面向可解释的NLP:北大、哈工大等提出文本分类的生成性解释框架

作者 | Hui Liu, Qingyu Yin, William Yang Wang
译者 | Rachel
编辑 | Jane
出品 | AI科技大本营(ID: rgznai100)
【导语】北大、哈工大和加州大学圣巴巴拉分校在 ACL 2019 的一篇论文中联合提出了一个全新的生成性解释框架,该框架能够对分类策略进行学习,并同时提供细粒度的解释。这项研究还提供了解释因子以及最小化风险训练(minimum risk training)方法,以便进行学习并产生更加合理的解释。
模型的可解释问题是学界现在一直在讨论和研究的工作之一,在自然语言处理领域亦是,想搭建一个具有可解释性的系统是一件非常困难的事。目前,现有的研究尝试让模型具有可解释时,也对模型输出或输出与输入间的联系进行解释。但是这种方式忽略了很多细粒度信息(例如标签的文本解释),而且系统也无法产生人类可以阅读的解释。
为了解决这一问题,北大、哈工大和加州大学圣巴巴拉分校在 ACL 2019 的一项工作中联合提出了一个全新的生成性解释框架,该框架能够对分类策略进行学习,并同时提供细粒度的解释。另外,本文提供了解释因子以及最小化风险训练(minimum risk training)方法,这个方法能够进行学习并产生更加合理的解释。本文构建了两个新的训练集,作者在两个数据集上进行了实验,并将框架和一些基线神经网络进行了对比。实验结果显示,本文提出的框架性能在两个数据集上都超越了基线模型,且能够生成简练的解释。

论文链接:
https://arxiv.org/abs/1811.00196
1、介绍
深度学习方法在很多 NLP 任务中都得到了非常好的结果。但由于这些模型对人们而言都是黑箱,其很难让人们完全信任其预测结果。例如,如果一个论文评分系统仅给出评分而不提供明确的理由,用户将很难信任系统的判断。因此,对于 NLP 系统而言,系统的可解释性至关重要,这要求传统的 NLP 模型提供人类可读的解释。
近几年,很多工作都在文本分类中取得了新的进展,但少有对系统的解释能力进行讨论的研究。有学者尝试通过可解释的表示来搭建模型,但该方法仅适用于特定的分类器,无法推广。还有学者尝试使用热图来可视化隐藏元素对预测结果的影响。这些方法具有一定的合理性,但都没有使用可用于解释模型行为的细粒度信息。但对于人类而言,当其对一个产品进行打分时,他/她可能会首先写下一些评价,然后对产品的一些组成部分(如价格、包装、质量等)进行总结或打分,最后基于上述细粒度信息对整个产品进行打分。因此,对于可解释的文本分类模型而言,产生用于对预测结果进行解释的简练的细粒度信息至关重要。
为实现这一目标,本文提出了一个全新的文本分类生成性解释框架,该框架能够在进行分类预测的同时产生预测结果解释的细粒度信息。该框架为生成-判别混合模型,其原理为,基于原文本推测细粒度信息并进行精简,并使用该信息辅助预测分类结果的解释,提升整体模型表现。另外,作者提出了解释因子以及一个最小化风险训练方法,该方法能够生成整个预测结果的合理解释。同时,由于该方法提供了解释和预测间的联系,还能反过来提升模型分类效果。本文是第一个使用抽象的生成的细粒度信息来解释预测结果的模型。
在本文中,作者将文本概要(内容为文本)和打分(内容为数字)称为细粒度信息。作者构建了两个包含这两类信息的数据集用于模型的评测,均从网络爬取获得。第一个数据集为 PCMag,数据集中的每个实例包含三部分:一段关于产品的长评价文本,三段简短的文本评论(从积极、消极和中立角度解释产品的属性),一个整体打分。作者将三段短文本看作长评论文本的细粒度信息。第二个数据集为 Skytrax 用户评论数据集,每个实例包括三部分:一段对于航班的评价,五个关于航班不同方面的打分(座椅舒适度,机舱人员,食物,机舱内环境,机票价值),一个总体评分。对于这一数据集,作者将五个子得分看作飞机评论文本的细粒度信息。
在实验中,作者在两个数据集上对比了本文的框架和一些已有的基线神经网络模型。实验结果显示,本文方法相比于基线模型显著提升了文本分类效果,展示了使用细粒度信息的优势。另外,模型也提供了可令人信服的结果解释。本文的贡献主要有三方面:
首次使用生成的细粒度信息构建文本分类的生成性解释框架,提出了一个解释因子,并介绍了用于该生成-判别混合模型的最小化风险训练方法;
在两个数据集上对比了本文框架和不同的神经网络架构的效果,发现本文方法带来显著提升;
构建了两个新的公开可获取的解释性 NLP 数据集,其中包括可用于文本分类结果解释的细粒度信息。
2、任务定义及符号
本文的研究任务为生成文本分类模型结果的细粒度解释。作者首先讨论了好的细粒度解释的标准。在情感分类中,假设产品 A 包含三个属性:质量、可用性、价格。每一个属性可描述为“高”或“低”。在讨论产品 A 是一个“好”产品还是“坏”产品时,如果模型判断 A 是一个好产品,且指出 A 的质量高、可用性高、价格低,则可认为这些属性值较好地解释了模型的预测结果。反之,如果模型提供的属性值相同但预测 A 是一个坏产品,则认为模型给出的解释较差。因此对于一个文本分类预测结果,需要了解更多细粒度信息以对结果进行解释。另外,作者还希望讨论这些解释是否能够帮助提升分类效果。
本文中,输入文本序列表示为 S{s1, s2, ..., s|s|},预测得到的文本 S 所属类别表示为 yi(i属于[1, 2, ..., N]),对预测结果 yi 的解释表示为 ec 。
3、生成性解释框架
本部分介绍了本文提出的生成性解释框架(Generative Explanation Framework, GEF),图1展示了框架的结构。
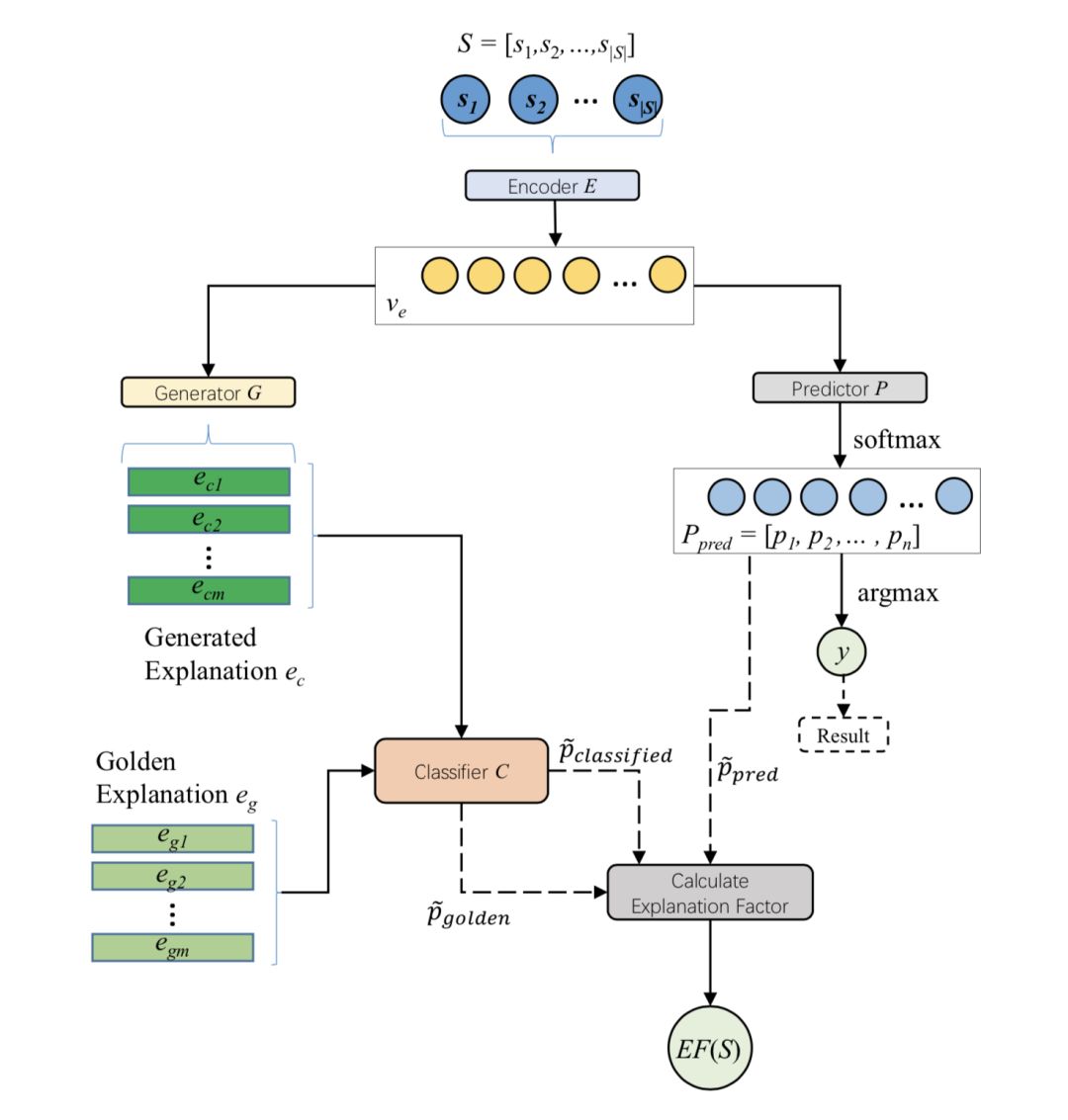
图1:GEF 的结构。E 将 S 编码为向量表示 ve 。P 为各个类别提供分布概率 Ppred ,并从 Ppred 中提取真值概率。生成器 G 将ve 作为输入,并生成解释 ec 。分类器 C 和预测器 P 共同预测类别 y 。将 ec 输入 C 时,C 对分布概率 Pclassified 进行预测,之后输出两个真值概率,并用于计算解释因子 EF(S) 。
3.1 基础性分类器和生成器
在文本分类任务中,普遍做法为使用编码器-预测器结构。如图1,编码器 E 接收文本序列 S 作为输入,并将其转换为表示向量 ve 。之后,类别预测器 P 接收 ve 作为输入,并输出预测类别 yi 机器关联概率分布 Ppred 。
一个理想的模型应同时提供预测结果及其解释。一个简单的生成解释的方法即将 ve 输入到一个解释生成器 G ,以生成细粒度解释 ec ,公式如下:

其中,模型使用 softmax 函数将分布概率转换为分类。
在训练过程中,整体损失函数 L 包括两部分:分类损失 Lp 和解释生成损失 Le ,公式如下:
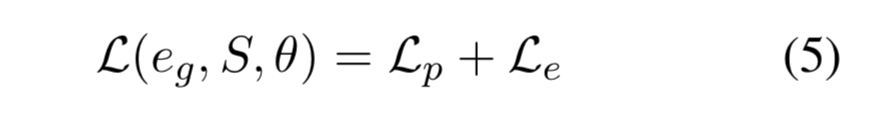
其中,θ 代表所有参数。
3.2 解释因子
上文提到的方法存在一个明显的缺陷:该方法无法在生成的解释和预测之间建立合理解释,即解释和预测结果相互独立。为了生成更加合理的结果解释,作者提出使用一个解释因子来建立结果和解释间的联系。
一些情况下,细粒度信息比输入的原始文本序列更能反映整体结果。因此,作者预训练了一个分类器 C ,该分类器直接将解释作为输入,并学习预测分类 y 。也就是说, C的目标为模仿人类行为,比使用原始文本作为输入的模型更佳准确地预测结果。作者在实验部分证明了这一假设。
作者使用这一预训练分类器 C 为文本编码器 E 提供指导,使其能够生成一个含有更多信息量的向量表示 ve 。在训练过程中,作者首先使用解释生成器 G 得到生成性解释 ec ,之后将 ec 输入到分类器 C 中,得到预测结果 Pclassified 的概率分布。同时,作者将人们可接受的文本解释 eg 输入到分类器中,得到可接受的解释(golden explanation)的概率分布 Pgold ,公式如下:

为了衡量预测结果、生成的解释和可接受解释的生成结果之间的距离,作者从 Pclassified, Ppred, Pgold 中分别抽取了真值(ground-truth),用于衡量最小化风险训练中预测结果和真值结果的差异。
作者将解释因子 EF(S) 定义如下:
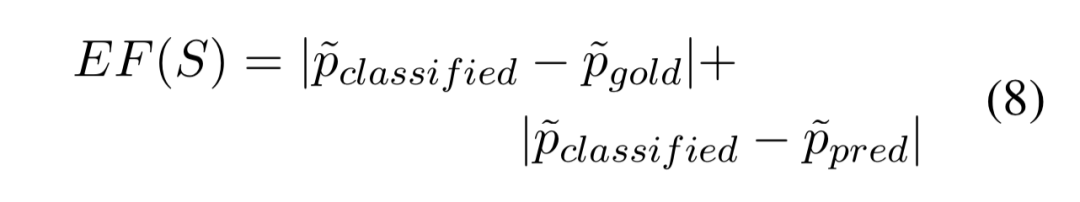
该公式包含两部分:
第一部分
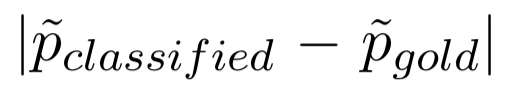 表示生成的解释 ec 和可接受的解释 eg 之间的距离。作者认为,由于使用了可接受的解释对 C 进行了预训练,当 C 接收了相似的解释时,其应当产生相似的预测结果。在该任务中,作者希望 ec 可以表达与 eg 相同或相似的含义。
表示生成的解释 ec 和可接受的解释 eg 之间的距离。作者认为,由于使用了可接受的解释对 C 进行了预训练,当 C 接收了相似的解释时,其应当产生相似的预测结果。在该任务中,作者希望 ec 可以表达与 eg 相同或相似的含义。第二部分
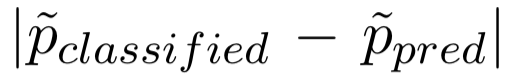 表示生成解释 ec 和原始文本 S 之间的相关性。生成的解释应当和原始文本的预测结果保持一致。
表示生成解释 ec 和原始文本 S 之间的相关性。生成的解释应当和原始文本的预测结果保持一致。
3.3 最小化风险训练
作者使用最小化风险训练(Minimum risk training, MRT )对模型进行优化,以最小化期望损失。对于一个给定的序列 S 和一个可接受的解释 eg , 作者使用 γ(eg, S, θ) 表示参数 θ 的整体预测结果集合, ![]() 表示整体预测结果和真值之间的语义距离。因此目标函数可表示如下:
表示整体预测结果和真值之间的语义距离。因此目标函数可表示如下:
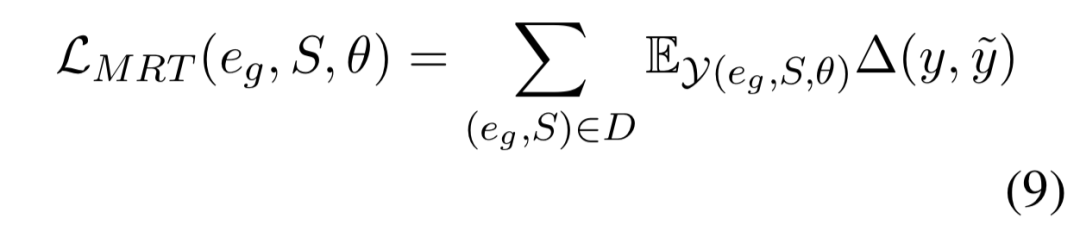
其中 D 表示整个训练集。
在本文的实验中,E(eg, S, θ) 是集合 γ(eg, S, θ) 上的期望,即公式(5)中的整体损失。作者将解释因子 EF(S) 定义为输入文本、生成解释和可接受解释之间的语义距离,因此, MRT 的目标函数可表示为如下公式:
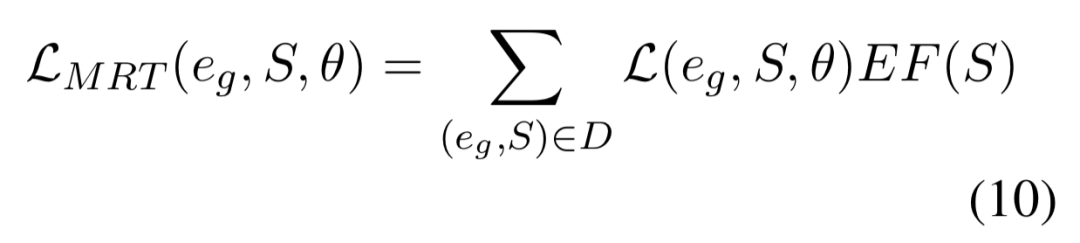
MRT 使用 EF(S) 衡量损失,以使用特定的评估指标对 GEF 进行优化。尽管当输入文本、生成解释和可接受解释的真值非常接近时, LMRT 可取0或接近0,仍然不能保证生成的解释接近可接受解释。为了避免损失的性能退化,作者将最终的损失函数定义为 MRT 损失和解释生成损失的加和,即:
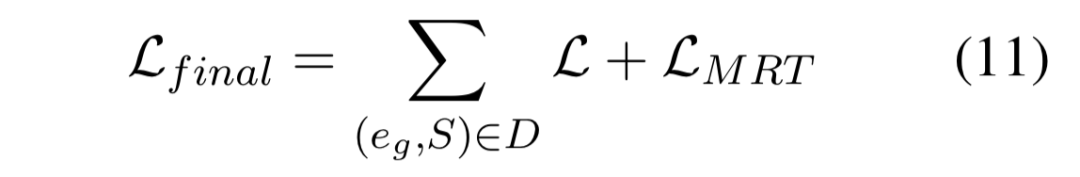
经实验,作者将两损失的权重比例设定为1:1。
3.4 应用实例
由于真实世界的细粒度信息的形式包括文本和数字两种形式,作者在不同形式的细粒度信息上对对 GEF 和 基线模型进行了实验。
实例1:文本解释
为检验 GEF 在生成文本解释上的效果,作者在条件式变分自编码器(Conditional Variational Autoencoder, CVAE)上应用了GEF ,目的为生成具有不同情感倾向(积极、消极和中立)的解释。选择 CVAE 的原因为,其能够生成带情感的文本,且相较于传统 SEQ2SEQ 模型能够捕捉更大的多样性。
图2展示了一个 CVAE + GEF 的结构示例。为节省空间,图中省略了 CVAE 的具体结构,并在补充材料中进行了说明。在该结构中,可接受的解释 eg 和生成解释 ec据包括积极、消极和中立三类评论。分类器为使用双向 GRU-RNN 结构的残差模型。模型的输入为三类评论,输出为预测分类的概率分布。
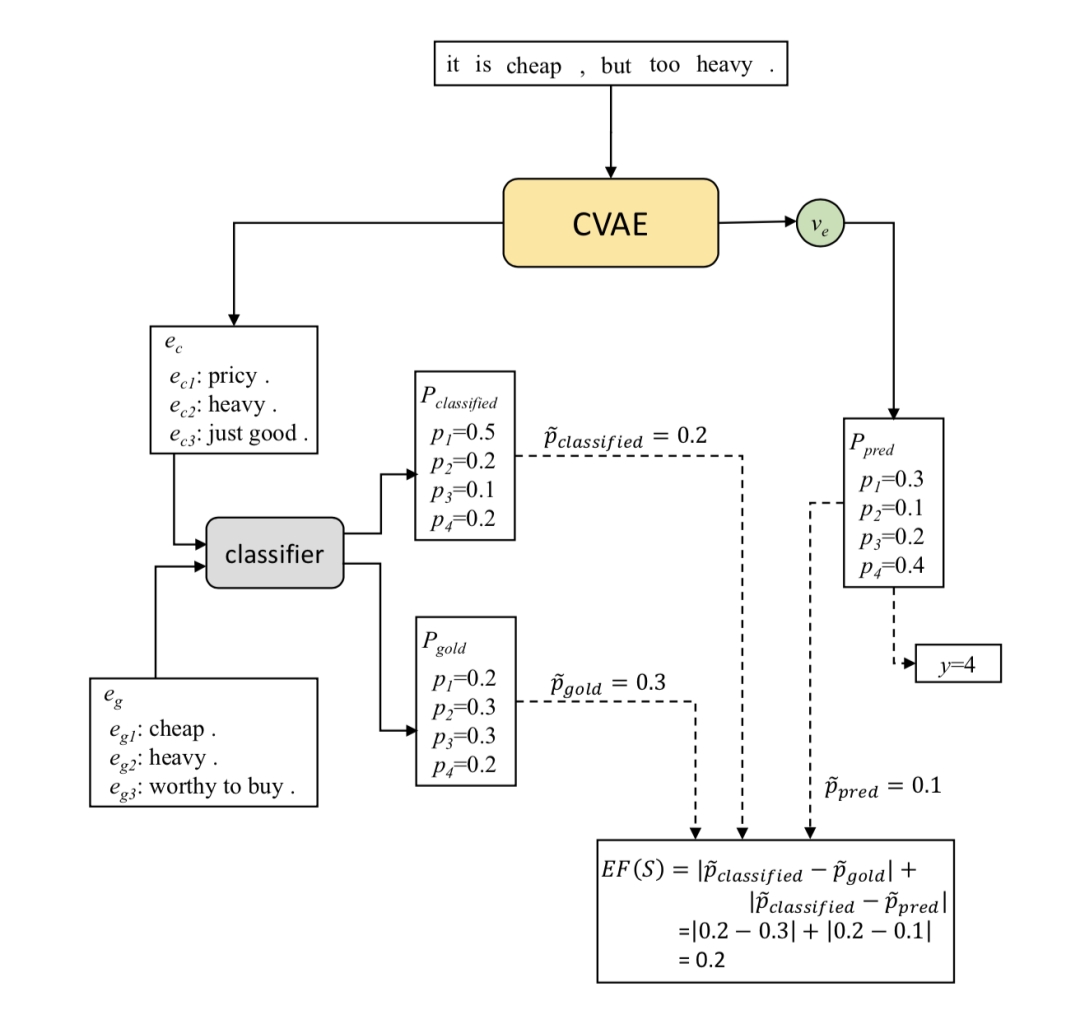
图2:CVAE+GEF 的结构。分类结果共有4类,本示例中的分类真值为2。作者假设预训练的分类器是一个“完美”的分类器,能在接收 eg 作为输入时将最终标签正确预测为2。因此作者希望向该结构输入 ec 时,同样能够得到结果为2。
实例2:数字解释
作者提出,对产品属性的打分能够在一定程度上解释对产品整体的打分。考虑到 LSTM 和 CNN 在文本分类任务中的表现较好,作者使用 LSTM 和 CNN 模型作为编码器。数字解释的生成同样看作一个分类问题。
4、数据集
作者在 PCMag 和 Skytrax 用户评论数据集上分别进行了实验。数据集的文本均使用斯坦福分词器(Stanford Tokenizer )进行了预处理。
4.1 PCMag 评论数据集
该数据集从 PCMag 的网站爬取得到,该网站提供了电子产品的评论。数据集中的每条数据都包含三部分:一段长评论,三段段评论,一个整体打分。
由于本文目标并非长文本生成,作者过滤了包含超过70个句子的长评论及包含超过75个词的段评论。数据集被随机划分为 10919/1373/1356 个句子对并分别用于训练、开发和测试集。该语料的整体得分分布如表1所示。

表1:PCMag 数据集的整体得分分布
4.2 Skytrax 用户评论数据集
该数据集从 Skytraxs 网站爬取得到,每条数据包含三部分:一段评论文本,五个子项打分和一个整体打分。子项打分在0-5之间,整体打分在0-10之间。作者移除了包含300个字符以上的评论,并将数据集随机划分为 21676/2710/2709 三部分用于训练/开发/测试。打分分布如表2所示。

表2:Skytrax 用户评论数据集的得分分布
5、实验与分析
5.1 实验设置
作者在基础模型和 应用 GEF 的基础模型上使用了相同的实验设置。本文使用 GloVe 对 PCMag 进行词嵌入,使用 Adam 最小化目标函数。模型的超参数设置如表3所示。在分类损失达到一定阈值后,作者停止了对预测器的更新。

表3:实验中的超参数设置
5.2 实验结果
文本解释的实验结果
作者使用 BLEU 分数对生成的文本解释进行评分。表4 显示了 CVAE 和 CVAE+GEF 生成的解释的比较。可以看到, CVAE+GEF 的生成质量更高。
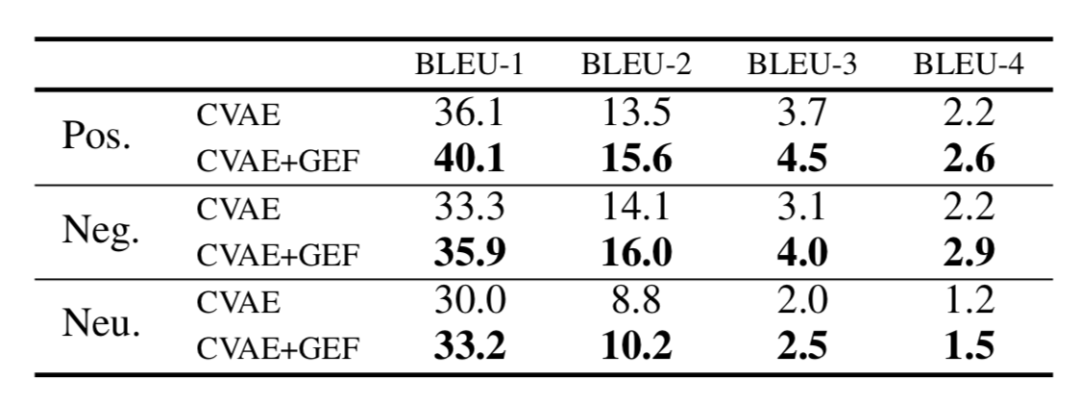
表4:CVAE 和 CVAE+GEF 生成解释的 BLEU 分值比较
作者同样对比了两个模型的分类准确率,表5展示了模型结果。可以看到, CVAE+GEF 的分类准确率更高。因此,作者认为使用细粒度解释能够提高文本分类效果。
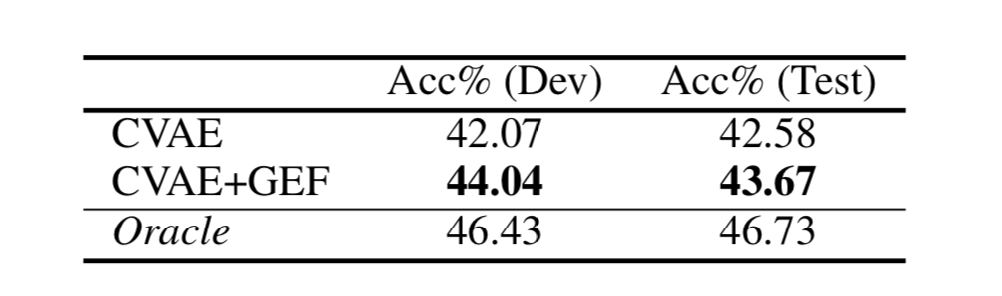
表5:PCMag 评论数据集上的分类准确率
数字解释的实验结果
作者使用 Skytrax 用户评论数据集进行了实验。表6展示了模型预测子项打分分类的准确率,本文框架提升了该预测效果,说明生成数字预测的质量也有所提升。
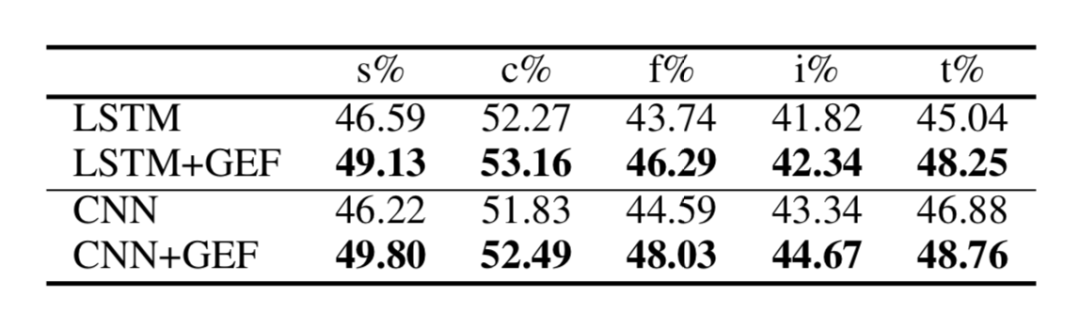
表6:Skytrax 用户评论数据集上的子项数字预测准确率
表7展示了本文模型和基线模型的分类效果,可以发现 GEF 同样提升了分类表现。
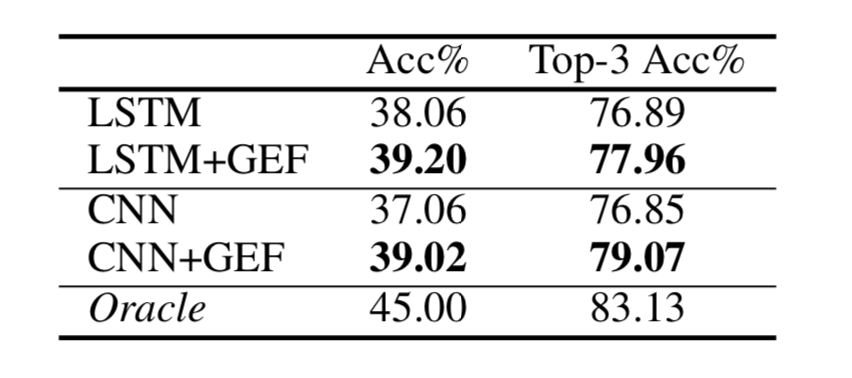
表7:Skytrax 用户评论数据集上的分类准确率
5.3 人工评测
为进一步评测模型效果,作者随机选择了100个文本实例,并使用众包评测对模型生成的解释结果进行了评估。表8展示了评估情况,可以看到 GEF 产生的解释更能被人工评测者接受。

表8:人工评测结果
5.4 错误及分析
本部分对 GEF 的缺陷进行了分析。
第一,作者认为,生成的文本解释比可接受的解释短,如表9所示,其原因为较长的解释倾向于产生更多损失。为解决这一问题,可以考虑通过强化学习增加长度奖励/惩罚来控制生成文本的长度。

表9 生成解释示例
第二,生成文本中包含一些 <UNK> 字符。由于本文生成的内容为产品评论的抽象摘要,可能存在一些特定领域的词,由于词语频率较低,对 GEF 而言进行词嵌入和生成都存在困难。一个可能的替代方法为使用复制机制(copy-mechanism)生成特定领域的词。
6、结论
本文尝试使用细粒度信息解释文本分类模型,并提出了一个生成性解释框架 GEF ,该框架可应用于不同模型。GEF 使用了最小化风险训练方法。实验表明,通过将模型和 GEF 框架结合,能够提升原始模型的效果。同时,该框架也提升了模型生成的解释的质量,说明 GEF 能够生成更加合理的结果解释。由于该框架与具体模型无关,其也可应用于自动文摘、文本抽取等工作。
(*本文为 AI科技大本营原创文章,转载请联系微信 1092722531)
◆
福利时刻
◆
入群参与每周抽奖~
扫码添加小助手,回复:大会,加入福利群,参与抽奖送礼!

AI ProCon 2019 邀请到了亚马逊首席科学家@李沐,在大会的前一天(9.5)亲授「深度学习实训营」,通过动手实操,帮助开发者全面了解深度学习的基础知识和开发技巧,现场还将赠送《动手学深度学习》。9大技术论坛、60+主题分享,百余家企业、千余名开发者共同相约 2019 AI ProCon!5折优惠票抢购中!

推荐阅读
机器学习知识点全攻略
开发者华丽转身的新机会
白话中台战略:中台是个什么鬼?
从原理到代码,轻松深入逻辑回归模型!
只需要支付0.5元就可以撤回交易?这下可坑苦DApp了……
鸿蒙 OS 背后神秘人物曝光!
5G基站功耗,到底有多大?

你点的每个“在看”,我都认真当成了喜欢
相关文章:

pyramid参数
2019独角兽企业重金招聘Python工程师标准>>> 普通参数permission: 该view的访问权限,这个后续会具体介绍。attr: Pyramid默认调用的是view类的__call__函数,如果需要指定调用其他方法,通过attr指定。如attrindex。renderer: 指定构…

Linux下常用的C/C++开源Socket库
1. Linux Socket Programming In C : http://tldp.org/LDP/LG/issue74/tougher.html 2. ACE: http://www.cs.wustl.edu/~schmidt/ACE.html ACE采用ACE_OS适配层屏蔽各种不同的、复杂繁琐的操作系统API。 ACE是一个大型的中间件产品,代码20万行左右&…
前端技术选型的遗憾和经验教训
我是Max,Spectrum的技术联合创始人。Spectrum 是一个面向大型在线社区的开源聊天应用程序,最近被GitHub收购。我们是一个三人团队,主要拥有前端和设计背景,我们在这个项目上工作了近两年时间。 事后看来,以下是我做出的…

时间序列的建模新思路:清华、李飞飞团队等提出强记忆力E3D-LSTM网络
作者 | Yunbo Wang,、Lu Jiang、 Ming-Hsuan Yang、Li-Jia Li、Mingsheng Long、Li Fei-Fei译者 | 凯隐编辑 | Jane出品 | AI科技大本营(ID:rgznai100)【导读】如何对时间序列进行时空建模及特征抽取,是RGB视频预测分类࿰…
了解node.js
转载自http://debuggable.com/posts/understanding-node-js:4bd98440-45e4-4a9a-8ef7-0f7ecbdd56cb 当我向人们介绍node.js时,通常会得到两种反应,一种人马上就能了解,另一种则是非常困惑。 如果你是第二种人,请看一下我对node的解…
VS2013中Image Watch插件的使用(OpenCV)
之前在vs2010中写OpenCV程序时经常用NativeViewer,安装此插件后,在调试代码时,对于cv::Mat变量,CV_TYPE类型为CV_8UC1或CV_8UC3,可以随时查看显示结果。其操作步骤为:1. 从http://sourceforge.net/p…

【spring boot2】第8篇:spring boot 中的 servlet 容器及如何使用war包部署
嵌入式 servlet 容器 在 spring boot 之前的web开发,我们都是把我们的应用部署到 Tomcat 等servelt容器,这些容器一般都会在我们的应用服务器上安装好环境,但是 spring boot 中并不需要外部应用服务器安装这些servlet容器,spring …

让织梦内容页arclist标签的当前文章标题加亮显示
很多人在用织梦做站的时候,会用到在当前栏目页面,给当前栏目标题使用指定样式如标题加亮,或者放个背景图。这是一个很常用和实用的功能,比如在导航页面,标识当前在浏览哪个栏目。如下图: 但是有些时候&…
RHEL6入门系列之九,常用命令2
今天还是继续来学习Linux的基本命令。4、touch命令——建立空文件touch命令用于建立空文件。[rootlocalhost ~]# mkdir /root/test ‘创建目录/root/test[rootlocalhost ~]# touch /root/test/test1.txt ‘在目录/root/test中创建空文件test1.txt[rootlocalhos…

为什么华为200万招聘AI博士,马斯克却推出脑机接口对抗AI?
作者 | 伍杏玲来源 | CSDN(ID:CSDNnews)7 月,华为一则薪资通知刷爆朋友圈:华为给8位博士应届生给予 89.6 万至 201 万的年薪。其中薪资最高的两位博士均研究人工智能相关专业。7 月还有一件大事:马斯克发布…
Artistic Style在windows下的使用(C/C++)
ArtisticStyle是一个开源的源代码格式化工具。主页地址为:http://astyle.sourceforge.net/,它可以应用在C、C、Objective-C、C#、Java等程序语言中。http://astyle.sourceforge.net/astyle.html中为对使用它的详细介绍。从http://sourceforge.net/projec…
ESXi主机与网络中其他主机的网咯数据包捕获
1、tcpdump-uw -i vmk0 -s 1514 host x.x.x.x 指定捕获与某台主机间的网络数据包2、tcpdump -i vmk0 -s 1514 port not 22 and port not 53 在捕获的数据包中,过滤掉指定端口的数据包3、tcpdump-uw -i vmk0 -s 1514 -w traffic.pcap 捕获的数据包保存成PCAP文件&…
Windows下批处理文件(.bat)的使用
批处理(Batch),就是进行批量的处理,英文译文BATCH,批处理文件后缀BAT就取的前三个字母,通常被认为是一种简化的脚本语言,它应用于DOS和Windows系统中。批处理文件是扩展名为.bat或.cmd的文本文件,包含一条或…

金融业加速智能化,解析360金融AI基础架构和应用
传统金融信贷业务中,催收、客服及电销人员占比超过 60%,人员素质参差不齐的现状造成了管理成本过高的问题,由此衍生的客户体验差,也成为困扰金融业的一大通病。 8 月 15 日,在 360金融 AI 媒体开放日上,360…
正则:匹配一个汉字姓名
//汉字姓名正则var reg/^[\u4e00-\u9fa5]{2,}(\.[\u4e00-\u9fa5])?$/console.log(reg.test(张卫健.爱新觉罗))console.log(reg.test(兔子)) 复制代码

NLP命名实体识别开源实战教程 | 深度应用
作者 | 小宋是呢来源 | CSDN博客近几年来,基于神经网络的深度学习方法在计算机视觉、语音识别等领域取得了巨大成功,另外在自然语言处理领域也取得了不少进展。在NLP的关键性基础任务—命名实体识别(Named Entity Recognition,NER…
poj 2063完全背包
题意:给出总资金和投资年份 ,n个股票 给出股票价格和其一年的利润。问如何选择能获得最大利润。 思路:股票可以重复选择,完全背包问题,完全背包也是从01背包衍生而行的,其主要区别在于中间那层循环的次序不…
UTF-8 CPP的使用
UTF-8 CPP是一个简单、小巧、轻量级、跨平台的UTF-8编码字符串库。下面对其使用方法进行简单的介绍:1. 从http://sourceforge.net/projects/utfcpp/下载最新的utf8_v2_3_4.zip源码,将其解压缩;2. 新建一个vs2013 控制台工程TestUTF…

一行js代码识别Selenium+Webdriver及其应对方案
有不少朋友在开发爬虫的过程中喜欢使用Selenium Chromedriver,以为这样就能做到不被网站的反爬虫机制发现。 先不说淘宝这种基于用户行为的反爬虫策略,仅仅是一个普通的小网站,使用一行Javascript代码,就能轻轻松松识别你是否使用…

Android系统移植与调试之-------如何修改Android设备添加重启、飞行模式、静音模式等功能(一)...
1、首先先来看一下修改前后的效果对比图 修改之后的图片 确认重启界面 具体的修改内容在下一篇中具体介绍。 Android系统移植与调试之------->如何修改Android设备添加重启、飞行模式、静音模式等功能(二) 作者:欧阳鹏 欢迎转载…
鸿蒙霸榜GitHub,从最初的Plan B到“取代Android”?
整理 | 郭芮出品 | CSDN(ID:CSDNnews)距离 8 月 9 日鸿蒙(HarmonyOS)正式发布刚刚过去九天,这场由华为领衔的技术风暴,经过十年蛰伏,终于成功引爆全球。与此同时,一个非官…

CODING 最佳实践:快课网研发效能提升之路
快课企业移动学习平台是上海快微网络科技有限公司自主研发的企业级 SaaS 平台,提供移动学习、考试练习、培训管理、知识分享、统计分析等学习和培训功能,为员工、经销商及客户等全价值链合作伙伴提供全面的知识服务。本文将详细介绍快课网的研发团队是如…
基于chyh1990/caffe-compact在windows vs2013上编译caffe步骤
1. 从https://github.com/chyh1990/caffe-compact下载caffe-compact代码; 2. 通过CMake(cmake-gui)生成vs2013 x64 caffe工程; 3. 从https://github.com/google/protobuf下载ProtoBuf,解压缩,编译ProtoBuf…
菜鸟学***——菜鸟的旅程
第一章.菜鸟的旅程作为一个典型的菜鸟,第一次去网吧上网我不知道怎么开机是很正常的事情,但是无论怎么菜怎么无知也无法阻止我对于***的崇拜,我喜欢他们的那种神秘和在我们普通人眼中的无所不能,在网络世界里他们就想鱼…
程序员假冒AI,印度公司竟骗取2亿元投资
作者 | 神经小姐姐来源 | HyperAI超神经(ID:HyperAI)人工智能界有句调侃的话——「有多少智能,就有多少人工」,今天,印度的一家人工智能公司就印证了这句话。据《华尔街日报》报道,印度创业公司…

Windows7上使用VS2013编译Caffe源码(不带GPU支持)步骤
1. 从https://github.com/BVLC/caffe/通过git clone下载caffe源码,master分支,版本号为09868ac:$ git clone https://github.com/BVLC/caffe.git ;2. 先使用cmake-gui构建生成vs2013工程,发现有很多错误,提示缺少各种依…
区块链之比特币的潜在激励
想知道更多区块链技术知识,请百度【链客区块链技术问答社区】链客,有问必答!! 比特币,这个建立在开放P2P(点对点)网络结构之上的货币(文献9),继续享受人们的追…
每天超50亿推广流量、3亿商品展现,阿里妈妈的推荐技术有多牛?
作者 | 夕颜出品 | AI科技大本营(ID:rgznai100)随着深度学习、强化学习、知识图谱、AutoML 等 AI 技术出现更多突破,推荐系统领域的企业和开发者开始将这些技术与传统推荐算法相结合,使得推荐效果得到显著提升。不过,越…
常用的JQuery数字类型验证正则表达式
var regexEnum { intege:"^-?[1-9]//d*$", //整数 intege1:"^[1-9]//d*$", //正整数 intege2:"^-[1-9]//d*$", //负整数 num:"^([-]?)//d*//.?//d$", //数字 num1:"^([1-9]//d*|0)$", //正数ÿ…
Java多线程编程实战:模拟大量数据同步
背景 最近对于 Java 多线程做了一段时间的学习,笔者一直认为,学习东西就是要应用到实际的业务需求中的。否则要么无法深入理解,要么硬生生地套用技术只是达到炫技的效果。 不过笔者仍旧认为自己对于多线程掌握不够熟练,不敢轻易应…