Redis源码解析——字典基本操作
有了《Redis源码解析——字典结构》的基础,我们便可以对dict的实现进行展开分析。(转载请指明出于breaksoftware的csdn博客)
创建字典
一般字典创建时,都是没有数据的,但是字典类型需要确定,所以我们看到Redis字典创建主要需要定义数据操作的dictType对象:
static void _dictReset(dictht *ht)
{ht->table = NULL;ht->size = 0;ht->sizemask = 0;ht->used = 0;
}/* Create a new hash table */
dict *dictCreate(dictType *type,void *privDataPtr)
{dict *d = zmalloc(sizeof(*d));_dictInit(d,type,privDataPtr);return d;
}/* Initialize the hash table */
int _dictInit(dict *d, dictType *type,void *privDataPtr)
{_dictReset(&d->ht[0]);_dictReset(&d->ht[1]);d->type = type;d->privdata = privDataPtr;d->rehashidx = -1;d->iterators = 0;return DICT_OK;
}dictCreate的privaDataPtr一般都传Null。但是这个变量的设计是有原因的,因为作者希望提供一种能力,在框架调用一些使用者提供的方法时,能够将一些他们可能关心的数据透传回去。这种数据可能不一定是简单的数据,也可能是个函数指针。如果是个函数指针的话,那么在框架调用相关函数时,使用者通过privaDataPtr传递进来的函数指针将被回传,并在用户自定义的方法中执行。比如调用用户提供的对比数据的函数:
#define dictCompareKeys(d, key1, key2) \(((d)->type->keyCompare) ? \(d)->type->keyCompare((d)->privdata, key1, key2) : \(key1) == (key2))还有一个需要注意的是rehashidx。因为刚创建的初始字典不需要rehash,所以rehashidx为-1。
删除字典
字典删除操作也非常简单,其主要处理的就是两个dictht对象。因为这两个对象中有dictEntry数组,而每个数组元素均为一条链的首地址,于是删除操作既有链表释放,也有动态数组释放操作。
int _dictClear(dict *d, dictht *ht, void(callback)(void *)) {unsigned long i;/* Free all the elements */for (i = 0; i < ht->size && ht->used > 0; i++) {dictEntry *he, *nextHe;if (callback && (i & 65535) == 0) callback(d->privdata);if ((he = ht->table[i]) == NULL) continue;while(he) {nextHe = he->next;dictFreeKey(d, he);dictFreeVal(d, he);zfree(he);ht->used--;he = nextHe;}}/* Free the table and the allocated cache structure */zfree(ht->table);/* Re-initialize the table */_dictReset(ht);return DICT_OK; /* never fails */
}/* Clear & Release the hash table */
void dictRelease(dict *d)
{_dictClear(d,&d->ht[0],NULL);_dictClear(d,&d->ht[1],NULL);zfree(d);
}上面函数中dictFreeKey和dictFreeValue实则是调用dictType中传入的数据释放函数
#define dictFreeVal(d, entry) \if ((d)->type->valDestructor) \(d)->type->valDestructor((d)->privdata, (entry)->v.val)#define dictFreeKey(d, entry) \if ((d)->type->keyDestructor) \(d)->type->keyDestructor((d)->privdata, (entry)->key)字典扩容和缩容
我们知道Redis的字典是通过数组和链表相结合的方式实现的。理论上说,如果数组长度不变,链表长度改变则可以达到字典内容增减的目的。但是为什么还要设计扩容和缩容呢?首先说明下,这儿讲解的两个概念是针dictht的table的——即针对数组结构的。那么有了《Redis源码解析——字典结构》知识,我们可以得知,针对数组长度的增减是为了:在链表过长影响查找效率时,扩大数组长度以减小链表长度,达到性能优化。在数据过于稀疏的情况下,减小数组长度以使得无效数组指针变少,从而达到节约空间的目的。
我们先看看扩容的计算:
/* Expand the hash table if needed */
static int _dictExpandIfNeeded(dict *d)
{/* Incremental rehashing already in progress. Return. */if (dictIsRehashing(d)) return DICT_OK;/* If the hash table is empty expand it to the initial size. */if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);/* If we reached the 1:1 ratio, and we are allowed to resize the hash* table (global setting) or we should avoid it but the ratio between* elements/buckets is over the "safe" threshold, we resize doubling* the number of buckets. */if (d->ht[0].used >= d->ht[0].size &&(dict_can_resize ||d->ht[0].used/d->ht[0].size > dict_force_resize_ratio)){return dictExpand(d, d->ht[0].used*2);}return DICT_OK;
}其中最核心的是检查ht[0]中元素个数和保存链表首地址的数组长度的商是否大于dict_force_resize_ratio——5。这个公式是计算链表的平均长度(数组中NULL意味着该对应的链表长度为0)。如果平均长度大于5,则需要通过dictExpand方法让数组去扩容
int dictExpand(dict *d, unsigned long size)
{dictht n; /* the new hash table */unsigned long realsize = _dictNextPower(size);/* the size is invalid if it is smaller than the number of* elements already inside the hash table */if (dictIsRehashing(d) || d->ht[0].used > size)return DICT_ERR;/* Rehashing to the same table size is not useful. */if (realsize == d->ht[0].size) return DICT_ERR;/* Allocate the new hash table and initialize all pointers to NULL */n.size = realsize;n.sizemask = realsize-1;n.table = zcalloc(realsize*sizeof(dictEntry*));n.used = 0;/* Is this the first initialization? If so it's not really a rehashing* we just set the first hash table so that it can accept keys. */if (d->ht[0].table == NULL) {d->ht[0] = n;return DICT_OK;}/* Prepare a second hash table for incremental rehashing */d->ht[1] = n;d->rehashidx = 0;return DICT_OK;
}至于扩容的大小要看下面的实现
static unsigned long _dictNextPower(unsigned long size) {unsigned long i = DICT_HT_INITIAL_SIZE;if (size >= LONG_MAX) return LONG_MAX;while(1) {if (i >= size)return i;i *= 2;}
}可以见的_dictNextPower是获取最近接size的,但是比size大的2的N次幂。这样就可以让链表平均长度降低到5/4~5/2之间(1.24~2.5)。
我们再注意下dictExpand函数,它最后将分配的空间赋值给ht[1]。如果进入这个场景,就意味着要进行rehash操作了——因为ht[1]就是为了临时保存rehash结果的。
接下来看看缩容计算:
/* Resize the table to the minimal size that contains all the elements,* but with the invariant of a USED/BUCKETS ratio near to <= 1 */
int dictResize(dict *d)
{int minimal;if (!dict_can_resize || dictIsRehashing(d)) return DICT_ERR;minimal = d->ht[0].used;if (minimal < DICT_HT_INITIAL_SIZE)minimal = DICT_HT_INITIAL_SIZE;return dictExpand(d, minimal);
}函数注释写的很清楚:在平均链表长度低于1时要缩容了。但是作者并没有在字典内容减少时检测是否需要缩容,甚至没有设计一个检测是否需要缩容的函数,而是将这个方法暴露给用户去做。我想是因为这种场景不影响字典的执行效率,而内存问题可能更多是应该让用户去考虑。
Rehash操作
Rehash操作是Dict库的重要算法,好在逻辑我们已经在《Redis源码解析——字典结构》讲清楚了,现在我们就看看它的实现
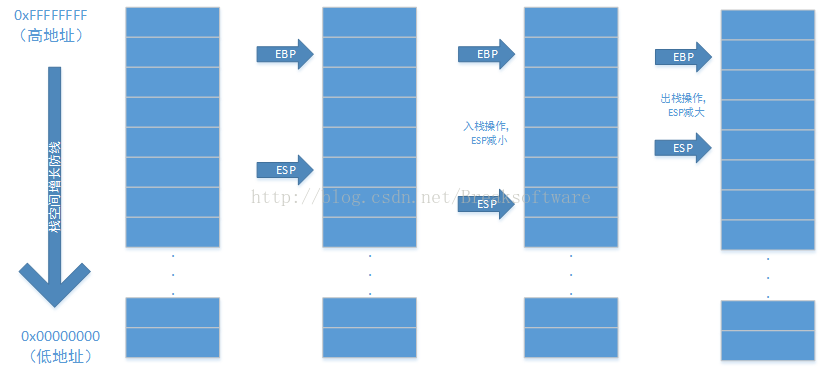
int dictRehash(dict *d, int n) {该函数需要传入字典指针d和步进长度n,返回0或者1。这儿的步进长度需要说明下,因为Redis的字典rehash操作是渐进的分步来完成,所以每步需要渐进多少距离需要指定。然后dictht的dictEntry数组可能存在连续的空指针,这些空指针没有数据链,因此不需要rehash,所以不用对它们进行操作。于是步进距离只是针对有效的数组指针,比如我们针对下图结构进行rehash
我们假设步进长度为1,则对上面进行rehash时,ht[0].table的前两个元素均被跳过,第三个元素所指向的链上数据将被rehash。因为步进长度为1,且已经rehash了数组中第三条链的数据,所以认为该次步进结束。

int empty_visits = n*10; /* Max number of empty buckets to visit. */if (!dictIsRehashing(d)) return 0;while(n-- && d->ht[0].used != 0) {dictEntry *de, *nextde;/* Note that rehashidx can't overflow as we are sure there are more* elements because ht[0].used != 0 */assert(d->ht[0].size > (unsigned long)d->rehashidx);while(d->ht[0].table[d->rehashidx] == NULL) {d->rehashidx++;if (--empty_visits == 0) return 1;}但是作者认为数组中有效步进长度内,过多的空指针也是会影响rehash效率。于是作者定义了empty_visits的值为步进长度10倍,如果有效步进长度内空指针数大于empty_visits的值,则需要提前跳出rehash操作,并返回1。可能有读者会疑问,跳过空指针又不耗费时间,干嘛要做这个限制呢?其实问题不出在空指针上,而是因为数组中有过多空指针的话,意味着数据向数据链上堆积,于是每步进一次,需要rehash该链上的数据也会相对较多,时间消耗也会变长。所以限制空数据链的实质是优化步进的操作耗时的不确定性。
通过while我们可以看出,如果达到步进长度,或者ht[0]上的数据已经全被rehash到ht[1]上去了,rehash操作就完成了。我们再看戏rehash的具体操作:
de = d->ht[0].table[d->rehashidx];/* Move all the keys in this bucket from the old to the new hash HT */while(de) {unsigned int h;nextde = de->next;/* Get the index in the new hash table */h = dictHashKey(d, de->key) & d->ht[1].sizemask;de->next = d->ht[1].table[h];d->ht[1].table[h] = de;d->ht[0].used--;d->ht[1].used++;de = nextde;}d->ht[0].table[d->rehashidx] = NULL;d->rehashidx++;}这个过程就是不停的对ht[0].table上数组进行遍历,如果数组元素不为空,则遍历并rehash该元素指向的链表上的元素。如果ht[0]上数据已经全rehash到ht[1]上,则其used参数为0。这个时候则让ht[0]等于ht[1],而ht[1]自身释放掉,从而达到在ht[0]中的数据被全部rehash的目的。
/* Check if we already rehashed the whole table... */if (d->ht[0].used == 0) {zfree(d->ht[0].table);d->ht[0] = d->ht[1];_dictReset(&d->ht[1]);d->rehashidx = -1;return 0;}/* More to rehash... */return 1;
}总结下dictRehash操作:它是通过用户指定有效步进长度,并结合实际数据分布情况,将ht[0]上数据重新rehash到ht[1]上。如果ht[0].table数组全部被遍历过,则认为rehash完成并返回0,否则返回1。
Rehash的时机
之前我们讲过为什么要rehash,现在我们探讨下分步rehash的时机。
当一个Redis字典需要rehash时,它没有采用一次性完成的方案,而是采用渐进式。于是保持在中间状态的字典又是在何时被继续rehash的呢?Redis的字典库提供了两个时机,一个是在对字典进行更新或者查找操作时;另一个则是提供给使用者一个接口,由其决定决定何时去rehash。
因为查找或者更新操作都是需要耗费一定时间,所以此时的rehash也不应该“蹭”过多的时间,于是步进设置为1。
static void _dictRehashStep(dict *d) {if (d->iterators == 0) dictRehash(d,1);
}另一种是是提供给用户触发的,但是作者还是希望尽量保证其操作时间不可以过长,所以提供了下面的方法:
/* Rehash for an amount of time between ms milliseconds and ms+1 milliseconds */
int dictRehashMilliseconds(dict *d, int ms) {long long start = timeInMilliseconds();int rehashes = 0;while(dictRehash(d,100)) {rehashes += 100;if (timeInMilliseconds()-start > ms) break;}return rehashes;
}此时rehash操作的步进长度为100,这样相对于步进长度为1的情况,算是批量操作,可以省去函数调用和返回的时间消耗。相应的,还需要使用者提供时间进行约束。至于时长多少,使用者需要自己权衡了。
增加元素
新增元素通过下面函数实现
int dictAdd(dict *d, void *key, void *val)
{dictEntry *entry = dictAddRaw(d,key);if (!entry) return DICT_ERR;dictSetVal(d, entry, val);return DICT_OK;
}dictAddRaw方法获取一个新的dictEntry指针,然后通过用于传入的函数指针,将value复制到dictEntry所指向的对象的值上
#define dictSetVal(d, entry, _val_) do { \if ((d)->type->valDup) \entry->v.val = (d)->type->valDup((d)->privdata, _val_); \else \entry->v.val = (_val_); \
} while(0)dictAddRaw方法的实现我们需要注意下。首先它会检测该字典是否处在rehash的状态,如果是,则让其rehash一步
dictEntry *dictAddRaw(dict *d, void *key)
{int index;dictEntry *entry;dictht *ht;if (dictIsRehashing(d)) _dictRehashStep(d);然后检测key是否已经在map中存在,如果存在则不能新增;否则返回key所在的指针数组的下标。(dictHashKey(ht, key) & ht->sizemask;)
/* Get the index of the new element, or -1 if* the element already exists. */if ((index = _dictKeyIndex(d, key)) == -1)return NULL;由于字典可能处在rehash的中间状态,数据一部分在ht[0]中,有一部分在ht[1]中。这个时候就需要判断新增的dictEntry是要加到哪个dictht上:如果在rehash,则新增到ht[1]上。因为如果新增到ht[0]上,此时rehashidx可能已经越过刚新增key对应的索引,导致数据丢失;如果不在rehash状态,则新增到ht[0]上。
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];entry = zmalloc(sizeof(*entry));entry->next = ht->table[index];ht->table[index] = entry;ht->used++;/* Set the hash entry fields. */dictSetKey(d, entry, key);return entry;
}删除元素
删除元素时,需要在ht[0]和ht[1]中查找并删除,所以会遍历两个table
static int dictGenericDelete(dict *d, const void *key, int nofree)
{unsigned int h, idx;dictEntry *he, *prevHe;int table;if (d->ht[0].size == 0) return DICT_ERR; /* d->ht[0].table is NULL */if (dictIsRehashing(d)) _dictRehashStep(d);h = dictHashKey(d, key);for (table = 0; table <= 1; table++) {然后找到key对应的指针数组的下标
idx = h & d->ht[table].sizemask;sizemask是数组长度减去1。上面这步与操作,相当于让hash值向数组长度取余数。比如我们hash值是5(0x101),数组长度是4(0x100),则sizemask为3(0x011)。5和3进行与运算,得出的是0x001,即5%4的结果。
找到指针下标后,则对该下标所指向的链表进行遍历。找到元素就将其从链表中摘除。至于是否需要通过用户提供的析构函数将key和value析构掉,要视传入的force值决定。
he = d->ht[table].table[idx];prevHe = NULL;while(he) {if (key==he->key || dictCompareKeys(d, key, he->key)) {/* Unlink the element from the list */if (prevHe)prevHe->next = he->next;elsed->ht[table].table[idx] = he->next;if (!nofree) {dictFreeKey(d, he);dictFreeVal(d, he);}zfree(he);d->ht[table].used--;return DICT_OK;}prevHe = he;he = he->next;}if (!dictIsRehashing(d)) break;}return DICT_ERR; /* not found */
}Redis字典库对上面方法进行封装,提供了下面这两个函数:
int dictDelete(dict *ht, const void *key) {return dictGenericDelete(ht,key,0);
}int dictDeleteNoFree(dict *ht, const void *key) {return dictGenericDelete(ht,key,1);
}查找元素
查找元素也需要考虑字典是否在rehash的过程中,于是查找也要视情况看看在ht[0]中查找,还是也要在ht[1]中查找:
dictEntry *dictFind(dict *d, const void *key)
{dictEntry *he;unsigned int h, idx, table;if (d->ht[0].used + d->ht[1].used == 0) return NULL; /* dict is empty */if (dictIsRehashing(d)) _dictRehashStep(d);h = dictHashKey(d, key);for (table = 0; table <= 1; table++) {idx = h & d->ht[table].sizemask;he = d->ht[table].table[idx];while(he) {if (key==he->key || dictCompareKeys(d, key, he->key))return he;he = he->next;}if (!dictIsRehashing(d)) return NULL;}return NULL;
}void *dictFetchValue(dict *d, const void *key) {dictEntry *he;he = dictFind(d,key);return he ? dictGetVal(he) : NULL;
}修改(无时新增)元素
Redis的字典库,会先尝试往字典里新增该key,然后再查找到该key,让其value变成需要替换的值,最后还要将原来的value释放掉
int dictReplace(dict *d, void *key, void *val)
{dictEntry *entry, auxentry;/* Try to add the element. If the key* does not exists dictAdd will suceed. */if (dictAdd(d, key, val) == DICT_OK)return 1;/* It already exists, get the entry */entry = dictFind(d, key);/* Set the new value and free the old one. Note that it is important* to do that in this order, as the value may just be exactly the same* as the previous one. In this context, think to reference counting,* you want to increment (set), and then decrement (free), and not the* reverse. */auxentry = *entry;dictSetVal(d, entry, val);dictFreeVal(d, &auxentry);return 0;
}相关文章:

[转]控制 Cookie 的作用范围
默认时,网站的所有 Cookies 都一起被存储在客户端,并且所有 Cookies 连同网站的任何请求一起被发送到服务器。换句话说,网站中的每个页面都能够为网站获取所有的 Cookies。但是,你能够通过两个方式来设置 Cookies 的作用范围&…
强化学习70年演进:从精确动态规划到基于模型
作者 | Nathan Lambert译者 | 泓礼编辑 | 夕颜出品 | AI科技大本营(ID: rgznai100)【导读】这是一份帮你了解强化学习算法本质的资源,无需浏览大量文档,没有一条公式,非常适合学生和研究人员阅读。作为强化学习研究人员…
Android ActionBar相关
1.Android 5.0 删除ActionBar下面的阴影 于Android 5.0假设你发现的ActionBar下面出现了阴影,例如,下面的设置,以消除阴影: getActionBar().setElevation(0); Android 5.0之前能够用以下代码消除阴影: <item name&q…

Redis源码解析——字典遍历
之前两篇博文讲解了字典库的基础,本文将讲解其遍历操作。之所以将遍历操作独立成一文来讲,是因为其中的内容和之前的基本操作还是有区别的。特别是高级遍历一节介绍的内容,充满了精妙设计的算法智慧。(转载请指明出于breaksoftwar…
开发者在行动!中国防疫开源项目登上GitHub TOP榜
整理 | 唐小引出品 | CSDN(ID:CSDNnews)【导读】用开发者们的方式支援这场没有硝烟的战争!截止北京时间 1 月 28 日下午 15:47,全国确诊新型冠状病毒的数字已经到达了 4586 例,疑似高达 6973 例,…
像童话一样学习OSPF原理
可以把整个网络(一个自治系统AS)看成一个王国,这个王国可以分成几个 区(area),现在我们来看看区域内的某一个人(你所在的机器root)是怎样得到一张 世界地图(routing table)的。 首先,你得跟你周围的人(…

队列——PowerShell版
继续读啊哈磊《啊哈!算法》感悟系列——队列 地铁售票处排队,先来的人先到队首先买完先走,后来的人排在队尾等候后买完后走。 想买票,必须排在队尾;买完票,只能从队首离开。 这种先进先出(First…
Redis源码解析——双向链表
相对于之前介绍的字典和SDS字符串库,Redis的双向链表库则是非常标准的、教科书般简单的库。但是作为Redis源码的一部分,我决定还是要讲一讲的。(转载请指明出于breaksoftware的csdn博客) 基本结构 首先我们看链表元素的结构。因为…
12月第三周安全要闻回顾:浏览器安全不容忽视,SSL弱点影响网站安全
本周(081215至081221)安全方面的新闻众多,主要集中在***与威胁趋势方面。浏览器安全方向波澜起伏,微软推出了针对上周公开的IE7新漏洞的紧急安全补丁,但目前互联网上针对该漏洞的大规模***仍在继续,******的…
GPT2文本生成有问题?这里有些潜在解决思路
作者 | Leo Gao译者 | 凯隐编辑 | 夕颜出品 | AI科技大本营(ID: rgznai100) 【导读】在过去的一年中,人们对文本生成模型的兴趣重新燃起,这在很大程度上要归功于GPT2,它主要展示了使用更大模型、更大数据和更大计算量的…
HTML5学习之二:HTML5中的表单2
(本内容部分节选自《HTML 5从入门到精通》) 对表单的验证 ———————————————————————————————————————————————————————— •1、required属性 required属性主要目的是确保表单控件中的值已填写。在提交时&…
Redis源码解析——有序整数集
有序整数集是Redis源码中一个以大尾(big endian)形式存储,由小到大排列且无重复的整型集合。它存储的类型包括16位、32位和64位的整型数。在介绍这个库的实现前,我们还需要先熟悉下大小尾内存存储机制。(转载请指明出于…
GitHub标星1.2w+,Chrome最天秀的插件都在这里
作者 | Rocky0429来源 | Python空间(ID: Devtogether)大家好,我是 Rocky0429,一个沉迷 Chrome 不能自拔的蒟蒻...作为一个在远古时代用过什么 IE、360、猎豹等浏览器的资深器哥,当我第一次了解 Chrome 的时候ÿ…
基础篇 第四节 项目进度计划编辑 之 任务关联性设定
1.任务关联性的类型 ◎完成 —— 开始 FS ◎开始 —— 开始 SS ◎开始 —— 完成 SF 完成 —— 完成 FF 2.设定任务关联性 三种方法: ◎在条形图中直接拖拽 ◎在“前置任务”列中编辑 ◎在“任务信息”中的“前置任务”选项卡中编辑 3.设定“延隔时间” 延隔时间小于…

开坑,写点Polymer 1.0 教程第3篇——组件注册与创建
之前一篇算是带大家大致领略了一下Polymer的风采。这篇我们稍微深入一丢丢,讲下组件的注册和创建。 创建自定义组件的几种方式 这里我们使用Polymer函数注册了一个自定义组件"my-element" // register an element Polymer({is: my-element,created: funct…

Redis源码解析——Zipmap
本文介绍的是Redis中Zipmap的原理和实现。(转载请指明出于breaksoftware的csdn博客) 基础结构 Zipmap是为了实现保存Pair(String,String)数据的结构,该结构包含一个头信息、一系列字符串对(之后把一个“字符串对”称为一个“元素…
IIS7入门之旅:(3)CGI application和FastCGI application的区别
前言: 一如既往地,IIS支持通过提供pluggable module来提供对第3方script的支持,例如php等。在IIS7中,对于CGI的支持有了一个新的变化,就是同时提供了2种CGI支持模块,分别为:CGIModule (cgi.dll)和FastCGIMo…

抗击疫情!阿里云为加速新药疫苗研发提供免费AI算力
1月29日,阿里云正式宣布:疫情期间,向全球公共科研机构免费开放一切AI算力,以加速本次新型肺炎新药和疫苗研发。 目前,中国疾控中心已成功分离病毒,疫苗研发和药物筛选仍在争分夺秒地进行。新药和疫苗研发期…
SpriteBuilder中如何平均拉伸精灵帧动画的距离
首先要在Timeline中选中所有的精灵帧,可以通过如下2种的任意一种办法达成: 1按下Shift键的同时鼠标单击它们 2鼠标在Timeline空白区拖拽直到拉出的矩形包围住所有精灵帧方块后放开鼠标。 你可以通过查看Timeline中精灵帧方块上是否有阴影来辨识是否选中…
C++拾趣——类构造函数的隐式转换
之前看过一些批判C的文章,大致意思是它包含了太多的“奇技淫巧”,并不是一门好的语言。我对这个“奇技淫巧”的描述颇感兴趣,因为按照批判者的说法,C的一些特性恰巧可以让一些炫耀技术的同学有了炫耀的资本——毕竟路人皆知的东西…
数十名工程师作战5天,阿里达摩院连夜研发智能疫情机器人
作者 | Just出品 | AI科技大本营(ID:rgznai100)新型肺炎疫情防控战在各大互联网科技公司拉响,阿里、百度等公司陆续对外提供相应技术和产品。当前,疫情当前防控一线人员紧缺,多地政务热线迎来大波问询市民,…

路由器互联端口处于不同网段的路由方法和原理
如下图:两台cisco路由器相连接的两个端口不在同一个网络,如何实现两台路由器的互联?初看似乎绝对不可能,但是这是可行的,而且我已经把这个变成了现实。这里讲述配置的方法,以及解释原理。这个就要讲到路由原…

上网行为管理产品选型简单考量
信息化浪潮汹涌向前,人们的生活、工作、学习越来越离不开IT,离不开网络。 对于很多组织来讲,网络就意味着效率、甚至生产力,协同办公、决策、科研、资金划拨等等都对网络有了前所未有的依赖。网络应用日益复杂、多变、动态特征发展…

码农技术炒股之路——配置管理器、日志管理器
配置管理器和日志管理器是项目中最为独立的模块。我们可以很方便将其剥离出来供其他Python工程使用。文件的重点将是介绍Python单例和logging模块的使用。(转载请指明出于breaksoftware的csdn博客) 配置管理器 在《码农技术炒股之路——架构和设计》中我…
“数学不好,干啥都不行!”资深程序员:别再瞎努力了!
之前很多程序员读者向我们反馈:1)做算法优化时,只能现搬书里的算法,遇到不一样的问题,就不会了。2)面试一旦涉及到算法和数据结构,如果数学不行,面试基本就凉凉了。3)算法…

受限列表 队列与栈
2019独角兽企业重金招聘Python工程师标准>>> 队列与栈为受限列表,队列为先入先出型列表,而栈为先入后出型列表,有关列表的实现可以查看 http://my.oschina.net/u/2011113/blog/514713 。 结构图为 Queue实现了IQueue接口ÿ…

码农技术炒股之路——数据库管理器、正则表达式管理器
我选用的数据库是Mysql。选用它是因为其可以满足我的需求,而且资料多。因为作为第三方工具,难免有一些配置问题。所以本文也会讲解一些和Mysql配置及开发相关的问题。(转载请指明出于breaksoftware的csdn博客) 数据库管理器 Mysq…

Overview of ISA and TMG Networking and ISA Networking Case Study (Part 1)
老方说:此篇文章摘自ISASERVER.ORG网站,出自Thomas Shinder达人之手。严重建议ISA爱好者看看。Published: Dec 16, 2008 Updated: Jan 21, 2009 Author: Thomas Shinder What ISA/TMG firewall Networks are about and how the firewall uses these ne…
阿里云免费开放一切AI算力,加速新型冠状病毒新药和疫苗研发
近日,阿里云宣布,为了帮助加速新药和疫苗研发,将向全球公共科研机构免费开放一切AI算力。目前,中国疾控中心已成功分离病毒,疫苗研发和药物筛选仍在争分夺秒地进行。新药和疫苗研发期间,需要进行大量的数据…