新一届最强预训练模型上榜,出于BERT而胜于BERT

作者 | Facebook AI译者 | Lucy编辑 | Jane出品 | AI科技大本营(ID: rgznai100) 【导读】预训练方法设计有不同的训练目标,包括语言建模、机器翻译以及遮蔽语言建模等。最近发表的许多论文都使用了微调模型,并预先训练了一些遮蔽语言模型的变体。然而,还有一些较新的方法是通过对多任务微调提高性能,结合实体嵌入,跨度预测和自回归预训练的多种变体。它们通常在更大数据上训练更大的模型来提高性能。本文的目标是通过复制、简化和更好地微调训练BERT,以作为更好理解上述方法的相对性能的参考值。
 论文地址:https://arxiv.org/abs/1907.11692
论文地址:https://arxiv.org/abs/1907.11692语言模型预训练能获得显著的性能提升,但是不同方法之间很难进行详细的比较。训练模型计算成本高,通常在各自的数据集上完成,并且作者将展示超参数对最终结果的显著影响。作者提出了BERT 预训练的复制研究,该研究测量了关键超参数和训练数据量对结果的影响。发现BERT 可以超过其后发布的每个模型的性能。该模型在 GLUE,RACE 和SQuAD 上实现了目前最好的结果。这些结果强调了先前被忽视的设计选择的重要性,然后提出了有关最近报告的改进的来源的问题,并发布了模型和公开了程序代码。
1、 介绍
自训练方法,如ELMo、 GPT、 BERT、 XLM 和XLNet 得到了显著的性能提升,但很难确定每种方法的哪些方面贡献最大。训练计算成本很高,限制了微调的数据量,并且通常使用不同大小的私人训练数据来完成,这限制了测量模型效果的能力。 作者提出了BERT 预训练的复制研究,其中包括评估超参数和训练数据量对结果的影响。提出了一个改进的训练BERT模型的方法,称之为 RoBERTa,该方法可以超过所有 post-BERT 方法的性能。修改的部分包括:(1)训练模型时间更长,batch更大,数据更多;(2)删除下一句预测目标;(3)对较长序列进行训练;(4)动态改变应用于训练数据的遮蔽模式。为了更好地控制训练集大小对结果的影响,作者收集了与其他私人使用的数据集大小相当的大型新数据集(CC-NEWS)。 在控制训练数据时,改进的训练程序比在GLUE 和SQUAD 上公布的BERT 结果有所提高。经过长时间训练,该模型在公共GLUE 排行榜上得分为88.5,与 Yang 等人报道的88.4 相当。该模型建立了一个最新的4/9GLUE 任务:MNLI, QNLI, RTE 和STS-B。在 SQuAD 和RACE 上获得最好的实验结果。总的来说,重新确定BERT的遮蔽语言模型训练目标是与其他最近提出的训练目标竞争,例如扰动自回归语言模型。 总之,本文的贡献是:(1)提出了一套重要的 BERT 设计选择和培训策略,并介绍了可以带来更好的下游任务绩效的替代方案;(2)使用一种新的数据集 CCNEWS,确认使用更多数据进行预训练可以进一步提高下游任务的性能;(3)训练结果表明,在配置正确的情况下,预训练的遮蔽语言模型比其他最近发布的模型效果更好。作者发布了模型,上传了基于 PyTorch 的预训练和微调代码。2、 背景
2.1 设置
BERT 将两个段(令牌序列),x1,..., xN 和y1,..., yM 的串联作为输入。该模型首先在大的未标记文本语料库上预先训练,然后使用最终任务标记数据进行网络化。2.2 结构
本文使用具有L 层的变压器架构,每个块使用A 自注意头和H 层隐藏层.
2.3 训练目标
在预训练期间,BERT 的两个目标:遮蔽语言模型和下一句话预测。遮蔽语言模型(MLM)使用已标记的随机样本作为输入序列,并用特殊标记[MASK] 替换。MLM的目标是预测被遮蔽标记的交叉熵损失。下一句话预测(NSP) NSP 是一种二元分类损失,用于预测原始文本中两个段落是否相连。
2.4 优化
BERT使用以下参数对Adam 进行优化:β1= 0.9,β2= 0.999,ǫ= 1e-6,L2 权重衰减为0.01。 学习率在最初的10,000次迭代中峰值为1e-4,然后线性衰减。BERT 每层Dropout 为0.9,以及一个 GELU 激活函数。模型预训练在S = 1,000,000时更新,最小的batch 包含序列最大长度B = 256 和标记T = 512。
2.5 数据
BERT 的训练数据包含BOOKCORPUS 和英语WIKIPEDIA,压缩前共 16GB。
3、 实验设置
3.1 配置
作者在FAIRSEQ 中重新实现了BERT。主要遵循第2节中给出的初始 BERT 优化超参数,除了峰值学习速率和预热步数,这些步骤针对每个设置单独调整。Adam 在训练中非常敏感,在某些情况下,调整后能提高性能。并设置β2= 0.98 以提高大批量训练时的稳定性。作者预先训练了最多T = 512 标记序列。不会随机注入短序列,并且不会针对前90% 的更新以减少的序列长度进行训练,只训练全长序列。在 DGX-1 机器上进行混合精密浮点运算,每个机器都有8×32GB Nvidia V100 GPU,并由 Infiniband 互连。3.2 数据
BERT 式预训练依赖于大量的文本。本文考虑了不同大小和域的五种英语语料库,总共超过160GB 的未压缩文本。使用的文本语料库如下: BOOKCORPUS 和英语WIKIPEDIA:这是用于训练 BERT 的原始数据(16 GB)。
CC-NEWS:收集的 CommonCrawl 新闻数据集的英文部分。该数据包含2016 年9 月至2019 年2 月期间6300 万份英文新闻(过滤后为76GB)。
OPENWEBTEXT:Radford 等人的WebText 语料库的开源数据。该文本是从Reddit 上共享的URL 中提取的网页内容,爬取的每个内容都至少有三个人点赞(38GB)。
STORIES:是 Trinh 和Le 引入的数据集,其中包含一部分CommonCrawl 数据,用于匹配Winograd 模式的故事风格(31GB)。
3.3 评估
作者使用以下三个基准评估下游任务的预训练模型。 GLUE 通用语言理解评估(GLUE)基准是用于评估自然语言理解系统的 9 个数据集的集合。
SQuAD 斯坦福问题答疑数据集(SQuAD)提供了一段背景和一个问题。任务是通过从上下文中提取相关跨度来回答问题。
RACE 考试的重新理解(RACE)任务是一个大型阅读理解数据集,有超过 28000 个段落和近100000 个问题。该数据集来自中国的英语考试,专为中学生和高中生设计。
4、 训练程序分析
本节探讨在保持模型架构不变的情况下,哪些量化指标对预训练BERT 模型有影响。首先训练BERT 模型,其配置与BERTBASE 相同(L = 12, H = 768, A = 12,110M 参数)。4.1 静态与动态掩蔽
可以发现使用静态遮蔽重新实现的功能与原始BERT模型类似,动态遮蔽与静态遮蔽效果差距不大。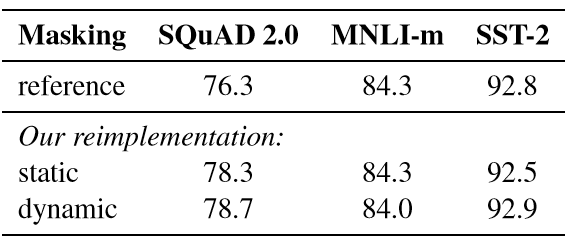 表1:BERTBASE 的静态遮蔽和动态遮蔽之间的比较。
表1:BERTBASE 的静态遮蔽和动态遮蔽之间的比较。 4.2 模型输入格式和下一句预测
本文比较了几种可选择训练模式:
SEGMENT-PAIR+NSP:BERT 中使用带NSP 损失的原始输入格式。每个输入都有两个段落,每个段可以包含多句话,但总组合长度必须小于512 个tokens。
SENTENCE-PAIR+NSP:每个输入包含两句话,从一个文档的连续部分或从单独的文档中采样。由于这些输入明显少于512 个tokens,因此我们增加batch的大小,以使 tokens 总数保持与SEGMENT-PAIR + NSP 相似,同时保留了NSP 损失。
FULL-SENTENCES:每个输入都包含从一个或多个文档连续采样的完整句子,使得总长度最多为512 个tokens。输入可能跨越文档边界。当到达一个文档的末尾时,从下一个文档开始对句子进行抽样,并在文档之间添加一个额外的分隔符号,这里不使用 NSP 损失。
DOC-SENTENCES:输入的构造类似于FULL-SENTENCES,除了它们可能不需要跨越文档边界。在文档末尾附近采样的输入可以短于 512 个tokens,因此在这些情况下动态增加batch大小以达到与 FULLSENTENCES 相同的tokens总数,这里不使用 NSP 损失。
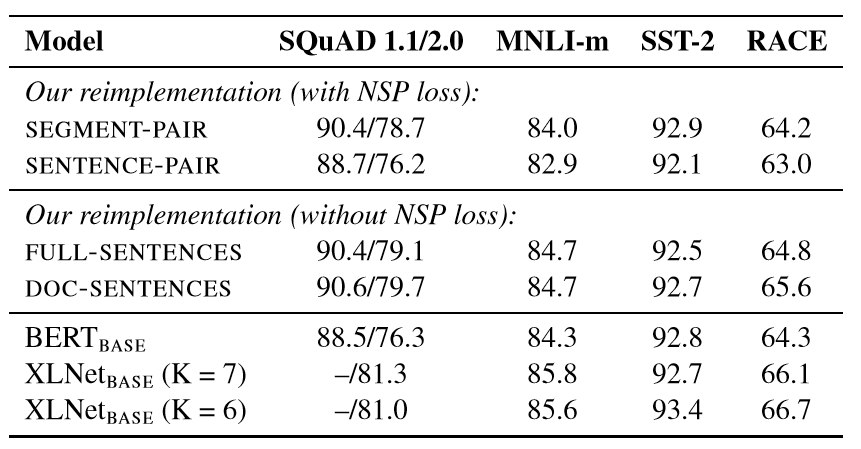 表2:在 BOOKCORPUS 和WIKIPEDIA 上预训练的基础模型的开发集结果。 首先比较Devlin等人的原始SEGMENT-PAIR输入格式。采用SENTENCE-PAIR格式;两种格式都保留了NSP损失,但后者使用单句。发现单个句子会损害下游任务的性能,认为这是因为模型无法学习远程依赖。
表2:在 BOOKCORPUS 和WIKIPEDIA 上预训练的基础模型的开发集结果。 首先比较Devlin等人的原始SEGMENT-PAIR输入格式。采用SENTENCE-PAIR格式;两种格式都保留了NSP损失,但后者使用单句。发现单个句子会损害下游任务的性能,认为这是因为模型无法学习远程依赖。4.3 大批量训练
在神经网络机器翻译模型中,当学习率适当增加时,使用非常大的mini-batch 训练可以提高优化速度和终端任务性能。研究结果表明,BERT 也适用于大批量训练。 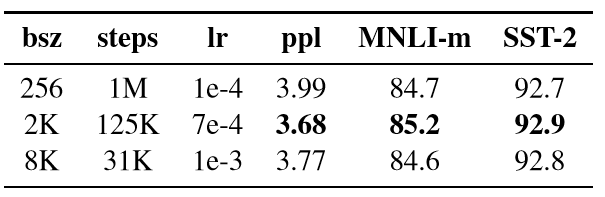 表3:在不同 batchs(bsz)下, BOOKCORPUS 和WIKIPEDIA 作为训练数据,模型的持续训练数据(ppl)和开发集准确率。 比较了BERTBASE 的性能,因为增加了batch 的大小,控制了通过训练数据的次数。观察到大批量训练可以改善遮蔽语言模型目标的困惑度,以及最终任务的准确性。通过分布式数据并行训练,大批量也更容易并行化,后续的实验中,作者使用8K 序列进行训练。
表3:在不同 batchs(bsz)下, BOOKCORPUS 和WIKIPEDIA 作为训练数据,模型的持续训练数据(ppl)和开发集准确率。 比较了BERTBASE 的性能,因为增加了batch 的大小,控制了通过训练数据的次数。观察到大批量训练可以改善遮蔽语言模型目标的困惑度,以及最终任务的准确性。通过分布式数据并行训练,大批量也更容易并行化,后续的实验中,作者使用8K 序列进行训练。4.4 文本编码
字节对编码(BPE)是字符和单词级表示之间的混合,允许处理自然语言语料库中常见的大词汇表。BPE 不依赖于完整的单词,而是依赖于子词单元,这些子单元是通过对训练语料库进行统计分析而提取的。5、RoBERTa
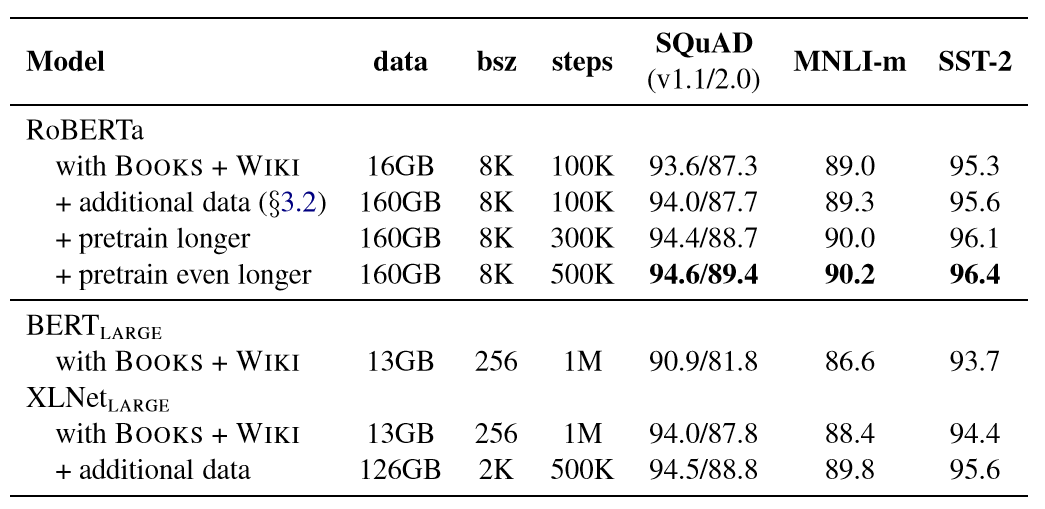 表4:RoBERTa的开发集结果,因为预先训练了更多数据(16GB→160GB的文本)和预训练更长时间(100K→300K→500K步),每行累积上述行的改进。RoBERTa 符合BERTLARGE 的架构和训练目标。 当控制训练数据时,观察到RoBERTa 比最初报告的BERTLARGE 结果有了明显的改进。
表4:RoBERTa的开发集结果,因为预先训练了更多数据(16GB→160GB的文本)和预训练更长时间(100K→300K→500K步),每行累积上述行的改进。RoBERTa 符合BERTLARGE 的架构和训练目标。 当控制训练数据时,观察到RoBERTa 比最初报告的BERTLARGE 结果有了明显的改进。 5.1 GLUE结果
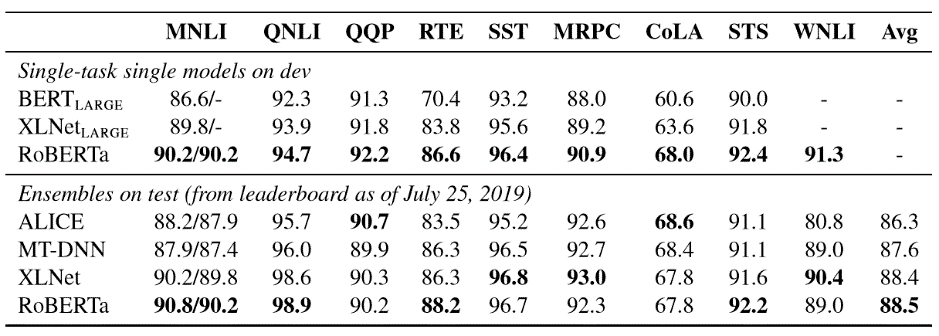
5.2 SQuAD结果
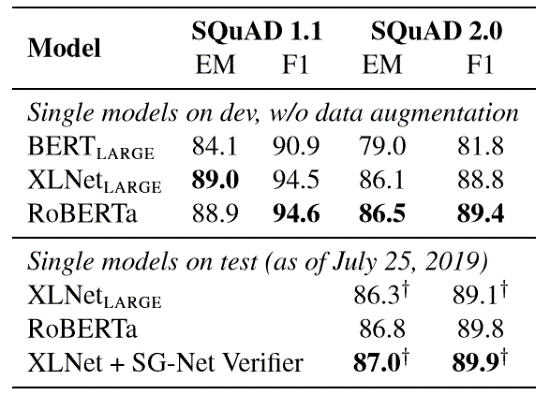 表6 :SQuAD 的结果。†表示取决于其他外部训练数据的结果。RoBERTa 仅在开发和测试设置中使用提供的SQuAD 数据。
表6 :SQuAD 的结果。†表示取决于其他外部训练数据的结果。RoBERTa 仅在开发和测试设置中使用提供的SQuAD 数据。 5.3 RACE结果
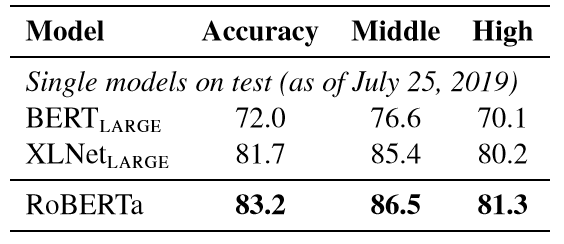 表7 :RACE 测试集的结果 RoBERT在中学和高中设置上都能获得最好的实验结果。
表7 :RACE 测试集的结果 RoBERT在中学和高中设置上都能获得最好的实验结果。
6、结论
在预训练BERT模型时,作者会仔细评估一些设计决策。通过更长时间地训练模型,处理更多数据,可以显著提高模型性能;删除下一句预测目标; 培训更长的序列; 并动态地改变应用于训练数据的遮蔽模式。改进的预训练程序,称之为RoBERTa,在GLUE,RACE和SQuAD上实现了目前最好的结果,没有GLUE的多任务网络化或SQuAD的附加数据。这些结果说明这些先前被忽视的设计决策的重要性,并表明BERT的预训练目标仍与最近提出的替代方案不相上下。 作者还使用了一个新的数据集CC-NEWS,并发布了用于预训练和网络训练的模型和代码。Github地址:https://github.com/pytorch/fairseq
(*本文为 AI科技大本营编译文章,转载请联系微信 1092722531)
社群福利
扫码添加小助手,回复:大会,加入2019 AI开发者大会福利群,每周一、三、五更新技术福利,还有不定期的抽奖活动~

◆
精彩推荐
◆
60+技术大咖与你相约 2019 AI ProCon!大会早鸟票已售罄,优惠票速抢进行中......2019 AI开发者大会将于9月6日-7日在北京举行,这一届AI开发者大会有哪些亮点?一线公司的大牛们都在关注什么?AI行业的风向是什么?2019 AI开发者大会,倾听大牛分享,聚焦技术实践,和万千开发者共成长。
推荐阅读
认知智能的突围:NLP、知识图谱是AI下一个“掘金地”?
自动驾驶激荡风云录:来自圈内人的冷眼解读
华人“霸榜”ACL最佳长短论文、杰出论文一作,华为、南理工等获奖
5G+AI重新定义生老病死
干货 | 20个Python教程,掌握时间序列的特征分析(附代码)
2019 年度程序员吸金榜:你排第几?
字节跳动入局全网搜索;思科回应中国区裁员;IntelliJ IDEA 新版发布! | 极客头条
AI+DevOps正当时
知名饮料制造商股价暴涨500%惊动FBI,只因在名字中加入了"区块链" ?
 你点的每个“在看”,我都认真当成了喜欢
你点的每个“在看”,我都认真当成了喜欢相关文章:

Ubuntu 32下Android NDK+NEON的配置过程及简单使用举例
1、 利用VMware在Windows7 64位下安装Ubuntu13.10 32位虚拟机; 2、 从 https://developer.android.com/tools/sdk/ndk/index.html下载android-ndk32-r10-linux-x86.tar.bz2; 3、 将android-ndk32-r10-linux-x86.tar.bz2拷贝到Ubuntu的/home/spring/NE…
Neon Intrinsics各函数介绍
#ifndef __ARM_NEON__ #error You must enable NEON instructions (e.g. -mfloat-abisoftfp -mfpuneon) to use arm_neon.h #endif/*(1)、正常指令:生成大小相同且类型通常与操作数向量相同的结果向量; (2)、长指令:对双字向量操作数执行运算…
ubuntu bind9 配置简单记录
ubuntu bind9 配置简单记录ubuntu版本:Ubuntu 12.04.2bind9安装:apt-get install bind9bind9配置文件目录:/etc/bindbind9主要配置文件:named.conf.local以及对应db配置1,主服务器配置:rootubuntu:/etc/bin…
不止最佳长论文,腾讯AI在ACL上还有这些NLP成果
编辑 | Jane出品 | AI科技大本营(ID:rgznai100)【导语】7 月 31 日晚,自然语言处理领域最大顶会 ACL 2019 公布了今年的八个论文奖项,其中最佳长论文的获奖者被来自中国科学院大学、中国科学院计算技术研究所、腾讯 We…
python中package机制的两种实现方式(转载)
当执行import module时,解释器会根据下面的搜索路径,搜索module1.py文件。 1) 当前工作目录 2) PYTHONPATH中的目录 3) Python安装目录 (/usr/local/lib/python) 事实上,模块搜索是在保存在sys.path这个全局变量中的目录列表中进行搜索。 sys…

Magento如何使用和设置CookieSession
2019独角兽企业重金招聘Python工程师标准>>> 给大家介绍两个Magento的核心对象-Mage_Core_Model_Cookie & Mage_Core_Model_Session 首先介绍Mage_Core_Model_Cookie,这个对象主要是用来设置Cookie的,里面主要下列方法&#x…

AI+DevOps正当时
随着业务复杂化和人员的增加,开发人员和运维人员逐渐演化成两个独立的部门,他们工作地点分离,工具链不同,业务目标也有差异,这使得他们之间出现一条鸿沟。而发布软件就是将一个软件想从鸿沟的这边送去那边,…
clientdataset 用法
影响ClientDataSet处理速度的一个因素TClientDataSet是Delphi开发数据库时一个非常好的控件。有很强大的功能。我常常用ClientDataSet做MemoryDataSet来使用。还可以将ClientDataSet的数据保存为XML,这样就可以做简单的本地数据库使用。还有很多功能就不多说了。在使…
用vs2010编译vigra静态库及简单使用举例
1、 从 http://ukoethe.github.io/vigra/ 下载最新源代码vigra-1.10.0-src-with-docu.tar.gz,并加压缩到D:\soft\vigra,生成vigra-1.10.0文件夹; 2、 从http://www.cmake.org/cmake/resources/software.html下载CMake并安装; …
39个超实用jQuery实例应用特效
2019独角兽企业重金招聘Python工程师标准>>> 1.Contextual Slideout:上下文滑动特效 2.Revealing Photo Slider:图片幻灯片特效 3.Fancy Box:魔幻盒 4.Scrollable:滚动特效 5.Flip:翻转特效,实现4个方向…
Android.mk和Application.mk文件语法规范说明及举例
以下英文内容摘自:http://www.kandroid.org/ndk/docs/OVERVIEW.html The Android NDK is a set of tools that allows Android application developers to embed native machine code compiled from C and/or C source files into their application packages.NDK d…
ASP.NET Web API实践系列06, 在ASP.NET MVC 4 基础上增加使用ASP.NET WEB API
本篇尝试在现有的ASP.NET MVC 4 项目上增加使用ASP.NET Web API。 新建项目,选择"ASP.NET MVC 4 Web应用程序"。 选择"基本"项目模版。 在Controllers文件夹下添加一个名称为"TestController"的空API控制器。 在引用文件夹中多了以下…

滴滴自动驾驶部门成立独立公司,CTO张博兼任新公司CEO
整理 | 夕颜出品 | AI科技大本营(ID:rgznai100)导读:8 月 5 日,滴滴出行官方微信公众号发文,宣布旗下自动驾驶部门升级为独立公司。目前,新成立公司的名称还未曝光,但据官方介绍将专注于自动驾驶…

在ASP.NET MVC下实现树形导航菜单
在需要处理很多分类以及导航的时候,树形导航菜单就比较适合。例如在汽车之家上: 页面主要分两部分,左边是导航菜单,右边显示对应的内容。现在,我们就在ASP.NET MVC 4 下临摹一个,如下: 实现的效…
mongodb学习笔记6--杂项与补充
2019独角兽企业重金招聘Python工程师标准>>> 1。适用场景:持久化缓存层,高效的时效性,用于对象和Json数据的存储,高伸缩性的场景,大尺寸,低价值的数据存储。 不适用:高度事务性的场景…
GraphSAGE:我寻思GCN也没我厉害!
作者 | 郭必扬来源 | SimpleAI(ID:SimpleAI_1)众所周知,2017年ICLR出产的GCN现在是多么地热门,仿佛自己就是图神经网络的名片。然而,在GCN的风头中,很多人忽略了GCN本身的巨大局限——Transductive Learnin…
CxImage的编译及简单使用举例
1、 从http://sourceforge.net/projects/cximage/下载最新的CxImage 702源码; 2、 解压缩后,以管理员身份打开CxImageFull_vc10.sln工程,在编译之前先将每个工程属性的Character Set由原先的Use Unicode Character Set改为Use Multi-ByteC…
如何使用好android的可访问性服务(Accessibility Services)
原文:http://android.eoe.cn/topic/android_sdk * 主题* Manifest声明和权限 可访问性服务声明 可访问性服务配置 AccessibilityService方法 获得事件细节 示例代码 主要的类*AccessibilityService AccessibilityServiceInfo AccessibilityEvent AccessibilityReco…
自动驾驶人的福音!Lyft公开Level 5部署平台Flexo细节
作者 | Mathias Gug等,Lyft Level 5 软件工程师译者 | Lucy编辑 | 夕颜出品 | AI科技大本营(ID:rgznai100)导读:经过一年半的 bootstrapping(一种再抽样统计方法),Lyft 让 Level 5 实现区分非常…
Cygwin的安装及在Android jni中的简单使用举例
Cygwin是一个在windows平台上运行的类UNIX模拟环境,是cygnussolutions公司开发的自由软件。Cygwin是许多自由软件的集合,Cygwin的主要目的是通过重新编译,将POSIX系统上的软件移植到Windows上。Cygwin包括了一套库,该库在win32系统…
university, school, college, department, institute的区别
这些个词没有太大区别,有时候有些词是可以通用的,而有些用法则是随着地域时间的不同而变迁。一般说来,college译作“学院”,它是university (综合性大学)的一个组成部分,例如,一所综…
XML简介及举例
可扩展标记语言(eXtensibleMarkup Language,简称XML),是一种标记语言。标记指计算机所能理解的信息符号,通过此种标记,计算机之间可以处理包含各种信息的文章等。如何定义这些标记,既可以选择国际通用的标记语言&#…
关于事务的传播特性和隔离级别的问题
REQUIRED:业务方法需要在一个事务中运行。如果方法运行时,已经处在一个事务中,那么加入到该事务,否则为自己创建一个新的事务。 NOT_SUPPORTED:声明方法不需要事务。如果方法没有关联到一个事务,容器不会为…

[Big Data - Kafka] kafka学习笔记:知识点整理
一、为什么需要消息系统 1.解耦: 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。 2.冗余:消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。许多消息队列所采用的&q…

自然语言处理十问!独家福利
最近,NLP 圈简直不要太热闹!预训练模型频频刷新榜单,让一众研究者、开发者“痛并快乐着”。自 2018 年 10 月,Google 提出 BERT 以来,NLP 领域预训练模型的发展仿佛坐上了火箭,完全控制不住。BERT 出世前&a…
BERT的成功是否依赖于虚假相关的统计线索?
作者 | 李理来源 | 个人博客导读:本文介绍论文Probing Neural Network Comprehension of Natural Language Arguments,讨论BERT在ACRT任务下的成绩是否依赖虚假的统计线索,同时分享一些个人对目前机器学习尤其是自然语言理解的看法。目录论文…
【电子基础】模拟电路问答
模拟电路基础知识问答整理 mystery 1、温度对半导体材料的导电性能有什么影响? 答:温度对半导体的导电性能有很大影响。当温度升高时,半导体材料内的自由电子和空穴数量迅速增加,半导体的导电性能将迅速提高。 2、什么是本征半导体和杂质半导…
XML解析简介及Xerces-C++简单使用举例
XML是由World WideWeb联盟(W3C)定义的元语言。它已经成为一种通用的数据交换格式,它的平台无关性,语言无关性,系统无关性,给数据集成与交互带来了极大的方便。XML在不同的语言里解析方式都是一样的,只不过实现的语法不…

[干货]Kaggle热门 | 用一个框架解决所有机器学习难题
新智元推荐 来源:LinkedIn 作者:Abhishek Thakur 译者:弗格森 【新智元导读】本文是数据科学家Abhishek Thakur发表的Kaggle热门文章。作者总结了自己参加100多场机器学习竞赛的经验,主要从模型框架方面阐述了机器学习过程中可能会…
gtest简介及简单使用
gtest是一个跨平台(Liunx、Mac OS X、Windows、Cygwin、Windows CE and Symbian)的C测试框架,有google公司发布。gtest测试框架是在不同平台上为编写C测试而生成的。从http://code.google.com/p/googletest/downloads/detail?namegtest-1.7.0.zip&can2&q下…