TensorRT Samples: MNIST(serialize TensorRT model)
这里实现在构建阶段将TensorRT model序列化存到本地文件,然后在部署阶段直接load TensorRT model序列化的文件进行推理,mnist_infer.cpp文件内容如下:
#include <iostream>
#include <string>
#include <tuple>
#include <fstream>
#include <memory>#include <cuda_runtime_api.h>
#include <NvInfer.h>
#include <NvCaffeParser.h>
#include <opencv2/opencv.hpp>#include "common.hpp"// 序列化TensorRT模型,然后load TensorRT模型进行推理namespace {
typedef std::tuple<int, int, int, std::string, std::string> DATA_INFO; // intput width, input height, output size, input blob name, output blob nameint caffeToGIEModel(const std::string& deployFile, // name for caffe prototxtconst std::string& modelFile, // name for model const std::vector<std::string>& outputs, // network outputsunsigned int maxBatchSize, // batch size - NB must be at least as large as the batch we want to run with)Logger logger, const std::string& engine_file)
{// create the buildernvinfer1::IBuilder* builder = nvinfer1::createInferBuilder(logger);// parse the caffe model to populate the network, then set the outputsnvinfer1::INetworkDefinition* network = builder->createNetwork();nvcaffeparser1::ICaffeParser* parser = nvcaffeparser1::createCaffeParser();const nvcaffeparser1::IBlobNameToTensor* blobNameToTensor = parser->parse(deployFile.c_str(), modelFile.c_str(), *network, nvinfer1::DataType::kFLOAT);// specify which tensors are outputsfor (auto& s : outputs)network->markOutput(*blobNameToTensor->find(s.c_str()));// Build the enginebuilder->setMaxBatchSize(maxBatchSize);builder->setMaxWorkspaceSize(1 << 20);nvinfer1::ICudaEngine* engine = builder->buildCudaEngine(*network);CHECK(engine != nullptr);// we don't need the network any more, and we can destroy the parsernetwork->destroy();parser->destroy();// serialize the engine, then close everything downnvinfer1::IHostMemory* gieModelStream = engine->serialize(); // GIE modelfprintf(stdout, "allocate memory size: %d bytes\n", gieModelStream->size());std::ofstream outfile(engine_file.c_str(), std::ios::out | std::ios::binary);if (!outfile.is_open()) {fprintf(stderr, "fail to open file to write: %s\n", engine_file.c_str());return -1;}unsigned char* p = (unsigned char*)gieModelStream->data();outfile.write((char*)p, gieModelStream->size());outfile.close();engine->destroy();builder->destroy();if (gieModelStream) gieModelStream->destroy(); nvcaffeparser1::shutdownProtobufLibrary();return 0;
}int doInference(nvinfer1::IExecutionContext& context, const float* input, float* output, int batchSize, const DATA_INFO& info)
{const nvinfer1::ICudaEngine& engine = context.getEngine();// input and output buffer pointers that we pass to the engine - the engine requires exactly IEngine::getNbBindings(),// of these, but in this case we know that there is exactly one input and one output.CHECK(engine.getNbBindings() == 2);void* buffers[2];// In order to bind the buffers, we need to know the names of the input and output tensors.// note that indices are guaranteed to be less than IEngine::getNbBindings()int inputIndex = engine.getBindingIndex(std::get<3>(info).c_str()), outputIndex = engine.getBindingIndex(std::get<4>(info).c_str());// create GPU buffers and a streamcheckCudaErrors(cudaMalloc(&buffers[inputIndex], batchSize * std::get<1>(info) * std::get<0>(info) * sizeof(float)));checkCudaErrors(cudaMalloc(&buffers[outputIndex], batchSize * std::get<2>(info) * sizeof(float)));cudaStream_t stream;checkCudaErrors(cudaStreamCreate(&stream));// DMA the input to the GPU, execute the batch asynchronously, and DMA it back:checkCudaErrors(cudaMemcpyAsync(buffers[inputIndex], input, batchSize * std::get<1>(info) * std::get<0>(info) * sizeof(float), cudaMemcpyHostToDevice, stream));context.enqueue(batchSize, buffers, stream, nullptr);checkCudaErrors(cudaMemcpyAsync(output, buffers[outputIndex], batchSize * std::get<2>(info) * sizeof(float), cudaMemcpyDeviceToHost, stream));cudaStreamSynchronize(stream);// release the stream and the bufferscudaStreamDestroy(stream);checkCudaErrors(cudaFree(buffers[inputIndex]));checkCudaErrors(cudaFree(buffers[outputIndex]));return 0;
}} // namesapceint test_mnist_infer()
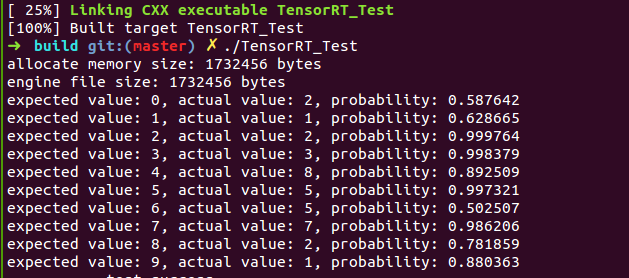
{// 1. build phase// stuff we know about the network and the caffe input/output blobsconst DATA_INFO info(28, 28, 10, "data", "prob");const std::string deploy_file { "models/mnist.prototxt" };const std::string model_file { "models/mnist.caffemodel" };const std::string mean_file { "models/mnist_mean.binaryproto" };const std::string engine_file { "tensorrt_mnist.model" };Logger logger; // multiple instances of IRuntime and/or IBuilder must all use the same loggerCHECK(caffeToGIEModel(deploy_file, model_file, std::vector<std::string>{std::get<4>(info)}, 1, logger, engine_file) == 0);// 2. deploy phase// parse the mean file and subtract it from the imagenvcaffeparser1::ICaffeParser* parser = nvcaffeparser1::createCaffeParser();nvcaffeparser1::IBinaryProtoBlob* meanBlob = parser->parseBinaryProto(mean_file.c_str());parser->destroy();std::ifstream in_file(engine_file.c_str(), std::ios::in | std::ios::binary);if (!in_file.is_open()) {fprintf(stderr, "fail to open file to write: %s\n", engine_file.c_str());return -1;}std::streampos begin, end;begin = in_file.tellg();in_file.seekg(0, std::ios::end);end = in_file.tellg();std::size_t size = end - begin;fprintf(stdout, "engine file size: %d bytes\n", size);in_file.seekg(0, std::ios::beg);std::unique_ptr<unsigned char[]> engine_data(new unsigned char[size]);in_file.read((char*)engine_data.get(), size);in_file.close();// deserialize the engine nvinfer1::IRuntime* runtime = nvinfer1::createInferRuntime(logger); nvinfer1::ICudaEngine* engine = runtime->deserializeCudaEngine((const void*)engine_data.get(), size, nullptr);nvinfer1::IExecutionContext* context = engine->createExecutionContext();const float* meanData = reinterpret_cast<const float*>(meanBlob->getData());const std::string image_path{ "images/digit/" };for (int i = 0; i < 10; ++i) {const std::string image_name = image_path + std::to_string(i) + ".png";cv::Mat mat = cv::imread(image_name, 0);if (!mat.data) {fprintf(stderr, "read image fail: %s\n", image_name.c_str());return -1;}cv::resize(mat, mat, cv::Size(std::get<0>(info), std::get<1>(info)));mat.convertTo(mat, CV_32FC1);float data[std::get<1>(info)*std::get<0>(info)];const float* p = (float*)mat.data;for (int j = 0; j < std::get<1>(info)*std::get<0>(info); ++j) {data[j] = p[j] - meanData[j];}// run inferencefloat prob[std::get<2>(info)];doInference(*context, data, prob, 1, info);float val{-1.f};int idx{-1};for (int t = 0; t < std::get<2>(info); ++t) {if (val < prob[t]) {val = prob[t];idx = t;}}fprintf(stdout, "expected value: %d, actual value: %d, probability: %f\n", i, idx, val);}meanBlob->destroy();// destroy the enginecontext->destroy();engine->destroy();runtime->destroy();return 0;
}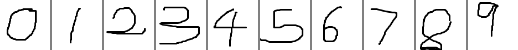
测试结果如下:与http://blog.csdn.net/fengbingchun/article/details/78552908 结果一致
在Linux下通过CMake编译TensorRT_Test中的测试代码步骤:
1. 将终端定位到CUDA_Test/prj/linux_tensorrt_cmake,依次执行如下命令:$ mkdir build$ cd build$ cmake ..$ make (生成TensorRT_Test执行文件)$ ln -s ../../../test_data/models ./ (将models目录软链接到build目录下)$ ln -s ../../../test_data/images ./ (将images目录软链接到build目录下)$ ./TensorRT_Test
2. 对于有需要用OpenCV参与的读取图像的操作,需要先将对应文件中的图像路径修改为Linux支持的路径格式
GitHub: https://github.com/fengbingchun/CUDA_Test
相关文章:

【mysql错误】用as别名 做where条件,报未知的列 1054 - Unknown column 'name111' in 'field list'...
需求:SELECT a AS b WHRER b1; //这样使用会报错,说b不存在。 因为mysql底层跑SQL语句时:where 后的筛选条件在先, as B的别名在后。所以机器看到where 后的别名是不认的,所以会报说B不存在。 这个b只是字段a查询结…
C++2年经验
网络 sql 基础算法 最多到图和树 常用的几种设计模式,5以内即可转载于:https://www.cnblogs.com/liujin2012/p/3766106.html
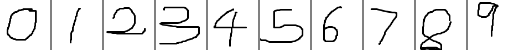
在Caffe中调用TensorRT提供的MNIST model
在TensorRT 2.1.2中提供了MNIST的model,这里拿来用Caffe的代码调用实现,原始的mnist_mean.binaryproto文件调整为了纯二进制文件mnist_tensorrt_mean.binary,测试结果与使用TensorRT调用(http://blog.csdn.net/fengbingchun/article/details/…

142页ICML会议强化学习笔记整理,值得细读
作者 | David Abel编辑 | DeepRL来源 | 深度强化学习实验室(ID: Deep-RL)ICML 是 International Conference on Machine Learning的缩写,即国际机器学习大会。ICML如今已发展为由国际机器学习学会(IMLS)主办的年度机器…

CF1148F - Foo Fighters
CF1148F - Foo Fighters 题意:你有n个物品,每个都有val和mask。 你要选择一个数s,如果一个物品的mask & s含有奇数个1,就把val变成-val。 求一个s使得val总和变号。 解:分步来做。发现那个奇数个1可以变成&#x…
html传參中?和amp;
<a href"MealServlet?typefindbyid&mid<%m1.getMealId()%> 在这句传參中?之后的代表要传递的參数当中有两个參数第一个为type第二个为mid假设是一个參数就不用加&假设是多个參数须要加上&来传递

实战:手把手教你实现用语音智能控制电脑 | 附完整代码
作者 | 叶圣出品 | AI科技大本营(ID:rgznai100)导语:本篇文章将基于百度API实现对电脑的语音智能控制,不需要任何硬件上的支持,仅仅依靠一台电脑即可以实现。作者经过测试,效果不错,同时可以依据…
C++/C++11中左值、左值引用、右值、右值引用的使用
C的表达式要不然是右值(rvalue),要不然就是左值(lvalue)。这两个名词是从C语言继承过来的,原本是为了帮助记忆:左值可以位于赋值语句的左侧,右值则不能。 在C语言中,二者的区别就没那么简单了。一个左值表达式的求值结…

Could not create the view: An unexpected exception was thrown. Myeclipse空间报错
转载于:https://blog.51cto.com/82654993/1424339
Banknote Dataset(钞票数据集)介绍
Banknote Dataset(钞票数据集):这是从纸币鉴别过程中的图像里提取的数据,用来预测钞票的真伪的数据集。该数据集中含有1372个样本,每个样本由5个数值型变量构成,4个输入变量和1个输出变量。小波变换工具用于从图像中提取特征。这是…
快速适应性很重要,但不是元学习的全部目标
作者 | Khurram Javed, Hengshuai Yao, Martha White译者 | Monanfei出品 | AI科技大本营(ID:rgznai100)实践证明,基于梯度的元学习在学习模型初始化、表示形式和更新规则方面非常有效,该模型允许从少量样本中进行快速适应。这些方…
面试题-自旋锁,以及jvm对synchronized的优化
背景 想要弄清楚这些问题,需要弄清楚其他的很多问题。 比如,对象,而对象本身又可以延伸出很多其他的问题。 我们平时不过只是在使用对象而已,怎么使用?就是new 对象。这只是语法层面的使用,相当于会了一门编…
DNS解析故障
在实际应用过程中可能会遇到DNS解析错误的问题,就是说当我们访问一个域名时无法完成将其解析到IP地址的工作,而直接输入网站IP却可以正常访问,这就是因为DNS解析出现故障造成的。这个现象发生的机率比较大,所以本文将从零起步教给…
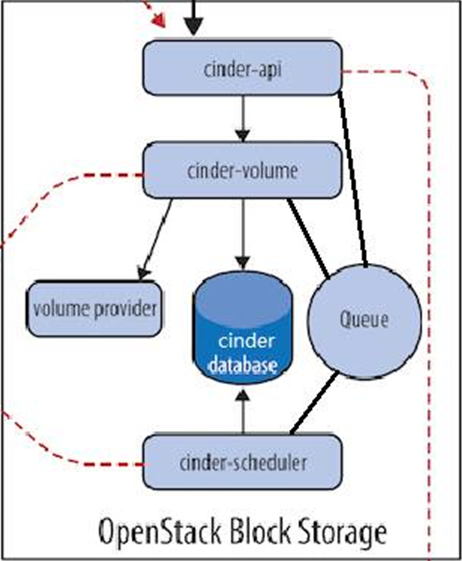
cinder存储服务
一、cinder 介绍: 理解 Block Storage 操作系统获得存储空间的方式一般有两种: 1、通过某种协议(SAS,SCSI,SAN,iSCSI 等)挂接裸硬盘,然后分区、格式化、创建文件系统;或者直接使用裸硬盘存储数据࿰…
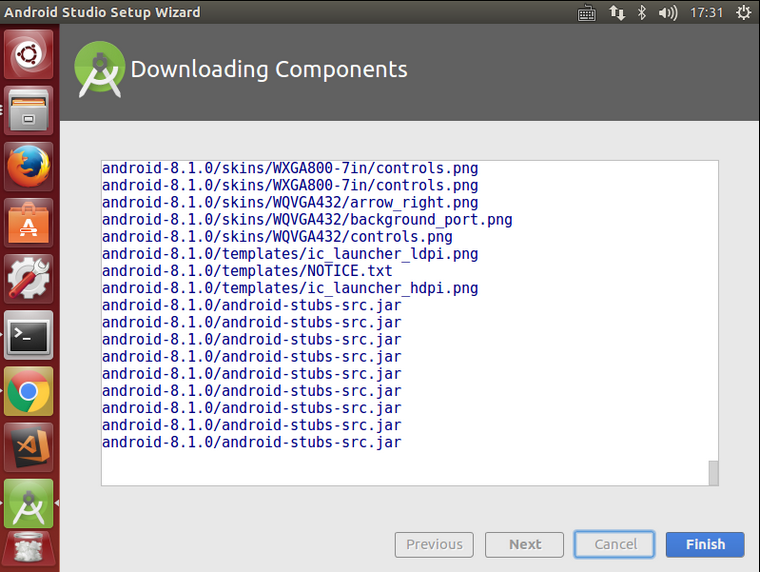
Ubuntu 14.04 64位机上配置Android Studio操作步骤
Android Studio是一个为Android平台开发程序的集成开发环境。2013年5月16日在Google I/O上发布,可供开发者免费使用。Android Studio基于JetBrains IntelliJ IDEA,为Android开发特殊定制,并在Windows、OS X和Linux平台上均可运行。1. 从 htt…
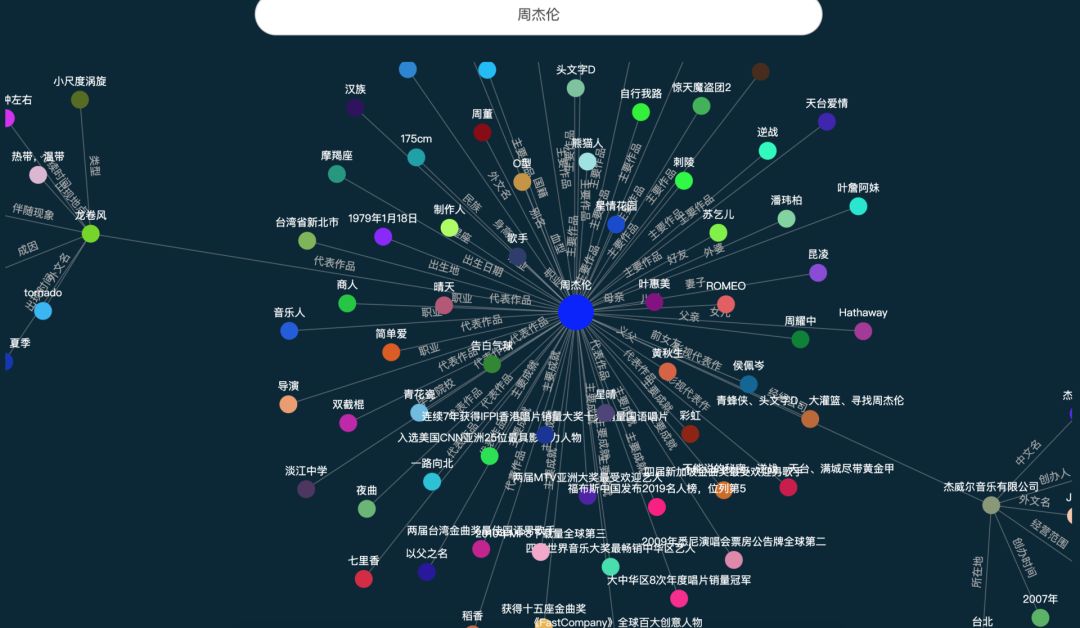
大规模1.4亿中文知识图谱数据,我把它开源了
作者 | Just出品 | AI科技大本营(ID:rgznai100)人工智能从感知阶段逐步进入认知智能的过程中,知识图谱技术将为机器提供认知思维能力和关联分析能力,可以应用于机器人问答系统、内容推荐等系统中。不过要降低知识图谱技术应用的门…

使用CSS 3创建不规则图形
2019独角兽企业重金招聘Python工程师标准>>> 前言 CSS 创建复杂图形的技术即将会被广泛支持,并且应用到实际项目中。本篇文章的目的是为大家开启它的冰山一角。我希望这篇文章能让你对不规则图形有一个初步的了解。 现在,我们已经可以使用CSS…

谷歌丰田联合成果ALBERT了解一下:新轻量版BERT,参数小18倍,性能依旧SOTA
作者 | Less Wright编译 | ronghuaiyang来源 | AI公园(ID:AI_Paradise)【导读】这是来自Google和Toyota的新NLP模型,超越Bert,参数小了18倍。你以前的NLP模型参数效率低下,而且有些过时。祝你有美好的一天。谷歌Resear…
C++中extern C的使用
C程序有时需要调用其它语言编写的函数,最常见的是调用C语言编写的函数。像所有其它名字一样,其它语言中的函数名字也必须在C中进行声明,并且该声明必须指定返回类型和形参列表。对于其它语言编写的函数来说,编译器检查…
Linux之tmpwatch命令
1、tmpwatch命令功能简介[rootvms002 /]# whatis tmpwatch tmpwatch (8) - removes files which havent been accessed for a period of... #删除一段时间内未被访问的文件tmpwatch删除最近一段时间内没有被访问的文件,时间以小时为单位,节省磁盘空间。…
你不得不知道的Visual Studio 2012(1)- 每日必用功能
2019独角兽企业重金招聘Python工程师标准>>> Visual Studio 2012已经正式发布,有很多花哨的新特性,也有很多方便使用者的新功能,当然也有负面声音。对于我们程序员,最关心的还是如何快速掌握VS2012,用于平时…
C++11中std::unique_lock的使用
std::unique_lock为锁管理模板类,是对通用mutex的封装。std::unique_lock对象以独占所有权的方式(unique owership)管理mutex对象的上锁和解锁操作,即在unique_lock对象的声明周期内,它所管理的锁对象会一直保持上锁状态;而unique…
为何Google将几十亿行源代码放在一个仓库?| CSDN博文精选
作者 | Rachel Potvin,Josh Levenberg译者 | 张建军编辑 | apddd【AI科技大本营导读】与大多数开发者的想象不同,Google只有一个代码仓库——全公司使用不同语言编写的超过10亿文件,近百TB源代码都存放在自行开发的版本管理系统Piper中&#…
小小hanoi
为什么80%的码农都做不了架构师?>>> View Code #include " iostream " using namespace std; int k 0 ; void hanoi( int m , char a , char b, char c){ if (m 1 ) { k ; printf( " %c->%c " ,a , c); return…
Unity3D心得分享
本篇文章的内容以各种tips为主,不间断更新 2019/05/10 最近更新: 使用Instantiate初始化参数去实例对象 Unity DEMO学习 Unity3D Adam Demo的学习与研究 Unity3D The Blacksmith Demo部分内容学习 Viking Village维京村落demo中的地面积水效果 Viking V…
django搭建示例-ubantu环境
python3安装--------------------------------------------------------------------------- 最新的django依赖python3,同时ubantu系统默认自带python2与python3,这里单独安装一套python3,并且不影响原来的python环境 django demo使用sqlite3,…
C++11中std::lock_guard的使用
互斥类的最重要成员函数是lock()和unlock()。在进入临界区时,执行lock()加锁操作,如果这时已经被其它线程锁住,则当前线程在此排队等待。退出临界区时,执行unlock()解锁操作。更好的办法是采用”资源分配时初始化”(RAII)方法来加…
OpenAI机械手单手轻松解魔方,背靠强化学习+新技术ADR
编译 | 夕颜出品 | AI科技大本营(ID:rgznai100)【导读】10月15日,人工智能研究机构OpenAI发布了一条机械手单手解魔方的视频。这个自学式的类人机器人手臂名为 Dactyl,不仅可以单手解魔方,甚至能在外加各种干扰&#x…
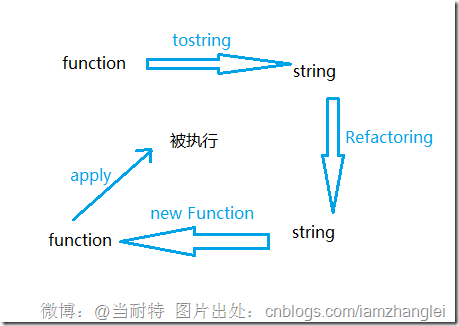
AMD and CMD are dead之js模块化黑魔法
缘由 在2013-03-06 13:58的时候,曾甩下一片文章叫:《为什么不使用requirejs和seajs》,并放下豪言说发布一款完美的模块化库,再后来就把那篇文章删了,再然后就没有然后。该用seajs还用seajs,甚至我码的SCJ都…
一文了解Python常见的序列化操作
关于我 编程界的一名小小程序猿,目前在一个创业团队任team lead,技术栈涉及Android、Python、Java和Go,这个也是我们团队的主要技术栈。 联系:hylinux1024gmail.com 0x00 marshal marshal使用的是与Python语言相关但与机器无关的二…