GoogleLog(GLog)源码分析
GLog是Google开发的一套日志输出框架。由于其具有功能强大、方便使用等特性,它被众多开源项目使用。本文将通过分析其源码,解析Glog实现的过程。
该框架的源码在https://github.com/google/glog上可以获取到。本文将以目前最新的0.3.3版本源码为范例进行分析。(转载请指明出于breaksoftware的csdn博客)
首先我们介绍下Glog简单的使用方法。Glog暴露了很多方法供使用者调用,一般它们都是通过宏的形式提供的。这些方法的功能包括:参数设置、判断、日志输出、自定义行为。基于重要性的考虑,我并不准备在本文中介绍参数设置和判断两个特性的函数。而将重点放在Glog的核心——日志输出和自定义行为上。而且在日志输出环节,我们将重点关注于文件形式的输出。下文中很多未加设定的场景一般都是以文件输出为例说明的。
我们以一个简单的例子作为开始
int _tmain(int argc, _TCHAR* argv[])
{google::InitGoogleLogging(argv[0]);FLAGS_log_dir = "D:\\Dev\\glog-0.3.3\\glog-0.3.3\\Debug\\log";LOG(INFO) << "INFO";LOG(INFO) << "INFO1";LOG(WARNING) << "WARNING";LOG(WARNING) << "WARNING1";LOG(ERROR) << "ERROR";LOG(ERROR) << "ERROR1";LOG(FATAL) << "FATAL";google::ShutdownGoogleLogging();return 0;
}第3和12行是对称的,用于初始化和关闭Glog系统。这两个过程的实现也非常简单,其比较有意义的是ShutdownGoogleLogging中实现了对过程中新建对象的清理。即调用了
static LogDestination* log_destinations_[NUM_SEVERITIES];
void LogDestination::DeleteLogDestinations() {for (int severity = 0; severity < NUM_SEVERITIES; ++severity) {delete log_destinations_[severity];log_destinations_[severity] = NULL;}
}LogDestination是是GLog非常核心的一个类。按英文翻译过来,它就是“日志目标”类。正如它名称,我们对日志的输出最终将落到该类上去执行。之后我们将一直和它打交道。
上面main函数的04行对Glog的全局变量重新赋值,它用于标记日志文件的生成路径。这类全局变量在logging.h中暴露了很多,它们很多是以DECLARE_bool、DECLARE_int32或DECLARE_string等宏声明的。这些就是我前文所述的“参数”。我们先只要知道FLAGS_log_dir的作用就行了。
05到11行向GLog系统中输出了4中类型的日志,即INFO、WARNING、ERROR和FATAL。GLog框架一共提供了上述四种类型的日志,这些日志将被分别输出到四个文件中。如本例我们将生成如下四个文件:
glog_test.exe.computername.username.log.ERROR.20160510-153013.9704
glog_test.exe.computername.username.log.FATAL.20160510-153013.9704
glog_test.exe.computername.username.log.INFO.20160510-153013.9704
glog_test.exe.computername.username.log.WARNING.20160510-153013.9704其中computername是设备的ID,username是登录用户的名称。
这种设计是非常有意义的。在我们开发过程中,我们可以通过INFO类型的日志进行过程分析。在自测阶段,我们可能更多要关注于是否存在WARNING类型的日志。而上线后,可能会出现一些我们认为不合法或者异常的场景,则这个时候就要关注ERROR和FATAL类型的日志了。这四种日志并不是相互独立的,而是存在包含关系。按照重要性,INFO日志文件将包含INFO、WARNING、ERROR和FATAL日志,因为在开发过程中我们需要关注所有信息。WARNING日志文件将包含WARNING、ERROR和FATAL日志。ERROR日志将包含ERROR和FATAL日志。FATAL日志文件里只有FATAL类型的日志。这种层级关系将非常有助于我们在不同时期关注不同性质的问题。我们看下INFO日志文件的内容
Log file created at: 2016/05/10 15:30:13
Running on machine: COMPUTERNAME
Log line format: [IWEF]mmdd hh:mm:ss.uuuuuu threadid file:line] msg
I0510 15:30:13.564411 11392 glog_test.cpp:11] INFO
I0510 15:30:13.566411 11392 glog_test.cpp:12] INFO1
W0510 15:30:13.566411 11392 glog_test.cpp:13] WARNING
W0510 15:30:13.566411 11392 glog_test.cpp:14] WARNING1
E0510 15:30:13.567411 11392 glog_test.cpp:15] ERROR
E0510 15:30:13.567411 11392 glog_test.cpp:16] ERROR1
F0510 15:30:13.568413 11392 glog_test.cpp:17] FATAL眼尖的同学可能发现INFO、ERROR和WARNING日志都有两条,而FATAL日志只有一条。这个地方引出FATAL类型日志的使用场景问题。一般情况下,如果出现程序已经无法执行的场景才使用FATAL日志用于记录临死之前的事情。所以如果我们在项目中发现日志中出现一连串的FATAL日志,往往是对Glog的错误使用。
Glog的基本使用我们讲完了,我们开始进行源码的讲解。
我们先看下LOG宏的定义
#define LOG(severity) COMPACT_GOOGLE_LOG_ ## severity.stream()可以见得,LOG宏的等级参数和COMPACT_GOOGLE_LOG_联合在一块组成一个宏。比如INFO则对应于COMPACT_GOOGLE_LOG_INFO;FATAL对应于COMPACT_GOOGLE_LOG_FATAL。这些宏最终都将对应于一个google::LogMessage对象,比如
#define LOG_TO_STRING_ERROR(message) google::LogMessage( \__FILE__, __LINE__, google::GLOG_ERROR, message)通过对不同日志类型的LogMessage构造对象对比说明,它们是通过LogMessage的第三个参数进行区分的,上例中ERROR日志的等级就是google::GLOG_ERROR。在log_severity.h文件中,定义了GLog四个等级对应的值。
const int GLOG_INFO = 0, GLOG_WARNING = 1, GLOG_ERROR = 2, GLOG_FATAL = 3,NUM_SEVERITIES = 4;这四个值并非随便定义的。它们这样设计,将有助于完成之前所说的日志包含输出问题。在将日志输出到文件的函数LogDestination::LogToAllLogfiles中
for (int i = severity; i >= 0; --i)LogDestination::MaybeLogToLogfile(i, timestamp, message, len);}这段简单的for循环,让日志输出到自己以及低于自己等级的日志文件中。
在现实使用中,我们往往会通过一个临时变量或者宏,来区分开发环境和线上环境。比如开发环境我们需要INFO级别的日志,而线上环境我们需要ERROR及其以上等级的日志。当我们测试完毕,准备上线前,我们不可能将输出INFO类型日志的语句删掉——因为可能很多、很分散且删除代码是不安全的。那么我们就需要使用一种手段让INFO和WARNING等级的日志失效。GLog是这么做的
#if GOOGLE_STRIP_LOG == 0
#define COMPACT_GOOGLE_LOG_INFO google::LogMessage( \__FILE__, __LINE__)
#define LOG_TO_STRING_INFO(message) google::LogMessage( \__FILE__, __LINE__, google::GLOG_INFO, message)
#else
#define COMPACT_GOOGLE_LOG_INFO google::NullStream()
#define LOG_TO_STRING_INFO(message) google::NullStream()
#endif#if GOOGLE_STRIP_LOG <= 1
#define COMPACT_GOOGLE_LOG_WARNING google::LogMessage( \__FILE__, __LINE__, google::GLOG_WARNING)
#define LOG_TO_STRING_WARNING(message) google::LogMessage( \__FILE__, __LINE__, google::GLOG_WARNING, message)
#else
#define COMPACT_GOOGLE_LOG_WARNING google::NullStream()
#define LOG_TO_STRING_WARNING(message) google::NullStream()
#endif#if GOOGLE_STRIP_LOG <= 2
#define COMPACT_GOOGLE_LOG_ERROR google::LogMessage( \__FILE__, __LINE__, google::GLOG_ERROR)
#define LOG_TO_STRING_ERROR(message) google::LogMessage( \__FILE__, __LINE__, google::GLOG_ERROR, message)
#else
#define COMPACT_GOOGLE_LOG_ERROR google::NullStream()
#define LOG_TO_STRING_ERROR(message) google::NullStream()
#endif#if GOOGLE_STRIP_LOG <= 3
#define COMPACT_GOOGLE_LOG_FATAL google::LogMessageFatal( \__FILE__, __LINE__)
#define LOG_TO_STRING_FATAL(message) google::LogMessage( \__FILE__, __LINE__, google::GLOG_FATAL, message)
#else
#define COMPACT_GOOGLE_LOG_FATAL google::NullStreamFatal()
#define LOG_TO_STRING_FATAL(message) google::NullStreamFatal()
#endif我们可以通过定义GOOGLE_STRIP_LOG的值,来控制相应宏的定义。比如我们给GOOGLE_STRIP_LOG赋值2,则COMPACT_GOOGLE_LOG_WARNING会被定义为google::NullStream(),从而不会进行输出。ERROR和FATAL都将定义为LogMessage的临时对象进行之后的业务逻辑。
以一个常用的LogMessage的构造函数来看临时对象的初始化
LogMessage::LogMessage(const char* file, int line, LogSeverity severity): allocated_(NULL) {Init(file, line, severity, &LogMessage::SendToLog);
}该函数中传入了执行语句所在的文件名和行号,这些我们都将在输出的日志中见到过。第三个参数是日志等级,即GLOG_INFO等值。Init传入的第四个参数是该类的一个成员函数地址。它才是我们关注的重点。
LogMessage::SendToLog函数主要执行的是下面这段代码
// log this message to all log files of severity <= severity_LogDestination::LogToAllLogfiles(data_->severity_, data_->timestamp_,data_->message_text_,data_->num_chars_to_log_);LogDestination::MaybeLogToStderr(data_->severity_, data_->message_text_,data_->num_chars_to_log_);LogDestination::MaybeLogToEmail(data_->severity_, data_->message_text_,data_->num_chars_to_log_);LogDestination::LogToSinks(data_->severity_,data_->fullname_, data_->basename_,data_->line_, &data_->tm_time_,data_->message_text_ + data_->num_prefix_chars_,(data_->num_chars_to_log_- data_->num_prefix_chars_ - 1));这段代码分别是:尝试向文件中输出、尝试向标准错误流中输出、尝试发送邮件、尝试向用户自定义池中输出。
尝试发送邮件的方式我们很少使用到,它实际是借用了linux系统上/bin/mail程序去发送邮件,所以对这块有兴趣的同学,可以主要关注下邮件内容的组装和发送命令的使用。
LogToAllLogfiles函数不仅具有向文件输出的能力,还有向标准错误流中输出的能力。
inline void LogDestination::LogToAllLogfiles(LogSeverity severity,time_t timestamp,const char* message,size_t len) {if ( FLAGS_logtostderr ) { // global flag: never log to fileColoredWriteToStderr(severity, message, len);} else {for (int i = severity; i >= 0; --i)LogDestination::MaybeLogToLogfile(i, timestamp, message, len);}
}else中的for循环就是之前我们讲解的日志包含的实现。
MaybeLogToLogfile方法将让一个全局的LogDestination对象执行日志输出逻辑
inline void LogDestination::MaybeLogToLogfile(LogSeverity severity,time_t timestamp,const char* message,size_t len) {const bool should_flush = severity > FLAGS_logbuflevel;LogDestination* destination = log_destination(severity);destination->logger_->Write(should_flush, timestamp, message, len);
}log_destination方法将通过日志等级新建并返回或者获取一个保存在全局区域中LogDestination指针
LogDestination* LogDestination::log_destinations_[NUM_SEVERITIES];inline LogDestination* LogDestination::log_destination(LogSeverity severity) {assert(severity >=0 && severity < NUM_SEVERITIES);if (!log_destinations_[severity]) {log_destinations_[severity] = new LogDestination(severity, NULL);}return log_destinations_[severity];
}如此可见,我们的测试代码将新建四个LogDestination对象,并将指针保存在全局数组log_destinations_中。这四个指针分别对应于INFO、WARNING、ERROR和FATAL日志的输出目标对象。所以,不管在多线程还是在单线程环境中,我们日志输出都将调用到这四个对象指针。
LogDestination类有个用于实际输出日志的成员变量
LogFileObject fileobject_;base::Logger* logger_; // Either &fileobject_, or wrapper around itLogger是个接口类,其暴露出来的方法都是纯虚。所以实际操作的是其继承类。LogFileObject继承于Logger接口,对于文件类型的输出,logger_指向fileobject_对象。
LogDestination::LogDestination(LogSeverity severity,const char* base_filename): fileobject_(severity, base_filename),logger_(&fileobject_) {
}LogFileObject的Write的实现非常简单,除了在文件不存在的情况下新建了日志文件,还有就是日志个格式化输出。它的整个逻辑是在锁内部完成的,这样可以保证多线程写操作是安全的。
我们分析完LogToAllLogfiles的实现,再探索下它是在何处被调用的。之前我们讲过LOG宏构建了一个LogMessage临时对象。这个临时对象的生命周期就是C++语句中其所在的那一行的执行周期。
LOG(ERROR) << "ERROR";LOG(ERROR) << "ERROR1";上述两行,就构建了两个LogMessage临时对象。第一行的临时对象在第二行执行之前就消亡了,第二行的临时对象在之后一行执行之前就消亡了。而对LogToAllLogfiles的调用就是在LogMessage的析构函数中(实际是Flush中)。
LogMessage::~LogMessage() {Flush();delete allocated_;
}Flush中的核心代码是
{MutexLock l(&log_mutex);(this->*(data_->send_method_))();++num_messages_[static_cast<int>(data_->severity_)];}LogDestination::WaitForSinks(data_);注意在调用send_method_所指向的函数(保存为文件时默认的就是LogToAllLogfiles方法)之前上了锁。这个锁非常必要,可以保证之后的操作是受到保护的。否则之前在全局区域保存LogDestination对象指针的逻辑就存在多线程访问的问题。
我们可以总结下,每条日志的输出都通过一个LogMessage临时对象的析构,传递到全局变量log_destinations_中相应等级对应的LogDestination指针所指向的对象。那么LogDestination对象又是在何时进行日志写入文件的呢?我们知道文件的Write方法并不一定马上把内容写入文件,而是存在一定的缓存中,再根据系统的判断或者用户主动调用fflush,将数据实际写入文件。LogFileObject提供了两个Flush方法
void LogFileObject::Flush() {MutexLock l(&lock_);FlushUnlocked();
}void LogFileObject::FlushUnlocked(){if (file_ != NULL) {fflush(file_);bytes_since_flush_ = 0;}// Figure out when we are due for another flush.const int64 next = (FLAGS_logbufsecs* static_cast<int64>(1000000)); // in usecnext_flush_time_ = CycleClock_Now() + UsecToCycles(next);
}一个是通过锁保证多线程安全的版本,一个是不安全的版本。它们都是执行了fflush,并计算了下一次flush时间。在LogFileObject的Write方法末尾,通过该时间的判断,确定是否真的将缓存写入文件中。
// See important msgs *now*. Also, flush logs at least every 10^6 chars,// or every "FLAGS_logbufsecs" seconds.if ( force_flush ||(bytes_since_flush_ >= 1000000) ||(CycleClock_Now() >= next_flush_time_) ) {FlushUnlocked();
#ifdef OS_LINUXif (FLAGS_drop_log_memory) {if (file_length_ >= logging::kPageSize) {// don't evict the most recent pageuint32 len = file_length_ & ~(logging::kPageSize - 1);posix_fadvise(fileno(file_), 0, len, POSIX_FADV_DONTNEED);}}
#endif}还有一种强制写入文件的方法,就是LogDestination::FlushLogFilesUnsafe和LogDestination::FlushLogFiles方法,它们的实现是
inline void LogDestination::FlushLogFilesUnsafe(int min_severity) {// assume we have the log_mutex or we simply don't care// about itfor (int i = min_severity; i < NUM_SEVERITIES; i++) {LogDestination* log = log_destination(i);if (log != NULL) {// Flush the base fileobject_ logger directly instead of going// through any wrappers to reduce chance of deadlock.log->fileobject_.FlushUnlocked();}}
}inline void LogDestination::FlushLogFiles(int min_severity) {// Prevent any subtle race conditions by wrapping a mutex lock around// all this stuff.MutexLock l(&log_mutex);for (int i = min_severity; i < NUM_SEVERITIES; i++) {LogDestination* log = log_destination(i);if (log != NULL) {log->logger_->Flush();}}
}使用者可以通过这两个函数人为主动的刷新缓冲区,让内容落地。
以上,我们讲解了GLog主要使用方法及其实现原理。实际GLog作为一个框架,也不失灵活性。
比如我们可以通过SetLogger方法修改不同等级的日志输出方法。
base::Logger* base::GetLogger(LogSeverity severity) {MutexLock l(&log_mutex);return LogDestination::log_destination(severity)->logger_;
}void base::SetLogger(LogSeverity severity, base::Logger* logger) {MutexLock l(&log_mutex);LogDestination::log_destination(severity)->logger_ = logger;
}下面代码是其使用的一个实例
struct MyLogger : public base::Logger {string data;virtual void Write(bool /* should_flush */,time_t /* timestamp */,const char* message,int length) {data.append(message, length);}virtual void Flush() { }virtual uint32 LogSize() { return data.length(); }
};static void TestWrapper() {fprintf(stderr, "==== Test log wrapper\n");MyLogger my_logger;base::Logger* old_logger = base::GetLogger(GLOG_INFO);base::SetLogger(GLOG_INFO, &my_logger);LOG(INFO) << "Send to wrapped logger";FlushLogFiles(GLOG_INFO);base::SetLogger(GLOG_INFO, old_logger);CHECK(strstr(my_logger.data.c_str(), "Send to wrapped logger") != NULL);
}我们还可以使用AddLogSink和RemoveLogSink方法自定义处理日志的逻辑。AddLogSink最终会调用到
inline void LogDestination::AddLogSink(LogSink *destination) {// Prevent any subtle race conditions by wrapping a mutex lock around// all this stuff.MutexLock l(&sink_mutex_);if (!sinks_) sinks_ = new vector<LogSink*>;sinks_->push_back(destination);
}其中sinks_是全局vector指针。它是独立于之前介绍的log_destinations_数组管理的日志输出方式。
// arbitrary global logging destinations.static vector<LogSink*>* sinks_;最终它会在SendToLog方法中的LogToSinks中被调用。
inline void LogDestination::LogToSinks(LogSeverity severity,const char *full_filename,const char *base_filename,int line,const struct ::tm* tm_time,const char* message,size_t message_len) {ReaderMutexLock l(&sink_mutex_);if (sinks_) {for (int i = sinks_->size() - 1; i >= 0; i--) {(*sinks_)[i]->send(severity, full_filename, base_filename,line, tm_time, message, message_len);}}
}作为使用者,我们需要定义send方法,并根据日志等级的不同,处理不同的逻辑。下面是GLog测试代码中的一个例子
virtual void send(LogSeverity severity, const char* /* full_filename */,const char* base_filename, int line,const struct tm* tm_time,const char* message, size_t message_len) {// Push it to Writer thread if we are the original logging thread.// Note: Something like ThreadLocalLogSink is a better choice// to do thread-specific LogSink logic for real.if (pthread_equal(tid_, pthread_self())) {writer_.Buffer(ToString(severity, base_filename, line,tm_time, message, message_len));}}最后介绍LOG_TO_SINK和LOG_TO_SINK_BUT_NOT_TO_LOGFILE宏,它是设置单个Sink的方式(AddLogSink是设置一个到多个sink的方式)
#define LOG_TO_SINK(sink, severity) \google::LogMessage( \__FILE__, __LINE__, \google::GLOG_ ## severity, \static_cast<google::LogSink*>(sink), true).stream()
#define LOG_TO_SINK_BUT_NOT_TO_LOGFILE(sink, severity) \google::LogMessage( \__FILE__, __LINE__, \google::GLOG_ ## severity, \static_cast<google::LogSink*>(sink), false).stream()它调用的是5个参数版本的LogMessage构造函数
LogMessage::LogMessage(const char* file, int line, LogSeverity severity,LogSink* sink, bool also_send_to_log): allocated_(NULL) {Init(file, line, severity, also_send_to_log ? &LogMessage::SendToSinkAndLog :&LogMessage::SendToSink);data_->sink_ = sink; // override Init()'s setting to NULL
}构造函数中true或false标识是否需要调用之前分析过的SendToLog()方法,还是只是调用SendToSink方法
void LogMessage::SendToSink() EXCLUSIVE_LOCKS_REQUIRED(log_mutex) {if (data_->sink_ != NULL) {RAW_DCHECK(data_->num_chars_to_log_ > 0 &&data_->message_text_[data_->num_chars_to_log_-1] == '\n', "");data_->sink_->send(data_->severity_, data_->fullname_, data_->basename_,data_->line_, &data_->tm_time_,data_->message_text_ + data_->num_prefix_chars_,(data_->num_chars_to_log_ -data_->num_prefix_chars_ - 1));}
}至此,我们便将Glog的实现原理分析完毕了。
在阅读代码和实验其使用过程中,可以发现GLog是一个非常优秀的日志开源库。但是如果想让GLog灵活的应用于产品中,其实还有很多事情可以做。比如我们可以将参数放到配置文件中,这样不至于我们每次修改参数时要重新编译代码。再比如我们可以定制自己的Sink,将日志数据发送到指定机器。
相关文章:

Ajax Toolkit 控件学习系列(13) ——FilteredTextBoxExtender 控制输入
这个控件的作用是对TextBox所要输入的内容进行过滤控制。按照自己需要过滤,可以自定义,再或者使用定义好的方式。看效果。效果不是很突出,说明下,就是只能输入大写字母和数字。因为加了限制,但是具体有什么高深的应用呢…
Uber最新开源Manifold,助力机器学习开发者的可视化与调试需求
所有参与投票的 CSDN 用户都参加抽奖活动群内公布奖项,还有更多福利赠送作者 | Lezhi Li译者 | 凯隐编辑 | Jane出品 | AI科技大本营(ID:rgznai100)【导语】2019 年 1 月,Uber 推出了 Manifold,一款与模型无…

jQuery对象和DOM对象使用说明
1.jQuery对象和DOM对象第一次学习jQuery,经常分辨不清哪些是jQuery对象,哪些是 DOM对象,因此需要重点了解jQuery对象和DOM对象以及它们之间的关系.DOM对象,即是我们用传统的方法(javascript)获得的对象,jQuery对象即是用jQuery类库…
[WPF疑难]避免窗口最大化时遮盖任务栏
[WPF疑难]避免窗口最大化时遮盖任务栏 周银辉 WPF窗口最大化时有个很不好的现象是:如果窗口的WindowStyle被直接或间接地设置为None后(比如很多情况下你会覆盖默认的窗体样式,即不采用Windows默认的边框和最大化最等按钮,来打造个…
Google Mock(Gmock)简单使用和源码分析——简单使用
初识Gmock是之前分析GTest源码时,它的源码和GTest源码在同一个代码仓库中(https://github.com/google/googletest)。本文我将以目前最新的Gmock1.7版本为范例,分析其实现原理。(转载请指明出于breaksoftware的csdn博客…
浪潮刘军:为什么说计算力是AI时代“免费的午餐”?
出品 | AI科技大本营(ID:rgznai100)产业AI、元脑生态是浪潮集团2019年度的两大关键词。作为一家以计算力为核心生产力的企业,浪潮还一直强调人工智能计算是未来最重要的计算力,而无论产业AI、元脑生态都构筑于计算的基础设施之上。…

Journey源码分析四:url路由
2019独角兽企业重金招聘Python工程师标准>>> 在入口函数main()的default分支中,对路由进行了注册,现在分析下。 ##main()中路由注册相关代码 源码: httpRouter : httptreemux.New() // Blog and pages as http server.InitializeBlog(httpRou…
“天河二号”总工程师杜云飞谈星光超算应用平台设计
整理 | 夕颜出品 | AI科技大本营(ID:rgznai100)【导读】12 月 21-22 日,OpenI/O 启智开发者大会在深圳召开。在大会上, 国家超级计算广州中心总工程师、“天河二号”总工程师杜云飞发表了题为《星光超算应用平台》的主题报告&…
Google Mock(Gmock)简单使用和源码分析——源码分析
源码分析 通过《Google Mock(Gmock)简单使用和源码分析——简单使用》中的例子,我们发现被mock的相关方法在mock类中已经被重新实现了,否则它们也不会按照我们的期待的行为执行。我们通过阅读源码,来分析整个过程的实现逻辑。(转载…

远程控制软件VNC教程和对内网机器控制的实现
网络遥控技术是指由一部计算机(主控端)去控制另一部计算机(被控端),而且当主控端在控制端时,就如同用户亲自坐在被控端前操作一样,可以执行被控端的应用程序,及使用被控端的系统资源…
GRUB2相关概念
GNU GRUB,简称“GRUB”,是一个来自GNU项目的启动引导程序。GRUB是多启动规范的实现,它允许用户可以在计算机内同时拥有多个操作系统,并在计算机启动时选择希望运行的操作系统。GRUB可用于选择操作系统分区上的不同内核,…
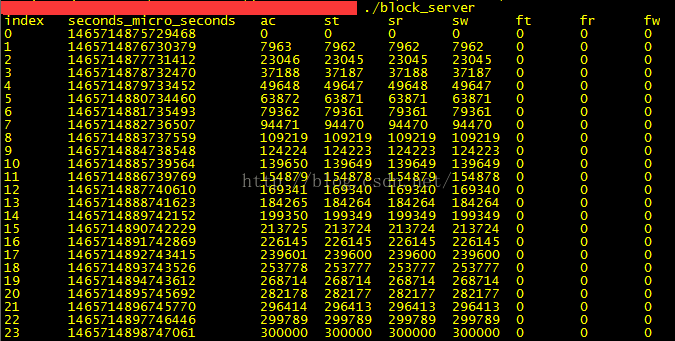
朴素、Select、Poll和Epoll网络编程模型实现和分析——朴素模型
做Linux网络开发,一般绕不开标题中几种网络编程模型。网上已有很多写的不错的分析文章,它们的基本论点是差不多的。但是我觉得他们讲的还不够详细,在一些关键论点上缺乏数据支持。所以我决定好好研究这几个模型。(转载请指明出于b…
支付宝账单出来后,除了总消费,你看到你的学习支出了吗?
当支付宝的2019年年度账单出来的时候很多人的第一反应就是我怎么花了这么多钱不少人都有这样的困惑忙忙碌碌一年到头,到底得到了什么?而这一切又和自己最开始的规划一样吗?其实从账单上可以看出你在2019年花费了哪些大头居家生活、穿衣打扮还…

体验Windows 7的Superbar
随着PDC 2008上Windows 7 M3 6801的发布,这个微软的下一代操作系统也渐渐浮出了水面。对于我们这些普通的PC用户而言,Windows 7相对于Windows Vista最显而易见的改变,无疑就是著名的Superbar任务栏了。说起它相比于原来的任务栏变化ÿ…
Linux 安装图形界面及远程连接
#可查询哪些组件是否已经安装(可用来对照组件名称) yum grouplistyum groupinstall X Window System -y #安装GNOME桌面环境 yum groupinstall GNOME Desktop Environment -y #安装KDE桌面环境 yum groupinstall KDE (K Desktop Environment)卸载 卸载GNOME桌面环境…
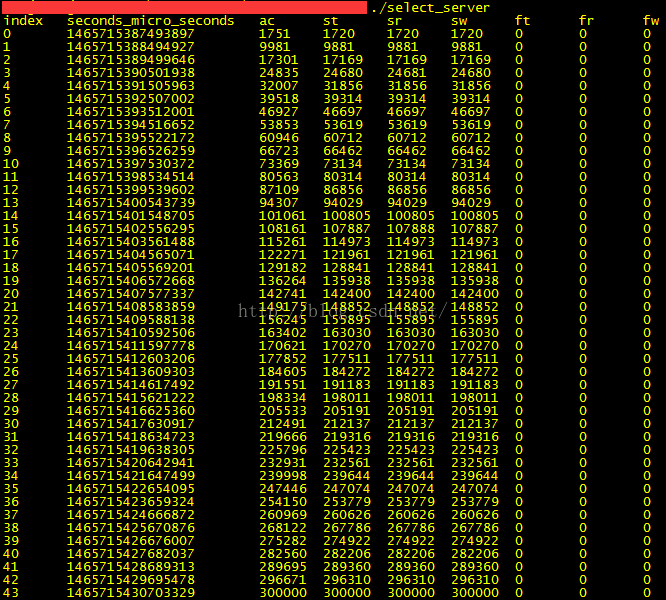
朴素、Select、Poll和Epoll网络编程模型实现和分析——Select模型
在《朴素、Select、Poll和Epoll网络编程模型实现和分析——朴素模型》中我们分析了朴素模型的一个缺陷——一次只能处理一个连接。本文介绍的Select模型则可以解决这个问题。(转载请指明出于breaksoftware的csdn博客) 和朴素模型一样,我们首先…
微软开源NAS算法Petridish,提高神经网络迁移能力
作者 | Jesus Rodriguez译者 | Rachel编辑 | 夕颜出品 | AI科技大本营(ID:rgznai100) 【导读】神经架构搜索(Neural architecture search, NAS)是深度学习中最热门的趋势之一。NAS方法针对特定问题和数据…
[转]g++ 编译多个相关文件
三个文件,一个头文件,两个程序文件 /*d.h */#include <iostream>usingnamespacestd; classDataset { public: intgetdata(); }; /*d.cpp */#include "d.h"intDataset::getdata() { return1231; } /*out.cpp */#include <ios…
POJ--2391--Ombrophobic Bovines【分割点+Floyd+Dinic优化+二分法答案】最大网络流量
联系:http://poj.org/problem?id2391 题意:有f个草场,每一个草场当前有一定数目的牛在吃草,下雨时它能够让一定数量的牛在这里避雨,f个草场间有m条路连接,每头牛通过一条路从一点到还有一点有一定的时间花…
25年了,我总结出这些信息提取的经验教训
作者 | Ehud Reiter译者 | 夕颜出品 | AI科技大本营(ID:rgznai100)【导读】近日,本文作者阿伯丁大学计算科学系教授 Ehud Reiter 及其带领的阅读小组读了一篇让他们印象深刻的论文——由 Ralph Grishman 发表的《信息提取 25 年》(…

朴素、Select、Poll和Epoll网络编程模型实现和分析——Poll模型
在《朴素、Select、Poll和Epoll网络编程模型实现和分析——Select模型》中,我们分析了它只能支持1024个连接同时处理的原因。但是在有些需要同时处理更多连接的情况下,1024个连接往往是不够的,也就是不能够高并发。那么这个时候我们就可以采用…
flashcom中远程共享对象SharedObject的用法
觉得这篇文章比较好,转载回来。学习fcs也有差不多一个月了,感觉最有特色的东西还是SharedObject.SharedObject有不少东西,本地操作就不说了(相信很多人没接触fcs也用过);就说说远程共享对象吧.基本的应用流程是:my_nc new NetConnection(); my_nc.connect("rt…

Hive-1.2.0学习笔记(一)安装配置
鲁春利的工作笔记,好记性不如烂笔头下载hive:http://hive.apache.org/index.htmlHive是基于Hadoop的一个数据仓库工具,提供了SQL查询功能,能够将SQL语句解析成MapReduce任务对存储在HDFS上的数据进行处理。MySQ安装Hive有三种运行…
邮件安全隐患及其防范技术研究
邮件安全隐患及其防范技术研究<?xml:namespace prefix o ns "urn:schemas-microsoft-com:office:office" />陈小兵【antian365.com】摘要电子邮件是Internet上使用最为频繁和广泛的服务,在给人们带来便利的同时,亦带来令人担忧的邮件…
必看!52篇深度强化学习收录论文汇总 | AAAI 2020
所有参与投票的 CSDN 用户都参加抽奖活动群内公布奖项,还有更多福利赠送来源 | 深度强化学习实验室(ID:Deep-RL)作者 | DeepRLAAAI 2020 共收到的有效论文投稿超过 8800 篇,其中 7737 篇论文进入评审环节,最终收录数量…

朴素、Select、Poll和Epoll网络编程模型实现和分析——Epoll模型
在阅读完《朴素、Select、Poll和Epoll网络编程模型实现和分析——Select模型》和《朴素、Select、Poll和Epoll网络编程模型实现和分析——Poll模型》两篇文章后,我们发现一个问题,不管select函数还是poll函数都不够智能,它们只能告诉我们成功…
Scala 深入浅出实战经典 第88讲:Scala中使用For表达式实现map、flatMap、filter
高级函数 map,flatMap,filter用for循环的实现。package com.dt.scala.forexpressionobject For_Advanced {def main(args: Array[String]) {}def map[A, B](list: List[A], f: A > B): List[B] for(element <- list) yield f(element)def flatMap[A, B](list: List[A], f…
抛弃Python,我们为什么用Go编写机器学习架构?
所有参与投票的 CSDN 用户都参加抽奖活动群内公布奖项,还有更多福利赠送作者 | Caleb Kaiser译者 | 弯月,编辑 | 郭芮来源 | CSDN(ID:CSDNnews)如今,众所周知Python是机器学习项目中最流行的语言。尽管R、C…

朴素、Select、Poll和Epoll网络编程模型实现和分析——模型比较
经过之前四篇博文的介绍,可以大致清楚各种模型的编程步骤。现在我们来回顾下各种模型(转载请指明出于breaksoftware的csdn博客) 模型编程步骤对比《朴素、Select、Poll和Epoll网络编程模型实现和分析——朴素模型》中介绍的是最基本的网络编程…

使用VM虚拟机的一点小技巧
今天想为朋友弄一个虚拟机系统文件,这样就可以直接拷贝过去,直接让他用了。哪成想电脑里的系统镜像文件不能用,也不知道是不是VM不支持,反正怎么着也引导不起来了。无奈只好用硬件光驱来装虚拟系统,把2003系统盘装入光…