怎样搞定分类表格数据?有人用TF2.0构建了一套神经网络 | 技术头条

作者 | 王树义
来源 | 玉树芝兰(ID:nkwangshuyi)
以客户流失数据为例,看 Tensorflow 2.0 版本如何帮助我们快速构建表格(结构化)数据的神经网络分类模型。
变化
表格数据,你应该并不陌生。毕竟, Excel 这东西在咱们平时的工作和学习中,还是挺常见的。
在之前的教程里,我为你分享过,如何利用深度神经网络,锁定即将流失的客户。里面用到的,就是这样的表格数据。
时间过得真快,距离写作那篇教程,已经一年半了。
这段时间里,出现了2个重要的变化,使我觉得有必要重新来跟你谈谈这个话题。
这两个变化分别是:
首先,tflearn 框架的开发已经不再活跃。
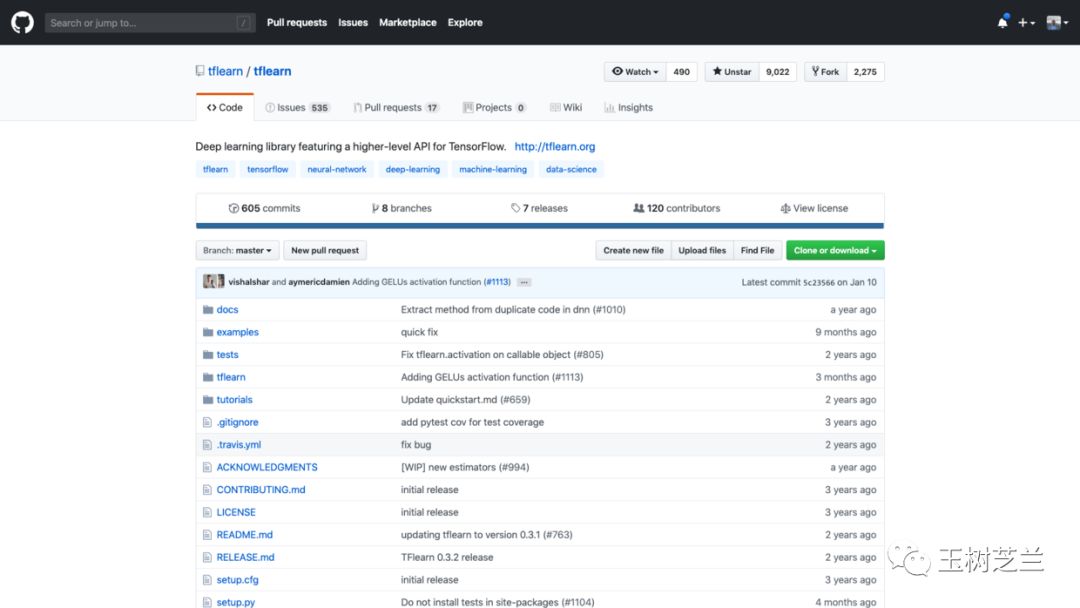
tflearn 是当时教程中我们使用的高阶深度学习框架,它基于 Tensorflow 之上,包裹了大量的细节,让用户可以非常方便地搭建自己的模型。
但是,由于 Tensorflow 选择拥抱了它的竞争者 Keras ,导致后者的竞争优势凸显。
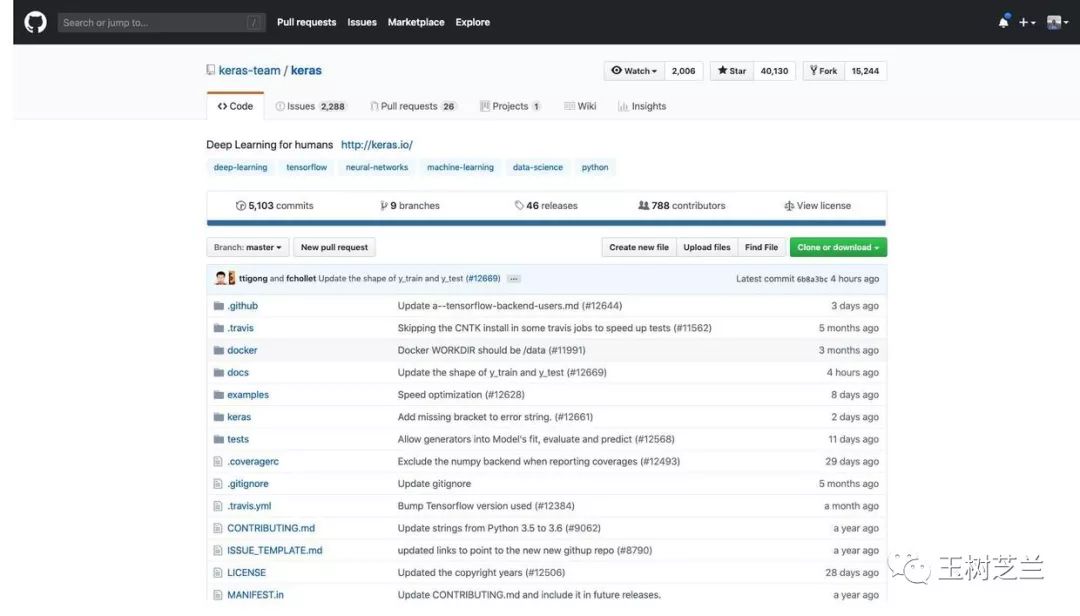
对比二者获得的星数,已经不在同一量级。
观察更新时间,tflearn 已经几个月没有动静;而 Keras 几个小时之前,还有更新。
我们选择免费开源框架,一定要使用开发活跃、社区支持完善的。只有这样,遇到问题才能更低成本、高效率地解决。
看过我的《Python编程遇问题,文科生怎么办?》一文之后,你对上述结论,应该不陌生。
另一项新变化,是 Tensorflow 发布了 2.0 版本。
相对 1.X 版本,这个大版本的变化,我在《如何用 Python 和 BERT 做中文文本二元分类?》一文中,已经粗略地为你介绍过了。简要提炼一下,就是:
之前的版本,以计算图为中心。开发者需要为这张图服务。因此,引入了大量的不必要术语。新版本以人为中心,用户撰写高阶的简洁语句,框架自动将其转化为对应的计算图。
之前的版本,缺少目前竞争框架(如 PyTorch 等)包含的新特性。例如计算图动态化、运行中调试功能等。
但对普通开发者来说,最为重要的是,官方文档和教程变得对用户友好许多。不仅写得清晰简明,更靠着 Google Colab 的支持,全都能一键运行。我尝试了 2.0 版本的一些教程样例,确实感觉大不一样了。
其实你可能会觉得奇怪—— Tensorflow 大张旗鼓宣传的大版本改进,其实也无非就是向着 PyTorch 早就有的功能靠拢而已嘛。那我干脆去学 PyTorch 好了!
如果我们只说道理,这其实没错。然而,还是前面那个论断,一个框架好不好,主要看是否开发活跃、社区支持完善。这就是一个自证预言。一旦人们都觉得 Tensorflow 好用,那么 Tensorflow 就会更好用。因为会有更多的人参与进来,帮助反馈和改进。
看看现在 PyTorch 的 Github 页面。
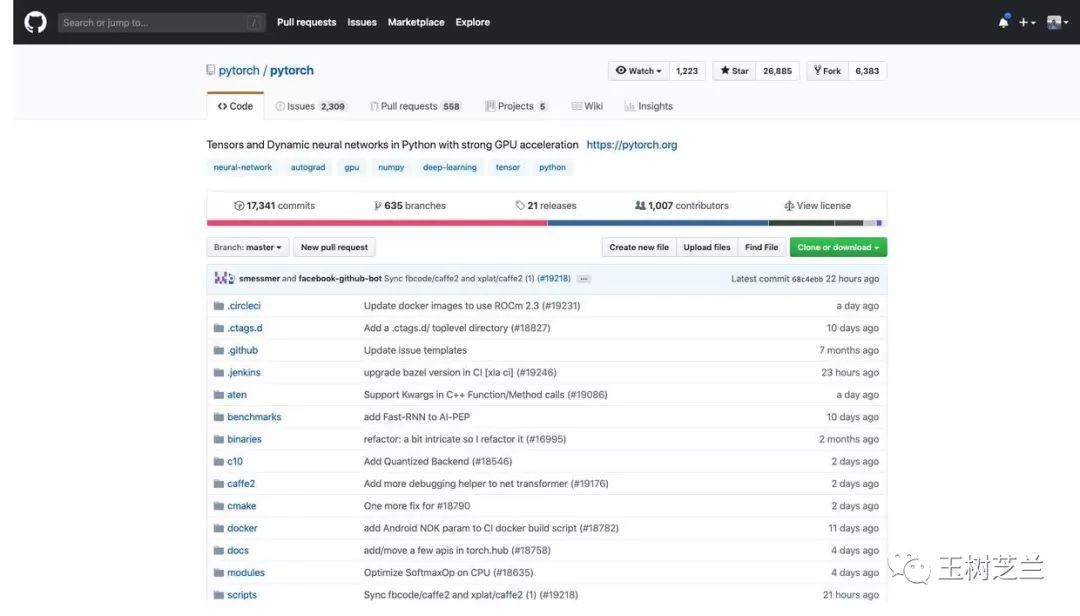
受关注度,确实已经很高了。
然而你再看看 Tensorflow 的。
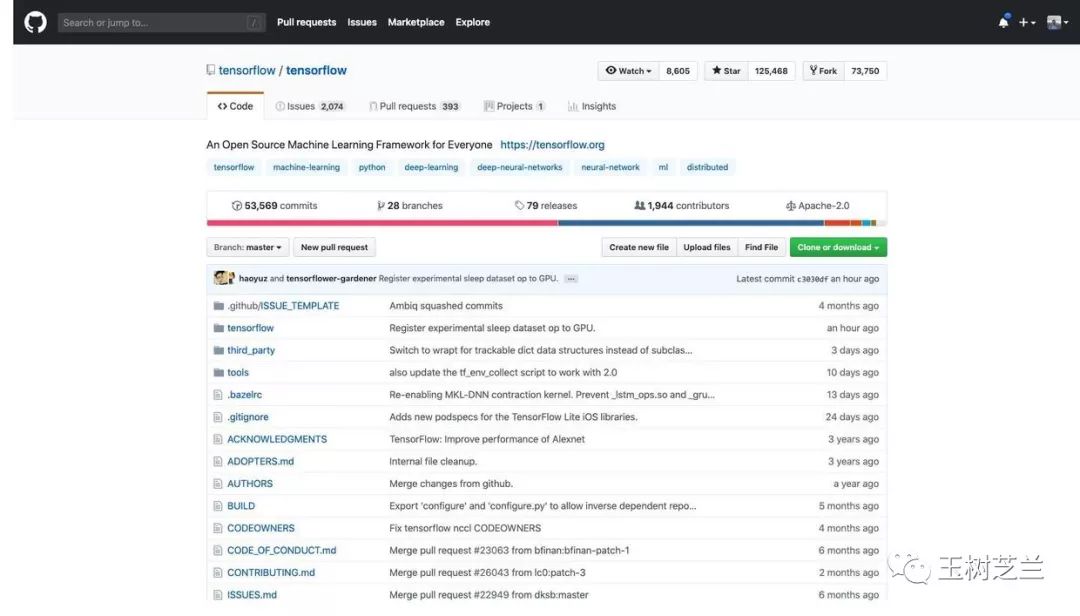
至少在目前,二者根本不在一个数量级。
Tensorflow 的威力,不只在于本身构建和训练模型是不是好用。那其实只是深度学习中,非常小的一个环节。不信?你在下图里找找看。
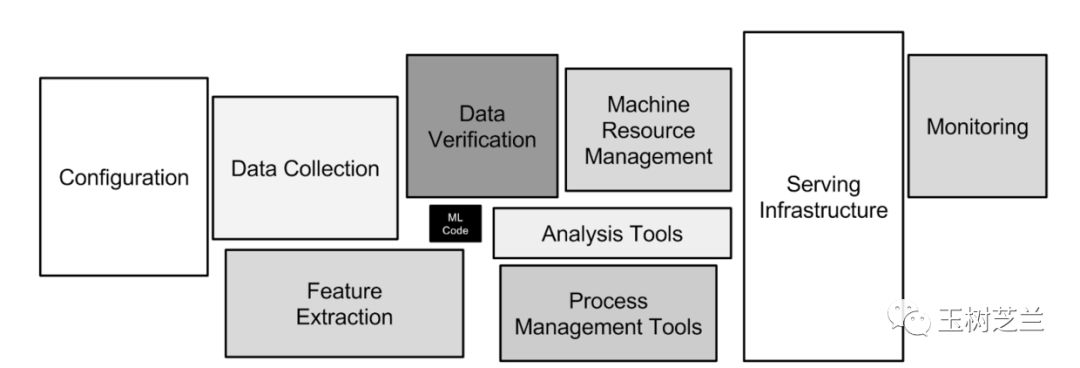
真正的问题,在于是否有完整的生态环境支持。其中的逻辑,我在《学 Python ,能提升你的竞争力吗?》一文中,已经为你详细分析过了。
而 Tensorflow ,早就通过一系列的布局,使得其训练模型可以直接快速部署,最快速度铺开,帮助开发者占领市场先机。
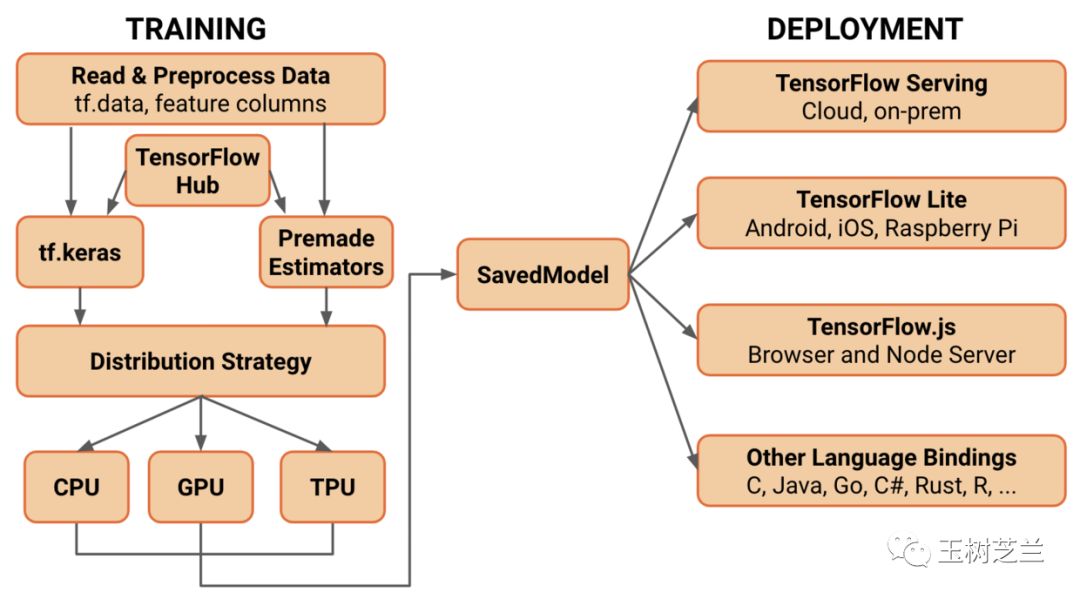
如果你使用 PyTorch ,那么这样的系统,是相对不完善的。当然你可以在 PyTorch 中训练,然后转换并且部署到 Tensorflow 里面。毕竟三巨头达成了协议,标准开放,这样做从技术上并不困难。

但是,人的认知带宽,是非常有限的。大部分人,是不会选择在两个框架甚至生态系统之间折腾的。这就是路径依赖。
所以,别左顾右盼了,认认真真学 Tensorflow 2.0 吧。
这篇文章里面,我给你介绍,如何用 Tensorflow 2.0 ,来训练神经网络,对用户流失数据建立分类模型,从而可以帮你见微知著,洞察风险,提前做好干预和防范。
数据
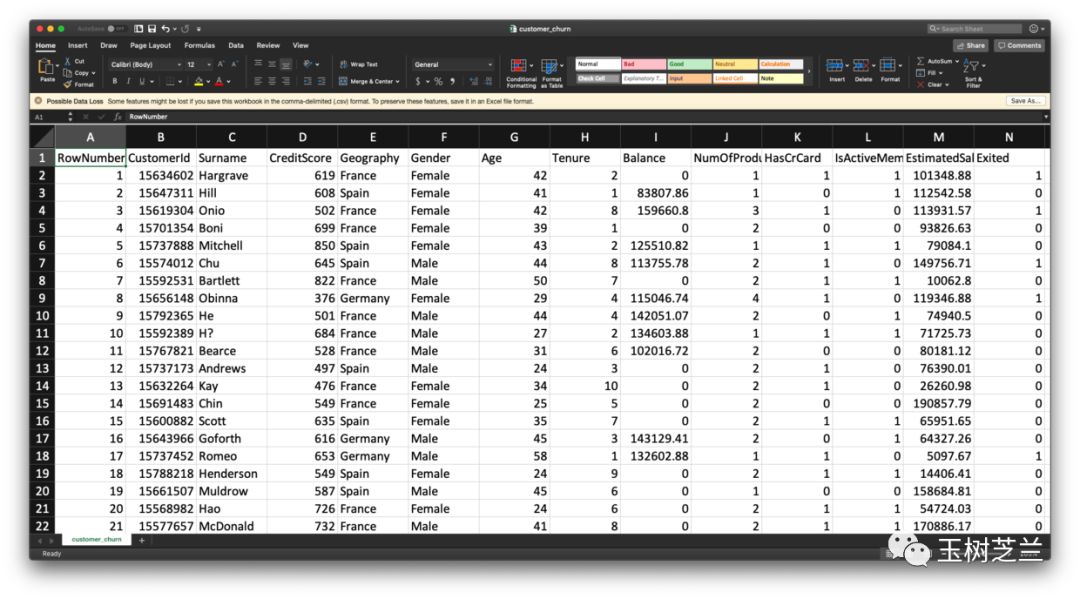
你手里拥有的,是一份银行欧洲区客户的数据,共有10000条记录。客户主要分布在法国、德国和西班牙。
数据来自于匿名化处理后的真实数据集,下载自 superdatascience 官网。
从表格中,可以读取的信息,包括客户们的年龄、性别、信用分数、办卡信息等。客户是否已流失的信息在最后一列(Exited)。
这份数据,我已经上传到了这个地址,你可以下载,并且用 Excel 查看。
环境
本文的配套源代码,我放在了这个 Github 项目中。请你点击这个链接(http://t.cn/EXffmgX)访问。
如果你对我的教程满意,欢迎在页面右上方的 Star 上点击一下,帮我加一颗星。谢谢!
注意这个页面的中央,有个按钮,写着“在 Colab 打开” (Open in Colab)。请你点击它。
然后,Google Colab 就会自动开启。
我建议你点一下上图中红色圈出的 “COPY TO DRIVE” 按钮。这样就可以先把它在你自己的 Google Drive 中存好,以便使用和回顾。
Colab 为你提供了全套的运行环境。你只需要依次执行代码,就可以复现本教程的运行结果了。
如果你对 Google Colab 不熟悉,没关系。我这里有一篇教程,专门讲解 Google Colab 的特点与使用方式。
为了你能够更为深入地学习与了解代码,我建议你在 Google Colab 中开启一个全新的 Notebook ,并且根据下文,依次输入代码并运行。在此过程中,充分理解代码的含义。
这种看似笨拙的方式,其实是学习的有效路径。
代码
首先,我们下载客户流失数据集。
!wget https://raw.githubusercontent.com/wshuyi/demo-customer-churn-ann/master/customer_churn.csv
载入 Pandas 数据分析包。
import pandas as pd
利用 read_csv 函数,读取 csv 格式数据到 Pandas 数据框。
df = pd.read_csv('customer_churn.csv')
我们来看看前几行显示结果:
df.head()
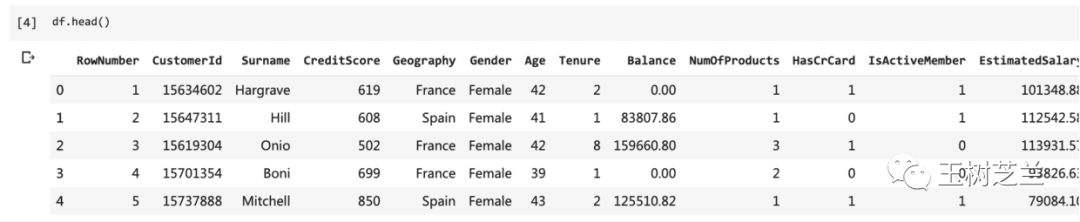
显示正常。下面看看一共都有哪些列。
df.columns

我们对所有列,一一甄别。
RowNumber:行号,这个对于模型没用,忽略
CustomerID:用户编号,这个是顺序发放的,忽略
Surname:用户姓名,对流失没有影响,忽略
CreditScore:信用分数,这个很重要,保留
Geography:用户所在国家/地区,这个有影响,保留
Gender:用户性别,可能有影响,保留
Age:年龄,影响很大,年轻人更容易切换银行,保留
Tenure:当了本银行多少年用户,很重要,保留
Balance:存贷款情况,很重要,保留
NumOfProducts:使用产品数量,很重要,保留
HasCrCard:是否有本行信用卡,很重要,保留
IsActiveMember:是否活跃用户,很重要,保留
EstimatedSalary:估计收入,很重要,保留
Exited:是否已流失,这将作为我们的标签数据
确定了不同列的含义和价值,下面我们处理起来,就得心应手了。
数据有了,我们来调入深度学习框架。
因为本次我们需要使用 Tensorflow 2.0 ,而写作本文时,该框架版本尚处于 Alpha 阶段,因此 Google Colab 默认使用的,还是 Tensorflow 1.X 版本。要用 2.0 版,便需要显式安装。
!pip install -q tensorflow==2.0.0-alpha0
安装框架后,我们载入下述模块和函数,后文会用到。
import numpy as np
import tensorflow as tf
from tensorflow import keras
from sklearn.model_selection import train_test_split
from tensorflow import feature_column
这里,我们设定一些随机种子值。这主要是为了保证结果可复现,也就是在你那边的运行结果,和我这里尽量保持一致。这样我们观察和讨论问题,会更方便。
首先是 Tensorflow 中的随机种子取值,设定为 1 。
tf.random.set_seed(1)
然后我们来分割数据。这里使用的是 Scikit-learn 中的 train_test_split 函数。指定分割比例即可。
我们先按照 80:20 的比例,把总体数据分成训练集和测试集。
train, test = train_test_split(df, test_size=0.2, random_state=1)
然后,再把现有训练集的数据,按照 80:20 的比例,分成最终的训练集,以及验证集。
train, valid = train_test_split(train, test_size=0.2, random_state=1)
这里,我们都指定了 random_state ,为的是保证咱们随机分割的结果一致。
我们看看几个不同集合的长度。
print(len(train))
print(len(valid))
print(len(test))

验证无误。下面我们来做特征工程(feature engineering)。
因为我们使用的是表格数据(tabular data),属于结构化数据。因此特征工程相对简单一些。
先初始化一个空的特征列表。
feature_columns = []
然后,我们指定,哪些列是数值型数据(numeric data)。
numeric_columns = ['CreditScore', 'Age', 'Tenure', 'Balance', 'NumOfProducts', 'EstimatedSalary']
可见,包含了以下列:
CreditScore:信用分数
Age:年龄
Tenure:当了本银行多少年用户
Balance:存贷款情况
NumOfProducts:使用产品数量
EstimatedSalary:估计收入
对于这些列,只需要直接指定类型,加入咱们的特征列表就好。
for header in numeric_columns:
feature_columns.append(feature_column.numeric_column(header))
下面是比较讲究技巧的部分了,就是类别数据。
先看看都有哪些列:
categorical_columns = ['Geography', 'Gender', 'HasCrCard', 'IsActiveMember']
Geography:用户所在国家/地区
Gender:用户性别
HasCrCard:是否有本行信用卡
IsActiveMember:是否活跃用户
类别数据的特点,在于不能直接用数字描述。例如 Geography 包含了国家/地区名称。如果你把法国指定为1, 德国指定为2,电脑可能自作聪明,认为“德国”是“法国”的2倍,或者,“德国”等于“法国”加1。这显然不是我们想要表达的。
所以我这里编了一个函数,把一个类别列名输入进去,让 Tensorflow 帮我们将其转换成它可以识别的类别形式。例如把法国按照 [0, 0, 1],德国按照 [0, 1, 0] 来表示。这样就不会有数值意义上的歧义了。
def get_one_hot_from_categorical(colname):
categorical = feature_column.categorical_column_with_vocabulary_list(colname, train[colname].unique().tolist())
return feature_column.indicator_column(categorical)
我们尝试输入 Geography 一项,测试一下函数工作是否正常。
geography = get_one_hot_from_categorical('Geography'); geography

观察结果,测试通过。
下面我们放心大胆地把所有类别数据列都在函数里面跑一遍,并且把结果加入到特征列表中。
for col in categorical_columns:
feature_columns.append(get_one_hot_from_categorical(col))
看看此时的特征列表内容:
feature_columns
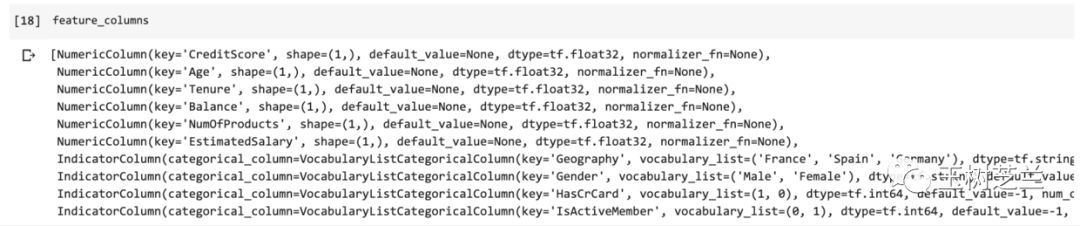
6个数值类型,4个类别类型,都没问题了。
下面该构造模型了。
我们直接采用 Tensorflow 2.0 鼓励开发者使用的 Keras 高级 API 来拼搭一个简单的深度神经网络模型。
from tensorflow.keras import layers
我们把刚刚整理好的特征列表,利用 DenseFeatures 层来表示。把这样的一个初始层,作为模型的整体输入层。
feature_layer = layers.DenseFeatures(feature_columns); feature_layer

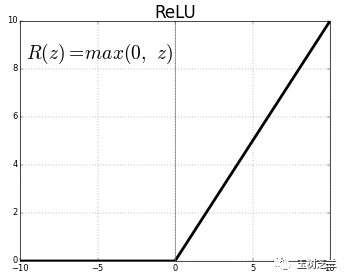
下面,我们顺序叠放两个中间层,分别包含200个,以及100个神经元。这两层的激活函数,我们都采用 relu 。
relu 函数大概长这个样子:
model = keras.Sequential([
feature_layer,
layers.Dense(200, activation='relu'),
layers.Dense(100, activation='relu'),
layers.Dense(1, activation='sigmoid')
])
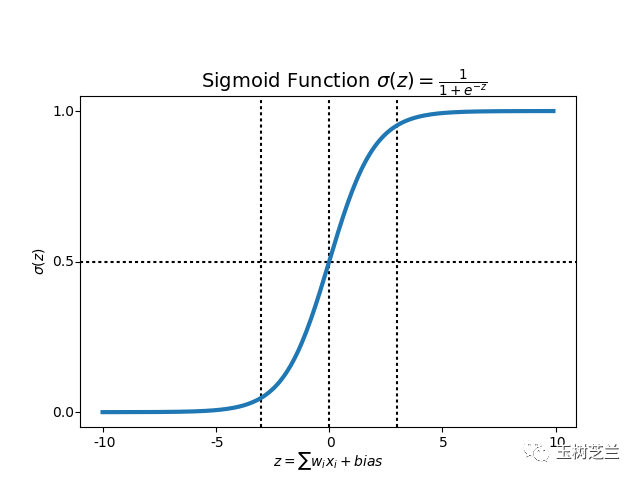
我们希望输出结果是0或者1,所以这一层只需要1个神经元,而且采用的是 sigmoid 作为激活函数。
sigmoid 函数的长相是这样的:
模型搭建好了,下面我们指定3个重要参数,编译模型。
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
这里,我们选择优化器为 adam 。
因为评判二元分类效果,所以损失函数选的是 binary_crossentropy。
至于效果指标,我们使用的是准确率(accuracy)。
模型编译好之后。万事俱备,只差数据了。
你可能纳闷,一上来不就已经把训练、验证和测试集分好了吗?
没错,但那只是原始数据。我们模型需要接收的,是数据流。
在训练和验证过程中,数据都不是一次性灌入模型的。而是一批次一批次分别载入。每一个批次,称作一个 batch;相应地,批次大小,叫做 batch_size 。
为了方便咱们把 Pandas 数据框中的原始数据转换成数据流。我这里编写了一个函数。
def df_to_tfdata(df, shuffle=True, bs=32):
df = df.copy()
labels = df.pop('Exited')
ds = tf.data.Dataset.from_tensor_slices((dict(df), labels))
if shuffle:
ds = ds.shuffle(buffer_size=len(df), seed=1)
ds = ds.batch(bs)
return ds
这里首先是把数据中的标记拆分出来。然后根据把数据读入到 ds 中。根据是否是训练集,我们指定要不要需要打乱数据顺序。然后,依据 batch_size 的大小,设定批次。这样,数据框就变成了神经网络模型喜闻乐见的数据流。
train_ds = df_to_tfdata(train)
valid_ds = df_to_tfdata(valid, shuffle=False)
test_ds = df_to_tfdata(test, shuffle=False)
这里,只有训练集打乱顺序。因为我们希望验证和测试集一直保持一致。只有这样,不同参数下,对比的结果才有显著意义。
有了模型架构,也有了数据,我们把训练集和验证集扔进去,让模型尝试拟合。这里指定了,跑5个完整轮次(epochs)。
model.fit(train_ds,
validation_data=valid_ds,
epochs=5)
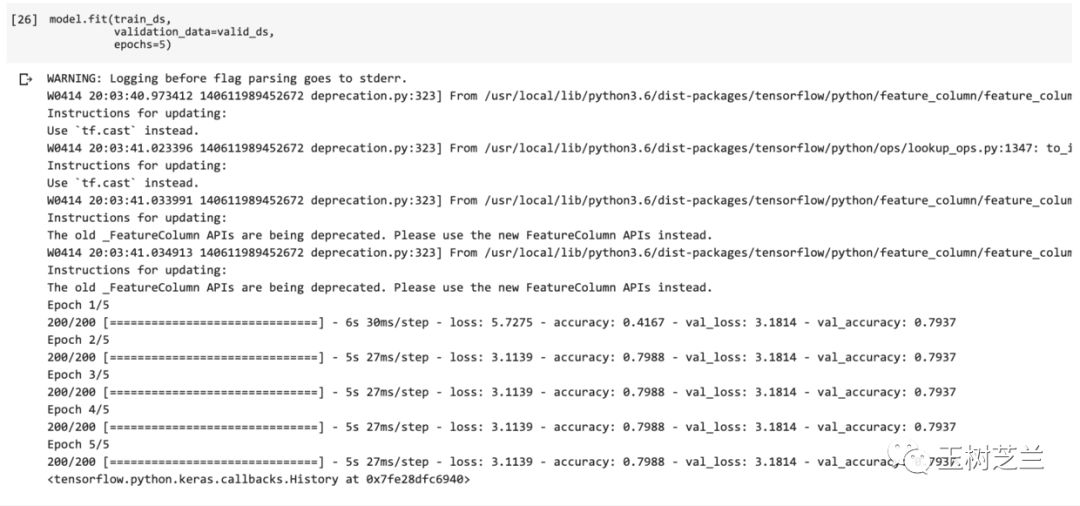
你会看到,最终的验证集准确率接近80%。
我们打印一下模型结构:
model.summary()
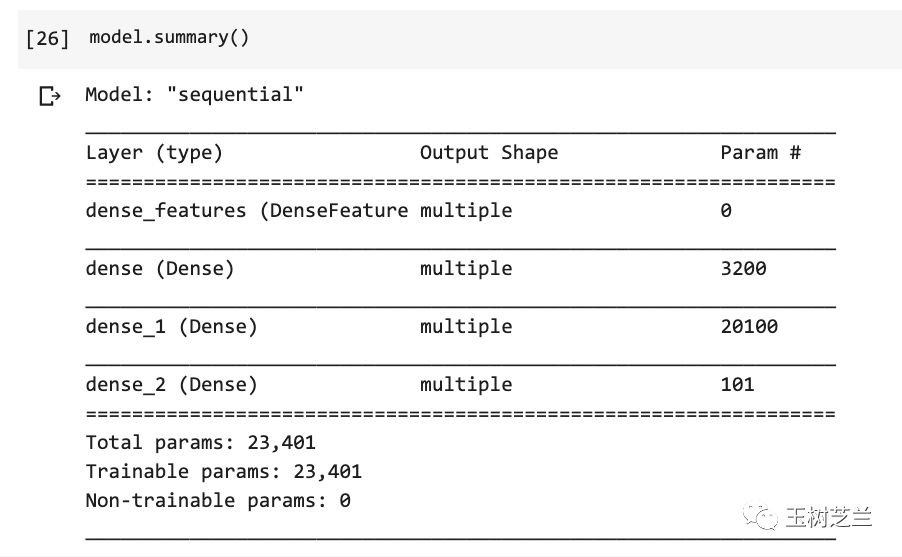
虽然我们的模型非常简单,却也依然包含了23401个参数。
下面,我们把测试集放入模型中,看看模型效果如何。
model.evaluate(test_ds)

依然,准确率接近80%。
还不错吧?
……
真的吗?
疑惑
如果你观察很仔细,可能刚才已经注意到了一个很奇特的现象:
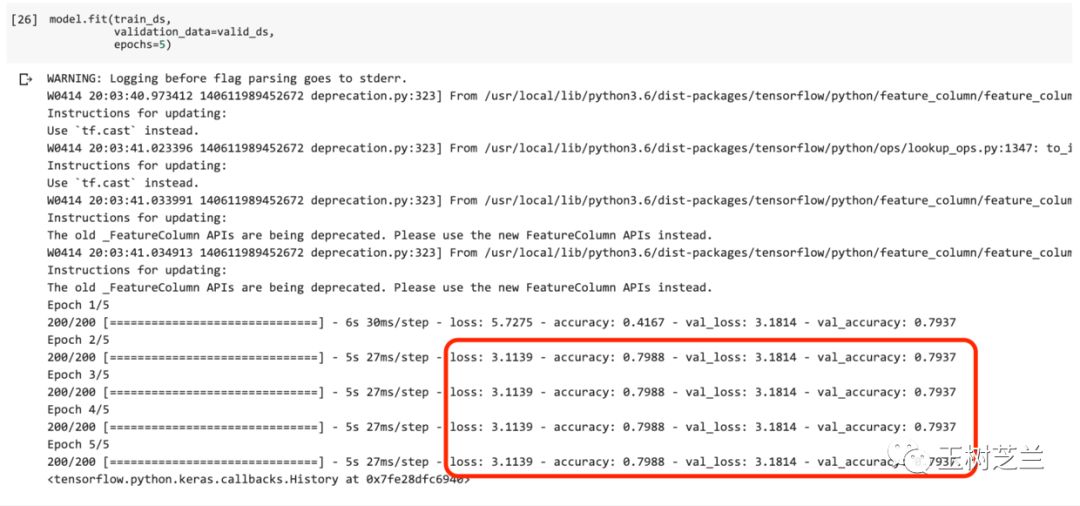
训练的过程中,除了第一个轮次外,其余4个轮次的这几项重要指标居然都没变!
它们包括:
训练集损失
训练集准确率
验证集损失
验证集准确率
所谓机器学习,就是不断迭代改进啊。如果每一轮下来,结果都一模一样,这难道不奇怪吗?难道没问题吗?
我希望你,能够像侦探一样,揪住这个可疑的线索,深入挖掘进去。
这里,我给你个提示。
看一个分类模型的好坏,不能只看准确率(accuracy)。对于二元分类问题,你可以关注一下 f1 score,以及混淆矩阵(confusion matrix)。
如果你验证了上述两个指标,那么你应该会发现真正的问题是什么。
下一步要穷究的,是问题产生的原因。
回顾一下咱们的整个儿过程,好像都很清晰明了,符合逻辑啊。究竟哪里出了问题呢?
如果你一眼就看出了问题。恭喜你,你对深度学习已经有感觉了。那么我继续追问你,该怎么解决这个问题呢?
欢迎你把思考后的答案在留言区告诉我。
对于第一名全部回答正确上述问题的读者,我会邀请你作为嘉宾,免费(原价199元)加入我本年度的知识星球。当然,前提是你愿意。
小结
希望通过本文的学习,你已掌握了以下知识点:
Tensorflow 2.0 的安装与使用;
表格式数据的神经网络分类模型构建;
特征工程的基本流程;
数据集合的随机分割与利用种子数值保持一致;
数值型数据列与类别型数据列的分别处理方式;
Keras 高阶 API 的模型搭建与训练;
数据框转化为 Tensorflow 数据流;
模型效果的验证;
缺失的一环,也即本文疑点产生的原因,以及正确处理方法。
希望本教程对于你处理表格型数据分类任务,能有帮助。
祝深度学习愉快!
(本文为AI科技大本营转载文章,转载请联系原作者)
长三角开发者联盟代码就是力量,长三角的开发者联合起来!
加入「长三角开发者联盟」将获得以下权益
长三角地区明星企业内推岗位
CSDN独家技术与行业报告
CSDN线下活动优先参与权
CSDN线上分享活动优先参与权
扫码添加联盟小助手,回复关键词“长三角2”,加入「长三角开发者联盟」。

推荐阅读:
机器学习萌新必备的三种优化算法 | 选型指南
A* 算法之父、人工智能先驱Nils Nilsson逝世 | 缅怀
Python程序员Debug的利器,和Print说再见 | 技术头条
入门AI第一步,从安装环境Ubuntu+Anaconda开始教!
小程序的侵权“生死局”
@996 程序员,ICU 你真的去不起!
Elastic Jeff Yoshimura:开源正在开启新一轮的创新 | 人物志
19岁当老板, 20岁ICO失败, 21岁将项目挂到了eBay, 为何初创公司如此艰难?
她说:为啥程序员都特想要机械键盘?这答案我服!

点击阅读原文,了解「CTA核心技术及应用峰会」。
相关文章:

【FFmpeg】Hello World!尝试如何编译FFmpeg程序
1、说明 下面的例子只演示,编译FFmpeg时用的头文件和库,不涉及编解码,只调用一个可以打印编译FFmpeg库的配置项的接口:avcodec_configuration() 2、avCfg.c #include <stdio.h> #include <libavcodec/avcodec.h>int main(int argc,char *argv[]
x-pack watch邮件报警配置
参考网址: https://www.cnblogs.com/reboot51/p/8328720.html https://www.elastic.co/guide/en/x-pack/5.6/actions-email.html #邮件设置 elasticsearch 配置 xpack.notification.email.account:exchange_account:profile: outlookemail_defaults:from: infomail.…

虚拟桌面的备份恢复最佳实践 第一部分
摘要 VMware View 是目前虚拟桌面市场的旗舰产品。借助它,企业可以将办公系统、应用和基础架构以高性能、高度可扩展的集中式托管服务形式交付给用户。View 还可提供保护它所支持的系统和应用以及相关用户数据所需的功能。它支持方便地备份和还原存档数据。 通常&…
Python程序员Debug利器,和Print说再见 | 技术头条
整理 | Rachel责编 | Jane出品 | Python大本营(id:pythonnews)【导语】程序员每日都在和 debug 相伴。新手程序员需要学习的 debug 手段复杂多样,设置断点、查看变量值……一些网站还专门针对debug撰写了新手教程。老司机们在大型…
【FFmpeg】解决警告warning: xxx is deprecated [-Wdeprecated-declarations]的方法
1、问题描述 编译FFmpeg程序时,经常报一些关于“deprecated”的警告信息,具体内容如下: decode.cpp:28:2: warning: ‘void av_register_all()’ is deprecated [-Wdeprecated-declarations]av_register_all(); decode.<
[BZOJ2527]Meteors
整体二分挺好玩的...学一发 这个询问显然是可以二分的,但每次都二分就会T爆,所以我们有了“整体”二分 每次处理一些询问,要求这些询问的答案一定在$[l,r]$中 先把$l$到$mid$的操作实施,那么当前TAK的询问答案一定在$[l,mid]$中&a…

一个可提供html5制作服务的网站
2019独角兽企业重金招聘Python工程师标准>>> 【TechWeb报道】最近网上出现了一个专门基于HTML5/CSS3制作服务的组织 P2H.cn. 就是专门提供网站切图的一项服务。特别在哪儿呢 ,P2H.cn 可以制作出完美的兼容的html5/css3的页面。 王大利/文 如果你不知…
【Ubuntu】Ubuntu下的录频软件SimpleScreenRecorder
1、说明 官网介绍:https://www.maartenbaert.be/simplescreenrecorder/ 源码参见github:https://github.com/MaartenBaert/ssr 2、安装 Ubuntu版本>17.04,直接安装 sudo apt-get install simplescreenrecorderUbuntu版本<17.04&…
打开阿兹海默之门:华裔张复伦利用RNN成功解码脑电波,合成语音 | Nature
作者 | 琥珀出品 | AI科技大本营(ID:rgznai100)2019 年 4 月 24 日,来自加州大学旧金山分校(UCSF)神经外科学系 Gopala K. Anumanchipalli,Josh Chartier,Edward F. Chang 团队在 Nature 杂志上…

[转载] 别人的心得感悟
原文: https://www.cnblogs.com/double-K/p/6926367.html#commentform ---------------------------------------- 不可说的感悟-——十年老技术转型(一) 佛曰:“不可说,说既是错”,所以本篇也是错…

Windows Phone 7、XNA的旋转的背景
在游戏表现的过程中需要一些比较酷的动作,我们需要通过图型与XNA中的一些代码来实现,比如我们要说到的一个360度转动的圆。 在手机上的效果如下: 当然在这里我们看不到转动的效果,下边提供的有源码,大家可以下载运行测试一下。 操…
【Qt】报错error: undefined reference to `vtable for的解决方法
1、问题描述 编译Qt程序时,在某个类构造函数定义处报错: error: undefined reference to vtable for2、原因分析 导致错误信息的原因是:子类没有实现父类的纯虚函数; 在Qt中,首先要想到的是在一个类中添加了新的继承…

110万开发者的福音,百度Easy DL商品检测专业版上线
继首场百度大脑开放日上一口气开放24项全新AI技术后,4 月 25 日下午,第二期百度大脑开放日如约举行,本次共发布了13款AI通用新能力、5项技术升级,并推出了EasyDL商品检测专业版和语音识别自训练平台两大全新的可定制训练平台。 实…

简单爬虫学习记录
实现思路解析:爬虫调度器:启动/停止爬虫,规定爬虫的范围;URL管理器:管理2个URL:新的没有爬过的urls;旧的爬过的urls;URL下载器:下载url对应的html数据;HTML解…

开启笔记本win7的虚拟热点,让你的本本变成wifi
写在前面:相信很多人都跟我一样有困扰,在学校用校园网不能wifi,所以在此提供一个教程,希望能给机友们一些帮助。帖子转自网络,自己也测试过了。分享给大家,希望能给大家带来一些方便。开启windows 7的隐藏功…
检测到包降级: Microsoft.Extensions.Configuration.Abstractions 从 2.1.1 降 2.1.0
解决方法:工具-nuget管理包-程序管理控制台-选择 项目- 执行 -Install-Package Microsoft.Extensions.Configuration.Abstractions -Version 2.1.1命令即可。 转载于:https://www.cnblogs.com/dashanboke/p/9229826.html
【FFmpeg】如何通过url的格式找到对应的协议,以rtmp为例
1、简述 在使用 avio_open 接口时,只要给形参 filename 传入 url 格式的字符串就能找到对应的协议。这篇博客就是追踪 avio_open 的调用关系,探明如何根据一个url字符串就能找到对应的协议。下面以rtmp协议为例。 2、FFmpeg对rtmp协议的支持 rtmp协议的实现源码在 libavfo…
李开复口中的“联邦学习” 到底是什么?| 技术头条
近日,在百大人物峰会上,创新工场创始人李开复谈及数据隐私保护和监管问题时,表示:“人们不应该只将人工智能带来的隐私问题视为一个监管问题,可尝试用‘以子之矛攻己之盾’——用更好的技术解决技术带来的挑战…
业务逻辑应该在哪里实现更为合理呢?
请大牛们讨论下业务逻辑应该在哪实现较为合理 1、java业务逻辑层。 2、后台存储过程。 因为本人一直都在业务逻辑层实现。但新项目中领导要求将业务写到后台存储过程,java业务逻辑层不承载业务逻辑的实现功能。 先说本人的观点: 本人偏向写在java业务逻辑…
前端不哭!最新优化性能经验分享来啦 | 技术头条
作者 | Dimitris Kiriakakis译者 | 风车云马编辑 | Jane出品 | Python大本营(id:pythonnews)【导语】Angular、React、VueJS 是现在一些主流的 JS 框架,那它们在构建网站或前端程序时,是如何保证性能,减少大…
【FFmpeg】如何通过字符串到对应的封装器,以flv为例
1、简述 使用avformat_alloc_output_context2创建封装器上下文AVFormatContext时,只需将封装器的名字传递给形参format_name,就可以获取对应的封装器。这篇博客就是追寻avformat_alloc_output_context2的调用关系,探明原因。 函数原型如下: int avformat_alloc_output_co…
坚持使用Override 注解(36)
2019独角兽企业重金招聘Python工程师标准>>> 1、覆盖超类时千万小心,一不小心就变成重载了 2、现代的IDE 会在覆盖父类方法而没有使用Override 时给出一个警告 在具体类中不必标注你确信覆盖了的抽象方法声明的方法(虽然这样做没什么不好&…
sql语句动态创建连接服务器
--建立连接服务器 EXEC sp_addlinkedserver --要创建的链接服务器名称 DMZLINK,--产品名称 MS,--OLE DB 字符 SQLOLEDB,--数据源 192.168.0.68 EXEC sp_addlinkedsrvlogin DMZLINK, false, NULL, --远程服务器的登陆用户名 sa, --远程服务器的登陆密码 sa go 转载于:h…
【FFmpeg】FFmpeg中操作目录、文件的接口
1、简述 在学习FFmpeg源码中的例子时,发现FFmpeg封装了操作目录和文件的接口。这篇博客把这些接口罗列出来,作为笔记简单记录下。 2、接口列表 打开目录,准备读取目录信息 int avio_open_dir(AVIODirContext **s, const char *url, AVDictionary **options); 参数说明: u…
Scrapy爬取IT之家
创建项目 scrapy startproject ithome 创建CrawSpider scrapy genspider -t crawl IT ithome.com items.py 1 import scrapy 2 3 4 class IthomeItem(scrapy.Item): 5 # define the fields for your item here like: 6 # name scrapy.Field() 7 title scrapy.F…
高效读CV论文法则:先在GitHub上立Flag!| 资源
整理 | 琥珀出品 | AI科技大本营(id:rgznai100)今天介绍一份在 GitHub 上发现的最新干货资源——计算机视觉论文笔记,该项目是由一位名叫 ahong007007 的网友贡献的。该项目上线仅 20 天,尚未获得太多人的关注…

JS+CSS控制左右切换鼠标可控的无缝图片滚动代码
代码简介: 以前见过这种效果,但是是基于FLASH技术,现在是纯用JS实现的,代码有点多,不过效果还不错,实际上它也是一个图片滚动,只不过它完全是用鼠标点击控制的,也就是说鼠标不点击的…
【FFmpeg】自定义回调函数处理AVIOContext中的数据
1、简述 AVIOContext是FFmpeg管理输入输出数据的结构体,它的成员变量有指向数据的指针、大小以及处理数据的回调函数指针等等。如果使用avio_open或avio_open2来创建,它会根据指定的url协议,将协议处理数据的回调函数指针赋值给AVIOContext的相应成员变量。 我们也可以自己…
ZooKeeper系列(4):ZooKeeper的配置文件详解
ZooKeeper系列文章:https://www.cnblogs.com/f-ck-need-u/p/7576137.html#zk zkServer.sh读取的默认配置文件是$ZOOKEEPER_HOME/conf/zoo.cfg。如果要用其它配置文件。如下传递配置文件参数: zkServer.sh start your_config zkServer.sh stop your_co…

明星企业内推+BAT面经,长三角的开发者联合起来!
“为什么公司宁愿花20K招新人,也不愿给老员工加到20K?”这个热门的微博话题戳起了很多人的痛处,但根据 CSDN &《程序员》杂志发布的「中国软件开发者薪资调查报告」,有32.98%的开发者在过去曾换过工作,其中有72.5%…