多模态人物识别技术及其在爱奇艺视频场景中的应用 | 公开课笔记
【12月公开课预告】,入群直接获取报名地址
12月11日晚8点直播主题:人工智能消化道病理辅助诊断平台——从方法到落地
12月12日晚8点直播:利用容器技术打造AI公司技术中台
12月17日晚8点直播主题:可重构计算:能效比、通用性,一个都不能少
嘉宾 | 爱奇艺
编辑 | Jane
出品 | AI科技大本营(ID:rgznai100)
在本期 CSDN 技术公开课Plus:《多模态人物识别技术及其在视频场景中的应用》中,爱奇艺科学家路香菊博士将为大家介绍了多模态人物识别技术及在视频场景中的应用。大家可以学习到爱奇艺在多模态技术领域的三项主要研究工作,并且在爱奇艺视频中是如何应用这些技术的。
讲师介绍:路香菊,爱奇艺科学家,身份识别(PersonAI)团队负责人,专注于人物识别、AI等技术,负责爱奇艺多模态人物识别、智能创作等相关业务。组织创办“爱奇艺多模态视频人物识别赛”,开放全球首个影视视频人物数库iQIYI-VID,创建百万人物库及四万卡通角色库,相关技术应用到爱奇艺APP“扫一扫”及AI雷达等产品中。
一、多模态技术基础介绍
首先,请大家思考一个问题:人物识别只是等同于人脸识别吗?其实,人物识别我们现在的工作中不仅仅是人脸识别,为什么是这样呢?因为在视频中,特别是在一些综艺节目、或者动作片中,完全通过个人的人脸是无法满足所有情况的,知道一个人的身份还需要其他属性,像下图中右边这个图人物,大家一看就知道他是郭德纲,但是如我我们用人脸识别绝对是没有办法识别出来的,因为他的人脸没有露出来,只有一个后脑勺,所以,我们现在基于人物识别的技术还涉及人体的识别,也就是我们监控上的 RE-ID。除此之外,在视频中,还需要识别服饰、发型、声纹和指纹、虹膜等生物特征。所以,现在基于视频场景中的人物识别已经成为一个综合需求的识别。
第二,如何识别虚拟人物?我们之所以叫虚拟人物,是因为它不是真实的一个人物,它包括卡通人物、二次元、动漫以及与游戏人物等形象,现在这部分角色也越来越多,已经成为娱乐行业一个非常重要的需求。在这些现实需求下,我们的研究工作也基本上在实际中落地应用。基于这些实际应用,接下来就与大家分享我们在人物识别与虚拟人物识别工作中的主要算法。
二、多模态技术解读(一):人物识别(IQFace)
这部分内容将主要为大家介绍真人人物识别的多模态基础技术。基于爱奇艺视频内容的需求,我们不仅要做人脸识别,在人脸信息不足或不清晰的情况下,还需要其他信息来辅助进行人物定位,在所有的信息中,我们首先想到的是声音信息;其次,在无声情境中,我们需要结合场景(如打斗、行走中、监控)利用人物的一些动作信息、背影等姿态信息以及服饰等信息来进行人物身份判断。如下图所示,是我们在业务中需要处理的主要信息类别。
通过人脸检测与五官定位进行人脸识别及年龄、性别、表情姿态等属性分析,得到更好的认识;此外,根据实际业务需求,如视频中一些艺人本身独有的气质,得到一些特殊的属性,这部分的处理方法是我们根据实际业务场景进行“量身订作”的。除了人脸信息外,还会用到人体信息,如人体姿态的估计(体型、服饰)、行为数据(手势、动作)、人体RE-ID特征提取、从人物的声音提取声纹特征,这这些都有助于我们对人物进行属性分析与人物身份判断,我们也在实际工程中用到人脸,人体,声纹这三种信息组成多模态信息识别。
有了多模态识别的基础数据信息,接下来就是多模态技术的算法,如图所呈现的是我们整体算法框架及工程逻辑。
目前,我们人脸别相关算法使用的人脸数据库 ID数达到了550万,可直接识别名字的名人数量达到30万左右,为了支持这么大规模的人物数据训练,我们自研一个定制化分布式框架,虽然也有一些开源的框架,不过更多情况下适合一些简单任务,针对有定制化需求的任务难以满足,所以我们自研的框架无论是整体训练的精度还是训练速度,都可以取得非常大的提升。
我们可以针对模型定型、数据定型,包括GPO、进程的通讯,都进做了优化处理;在识别的精度方面,我们在自己的数据集上进行了评测:第一个数据集是中学生库,数据分布主要集中在证件照或证件照相匹配的实际应用场景;二是爱奇艺员工数据库,是我们内部员工的数据库,里面包含了大量的人脸、姿态、表情等变化;三是爱奇艺在多模态人物识别竞赛中发布的数据集,里面主要是针对明星的视频数据进行身份识别。
实际业务场景中面临非常多人脸属性的相关需求,现在人脸属性已支持到27个,包含常见属性(表情、男女、年龄)和独有的人脸属性,比如说气质、微表情属性。(微表情指的是人脸基本活动单元的一个激活状态,也叫做一个A,目前微表情除了十一个常见的AU基本能源外,我们根据实际业务中有着强需求的类别,比如吐舌头,翻白眼,嘟嘴,眉毛上升进行处理)微表情指的是人脸基本活动单元的一个激活状态,也叫做一个A,目前微表情除了十一个常见的AU基本能源外,我们根据实际业务中有着强需求的类别,比如吐舌头,翻白眼,嘟嘴,眉毛上升进行处理;在这方面,我们提出了一个创新性工作:利用微表情和数据库中的表情包来自动生成视频中的微表情包数据,具体做法是将库中微表情的一个表情包数据来分别提取人脸的微表情特征与表情包文案同时与长视频中取到的人物微表情素材进行匹配,最后再进行文案迁移,来实现表情包的自动生成,这个方法不仅可用于人脸微表情生成,也已经实际用于卡通人物的微表情生成。
面对这么多人脸数据,如何处理噪声是一项非常艰巨的一个任务。图中是我们有一系列噪声的处理流程,以算法为主,人工为辅,将人脸数据集的噪声比例降到了非常低,使模型精度有较大提升。通过模型量化、剪枝、蒸馏等处理优化模型速度,同时对CPU版本进行定制优化,节省了大量资源。
另外,除了已知ID信息,还要充分利用爱奇艺站内视频资来源获取无标签数据辅助人脸模型训练,下面主要讲一下我们如何利用这些无标签数据进行训练,这个相关工作的论文《利用无标签数据优化人脸识别模型》今年发表于被 ICCV 2019 Workshop大会收录。
如果想要所有数据都是已知ID是比较困难的,需要大量人工标注工作,但是获取无标签数据是非常容易的,我们可以获取海量的无标签数据来辅助人脸识别模型训练,主要的一个思路是利用无标签数据填充有标签数据分布的未知区域,使有标签数据分布变得更紧,即有标签数据的分类间隔更大,分类内间隔变紧致,最终获得更好的分类效果,具体做法如下图,令无标签数据得到一个额外的Loss,叠加到之前训练的Loss 中,辅助最终的模型训练。
具体模型与算法解读:Unknown Identity Rejection(UIR)Loss
为了利用无标签数据,我们设计了半监督损失函数,Unknown Identity Rejection(UIR)Loss。人脸识别是open-set问题,将开放环境中的人物类别分为两类:有标签类 和无标签类
,
。训练过程中,对于有标签类,每个样本特征需要逼近分类层对应类别的类心向量;对于无标签类,它不属于分类层的任何一个类,模型需要“拒绝”它们,即特征与每个分类层类心距离都足够远。如下图(a),
表示两个分类层类心向量,圆点表示样本特征。图(b)中,加入无标签类
后,为了
距离
足够远,会使得有标签类别在特征空间上更稀疏,类间距离更大。
对于 CNN 分类模型,全连接分类层的输出经过 softmax 后得到,表示属于各个类别的概率值。然而无标签类别并不属于任何一类,理想情况下
应该都足够小,可以通过设置阈值将其过滤,提升库外拒绝率。基于这个想法,问题可以转化成:
上式是多目标最小化问题,可以转化成:
因此得到UIR loss,即:
模型总的loss是有标签类别的loss加上无标签类别的UIR loss:
模型框图如下,无标签数据和有标签数据一起作为输入,经过骨干网络得到特征,全连接层得到输出概率值,根据概率值分别计算 。
实验结果
我们采用MS-Celeb-1M清洗过后的MS1MV2数据集作为有标签数据,包括9万人物类别的5百万图片数据。从网上爬取数据,经过清洗,基本保证与有标签数据较低的重合率,得到约4.9百万张无标签数据。
分别在iQIYI-VID和Trillion-Pairs和IJB-C三个测试集上验证了方法的有效性。测试了四种骨干网络,实验结果说明,加入无标签数据的UIR loss后,模型性能有所提升。由于篇幅原因,IJB-C测试结果只贴了ResNet100部分,其他结果可参照论文。
二、多模态技术解读(二):虚拟人物识别(iCartoonFace)
基于对真实人物识别的多模态技术的初步认识,接下来介绍在虚拟人物识别的技术与经验。虚拟人物识别包含什么?概括来说虚拟人物识别包含卡通、动漫、游戏人物等所有创作出来的虚拟形象。
虚拟人物识别技术遇到的第一个挑战就是数据源问题,无论是图片数量还是人物身份信息数量,对应用到实际业务中来说都是远远不够的,同时这些数据的标注信息质量也不高,需要我们在前期工作中花费大量的时间进行数据清洗与标注工作。目前我们已经积累了大约四万多个角色,近50万张训练图片,标注精度打98%,标注信息包括位置检测框、姿态、性别、颜色等。
数据整理后进行模型训练,训练过程中有一类数据需要特别关注,如下图所示,模型很难识别差异很小的不同人物与差异很大的同一人物,这种现象在实际的视频中是很常见的一种情况,如何解决这一难点?在实际工程中,我们可以有针对性在模型本身或测试标准上进行特殊处理。
这里借鉴了上述真人识别方法中的一些损失函数,如 Softmax、SphereFace、CasFace、ARCFace等,不断使类内分布更紧密,类间分布差异更大,提高实践应用中判别的准确性。
此外,利用真人数据与卡通数据进行融合来弥补虚拟人物数据不足的现状。如下图中A表示融合之前,B表示与真人人脸融合之后使卡通人物的分布更紧密,同时拉开类间距离,实验数据上也证明了方法的有效性。
相关论文暂未发表,请大家后续继续关注我们的消息。
三、多模态数据库与多模态算法
通过两年的积累,目前爱奇艺基于真实场景中视频任务的多模态数据库已经成为业内首个多模态数据,并且标签清晰,规模最大,致力于给大家的研究工作提供更多的帮助。
基于多模态数据库,利用人脸、人头、人体与声纹四中特征,我们设计了一种多模态识别算法架构,在模型中提出多模型注意力模型,将这四种特种进行融合。
多模态人物识别数据集 iQIYI-VID 下载地址:
http://challenge.ai.iqiyi.com/detail?raceId=5c767dc41a6fa0ccf53922e7.
文章中主要是描述了数据集的收集与标注过程,暂时未涉及到具体的多模态算法,爱奇艺多模态算法的更多信息请持续关注我们的消息,发表后会为大家做详细解读。
有很多研究团队基于此在数据增强、交叉验证和使用无噪声样本进行训练等方面进行了工作的改进。也有工作针对模型架构进行了改进,提出了开放性网络架构,如下图所示,模型主体为全连接层网络,能接收深层次与浅层次间的信息,在两个 dense 层之间加入跳跃连接,将不同层信息进行融合,同时根据 residual block 思路进行改进,加入dropout和batch norm防止过拟合。
四、多模态技术在视频场景中的应用与实践案例:
只看TA与AI 雷达
大家在使用爱奇艺APP过程中可能已经体验过「只看TA」功能了,其次还有 TV端的 AI 雷达功能等,这些大家日常使用的应用背后都离不开多模态数据库与多模态技术算法的支撑。针对大家都很关注的多模态算法问题上, 主要和大家分享以下几点:
1、大家都很关注算法中多模态是如何加权、联合与统一的,而多模态算法是一个非常复杂的问题,而且数据噪声很大,某一机器学习模型可能无法识别所有特征,也不是多有特征都能起到正面作用,因此我们不能只依靠调整权重解决,要从模型学习过程入手,用算法提炼在什么情况什么特征起到关键作用。
2、微表情特征的匹配一个环节是根据人脸的相似度和每个AU的相似度进行匹配;文案匹配是通过网上下载了很多带有文案的表情包,再与视频中提取的表情包进行匹配,如果匹配效果较好,再将文案迁移。
爱奇艺「只看TA 」功能展示
对于上面提到的多项研究论文与数据库感兴趣,大家可以查阅:
论文与论文地址:
《Unknown Identity Rejection Loss: Utilizing Unlabeled Data for Face Recognition》
https://arxiv.org/pdf/1910.10896v1.pdf
《iCartoonFace: A Benchmark of Cartoon Person Recognition》
https://arxiv.org/pdf/1907.13394v1.pdf
《iQIYI-VID: A Large Dataset for Multi-modal Person Identification》
https://arxiv.org/abs/1811.07548
本期公开课回顾学习:
https://edu.csdn.net/huiyiCourse/detail/1075
技术公开课专题页:
https://bss.csdn.net/m/topic/ai_edu
12月公开课,精彩预告
12月11日晚8点:人工智能消化道病理辅助诊断平台——从方法到落地
报名地址:https://edu.csdn.net/huiyiCourse/detail/1111
12月12日晚8点:公司要不要做 AI 中台?开发者要了解的技术
报名地址:https://edu.csdn.net/huiyiCourse/detail/1117
12月17日晚8点:如何设计基于可重构计算的AI芯片,效比与通用性皆有
报名地址:https://edu.csdn.net/huiyiCourse/detail/1112
加入公开课「交流群」获取更多课程、学习资料、岗位招聘等信息
点击[阅读原文],马上报名
相关文章:

JsonObject json字符串转换成JSonObject对象
字符串:{"code":"1004","msg":"请先添加系统靠勤人员信息!","userRegistInfo":{"acc":"小谷","id":0,"phoneMac":"","phoneNum":"…
基于人脸关键点修复人脸,腾讯等提出优于SOTA的LaFIn生成网络
作者 | Yang Yang、Xiaojie Guo、Jiayi Ma、Lin Ma、Haibin Ling译者 | 刘畅编辑 | Jane出品 | AI科技大本营(ID:rgznai100)【导语】现实场景中,人脸的变化是很大的,例如不同的姿势、表情和遮挡等,因此在现…

在Ubuntu上编译opencv 2.4.13源码支持android平台操作步骤
之前在https://blog.csdn.net/fengbingchun/article/details/96430706中编译过opencv源码用于海思平台,这里通过修改脚本编译opencv 2.4.13.6源码,使其支持android平台。 1. 从https://github.com/opencv/opencv/releases下载opencv 2.4.13.6源码&#…
Java组合模式
组合模式:适用于把一组相似的对象当作一个单一的对象,组合迷失一句树形结构来组合对象,用来表示部分以及整体层次。这种类的设计模式属于结构型模式,他创建了对象组的树形结构 这种模式创建了一个包含自己对象组的的类。给类提供了…

SQL故障转移集群操作方法
SQL故障转移集群操作方法1 给SQL服务器配置IP地址,每台服务器需要两个IP,一个通讯用,一个作为心跳线,修改计算机的名称,关闭服务器的防火墙,开启远程桌面.2心跳网卡配置去掉ipv6,并去掉下列几项进行验证3域控制器服务器管理器 添加角色 AD域服务启动AD域服务加入到域中打开DNS服…
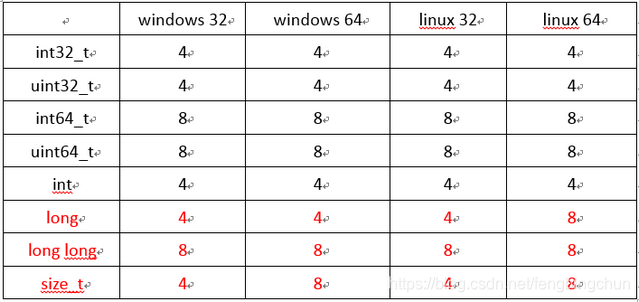
Windows/Linux上使用fopen相关函数读取大文件
在介绍读取大文件之前,先了解下<cstdint>文件,标准头文件,存放固定宽度整数类型,如int32_t, uint32_t,不管在32位上还是64位上,长度都为4个字节;int64_t, uint64_t,不管在32位…
蚂蚁金服提新概率图模型GLN,正确率提升8.2%,具备可解释性 | NeurIPS 2019
作者 | 蚂蚁金服编辑 | Jane出品 | AI科技大本营(ID;rgznai100)【导读】一年一度的国际顶级学术会议NeurIPS 2019将于12月8日至14日在加拿大温哥华举行。作为人工智能和机器学习领域最顶级的盛会之一,每年都会吸引来自全世界的AI大…
Java外观模式
外观模式:隐藏系统的复杂性,并向客户提供了一个客户端可以访问系统的接口,这种类型的设计模式属于结构型模式,他向现有的系统添加一个接口,来隐藏系统的复杂性 这种模式设计到一个单一的类,该类提供了客户请…
【spring框架】spring整合hibernate初步
spring与hibernate做整合的时候,首先我们要获得sessionFactory。我们一般只需要操作一个sessionFactory,也就是一个"单例",这一点很适合交给spring来管理。下面的代码演示如何创建一个JDBC DataSource 和Hibernate SessionFactory:…
PyTorch简介
PyTorch是一个针对深度学习,并且使用GPU和CPU来优化的tensor library(张量库)。最新发布的稳定版本为1.9,源码在https://github.com/pytorch/pytorch 。它支持在Linux、Mac和Windows上编译和运行。调用Python接口可以通过Anaconda或Pip的方式安装&#x…
Java 责任链模式
顾名思义,责任链模式(Chain of Responsibility Pattern)为请求创建了一个接收者对象的链。这种模式给予请求的类型,对请求的发送者和接收者进行解耦。这种类型的设计模式属于行为型模式。 在这种模式中,通常每个接收者…
2019嵌入式智能国际大会圆满落幕,7大专场精彩瞬间释出!
全球第二大市场研究机构MarketsandMarkets报告称,2019年全球AIoT市场规模为51亿美元,到2024年,这一数字将增长至162亿美元。5G元年,人工智能开始更多地转向应用智能。基于此,12月6-7日,由哈尔滨工业大学&am…
ubuntu12.04 alternate win7 双系统安装
ubuntu alternate的安装比desktop复杂一点,因为alternate的安装过程有个步骤是检测cd-rom,如果你是刻盘安装,自然没问题,但是,现在的安装一般是将系统刻到U盘里,或者在硬盘中划出一个分区,将其制作成启动盘. 这里我是用U盘安装的... 安装前的准备: 1)在硬盘上分出一个空闲分区:…

C/C++包管理工具Conan简介
Conan是一个开源的、跨平台的、去中心化的C和C包管理器,它的源码在https://github.com/conan-io/conan ,License为MIT,最新发布版本为1.38.0,由Python实现。版本更新较频繁,但保持向前兼容。 Conan特点: (1…
神经架构搜索在视频理解中研究进展的综述
作者 | Michael S. Ryoo 研究员与 AJ Piergiovanni 学生研究员(Google 机器人团队)来源 | TensorFlow(ID:TensorFlow_official)视频理解一直是项颇具挑战性的难题。视频中包含时空数据,因此要提取特征表示需…
Java命令模式
命令模式(Command Pattern)是一种数据驱动的设计模式,它属于行为型模式。请求以命令的形式包裹在对象中,并传给调用对象。调用对象寻找可以处理该命令的合适的对象,并把该命令传给相应的对象,该对象执行命令…
关于本分类(codeforces-好题系列)
前前后后花了将近半个月,终于将吴神的十场cf的50题目补完了,看到了各种技巧和DP的好题,为了方便以后查阅,新增一个分类便于查找,当然本分类的题目其他分类一般都有,先去吃个饭,回来刷题解转载于…
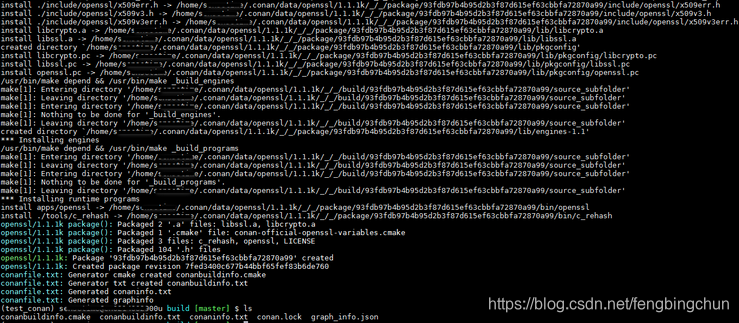
Conan客户端简单使用示例
在https://blog.csdn.net/fengbingchun/article/details/118443862 中对Conan进行了简单介绍,这里调用openssl的接口,写一个简单的test来说明Conan的使用步骤: (1).首先添加一个conanfile.txt文件,内容如下:依赖项为op…
Java解释器模式
解释器模式(Interpreter Pattern)提供了评估语言的语法或表达式的方式,它属于行为型模式。这种模式实现了一个表达式接口,该接口解释一个特定的上下文。这种模式被用在 SQL 解析、符号处理引擎等。 意图:给定一个语言&…
为什么鲜有炫富的程序员?看看中国各阶级收入统计表
网上那些口口声声随随便便就能年入百万的,听听就行。作为开发者,可以不参加双11,但是花钱最多的地方就是买电子产品和“买课”。他们的炫富就是:你根本不知道有多贵的机械键盘,为了赚钱和幸福,又买了多少大…
HQL中的Like查询需要注意的地方
public List getOrgan(String organCode, String organName) { String hsql; List list; if (organCode ! null && organCode.length() > 0) { hsql "from Ab31 where bae002 ? and aab061 like ?"; list getHibernateTemplate().find…

深度神经网络中的Batch Normalization介绍及实现
之前在经典网络DenseNet介绍_fengbingchun的博客-CSDN博客_densenet中介绍DenseNet时,网络中会有BN层,即Batch Normalization,在每个Dense Block中都会有BN参与运算,下面对BN进行介绍并给出C和PyTorch实现。 Batch Normalization即…
韬光养晦的Sony AI,凭什么与Google和Facebook平起平坐?
作者 | 藏狐来源 | 脑极体(ID:unity007)伴随着感恩节气氛的日渐浓重,面对只剩下最后一个月份额的2019,奋进的、错失的,都已尘埃落定,是时候迎来盘点得失、清理思绪的冬藏时节了。整体来看&#…
Java迭代器模式
迭代器模式(Iterator Pattern)是 Java 和 .Net 编程环境中非常常用的设计模式。这种模式用于顺序访问集合对象的元素,不需要知道集合对象的底层表示。 迭代器模式属于行为型模式。 意图:提供一种方法顺序访问一个聚合对象中各个元…
Linux下搭建高效的SVN
第一种安装方式:svn下载:http://archive.apache.org/dist/subversion/需要的包yum install gcc gcc-cyum install expat-develyum install openssl-develhttp://labs.renren.com/apache-mirror//httpd/httpd-2.2.22.tar.gz //最好用2.2版本http://subver…
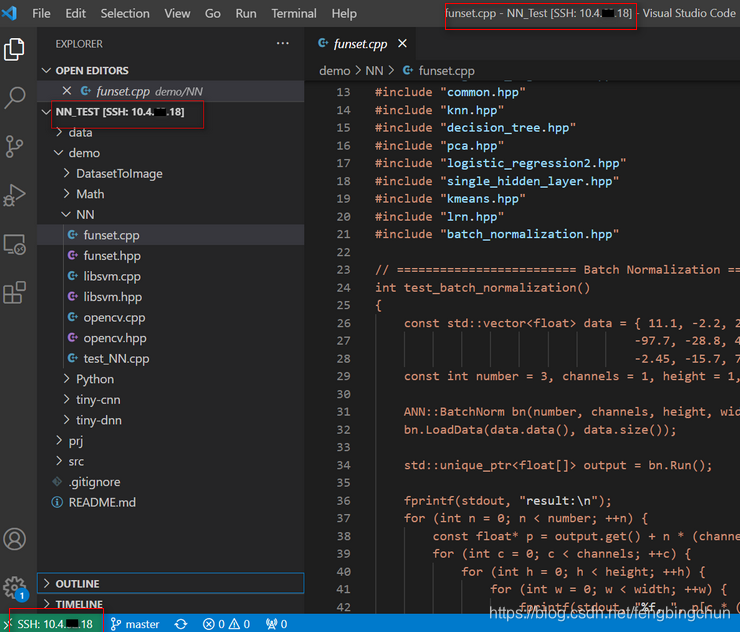
通过Windows10上的VS Code打开远端Ubuntu上的项目操作步骤
Ubuntu版本要求是16.04及以上版本。这里以16.04为例。 在Ubuntu上安装OpenSSH server,执行:$ sudo apt-get install openssh-server 在Windows 10 1803上安装Windows OpenSSH Client(注:Windows早期版本则需要安装Git for Windows)࿱…
Java中介者模式
中介者模式(Mediator Pattern)是用来降低多个对象和类之间的通信复杂性。这种模式提供了一个中介类,该类通常处理不同类之间的通信,并支持松耦合,使代码易于维护。中介者模式属于行为型模式。 意图:用一个中…
那些打着AI万金油旗号的产品欺骗大众,如何识别?
作者 | Arvind Narayanan译者 | 刘畅出品 | AI科技大本营(ID:rgznai100)如今,很多打着AI名号售出的产品都属于万金油系列,没什么实质性的功能。为什么会这样?我们应该如何识别这类AI?幻灯片上是评估性格和工…

分享一款jQuery全屏滚动页面特性案例
分享一款jQuery全屏滚动页面特性案例。我们在来往官网,或者小米官网都会看到全屏滚动页面的一些例子。可以说全屏滚动页面越来越受欢迎。它们就像是竖着的图片轮转一样。这样的页面有很多,如:iPhone 5C页面:http://www.dowebok.co…
后深度学习时代的一大研究热点?论因果关系及其构建思路
作者 | Bernhard Schlkopf译者 | Kolen编辑 | Jane出品 | AI科技大本营(ID:rgznai100)尽管机器学习在现阶段取得了很大成功,但是相比于动物所能完成的工作,机器学习在动物擅长的关键技术上表现不尽人意,比如…