常用排序算法的C++实现
排序是将一组”无序”的记录序列调整为”有序”的记录序列。
假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,ri=rj,且ri在rj之前,而在排序后的序列中,ri仍在rj之前,则称这种排序算法是稳定的;否则称为不稳定的。
冒泡排序:依次比较相邻的两个数,按照从小到大或者从大到小的顺序进行交换。
插入排序:每次从无序表中取出第一个元素,把它插入到有序表的合适位置,使有序表仍然有序。
选择排序:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
希尔排序:先将整个待排序记录序列分割成若干个子序列,再在子序列内分别进行直接插入排序,待整个序列基本有序时,再对全体记录进行一次直接插入排序。
归并排序:采用分治法,通过对若干个有序结点序列的归并来实现排序。所谓归并是指将若干个已排好序的部分合并成一个有序的部分。
堆排序:是一个完全二叉树。
快速排序:采用分治法,使数组中的每个元素与基准值比较,数组中比基准值小的放在基准值的左边,形成左部;大的放在右边,形成右部;接下来将左部和右部分别递归地执行上面的过程。
std::sort(std::stable_sort):类似于快速排序。
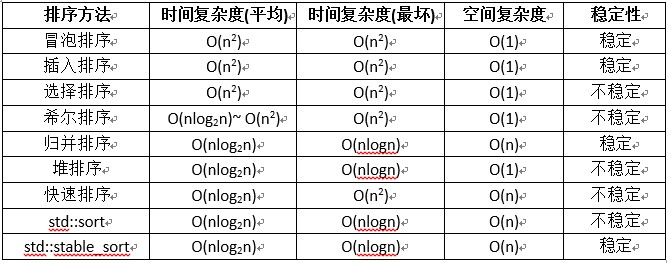
各种排序算法的时间复杂度如下:
下面是从其他文章中copy的测试代码,详细内容介绍可以参考对应的reference:
#include "sort.hpp"
#include <iostream>
#include <vector>
#include <algorithm>const std::vector<int> array_src{ 12, -32, 138, -54, 34, 87, 200, -1, -901, 88 };static void print_result(const std::vector<int>& vec)
{for (int i = 0; i < vec.size(); i++)fprintf(stderr, "%d ", vec[i]);fprintf(stderr, "\n");
}int test_sort_bubble() // 冒泡排序
{// reference: http://mathbits.com/MathBits/CompSci/Arrays/Bubble.htmstd::vector<int> vec(array_src.begin(), array_src.end());int tmp = 0;for (int i = 1; i < vec.size(); i++) {for (int j = 0; j < vec.size() - 1; j++) {if (vec[j + 1] < vec[j]) {tmp = vec[j];vec[j] = vec[j + 1];vec[j + 1] = tmp;}}}fprintf(stderr, "bubble sort result: \n");print_result(vec);return 0;
}int test_sort_insertion() // 插入排序
{// reference: http://cforbeginners.com/insertionsort.htmlstd::vector<int> vec(array_src.begin(), array_src.end());int tmp = 0, j = 0;for (int i = 1; i < vec.size(); i++){j = i;while (j > 0 && vec[j] < vec[j - 1]){tmp = vec[j];vec[j] = vec[j - 1];vec[j - 1] = tmp;j--;}}fprintf(stderr, "insertion sort result: \n");print_result(vec);return 0;
}int test_sort_selection() // 选择排序
{// reference: http://mathbits.com/MathBits/CompSci/Arrays/Selection.htmstd::vector<int> vec(array_src.begin(), array_src.end());int tmp = 0;for (int i = vec.size() - 1; i > 0; i--) {int first = 0;for (int j = 1; j <= i; j++) {if (vec[j] > vec[first])first = j;}tmp = vec[first];vec[first] = vec[i];vec[i] = tmp;}fprintf(stderr, "selection sort result: \n");print_result(vec);return 0;
}int test_sort_shell() // 希尔排序
{// reference: http://www.cplusplus.com/forum/general/123961/std::vector<int> vec(array_src.begin(), array_src.end());int tmp = 0, gap = 0;for (int gap = vec.size() / 2; gap > 0; gap /= 2) {for (int i = gap; i < vec.size(); i++) {for (int j = i - gap; j >= 0 && vec[j] > vec[j + gap]; j -= gap) {tmp = vec[j];vec[j] = vec[j + gap];vec[j + gap] = tmp;}}}fprintf(stderr, "shell sort result: \n");print_result(vec);return 0;
}// left is the index of the leftmost element of the subarray
// right is one past the index of the rightmost element
static void merge(std::vector<int>& vecSrc, int left, int right, std::vector<int>& vecDst)
{// base case: one elementif (right == left + 1) {return;} else {int i = 0;int length = right - left;int midpoint_distance = length / 2;/* l and r are to the positions in the left and right subarrays */int l = left, r = left + midpoint_distance;/* sort each subarray */merge(vecSrc, left, left + midpoint_distance, vecDst);merge(vecSrc, left + midpoint_distance, right, vecDst);/* merge the arrays together using scratch for temporary storage */for (i = 0; i < length; i++) {/* Check to see if any elements remain in the left array; if so,* we check if there are any elements left in the right array; if* so, we compare them. Otherwise, we know that the merge must* use take the element from the left array */if (l < left + midpoint_distance && (r == right || std::min(vecSrc[l], vecSrc[r]) == vecSrc[l])) {vecDst[i] = vecSrc[l];l++;} else {vecDst[i] = vecSrc[r];r++;}}/* Copy the sorted subarray back to the input */for (i = left; i < right; i++) {vecSrc[i] = vecDst[i - left];}}
}int test_sort_merge() // 归并排序
{// reference: http://www.cprogramming.com/tutorial/computersciencetheory/merge.htmlstd::vector<int> vecSrc(array_src.begin(), array_src.end());std::vector<int> vecDst(array_src.size());merge(vecSrc, 0, vecSrc.size(), vecDst);fprintf(stderr, "merge sort result: \n");print_result(vecDst);return 0;
}static void quick(std::vector<int>& vec, int left, int right)
{int i = left, j = right;int tmp;int pivot = vec[(left + right) / 2];// partitionwhile (i <= j) {while (vec[i] < pivot)i++;while (vec[j] > pivot)j--;if (i <= j) {tmp = vec[i];vec[i] = vec[j];vec[j] = tmp;i++;j--;}};// recursionif (left < j)quick(vec, left, j);if (i < right)quick(vec, i, right);
}int test_sort_quick() // 快速排序
{// reference: http://www.algolist.net/Algorithms/Sorting/Quicksortstd::vector<int> vec(array_src.begin(), array_src.end());quick(vec, 0, vec.size() - 1);fprintf(stderr, "quick sort result: \n");print_result(vec);return 0;
}static void max_heapify(std::vector<int>& vec, int i, int n)
{int temp = vec[i];int j = 2 * i;while (j <= n) {if (j < n && vec[j + 1] > vec[j])j = j + 1;if (temp > vec[j]) {break;} else if (temp <= vec[j]) {vec[j / 2] = vec[j];j = 2 * j;}}vec[j / 2] = temp;
}static void heapsort(std::vector<int>& vec, int n)
{for (int i = n; i >= 2; i--) {int temp = vec[i];vec[i] = vec[1];vec[1] = temp;max_heapify(vec, 1, i - 1);}
}static void build_maxheap(std::vector<int>& vec, int n)
{for (int i = n / 2; i >= 1; i--)max_heapify(vec, i, n);
}int test_sort_heap() // 堆排序
{// reference: http://proprogramming.org/heap-sort-in-c/std::vector<int> vec(array_src.begin(), array_src.end());vec.insert(vec.begin(), -1);build_maxheap(vec, vec.size()-1);heapsort(vec, vec.size()-1);std::vector<int> vecDst(vec.begin() + 1, vec.end());fprintf(stderr, "heap sort result: \n");print_result(vecDst);return 0;
}static bool cmp(int i, int j)
{return (i<j);
}int test_sort_STL() // std::sort
{// reference: http://www.cplusplus.com/reference/algorithm/sort/std::vector<int> vec(array_src.begin(), array_src.end());std::sort(vec.begin(), vec.end(), cmp);fprintf(stderr, "STL sort result: \n");print_result(vec);std::vector<int> vec1(array_src.begin(), array_src.end());std::stable_sort(vec1.begin(), vec1.end(), cmp);fprintf(stderr, "STL stable sort result: \n");print_result(vec1);return 0;
}GitHub: https://github.com/fengbingchun/Messy_Test
相关文章:

4.65FTP服务4.66测试登录FTP
2019独角兽企业重金招聘Python工程师标准>>> FTP服务 测试登录FTP 4.65FTP服务 文件传输协议(FTP),可以上传和下载文件。比如我们可以把Windows上的文件shan上传到Linux,也可以把Linux上的文件下载到Windows上。 Cent…

JavaScript的应用
DOM, BOM, XMLHttpRequest, Framework, Tool (Functionality) Performance (Caching, Combine, Minify, JSLint) ---------------- 人工做不了,交给程序去做,这样可以流程化。 Maintainability (Pattern) http://www.jmarshall.com/easy/http/ http://dj…
miniz库简介及使用
miniz:Google开源库,它是单一的C源文件,紧缩/膨胀压缩库,使用zlib兼容API,ZIP归档读写,PNG写方式。关于miniz的更详细介绍可以参考:https://code.google.com/archive/p/miniz/miniz.c is a loss…
iOS之runtime详解api(三)
第一篇我们讲了关于Class和Category的api,第二篇讲了关于Method的api,这一篇来讲关于Ivar和Property。 4.objc_ivar or Ivar 首先,我们还是先找到能打印出Ivar信息的函数: const char * _Nullable ivar_getName(Ivar _Nonnull v) …

亚马逊首席科学家李沐「实训营」国内独家直播,马上报名 !
开学了,别人家的学校都开始人工智能专业的学习之旅了,你呢?近年来,国内外顶尖科技企业的 AI 人才抢夺战愈演愈烈。华为开出200万年薪吸引 AI 人才,今年又有 35 所高校新增人工智能本科专业,众多新生即将开展…


人脸检测库libfacedetection介绍
libfacedetection是于仕琪老师放到GitHub上的二进制库,没有源码,它的License是MIT,可以商用。目前只提供了windows 32和64位的release动态库,主页为https://github.com/ShiqiYu/libfacedetection,采用的算法好像是Mult…

倒计时1天 | 2019 AI ProCon报名通道即将关闭(附参会指南)
2019年9月5-7日,面向AI技术人的年度盛会—— 2019 AI开发者大会 AI ProCon,震撼来袭!2018 年由 CSDN 成功举办 AI 开发者大会一年之后,全球 AI 市场正发生着巨大的变化。顶尖科技企业和创新力量不断地进行着技术的更迭和应用的推…

法院判决:优步无罪,无人车安全员可能面临过失杀人控诉
据路透社报道,负责优步无人车在亚利桑那州致人死亡事件调查的律师事务所发布公开信宣布,优步在事故中“不承担刑事责任”,但是当时在车上的安全员Rafaela Vasquez要接受进一步调查,可能面临车辆过失杀人罪指控。2018年3月…

09 Storage Structure and Relationships
目标:存储结构:Segments分类:Extents介绍:Blocks介绍:转载于:https://blog.51cto.com/eread/1333894
边界框的回归策略搞不懂?算法太多分不清?看这篇就够了
作者 | fivetrees来源 | https://zhuanlan.zhihu.com/p/76477248本文已由作者授权,未经允许,不得二次转载【导读】目标检测包括目标分类和目标定位 2 个任务,目标定位一般是用一个矩形的边界框来框出物体所在的位置,关于边界框的回…
人脸识别引擎SeetaFaceEngine简介及在windows7 vs2013下的编译
SeetaFaceEngine是开源的C人脸识别引擎,无需第三方库,它是由中科院计算所山世光老师团队研发。它的License是BSD-2.SeetaFaceEngine库包括三个模块:人脸检测(detection)、面部特征点定位(alignment)、人脸特征提取与比对(identification)。人…

当移动数据分析需求遇到Quick BI
我叫洞幺,是一名大型婚恋网站“我在这等你”的资深老员工,虽然在公司五六年,还在一线搬砖。“我在这等你”成立15年,目前积累注册用户高达2亿多,在我们网站成功牵手的用户达2千多万。目前我们的公司在CEO的英名带领下&…
为什么选择数据分析师这个职业?
我为什么选择做数据分析师? 我大学专业是物流管理,学习内容偏向于管理学和经济学,但其实最感兴趣的还是心理学,即人在各种刺激下反应的机制以及原理。做数据分析师,某种意义上是对群体行为的研究和量化,两者…
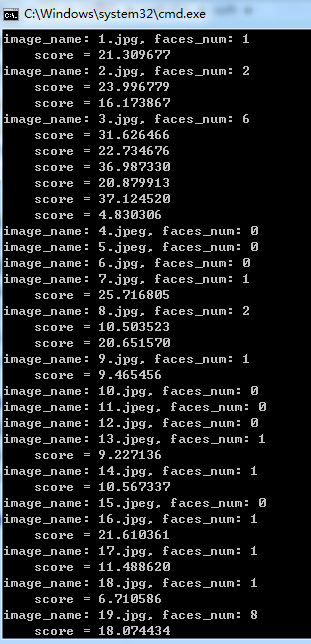
人脸识别引擎SeetaFaceEngine中Detection模块使用的测试代码
人脸识别引擎SeetaFaceEngine中Detection模块用于人脸检测,以下是测试代码:int test_detection() {std::vector<std::string> images{ "1.jpg", "2.jpg", "3.jpg", "4.jpeg", "5.jpeg", "…
基于Pygame写的翻译方法
发布时间:2018-11-01技术:pygameeasygui概述 实现一个翻译功能,中英文的互相转换。并可以播放翻译后的内容。 翻译接口调用的是百度翻译的api接口。详细 代码下载:http://www.demodashi.com/demo/14326.html 一、需求分析 使用pyg…

冠军奖3万元!CSDN×易观算法大赛开赛啦
伴随着5G、物联网与大数据形成的后互联网格局的逐步形成,日益多样化的用户触点、庞杂的行为数据和沉重的业务体量也给我们的数据资产管理带来了不容忽视的挑战。为了建立更加精准的数据挖掘形式和更加智能的机器学习算法,对不断生成的用户行为事件和各类…
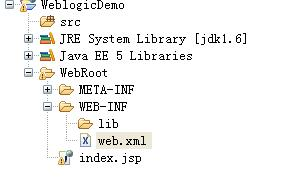
快速把web项目部署到weblogic上
weblogic简介 BEA WebLogic是用于开发、集成、部署和管理大型分布式Web应用、网络应用和数据库应 用的Java应用服务器。将Java的动态功能和Java Enterprise标准的安全性引入大型网络应用的开发、集成、部署和管理之中。 BEA WebLogic Server拥有处理关键Web应用系统问题所需的性…
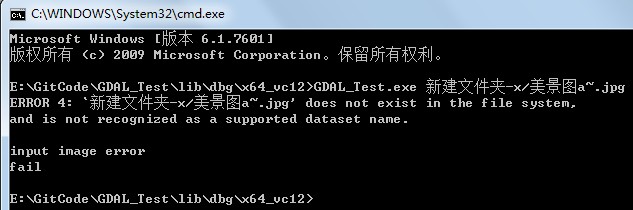
使GDAL库支持中文路径或中文文件名的处理方法
之前生成的gdal 2.1.1动态库,在通过命令行执行时,遇到有中文路径或中文图像名时,GDALOpen函数不能正确的被调用,如下图:解决方法:1. 在所有使用GDALAllRegister();语句后面加上一句CPLSetConfigOption…

创新工场论文入选NeurIPS 2019,研发最强“AI蒙汗药”
9月4日,被誉为机器学习和神经网络领域的顶级会议之一的 NeurIPS 2019 揭晓收录论文名单,创新工场人工智能工程院的论文《Learning to Confuse: Generating Training Time Adversarial Data with Auto-Encoder》被接收在列。这篇论文围绕现阶段人工智能系…
Flutter环境搭建(Windows)
SDK获取 去官方网站下载最新的安装包 ,或者在Github中的Flutter项目去 下载 。 将下载的安装包解压 注意:不要将Flutter安装到高权限路径,例如 C:\Program Files\ 配置环境变量,在Path中添加flutter\bin的全路径(如:D…
Android在eoe分享一篇推荐开发组件或者框架的文章
http://www.eoeandroid.com/thread-311194-1-1.html y4078275315 主题 62 帖子 352 e币实习版主 积分314发消息电梯直达楼主 回复 发表于 2013-11-7 09:58:45 | 只看该作者 |只看大图 34本帖最后由 y407827531 于 2013-11-28 15:07 编辑感谢版主推荐,本贴会持续更新…

如何打造高质量的机器学习数据集?这份超详指南不可错过
作者 | 周岩,夕小瑶,霍华德,留德华叫兽转载自知乎博主『运筹OR帷幄』导读:随着计算机行业的发展,人工智能和数据科学近几年成为了学术和工业界关注的热点。特别是这些年人工智能的发展日新月异,每天都有新的…

人脸识别引擎SeetaFaceEngine中Alignment模块使用的测试代码
人脸识别引擎SeetaFaceEngine中Alignment模块用于检测人脸关键点,包括5个点,两个眼的中心、鼻尖、两个嘴角,以下是测试代码:int test_alignment() {std::vector<std::string> images{ "1.jpg", "2.jpg"…
微软宣布 Win10 设备数突破8亿,距离10亿还远吗?
开发四年只会写业务代码,分布式高并发都不会还做程序员? >>> 微软高管 Yusuf Mehdi 昨天在推特发布了一条推文,宣布运行 Windows 10 的设备数已突破 8 亿,比半年前增加了 1 亿。 根据之前的报道,两个月前 W…
领导者必须学会做的十件事情
在这个世界上你可以逃避很多事情并且仍然能够获得成功,但是有些事情你根本就无法走捷径。商业领导者们并不存在于真空之中。成功总是与竞争有关。你可能拥有伟大的产品、服务、概念、战略、团队等等,如果它不能从某种程度上超越竞争对手,这对…

人脸识别引擎SeetaFaceEngine中Identification模块使用的测试代码
人脸识别引擎SeetaFaceEngine中Identification模块用于比较两幅人脸图像的相似度,以下是测试代码:int test_recognize() {const std::string path_images{ "E:/GitCode/Face_Test/testdata/recognization/" };seeta::FaceDetection detector(&…

李沐亲授加州大学伯克利分校深度学习课程移师中国,现场资料新鲜出炉
2019 年 9 月 5 日,AI ProCon 2019 在北京长城饭店正式拉开帷幕。大会的第一天,以亚马逊首席科学家李沐面对面亲自授课完美开启!“大神”,是很多人对李沐的印象。除了是亚马逊首席科学家李,李沐还拥有多重身份…
对Python课的看法
学习Python已经有两周的时间了,我是计算机专业的学生,我抱着可以多了解一种语言的想法报了Python的选修课,从第一次听肖老师的课开始,我便感受到一种好久没有感受到的课堂氛围,感觉十分舒服,不再是那种高中…
维护学习的一点体会与看法
学习维护的知识也有2个月了,对于知识的学习也有一定的看法。接下来我就说一下我对学习的看法。首先,你要学会自学,无论是看书还是上网查资料,维护的知识很多很杂,想要人一下子来教是不可能。只能是自己慢慢的学。其次&…