PyTorch实现L2和L1正则化的方法 | CSDN博文精选
作者 | pan_jinquan
来源 | CSDN博文精选
目录
1.torch.optim优化器实现L2正则化
2.如何判断正则化作用了模型?
2.1未加入正则化loss和Accuracy
2.1加入正则化loss和Accuracy
2.3正则化说明
3.自定义正则化的方法
3.1自定义正则化Regularization类
3.2Regularization使用方法
4.Github项目源码下载
1.torch.optim优化器实现L2正则化
torch.optim集成了很多优化器,如SGD,Adadelta,Adam,Adagrad,RMSprop等,这些优化器自带的一个参数weight_decay,用于指定权值衰减率,相当于L2正则化中的λ参数,注意torch.optim集成的优化器只有L2正则化方法,你可以查看注释,参数weight_decay 的解析是:
weight_decay (float, optional): weight decay (L2 penalty) (default: 0)
使用torch.optim的优化器,可如下设置L2正则化
optimizer = optim.Adam(model.parameters(),lr=learning_rate,weight_decay=0.01)
但是这种方法存在几个问题,
(1)一般正则化,只是对模型的权重W参数进行惩罚,而偏置参数b是不进行惩罚的,而torch.optim的优化器weight_decay参数指定的权值衰减是对网络中的所有参数,包括权值w和偏置b同时进行惩罚。很多时候如果对b 进行L2正则化将会导致严重的欠拟合,因此这个时候一般只需要对权值w进行正则即可。(PS:这个我真不确定,源码解析是 weight decay (L2 penalty) ,但有些网友说这种方法会对参数偏置b也进行惩罚,可解惑的网友给个明确的答复)
(2)缺点:torch.optim的优化器固定实现L2正则化,不能实现L1正则化。如果需要L1正则化,可如下实现:
(3)根据正则化的公式,加入正则化后,loss会变原来大,比如weight_decay=1的loss为10,那么weight_decay=100时,loss输出应该也提高100倍左右。而采用torch.optim的优化器的方法,如果你依然采用loss_fun= nn.CrossEntropyLoss()进行计算loss,你会发现,不管你怎么改变weight_decay的大小,loss会跟之前没有加正则化的大小差不多。这是因为你的loss_fun损失函数没有把权重W的损失加上。
(4)采用torch.optim的优化器实现正则化的方法,是没问题的!只不过很容易让人产生误解,对鄙人而言,我更喜欢TensorFlow的正则化实现方法,只需要tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES),实现过程几乎跟正则化的公式对应的上。
(5)Github项目源码:
https://github.com/PanJinquan/pytorch-learning-tutorials/blob/master/image_classification/train_resNet.py,麻烦给个“Star”
为了,解决这些问题,我特定自定义正则化的方法,类似于TensorFlow正则化实现方法。
2.如何判断正则化作用了模型?
一般来说,正则化的主要作用是避免模型产生过拟合,当然啦,过拟合问题,有时候是难以判断的。但是,要判断正则化是否作用了模型,还是很容易的。下面我给出两组训练时产生的loss和Accuracy的log信息,一组是未加入正则化的,一组是加入正则化:
2.1未加入正则化loss和Accuracy
优化器采用Adam,并且设置参数weight_decay=0.0,即无正则化的方法
optimizer = optim.Adam(model.parameters(),lr=learning_rate,weight_decay=0.0)
训练时输出的 loss和Accuracy信息
step/epoch:0/0,Train Loss: 2.418065, Acc: [0.15625]step/epoch:10/0,Train Loss: 5.194936, Acc: [0.34375]step/epoch:20/0,Train Loss: 0.973226, Acc: [0.8125]step/epoch:30/0,Train Loss: 1.215165, Acc: [0.65625]step/epoch:40/0,Train Loss: 1.808068, Acc: [0.65625]step/epoch:50/0,Train Loss: 1.661446, Acc: [0.625]step/epoch:60/0,Train Loss: 1.552345, Acc: [0.6875]step/epoch:70/0,Train Loss: 1.052912, Acc: [0.71875]step/epoch:80/0,Train Loss: 0.910738, Acc: [0.75]step/epoch:90/0,Train Loss: 1.142454, Acc: [0.6875]step/epoch:100/0,Train Loss: 0.546968, Acc: [0.84375]step/epoch:110/0,Train Loss: 0.415631, Acc: [0.9375]step/epoch:120/0,Train Loss: 0.533164, Acc: [0.78125]step/epoch:130/0,Train Loss: 0.956079, Acc: [0.6875]step/epoch:140/0,Train Loss: 0.711397, Acc: [0.8125]
2.2 加入正则化loss和Accuracy
优化器采用Adam,并且设置参数weight_decay=10.0,即正则化的权重lambda =10.0
optimizer = optim.Adam(model.parameters(),lr=learning_rate,weight_decay=10.0)
这时,训练时输出的 loss和Accuracy信息:
step/epoch:0/0,Train Loss: 2.467985, Acc: [0.09375]step/epoch:10/0,Train Loss: 5.435320, Acc: [0.40625]step/epoch:20/0,Train Loss: 1.395482, Acc: [0.625]step/epoch:30/0,Train Loss: 1.128281, Acc: [0.6875]step/epoch:40/0,Train Loss: 1.135289, Acc: [0.6875]step/epoch:50/0,Train Loss: 1.455040, Acc: [0.5625]step/epoch:60/0,Train Loss: 1.023273, Acc: [0.65625]step/epoch:70/0,Train Loss: 0.855008, Acc: [0.65625]step/epoch:80/0,Train Loss: 1.006449, Acc: [0.71875]step/epoch:90/0,Train Loss: 0.939148, Acc: [0.625]step/epoch:100/0,Train Loss: 0.851593, Acc: [0.6875]step/epoch:110/0,Train Loss: 1.093970, Acc: [0.59375]step/epoch:120/0,Train Loss: 1.699520, Acc: [0.625]step/epoch:130/0,Train Loss: 0.861444, Acc: [0.75]step/epoch:140/0,Train Loss: 0.927656, Acc: [0.625]
当weight_decay=10000.0
step/epoch:0/0,Train Loss: 2.337354, Acc: [0.15625]step/epoch:10/0,Train Loss: 2.222203, Acc: [0.125]step/epoch:20/0,Train Loss: 2.184257, Acc: [0.3125]step/epoch:30/0,Train Loss: 2.116977, Acc: [0.5]step/epoch:40/0,Train Loss: 2.168895, Acc: [0.375]step/epoch:50/0,Train Loss: 2.221143, Acc: [0.1875]step/epoch:60/0,Train Loss: 2.189801, Acc: [0.25]step/epoch:70/0,Train Loss: 2.209837, Acc: [0.125]step/epoch:80/0,Train Loss: 2.202038, Acc: [0.34375]step/epoch:90/0,Train Loss: 2.192546, Acc: [0.25]step/epoch:100/0,Train Loss: 2.215488, Acc: [0.25]step/epoch:110/0,Train Loss: 2.169323, Acc: [0.15625]step/epoch:120/0,Train Loss: 2.166457, Acc: [0.3125]step/epoch:130/0,Train Loss: 2.144773, Acc: [0.40625]step/epoch:140/0,Train Loss: 2.173397, Acc: [0.28125]
2.3 正则化说明
就整体而言,对比加入正则化和未加入正则化的模型,训练输出的loss和Accuracy信息,我们可以发现,加入正则化后,loss下降的速度会变慢,准确率Accuracy的上升速度会变慢,并且未加入正则化模型的loss和Accuracy的浮动比较大(或者方差比较大),而加入正则化的模型训练loss和Accuracy,表现的比较平滑。并且随着正则化的权重lambda越大,表现的更加平滑。这其实就是正则化的对模型的惩罚作用,通过正则化可以使得模型表现的更加平滑,即通过正则化可以有效解决模型过拟合的问题。
3.自定义正则化的方法
为了解决torch.optim优化器只能实现L2正则化以及惩罚网络中的所有参数的缺陷,这里实现类似于TensorFlow正则化的方法。
3.1 自定义正则化Regularization类
这里封装成一个实现正则化的Regularization类,各个方法都给出了注释,自己慢慢看吧,有问题再留言吧。
# 检查GPU是否可用device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# device='cuda'print("-----device:{}".format(device))print("-----Pytorch version:{}".format(torch.__version__))class Regularization(torch.nn.Module): def __init__(self,model,weight_decay,p=2): ''' :param model 模型 :param weight_decay:正则化参数 :param p: 范数计算中的幂指数值,默认求2范数, 当p=0为L2正则化,p=1为L1正则化 ''' super(Regularization, self).__init__() if weight_decay <= 0: print("param weight_decay can not <=0") exit(0) self.model=model self.weight_decay=weight_decay self.p=p self.weight_list=self.get_weight(model) self.weight_info(self.weight_list) def to(self,device): ''' 指定运行模式 :param device: cude or cpu :return: ''' self.device=device super().to(device) return self def forward(self, model): self.weight_list=self.get_weight(model)#获得最新的权重 reg_loss = self.regularization_loss(self.weight_list, self.weight_decay, p=self.p) return reg_loss def get_weight(self,model): ''' 获得模型的权重列表 :param model: :return: ''' weight_list = [] for name, param in model.named_parameters(): if 'weight' in name: weight = (name, param) weight_list.append(weight) return weight_list def regularization_loss(self,weight_list, weight_decay, p=2): ''' 计算张量范数 :param weight_list: :param p: 范数计算中的幂指数值,默认求2范数 :param weight_decay: :return: ''' # weight_decay=Variable(torch.FloatTensor([weight_decay]).to(self.device),requires_grad=True) # reg_loss=Variable(torch.FloatTensor([0.]).to(self.device),requires_grad=True) # weight_decay=torch.FloatTensor([weight_decay]).to(self.device) # reg_loss=torch.FloatTensor([0.]).to(self.device) reg_loss=0 for name, w in weight_list: l2_reg = torch.norm(w, p=p) reg_loss = reg_loss + l2_reg reg_loss=weight_decay*reg_loss return reg_loss def weight_info(self,weight_list): ''' 打印权重列表信息 :param weight_list: :return: ''' print("---------------regularization weight---------------") for name ,w in weight_list: print(name) print("---------------------------------------------------")
3.2 Regularization使用方法
使用方法很简单,就当一个普通Pytorch模块来使用:例如
# 检查GPU是否可用device = torch.device("cuda" if torch.cuda.is_available() else "cpu")print("-----device:{}".format(device))print("-----Pytorch version:{}".format(torch.__version__))weight_decay=100.0 # 正则化参数model = my_net().to(device)# 初始化正则化if weight_decay>0: reg_loss=Regularization(model, weight_decay, p=2).to(device)else: print("no regularization")criterion= nn.CrossEntropyLoss().to(device) # CrossEntropyLoss=softmax+cross entropyoptimizer = optim.Adam(model.parameters(),lr=learning_rate)#不需要指定参数weight_decay# trainbatch_train_data=...batch_train_label=...out = model(batch_train_data)# loss and regularizationloss = criterion(input=out, target=batch_train_label)if weight_decay > 0: loss = loss + reg_loss(model)total_loss = loss.item()# backpropoptimizer.zero_grad()#清除当前所有的累积梯度total_loss.backward()optimizer.step()
训练时输出的 loss和Accuracy信息:
(1)当weight_decay=0.0时,未使用正则化
step/epoch:0/0,Train Loss: 2.379627, Acc: [0.09375]step/epoch:10/0,Train Loss: 1.473092, Acc: [0.6875]step/epoch:20/0,Train Loss: 0.931847, Acc: [0.8125]step/epoch:30/0,Train Loss: 0.625494, Acc: [0.875]step/epoch:40/0,Train Loss: 2.241885, Acc: [0.53125]step/epoch:50/0,Train Loss: 1.132131, Acc: [0.6875]step/epoch:60/0,Train Loss: 0.493038, Acc: [0.8125]step/epoch:70/0,Train Loss: 0.819410, Acc: [0.78125]step/epoch:80/0,Train Loss: 0.996497, Acc: [0.71875]step/epoch:90/0,Train Loss: 0.474205, Acc: [0.8125]step/epoch:100/0,Train Loss: 0.744587, Acc: [0.8125]step/epoch:110/0,Train Loss: 0.502217, Acc: [0.78125]step/epoch:120/0,Train Loss: 0.531865, Acc: [0.8125]step/epoch:130/0,Train Loss: 1.016807, Acc: [0.875]step/epoch:140/0,Train Loss: 0.411701, Acc: [0.84375]
(2)当weight_decay=10.0时,使用正则化
---------------------------------------------------step/epoch:0/0,Train Loss: 1563.402832, Acc: [0.09375]step/epoch:10/0,Train Loss: 1530.002686, Acc: [0.53125]step/epoch:20/0,Train Loss: 1495.115234, Acc: [0.71875]step/epoch:30/0,Train Loss: 1461.114136, Acc: [0.78125]step/epoch:40/0,Train Loss: 1427.868164, Acc: [0.6875]step/epoch:50/0,Train Loss: 1395.430054, Acc: [0.6875]step/epoch:60/0,Train Loss: 1363.358154, Acc: [0.5625]step/epoch:70/0,Train Loss: 1331.439697, Acc: [0.75]step/epoch:80/0,Train Loss: 1301.334106, Acc: [0.625]step/epoch:90/0,Train Loss: 1271.505005, Acc: [0.6875]step/epoch:100/0,Train Loss: 1242.488647, Acc: [0.75]step/epoch:110/0,Train Loss: 1214.184204, Acc: [0.59375]step/epoch:120/0,Train Loss: 1186.174561, Acc: [0.71875]step/epoch:130/0,Train Loss: 1159.148438, Acc: [0.78125]step/epoch:140/0,Train Loss: 1133.020020, Acc: [0.65625]
(3)当weight_decay=10000.0时,使用正则化
step/epoch:0/0,Train Loss: 1570211.500000, Acc: [0.09375]step/epoch:10/0,Train Loss: 1522952.125000, Acc: [0.3125]step/epoch:20/0,Train Loss: 1486256.125000, Acc: [0.125]step/epoch:30/0,Train Loss: 1451671.500000, Acc: [0.25]step/epoch:40/0,Train Loss: 1418959.750000, Acc: [0.15625]step/epoch:50/0,Train Loss: 1387154.000000, Acc: [0.125]step/epoch:60/0,Train Loss: 1355917.500000, Acc: [0.125]step/epoch:70/0,Train Loss: 1325379.500000, Acc: [0.125]step/epoch:80/0,Train Loss: 1295454.125000, Acc: [0.3125]step/epoch:90/0,Train Loss: 1266115.375000, Acc: [0.15625]step/epoch:100/0,Train Loss: 1237341.000000, Acc: [0.0625]step/epoch:110/0,Train Loss: 1209186.500000, Acc: [0.125]step/epoch:120/0,Train Loss: 1181584.250000, Acc: [0.125]step/epoch:130/0,Train Loss: 1154600.125000, Acc: [0.1875]step/epoch:140/0,Train Loss: 1128239.875000, Acc: [0.125]
对比torch.optim优化器的实现L2正则化方法,这种Regularization类的方法也同样达到正则化的效果,并且与TensorFlow类似,loss把正则化的损失也计算了。
此外更改参数p,如当p=0表示L2正则化,p=1表示L1正则化。
4.Github项目源码下载
《Github项目源码》https://github.com/PanJinquan/pytorch-learning-tutorials/blob/master/image_classification/train_resNet.py
麻烦给个“Star”~~
技术的道路一个人走着极为艰难?
一身的本领得不施展?
优质的文章得不到曝光?
别担心,
即刻起,CSDN 将为你带来创新创造创变展现的大舞台,
扫描下方二维码,欢迎加入 CSDN 「原力计划」!
(*本文为AI科技大本营转载文章,转载请联系原作者)
◆
精彩公开课
◆
推荐阅读
GitHub宝藏项目标星1.6w+,编程新手有福了
芬兰开放“线上AI速成班”课程,全球网民均可免费观看
英特尔首推异构编程神器 oneAPI,可让程序员少加班!
该如何缓解网卡的普遍问题?
英特尔首推异构编程神器 oneAPI,可让程序员少加班!
马云穿布鞋演讲,任正非打的出行,盘点科技大佬们令人发指的节俭生活
行!人工智能玩大了!程序员:太牛!你怎么看?
2019 区块链大事记 | Libra 横空出世,莱特币减产,美国放行 Bakkt……这一年太精彩!
谁是蒋涛?
你点的每个“在看”,我都认真当成了AI
相关文章:

构建插件式的应用程序框架(六)----通讯机制(ZT)
前天发了构建插件式的应用程序框架(五)----管理插件这篇文章,有几个朋友在回复中希望了解插件之间是如何通讯的。这个系列的文章写到这里,也该谈谈这个问题了,毕竟已经有了插件管理。不知道大家…

【翻译】将Ext JS Grid转换为Excel表格
原文:Converting an Ext 5 Grid to Excel Spreadsheet稍微迟来的礼物——Ext JS Grid转为Excel代码,现在支持Ext JS 5!功能包括: - 支持分组 - 数字的处理 VS 字符串数据类型 - 对于不支持客户端下载的浏览器会提交回服务器Enjoy&…
AI研究过于集中狭隘,我们是不是该反思了?
作者 | Sergii Shelpuk译者 | 陆离编辑 | 夕颜出品 | AI科技大本营(ID: rgznai100)【导读】2019年是AI领域更加冷静的一年,少了些喧嚣和泡沫,大浪淘沙留下的是经过检验的真正的AI研究者、实践者。但是你也许没有发现,本…
上周回顾:微软与苹果比赛谁更“不安全”
每个月的第二周应该是微软例行发布补丁的日子,本周也不例外,微软如定期新闻发布会一样公布了自己的安全公告。这本来已经成了例如51CTO.com这样关注企业网络安全的媒体重要的素材,不过没想到的是本周苹果偏要抢这个风头……热点一:…

一种注册表沙箱的思路、实现——注册表的一些基础知识
要做注册表沙箱,就必须要了解部分注册表知识。而注册表的知识很多,本文主要讲述如何在win32系统是上识别注册表映射的。(转载请指明出处) 在我的xp 32bit系统上,WinR regedit之后打开注册表管理器。我们可以看到如下主…
bzoj 2565: 最长双回文串 manacher算法
2565: 最长双回文串 Time Limit: 20 Sec Memory Limit: 256 MB 题目连接 http://www.lydsy.com/JudgeOnline/problem.php?id2565 Description 顺序和逆序读起来完全一样的串叫做回文串。比如acbca是回文串,而abc不是(abc的顺序为“abc”,逆…
44岁的微软如何刷新未来?
整理 | 伍杏玲出品 | AI科技大本营(ID:rgznai100)在当今的“云”时代,很多企业在多个云计算平台部署应用,且需要统一管理和保护应用。在微软Ignite 2019 大会上,为了让企业轻松地在任何类型的基础设施平台上…
一种注册表沙箱的思路、实现——Hook Nt函数
Nt函数是在Ring3层最底层的函数了,选择此类函数进行Hook,是为了提高绕过门槛。我的Hook方案使用的是微软的Detours。(转载请指明出处)Detours的Hook和反Hook的写入如下: DetourTransactionBegin(); DetourUpdateThread…

浅析Struts 体系结构与工作原理(图)
Struts 体系结构是目前基于java的 web系统设计中广泛使用的mvc构架。基本概念 Struts是Apache 基金会Jakarta 项目组的一个Open Source 项目,它采用模型-视图-控制器(Model-View- Controller,简称MVC)模式,能够…
2015第22周一Web性能测试工具及IE扩展区别
在高性能web测试工具推荐http://www.jb51.net/article/23034.htm中发现了dynaTrace 感觉很不错,不但可以检测资源加载瀑布图,而且还能监控页面呈现时间,CPU花销,JS分析和执行时间,CSS解析时间的等。http://www.ibm.com…
一种注册表沙箱的思路、实现——研究Reactos中注册表函数的实现1
因为我们沙箱注入了一个DLL到了目标进程,并且Hook了一系列NtXX(NtOpenKey)函数,所以我们在注入的代码中是不能使用RegXX(RegOpenKey等)这类函数的。因为RegXX系列函数在底层使用了NtXX系列函数,如果在注入DLL执行Hook后的逻辑中使用了RegXX系…
面试大厂背怼!这都搞不定,你只能做“搬运工”!
每一个面试过大厂的程序员似乎总会有种种困境:毕业季参加大厂校招面试,我本以为做过一些真实项目就不错了,没想到根本没问什么项目,都是基础知识,数学、算法,然而平时只喜欢学程序设计。小公司工作3年&…
net程序架构开发
< DOCTYPE html PUBLIC -WCDTD XHTML StrictEN httpwwwworgTRxhtmlDTDxhtml-strictdtd> 程序架构,功能的划分: 数据库(包括存储过程) 数据访问(包括Microsoft Application Blocks for .NET的2.0版) 数据结构(等价于强类型DataSet) 业务逻辑层 业务表现层 数据库:不用说…
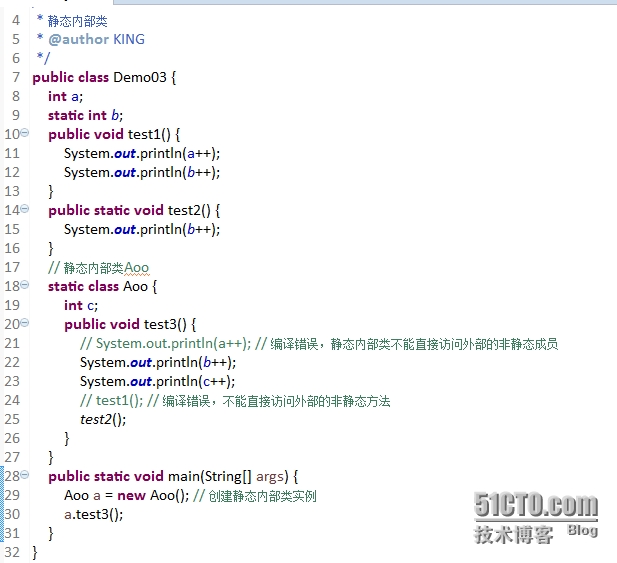
Java面向对象学习笔记 -- 6(内部类、Timer)
1. 内部类内部类就是在一个类的内部定义的类,有:静态内部类、成员内部类,局部内部类、匿名内部类。-1) 静态内部类:使用static修饰,声明在类体中, 静态内部类中可以访问外部类的静态成员,开发很…
30年间,软件开发行业为何Bug纷飞?
作者 | Chris Fox译者 | 弯月,责编 | 屠敏出品 | CSDN(ID:CSDNnews)【导语】在时间的推移历程中,软件行业早已发生了天翻地覆的变化。和曾经大家习以为常的编码日常相比,越多越多的开发者发现,如…
去掉字符串两端的全角空格和半角空格(含源代码)
昨天,遇到了一个技术问题。本来我在程序中用的trim()方法来处理从JSP页面传来的值,后来在测试时,发现当我输入的是全角空格时,trim()方法失效。需求是这样的,只是去掉字符串两端的空格(不论是全角空格还是半角空格&…
一种注册表沙箱的思路、实现——研究Reactos中注册表函数的实现2
上一篇博文中主要介绍了Reactos中大部分函数的思路和HKEY和HANDLE之间的关系,本文将介绍一些Reactos中有意思的函数和存在bug的函数。(转载请指明出处)CreateNestedKey是一个辅助创建键的函数,比如我们要创建\Regsitry\User\3\2\1…
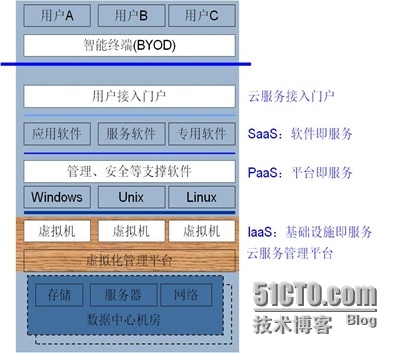
云计算安全解决方案白皮书(一)
云计算安全解决方案白皮书Jack zhai研究云的安全有两三年了,但形成完整的安全思路,还是去年的事,这也是“流安全”思路形成的主要阶段。云计算的安全问题之所以突出,是因为虚拟机的动态迁移,以及多业务系统交织在一起&…
一种注册表沙箱的思路、实现——研究Reactos中注册表函数的实现3
这篇我们看一个”容错“”节省“的实例。一下是一个Win32API的声明(转载请指明出处) LONG WINAPI RegEnumKeyEx(__in HKEY hKey,__in DWORD dwIndex,__out LPTSTR lpName,__inout LPDWORD lpcName,__reserved LPDWORD lp…
腾讯Angel升级:加入图算法,支持十亿节点、千亿边规模!中国首个毕业于Linux AI基金会的开源项目...
出品 | AI科技大本营(ID:rgznai100)【导语】Angel 是腾讯的首个AI开源项目,于 2016 年底推出、2017年开源。近日,快速发展的 Angel 完成了从 2.0 版本到 3.0 版本的跨越,从一个单纯的模型训练系统进化成包…
如何在JSP页面中获取当前系统时间转
出自:http://hi.baidu.com/itfuck_/item/803662469cdf7baa61d7b945 1: import java.util.*; int y,m,d,h,mm; Calendar c Calendar.getInstance(); y c.get(Calendar.YEAR); //年 m c.get(Calendar.MONTH) 1; //月 d c.get(Calendar.DAY_OF_MONTH); //日 …
如何用Python实现超级玛丽的界面和状态机?
作者 | marble_xu编辑 | 郭芮来源 | CSDN博客小时候的经典游戏,代码参考了github上的项目Mario-Level-1(https://github.com/justinmeister/Mario-Level-1),使用pygame来实现,从中学习到了横版过关游戏实现中的一些处理…
一种注册表沙箱的思路、实现——研究Reactos中注册表函数的实现4
今天为了KPI,搞了一天的PPT,搞得恶心想吐。最后还是回到这儿,这儿才是我的净土,可以写写我的研究。 这儿讲一些Reactos中一些明显的错误。(转载请指明出处) 在Reactos的RegQueryInfoKeyW中有段这样的实现 i…
Netscaler 认证,访问报http 5000 内部错误
在VDI项目中,Netscaler经常与AD不在同一网络,有时在icaprofile中写的SF或WI的FQDN,访问VDI,会报http 5000 内部错误;解决办法如下:1.NS无法解析Storefont或WI的主机名,需要修改icaprofile 中SF或…
解读 | 2019年10篇计算机视觉精选论文(中)
导读:2019 年转眼已经接近尾声,我们看到,这一年计算机视觉(CV)领域又诞生了大量出色的论文,提出了许多新颖的架构和方法,进一步提高了视觉系统的感知和生成能力。因此,我们精选了 20…

PE文件和COFF文件格式分析--概述
刚工作的时候,我听说某某大牛在做病毒分析时,只是用notepad打开病毒文件,就能大致猜到病毒的工作原理。当时我是佩服的很啊,同时我也在心中埋下了一个种子:我也得有这天。随着后来的工作进行,一些任务的和这…
2015第22周六Java反射、泛型、容器简介
Java的反射非常强大,传递class, 可以动态的生成该类、取得这个类的所有信息,包括里面的属性、方法以及构造函数等,甚至可以取得其父类或父接口里面的内容。 obj.getClass().getDeclaredMethods();//取得obj类中自己定义的方法&…

中服公司企业信息化的ERP系统选择
中服公司企业信息化的ERP系统选择一、 中服公司概况 1. 组织概况 中服公司创建于1950年9月,是国家120家企业集团试点单位之一,主要经营各类纺织原料、半成品、服装、针棉毛织品以及其他商品的进出口业务,同时通过合资、联营等方…

PE文件和COFF文件格式分析--MS-DOS 2.0兼容Exe文件段
MS 2.0节是PE文件格式中第一个“节”。其大致结构如下:(转载请指明来源于breaksoftware的csdn博客) 在VC\PlatformSDK\Include\WinNT.h文件中有对MS-DOS 2.0兼容EXE文件头的完整定义 typedef struct _IMAGE_DOS_HEADER { // DOS .EXE h…
时间可以是二维的?基于二维时间图的视频内容片段检测 | AAAI 2020
作者 | 彭厚文、傅建龙来源 | 微软研究院AI头条(ID: MSRAsia)编者按:当时间从一维走向二维,时序信息处理问题中一种全新的建模思路由此产生。根据这种新思路及其产生的二维时间图概念,微软亚洲研究院提出一种新的解决时…