时间可以是二维的?基于二维时间图的视频内容片段检测 | AAAI 2020
作者 | 彭厚文、傅建龙
来源 | 微软研究院AI头条(ID: MSRAsia)
编者按:当时间从一维走向二维,时序信息处理问题中一种全新的建模思路由此产生。根据这种新思路及其产生的二维时间图概念,微软亚洲研究院提出一种新的解决时间定位问题的通用方法:二维时域邻近网络 2D-TAN,在基于自然语言描述的视频内容定位和视频内人体动作检测两个任务上验证了其有效性,并在 ICCV 2019 中的 HACS Action Localization Challenge 比赛中获得了第一,相关技术细节将发表于 AAAI 2020 论文“Learning 2D Temporal Adjacent Network for Moment Localization with Natural Language”。本文将对这一研究进行深入解读。
时间可以是二维的吗?这是一个好问题!
我们常常将物理世界定义为三维空间,将时间定义为一维空间。但是,这不是唯一的定义方式。最近,研究院的童鞋们大开脑洞,提出了一种新的时间表示方式,将时间定义成了二维的!
在二维空间里,时间是如何表达的呢?童鞋们给出的答案是这样的:在二维空间中,我们定义其中一个维度表示时间的开始时刻,另外一个维度表示时间的结束时刻;从而,二维空间中的每一个坐标点就可以表达一个时间片段(例如,从 A 时刻开始到 B 时刻结束的时间片),也可以是一个特定的时间点(例如,从 A 时刻开到 A 时刻结束,即为 A 时刻)。
这种二维时间定义的用途和意义在哪里呢?童鞋们认为这种新的时间定义方式,可以为时序信息处理问题提供一种新的建模思路,例如视频、语音、轨迹等时序信息的分析与处理。近期,他们已将这种新的时间表达方式,应用于视频内容理解中,并在视频内人体动作检测、视频内容片段定位任务中取得了优异的性能。值得一提的是,他们应用这种新的时间表达方式,结合最新的深度学习模型,在视频行为识别与检测竞赛(HACS Temporal Action Localization Challenge)中取得了第1名的成绩。
下面,就让我们了解一下这种二维时间表达方式是如何应用在视频内容理解任务中的。
基于二维时间图的视频内容片段定位
视频内容片段定位包含多个子任务,例如,基于自然语言描述的视频片段定位(moment localization with natural language)与视频内人体动作检测(temporal action localization)。前者需要根据用户给定的描述语句,从视频中定位文字所描述的视频片段的开始和结束时间点;后者则需要在给定的长视频中,检测出其存在的动作片段类别,并定位出动作开始和结束的时间点。
在这些任务中,一个通用的做法是预先设定一些候选视频片段(proposals/moments/ segments),再对每个片段的可能性进行相应的预测。然而在预测过程中,前人的工作通常只是对每个片段独立预测,却忽略了片段之间的依赖关系。为此,本文提出了二维时间图的概念,并通过二维时域邻近网络(2D Temporal Adjacent Network, i.e. 2D-TAN)来解决这一问题。该方法是一个解决时间定位问题的通用方法,不仅可以学习出片段之间的时域邻近关系,同时也能学习出更具有区分性的特征表达。
我们的方法在上述的视频内容片段定位任务上进行了验证。在基于自然语言描述的视频片段定位任务中,我们提出的 2D-TAN 方法在三个基准数据集均获得了良好的性能结果,相关论文已经被 AAAI 2020 接收[1]。在视频内人体动作检测中,我们基于 2D-TAN 的改进方案[2]在 HACS Temporal Action Localization Challenge 中获得第一。
下面以自然语言描述的视频内容片段定位为例介绍我们的工作,并简要介绍人体动作检测方面的拓展。
基于自然语言描述的视频片段定位
基于自然语言描述的视频片段定位任务是根据用户给定的描述语句,从视频中定位文字所描述的视频片段,并返回该片段的开始和结束时间,如图1所示。前人的工作都是独立地匹配句子和一个片段,而忽略了其他片段对其影响。当要处理涉及多片段的情况,尤其是片段之间存在依赖关系的时候,这种做法很难得到精确的结果。例如,当我们要定位“这个人又吹起了萨克斯 The guy plays the saxophone again”,如果只看后面的视频而不看前面的,我们不可能在视频中定位到这个片段。另一方面,有很多候选片段都与目标片段有重叠,例如图1中 Query B 下面所对应的多种片段。这些片段有着相似的视频内容,但是语义上会略有所不同。如果不将这些片段综合考虑来区分其中的细微差别,同样很难得到精确的结果。
图1:任务示意图。在二维时间图中,黑色坐标轴上的数字表示开始和结束的序号,灰色坐标轴上的数字表示序号所对应的时间点。二维时间图中方格的红色程度反映该片段与目标片段的重叠程度,取决于视频长度及采样比例。
为解决这一问题,我们提出了二维时域邻近网络(2D-TAN)。其核心思想是在二维时间图中做视频片段定位,如图1所示。具体来说,图中(i,j)表示的是一个从 i 到 (j+1) 的时间片段。该图包含多种长度的片段,并通过图中坐标的远近,我们可以定义这些片段之间的邻近关系。有了这些关系,我们的 2D-TAN 模型便可以对依赖关系进行建模。与此同时,不同片段与目标片段之间的重叠程度会有所不同。2D-TAN 通过整体考虑这些重叠上的差异,而非单独考虑每个片段,可以学习更具有区分性的特征,如图2。
图2:与前人方法的对比。绿色长方体表示候选片段与句子融合后的相似度特征。方框表示得分,方框红色的程度表示该片段与目标片段的重叠程度。左图表示前人的方法,独立预测各个片段的得分。右图表示我们的方法,预测当前片段的得分时,综合考虑了邻近片段的关系。
二维时域邻近网络(2D-TAN)
我们的 2D-TAN 模型如图3所示。该网络由三部分构成:一个用来提取自然语言文本特征的编码器,一个用来提取视频特征图的编码器,及一个用来定位的时域邻近网络。我们在下文具体介绍各部分。
图3:2D-TAN的框架示意图
语句的文本特征
我们将每个文本单词转换成 GloVe 词向量表达[4],再将词向量依次通过 LSTM 网络[5],使用其最后一层输出作为文本语句的特征。
视频的二维特征图
我们首先将视频分割成小的单元片段(clip),之后等距降采样到统一长度,再通过预训练好的网络抽取其特征。抽取好的特征通过卷积、池化操作获得最终的单元片段特征(clip feature),大小是 N×d^v。候选片段由一段连续的单元片段构成,不同候选片段长度可能会不同。为获得统一的特征表示,对于每一个候选片段,我们通过对其相应的单元片段序列最大池化(max-pooling)获得其最终特证。根据每个候选片段的始末时间点,我们将所有的候选片段重新排列成一个二维特征图,大小是 N×N×d^v。因为开始时间永远小于结束时间,特征图的下三角部分是无效的,因此我们将它们填充成0,且不参与后续的计算。
当 N 较大时,特征图的计算量也会随之增大,为解决此问题,我们还提出了一种稀疏图的构造策略,如图4所示。在该图中,我们根据片段的长短进行不同密度的采样。对于短片段,我们枚举出所有可能,进行密集采样。对于中等长度的片段,我们采样的步长设为2。对于长片段,我们采样的步长设为4。通过这种方式,我们可以降低因枚举所带来的计算开销,同时保证精度。所有未被选中的片段被填充为0,不参与后续的计算。
图4:当 N=64 时的候选片段。蓝色的方格表示选中参与候选的片段,灰色的方格表示未选中的片段。白色的方格表示无效的片段。
通过时间邻近网络定位
有了视频的二维特征图(图3中的蓝色立方体)和语句的文本特征(图3中的黄色长方体),我们首先将其特征图中每个位置的视频特征与文本特征融合,获得相似度的特征图(图3右图中左侧的绿色立方体)。然后,将融合后的相似度特征图通过一系列的卷积层,逐层建立其每个片段与周边片段之间的关系。最后,我们将这种考虑了邻近关系的相似度特征输入到全联接层中,获得最终的得分。
损失函数
在训练整个 2D-TAN 网络时,我们采用二元交叉熵(binary cross-entropy)作为损失函数,并使用经过线性变换的 interp-over-union (IoU)值作为损失函数中的标签(label)。
实验结果
我们在 Charades-STA [6]、ActivityNet Captions [7] 和 TACoS [8] 三个数据集中进行了测试。实验结果如表1-3所示。从实验结果中我们可以看出,在不同数据集的多种评价指标下,我们的方法均取得了优异的性能。值得注意的是,我们的方法在更苛刻的评价标准下的提升更为明显(如表1-3中 rank{1,5}@{0.5,0.7} 的表现),尤其是在 TACoS、Rank1@0.5 和 Rank5@0.5 两个上获得了5和14个百分点的提升。这些实验结果说明基于二维时间图邻近关系的建模对性能提升有很大的帮助。
表1:Charades-STA 的实验结果。Pool 和 Conv 表示两种不同的片段特征提取方式,下表同。
表2:ActivityNet Captions 的实验结果
表3:TACoS 的实验结果
基于二维时间图的人体动作检测
考虑到 2D-TAN 方法的通用性和其在基于自然语言的时间定位任务上的优异性能,我们在后续的工作中将其拓展到了视频内人体动作检测任务中。该任务需要在给定的长视频中,检测出视频中预定义的动作片段类别及其开始和结束时间点。一种通常的做法是将该任务拆分成两步,首先检测出哪些片段可能存在预定义动作的片段(proposal generation),然后预测这些候选片段可能所属的类别(classification)。考虑到这类做法的第一步和我们提出的 2D-TAN 方法很相关,本质上都是要解决片段之间的相互依赖关系的问题,因此我们用 2D-TAN 方法针对该任务进行了改进,如图5。
图5:S-2D-TAN 框架示意图
相较于基于自然语言描述的视频片段定位,视频内动作定位的目标片段往往比较短。因此需要的采样频率更高,采样的单元片段个数 N 也因此更大。相应地,在特征图中长片段的采样步长也会比较大,底层的卷积层往往感受不到足够的上下文信息。在图5中,红色虚线方框表示的是中等长度片段在第一层涉及到的邻近片段,而黄色虚线方框表示的是短片段要涉及的邻近片段。我们可以看出,黄色框涉及的上下文信息要比红色框的多。因此我们在 2D-TAN 的基础上,针对长片段上下文信息较少,设计了一个稀疏二维时域邻近网络(Sparse 2D Temporal Adjacent Network, i.e. S-2D-TAN)。该网络将稀疏图按照采样的步长,拆分成三个更紧凑的时域特征图。通过将不同特征图分别通过一个共享内核的卷积网络,从而使得长片段可从周围的特征中获得更多的上下文信息。
我们的算法在 ICCV 2019 中的 HACS Action Localization Challenge 比赛中获得了第一名的成绩。值得一提的是,HACS 目前是视频内人体动作检测任务中最大的数据集 [2]。更多细节请参考技术报告[3]。
图6:比赛获奖证书
结语
本文针对视频内容片段定位问题提出了一种二维时间图表示方式与一种新的时域邻近网络(2D-TAN),其有效性已在基于自然语言描述的视频内容定位和人体动作检测两个任务上得到了初步的验证。该方法目前仍处于一个初步探索的阶段:从网络结构的角度来说,当前的结构仅采用简单地堆叠卷积层的方式,相信进一步优化网络结构本身会带来性能上的提升。另一方面,从方法的通用性角度来说,目前我们仅验证了两个任务,仍有许多相关任务值得拓展,例如视频文本描述,视频内容问答,亦或是语音等其他包含时序信息的任务。
更多技术细节,详见论文:
Learning 2D Temporal Adjacent Network for Moment Localization with Natural Language
论文链接: https://arxiv.org/abs/1912.03590
代码链接: https://github.com/microsoft/2D-TAN
本文作者:彭厚文、张宋扬、傅建龙、罗杰波
参考文献
1. Songyang Zhang, Houwen Peng, JianlongFu and Jiebo Luo, “Learning 2D Temporal Adjacent Networks forMoment Localization with Natural Language”, AAAI 2020
2. Hang Zhao, Zhicheng Yan, Lorenzo Torresani and Antonio Torralba, “HACS: Human Action Clips and Segments Dataset for Recognition and Temporal Localization”, ICCV 2019
3. Songyang Zhang, Houwen Peng, Le Yang, Jianlong Fu and Jiebo Luo, “Learning Sparse 2D Temporal Adjacent Networks for Temporal Action Localization”, Technical Report
4. Jeffrey Pennington, Richard Socher and Christopher D. Manning, “GloVe: Global Vectors for Word Representation”, EMNLP 2014
5. Hochreiter, Sepp and Schmidhuber,Jurgen, “Long short-term memory”, Neural computation 1997
6. Jiyang Gao, Chen Sun, Zhenheng Yang and Ram Nevatia, “TALL: Temporal activity localization via language query”, ICCV2017
7. Ranjay Krishna, Kenji Hata, Frederic Ren, Li Fei-Fei, and Juan Carlos Niebles, “Dense-Captioning Events in Videos”, ICCV 2017
8. Michaela Regneri, Marcus Rohrbach, Dominikus Wetzel, Stefan Thater, and Bernt Schiele, and Manfred Pinkal, “Grounding action descriptions in videos”, TACL 2013
(*本文为AI科技大本营转载文章,转载请联系原作者)
◆
精彩公开课
◆
推荐阅读
大四学生发明文言文编程语言,设计思路清奇
芬兰开放“线上AI速成班”课程,全球网民均可免费观看
腾讯 Angel 升级:加入图算法,支持十亿节点、千亿边规模!
解读 | 2019年10篇计算机视觉精选论文(上)
高通:2 亿像素手机 2020 年诞生!
英特尔首推异构编程神器 oneAPI,可让程序员少加班!
VS Code 成主宰、Vue 备受热捧!2019 前端开发趋势必读
我在华为做外包的真实经历
2019 区块链大事记 | Libra 横空出世,莱特币减产,美国放行 Bakkt……这一年太精彩!
互联网诞生记: 浪成于微澜之间
你点的每个“在看”,我都认真当成了AI
相关文章:

《燃烧的岁月》
温含着优美的文句中,字里行间,透过一层薄薄的纸,牵挂起往事如烟,曾经的努力和成长,透过那以视频同时走过的路,默默无闻,牵挂着的是一句句唯美的文笔,留下情感的诗句文笔,…

PE文件和COFF文件格式分析——签名、COFF文件头和可选文件头1
本文将讨论PE文件中非常重要的一部分信息。(转载请指明来源于breakSoftware的CSDN博客) 首先说一下VC中对应的数据结构。“签名、COFF文件头和可选文件头”这三部分信息组合在一起是一个叫IMAGE_NT_HEADERS的结构体。 typedef struct _IMAGE_NT_HEADERS6…
遇到bug心寒了?用Enter键即可解决!
本文图片来自网络做程序员难不难?很难!做个程序员压力大不大?超级大!!测试bug时(图片来自网络)当找到Bug,开始修改的你……(图片来自网络)那怎么办࿱…

8月第1周安全回顾 0Day漏洞成企业最大威胁 应重视网络监听
文章同时发表在:[url]http://netsecurity.51cto.com/art/200708/52822.htm[/url]本周(0730至0805)安全方面值得关注的新闻集中在安全管理、安全威胁和安全产品方面。安全管理:0Day漏洞***成为企业信息安全的最大威胁新闻ÿ…
最大匹配、最小顶点覆盖、最大独立集、最小路径覆盖(转)
在讲述这两个算法之前,首先有几个概念需要明白: 二分图: 二分图又称二部图,是图论中的一种特殊模型。设G(V,E)是一个无向图,如果顶点V可以分割为两个互不相交的子集(A,B),并且图中的每条边(i,j)所关联的两个顶点i和j分别属于这两个…

一种在注入进程中使用WTL创建无焦点不在任务栏出现“吸附”窗口的方法和思路
最近一直在做沙箱项目,在项目快接近结尾的时候,我想给在我们沙箱中运行的程序界面打上一个标记——标识其在我们沙箱中运行的。我大致想法是:在被注入程序的顶层窗口上方显示一个“标题性”窗口,顶层窗口外框外显示一个“异形”的…
转:ASP.NET状态保存方法
ASP.NET状态保存分为客户端保存和服务器端保存两种:使用客户端选项存储页信息而不使用服务器资源的这些选项往往具有最低的安全性但具有最快 的服务器性能,因为对服务器资源的要求是适度的。但是,由于必须将信息发送到客户端来进行存储&#…
时至今日,NLP怎么还这么难!
作者 | 刘知远在微博和知乎上关注自然语言处理(NLP)技术的朋友,应该都对#NLP太难了#、#自然语言理解太难了#两个话题标签不陌生,其下汇集了各种不仅难煞计算机、甚至让人也发懵的费解句子或歧义引起的笑话。然而,这些例…
Quartz定时任务学习(四)调度器
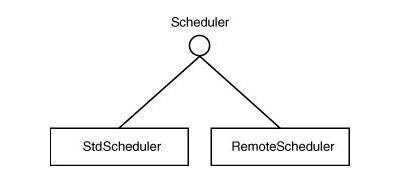
org.quartz.Scheduler 类层次 作为一个 Quartz 用户,你要与实现了 org.quartz.Scheduler 接口的类交互。在你调用它的任何 API 之前,你需要知道如何创建一个 Scheduler 的实例。取而代之的是用了某个工厂方法来确保了构造出 Sheduler 实例并正确的得到初…

反汇编算法介绍和应用——线性扫描算法分析
做过逆向的朋友应该会很熟悉IDA和Windbg这类的软件。IDA的强项在于静态反汇编,Windbg的强项在于动态调试。往往将这两款软件结合使用会达到事半功倍的效果。可能经常玩这个的朋友会发现IDA反汇编的代码准确度要高于Windbg,深究其原因,是因为I…
项目计划书的内容
1.引言 1.1计划的目的 1.2项目的范围和目标 1.2.1范围描述 1.2.2主要功能 1.2.3性能 1.2.4管理和技术约束 2.项目估算 2.1使用的历史数据 2.2使用的评估技术 2.3工作量、成本、时间估算 3.风险管理战略 3.1风险识别 3.2有关风险的讨论 3.3风险管理计划 3.3.1风险计划 3.3.2风险…
不用写代码就能学用Pandas,适合新老程序员的神器Bamboolib
作者 | Rahul Agarwal译者 | 陆离编辑 | Jane出品 | AI科技大本营(ID:rgznai100)曾经,你有没有因为学习与使用 Pandas 进行数据检索等操作而感到厌烦过?实现同样的功能,Pandas 给用户提供了很多种方法&…
后海日记(8)
来深圳已经这么长时间了,深圳给我的感觉总体很好,天那么蓝,空气也很清新,总的来说很不错。 努力学习,早日成才。 加油!版权声明:本文为博主原创文章,未经博主允许不得转载。 转载于:…

反汇编算法介绍和应用——递归下降算法分析
上一篇博文我介绍了Windbg使用的线性扫描(linear sweep)反汇编算法。本文我将介绍IDA使用的递归下降(recursive descent)反汇编算法。(转载请指明来源于breaksoftware的csdn博客) 递归(recursiv…
如何快速get到AI工程师面试重点,这12道题必备!
作者 | JP Tech译者 | 刘畅编辑 | Jane出品 | AI科技大本营(ID:rgznai100)【导读】2020 年的三月春招要来了,现在想要 Get 一个算法工程师的实习或全职机会,已经不是一件易事了。如果现在着手复习,茫茫题海…

金邦黑金刚4G内存 VS Vista系统
我的机器配置是 Intel Core 2 4320CPU 金邦黑金刚2G DDR2 800*2 P965P-DS3主板 N 8600GTS 为什么在Vista中 只识别了3.5G 我升级了主版BIOS 主版最高支持8G,哎结果网上一看,才明白。。。现在的系统不是很好的支持4G的内存。…
程序员的量化交易之路(25)--Cointrader之MarketData市场数据实体(12)
转载需注明出处:http://blog.csdn.net/minimicall,http://cloudtrade.top/ 前面一节我们说到了远端事件。其中,市场数据就属于远端事件。市场数据有什么?我们通过代码来回答这个问题: package org.cryptocoinpartners.…
滴滴开源在2019:十大重点项目盘点,DoKit客户端研发助手首破1万Star
整理 | Jane出品 | AI科技大本营(ID;rgznai100)2018 年,科技企业纷纷布局开源战略后迎来的第一个“丰收年”。但对滴滴来说,2019 年才迎来其第一波开源小高潮。自2017年滴滴零星开源数个项目后,滴滴开源项目…
PE文件和COFF文件格式分析——签名、COFF文件头和可选文件头2
之前的博文中介绍了IMAGE_FILE_HEADER结构,现在来讨论比较复杂的“可选文件头”结构体。(转载请指明来自breaksoftware的csdn博客)先看下其声明 typedef struct _IMAGE_OPTIONAL_HEADER {//// Standard fields.//WORD Magic;...DWORD BaseOfData; // not e…
9月第1周安全回顾 IM安全威胁严重 企业增加无线安全投入
本文同时发表在:[url]http://netsecurity.51cto.com/art/200709/55180.htm[/url]本周(0827至0902)安全方面值得关注的新闻集中在安全产品、即时通信安全、无线安全和安全市场。安全产品:Intel vPro技术逐渐升温,关注指…

centos下LAMP之源码编译安装httpd
1 最好先安装组件[rootlocalhost ~]# yum groupinstall additional development [rootlocalhost ~]# yum groupinstall development tool2 安装ap1.5.2r(Apache Portable Runtime),安装apr-util 1.5.4工具[rootlocalhost ~]wget http://mirrors.cnnic.cn/apache//apr/apr-1.5.2…
PE文件和COFF文件格式分析——签名、COFF文件头和可选文件头3
《PE2》中介绍了一些可选文件头中重要的属性,为了全面起见,本文将会讲解那些不是那么重要的属性。虽然不重要,但是还是可以发现很多好玩的情况。首先看一下32位的可选文件头详细定义。(转载请指明来源于breaksoftware的CSDN博客&a…
高效决策的三个关键
“领导者的责任,归纳起来,主要是出主意、用干部两件事。”***的这句话高度概括了领导者的关键任务,而这两件事都有一个共同的核心——决策。决策是管理者的天职,与其说这是他们的权力,不如说是一种责任。每一个经理人&…
开发者都想收藏的深度学习脑图,我们抢先曝光了!
可以看到,通过机器学习技术,软件或服务的功能和体验得到了质的提升。比如,我们甚至可以通过启发式引擎智能地预测并调节云计算分布式系统的节点压力,以此改善服务的弹性和稳定性,这是多么美妙。而对移动平台来说&#…

Cookie 位置_无需整理
为什么80%的码农都做不了架构师?>>> Cookie 位置 C:\Users\admin\AppData\Roaming\Microsoft\Windows\Cookies 转载于:https://my.oschina.net/Majw/blog/464018

PE文件和COFF文件格式分析——节信息
在《PE文件和COFF文件格式分析——签名、COFF文件头和可选文件头3》中,我们看到一些区块的信息都有偏移指向。而我们本文讨论的节信息是没有任何偏移指向的,所以它是紧跟在可选文件头后面的。(转载请注明来源于breaksoftware的csdn博客&#…

强悍!使用Flash和Silverlight制作控件
Silverlight已经发布了正式版本,我也到网站下载了一个并看看,突然发现了他的例子中包含了这个公司。NETiKA TECH。之所以说他强,是因为他尽然使用Flash和Silverlight制作了仿造WinForm的控件,包括:常见的控件ÿ…

《评人工智能如何走向新阶段》后记(再续8)
由AI科技大本营下载自视觉中国2019.12.13 81.近来一波人工智能热潮是在大数据的海量样本及超强计算能力两者支撑下形成的。所以说这一波人工智能是由大数据喂养出来的。这时的机器智能在感知智能和计算智能等一些具体问题上已经达到甚至超越人类水平,目前在语音识别…
Hadoop集群安全性:Hadoop中Namenode单点故障的解决方案及详介AvatarNode
2019独角兽企业重金招聘Python工程师标准>>> 正如大家所知,NameNode在Hadoop系统中存在单点故障问题,这个对于标榜高可用性的Hadoop来说一直是个软肋。本文讨论一下为了解决这个问题而存在的几个solution。 1. Secondary NameNode 原理&#…

PE文件和COFF文件格式分析——RVA和RA相互计算
之前几节一直是理论性质的东西非常多。本文将会讲到利用之前的知识得出一个一个非常有用的一个应用。(转载请指明来源于breaksoftware的csdn博客) 首先我们说下磁盘上A.exe文件和正在内存中运行的A.xe之间的关系。当我们双击A.exe后,A.exe会运…