CVPR 2019论文阅读:Libra R-CNN如何解决不平衡对检测性能的影响?

Paper link:
https://arxiv.org/pdf/1904.02701.pdf
Code link:
https://github.com/OceanPang/Libra_R-CNN
Abstract
在目标检测中,人们更关注的往往是模型结构,而在训练过程中投入的注意力相对较少。但是训练过程对于一个目标检测器来说同样关键。在本工作中,作者仔细回顾了检测器的标准训练过程,发现在训练过程中,检测性能往往受到不平衡的限制。这种不平衡往往包括三个方面:sample level(样本层面),feature level(特征层面),objective level(训练目标层面),为了上述三个不平衡对检测性能的影响,本文提出了Libra R-CNN,一个针对目标检测平衡学习的简单有效框架。该框架集成了三个组件:IoU-balanced sampling,balanced feature pyramid,balanced L1 loss,分别对应解决上述的三个不平衡。基于这些改造,Libra R-CNN在AP上的提升有两个多点,可以说是简洁高效。
Introduction
随着深度卷积神经网络的发展,目标检测任务取得了很大的突破。Faster R-CNN,RetinaNet,Cascade R-CNN是其中的代表性框架。不论是one-stage结构还是two-stage结构,主流检测框架大都遵循一种常见的训练范式,即对区域进行采样,从中提取特征,然后在一个标准的多任务目标函数的指导下,共同进行分类和细化位置任务。基于这种指导思想,目标检测训练的成功取决于三个关键方面:(1)选取的区域是否具有代表性(2)提取的特征是否被充分利用到(3)目标损失函数是否是最优的。
作者研究发现,现有的目标检测网络在三个方面都存在严重的不平衡。这种不平衡阻碍了网络架构发挥最佳性能,进而影响了整个检测器的效果。下面介绍一下这三个不平衡,如下图所示:
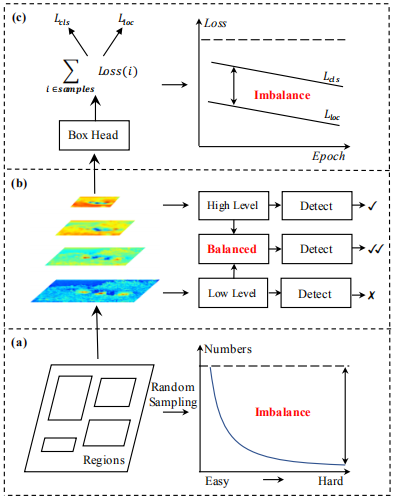
(a)Sample level imbalance:
当训练一个目标检测器时,对于hard samples的训练更有利于提升检测器的表现,如果把训练中心放在easy samples,整个训练结果会被带偏。基于随机采样机制进行区域选取,造成的结果一般是使挑选的样本趋向于easy类型,为了解决这个问题,有著名的OHEM,能够更多的关注hard samples,但是它们通常对噪音很敏感,并会产生相当大的内存和计算成本;RetinaNet中提出了著名的损失函数Focal loss,应用于one-stage的效果较好,但是,扩展到大部分样本为简单负样本的two-stage模型中,效果一般。
(b)Feature level imbalance
我们知道,底层特征拥有高分辨率信息,随着卷积层数的加深,高层特征拥有更丰富的语义信息。把高分辨率信息和丰富的语义信息结合能显著增强特征表达,FPN,PANet都是这方面的成功案例。这些网络结构给我们的启发是可以通过将底层特征信息和高层特征信息互补应用于目标检测。如何利用它们来整合金字塔特征表示的方法决定了检测性能,那么这就引申出一个问题:将不同层特征组合在一起的最佳方法是什么?作者实验表明,组合后的特征必须从各分辨率特征中进行均衡。但是上述方法中的顺序方式将使组合特征更多地关注相邻分辨率,而较少关注其他分辨率,每融合一次,非相邻层中包含的语义信息将被稀释一次。
(c)Objective level imbalance
一个目标检测器需要完成两个任务,目标分类和定位,因此总的训练目标是两个任务目标的结合,这可以看做是一个multi-task的训练优化问题,如何给不同任务赋予权重,保持各个任务之间的平衡,将决定最后的效果。此情形同样适用于训练过程中的样本,如果不平衡,由简单样本产生的小梯度值会淹没困难样本产生的较大的梯度值,进而使得训练被简单样本主导,某些任务无法收敛。因此,针对最优收敛,需要平衡相关的任务及样本。
为了减轻这些不平衡造成的影响,本文提出了Libra R-CNN,通过引入IoU-balanced sampling,balanced feature pyramid和balanced L1 loss三个架构组件来解决不平衡问题。
Libra R-CNN在COCO上相比Faster R-CNN,RetinaNet AP至少涨了两个点,在简单有高效的框架基础上,更加难能可贵。
Method
下图是整个Libra R-CNN的结构图,作者的目标是使用整体平衡的设计来缓解检测器训练过程中的不平衡,从而尽可能地挖掘模型架构的潜力。
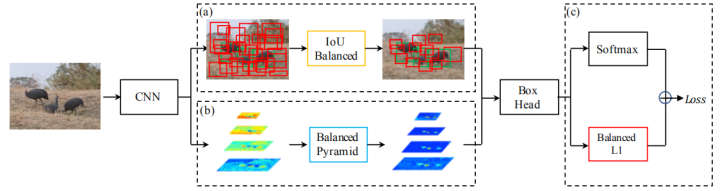
下面来详细介绍一下:
1. IoU-balanced Sampling
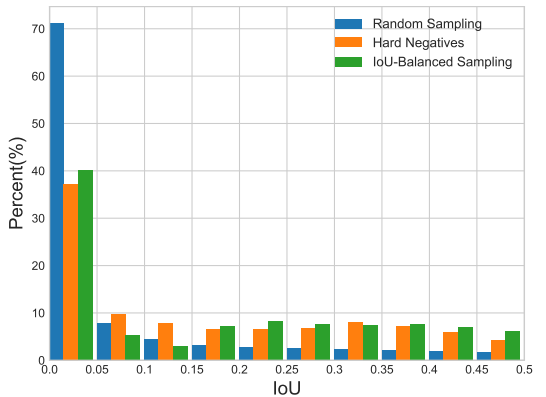
作者首先进行了一个实验,实验的目的是为了验证训练样本与其对应ground-truth之间的重叠是否与其难度相关。也就是说,样本的hard还是easy和对应ground-truth的IoU有没有关系。这里重点看hard negative samples,结果如下图所示,超过60%的hard negative samples的IoU都是大于0.05的,但是在随机抽样中,只有大约30%的样本IoU大于0.05,这种极度的不平衡性导致hard samples被大量的easy samples淹没。
基于实验发现,本文提出了IoU-balanced sampling解决样本之间的不平衡性。具体做法为:假定我们需要从M个候选中抽取N个负样本,每个样本被抽中的概率很好计算:
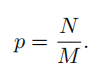
为了增加hard negative samples被抽中的概率,根据IoU将抽样区间平均分成K个格子。N个负样本平均分配到每个格子中,然后均匀地从中选择样本,此时被选中的概率为:
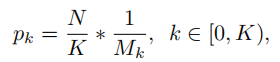
*Mk表示k个对应区间内的抽样候选个数,K在实验中默认为3
*实际上,作者在实验中证明,K的取值并不敏感,如下图所示,取不同的K值,AP表现差别不大,也就是说,将IoU分为几个区间,并没有那么重要。
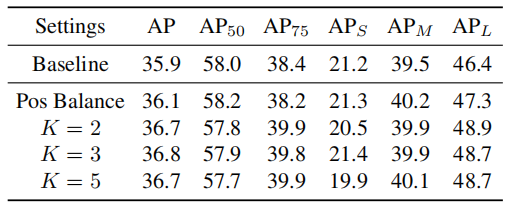
这种方法最大的转变是作者通过在IoU上均匀采样, 使得hard negative在IoU上均匀分布。
2. Balanced Feature Pyramid
为了将不同特征层的信息融合,得到高分辨率和高语义信息的表达,FPN等网络结构提出了横向连接(lateral connection),与以往使用横向连接来整合多层次特征的方法不同,本文的核心思想是利用深度整合的均衡语义特征来强化多层次特征。
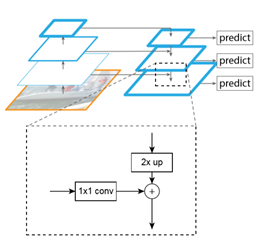
如下图所示,整个过程分为四步,rescaling(尺寸调节),integrating(特征融合),refining(特征细化),strengthening(特征增强)。
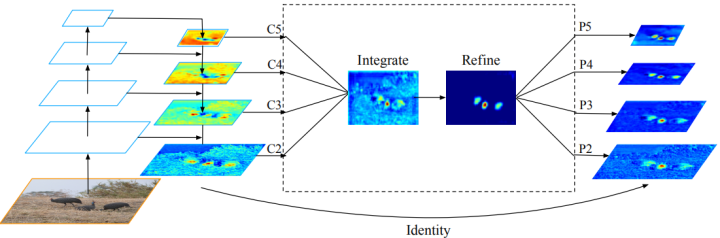
Obtaining balanced semantic features
假设C_l表示第l层特征,lmin,lmax分别表示最底层和最高层的特征。如下图所示,C2有最高的分辨率,为了整合多层次的功能,同时保持它们的语义层次。作者首先将不同层的特征{C2,C3,C4,C5 }进行resize,resize到相同的尺寸,如C4。resize的方法无外乎插值和最大池化。尺寸调整完毕后,可以通过下式得到平衡后的语义特征:
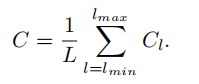
得到的特征C,进行rescale然后通过反向操作增强原始每层的特征,每个分辨率特征从其他分辨率特征中同等的获得信息。此过程不包含任何参数,证明了信息传递的高效性。
Refining balanced semantic features
平衡的语义特征可以进一步细化,使其更具辨别力,作者受《Non-local neural networks》的启发,利用embedded Gaussian non-local attention进行特征细化。通过特征细化能进一步丰富特征信息。
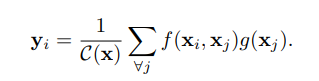
融合后得到的特征{P2,P3,P4,P5}用于后续的目标检测中,流程和FPN相同。
3. Balanced L1 Loss
目标检测的损失函数可以看做是一个多任务的损失函数,分为分类损失和定位损失,可以用下列式子表示:
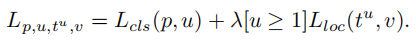
其中,Lcls 和Lloc分别是分类和定位的损失函数。在分类损失函数中,p是预测值,u是真实值, 是类别u的位置回归结果,v是位置回归目标。λ是调整多任务权重参数。在这里定义损失大于等于0.1的样本为outliers,剩余样本为inliers。
为了平衡不同任务,调整参数λ是一个可行的办法。但是,由于回归目标是没有边界限制的,直接增加回归损失的权重将会使模型对outliers更加敏感。对于outliers会被看作是困难样本(hard example),这些困难样本会产生很大的梯度阻碍训练,而inliers被看做是简单样本(easy example)只会产生相比outliers大概0.3倍的梯度。基于此,作者提出了balanced L1 Loss,在下文中用Lb表示。
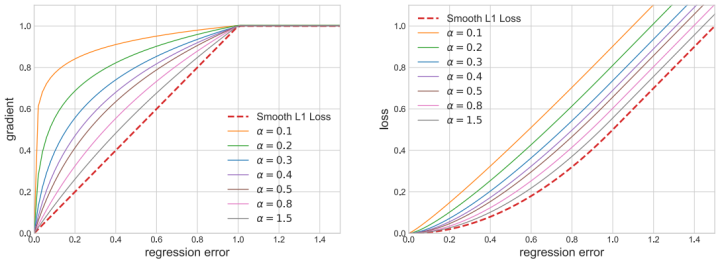
Balanced L1 Loss受smooth L1 Loss的启发,所以这里先贴一个smooth L1 loss的解释:


smooth L1 Loss的思想是,当x较大时,按照一个恒定的速率梯度下降,等到x较小时, 不再按照一个恒定大梯度下降,而是按照自身进行动态调整。
如下图所示,设置一个拐点区分outliers和inliers,对于那些outliers,将梯度固定为1。
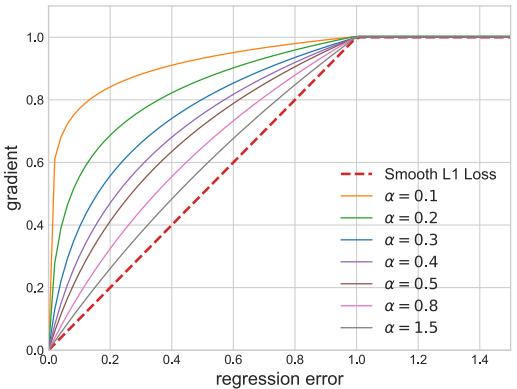
Balanced L1 Loss的关键思想是提升关键的回归梯度,即来自inliers的梯度(准确样本),以重新平衡所涉及的样本和任务,从而在分类、整体定位和准确定位方面实现更平衡的训练。
利用balanced L1 Loss的 可以表示为:
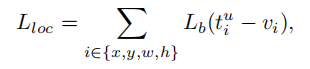
对应的梯度公式如下所示:
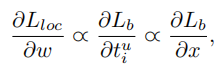
基于上述公式,设计了一个提升梯度的公式:
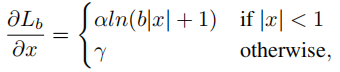
其中,α控制着inliers梯度的提升;一个很小的α会提升inliers的梯度同时不影响outliers的值。γ控制调整回归误差的上界,能够使得不同任务间更加平衡。α,γ从样本和任务层面控制平衡,这两个控制不同方面的因素相互增强,达到更加平衡的训练。
对梯度公式进行积分,就可以看到Lb也就是Balanced L1 Loss的庐山真面了:
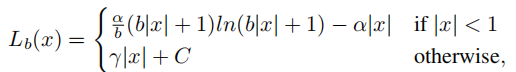
其中,为了保证函数的连续性,在x=1时,需要满足下式:
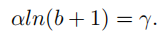
*在本文中,α = 0.5 and γ = 1.5
Experiments
三个组件的效果对比
可以看到,即使单独应用一个组件,总体相比baseline都会有提升,如果将三个都组合起来,AP提升是最大的,充分验证了Libra R-CNN的威力.

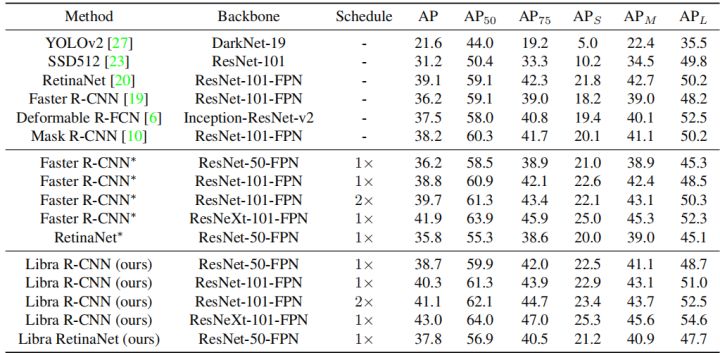
与主流目标检测网络对比
在COCO数据集上,Libra R-CNN在AP上相对主流的one-stage和two-stage方法都有不同程度的提升
Conclusion
本文分析了当前目标检测中存在的三个不平衡问题:
(1)Sample level
(2)Feature level
(3)Objective level
针对这三个不平衡,对症下药,提出了包含三个组件的Libra R-CNN架构,包括:
(1)IoU-balanced Sampling
(2)Balanced Feature Pyramid
(3)Balanced L1 Loss
很好的解决了三个不平衡带来的问题和挑战,使得网络框架能够发挥出更好的性能,COCO数据集上的实验结果表明,Libra R-CNN与最先进的探测器相比,包括one-stage和two-stage框架相比,都获得了显著的改进。
◆
精彩推荐
◆

推荐阅读
人体姿态估计的过去、现在和未来
图灵奖得主Bengio再次警示:可解释因果关系是深度学习发展的当务之急
技术领域有哪些接地气又好玩的应用?
Python新工具:用三行代码提取PDF表格数据
国产嵌入式操作系统发展思考
2019 年诺贝尔物理学奖揭晓!三得主让宇宙“彻底改观”!
公链故事难再续?
使用Vue.js开发微信小程序:开源框架mpvue解析

你点的每个“在看”,我都认真当成了喜欢
相关文章:

实现nginx上配置免费证书Let's Encrypt
Lets Encrypt 的免费证书有效期为三个月,不过可以免费续期,写一个脚本定期更新即可。 准备一台nginx 服务器 ,将以下三个附件上传到你的nginx服务器。 1、下载脚本文件,wget https://raw.githubusercontent.com/xdtianyu/scripts/…

深入解析Windows操作系统笔记——CH1概念和术语
1.概念和工具 本章主要介绍Windows操作系统的关键概念和术语 1.概念和工具... 1 1.1操作系统版本... 1 1.2基础概念和术语... 2 1.2.1Windows API2 1.2.2 服务、函数和例程... 3 1.2.3 进程、线程和作业... 4 1.2.3.1 进程... 4 1.2.3.2 线程... 4 1.2.3.3 虚拟地址描述符... 4…

C++/C++11中std::exception的使用
std::exception:标准异常类的基类,其类的声明在头文件<exception>中。所有标准库的异常类均继承于此类,因此通过引用类型可以捕获所有标准异常。 std::exception类定义了无参构造函数、拷贝构造函数、拷贝赋值运算符、一个虚析构函数和…

技术不错的程序员,为何面试却“屡战屡败”
为何很多有不少编程经验,技术能力不错的程序员,去心仪公司面试时却总是失败?至于失败的原因,可能很多人都没意识到过。01想要通关面试,千万别让数据结构拖了后腿很多公司,比如 BAT、Google、Facebook&#…
FastJson 转换 javaBean 时 null 值被忽略都问题
[toc] 问题 当 JavaeBean 中某个属性值为 null 时,转换为 JSONObject 对象或者 json 字符串时,该属性值被忽略。如何让不管值是否为 null,转化后该属性还存在,只是值为 null。 情况演示 class St {private String sid;private Str…
来玩Play框架07 静态文件
作者:Vamei 出处:http://www.cnblogs.com/vamei 欢迎转载,也请保留这段声明。谢谢! Play框架的主要功能是提供动态响应的内容。但一个网络项目中必然有大量的静态内容,比如图片、Javascript文件、CSS文件等。我下面介绍…

C++/C++11中std::runtime_error的使用
std::runtime_error:运行时错误异常类,只有在运行时才能检测到的错误,继承于std::exception,它的声明在头文件<stdexcept>中。std::runtime_error也用作几个运行时错误异常的基类,包括std::range_error(生成的结…

估值被砍700亿美元后,Waymo发重磅公开信:即将推出全自动驾驶打车服务
(图片源自 Waymo 官网)编译 | 夕颜出品 | AI科技大本营(ID:rgznai100)近日,据 Reddit 盛传的一封电子邮件副本显示,Alphabet 旗下的自动驾驶汽车公司 Waymo 已经向其自动驾驶服务的用户发送了一封电子邮件&…
Swoft 2 Beta 发布,基于 Swoole 的云原生协程框架
Swoft 是首个基于 Swoole 原生协程的框架,从开发到发布据今已有2年多。 1.x 发布以来,已有大量的开发人员和企业使用,得到了大家的认可。从去年11月份开始,将近半年的时间从零开始,底层吸取之前经验,基于 S…
Linux中源码包的管理
什么是开放源码,编译程序和可执行文件开放源码:就是程序代码,写给人类看的程序语言,但机器不认识,所以无法执行;编译程序:将程序代码转译成为机器看得懂的语言;可执行文件:经过编译程序变成二进制程序后,机…
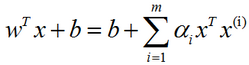
支持向量机(SVM)简介
支持向量机(support vector machine, SVM):是监督学习中最有影响力的方法之一。类似于逻辑回归,这个模型也是基于线性函数wTxb的。不同于逻辑回归的是,支持向量机不输出概率,只输出类别。当wTxb为正时,支持向量机预测属…

首届中文NL2SQL挑战赛:千支队伍参赛,国防科大夺冠
(图片由AI科技大本营付费下载自视觉中国)整理 | Jane出品 | AI科技大本营(ID:rgznai100)【导语】10月12日,追一科技主办的首届中文NL2SQL挑战赛在激烈的决赛中落下帷幕,冠军由国防科技大学学生组…
怎么使用CAD编辑器来打开图纸中的所有图层
在CAD绘图中,建筑设计师们不仅要对CAD图纸进行编辑,还要对CAD图纸进行查看,一张图纸中是有许多图层的,那在查看的过程中有的时候把其他的图层进行隐藏了,那如果想要把隐藏的CAD图层进行打开要怎么操作?如何…

域名年龄-SEO搜索引擎优化
为什么80%的码农都做不了架构师?>>> 域名年龄-SEO搜索引擎优化 在我们创建一个新的网站时,我们首先考虑到的是去注册一个新的域名。 有时发现我们 要注册的域名已经被注册了,于是就有两种方式: 一、重新注册另外的…

log库spdlog简介及使用
spdlog是一个开源的、快速的、仅有头文件的C11 日志库,code地址在 https://github.com/gabime/spdlog ,目前最新的发布版本为0.14.0。它提供了向流、标准输出、文件、系统日志、调试器等目标输出日志的能力。它支持的平台包括Windows、Linux、Mac、Andro…

多模态人物识别技术及其在视频场景中的应用 | CSDN技术公开课
不用倍速播放,还有什么功能可以让你高效追剧?爱奇艺的「只看TA」了解一下?而这个功能背后离不开多模态人物识别技术的支撑。识别视频中的人物涉及哪些信息?只有人脸识别就足够了吗?其实不然,这样一个看似简…
研究人员测试27个黑客服务 结果仅三个完成任务
现代电子邮件帐户不仅是一个电子邮件地址,它还是人们在网络上的身份的基础,可用于申请各种网络服务或重置服务密码,以便持有电子邮件的黑客服务帐户很受欢迎,为了了解这些服务的功能,谷歌和加州大学圣地亚哥分校的研究…
CIF、QCIF
分辨率: 每个像素的存储方式都是YUV QQCIF:88*72 QCIF:176*144 CIF:352*288 2CIF:704*288 DCIF:584*384 4CIF:704*576 QCIF: QCIF: Quarter Common Intermediate Format 英文缩写 qcif 英文全称 Quarter Common Intermediate Format 中文解释 四分之一通…
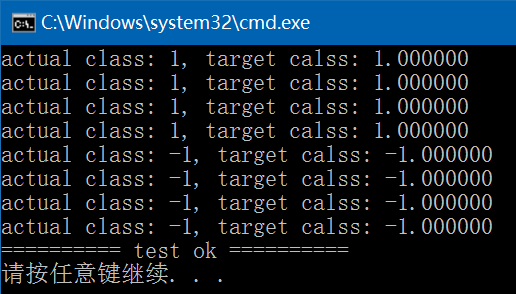
OpenCV3.3中支持向量机(Support Vector Machines, SVM)实现简介及使用
OpenCV 3.3中给出了支持向量机(Support Vector Machines)的实现,即cv::ml::SVM类,此类的声明在include/opencv2/ml.hpp文件中,实现在modules/ml/src/svm.cpp文件中,它既支持两分类,也支持多分类,还支持回归…
Facebook发布Detectron2,下一个万星目标检测新框架
作者 | CV君来源 | 我爱计算机视觉(ID:aicvml)Detectron是Facebook于2018年发布的专注于目标检测的深度学习框架,基于Caffe2深度学习框架,实现了众多state-of-the-art算法,其与商汤-香港中文大学MMLab实验室…
include和require的区别
细节决定成败! 1.引用文件方式 对include()来说,在include()执行时文件每次都要进行读取和评估;而对于require()来说,文件只处理一次(实际上,文件内容替换了require()语句)。这就意味着如果有包…
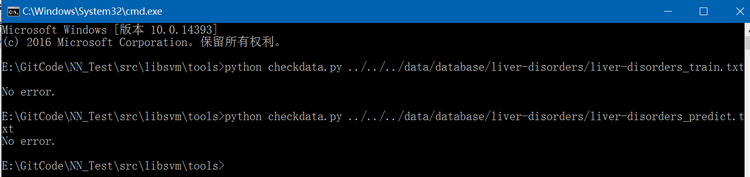
libsvm库简介及使用
libsvm是基于支持向量机(support vector machine, SVM)实现的开源库,由台湾大学林智仁(Chih-Jen Lin)教授等开发,它主要用于分类(支持二分类和多分类)和回归。它的License是BSD-3-Clause,最新发布版本是v322。libsvm具有操作简单、易于使用、…
Cron 表达式极速参考
Cron表达式: * * * * * * *这些星号由左到右按顺序代表 : [秒] [分] [小时] [日] [月] [周] [年] 序号说明 是否必填 允许填写的值 允许的通配符1 秒 是 0-59 , - * /2 分 是 0-59…

刘群:华为诺亚方舟NLP预训练模型工作的研究与应用 | AI ProCon 2019
演讲嘉宾 | 刘群(华为诺亚方舟实验首席科学家)编辑 | Jane出品 | AI科技大本营(ID:rgznai100)预训练语言模型对自然语言处理领域产生了非常大的影响,在近期由CSDN主办的 AI ProCon 2019 上,自然…

NuGet 无法连接到远程服务器-解决方法
一、 Entity Framework以下简称EF 安装EF4.3的步骤是首先安装VS扩展 NuGet,然后再使用NuGet安装EF程序包 安装完NuGet就可以安装EF了,有两种方式可以安装EF: 1.使用命令 install-package EntityFramework -Pre 但出现如下错误: 2.使用可视化工…

Facebook开源模型可解释库Captum,这次改模型有依据了
作者 | Narine Kokhlikyan, Vivek Miglani, Edward Wang, Orion Reblitz-Richardson译者 | Rachel出品 | AI科技大本营(ID:rgznai100)【导读】前脚 TF 2.0 刚发布,在 PyTorch 开发者大会首日也携 PyTorch1.3 版本而来。除此之外&a…
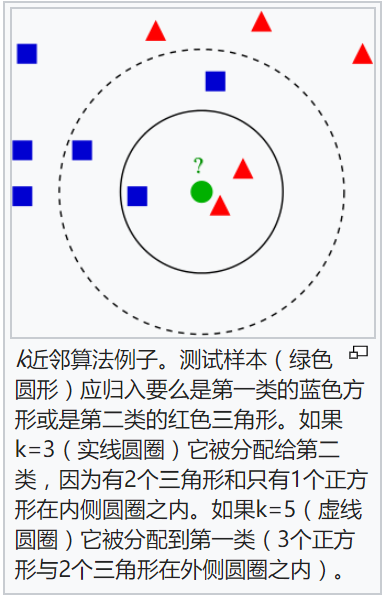
K-最近邻法(KNN)简介
K-最近邻法(K-Nearest Neighbor, KNN)最初由Cover和Hart于1968年提出,是一个在理论上比较成熟的分类算法。KNN是一类可用于分类或回归的技术。作为一个非参数学习算法,K-最近邻并不局限于固定数目的参数。我们通常认为K-最近邻算法没有任何参数ÿ…
demo17 clean-webpack-plugin (清除模式)
1.为什么需要自动清除 dist 文件夹 在之前的 demo 中,webpack 打包后会在根目录下自动创建 dist 目录,并且把生成的文件输出到 dist 下。 当配置的输出包名含有 [hash] 时,hash值会随着文件内容的改变而改变。 因此,我们需要在下一…
c语言-01背包问题
01背包问题 问题:有N件物品和一个容量为V的背包。第i件物品的费用是c[i],价值是w[i]。求解将哪些物品装入背包可使价值总和最大。 分析: 这是最基础的背包问题,特点是:每种物品仅有一件,可以选择放或不放。…

OpenCV3.3中 K-最近邻法(KNN)接口简介及使用
OpenCV 3.3中给出了K-最近邻(KNN)算法的实现,即cv::ml::Knearest类,此类的声明在include/opecv2/ml.hpp文件中,实现在modules/ml/src/knearest.cpp文件中。其中:(1)、cv::ml::Knearest类:继承自cv::ml::StateModel&…