libsvm库简介及使用
libsvm是基于支持向量机(support vector machine, SVM)实现的开源库,由台湾大学林智仁(Chih-Jen Lin)教授等开发,它主要用于分类(支持二分类和多分类)和回归。它的License是BSD-3-Clause,最新发布版本是v322。libsvm具有操作简单、易于使用、快速有效、且对SVM所涉及的参数调节相对较少的特点。Code地址: https://github.com/cjlin1/libsvm
libsvm直接支持的开发语言包括:C++、java、matlab、python。C++主要包括两个文件,一个是头文件svm.h,一个是实现文件svm.cpp,将这两个文件加入到工程中就可以使用libsvm了。
在windows平台下,可以直接使用libsvm/windows目录下已经编译好的执行文件。
关于支持向量机的基础介绍可以参考: http://blog.csdn.net/fengbingchun/article/details/78326704
libsvm中支持的svm类型包括:C-SVC(multi-class classification)、nu-SVC(multi-class classification)、one-class SVM、epsilon-SVR(regression)、nu-SVR(regression);支持的kernel类型包括:linear(u’*v)、polynomial((gamma*u’*v+coef0)^degree)、radial basis function(径向基, exp(-gamma*|u-v|^2))、sigmoid(tanh(gamma*u’*v+coef0))、precomputed kernel(kernel values in training_set_file)。libsvm中需要的参数虽然较多,但是绝大多数都有其默认值。
libsvm中对数据集进行缩放的目的在于:避免一些特征值范围过大而另一些特征值范围过小;避免在训练时为了计算核函数而计算内积的时候引起数值计算的困难。通常将数据缩放到[-1, 1]或[0, 1]之间。
libsvm使用一般步骤:
(1)、按照libsvm所要求的格式准备数据集;
(2)、对数据进行简单的缩放操作;
(3)、考虑选用RBF(radial basis function)核参数;
(4)、如果选用RBF,通过libsvm/tools/grid.py采用交叉验证获取最佳参数C与gamma;
(5)、采用最佳参数C与g对整个训练集进行训练获取支持向量机模型;
(6)、利用获取的模型进行测试与预测。
测试代码执行步骤:
(1)、训练和测试数据采用UCI/Liver-disorders( https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary.html#liver-disorders ):二分类、训练样本为145、测试样本为200、特征长度为5,分别保存为liver-disorders_train.txt、liver-disorders_predict.txt;
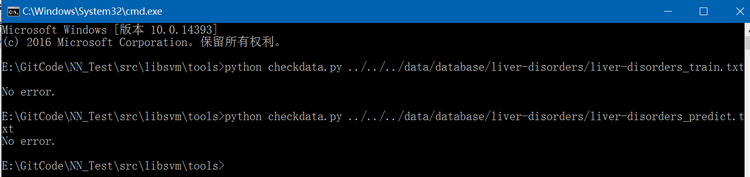
(2)、通过libsvm/tools/checkdata.py来验证liver-disorders数据集是否满足libsvm所要求的数据格式(注:在windows下,此两个.txt文件编码格式要由utf-8改为ansi,否则执行checkdata.py会有errror),执行结果如下:
(3)、调用test_libsvm_scale函数对liver-disorders_train.txt进行缩放操作,并保存scale后的数据liver-disorders_train_scale.txt,并通过checkdata.py验证数据格式;
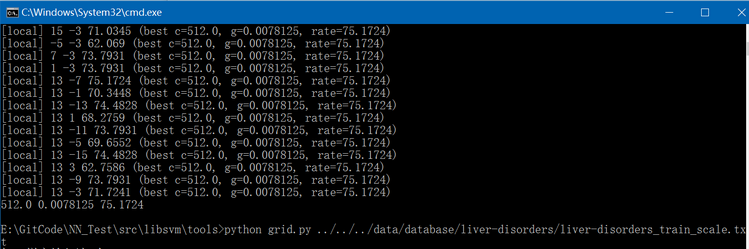
(4)、通过liver-disorders_train_scale.txt文件调用libsvm/tools/grid.py生成最优参数C和gamma,执行结果如下:
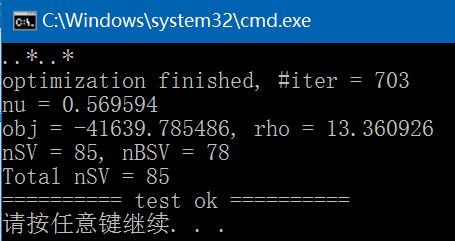
(5)、train,生成svm.model文件,执行结果如下,与libsvm/windows/svm-train.exe执行结果完全一致:
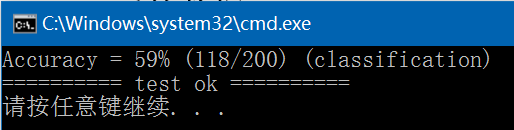
(6)、predict,执行结果如下,与libsvm/windows/svm-predict.exe执行结果完全一致:
以下二分类测试代码是参考libsvm中的svm-scale.c、svm-train.c、svm-predict.c:
#include "libsvm.hpp"
#include <iostream>
#include <limits>
#include <algorithm>
#include <fstream>
#include "svm.h"
#include "common.hpp"#define Malloc(type,n) (type *)malloc((n)*sizeof(type))static char* readline(FILE* input, int& max_line_len, char** line)
{if (fgets(*line, max_line_len, input) == nullptr) return nullptr;int len{ 0 };while (strrchr(*line, '\n') == nullptr) {max_line_len *= 2;*line = (char *)realloc(*line, max_line_len);len = (int)strlen(*line);if (fgets(*line + len, max_line_len - len, input) == nullptr) break;}return *line;
}static void output(const double* feature_max, const double* feature_min, double lower, double upper, long int& new_num_nonzeros, int index, double value, std::ofstream& out_file)
{/* skip single-valued attribute */if (feature_max[index] == feature_min[index]) return;if (value == feature_min[index]) value = lower;else if (value == feature_max[index]) value = upper;else value = lower + (upper - lower) * (value - feature_min[index]) / (feature_max[index] - feature_min[index]);if (value != 0) {//fprintf(stdout, "%d:%g ", index, value);out_file << index << ":" << value<<" ";new_num_nonzeros++;}
}int test_libsvm_scale(const char* input_file_name, const char* output_file_name)
{// reference: libsvm/svm-scale.cconst double lower{ -1. }, upper{ 1. }; // lower: x scaling lower limit(default -1); upper: x scaling upper limit(default +1)const double y_lower{ 0. }, y_upper{ 1. }, y_scaling{ 0. }; // y scaling limits (default: no y scaling)double y_max{ std::numeric_limits<double>::max() };double y_min{ std::numeric_limits<double>::lowest() };char* line{ nullptr };int max_line_len{ 1024 };double* feature_max{ nullptr };double* feature_min{ nullptr };int max_index{ 0 }, min_index{ 0 }, index{ 0 };long int num_nonzeros{ 0 }, new_num_nonzeros{ 0 };FILE* fp = fopen(input_file_name, "r");CHECK(nullptr != fp);line = (char *)malloc(max_line_len * sizeof(char));#define SKIP_TARGET \while (isspace(*p)) ++p; \while (!isspace(*p)) ++p;#define SKIP_ELEMENT \while (*p != ':') ++p; \++p; \while (isspace(*p)) ++p; \while (*p && !isspace(*p)) ++p;// pass 1: find out max index of attributesmax_index = 0;min_index = 1;while (readline(fp, max_line_len, &line) != nullptr) {char* p = line;SKIP_TARGETwhile (sscanf(p, "%d:%*f", &index) == 1) {max_index = std::max(max_index, index);min_index = std::min(min_index, index);SKIP_ELEMENTnum_nonzeros++;}}CHECK(min_index >= 1);rewind(fp);feature_max = (double *)malloc((max_index + 1)* sizeof(double));feature_min = (double *)malloc((max_index + 1)* sizeof(double));CHECK(feature_max != nullptr && feature_min != nullptr);for (int i = 0; i <= max_index; ++i) {feature_max[i] = std::numeric_limits<double>::lowest();feature_min[i] = std::numeric_limits<double>::max();}// pass 2: find out min/max valuewhile (readline(fp, max_line_len, &line) != nullptr) {char *p = line;int next_index = 1;double target;double value;CHECK(sscanf(p, "%lf", &target) == 1);y_max = std::max(y_max, target);y_min = std::min(y_min, target);SKIP_TARGETwhile (sscanf(p, "%d:%lf", &index, &value) == 2) {for (int i = next_index; i<index; ++i) {feature_max[i] = std::max(feature_max[i], 0.);feature_min[i] = std::min(feature_min[i], 0.);}feature_max[index] = std::max(feature_max[index], value);feature_min[index] = std::min(feature_min[index], value);SKIP_ELEMENTnext_index = index + 1;}for (int i = next_index; i <= max_index; ++i) {feature_max[i] = std::max(feature_max[i], 0.);feature_min[i] = std::min(feature_min[i], 0.);}}rewind(fp);std::ofstream out_file(output_file_name);CHECK(out_file);// pass 3: scalewhile (readline(fp, max_line_len, &line) != nullptr) {char *p = line;int next_index = 1;double target;double value;CHECK(sscanf(p, "%lf", &target) == 1);//fprintf(stdout, "%g ", target);out_file << target << " ";SKIP_TARGETwhile (sscanf(p, "%d:%lf", &index, &value) == 2) {for (int i = next_index; i<index; ++i)output(feature_max, feature_min, lower, upper, new_num_nonzeros, i, 0, out_file);output(feature_max, feature_min, lower, upper, new_num_nonzeros, index, value, out_file);SKIP_ELEMENTnext_index = index + 1;}for (int i = next_index; i <= max_index; ++i)output(feature_max, feature_min, lower, upper, new_num_nonzeros, i, 0, out_file);//fprintf(stdout, "\n");out_file << std::endl;}CHECK(new_num_nonzeros <= num_nonzeros);free(line);free(feature_max);free(feature_min);fclose(fp);out_file.close();return 0;
}static int read_problem(const char* input_file_name, svm_problem& prob, int& max_line_len, svm_parameter& param, char** line, svm_node** x_space)
{int max_index, inst_max_index;size_t elements, j;char* endptr;char *idx, *val, *label;FILE* fp = fopen(input_file_name, "r");CHECK(fp != nullptr);prob.l = 0;elements = 0;max_line_len = 1024;*line = Malloc(char, max_line_len);while (readline(fp, max_line_len, line) != nullptr) {char *p = strtok(*line, " \t"); // label// featureswhile (1) {p = strtok(nullptr, " \t");if (p == nullptr || *p == '\n') // check '\n' as ' ' may be after the last featurebreak;++elements;}++elements;++prob.l;}rewind(fp);prob.y = Malloc(double, prob.l);prob.x = Malloc(struct svm_node *, prob.l);*x_space = Malloc(struct svm_node, elements);max_index = 0;j = 0;for (int i = 0; i<prob.l; i++) {inst_max_index = -1; // strtol gives 0 if wrong format, and precomputed kernel has <index> start from 0readline(fp, max_line_len, line);prob.x[i] = &(*x_space)[j];label = strtok(*line, " \t\n");CHECK(label != nullptr); // empty lineprob.y[i] = strtod(label, &endptr);CHECK(!(endptr == label || *endptr != '\0'));while (1) {idx = strtok(nullptr, ":");val = strtok(nullptr, " \t");if (val == nullptr) break;errno = 0;(*x_space)[j].index = (int)strtol(idx, &endptr, 10);if (endptr == idx || errno != 0 || *endptr != '\0' || (*x_space)[j].index <= inst_max_index) {CHECK(0);} else {inst_max_index = (*x_space)[j].index;}errno = 0;(*x_space)[j].value = strtod(val, &endptr);if (endptr == val || errno != 0 || (*endptr != '\0' && !isspace(*endptr))) CHECK(0);++j;}if (inst_max_index > max_index) max_index = inst_max_index;(*x_space)[j++].index = -1;}if (param.gamma == 0 && max_index > 0) param.gamma = 1.0 / max_index;if (param.kernel_type == PRECOMPUTED) {for (int i = 0; i<prob.l; i++) {CHECK(prob.x[i][0].index == 0);if ((int)prob.x[i][0].value <= 0 || (int)prob.x[i][0].value > max_index) {CHECK(0);}}}fclose(fp);return 0;
}int test_libsvm_two_classification_train()
{// reference: libsvm/svm-train.cconst std::string input_file_name{ "E:/GitCode/NN_Test/data/database/liver-disorders/liver-disorders_train.txt" },output_file_name{ "E:/GitCode/NN_Test/data/database/liver-disorders/liver-disorders_train_scale.txt" },svm_model{"E:/GitCode/NN_Test/data/svm.model"};CHECK(0 == test_libsvm_scale(input_file_name.c_str(), output_file_name.c_str())); // data scalestruct svm_parameter param = {};struct svm_problem prob = {};struct svm_model* model = nullptr;struct svm_node* x_space = nullptr;int cross_validation{ 0 };int nr_fold{0};char* line = nullptr;int max_line_len{0};param = { C_SVC, RBF, 3, 0.0078125, 0., 100, 1e-3, 512., 0, nullptr, nullptr, 0.5, 0.1, 1, 0 };CHECK(read_problem(output_file_name.c_str(), prob, max_line_len, param, &line, &x_space) == 0);CHECK(svm_check_parameter(&prob, ¶m) == nullptr);model = svm_train(&prob, ¶m);CHECK(svm_save_model(svm_model.c_str(), model) == 0);svm_free_and_destroy_model(&model);svm_destroy_param(¶m);free(prob.y);free(prob.x);free(x_space);free(line);return 0;
}static int predict(FILE* input, FILE* output, const svm_model* model, int& max_line_len, char** line, int& max_nr_attr, svm_node** x)
{int correct = 0;int total = 0;double error = 0;double sump = 0, sumt = 0, sumpp = 0, sumtt = 0, sumpt = 0;int svm_type = svm_get_svm_type(model);int nr_class = svm_get_nr_class(model);double *prob_estimates = nullptr;int j;max_line_len = 1024;*line = (char *)malloc(max_line_len*sizeof(char));while (readline(input, max_line_len, line) != nullptr) {int i = 0;double target_label, predict_label;char *idx, *val, *label, *endptr;int inst_max_index = -1; // strtol gives 0 if wrong format, and precomputed kernel has <index> start from 0label = strtok(*line, " \t\n");CHECK(label != nullptr); // empty linetarget_label = strtod(label, &endptr);CHECK(!(endptr == label || *endptr != '\0'));while (1) {if (i >= max_nr_attr - 1) { // need one more for index = -1max_nr_attr *= 2;*x = (struct svm_node *) realloc(*x, max_nr_attr*sizeof(struct svm_node));}idx = strtok(nullptr, ":");val = strtok(nullptr, " \t");if (val == nullptr) break;errno = 0;(*x)[i].index = (int)strtol(idx, &endptr, 10);CHECK(!(endptr == idx || errno != 0 || *endptr != '\0' || (*x)[i].index <= inst_max_index));inst_max_index = (*x)[i].index;errno = 0;(*x)[i].value = strtod(val, &endptr);CHECK(!(endptr == val || errno != 0 || (*endptr != '\0' && !isspace(*endptr))));++i;}(*x)[i].index = -1;predict_label = svm_predict(model, *x);fprintf(output, "%g\n", predict_label);if (predict_label == target_label) ++correct;error += (predict_label - target_label)*(predict_label - target_label);sump += predict_label;sumt += target_label;sumpp += predict_label*predict_label;sumtt += target_label*target_label;sumpt += predict_label*target_label;++total;}fprintf(stdout, "Accuracy = %g%% (%d/%d) (classification)\n", (double)correct / total * 100, correct, total);return 0;
}int test_libsvm_two_classification_predict()
{// reference: libsvm/svm-predict.cconst std::string input_file_name{ "E:/GitCode/NN_Test/data/database/liver-disorders/liver-disorders_predict.txt" },scale_file_name{ "E:/GitCode/NN_Test/data/database/liver-disorders/liver-disorders_predict_scale.txt" },svm_model{ "E:/GitCode/NN_Test/data/svm.model" },predict_result_file_name{ "E:/GitCode/NN_Test/data/svm_predict_result.txt" };CHECK(0 == test_libsvm_scale(input_file_name.c_str(), scale_file_name.c_str())); // data scalestruct svm_node* x = nullptr;int max_nr_attr = 64;struct svm_model* model = nullptr;int predict_probability = 0;char* line = nullptr;int max_line_len = 0;FILE* input = fopen(scale_file_name.c_str(), "r");CHECK(input != nullptr);FILE* output = fopen(predict_result_file_name.c_str(), "w");CHECK(output != nullptr);CHECK((model = svm_load_model(svm_model.c_str())) != nullptr);x = (struct svm_node *) malloc(max_nr_attr*sizeof(struct svm_node));CHECK(svm_check_probability_model(model) == 0);predict(input, output, model, max_line_len, &line, max_nr_attr, &x);svm_free_and_destroy_model(&model);free(x);free(line);fclose(input);fclose(output);return 0;
}GitHub: https://github.com/fengbingchun/NN_Test
相关文章:

Cron 表达式极速参考
Cron表达式: * * * * * * *这些星号由左到右按顺序代表 : [秒] [分] [小时] [日] [月] [周] [年] 序号说明 是否必填 允许填写的值 允许的通配符1 秒 是 0-59 , - * /2 分 是 0-59…

刘群:华为诺亚方舟NLP预训练模型工作的研究与应用 | AI ProCon 2019
演讲嘉宾 | 刘群(华为诺亚方舟实验首席科学家)编辑 | Jane出品 | AI科技大本营(ID:rgznai100)预训练语言模型对自然语言处理领域产生了非常大的影响,在近期由CSDN主办的 AI ProCon 2019 上,自然…

NuGet 无法连接到远程服务器-解决方法
一、 Entity Framework以下简称EF 安装EF4.3的步骤是首先安装VS扩展 NuGet,然后再使用NuGet安装EF程序包 安装完NuGet就可以安装EF了,有两种方式可以安装EF: 1.使用命令 install-package EntityFramework -Pre 但出现如下错误: 2.使用可视化工…

Facebook开源模型可解释库Captum,这次改模型有依据了
作者 | Narine Kokhlikyan, Vivek Miglani, Edward Wang, Orion Reblitz-Richardson译者 | Rachel出品 | AI科技大本营(ID:rgznai100)【导读】前脚 TF 2.0 刚发布,在 PyTorch 开发者大会首日也携 PyTorch1.3 版本而来。除此之外&a…
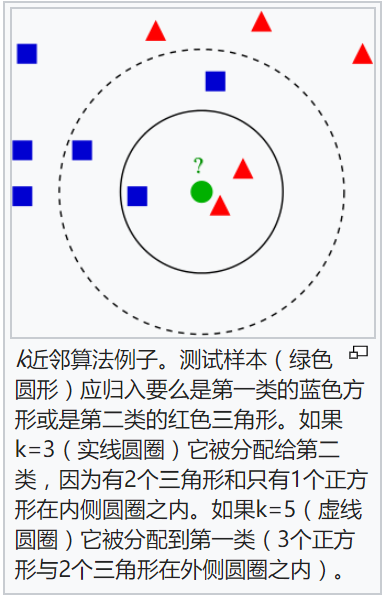
K-最近邻法(KNN)简介
K-最近邻法(K-Nearest Neighbor, KNN)最初由Cover和Hart于1968年提出,是一个在理论上比较成熟的分类算法。KNN是一类可用于分类或回归的技术。作为一个非参数学习算法,K-最近邻并不局限于固定数目的参数。我们通常认为K-最近邻算法没有任何参数ÿ…
demo17 clean-webpack-plugin (清除模式)
1.为什么需要自动清除 dist 文件夹 在之前的 demo 中,webpack 打包后会在根目录下自动创建 dist 目录,并且把生成的文件输出到 dist 下。 当配置的输出包名含有 [hash] 时,hash值会随着文件内容的改变而改变。 因此,我们需要在下一…
c语言-01背包问题
01背包问题 问题:有N件物品和一个容量为V的背包。第i件物品的费用是c[i],价值是w[i]。求解将哪些物品装入背包可使价值总和最大。 分析: 这是最基础的背包问题,特点是:每种物品仅有一件,可以选择放或不放。…

OpenCV3.3中 K-最近邻法(KNN)接口简介及使用
OpenCV 3.3中给出了K-最近邻(KNN)算法的实现,即cv::ml::Knearest类,此类的声明在include/opecv2/ml.hpp文件中,实现在modules/ml/src/knearest.cpp文件中。其中:(1)、cv::ml::Knearest类:继承自cv::ml::StateModel&…

华为于璠:新一代AI开源计算框架MindSpore的前世与今生 | AI ProCon 2019
演讲嘉宾 | 于璠(华为MindSpore资深架构师)编辑 | 刘静出品 | AI科技大本营(ID:rgznai100)9月,2019中国AI开发者大会(AI ProCon 2019)在北京举行。在AI开源技术专题中,华为MindSpore…
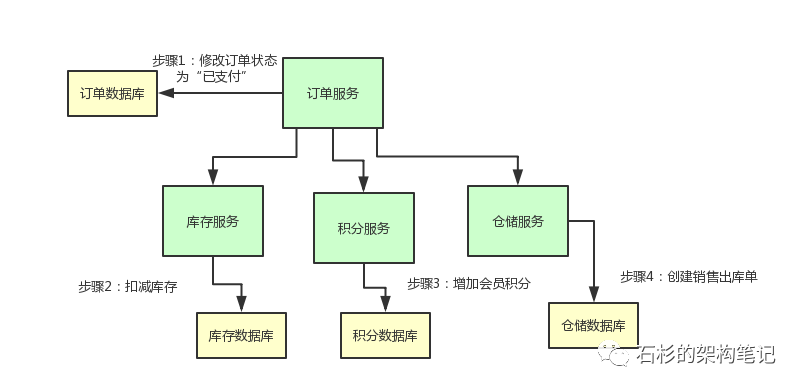
TCC分布式事务的实现原理
目录 一、写在前面 二、业务场景介绍 三、进一步思考 四、落地实现TCC分布式事务 (1)TCC实现阶段一:Try (2)TCC实现阶段二:Confirm (3)TCC实现阶段三:Cancel 五、总结与思考 一、写在前面 之前网上看到很多写分布式事务的文章,不过…
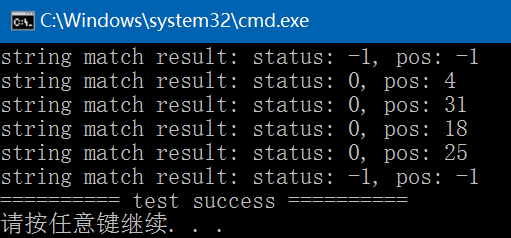
Brute Force算法介绍及C++实现
字符串的模式匹配操作可以通过Brute Force算法来实现。字符串匹配操作即是查看S串(目标串或主串)中是否含有T串(模式串或子串),如果在主串中查找到了子串,则模式匹配成功,返回模式串中的第一个字符在主串中的位置;如果未找到&…
使用Go内置库实现简易httpbin功能
简介 通过学习「Go语言圣经」的入门部分,了解到 go 内置库里提供了一个简单的 http 功能。于是想模拟下httpbin[1]的 get 方法显示 header 头信息的功能来练手。 本人 Go 初学小白,为了练习只是简单的实现了请求 header 的 JSON 格式展示,跟 …

Google图嵌入工业界最新大招,高效解决训练大规模深度图卷积神经网络问题
导读:本文主要介绍Google发表在KDD 2019的图嵌入工业界最新论文,提出Cluster-GCN,高效解决工业界训练大规模深度图卷积神经网络问题,性能大幅提升基础上依靠可训练更深层网络达到SOTA效果,并开源了源代码。作者 | yyl4…

经典树型表结构之SORT_NO
为什么80%的码农都做不了架构师?>>> 在以下情况需要对经典树型表的sort_no进行重排序:1、插入节点(插入子树),需调整节点后所有sort_no;2、删除节点(删除子树),需调整节…
Ubuntu14.04上安装TensorRT 2.1操作步骤
在Ubuntu14.04 上安装TensorRT2.1有两种方法:(1)、通过.deb直接安装;(2)、通过Tar文件安装。这里通过Tar文件安装。安装步骤:1. 安装CUDA 8.0,可参考: http://blog.csdn.net/fengbingchun/article/details/53840684 ;…

学会这门编程知识,可能决定你能进什么样的企业
对于程序员来讲,很多技术真正掌握之后,都能影响甚至说改变一个人的命运,比如:python、AI、DL、算法等等,但是如果只让你选择其中的一项基础知识,你会选择哪个呢?如果是我, 我会选——…
雷林鹏分享:MySQL 及 SQL 注入
MySQL 及 SQL 注入 如果您通过网页获取用户输入的数据并将其插入一个MySQL数据库,那么就有可能发生SQL注入安全的问题。 本章节将为大家介绍如何防止SQL注入,并通过脚本来过滤SQL中注入的字符。 所谓SQL注入,就是通过把SQL命令插入到Web表单递…
dedecms网站文章内容按自定义排序的方法
标签dede:arclist的排序是通过orderby来指定的,如下: {dede:arclist orderby’排序字段’ } {/dede:arclist} orderby’sortrank’ 文档排序方式 orderby’hot’ 或 orderby’click’ 表示按点击数排列 orderby’sortrank’ 或 orderby’pubdate’ 按…

有了这套模板,再不担心刷不动LeetCode了
(图片下载自视觉中国)作者 | 李威来源 | https://www.liwei.party/整理 | 五分钟学算法(ID: CXYxiaowu)正文下面的动画以 「力扣」第 704 题:二分查找 为例,展示了使用这个模板编写二分查找法的一般流程。b…
一线互联网技术:Java工程师架构知识系统化汇总,面完45K!
根据高端招聘平台100 offer发布的Java人才盘点报告,在过去的2018年,Java仍然是最流行、招聘供需量最大的技术语言。在此基础上,互联网行业针对 Java 开发的招聘需求,也是近年技术类岗位供需量最大,且变化最稳定的。企业…
C++中局部类的使用
类可以定义在某个函数的内部,我们称这样的类为局部类(local class)。局部类定义的类型只在定义它的作用域内可见。和嵌套类不同,局部类的成员受到严格控制。局部类的所有成员(包括函数在内)都必须完整定义在类的内部。因此,局部类的作用与嵌套…
按键驱动的恩恩怨怨之概述
转载请注明出处:http://blog.csdn.net/ruoyunliufeng/article/details/23946487 研究按键驱动已经有几天了,尽管是0基础的驱动,可是当中包括的知识确实不少。接下来的几篇文章我会分别从浅入深的分析按键驱动。希望能对大家有所帮助。因为屌…
C++中嵌套类的使用
一个类可以定义在另一个类的内部,前者称为嵌套类(nested class)或嵌套类型(nested type)。嵌套类常用于定义作为实现部分的类。嵌套类可用于隐藏实现细节。嵌套类是一个独立的类,与外层类基本没什么关系。特别是,外层类的对象和嵌套类的对象是…
挑战弱监督学习的三大热门问题 AutoWSL2019挑战赛正式开赛
AutoWSL2019作为11月17-19日亚洲机器学习大会(ACML)主会议竞赛单元之一,由第四范式、ChaLearn、RIKEN和微软联合举办,其中竞赛分享和颁奖将与大会WSL-Workshop共同举办。据悉,AutoWSL是继AutoCV、AutoCV2、AutoNLP、Au…
数据连接池的工作机制是什么?
以典型的数据库连接池为例: 首先普通的数据库访问是这样的:程序和数据库建立连接,发送数据操作的指令,完成后断开连接。等下一次请求的时候重复这个过程,即每个请求都需要和数据库建立连接和断开连接,这样当…
apkplug插件托管服务简化与简介-05
2019独角兽企业重金招聘Python工程师标准>>> 本文基于TuoClondService1.1.0讲解 apkplug插件托管服务是提供给开发者一个远程发布插件的管理平台,但v1.0.0版本接口调用有些复杂我们在v1.1.0版本中着重对其进行了简化 与封装,使开发者能更简…

SpringBoot-JPA入门
SpringBoot-JPA入门 JPA就是Spring集成了hibernate感觉。 注解,方法仓库(顾名思义的方法,封装好了,还有自定义的方法)。 案例: spring:datasource:url: jdbc:mysql://localhost:3306/springboot?useUnicodetrue&c…
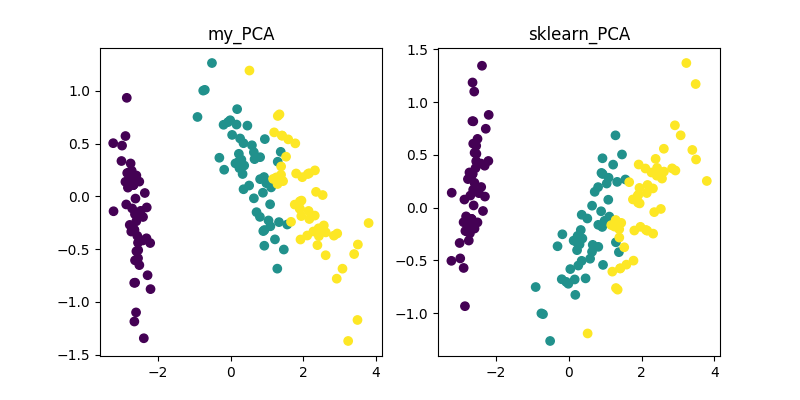
PCA、LDA、MDS、LLE、TSNE等降维算法的Python实现
整理 | 夕颜出品 | AI科技大本营(ID:rgznai100)【导读】网上关于各种降维算法的资料参差不齐,但大部分不提供源代码。近日,有人在 GitHub 上整理了一些经典降维算法的 Demo(Python)集合,同时给出了参考资料的链接。PCA…
C++11中enum class的使用
枚举类型(enumeration)使我们可以将一组整型常量组织在一起。和类一样,每个枚举类型定义了一种新的类型。枚举属于字面值常量类型。 C包含两种枚举:限定作用域的和不限定作用域的。这里主要介绍限定作用域的。不限定作用域的使用可以参考: ht…
Windows下Mysql主从配置(Mysql5.5)
主数据库IP:192.168.3.169从数据库IP:192.168.3.34主数据库配置my.inin:在[mysqld]下添加配置数据:server-id1 #配一个唯一的ID编号,1至32。log-binmysql-bin #二进制文件存放路径#设置要进行或不要进行主从复制的数据库名,同…