逻辑回归(Logistic Regression)简介及C++实现
逻辑回归(Logistic Regression):该模型用于分类而非回归,可以使用logistic sigmoid函数( 可参考:http://blog.csdn.net/fengbingchun/article/details/73848734 )将线性函数的输出压缩进区间(0,1):
p(y=1| x;θ)=σ(θTx).
逻辑回归是一种广义的线性回归分析(可参考: http://blog.csdn.net/fengbingchun/article/details/77892193 )模型,因此与多重线性回归分析有很多相同之处。它们的模型形式基本上相同,都具有w’x+b,其中w和b是待求参数,其区别在于它们的因变量不同,多重线性回归直接将w’x+b作为因变量,即y=w’x+b,而逻辑回归则通过函数L将w’x+b对应一个隐状态p, p=L(w’x+b),然后根据p与1-p的大小决定因变量的值。如果L是logistic函数,就是logistic回归,如果L是多项式函数就是多项式回归。
Logistic回归的因变量可以是二分类的,也可以是多分类的。多类可以使用softmax方法(可参考 http://blog.csdn.net/fengbingchun/article/details/75220591 )进行处理。
优化逻辑回归的方法包括:梯度下降法、牛顿法、BFGS。优化的主要目标是找到一个方向,参数朝这个方向移动之后使得似然函数的值能够减少,这个方向往往由一阶偏导或者二阶偏导各种组合求得。这几种方法一般都是采用迭代的方式来逐步逼近极小值。
Logistic回归类似于线性回归模型,但更适用于因变量为二分变量的模型。逻辑回归中预测函数用到了逻辑函数即sigmoid函数(逻辑回归拟合函数)。逻辑回归中的损失函数(cost function)是基于最大似然估计推导的。
逻辑回归中的过拟合:对于逻辑回归或线性回归的损失函数构成的模型,可能会有些权重很大,有些权重很小,导致过拟合,使得模型的复杂度提高,泛化能力较差。一般多用正则化的方法来解决过拟合。
以下是参考OpenCV3.3中LogisticRegression类实现的二分类逻辑回归code:包括训练方法包括Batch和Mini Batch,并支持简单的正则化方法,实现code如下:
logistic_regression.hpp:
#ifndef FBC_NN_LOGISTICREGRESSION_HPP_
#define FBC_NN_LOGISTICREGRESSION_HPP_#include <string>
#include <memory>
#include <vector>namespace ANN {template<typename T>
class LogisticRegression { // two categories
public:LogisticRegression() = default;int init(const T* data, const T* labels, int train_num, int feature_length,int reg_kinds = -1, T learning_rate = 0.00001, int iterations = 10000, int train_method = 0, int mini_batch_size = 1);int train(const std::string& model);int load_model(const std::string& model);T predict(const T* data, int feature_length) const; // y = 1/(1+exp(-(wx+b)))// Regularization kindsenum RegKinds {REG_DISABLE = -1, // Regularization disabledREG_L1 = 0 // L1 norm};// Training methodsenum Methods {BATCH = 0,MINI_BATCH = 1};private:int store_model(const std::string& model) const;T calc_sigmoid(T x) const; // y = 1/(1+exp(-x))T norm(const std::vector<T>& v1, const std::vector<T>& v2) const;void batch_gradient_descent();void mini_batch_gradient_descent();void gradient_descent(const std::vector<std::vector<T>>& data_batch, const std::vector<T>& labels_batch, int length_batch);std::vector<std::vector<T>> data;std::vector<T> labels;int iterations = 1000;int train_num = 0; // train samples numint feature_length = 0;T learning_rate = 0.00001;std::vector<T> thetas; // coefficient//T epsilon = 0.000001; // termination conditionT lambda = (T)0.; // regularization methodint train_method = 0;int mini_batch_size = 1;
};} // namespace ANN#endif // FBC_NN_LOGISTICREGRESSION_HPP_#include "logistic_regression.hpp"
#include <fstream>
#include <algorithm>
#include <functional>
#include <numeric>
#include "common.hpp"namespace ANN {template<typename T>
int LogisticRegression<T>::init(const T* data, const T* labels, int train_num, int feature_length,int reg_kinds, T learning_rate, int iterations, int train_method, int mini_batch_size)
{if (train_num < 2) {fprintf(stderr, "logistic regression train samples num is too little: %d\n", train_num);return -1;}if (learning_rate <= 0) {fprintf(stderr, "learning rate must be greater 0: %f\n", learning_rate);return -1;}if (iterations <= 0) {fprintf(stderr, "number of iterations cannot be zero or a negative number: %d\n", iterations);return -1;}CHECK(reg_kinds == -1 || reg_kinds == 0);CHECK(train_method == 0 || train_method == 1);CHECK(mini_batch_size >= 1 && mini_batch_size < train_num);if (reg_kinds == REG_L1) this->lambda = (T)1.;if (train_method == MINI_BATCH) this->train_method = 1;this->mini_batch_size = mini_batch_size;this->learning_rate = learning_rate;this->iterations = iterations;this->train_num = train_num;this->feature_length = feature_length;this->data.resize(train_num);this->labels.resize(train_num);for (int i = 0; i < train_num; ++i) {const T* p = data + i * feature_length;this->data[i].resize(feature_length+1);this->data[i][0] = (T)1; // biasfor (int j = 0; j < feature_length; ++j) {this->data[i][j+1] = p[j];}this->labels[i] = labels[i];}this->thetas.resize(feature_length + 1, (T)0.); // bias + feature_lengthreturn 0;
}template<typename T>
int LogisticRegression<T>::train(const std::string& model)
{CHECK(data.size() == labels.size());if (train_method == BATCH) batch_gradient_descent();else mini_batch_gradient_descent();CHECK(store_model(model) == 0);return 0;
}template<typename T>
void LogisticRegression<T>::batch_gradient_descent()
{for (int i = 0; i < iterations; ++i) {gradient_descent(data, labels, train_num);/*std::unique_ptr<T[]> z(new T[train_num]), gradient(new T[thetas.size()]);for (int j = 0; j < train_num; ++j) {z.get()[j] = (T)0.;for (int t = 0; t < feature_length + 1; ++t) {z.get()[j] += data[j][t] * thetas[t];}}std::unique_ptr<T[]> pcal_a(new T[train_num]), pcal_b(new T[train_num]), pcal_ab(new T[train_num]);for (int j = 0; j < train_num; ++j) {pcal_a.get()[j] = calc_sigmoid(z.get()[j]) - labels[j];pcal_b.get()[j] = data[j][0]; // biaspcal_ab.get()[j] = pcal_a.get()[j] * pcal_b.get()[j];}gradient.get()[0] = ((T)1. / train_num) * std::accumulate(pcal_ab.get(), pcal_ab.get() + train_num, (T)0.); // biasfor (int j = 1; j < thetas.size(); ++j) {for (int t = 0; t < train_num; ++t) {pcal_b.get()[t] = data[t][j];pcal_ab.get()[t] = pcal_a.get()[t] * pcal_b.get()[t];}gradient.get()[j] = ((T)1. / train_num) * std::accumulate(pcal_ab.get(), pcal_ab.get() + train_num, (T)0.) +(lambda / train_num) * thetas[j];}for (int i = 0; i < thetas.size(); ++i) {thetas[i] = thetas[i] - learning_rate / train_num * gradient.get()[i];}*/}
}template<typename T>
void LogisticRegression<T>::mini_batch_gradient_descent()
{const int step = mini_batch_size;const int iter_batch = (train_num + step - 1) / step;for (int i = 0; i < iterations; ++i) {int pos{ 0 };for (int j = 0; j < iter_batch; ++j) {std::vector<std::vector<T>> data_batch;std::vector<T> labels_batch;int remainder{ 0 };if (pos + step < train_num) remainder = step;else remainder = train_num - pos;data_batch.resize(remainder);labels_batch.resize(remainder, (T)0.);for (int t = 0; t < remainder; ++t) {data_batch[t].resize(thetas.size(), (T)0.);for (int m = 0; m < thetas.size(); ++m) {data_batch[t][m] = data[pos + t][m];}labels_batch[t] = labels[pos + t];}gradient_descent(data_batch, labels_batch, remainder);pos += step;}}
}template<typename T>
void LogisticRegression<T>::gradient_descent(const std::vector<std::vector<T>>& data_batch, const std::vector<T>& labels_batch, int length_batch)
{std::unique_ptr<T[]> z(new T[length_batch]), gradient(new T[this->thetas.size()]);for (int j = 0; j < length_batch; ++j) {z.get()[j] = (T)0.;for (int t = 0; t < this->thetas.size(); ++t) {z.get()[j] += data_batch[j][t] * this->thetas[t];}}std::unique_ptr<T[]> pcal_a(new T[length_batch]), pcal_b(new T[length_batch]), pcal_ab(new T[length_batch]);for (int j = 0; j < length_batch; ++j) {pcal_a.get()[j] = calc_sigmoid(z.get()[j]) - labels_batch[j];pcal_b.get()[j] = data_batch[j][0]; // biaspcal_ab.get()[j] = pcal_a.get()[j] * pcal_b.get()[j];}gradient.get()[0] = ((T)1. / length_batch) * std::accumulate(pcal_ab.get(), pcal_ab.get() + length_batch, (T)0.); // biasfor (int j = 1; j < this->thetas.size(); ++j) {for (int t = 0; t < length_batch; ++t) {pcal_b.get()[t] = data_batch[t][j];pcal_ab.get()[t] = pcal_a.get()[t] * pcal_b.get()[t];}gradient.get()[j] = ((T)1. / length_batch) * std::accumulate(pcal_ab.get(), pcal_ab.get() + length_batch, (T)0.) +(this->lambda / length_batch) * this->thetas[j];}for (int i = 0; i < thetas.size(); ++i) {this->thetas[i] = this->thetas[i] - this->learning_rate / length_batch * gradient.get()[i];}
}template<typename T>
int LogisticRegression<T>::load_model(const std::string& model)
{std::ifstream file;file.open(model.c_str(), std::ios::binary);if (!file.is_open()) {fprintf(stderr, "open file fail: %s\n", model.c_str());return -1;}int length{ 0 };file.read((char*)&length, sizeof(length));thetas.resize(length);file.read((char*)thetas.data(), sizeof(T)*thetas.size());file.close();return 0;
}template<typename T>
T LogisticRegression<T>::predict(const T* data, int feature_length) const
{CHECK(feature_length + 1 == thetas.size());T value{(T)0.};for (int t = 1; t < thetas.size(); ++t) {value += data[t - 1] * thetas[t];}return (calc_sigmoid(value + thetas[0]));
}template<typename T>
int LogisticRegression<T>::store_model(const std::string& model) const
{std::ofstream file;file.open(model.c_str(), std::ios::binary);if (!file.is_open()) {fprintf(stderr, "open file fail: %s\n", model.c_str());return -1;}int length = thetas.size();file.write((char*)&length, sizeof(length));file.write((char*)thetas.data(), sizeof(T) * thetas.size());file.close();return 0;
}template<typename T>
T LogisticRegression<T>::calc_sigmoid(T x) const
{return ((T)1 / ((T)1 + exp(-x)));
}template<typename T>
T LogisticRegression<T>::norm(const std::vector<T>& v1, const std::vector<T>& v2) const
{CHECK(v1.size() == v2.size());T sum{ 0 };for (int i = 0; i < v1.size(); ++i) {T minus = v1[i] - v2[i];sum += (minus * minus);}return std::sqrt(sum);
}template class LogisticRegression<float>;
template class LogisticRegression<double>;} // namespace ANN#include "funset.hpp"
#include <iostream>
#include "perceptron.hpp"
#include "BP.hpp""
#include "CNN.hpp"
#include "linear_regression.hpp"
#include "naive_bayes_classifier.hpp"
#include "logistic_regression.hpp"
#include "common.hpp"
#include <opencv2/opencv.hpp>// ================================ logistic regression =====================
int test_logistic_regression_train()
{const std::string image_path{ "E:/GitCode/NN_Test/data/images/digit/handwriting_0_and_1/" };cv::Mat data, labels;for (int i = 1; i < 11; ++i) {const std::vector<std::string> label{ "0_", "1_" };for (const auto& value : label) {std::string name = std::to_string(i);name = image_path + value + name + ".jpg";cv::Mat image = cv::imread(name, 0);if (image.empty()) {fprintf(stderr, "read image fail: %s\n", name.c_str());return -1;}data.push_back(image.reshape(0, 1));}}data.convertTo(data, CV_32F);std::unique_ptr<float[]> tmp(new float[20]);for (int i = 0; i < 20; ++i) {if (i % 2 == 0) tmp[i] = 0.f;else tmp[i] = 1.f;}labels = cv::Mat(20, 1, CV_32FC1, tmp.get());ANN::LogisticRegression<float> lr;const float learning_rate{ 0.00001f };const int iterations{ 250 };int reg_kinds = lr.REG_DISABLE; //ANN::LogisticRegression<float>::REG_L1;int train_method = lr.MINI_BATCH; //ANN::LogisticRegression<float>::BATCH;int mini_batch_size = 5;int ret = lr.init((float*)data.data, (float*)labels.data, data.rows, data.cols/*,reg_kinds, learning_rate, iterations, train_method, mini_batch_size*/);if (ret != 0) {fprintf(stderr, "logistic regression init fail: %d\n", ret);return -1;}const std::string model{ "E:/GitCode/NN_Test/data/logistic_regression.model" };ret = lr.train(model);if (ret != 0) {fprintf(stderr, "logistic regression train fail: %d\n", ret);return -1;}return 0;
}int test_logistic_regression_predict()
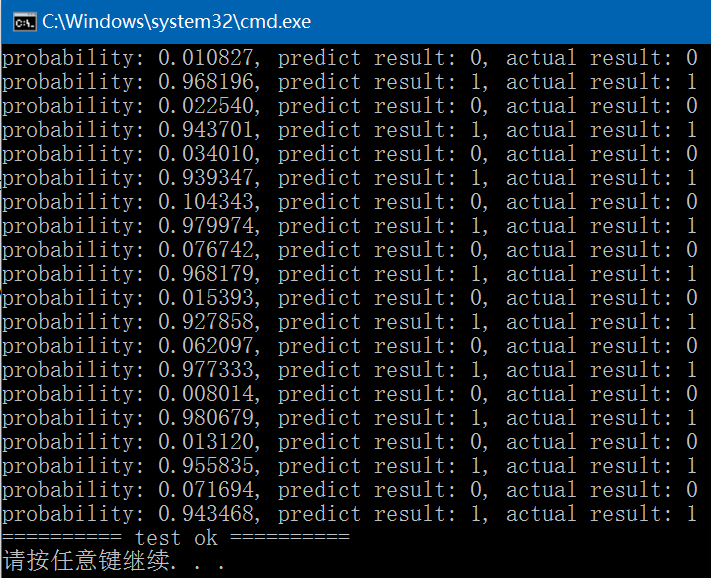
{const std::string image_path{ "E:/GitCode/NN_Test/data/images/digit/handwriting_0_and_1/" };cv::Mat data, labels, result;for (int i = 11; i < 21; ++i) {const std::vector<std::string> label{ "0_", "1_" };for (const auto& value : label) {std::string name = std::to_string(i);name = image_path + value + name + ".jpg";cv::Mat image = cv::imread(name, 0);if (image.empty()) {fprintf(stderr, "read image fail: %s\n", name.c_str());return -1;}data.push_back(image.reshape(0, 1));}}data.convertTo(data, CV_32F);std::unique_ptr<int[]> tmp(new int[20]);for (int i = 0; i < 20; ++i) {if (i % 2 == 0) tmp[i] = 0;else tmp[i] = 1;}labels = cv::Mat(20, 1, CV_32SC1, tmp.get());CHECK(data.rows == labels.rows);const std::string model{ "E:/GitCode/NN_Test/data/logistic_regression.model" };ANN::LogisticRegression<float> lr;int ret = lr.load_model(model);if (ret != 0) {fprintf(stderr, "load logistic regression model fail: %d\n", ret);return -1;}for (int i = 0; i < data.rows; ++i) {float probability = lr.predict((float*)(data.row(i).data), data.cols);fprintf(stdout, "probability: %.6f, ", probability);if (probability > 0.5) fprintf(stdout, "predict result: 1, ");else fprintf(stdout, "predict result: 0, ");fprintf(stdout, "actual result: %d\n", ((int*)(labels.row(i).data))[0]);}return 0;
}
相关文章:

CVPR 2019论文阅读:Libra R-CNN如何解决不平衡对检测性能的影响?
作者 | 路一直都在出品 | AI科技大本营(ID:rgznai100)Paper link:https://arxiv.org/pdf/1904.02701.pdfCode link:https://github.com/OceanPang/Libra_R-CNNAbstract在目标检测中,人们更关注的往往是模型结构&#x…

实现nginx上配置免费证书Let's Encrypt
Lets Encrypt 的免费证书有效期为三个月,不过可以免费续期,写一个脚本定期更新即可。 准备一台nginx 服务器 ,将以下三个附件上传到你的nginx服务器。 1、下载脚本文件,wget https://raw.githubusercontent.com/xdtianyu/scripts/…

深入解析Windows操作系统笔记——CH1概念和术语
1.概念和工具 本章主要介绍Windows操作系统的关键概念和术语 1.概念和工具... 1 1.1操作系统版本... 1 1.2基础概念和术语... 2 1.2.1Windows API2 1.2.2 服务、函数和例程... 3 1.2.3 进程、线程和作业... 4 1.2.3.1 进程... 4 1.2.3.2 线程... 4 1.2.3.3 虚拟地址描述符... 4…

C++/C++11中std::exception的使用
std::exception:标准异常类的基类,其类的声明在头文件<exception>中。所有标准库的异常类均继承于此类,因此通过引用类型可以捕获所有标准异常。 std::exception类定义了无参构造函数、拷贝构造函数、拷贝赋值运算符、一个虚析构函数和…

技术不错的程序员,为何面试却“屡战屡败”
为何很多有不少编程经验,技术能力不错的程序员,去心仪公司面试时却总是失败?至于失败的原因,可能很多人都没意识到过。01想要通关面试,千万别让数据结构拖了后腿很多公司,比如 BAT、Google、Facebook&#…
FastJson 转换 javaBean 时 null 值被忽略都问题
[toc] 问题 当 JavaeBean 中某个属性值为 null 时,转换为 JSONObject 对象或者 json 字符串时,该属性值被忽略。如何让不管值是否为 null,转化后该属性还存在,只是值为 null。 情况演示 class St {private String sid;private Str…
来玩Play框架07 静态文件
作者:Vamei 出处:http://www.cnblogs.com/vamei 欢迎转载,也请保留这段声明。谢谢! Play框架的主要功能是提供动态响应的内容。但一个网络项目中必然有大量的静态内容,比如图片、Javascript文件、CSS文件等。我下面介绍…

C++/C++11中std::runtime_error的使用
std::runtime_error:运行时错误异常类,只有在运行时才能检测到的错误,继承于std::exception,它的声明在头文件<stdexcept>中。std::runtime_error也用作几个运行时错误异常的基类,包括std::range_error(生成的结…

估值被砍700亿美元后,Waymo发重磅公开信:即将推出全自动驾驶打车服务
(图片源自 Waymo 官网)编译 | 夕颜出品 | AI科技大本营(ID:rgznai100)近日,据 Reddit 盛传的一封电子邮件副本显示,Alphabet 旗下的自动驾驶汽车公司 Waymo 已经向其自动驾驶服务的用户发送了一封电子邮件&…
Swoft 2 Beta 发布,基于 Swoole 的云原生协程框架
Swoft 是首个基于 Swoole 原生协程的框架,从开发到发布据今已有2年多。 1.x 发布以来,已有大量的开发人员和企业使用,得到了大家的认可。从去年11月份开始,将近半年的时间从零开始,底层吸取之前经验,基于 S…
Linux中源码包的管理
什么是开放源码,编译程序和可执行文件开放源码:就是程序代码,写给人类看的程序语言,但机器不认识,所以无法执行;编译程序:将程序代码转译成为机器看得懂的语言;可执行文件:经过编译程序变成二进制程序后,机…
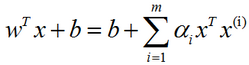
支持向量机(SVM)简介
支持向量机(support vector machine, SVM):是监督学习中最有影响力的方法之一。类似于逻辑回归,这个模型也是基于线性函数wTxb的。不同于逻辑回归的是,支持向量机不输出概率,只输出类别。当wTxb为正时,支持向量机预测属…

首届中文NL2SQL挑战赛:千支队伍参赛,国防科大夺冠
(图片由AI科技大本营付费下载自视觉中国)整理 | Jane出品 | AI科技大本营(ID:rgznai100)【导语】10月12日,追一科技主办的首届中文NL2SQL挑战赛在激烈的决赛中落下帷幕,冠军由国防科技大学学生组…
怎么使用CAD编辑器来打开图纸中的所有图层
在CAD绘图中,建筑设计师们不仅要对CAD图纸进行编辑,还要对CAD图纸进行查看,一张图纸中是有许多图层的,那在查看的过程中有的时候把其他的图层进行隐藏了,那如果想要把隐藏的CAD图层进行打开要怎么操作?如何…

域名年龄-SEO搜索引擎优化
为什么80%的码农都做不了架构师?>>> 域名年龄-SEO搜索引擎优化 在我们创建一个新的网站时,我们首先考虑到的是去注册一个新的域名。 有时发现我们 要注册的域名已经被注册了,于是就有两种方式: 一、重新注册另外的…

log库spdlog简介及使用
spdlog是一个开源的、快速的、仅有头文件的C11 日志库,code地址在 https://github.com/gabime/spdlog ,目前最新的发布版本为0.14.0。它提供了向流、标准输出、文件、系统日志、调试器等目标输出日志的能力。它支持的平台包括Windows、Linux、Mac、Andro…

多模态人物识别技术及其在视频场景中的应用 | CSDN技术公开课
不用倍速播放,还有什么功能可以让你高效追剧?爱奇艺的「只看TA」了解一下?而这个功能背后离不开多模态人物识别技术的支撑。识别视频中的人物涉及哪些信息?只有人脸识别就足够了吗?其实不然,这样一个看似简…
研究人员测试27个黑客服务 结果仅三个完成任务
现代电子邮件帐户不仅是一个电子邮件地址,它还是人们在网络上的身份的基础,可用于申请各种网络服务或重置服务密码,以便持有电子邮件的黑客服务帐户很受欢迎,为了了解这些服务的功能,谷歌和加州大学圣地亚哥分校的研究…
CIF、QCIF
分辨率: 每个像素的存储方式都是YUV QQCIF:88*72 QCIF:176*144 CIF:352*288 2CIF:704*288 DCIF:584*384 4CIF:704*576 QCIF: QCIF: Quarter Common Intermediate Format 英文缩写 qcif 英文全称 Quarter Common Intermediate Format 中文解释 四分之一通…
OpenCV3.3中支持向量机(Support Vector Machines, SVM)实现简介及使用
OpenCV 3.3中给出了支持向量机(Support Vector Machines)的实现,即cv::ml::SVM类,此类的声明在include/opencv2/ml.hpp文件中,实现在modules/ml/src/svm.cpp文件中,它既支持两分类,也支持多分类,还支持回归…
Facebook发布Detectron2,下一个万星目标检测新框架
作者 | CV君来源 | 我爱计算机视觉(ID:aicvml)Detectron是Facebook于2018年发布的专注于目标检测的深度学习框架,基于Caffe2深度学习框架,实现了众多state-of-the-art算法,其与商汤-香港中文大学MMLab实验室…
include和require的区别
细节决定成败! 1.引用文件方式 对include()来说,在include()执行时文件每次都要进行读取和评估;而对于require()来说,文件只处理一次(实际上,文件内容替换了require()语句)。这就意味着如果有包…
libsvm库简介及使用
libsvm是基于支持向量机(support vector machine, SVM)实现的开源库,由台湾大学林智仁(Chih-Jen Lin)教授等开发,它主要用于分类(支持二分类和多分类)和回归。它的License是BSD-3-Clause,最新发布版本是v322。libsvm具有操作简单、易于使用、…
Cron 表达式极速参考
Cron表达式: * * * * * * *这些星号由左到右按顺序代表 : [秒] [分] [小时] [日] [月] [周] [年] 序号说明 是否必填 允许填写的值 允许的通配符1 秒 是 0-59 , - * /2 分 是 0-59…

刘群:华为诺亚方舟NLP预训练模型工作的研究与应用 | AI ProCon 2019
演讲嘉宾 | 刘群(华为诺亚方舟实验首席科学家)编辑 | Jane出品 | AI科技大本营(ID:rgznai100)预训练语言模型对自然语言处理领域产生了非常大的影响,在近期由CSDN主办的 AI ProCon 2019 上,自然…

NuGet 无法连接到远程服务器-解决方法
一、 Entity Framework以下简称EF 安装EF4.3的步骤是首先安装VS扩展 NuGet,然后再使用NuGet安装EF程序包 安装完NuGet就可以安装EF了,有两种方式可以安装EF: 1.使用命令 install-package EntityFramework -Pre 但出现如下错误: 2.使用可视化工…

Facebook开源模型可解释库Captum,这次改模型有依据了
作者 | Narine Kokhlikyan, Vivek Miglani, Edward Wang, Orion Reblitz-Richardson译者 | Rachel出品 | AI科技大本营(ID:rgznai100)【导读】前脚 TF 2.0 刚发布,在 PyTorch 开发者大会首日也携 PyTorch1.3 版本而来。除此之外&a…
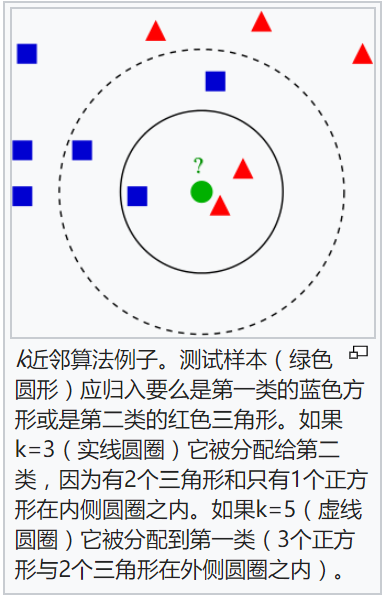
K-最近邻法(KNN)简介
K-最近邻法(K-Nearest Neighbor, KNN)最初由Cover和Hart于1968年提出,是一个在理论上比较成熟的分类算法。KNN是一类可用于分类或回归的技术。作为一个非参数学习算法,K-最近邻并不局限于固定数目的参数。我们通常认为K-最近邻算法没有任何参数ÿ…
demo17 clean-webpack-plugin (清除模式)
1.为什么需要自动清除 dist 文件夹 在之前的 demo 中,webpack 打包后会在根目录下自动创建 dist 目录,并且把生成的文件输出到 dist 下。 当配置的输出包名含有 [hash] 时,hash值会随着文件内容的改变而改变。 因此,我们需要在下一…
c语言-01背包问题
01背包问题 问题:有N件物品和一个容量为V的背包。第i件物品的费用是c[i],价值是w[i]。求解将哪些物品装入背包可使价值总和最大。 分析: 这是最基础的背包问题,特点是:每种物品仅有一件,可以选择放或不放。…