解读 | 2019年10篇计算机视觉精选论文(中)
导读:2019 年转眼已经接近尾声,我们看到,这一年计算机视觉(CV)领域又诞生了大量出色的论文,提出了许多新颖的架构和方法,进一步提高了视觉系统的感知和生成能力。因此,我们精选了 2019 年十大 CV 研究论文,帮你了解该领域的最新趋势。
我们看到,近年来,计算机视觉(CV)系统已经逐渐成功地应用在医疗保健,安防、运输、零售、银行、农业等领域,也正在逐渐改变整个行业的面貌。
今年,CV 领域依然硕果累累,在各个顶尖会议中诞生了多篇优秀论文。我们从中精选了 10 篇论文以供大家参考、学习。限于篇幅,我们将解读分为了上、中、下三个篇章分期进行推送。
以下是这 10 篇论文的目录:
1.EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
EfficientNet:卷积神经网络模型缩放的反思
2.Learning the Depths of Moving People by Watching Frozen People
通过观看静止的人来学习移动的人的深度
3.Reinforced Cross-Modal Matching and Self-Supervised Imitation Learning for Vision-Language Navigation
增强的跨模态匹配和自我监督的模仿学习,用于视觉语言导航
4.A Theory of Fermat Paths for Non-Line-of-Sight Shape Reconstruction
非视线形状重构的费马路径理论
5.Reasoning-RCNN: Unifying Adaptive Global Reasoning into Large-scale Object Detection
Reasoning-RCNN:将自适应全局推理统一到大规模目标检测中
6.Fixing the Train-Test Resolution Discrepancy
修复训练测试分辨率差异
7.SinGAN: Learning a Generative Model from a Single Natural Image
SinGAN:从单个自然图像中学习生成模型
8.Local Aggregation for Unsupervised Learning of Visual Embeddings
视觉聚合的无监督学习的局部聚合
9.Robust Change Captioning
强大的更改字幕
10.HYPE: A Benchmark for Human eYe Perceptual Evaluation of Generative Models
HYPE:人类对生成模型的 eYe 感知评估的基准
前三篇论文的详细解读在此,大家可点击图片或下方文字进行阅读:
解读 | 2019年10篇计算机视觉精选论文(上)
接下来,我们将从核心思想、关键成就、未来技术应用等方面,详细介绍第 4-7 篇论文,同时欢迎大家继续关注后续的内容推送。
4
非视线形状重构的费马路径理论
论文地址:http://1t.click/b49X
摘要
我们提出了一个新的理论,即在一个已知的可见场景和一个不在瞬态相机视线范围内的未知物体之间的 Fermat path。这些光路要么遵守镜面反射,要么被物体的边界反射,从而编码隐藏物体的形状。
我们证明费马路径对应于瞬态测量中的不连续性。然后,我们推导出一种新的约束,它将这些不连续处的路径长度的空间导数与表面法线相关联。
基于这一理论,我们提出了一种名为 Fermat Flow 的算法,来估计非视距物体的形状。我们的方法首次允许复杂对象的精确形状恢复,范围从隐藏在拐角处以及隐藏在漫射器后面的漫反射到镜面反射。
最后,我们的方法与用于瞬态成像的特定技术无关。因此,我们展示了使用 SPAD 和超快激光从皮秒级瞬态恢复的毫米级形状,以及使用干涉测量法从飞秒级瞬态微米级重建。我们相信我们的工作是非视距成像技术的重大进步。
本文的核心思想
•现有的对隐藏物体进行轮廓分析的方法,取决于测量反射光子的强度,这需要假设朗伯反射和可靠的光电探测器。
•研究小组建议通过依靠费马原理施加的几何约束,来重构非视线形状:
费马路径对应于瞬态测量中的不连续性。
具体而言,可以将瞬态测量中的不连续性识别为有助于瞬态的费马路径的长度。
给定费马路径长度的集合,该过程将为 NLOS 表面生成一个定向的点云。
关键成就
•从引入的理论推导出的费马流动算法,可以成功地重构出不依赖于特定瞬态成像技术的隐藏物体表面。
•费马路径理论适用于以下情形:
反射式 NLOS(环角);
透射式 NLOS(透过扩散器)。
本文在人工智能界的荣誉
该论文在计算机视觉和模式识别的顶尖会议 CVPR 2019 上获得了最佳论文奖。
未来的研究领域是什么?
•探索此处描述的几何方法与新介绍的用于对隐藏对象进行概要分析的反投影方法之间的联系。
•将几何和反投影方法结合起来用于其他相关应用,包括声学和超声成像,无透镜成像和地震成像。
有哪些可能的业务应用程序?
•摄像机或传感器可以「看到」超出其视野的增强的安全性。
•自动驾驶汽车可能会「看见」拐角处。
5
Reasoning-RCNN:将自适应全局推理统一到大规模目标检测中
论文地址:http://1t.click/b46x
摘要
在本文中,我们解决了具有数千个类别的大规模对象检测问题,由于长尾数据分布,严重的遮挡和类别模糊性,这带来了严峻的挑战。然而,主要对象检测范式是通过在不考虑对象之间关键的语义依赖性的情况下,分别处理每个对象区域而受到限制的。
在这项工作中,我们引入了一种新颖的 Reasoning-RCNN,通过利用各种人类常识知识,赋予所有检测网络在所有对象区域上自适应全局推理的能力。我们不只是直接在图像上传播视觉特征,而是在全球范围内发展所有类别的高级语义表示,以避免图像中分散注意力或不良的视觉特征。具体来说,基于基本检测网络的特征表示,提出的网络首先通过收集每个类别的先前分类层的权重,来生成全局语义池,然后通过参加全局语义池中的不同语义上下文,来自适应地增强每个对象的特征。
我们的自适应全局推理不是从嘈杂的所有可能的语义信息中传播信息,而是自动发现特征演变的大多数相对类别。我们的 Reasoning-RCNN 轻巧灵活,足以增强任何检测主干网络,并且可扩展以集成任何知识资源。在对象检测基准上进行的可靠实验显示了我们的 Reasoning-RCNN 的优势,例如,在 VisualGenome 上实现了约 16% 的改进,在 mAP 方面实现了 ADE 的 37% 的改进,在 COCO 方面实现了 15% 的改进。
本文的核心思想
•大规模物体检测面临许多重大挑战,包括高度不平衡的物体类别,严重遮挡,类歧义,小尺寸物体等。
•为了克服这些挑战,研究人员引入了一种新颖的 Reasoning-RCNN 网络,该网络可以对具有某些关系或相似属性的类别进行自适应全局推理:
首先,该模型通过收集先前分类层的权重,在大规模图像中的所有类别上生成全局语义池。
其次,按类别划分的知识图被设计为对语言知识(例如属性,共现,关系)进行编码。
第三,通过关注机制对当前图像进行编码,以自动发现每个对象最相关的类别。
第四,增强的类别通过软映射机制映射回区域,从而可以细化前一阶段不准确的分类结果。
第五,将每个区域的新增强功能与原始功能连接在一起,以端到端的方式增强分类和定位的性能。
关键成就
•Reasoning-RCNN 优于当前的最新对象检测方法,包括 Faster R-CNN,RetinaNet,RelationNet 和 DetNet。
•特别是,该模型在平均平均精度(mAP)方面实现了以下改进:
1000 个类别的 VisualGenome 占 15%;
3000 个类别的 VisualGenome 占16%;
ADE 占 37%;
MS-COCO 的 15%;
Pascal VOC 的 2%。
本文在人工智能界的荣誉
该论文在计算机视觉的顶尖会议 CVPR 2019 上被重点进行介绍。
未来的研究领域是什么?
•将 Reasoning-RCNN 中使用的推理框架嵌入到其他任务中,包括实例级细分。
有哪些可能的业务应用程序?
•所提出的方法可以显着提高依赖于大规模对象检测(例如,城市街道上的威胁检测)的系统的性能。
在哪里可以获得实现代码?
•GitHub 上提供了 Reasoning-RCNN 的实现代码:
https://github.com/chanyn/Reasoning-RCNN。
6
修复训练测试分辨率差异
论文地址:https://arxiv.org/pdf/1906.06423.pdf
摘要
数据扩充是训练神经网络进行图像分类的关键。本文首先显示,现有的增强会导致分类器在训练和测试时,看到的典型对象大小之间出现显著差异。我们通过实验验证,对于目标测试分辨率,使用较低的训练分辨率,可以在测试时提供更好的分类。
然后,我们提出了一种简单而有效的策略,以在训练分辨率和测试分辨率不同时优化分类器性能。它仅涉及在测试分辨率下计算机上廉价的网络微调。这样可以使用小型训练图像来训练强大的分类器。
例如,通过在 128×128 图像上训练的 ResNet-50,在 ImageNet 上获得 77.1% 的 top-1 精度,在 224×224 图像上训练出的 ResNet-50 达到 79.8%。另外,如果我们使用额外的训练数据,则使用具有 224×224 图像的 ResNet-50 train 可获得 82.5% 的效果。
相反,以 224×224 的分辨率对 9.4 亿张公共图像进行弱监督预训练的 ResNeXt-101 32×48d 并进一步优化测试分辨率 320×320 时,我们获得的测试 top-1 准确性为 86.4% (前 5 名:98.0%)(单作)。据我们所知,这是迄今为止 ImageNet 最高的单幅 top-1 和 top-5 精度。
本文的核心思想
•图像预处理程序在训练和测试时的差异会对图像分类器的性能产生不利影响:
为了增加训练数据,通常的做法是从图像(即分类区域或 RoC)中提取具有随机坐标的矩形。
在测试时,从图像的中央部分提取 RoC 。
这导致分类器在训练和测试时看到的对象大小之间存在显着差异。
•为了解决这个问题,研究人员建议在训练和测试时共同优化图像的分辨率和比例,分析表明:
在测试时增加图像作物的大小,可以补偿训练时随机选择 RoC;
在训练中使用比测试时使用更低分辨率的农作物可以改善模型的性能。
•因此,Facebook AI 团队建议保持相同的 RoC 采样,并且仅微调网络的两个层以补偿作物大小的变化。
关键成就
•通过获取以下内容来提高 ResNet-50 模型在 ImageNet 上进行图像分类的性能:
在 128×128 图像上训练时,top-1 精度为 77.1%;
在 224×224 图像上训练时,top-1 精度为 79.8%;
在带有额外训练数据的 224×224 图像上进行训练时,top-1 精度为 82.5%。
•使 ResNeXt-101 32×48d 在 9.4 亿张公共图像上以 224×224 图像的分辨率进行预训练,从而在 ImageNet 上进行图像分类的新技术:
top-1 准确性为 86.4%;
top-5 准确性为 98.0%。
有哪些可能的业务应用程序?
•建议的方法可以提高用于大型数据库中自动图像组织,股票网站上的图像分类,可视产品搜索等的 AI 系统的性能。
在哪里可以获得实现代码?
•作者提供了引入的方法的官方 PyTorch 实现,以解决训练测试分辨率的差异。
GitHub 地址:
https://github.com/facebookresearch/FixRes
7
SinGAN:从单个自然图像中学习生成模型
论文地址:https://arxiv.org/pdf/1905.01164.pdf
摘要
我们介绍了 SinGAN,一个可以从单个自然图像中学习的无条件生成模型。我们的模型经过训练,可以捕获图像内斑块的内部分布,然后能够生成高质量,多样的样本,并承载与图像相同的视觉内容。SinGAN 包含一个完全卷积的 GAN 金字塔,每个 GAN 负责学习图像不同比例的 patch 分布。这样就可以生成具有任意大小和纵横比的新样本,这些样本具有明显的可变性,同时又可以保持训练图像的整体结构和精细纹理。
与以前的单图像 GAN 方案相比,我们的方法不仅限于纹理图像,而且不是有条件的(即从噪声中生成样本)。通过用户的研究证实了,生成的样本通常被混淆为真实图像。我们将说明 SinGAN 在各种图像处理任务中的实用性。
本文的核心思想
•为了从单个图像中学习无条件生成模型,研究人员建议使用单个图像的补丁作为训练样本,而不是像常规 GAN 设置中的整个图像样本。
•该 SinGAN 生成框架:
由补丁 GAN 的层次结构组成,每个 GAN 负责捕获补丁在不同规模上的分布(例如,某些 GAN 了解全局属性和大对象的形状,例如「顶部的天空」和「底部的地面」,以及其他 GAN 可以学习精细的细节和纹理信息);
不仅可以生成纹理,还可以处理一般的自然图像;
允许生成任意大小和纵横比的图像;
通过选择在测试时间开始生成的标度,可以控制生成的样本的可变性。
关键成就
•实验证明 SinGAN:
可以生成描述新的现实结构和对象配置的图像,同时保留训练图像的内容;
成功保留全局图像属性和精细细节;
可以现实地合成反射和阴影;
生成难以与真实样本区分开的样本。
本文在人工智能界的荣誉
•该论文获得了计算机视觉领域的顶尖会议 ICCV 2019 最佳论文奖。
有哪些可能的业务应用程序?
•SinGAN 模型可以协助完成许多图像处理任务,包括图像编辑,超分辨率,协调,从绘画生成图像以及从单个图像创建动画。
在哪里可以获得实现代码?
•GitHub 上提供了 SinGAN 的 PyTorch 官方实现:
https://github.com/tamarott/SinGAN。
参考资料:
https://www.topbots.com/top-ai-vision-research-papers-2019/
(*本文为AI科技大本营转载文章,转载请联系原作者)
◆
精彩公开课
◆
推荐阅读
大四学生发明文言文编程语言,设计思路清奇
芬兰开放“线上AI速成班”课程,全球网民均可免费观看
腾讯 Angel 升级:加入图算法,支持十亿节点、千亿边规模!
解读 | 2019年10篇计算机视觉精选论文(上)
高通:2 亿像素手机 2020 年诞生!
英特尔首推异构编程神器 oneAPI,可让程序员少加班!
VS Code 成主宰、Vue 备受热捧!2019 前端开发趋势必读
我在华为做外包的真实经历
2019 区块链大事记 | Libra 横空出世,莱特币减产,美国放行 Bakkt……这一年太精彩!
互联网诞生记: 浪成于微澜之间
你点的每个“在看”,我都认真当成了AI
相关文章:

PE文件和COFF文件格式分析--概述
刚工作的时候,我听说某某大牛在做病毒分析时,只是用notepad打开病毒文件,就能大致猜到病毒的工作原理。当时我是佩服的很啊,同时我也在心中埋下了一个种子:我也得有这天。随着后来的工作进行,一些任务的和这…

2015第22周六Java反射、泛型、容器简介
Java的反射非常强大,传递class, 可以动态的生成该类、取得这个类的所有信息,包括里面的属性、方法以及构造函数等,甚至可以取得其父类或父接口里面的内容。 obj.getClass().getDeclaredMethods();//取得obj类中自己定义的方法&…

中服公司企业信息化的ERP系统选择
中服公司企业信息化的ERP系统选择一、 中服公司概况 1. 组织概况 中服公司创建于1950年9月,是国家120家企业集团试点单位之一,主要经营各类纺织原料、半成品、服装、针棉毛织品以及其他商品的进出口业务,同时通过合资、联营等方…

PE文件和COFF文件格式分析--MS-DOS 2.0兼容Exe文件段
MS 2.0节是PE文件格式中第一个“节”。其大致结构如下:(转载请指明来源于breaksoftware的csdn博客) 在VC\PlatformSDK\Include\WinNT.h文件中有对MS-DOS 2.0兼容EXE文件头的完整定义 typedef struct _IMAGE_DOS_HEADER { // DOS .EXE h…
时间可以是二维的?基于二维时间图的视频内容片段检测 | AAAI 2020
作者 | 彭厚文、傅建龙来源 | 微软研究院AI头条(ID: MSRAsia)编者按:当时间从一维走向二维,时序信息处理问题中一种全新的建模思路由此产生。根据这种新思路及其产生的二维时间图概念,微软亚洲研究院提出一种新的解决时…

《燃烧的岁月》
温含着优美的文句中,字里行间,透过一层薄薄的纸,牵挂起往事如烟,曾经的努力和成长,透过那以视频同时走过的路,默默无闻,牵挂着的是一句句唯美的文笔,留下情感的诗句文笔,…

PE文件和COFF文件格式分析——签名、COFF文件头和可选文件头1
本文将讨论PE文件中非常重要的一部分信息。(转载请指明来源于breakSoftware的CSDN博客) 首先说一下VC中对应的数据结构。“签名、COFF文件头和可选文件头”这三部分信息组合在一起是一个叫IMAGE_NT_HEADERS的结构体。 typedef struct _IMAGE_NT_HEADERS6…
遇到bug心寒了?用Enter键即可解决!
本文图片来自网络做程序员难不难?很难!做个程序员压力大不大?超级大!!测试bug时(图片来自网络)当找到Bug,开始修改的你……(图片来自网络)那怎么办࿱…
8月第1周安全回顾 0Day漏洞成企业最大威胁 应重视网络监听
文章同时发表在:[url]http://netsecurity.51cto.com/art/200708/52822.htm[/url]本周(0730至0805)安全方面值得关注的新闻集中在安全管理、安全威胁和安全产品方面。安全管理:0Day漏洞***成为企业信息安全的最大威胁新闻ÿ…
最大匹配、最小顶点覆盖、最大独立集、最小路径覆盖(转)
在讲述这两个算法之前,首先有几个概念需要明白: 二分图: 二分图又称二部图,是图论中的一种特殊模型。设G(V,E)是一个无向图,如果顶点V可以分割为两个互不相交的子集(A,B),并且图中的每条边(i,j)所关联的两个顶点i和j分别属于这两个…

一种在注入进程中使用WTL创建无焦点不在任务栏出现“吸附”窗口的方法和思路
最近一直在做沙箱项目,在项目快接近结尾的时候,我想给在我们沙箱中运行的程序界面打上一个标记——标识其在我们沙箱中运行的。我大致想法是:在被注入程序的顶层窗口上方显示一个“标题性”窗口,顶层窗口外框外显示一个“异形”的…
转:ASP.NET状态保存方法
ASP.NET状态保存分为客户端保存和服务器端保存两种:使用客户端选项存储页信息而不使用服务器资源的这些选项往往具有最低的安全性但具有最快 的服务器性能,因为对服务器资源的要求是适度的。但是,由于必须将信息发送到客户端来进行存储&#…
时至今日,NLP怎么还这么难!
作者 | 刘知远在微博和知乎上关注自然语言处理(NLP)技术的朋友,应该都对#NLP太难了#、#自然语言理解太难了#两个话题标签不陌生,其下汇集了各种不仅难煞计算机、甚至让人也发懵的费解句子或歧义引起的笑话。然而,这些例…
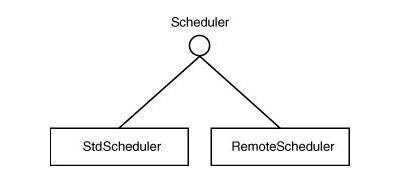
Quartz定时任务学习(四)调度器
org.quartz.Scheduler 类层次 作为一个 Quartz 用户,你要与实现了 org.quartz.Scheduler 接口的类交互。在你调用它的任何 API 之前,你需要知道如何创建一个 Scheduler 的实例。取而代之的是用了某个工厂方法来确保了构造出 Sheduler 实例并正确的得到初…

反汇编算法介绍和应用——线性扫描算法分析
做过逆向的朋友应该会很熟悉IDA和Windbg这类的软件。IDA的强项在于静态反汇编,Windbg的强项在于动态调试。往往将这两款软件结合使用会达到事半功倍的效果。可能经常玩这个的朋友会发现IDA反汇编的代码准确度要高于Windbg,深究其原因,是因为I…
项目计划书的内容
1.引言 1.1计划的目的 1.2项目的范围和目标 1.2.1范围描述 1.2.2主要功能 1.2.3性能 1.2.4管理和技术约束 2.项目估算 2.1使用的历史数据 2.2使用的评估技术 2.3工作量、成本、时间估算 3.风险管理战略 3.1风险识别 3.2有关风险的讨论 3.3风险管理计划 3.3.1风险计划 3.3.2风险…
不用写代码就能学用Pandas,适合新老程序员的神器Bamboolib
作者 | Rahul Agarwal译者 | 陆离编辑 | Jane出品 | AI科技大本营(ID:rgznai100)曾经,你有没有因为学习与使用 Pandas 进行数据检索等操作而感到厌烦过?实现同样的功能,Pandas 给用户提供了很多种方法&…
后海日记(8)
来深圳已经这么长时间了,深圳给我的感觉总体很好,天那么蓝,空气也很清新,总的来说很不错。 努力学习,早日成才。 加油!版权声明:本文为博主原创文章,未经博主允许不得转载。 转载于:…

反汇编算法介绍和应用——递归下降算法分析
上一篇博文我介绍了Windbg使用的线性扫描(linear sweep)反汇编算法。本文我将介绍IDA使用的递归下降(recursive descent)反汇编算法。(转载请指明来源于breaksoftware的csdn博客) 递归(recursiv…
如何快速get到AI工程师面试重点,这12道题必备!
作者 | JP Tech译者 | 刘畅编辑 | Jane出品 | AI科技大本营(ID:rgznai100)【导读】2020 年的三月春招要来了,现在想要 Get 一个算法工程师的实习或全职机会,已经不是一件易事了。如果现在着手复习,茫茫题海…

金邦黑金刚4G内存 VS Vista系统
我的机器配置是 Intel Core 2 4320CPU 金邦黑金刚2G DDR2 800*2 P965P-DS3主板 N 8600GTS 为什么在Vista中 只识别了3.5G 我升级了主版BIOS 主版最高支持8G,哎结果网上一看,才明白。。。现在的系统不是很好的支持4G的内存。…
程序员的量化交易之路(25)--Cointrader之MarketData市场数据实体(12)
转载需注明出处:http://blog.csdn.net/minimicall,http://cloudtrade.top/ 前面一节我们说到了远端事件。其中,市场数据就属于远端事件。市场数据有什么?我们通过代码来回答这个问题: package org.cryptocoinpartners.…
滴滴开源在2019:十大重点项目盘点,DoKit客户端研发助手首破1万Star
整理 | Jane出品 | AI科技大本营(ID;rgznai100)2018 年,科技企业纷纷布局开源战略后迎来的第一个“丰收年”。但对滴滴来说,2019 年才迎来其第一波开源小高潮。自2017年滴滴零星开源数个项目后,滴滴开源项目…
PE文件和COFF文件格式分析——签名、COFF文件头和可选文件头2
之前的博文中介绍了IMAGE_FILE_HEADER结构,现在来讨论比较复杂的“可选文件头”结构体。(转载请指明来自breaksoftware的csdn博客)先看下其声明 typedef struct _IMAGE_OPTIONAL_HEADER {//// Standard fields.//WORD Magic;...DWORD BaseOfData; // not e…
9月第1周安全回顾 IM安全威胁严重 企业增加无线安全投入
本文同时发表在:[url]http://netsecurity.51cto.com/art/200709/55180.htm[/url]本周(0827至0902)安全方面值得关注的新闻集中在安全产品、即时通信安全、无线安全和安全市场。安全产品:Intel vPro技术逐渐升温,关注指…

centos下LAMP之源码编译安装httpd
1 最好先安装组件[rootlocalhost ~]# yum groupinstall additional development [rootlocalhost ~]# yum groupinstall development tool2 安装ap1.5.2r(Apache Portable Runtime),安装apr-util 1.5.4工具[rootlocalhost ~]wget http://mirrors.cnnic.cn/apache//apr/apr-1.5.2…
PE文件和COFF文件格式分析——签名、COFF文件头和可选文件头3
《PE2》中介绍了一些可选文件头中重要的属性,为了全面起见,本文将会讲解那些不是那么重要的属性。虽然不重要,但是还是可以发现很多好玩的情况。首先看一下32位的可选文件头详细定义。(转载请指明来源于breaksoftware的CSDN博客&a…
高效决策的三个关键
“领导者的责任,归纳起来,主要是出主意、用干部两件事。”***的这句话高度概括了领导者的关键任务,而这两件事都有一个共同的核心——决策。决策是管理者的天职,与其说这是他们的权力,不如说是一种责任。每一个经理人&…
开发者都想收藏的深度学习脑图,我们抢先曝光了!
可以看到,通过机器学习技术,软件或服务的功能和体验得到了质的提升。比如,我们甚至可以通过启发式引擎智能地预测并调节云计算分布式系统的节点压力,以此改善服务的弹性和稳定性,这是多么美妙。而对移动平台来说&#…

Cookie 位置_无需整理
为什么80%的码农都做不了架构师?>>> Cookie 位置 C:\Users\admin\AppData\Roaming\Microsoft\Windows\Cookies 转载于:https://my.oschina.net/Majw/blog/464018