员每日都在和 debug 相伴。新手程序员需要学习的 debug 手段复杂多样,设置断点、查看变量值……一些网站还专门针对debug撰写了新手教程。老司机们在大型…
【FFmpeg】解决警告warning: xxx is deprecated [-Wdeprecated-declarations]的方法
1、问题描述 编译FFmpeg程序时,经常报一些关于“deprecated”的警告信息,具体内容如下: decode.cpp:28:2: warning: ‘void av_register_all()’ is deprecated [-Wdeprecated-declarations]av_register_all(); decode.<
[BZOJ2527]Meteors
整体二分挺好玩的...学一发 这个询问显然是可以二分的,但每次都二分就会T爆,所以我们有了“整体”二分 每次处理一些询问,要求这些询问的答案一定在$[l,r]$中 先把$l$到$mid$的操作实施,那么当前TAK的询问答案一定在$[l,mid]$中&a…

一个可提供html5制作服务的网站
2019独角兽企业重金招聘Python工程师标准>>> 【TechWeb报道】最近网上出现了一个专门基于HTML5/CSS3制作服务的组织 P2H.cn. 就是专门提供网站切图的一项服务。特别在哪儿呢 ,P2H.cn 可以制作出完美的兼容的html5/css3的页面。 王大利/文 如果你不知…
【Ubuntu】Ubuntu下的录频软件SimpleScreenRecorder
1、说明 官网介绍:https://www.maartenbaert.be/simplescreenrecorder/ 源码参见github:https://github.com/MaartenBaert/ssr 2、安装 Ubuntu版本>17.04,直接安装 sudo apt-get install simplescreenrecorderUbuntu版本<17.04&…
打开阿兹海默之门:华裔张复伦利用RNN成功解码脑电波,合成语音 | Nature
作者 | 琥珀出品 | AI科技大本营(ID:rgznai100)2019 年 4 月 24 日,来自加州大学旧金山分校(UCSF)神经外科学系 Gopala K. Anumanchipalli,Josh Chartier,Edward F. Chang 团队在 Nature 杂志上…

[转载] 别人的心得感悟
原文: https://www.cnblogs.com/double-K/p/6926367.html#commentform ---------------------------------------- 不可说的感悟-——十年老技术转型(一) 佛曰:“不可说,说既是错”,所以本篇也是错…

Windows Phone 7、XNA的旋转的背景
在游戏表现的过程中需要一些比较酷的动作,我们需要通过图型与XNA中的一些代码来实现,比如我们要说到的一个360度转动的圆。 在手机上的效果如下: 当然在这里我们看不到转动的效果,下边提供的有源码,大家可以下载运行测试一下。 操…
【Qt】报错error: undefined reference to `vtable for的解决方法
1、问题描述 编译Qt程序时,在某个类构造函数定义处报错: error: undefined reference to vtable for2、原因分析 导致错误信息的原因是:子类没有实现父类的纯虚函数; 在Qt中,首先要想到的是在一个类中添加了新的继承…

110万开发者的福音,百度Easy DL商品检测专业版上线
继首场百度大脑开放日上一口气开放24项全新AI技术后,4 月 25 日下午,第二期百度大脑开放日如约举行,本次共发布了13款AI通用新能力、5项技术升级,并推出了EasyDL商品检测专业版和语音识别自训练平台两大全新的可定制训练平台。 实…

简单爬虫学习记录
实现思路解析:爬虫调度器:启动/停止爬虫,规定爬虫的范围;URL管理器:管理2个URL:新的没有爬过的urls;旧的爬过的urls;URL下载器:下载url对应的html数据;HTML解…