这或许是东半球分析十大排序算法最好的一篇文章

作者 | 不该相遇在秋天
转载自五分钟学算法(ID:CXYxiaowu)
前言
本文全长 14237 字,配有 70 张图片和动画,和你一起一步步看懂排序算法的运行过程。
预计阅读时间 47 分钟,强烈建议先收藏然后通过电脑端进行阅读。
No.1 冒泡排序
冒泡排序无疑是最为出名的排序算法之一,从序列的一端开始往另一端冒泡(你可以从左往右冒泡,也可以从右往左冒泡,看心情),依次比较相邻的两个数的大小(到底是比大还是比小也看你心情)。

冒泡排序动图演示
▌图解冒泡排序
以 [ 8,2,5,9,7 ] 这组数字来做示例,上图来战:
从左往右依次冒泡,将小的往右移动

冒泡排序1
首先比较第一个数和第二个数的大小,我们发现 2 比 8 要小,那么保持原位,不做改动。位置还是 8,2,5,9,7 。
指针往右移动一格,接着比较:

冒泡排序2
比较第二个数和第三个数的大小,发现 2 比 5 要小,所以位置交换,交换后数组更新为:[ 8,5,2,9,7 ]。
指针再往右移动一格,继续比较:

冒泡排序3
比较第三个数和第四个数的大小,发现 2 比 9 要小,所以位置交换,交换后数组更新为:[ 8,5,9,2,7 ]
同样,指针再往右移动,继续比较:

冒泡排序4
比较第 4 个数和第 5 个数的大小,发现 2 比 7 要小,所以位置交换,交换后数组更新为:[ 8,5,9,7,2 ]
下一步,指针再往右移动,发现已经到底了,则本轮冒泡结束,处于最右边的 2 就是已经排好序的数字。
通过这一轮不断的对比交换,数组中最小的数字移动到了最右边。
接下来继续第二轮冒泡:

冒泡排序5

冒泡排序6

冒泡排序7
由于右边的 2 已经是排好序的数字,就不再参与比较,所以本轮冒泡结束,本轮冒泡最终冒到顶部的数字 5 也归于有序序列中,现在数组已经变化成了[ 8,9,7,5,2 ]。

冒泡排序8
让我们开始第三轮冒泡吧!

冒泡排序9

冒泡排序10
由于 8 比 7 大,所以位置不变,此时第三轮冒泡也已经结束,第三轮冒泡的最后结果是[ 9,8,7,5,2 ]
紧接着第四轮冒泡:

冒泡排序11
9 和 8 比,位置不变,即确定了 8 进入有序序列,那么最后只剩下一个数字 9 ,放在末尾,自此排序结束。
▌代码实现
public static void sort(int arr[]){ for( int i = 0 ; i < arr.length - 1 ; i++ ){ for(int j = 0;j < arr.length - 1 - i ; j++){ int temp = 0; if(arr[j] < arr[j + 1]){ temp = arr[j]; arr[j] = arr[j + 1]; arr[j + 1] = temp; } } }
}冒泡的代码还是相当简单的,两层循环,外层冒泡轮数,里层依次比较,江湖中人人尽皆知。
我们看到嵌套循环,应该立马就可以得出这个算法的时间复杂度为O(n2)。
▌冒泡优化
冒泡有一个最大的问题就是这种算法不管不管你有序还是没序,闭着眼睛把你循环比较了再说。
比如我举个数组例子:[ 9,8,7,6,5 ],一个有序的数组,根本不需要排序,它仍然是双层循环一个不少的把数据遍历干净,这其实就是做了没必要做的事情,属于浪费资源。
针对这个问题,我们可以设定一个临时遍历来标记该数组是否已经有序,如果有序了就不用遍历了。
public static void sort(int arr[]){ for( int i = 0;i < arr.length - 1 ; i++ ){ boolean isSort = true; for( int j = 0;j < arr.length - 1 - i ; j++ ){ int temp = 0; if(arr[j] < arr[j + 1]){ temp = arr[j]; arr[j] = arr[j + 1]; arr[j + 1] = temp; isSort = false; } } if(isSort){ break; } }
}No.2 选择排序
选择排序的思路是这样的:首先,找到数组中最小的元素,拎出来,将它和数组的第一个元素交换位置,第二步,在剩下的元素中继续寻找最小的元素,拎出来,和数组的第二个元素交换位置,如此循环,直到整个数组排序完成。
至于选大还是选小,这个都无所谓,你也可以每次选择最大的拎出来排,也可以每次选择最小的拎出来的排,只要你的排序的手段是这种方式,都叫选择排序。

选择排序动画演示
▌图解选择排序
我们还是以[ 8,2,5,9,7 ]这组数字做例子。
第一次选择,先找到数组中最小的数字 2 ,然后和第一个数字交换位置。(如果第一个数字就是最小值,那么自己和自己交换位置,也可以不做处理,就是一个 if 的事情)

选择排序1
第二次选择,由于数组第一个位置已经是有序的,所以只需要查找剩余位置,找到其中最小的数字5,然后和数组第二个位置的元素交换。

选择排序2
第三次选择,找到最小值 7 ,和第三个位置的元素交换位置。

选择排序3
第四次选择,找到最小值8,和第四个位置的元素交换位置。

选择排序4
最后一个到达了数组末尾,没有可对比的元素,结束选择。
如此整个数组就排序完成了。
▌代码实现
public static void sort(int arr[]){ for( int i = 0;i < arr.length ; i++ ){ int min = i;//最小元素的下标 for(int j = i + 1;j < arr.length ; j++ ){ if(arr[j] < arr[min]){ min = j;//找最小值 } } //交换位置 int temp = arr[i]; arr[i] = arr[min]; arr[min] = temp; }
}双层循环,时间复杂度和冒泡一模一样,都是O(n2)。
No.3 插入排序
插入排序的思想和我们打扑克摸牌的时候一样,从牌堆里一张一张摸起来的牌都是乱序的,我们会把摸起来的牌插入到左手中合适的位置,让左手中的牌时刻保持一个有序的状态。
那如果我们不是从牌堆里摸牌,而是左手里面初始化就是一堆乱牌呢? 一样的道理,我们把牌往手的右边挪一挪,把手的左边空出一点位置来,然后在乱牌中抽一张出来,插入到左边,再抽一张出来,插入到左边,再抽一张,插入到左边,每次插入都插入到左边合适的位置,时刻保持左边的牌是有序的,直到右边的牌抽完,则排序完毕。
插入排序动画演示
▌图解插入排序
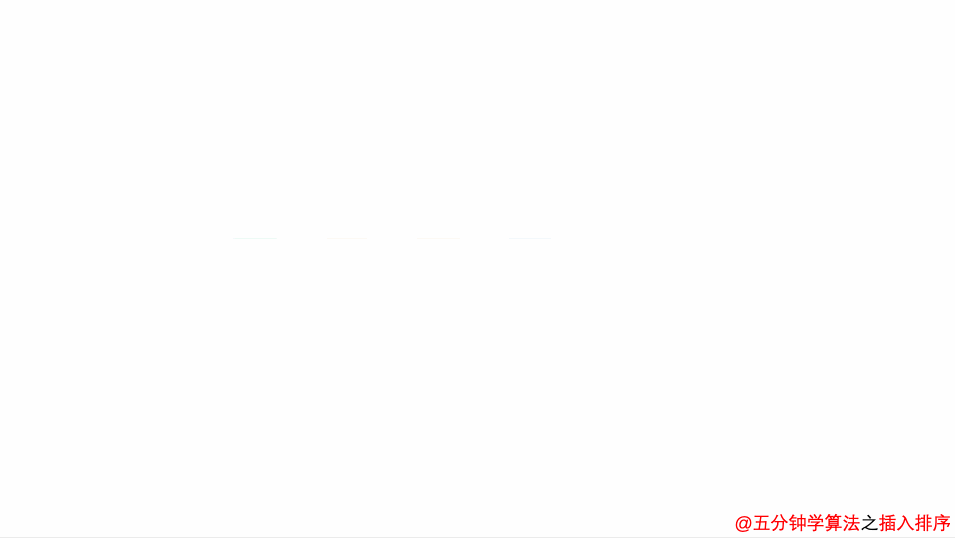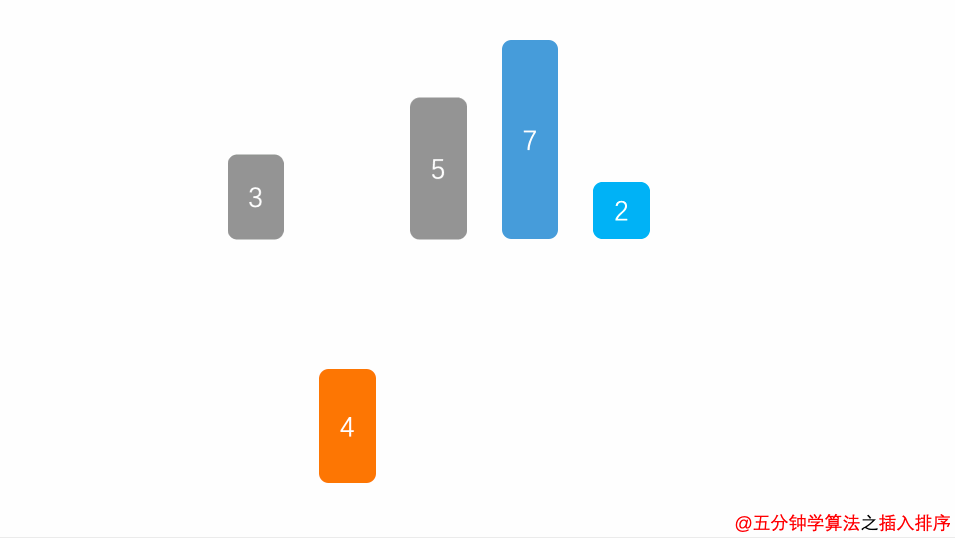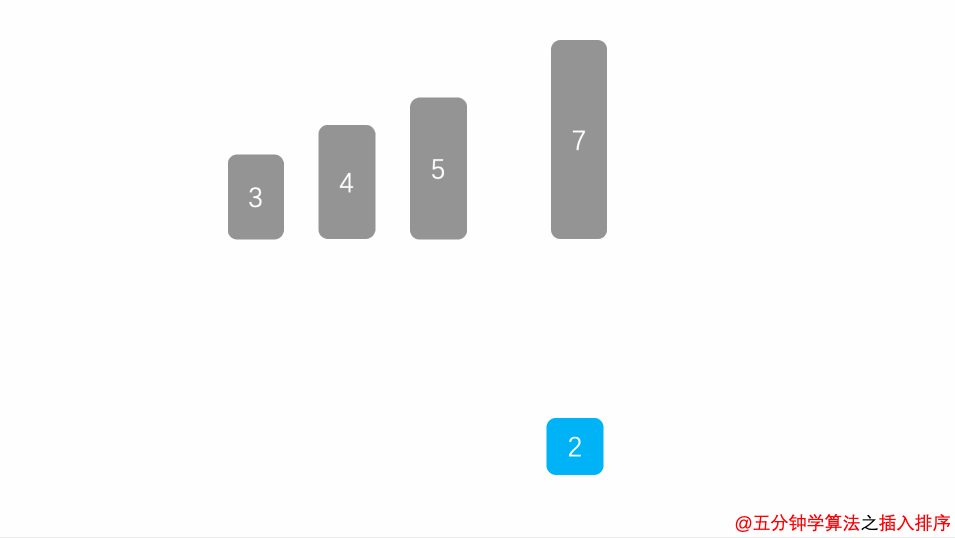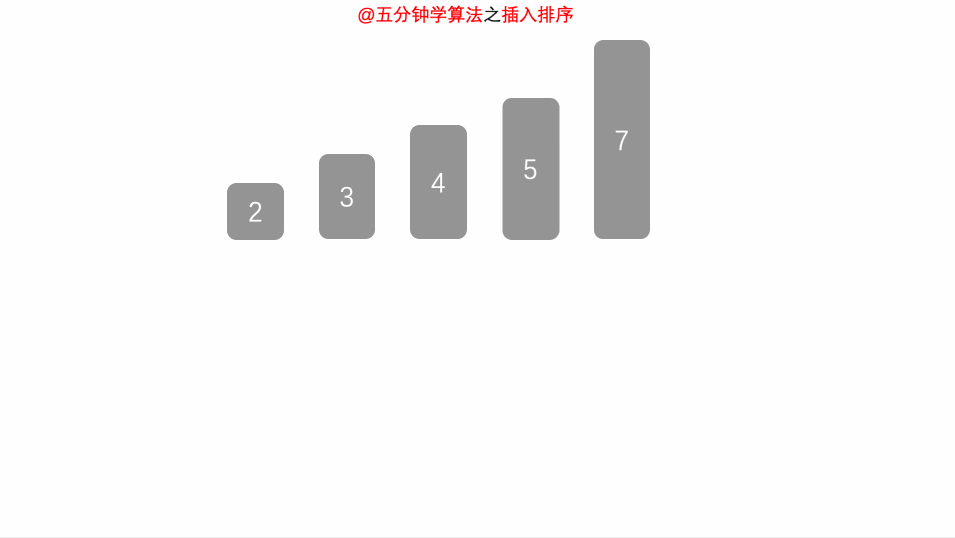
数组初始化:[ 8,2,5,9,7 ],我们把数组中的数据分成两个区域,已排序区域和未排序区域,初始化的时候所有的数据都处在未排序区域中,已排序区域是空。

插入排序1
第一轮,从未排序区域中随机拿出一个数字,既然是随机,那么我们就获取第一个,然后插入到已排序区域中,已排序区域是空,那么就不做比较,默认自身已经是有序的了。(当然了,第一轮在代码中是可以省略的,从下标为1的元素开始即可)

插入排序2
第二轮,继续从未排序区域中拿出一个数,插入到已排序区域中,这个时候要遍历已排序区域中的数字挨个做比较,比大比小取决于你是想升序排还是想倒序排,这里排升序:

插入排序3
第三轮,排 5 :

插入排序4
第四轮,排 9 :

插入排序5
第五轮,排 7

插入排序6
排序结束。
▌代码实现
public static void sort(int[] arr) { int n = arr.length; for (int i = 1; i < n; ++i) { int value = arr[i]; int j = 0;//插入的位置 for (j = i-1; j >= 0; j--) { if (arr[j] > value) { arr[j+1] = arr[j];//移动数据 } else { break; } } arr[j+1] = value; //插入数据 }
}从代码里我们可以看出,如果找到了合适的位置,就不会再进行比较了,就好比牌堆里抽出的一张牌本身就比我手里的牌都小,那么我只需要直接放在末尾就行了,不用一个一个去移动数据腾出位置插入到中间。
所以说,最好情况的时间复杂度是 O(n),最坏情况的时间复杂度是 O(n2),然而时间复杂度这个指标看的是最坏的情况,而不是最好的情况,所以插入排序的时间复杂度是 O(n2)。
No.4 希尔排序
希尔排序这个名字,来源于它的发明者希尔,也称作“缩小增量排序”,是插入排序的一种更高效的改进版本。
我们知道,插入排序对于大规模的乱序数组的时候效率是比较慢的,因为它每次只能将数据移动一位,希尔排序为了加快插入的速度,让数据移动的时候可以实现跳跃移动,节省了一部分的时间开支。

希尔排序动画演示
▌图解希尔排序
待排序数组 10 个数据:
希尔排序1
假设计算出的排序区间为 4 ,那么我们第一次比较应该是用第 5 个数据与第 1 个数据相比较。

希尔排序2
调换后的数据为[ 7,2,5,9,8,10,1,15,12,3 ],然后指针右移,第 6 个数据与第 2 个数据相比较。

希尔排序3
指针右移,继续比较。

希尔排序4

希尔排序5
如果交换数据后,发现减去区间得到的位置还存在数据,那么继续比较,比如下面这张图,12 和 8 相比较,原地不动后,指针从 12 跳到 8 身上,继续减去区间发现前面还有一个下标为 0 的数据 7 ,那么 8 和 7 相比较。

希尔排序6
比较完之后的效果是 7,8,12 三个数为有序排列。

希尔排序7
当最后一个元素比较完之后,我们会发现大部分值比较大的数据都似乎调整到数组的中后部分了。
假设整个数组比较长的话,比如有 100 个数据,那么我们的区间肯定是四五十,调整后区间再缩小成一二十还会重新调整一轮,直到最后区间缩小为 1,就是真正的排序来了。

希尔排序8
指针右移,继续比较:

希尔排序9
重复步骤,即可完成排序,重复的图就不多画了。
我们可以发现,当区间为 1 的时候,它使用的排序方式就是插入排序。
▌代码实现
public static void sort(int[] arr) { int length = arr.length; //区间 int gap = 1; while (gap < length) { gap = gap * 3 + 1; } while (gap > 0) { for (int i = gap; i < length; i++) { int tmp = arr[i]; int j = i - gap; //跨区间排序 while (j >= 0 && arr[j] > tmp) { arr[j + gap] = arr[j]; j -= gap; } arr[j + gap] = tmp; } gap = gap / 3; }
}可能你会问为什么区间要以 gap = gap*3 + 1 去计算,其实最优的区间计算方法是没有答案的,这是一个长期未解决的问题,不过差不多都会取在二分之一到三分之一附近。
No.5 归并排序
归并字面上的意思是合并,归并算法的核心思想是分治法,就是将一个数组一刀切两半,递归切,直到切成单个元素,然后重新组装合并,单个元素合并成小数组,两个小数组合并成大数组,直到最终合并完成,排序完毕。
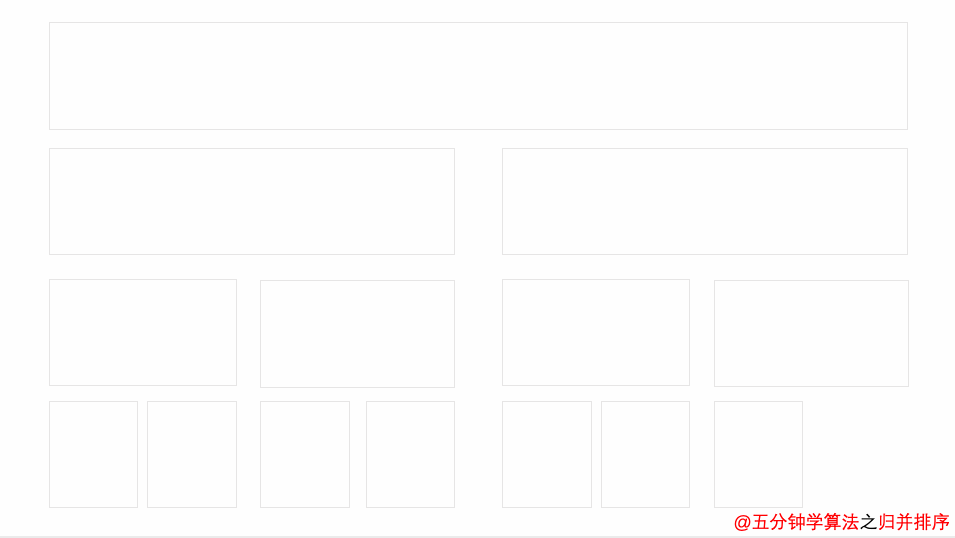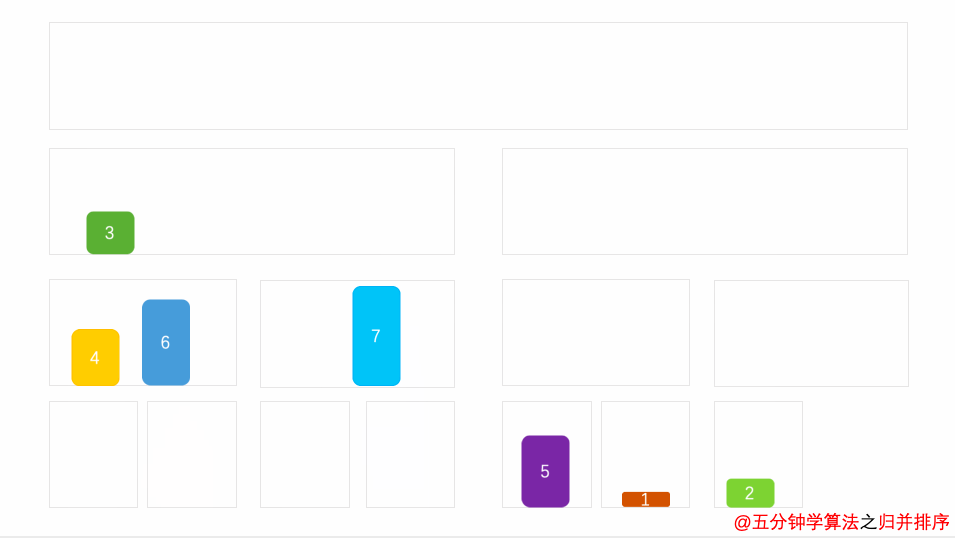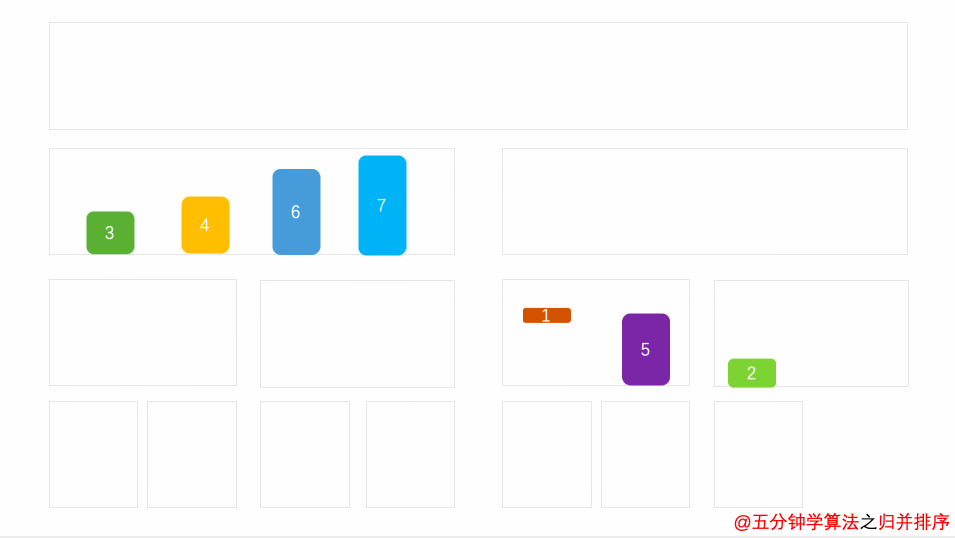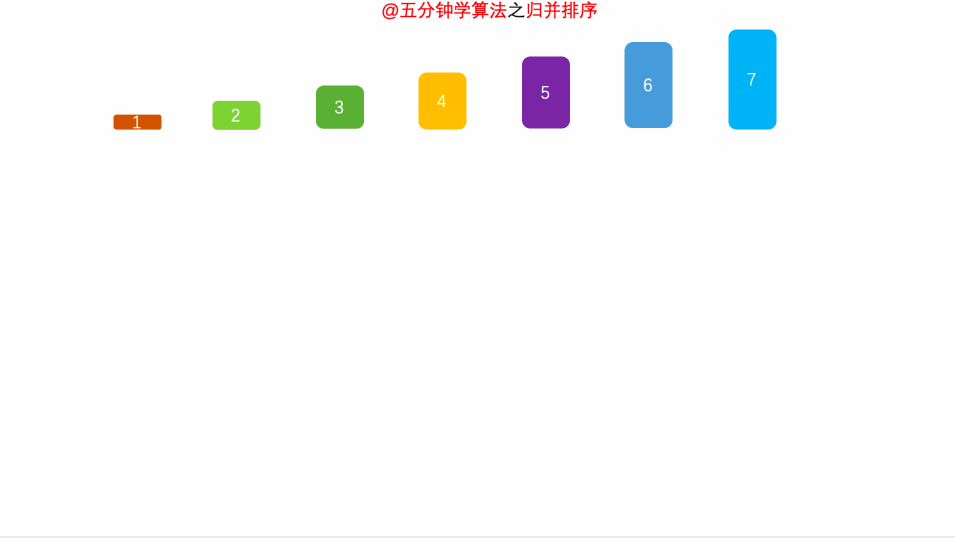
归并排序动画演示
▌图解归并排序
我们以[ 8,2,5,9,7 ]这组数字来举例

归并排序1
首先,一刀切两半:

归并排序2
再切:

归并排序3
再切

归并排序4
粒度切到最小的时候,就开始归并

归并排序5

归并排序6

归并排序7
数据量设定的比较少,是为了方便图解,数据量为单数,是为了让你看到细节,下面我画了一张更直观的图可能你会更喜欢:

归并排序8
▌代码实现
我们上面讲过,归并排序的核心思想是分治,分而治之,将一个大问题分解成无数的小问题进行处理,处理之后再合并,这里我们采用递归来实现:
public static void sort(int[] arr) { int[] tempArr = new int[arr.length]; sort(arr, tempArr, 0, arr.length-1); } /** * 归并排序 * @param arr 排序数组 * @param tempArr 临时存储数组 * @param startIndex 排序起始位置 * @param endIndex 排序终止位置 */ private static void sort(int[] arr,int[] tempArr,int startIndex,int endIndex){ if(endIndex <= startIndex){ return; } //中部下标 int middleIndex = startIndex + (endIndex - startIndex) / 2; //分解 sort(arr,tempArr,startIndex,middleIndex); sort(arr,tempArr,middleIndex + 1,endIndex); //归并 merge(arr,tempArr,startIndex,middleIndex,endIndex); } /** * 归并 * @param arr 排序数组 * @param tempArr 临时存储数组 * @param startIndex 归并起始位置 * @param middleIndex 归并中间位置 * @param endIndex 归并终止位置 */ private static void merge(int[] arr, int[] tempArr, int startIndex, int middleIndex, int endIndex) { //复制要合并的数据 for (int s = startIndex; s <= endIndex; s++) { tempArr[s] = arr[s]; } int left = startIndex;//左边首位下标 int right = middleIndex + 1;//右边首位下标 for (int k = startIndex; k <= endIndex; k++) { if(left > middleIndex){ //如果左边的首位下标大于中部下标,证明左边的数据已经排完了。 arr[k] = tempArr[right++]; } else if (right > endIndex){ //如果右边的首位下标大于了数组长度,证明右边的数据已经排完了。 arr[k] = tempArr[left++]; } else if (tempArr[right] < tempArr[left]){ arr[k] = tempArr[right++];//将右边的首位排入,然后右边的下标指针+1。 } else { arr[k] = tempArr[left++];//将左边的首位排入,然后左边的下标指针+1。 } } } 我们可以发现 merge 方法中只有一个 for 循环,直接就可以得出每次合并的时间复杂度为 O(n) ,而分解数组每次对半切割,属于对数时间 O(log n) ,合起来等于 O(log2n) ,也就是说,总的时间复杂度为 O(nlogn) 。
关于空间复杂度,其实大部分人写的归并都是在 merge 方法里面申请临时数组,用临时数组来辅助排序工作,空间复杂度为 O(n),而我这里做的是原地归并,只在最开始申请了一个临时数组,所以空间复杂度为 O(1)。
如果你对空间复杂度这一块不太了解,可以查看小吴之前的数据结构系列文章---冰与火之歌:「时间」与「空间」复杂度 。
No.6 快速排序
快速排序的核心思想也是分治法,分而治之。它的实现方式是每次从序列中选出一个基准值,其他数依次和基准值做比较,比基准值大的放右边,比基准值小的放左边,然后再对左边和右边的两组数分别选出一个基准值,进行同样的比较移动,重复步骤,直到最后都变成单个元素,整个数组就成了有序的序列。
(周知:动图里面的大于小于写反,小吴修正重新录制后,上传新动图到微信后台却一直失败)

快速排序动画演示
▌图解快速排序
我们以[ 8,2,5,0,7,4,6,1 ]这组数字来进行演示
首先,我们随机选择一个基准值:

快速排序1
与其他元素依次比较,大的放右边,小的放左边:

快速排序2
然后我们以同样的方式排左边的数据:

快速排序3
继续排 0 和 1 :

快速排序4
由于只剩下一个数,所以就不用排了,现在的数组序列是下图这个样子:

快速排序5
右边以同样的操作进行,即可排序完成。
▌单边扫描
快速排序的关键之处在于切分,切分的同时要进行比较和移动,这里介绍一种叫做单边扫描的做法。
我们随意抽取一个数作为基准值,同时设定一个标记 mark 代表左边序列最右侧的下标位置,当然初始为 0 ,接下来遍历数组,如果元素大于基准值,无操作,继续遍历,如果元素小于基准值,则把 mark + 1 ,再将 mark 所在位置的元素和遍历到的元素交换位置,mark 这个位置存储的是比基准值小的数据,当遍历结束后,将基准值与 mark 所在元素交换位置即可。
▌代码实现
public static void sort(int[] arr) { sort(arr, 0, arr.length - 1);
} private static void sort(int[] arr, int startIndex, int endIndex) { if (endIndex <= startIndex) { return; } //切分 int pivotIndex = partitionV2(arr, startIndex, endIndex); sort(arr, startIndex, pivotIndex-1); sort(arr, pivotIndex+1, endIndex);
} private static int partition(int[] arr, int startIndex, int endIndex) { int pivot = arr[startIndex];//取基准值 int mark = startIndex;//Mark初始化为起始下标 for(int i=startIndex+1; i<=endIndex; i++){ if(arr[i]<pivot){ //小于基准值 则mark+1,并交换位置。 mark ++; int p = arr[mark]; arr[mark] = arr[i]; arr[i] = p; } } //基准值与mark对应元素调换位置 arr[startIndex] = arr[mark]; arr[mark] = pivot; return mark;
}▌双边扫描
另外还有一种双边扫描的做法,看起来比较直观:我们随意抽取一个数作为基准值,然后从数组左右两边进行扫描,先从左往右找到一个大于基准值的元素,将下标指针记录下来,然后转到从右往左扫描,找到一个小于基准值的元素,交换这两个元素的位置,重复步骤,直到左右两个指针相遇,再将基准值与左侧最右边的元素交换。
我们来看一下实现代码,不同之处只有 partition 方法:
public static void sort(int[] arr) { sort(arr, 0, arr.length - 1);
} private static void sort(int[] arr, int startIndex, int endIndex) { if (endIndex <= startIndex) { return; } //切分 int pivotIndex = partition(arr, startIndex, endIndex); sort(arr, startIndex, pivotIndex-1); sort(arr, pivotIndex+1, endIndex);
} private static int partition(int[] arr, int startIndex, int endIndex) { int left = startIndex; int right = endIndex; int pivot = arr[startIndex];//取第一个元素为基准值 while (true) { //从左往右扫描 while (arr[left] <= pivot) { left++; if (left == right) { break; } } //从右往左扫描 while (pivot < arr[right]) { right--; if (left == right) { break; } } //左右指针相遇 if (left >= right) { break; } //交换左右数据 int temp = arr[left]; arr[left] = arr[right]; arr[right] = temp; } //将基准值插入序列 int temp = arr[startIndex]; arr[startIndex] = arr[right]; arr[right] = temp; return right;
}▌极端情况
快速排序的时间复杂度和归并排序一样,O(n log n),但这是建立在每次切分都能把数组一刀切两半差不多大的前提下,如果出现极端情况,比如排一个有序的序列,如[ 9,8,7,6,5,4,3,2,1 ],选取基准值 9 ,那么需要切分 n - 1 次才能完成整个快速排序的过程,这种情况下,时间复杂度就退化成了 O(n2),当然极端情况出现的概率也是比较低的。
所以说,快速排序的时间复杂度是 O(nlogn),极端情况下会退化成 O(n2),为了避免极端情况的发生,选取基准值应该做到随机选取,或者是打乱一下数组再选取。
另外,快速排序的空间复杂度为 O(1)。
No.7 堆排序
堆排序顾名思义,是利用堆这种数据结构来进行排序的算法。
如果你不了解堆这种数据结构,可以查看小吴之前的数据结构系列文章---看动画轻松理解堆
如果你了解堆这种数据结构,你应该知道堆是一种优先队列,两种实现,最大堆和最小堆,由于我们这里排序按升序排,所以就直接以最大堆来说吧。
我们完全可以把堆(以下全都默认为最大堆)看成一棵完全二叉树,但是位于堆顶的元素总是整棵树的最大值,每个子节点的值都比父节点小,由于堆要时刻保持这样的规则特性,所以一旦堆里面的数据发生变化,我们必须对堆重新进行一次构建。
既然堆顶元素永远都是整棵树中的最大值,那么我们将数据构建成堆后,只需要从堆顶取元素不就好了吗? 第一次取的元素,是否取的就是最大值?取完后把堆重新构建一下,然后再取堆顶的元素,是否取的就是第二大的值? 反复的取,取出来的数据也就是有序的数据。

堆排序动画演示
▌图解堆排序
我们以[ 8,2,5,9,7,3 ]这组数据来演示。
首先,将数组构建成堆。

堆排序1
既然构建成堆结构了,那么接下来,我们取出堆顶的数据,也就是数组第一个数 9 ,取法是将数组的第一位和最后一位调换,然后将数组的待排序范围 -1。

堆排序2
现在的待排序数据是[ 3,8,5,2,7 ],我们继续将待排序数据构建成堆。

堆排序3
取出堆顶数据,这次就是第一位和倒数第二位交换了,因为待排序的边界已经减 1 。

堆排序4
继续构建堆

堆排序5
从堆顶取出来的数据最终形成一个有序列表,重复的步骤就不再赘述了,我们来看一下代码实现。
▌代码实现
public static void sort(int[] arr) { int length = arr.length; //构建堆 buildHeap(arr, length); for ( int i = length - 1; i > 0; i-- ) { //将堆顶元素与末位元素调换 int temp = arr[0]; arr[0] = arr[i]; arr[i] = temp; //数组长度-1 隐藏堆尾元素 length--; //将堆顶元素下沉 目的是将最大的元素浮到堆顶来 sink(arr, 0, length); }
}
private static void buildHeap(int[] arr, int length) { for (int i = length / 2; i >= 0; i--) { sink(arr, i, length); }
} /** * 下沉调整 * @param arr 数组 * @param index 调整位置 * @param length 数组范围 */
private static void sink(int[] arr, int index, int length) { int leftChild = 2 * index + 1;//左子节点下标 int rightChild = 2 * index + 2;//右子节点下标 int present = index;//要调整的节点下标 //下沉左边 if (leftChild < length && arr[leftChild] > arr[present]) { present = leftChild; } //下沉右边 if (rightChild < length && arr[rightChild] > arr[present]) { present = rightChild; } //如果下标不相等 证明调换过了 if (present != index) { //交换值 int temp = arr[index]; arr[index] = arr[present]; arr[present] = temp; //继续下沉 sink(arr, present, length); }
}堆排序和快速排序的时间复杂度都一样是 O(nlogn)。
No.8 计数排序
计数排序是一种非基于比较的排序算法,我们之前介绍的各种排序算法几乎都是基于元素之间的比较来进行排序的,计数排序的时间复杂度为 O(n + m ),m 指的是数据量,说的简单点,计数排序算法的时间复杂度约等于 O(n),快于任何比较型的排序算法。
计数排序动画演示
▌图解计数排序
以下以[ 3,5,8,2,5,4 ]这组数字来演示。
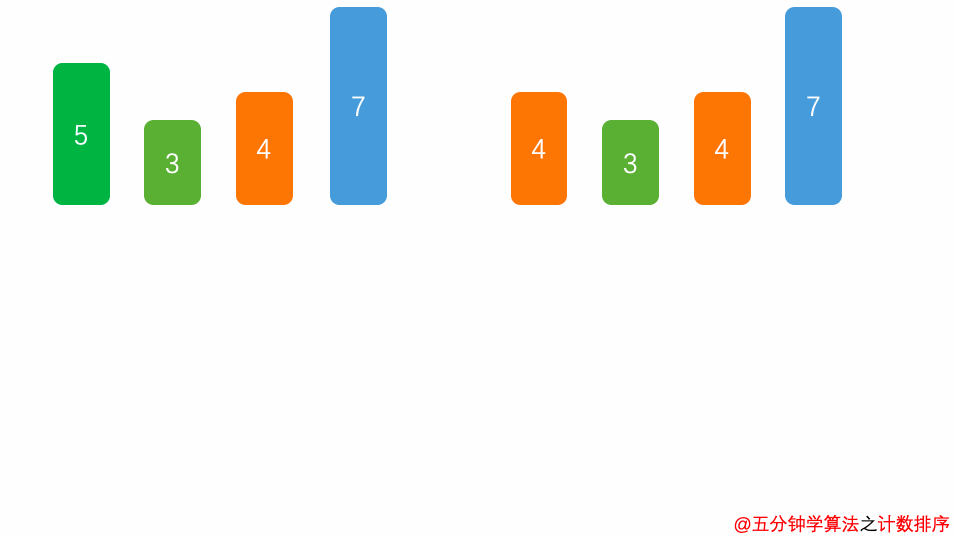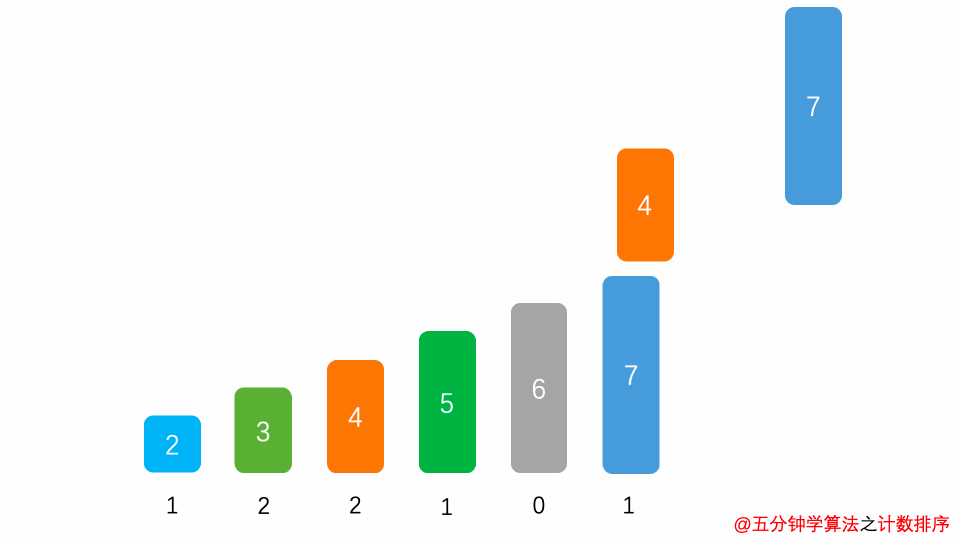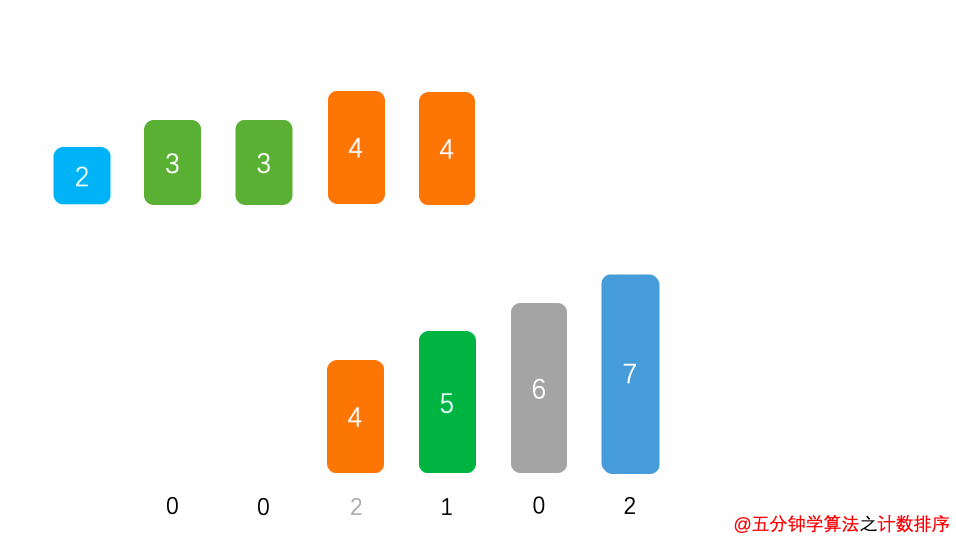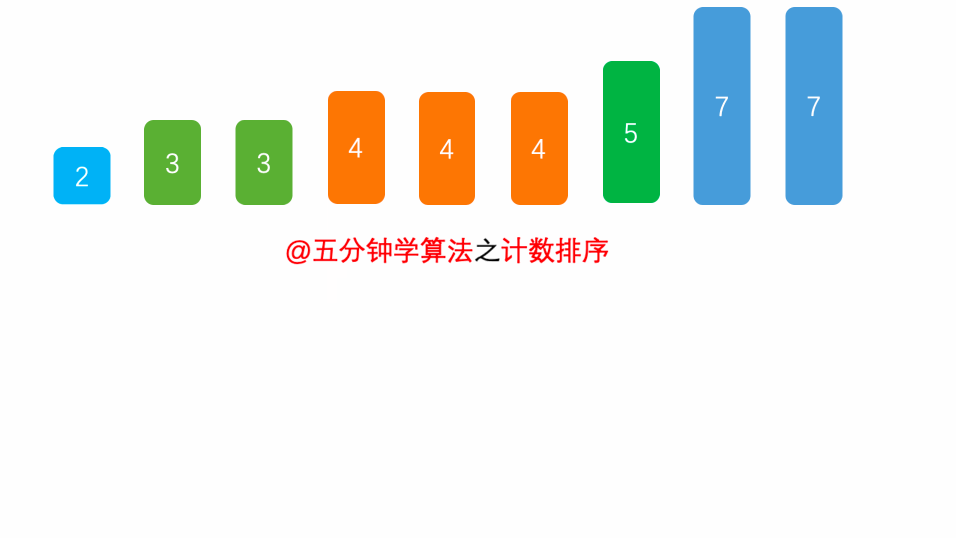
首先,我们找到这组数字中最大的数,也就是 8,创建一个最大下标为 8 的空数组 arr 。

计数排序1
遍历数据,将数据的出现次数填入arr中对应的下标位置中。

计数排序2
遍历 arr ,将数据依次取出即可。

计数排序3
▌代码实现
public static void sort(int[] arr) { //找出数组中的最大值 int max = arr[0]; for (int i = 1; i < arr.length; i++) { if (arr[i] > max) { max = arr[i]; } } //初始化计数数组 int[] countArr = new int[max + 1]; //计数 for (int i = 0; i < arr.length; i++) { countArr[arr[i]]++; arr[i] = 0; } //排序 int index = 0; for (int i = 0; i < countArr.length; i++) { if (countArr[i] > 0) { arr[index++] = i; } }
}▌稳定排序
有一个需求就是当对成绩进行排名次的时候,如何在原来排前面的人,排序后还是处于相同成绩的人的前面。
解题的思路是对 countArr 计数数组进行一个变形,变来和名次挂钩,我们知道 countArr 存放的是分数的出现次数,那么其实我们可以算出每个分数的最大名次,就是将 countArr 中的每个元素顺序求和。
如下图:

稳定排序
变形之后是什么意思呢?
我们把原数组[ 2,5,8,2,5,4 ]中的数据依次拿来去 countArr 去找,你会发现 3 这个数在 countArr[3] 中的值是 2 ,代表着排名第二名,(因为第一名是最小的 2,对吧?),5 这个数在 countArr[5] 中的值是 5 ,为什么是 5 呢?我们来数数,排序后的数组应该是[ 2,3,4,5,5,8 ],5 的排名是第五名,那 4 的排名是第几名呢?对应 countArr[4] 的值是 3 ,第三名,5 的排名是第五名是因为 5 这个数有两个,自然占据了第 4 名和第 5 名。
所以我们取排名的时候应该特别注意,原数组中的数据要从右往左取,从 countArr 取出排名后要把 countArr 中的排名减 1 ,以便于再次取重复数据的时候排名往前一位。
对应代码实现:
public static void sort(int[] arr) { //找出数组中的最大值 int max = arr[0]; for (int i = 1; i < arr.length; ++i) { if (arr[i] > max) { max = arr[i]; } } //初始化计数数组 int[] countArr = new int[max + 1]; //计数 for (int i = 0; i < arr.length; ++i) { countArr[arr[i]]++; } //顺序累加 for (int i = 1; i < max + 1; ++i) { countArr[i] = countArr[i-1] + countArr[i]; } //排序后的数组 int[] sortedArr = new int[arr.length]; //排序 for (int i = arr.length - 1; i >= 0; --i) { sortedArr[countArr[arr[i]]-1] = arr[i]; countArr[arr[i]]--; } //将排序后的数据拷贝到原数组 for (int i = 0; i < arr.length; ++i) { arr[i] = sortedArr[i]; }
}计数局限性
计数排序的毛病很多,我们来找找 bug 。
如果我要排的数据里有 0 呢? int[] 初始化内容全是 0 ,排毛线。
如果我要排的数据范围比较大呢?比如[ 1,9999 ],我排两个数你要创建一个 int[10000] 的数组来计数?
对于第一个 bug ,我们可以使用偏移量来解决,比如我要排[ -1,0,-3 ]这组数字,这个简单,我全给你们加 10 来计数,变成[ 9,10,7 ]计完数后写回原数组时再减 10。不过有可能也会踩到坑,万一你数组里恰好有一个 -10,你加上 10 后又变 0 了,排毛线。
对于第二个 bug ,确实解决不了,如果是[ 9998,9999 ]这种虽然值大但是相差范围不大的数据我们也可以使用偏移量解决,比如这两个数据,我减掉 9997 后只需要申请一个 int[3] 的数组就可以进行计数。
由此可见,计数排序只适用于正整数并且取值范围相差不大的数组排序使用,它的排序的速度是非常可观的。
No.9 桶排序
桶排序可以看成是计数排序的升级版,它将要排的数据分到多个有序的桶里,每个桶里的数据再单独排序,再把每个桶的数据依次取出,即可完成排序。

桶排序动画演示
▌图解桶排序
我们拿一组计数排序啃不掉的数据 [ 500,6123,1700,10,9999 ] 来举例。
第一步,我们创建 10 个桶,分别来装 0-1000 、1000-2000 、 2000-3000 、 3000-4000 、 4000-5000 、5000-6000、 6000-7000 、7000-8000 、8000-9000 区间的数据。

桶排序1
第二步,遍历原数组,对号入桶。

桶排序2
第三步,对桶中的数据进行单独排序,只有第一个桶中的数量大于 1 ,显然只需要排第一个桶。

桶排序3
最后,依次将桶中的数据取出,排序完成。

桶排序4
▌代码实现
这个桶排序乍一看好像挺简单的,但是要敲代码就需要考虑几个问题了。
桶这个东西怎么表示?
怎么确定桶的数量?
桶内排序用什么方法排?
代码如下:
public static void sort(int[] arr){ //最大最小值 int max = arr[0]; int min = arr[0]; int length = arr.length; for(int i=1; i<length; i++) { if(arr[i] > max) { max = arr[i]; } else if(arr[i] < min) { min = arr[i]; } } //最大值和最小值的差 int diff = max - min; //桶列表 ArrayList<ArrayList<Integer>> bucketList = new ArrayList<>(); for(int i = 0; i < length; i++){ bucketList.add(new ArrayList<>()); } //每个桶的存数区间 float section = (float) diff / (float) (length - 1); //数据入桶 for(int i = 0; i < length; i++){ //当前数除以区间得出存放桶的位置 减1后得出桶的下标 int num = (int) (arr[i] / section) - 1; if(num < 0){ num = 0; } bucketList.get(num).add(arr[i]); } //桶内排序 for(int i = 0; i < bucketList.size(); i++){ //jdk的排序速度当然信得过 Collections.sort(bucketList.get(i)); } //写入原数组 int index = 0; for(ArrayList<Integer> arrayList : bucketList){ for(int value : arrayList){ arr[index] = value; index++; } }
}桶当然是一个可以存放数据的集合,我这里使用 arrayList ,如果你使用 LinkedList 那其实也是没有问题的。
桶的数量我认为设置为原数组的长度是合理的,因为理想情况下每个数据装一个桶。
数据入桶的映射算法其实是一个开放性问题,我承认我这里写的方案并不佳,因为我测试过不同的数据集合来排序,如果你有什么更好的方案或想法,欢迎留言讨论。
桶内排序为了方便起见使用了当前语言提供的排序方法,如果对于稳定排序有所要求,可以选择使用自定义的排序算法。
▌桶排序的思考及其应用
在额外空间充足的情况下,尽量增大桶的数量,极限情况下每个桶只有一个数据时,或者是每只桶只装一个值时,完全避开了桶内排序的操作,桶排序的最好时间复杂度就能够达到 O(n)。
比如高考总分 750 分,全国几百万人,我们只需要创建 751 个桶,循环一遍挨个扔进去,排序速度是毫秒级。
但是如果数据经过桶的划分之后,桶与桶的数据分布极不均匀,有些数据非常多,有些数据非常少,比如[ 8,2,9,10,1,23,53,22,12,9000 ]这十个数据,我们分成十个桶装,结果发现第一个桶装了 9 个数据,这是非常影响效率的情况,会使时间复杂度下降到 O(nlogn),解决办法是我们每次桶内排序时判断一下数据量,如果桶里的数据量过大,那么应该在桶里面回调自身再进行一次桶排序。
No.10 基数排序
基数排序是一种非比较型整数排序算法,其原理是将数据按位数切割成不同的数字,然后按每个位数分别比较。
假设说,我们要对 100 万个手机号码进行排序,应该选择什么排序算法呢?排的快的有归并、快排时间复杂度是 O(nlogn),计数排序和桶排序虽然更快一些,但是手机号码位数是11位,那得需要多少桶?内存条表示不服。
这个时候,我们使用基数排序是最好的选择。

▌图解基数排序
我们以[ 892, 846, 821, 199, 810,700 ]这组数字来做例子演示。
首先,创建十个桶,用来辅助排序。

基数排序1
先排个位数,根据个位数的值将数据放到对应下标值的桶中。

基数排序2
排完后,我们将桶中的数据依次取出。

基数排序3
那么接下来,我们排十位数。

基数排序4
最后,排百位数。

基数排序5
排序完成。
▌代码实现
基数排序可以看成桶排序的扩展,也是用桶来辅助排序,代码如下:
public static void sort(int[] arr){ int length = arr.length; //最大值 int max = arr[0]; for(int i = 0;i < length;i++){ if(arr[i] > max){ max = arr[i]; } } //当前排序位置 int location = 1; //桶列表 ArrayList<ArrayList<Integer>> bucketList = new ArrayList<>(); //长度为10 装入余数0-9的数据 for(int i = 0; i < 10; i++){ bucketList.add(new ArrayList()); } while(true) { //判断是否排完 int dd = (int)Math.pow(10,(location - 1)); if(max < dd){ break; } //数据入桶 for(int i = 0; i < length; i++) { //计算余数 放入相应的桶 int number = ((arr[i] / dd) % 10); bucketList.get(number).add(arr[i]); } //写回数组 int nn = 0; for (int i=0;i<10;i++){ int size = bucketList.get(i).size(); for(int ii = 0;ii < size;ii ++){ arr[nn++] = bucketList.get(i).get(ii); } bucketList.get(i).clear(); } location++; }
} 其实它的思想很简单,不管你的数字有多大,按照一位一位的排,0 - 9 最多也就十个桶:先按权重小的位置排序,然后按权重大的位置排序。
当然,如果你有需求,也可以选择从高位往低位排。
总结
感谢你看到了这里,希望看完这篇文章能让你清晰的理解平时最常用的十大排序算法。
(*本文为 AI科技大本营转载文章,转载请联系原作者)
◆
精彩推荐
◆
想跟NVIDIA专业讲师学习TensorRT吗?扫码进群,获取报名地址,群内优秀提问者可获得限量奖品(定制T恤或者技术图书,包邮哦~)
NVIDIA TensorRT是一种高性能深度学习推理优化器和运行时加速库,可以为深度学习推理应用程序提供低延时和高吞吐量。通过TensorRT,开发者可以优化神经网络模型,以高精度校对低精度,最后将模型部署到超大规模数据中心、嵌入式平台或者汽车产品平台中。


推荐阅读
不让华为收专利费?美议员提案“秀下限”
解密Kernel:为什么适用任何机器学习算法?
Python助你叠猫猫,抢618大红包!
Python异常处理,3个好习惯分享给你
不是码农,不会敲代码的她,却最懂程序员!| 人物志
一张图告诉你到底学Python还是Java!
这位博士跑赢“地震波”:提前 10 秒预警宜宾地震!
10分钟读懂什么是容器云?
第二! 他排中本聪与V神中间, 单靠文字就“打败”了敲代码的程序员!
 你点的每个“在看”,我都认真当成了喜欢
你点的每个“在看”,我都认真当成了喜欢相关文章:

opencv使用cvFindContours提取联通域
转自:http://hi.baidu.com/irmosgarden/blog/item/8ce0174c54b307fad72afcbc.html // m_imgFeature为黑白目标图像,白色为前景,黑色为背景 // 注意此函数会修改m_imgFeature内容。若其不可更改,应另建立副本 // 1. count contou…

朱晔的互联网架构实践心得S1E9:架构评审一百问和设计文档五要素
朱晔的互联网架构实践心得S1E9:架构评审一百问和设计文档五要素 【下载文本PDF进行阅读】 本文我会来说说我认为架构评审中应该看的一些点,以及我写设计文档的一些心得。助你在架构评审中过五关斩六将,助你写出能让人收藏点赞的设计文档。 技…
Mail Archiving Expert电子邮件归档专家
概况作为企业往来最通用的交流工具,企业中有95%以上的文件都是通过邮件来传递与沟通,但是一旦当邮件服务罢工,影响的不仅仅是企业信息交流无法正确与及时的传达,更可能影响企业与客户之间的交易,其后果更是不堪设想&am…
C++中MessageBox的常见用法
转自:http://blog.csdn.net/qiumingbo/archive/2007/05/25/1625324.aspxMessageBox用法消息框是个很常用的控件,属性比较多,本文列出了它的一些常用方法,及指出了它的一些应用场合。1.MessageBox("这是一个最简单的消息框&am…

对标Mobileye!百度Apollo公布L4级自动驾驶纯视觉解决方案Apollo Lite
美国当地时间6月16日-20日,全球计算机视觉及模式识别领域顶级学术会议CVPR 2019(Conference on Computer Vision and Pattern Recognition)于美国长滩召开。百度Apollo在CVPR 2019公开了自动驾驶纯视觉城市道路闭环解决方案--百度Apollo Lite…
后台服务项目的白盒测试之旅
本文来自阿网易云社区作者:孙婷婷白盒测试起因17年下半年我开始介入部门新项目的服务v2版本的功能测试。刚接手项目时,感到十分头疼,首先它不像我刚接触测试时做的to C端项目,主要是页面展示操作,黑盒测试足够…

【自然框架 NatureFW】里的两种“映射”方式
自然框架里面采用了两种映射关系,一个是流行的ORM,另一是非主流的“CCM ” (我自己想的,呵呵)。 先说一下ORM。ORM是O和R的映射关系。也看到很多人写关于ORM的文章,发现好像有个误区。这个误区就是&#x…
ordfilt2函数功能说明
转自:http://www.ilovematlab.cn/thread-91331-1-1.html ordfilt2函数在MATLAB图像处理工具箱中提供了二维统计顺序滤波函数ordfilt2函数。二维统计顺序滤波是中值滤波的推广,对于给定的n个数值{al ,a2,...,an},将它们…

今晚直播写代码|英伟达工程师亲授如何加速YOLO目标检测
NVIDIA TensorRT是一种高性能深度学习推理优化器和运行时加速库,可以为深度学习推理应用程序提供低延时和高吞吐量。通过TensorRT,开发者可以优化神经网络模型,以高精度校对低精度,最后将模型部署到超大规模数据中心、嵌入式平台或…
TensorFlow Lite:TensorFlow在移动设备与嵌入式设备上的轻量级跨平台解决方案 | Google 开发者大会 2018...
Google 开发者大会 (Google Developer Days,简称 GDD) 是展示 Google 最新开发者产品和平台的全球盛会,旨在帮助你快速开发优质应用,发展和留住活跃用户群,充分利用各种工具获得更多收益。2018 Google 开发者大会于 9 月 20 日和 …
热烈庆祝“mysql 集群数据库架构成功”
坚持了两周,终于在linux下把mysql集群数据库给架起来了!下面简单说明下集群数据库原理 第一:集群数据库分MGM,NDBD,SQL 其中MGM是相当于“中央政府”,维持NDBD,SQL等服务器的之间的关系的 NDBD是数据存储的分布化&…

352万帧标注图片,1400个视频,亮风台推最大单目标跟踪数据集
CVPR 2019期间,专注于AR技术,整合软硬件的人工智能公司亮风台公开大规模单目标跟踪高质量数据集LaSOT,包含超过352万帧手工标注的图片和1400个视频,这也是目前为止最大的拥有密集标注的单目标跟踪数据集。论文《LaSOT: A High-qua…
centos7中nfs文件系统的使用
需求:file01:1.1.1.1(内网ip 172.20.103.212),file02:2.2.2.2(内网ip 172.20.103.211) 这两台机器的 /dev/mapper/myvg-mylv /data 这个盘都挂载到 video01 47.254.78.171, video02 47.254.83.81 这两台机器上即将file01和file02的/data目录都挂载到vid…
在图像变换中用最小二乘法求解仿射变换参数
设原图像为f(x,y),畸变后的图像为F(X,Y),要将F(X,Y)恢复为f(x,y),就是要找到(X,Y)坐标与(x,y)坐标的转换关系,这个转换关系称为坐标变换,表示为(x,y)T(X,Y)。 景物在成像过程中产生的扭曲,会使图像的比例失…
showModalDialog关闭子窗口,并刷新父窗口
一、用法:window.showModalDialog(url,args,dialogWidth650px;scrollno;dialogHeight250px;statusno; ); 二、关闭子窗口,并刷新父窗口 想在showModalDialog打开的窗口中提交表单且不打开新窗口 只需在打开的页面的<head>中加入<base target&qu…
cvDrawContours:在图像上绘制外部和内部轮廓
转自:http://www.aiseminar.cn/html/18/t-618.html?action-uchimage 函数cvDrawContours用于在图像上绘制外部和内部轮廓。当thickness > 0 时,绘制轮廓线;否则填充由轮廓包围的部分。 void cvDrawContours( CvArr *img, CvSeq* contour,…

Python最抢手、Go最有前途,7000位程序员揭秘2019软件开发现状
作者 | 屠敏 整理报告来源 | JetBrains转载自 CSDN(ID:CSDNnews)互联网的下半场,科技公司为面对更加严峻的竞争环境,越来越重视开源节流。而对于身处其中且撑起 IT 半边天的技术人,如今如何了?从…

main函数参数
参考:Where Does GCC Look to Find its Header Files? 命令行参数 VS 程序参数 ./a.out 1 2 3 4 5 6 1 2 3 4 5 6是程序参数,是传给a.out这个程序处理的,main里面的argv来接收 ./a.out 1 2 3 4 5 6完整的这一串才是命令行参数 代码演示 如下…

转载 load-on-startup的用法
转载于:http://www.ituring.com.cn/article/50477 Web.xml中的Servlet中的配置: <servlet><servlet-name>createBlog</servlet-name><servlet-class>com.cnblogs.CreateBlog</servlet-class><load-on-startup>0</load-on-s…

商汤62篇论文入选CVPR 2019,一览五大方向最新研究进展
(图源自视觉中国)作为与ICCV、ECCV并称为计算机视觉领域三大国际会议之一,本届CVPR大会共收到5265篇有效投稿,接收论文1300篇,接收率为25.2%。商汤科技CVPR 2019录取论文在多个领域实现突破作为国内CV领域的明星公司&a…
cvSaveImage保存图像
转自:http://blog.csdn.net/luhuillll/archive/2009/10/28/4739471.aspx opencv保存图象直接使用cvSaveImage,这个函数.但是windows位图的图象格式是RGBt格式,而opencv的图象存储格式是BGR. 这样导致保存的图象失真.在windows下查看图象好象变绿色了.所以在保存图象…
软工实践原型设计——PaperRepositories
软工实践原型设计——PaperRepositories 写在前面 本次作业链接队友(031602237吴杰婷)博客链接pdf文件地址原型设计地址(加载有点慢...)结对成员:031602237吴杰婷 & 031602636许舒玲原型设计工具:Axure RP 8PSP表格 PSP3.1Personal Software Process…
nagios+sendmail配置
以下为自己安装测试过的,如果有问题,大家一起讨论 系统环境:centos6.2 64位 最小化安装 一 安装nagios 见附件:nagios官方文档(nagios_nrpe20120929_web.pdf) 二 安装配置sendmail 我用hotmail邮箱接收nagi…

真正的博士是如何参加AAAI, ICML, ICLR等AI顶会的?
(图源自视觉中国)整理 | 一一出品 | AI科技大本营(ID:rgznai100)源于对学术的热爱,让很多人走上了博士这条求索之路,而热爱会让他们勤奋付出,勤奋让他们成为佼佼者。在刚刚过去的 ICML 大会上&a…
matlab图像滤波
转自:http://hi.baidu.com/wang%5Fpw/blog/item/36354a637ac87b48eaf8f879.html clc; clear all; Iimread(eight.tif); % %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% % %用中值滤波,多维滤波,使用中心为-4,-8的拉普 % %拉…

2018你不得不看的国内CRM软件排行榜
2018你不得不看的国内CRM软件排行榜短短几年时间,CRM在中国的发展就已经非常迅猛,现在已经成为了管理软件增长最快的产业。在我们总结的CRM软件排行榜中,腾讯企点的CRM软件赫然摆在前列。而CRM在中国中小企业已经突破千万家,占全国…
二维物体形状识别方法比较
二维物体形状识别方法比较 摘 要 针对模式识别中二维物体的形状识别问题,以二值图像中的物体形状为主要研究对象,依次从特征提取、分类器设计两个主要层面对形状识别方法进行了全面综述,并分析了国内外研究现状,特别是近年来所取…
个人知识管理的10个误区
100个人,有100个对个人知识管理的理解。 当我们热烈的讨论“个人知识管理”的时候,也许我们讨论的根本不是一个东西:你理解的个人知识管理和他理解的个人知识管理根本不同。 拙作《你的知识需要管理》试图去建立一个个人知识管理内容的框架&a…
关于比特币现金升级问题讨论不断升温
过去几周,比特币现金的支持者一直在讨论定于今年11月15日推出的硬叉。大多数人都明白,目前有两个阵营有着完全不同的愿景。看来双方在短期内不会达成妥协。最近,随着时间的推移,双方都在测试某些特性,并发表了关于特定…
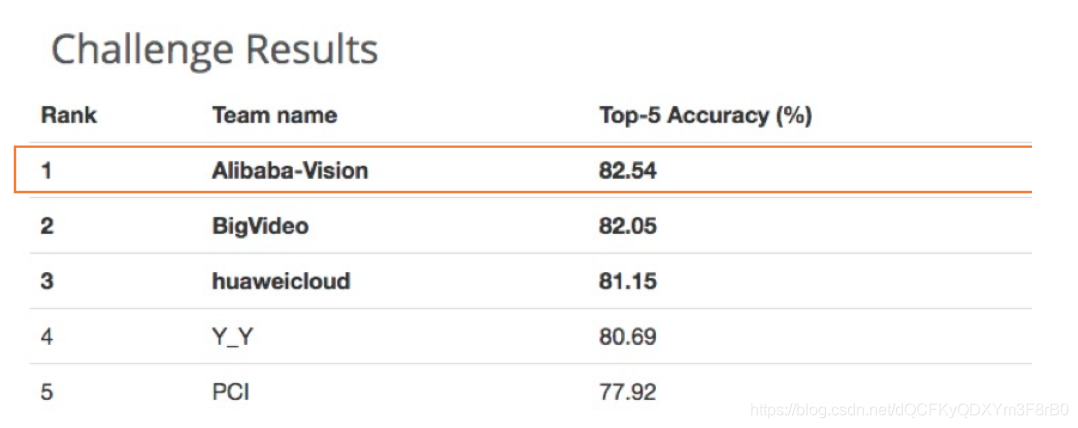
阿里AI摘图像识别竞赛WebVision桂冠,万物识别准确率创世界纪录
近日,第三届图像识别竞赛WebVision中,阿里AI击败了全世界150多支参赛队伍,获得冠军。 WebVision由谷歌、美国卡耐基梅隆大学、苏黎世联邦理工大学等机构联合全球视觉技术领域顶级学术会议CVPR发起,是目前图像识别领域最权威的竞赛…