华为于璠:新一代AI开源计算框架MindSpore的前世与今生 | AI ProCon 2019
演讲嘉宾 | 于璠(华为MindSpore资深架构师)
编辑 | 刘静
出品 | AI科技大本营(ID:rgznai100)
9月,2019中国AI开发者大会(AI ProCon 2019)在北京举行。在AI开源技术专题中,华为MindSpore资深架构师于璠发表了《MindSpore创新技术介绍》主题演讲。
AI从行业研究到场景应用存在着巨大鸿沟,开发门槛高、运营成本高、部署时间长都是显而易见的业界挑战。因此,新编程范式、新执行模式、新协作方式的技术创新,都在促使着MindSpore跨越应用鸿沟,助力普惠AI。
在演讲中,于璠详细介绍了新一代AI开源计算框架MindSpore的设计理念:第一,新编程范式,AI算法即代码,降低了AI开发门槛;第二,新执行模式,Ascend Natave的执行引擎;第三,全场景按需协同,实现了更好的资源效率和隐私保护。

以下为于璠演讲内容实录,AI科技大本营整理(ID:rgznai100):
我在华为是做全场景AI计算框架的架构师,我们计算框架的名字是MindSpore,这个MindSpore英文的意思是“思想的包子”。大家也许听过华为起了一堆山海经神兽的名字,包括昆仑、麒麟等等,但最后我们还是采取了这个英文名字。
我是计算框架的架构师以及创新技术的负责人,这次的分享主要分三大部分:第一,华为AI的整体战略;第二,计算框架的设计理念、意欲解决的问题以及达到的效果;第三,讲讲其中的关键技术。
◆
精彩推荐
◆

推荐阅读
刘群:华为诺亚方舟NLP预训练模型工作的研究与应用 | AI ProCon 2019
估值被砍700亿美元后,Waymo发重磅公开信:即将推出全自动驾驶打车服务
首届中文NL2SQL挑战赛:千支队伍参赛,国防科大夺冠
图灵奖得主Bengio再次警示:可解释因果关系是深度学习发展的当务之急
技术领域有哪些接地气又好玩的应用?
Python新工具:用三行代码提取PDF表格数据
国产嵌入式操作系统发展思考
2019 年诺贝尔物理学奖揭晓!三得主让宇宙“彻底改观”
公链故事难再续?

你点的每个“在看”,我都认真当成了AI
相关文章:
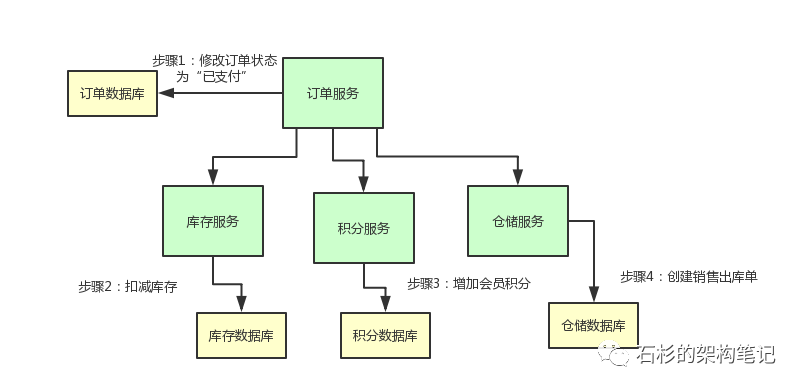
TCC分布式事务的实现原理
目录 一、写在前面 二、业务场景介绍 三、进一步思考 四、落地实现TCC分布式事务 (1)TCC实现阶段一:Try (2)TCC实现阶段二:Confirm (3)TCC实现阶段三:Cancel 五、总结与思考 一、写在前面 之前网上看到很多写分布式事务的文章,不过…
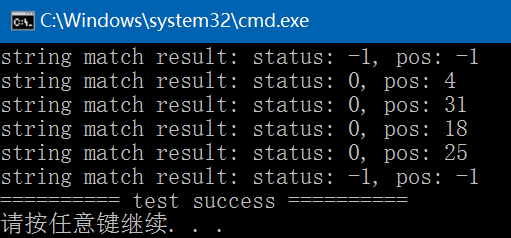
Brute Force算法介绍及C++实现
字符串的模式匹配操作可以通过Brute Force算法来实现。字符串匹配操作即是查看S串(目标串或主串)中是否含有T串(模式串或子串),如果在主串中查找到了子串,则模式匹配成功,返回模式串中的第一个字符在主串中的位置;如果未找到&…

使用Go内置库实现简易httpbin功能
简介 通过学习「Go语言圣经」的入门部分,了解到 go 内置库里提供了一个简单的 http 功能。于是想模拟下httpbin[1]的 get 方法显示 header 头信息的功能来练手。 本人 Go 初学小白,为了练习只是简单的实现了请求 header 的 JSON 格式展示,跟 …

Google图嵌入工业界最新大招,高效解决训练大规模深度图卷积神经网络问题
导读:本文主要介绍Google发表在KDD 2019的图嵌入工业界最新论文,提出Cluster-GCN,高效解决工业界训练大规模深度图卷积神经网络问题,性能大幅提升基础上依靠可训练更深层网络达到SOTA效果,并开源了源代码。作者 | yyl4…

经典树型表结构之SORT_NO
为什么80%的码农都做不了架构师?>>> 在以下情况需要对经典树型表的sort_no进行重排序:1、插入节点(插入子树),需调整节点后所有sort_no;2、删除节点(删除子树),需调整节…
Ubuntu14.04上安装TensorRT 2.1操作步骤
在Ubuntu14.04 上安装TensorRT2.1有两种方法:(1)、通过.deb直接安装;(2)、通过Tar文件安装。这里通过Tar文件安装。安装步骤:1. 安装CUDA 8.0,可参考: http://blog.csdn.net/fengbingchun/article/details/53840684 ;…

学会这门编程知识,可能决定你能进什么样的企业
对于程序员来讲,很多技术真正掌握之后,都能影响甚至说改变一个人的命运,比如:python、AI、DL、算法等等,但是如果只让你选择其中的一项基础知识,你会选择哪个呢?如果是我, 我会选——…
雷林鹏分享:MySQL 及 SQL 注入
MySQL 及 SQL 注入 如果您通过网页获取用户输入的数据并将其插入一个MySQL数据库,那么就有可能发生SQL注入安全的问题。 本章节将为大家介绍如何防止SQL注入,并通过脚本来过滤SQL中注入的字符。 所谓SQL注入,就是通过把SQL命令插入到Web表单递…
dedecms网站文章内容按自定义排序的方法
标签dede:arclist的排序是通过orderby来指定的,如下: {dede:arclist orderby’排序字段’ } {/dede:arclist} orderby’sortrank’ 文档排序方式 orderby’hot’ 或 orderby’click’ 表示按点击数排列 orderby’sortrank’ 或 orderby’pubdate’ 按…

有了这套模板,再不担心刷不动LeetCode了
(图片下载自视觉中国)作者 | 李威来源 | https://www.liwei.party/整理 | 五分钟学算法(ID: CXYxiaowu)正文下面的动画以 「力扣」第 704 题:二分查找 为例,展示了使用这个模板编写二分查找法的一般流程。b…
一线互联网技术:Java工程师架构知识系统化汇总,面完45K!
根据高端招聘平台100 offer发布的Java人才盘点报告,在过去的2018年,Java仍然是最流行、招聘供需量最大的技术语言。在此基础上,互联网行业针对 Java 开发的招聘需求,也是近年技术类岗位供需量最大,且变化最稳定的。企业…
C++中局部类的使用
类可以定义在某个函数的内部,我们称这样的类为局部类(local class)。局部类定义的类型只在定义它的作用域内可见。和嵌套类不同,局部类的成员受到严格控制。局部类的所有成员(包括函数在内)都必须完整定义在类的内部。因此,局部类的作用与嵌套…
按键驱动的恩恩怨怨之概述
转载请注明出处:http://blog.csdn.net/ruoyunliufeng/article/details/23946487 研究按键驱动已经有几天了,尽管是0基础的驱动,可是当中包括的知识确实不少。接下来的几篇文章我会分别从浅入深的分析按键驱动。希望能对大家有所帮助。因为屌…
C++中嵌套类的使用
一个类可以定义在另一个类的内部,前者称为嵌套类(nested class)或嵌套类型(nested type)。嵌套类常用于定义作为实现部分的类。嵌套类可用于隐藏实现细节。嵌套类是一个独立的类,与外层类基本没什么关系。特别是,外层类的对象和嵌套类的对象是…
挑战弱监督学习的三大热门问题 AutoWSL2019挑战赛正式开赛
AutoWSL2019作为11月17-19日亚洲机器学习大会(ACML)主会议竞赛单元之一,由第四范式、ChaLearn、RIKEN和微软联合举办,其中竞赛分享和颁奖将与大会WSL-Workshop共同举办。据悉,AutoWSL是继AutoCV、AutoCV2、AutoNLP、Au…
数据连接池的工作机制是什么?
以典型的数据库连接池为例: 首先普通的数据库访问是这样的:程序和数据库建立连接,发送数据操作的指令,完成后断开连接。等下一次请求的时候重复这个过程,即每个请求都需要和数据库建立连接和断开连接,这样当…
apkplug插件托管服务简化与简介-05
2019独角兽企业重金招聘Python工程师标准>>> 本文基于TuoClondService1.1.0讲解 apkplug插件托管服务是提供给开发者一个远程发布插件的管理平台,但v1.0.0版本接口调用有些复杂我们在v1.1.0版本中着重对其进行了简化 与封装,使开发者能更简…

SpringBoot-JPA入门
SpringBoot-JPA入门 JPA就是Spring集成了hibernate感觉。 注解,方法仓库(顾名思义的方法,封装好了,还有自定义的方法)。 案例: spring:datasource:url: jdbc:mysql://localhost:3306/springboot?useUnicodetrue&c…
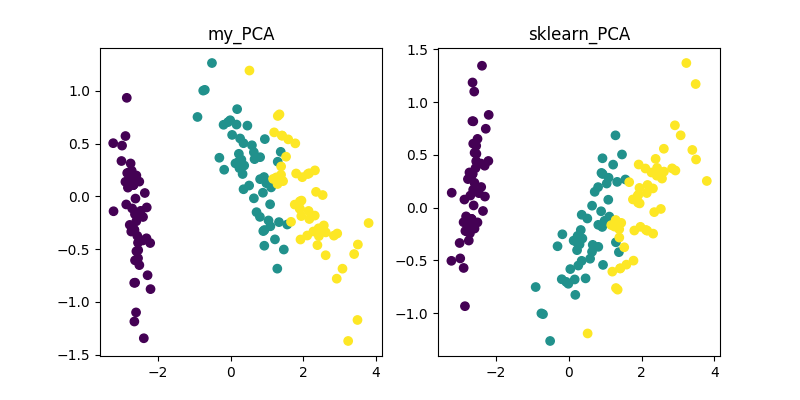
PCA、LDA、MDS、LLE、TSNE等降维算法的Python实现
整理 | 夕颜出品 | AI科技大本营(ID:rgznai100)【导读】网上关于各种降维算法的资料参差不齐,但大部分不提供源代码。近日,有人在 GitHub 上整理了一些经典降维算法的 Demo(Python)集合,同时给出了参考资料的链接。PCA…
C++11中enum class的使用
枚举类型(enumeration)使我们可以将一组整型常量组织在一起。和类一样,每个枚举类型定义了一种新的类型。枚举属于字面值常量类型。 C包含两种枚举:限定作用域的和不限定作用域的。这里主要介绍限定作用域的。不限定作用域的使用可以参考: ht…
Windows下Mysql主从配置(Mysql5.5)
主数据库IP:192.168.3.169从数据库IP:192.168.3.34主数据库配置my.inin:在[mysqld]下添加配置数据:server-id1 #配一个唯一的ID编号,1至32。log-binmysql-bin #二进制文件存放路径#设置要进行或不要进行主从复制的数据库名,同…

K-最近邻法(KNN) C++实现
关于KNN的介绍可以参考: http://blog.csdn.net/fengbingchun/article/details/78464169 这里给出KNN的C实现,用于分类。训练数据和测试数据均来自MNIST,关于MNIST的介绍可以参考: http://blog.csdn.net/fengbingchun/article/deta…

AI大佬“互怼”:Bengio和Gary Marcus隔空对谈深度学习发展现状
编译 | AI科技大本营编辑部出品 | AI科技大本营(ID:rgznai100)去年以来,由于纽约大学教授 Gary Marcus 对深度学习批评,导致他在社交媒体上与许多知名的 AI 研究人员如 Facebook 首席 AI 科学家 Yann LeCun 进行了一场论战。不止 …
Centos7多内核情况下修改默认启动内核方法
1.1 进入grub.cfg配置文件存放目录/boot/grub2/并备份grub.cfg配置文件 [rootlinux-node1 ~]# cd /boot/grub2/ [rootlinux-node1 grub2]# cp -p grub.cfg grub.cfg.bak [rootlinux-node1 grub2]# ls -ld grub.cfg* -rw-r--r--. 1 root root 5162 Aug 11 2018 grub.cfg -rw-r…
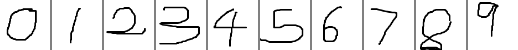
TensorRT Samples: MNIST
关于TensorRT的介绍可以参考: http://blog.csdn.net/fengbingchun/article/details/78469551以下是参考TensorRT 2.1.2中的sampleMNIST.cpp文件改写的实现对手写数字0-9识别的测试代码,各个文件内容如下:common.hpp:#ifndef FBC_TENSORRT_TE…
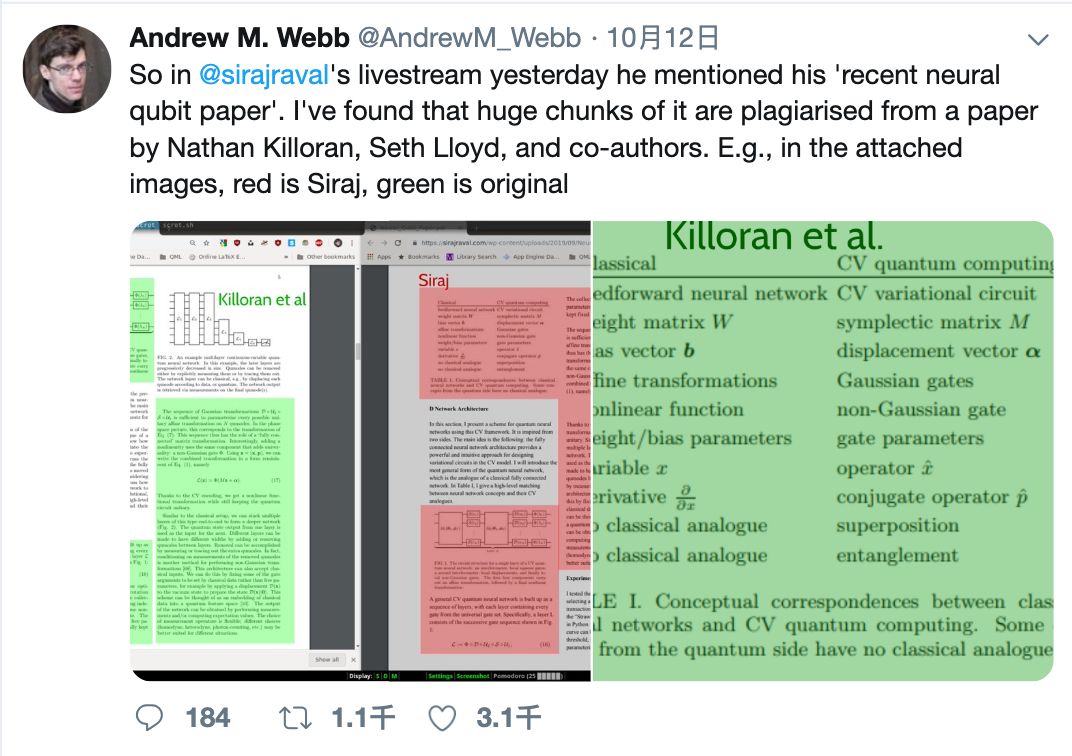
网红“AI大佬”被爆论文剽窃,Jeff Dean都看不下去了
作者 | 夕颜、Just出品 | AI科技大本营(ID:rgznai100)【导读】近日,推特上一篇揭露 YouTube 网红老师 Siraj Raval 新发表论文涉抄袭其他学者的帖子引起了讨论。揭露者是曼彻斯特大学计算机科学系研究员 Andrew M. Webb,他在 Twit…
数位dp(求1-n中数字1出现的个数)
题意:求1-n的n个数字中1出现的个数。 解法:数位dp,dp[pre][now][equa] 记录着第pre位为now,equa表示前边是否有降数字(即后边可不能够任意取,true为没降,true为已降);常规的记忆化搜…
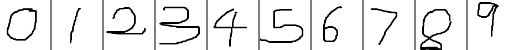
TensorRT Samples: MNIST API
关于TensorRT的介绍可以参考: http://blog.csdn.net/fengbingchun/article/details/78469551 以下是参考TensorRT 2.1.2中的sampleMNISTAPI.cpp文件改写的实现对手写数字0-9识别的测试代码,各个文件内容如下:common.hpp:#ifndef FBC_TENSORR…

免费学习AI公开课:打卡、冲击排行榜,还有福利领取
CSDN 技术公开课 Plus--AI公开课再度升级内容全新策划:贴近开发者,更多样、更落地形式多样升级:线上线下、打卡学习,资料福利,共同交流成长,扫描下方小助手二维码,回复:公开课&#…

Gamma阶段第一次scrum meeting
每日任务内容 队员昨日完成任务明日要完成的任务张圆宁#91 用户体验与优化:发现用户体验细节问题https://github.com/rRetr0Git/rateMyCourse/issues/91#91 用户体验与优化:发现并优化用户体验,修复问题https://github.com/rRetr0Git/rateMyC…