几行代码构建全功能的对象检测模型,他是如何做到的?
作者 | Alan Bi
译者 | 武明利,责编 | Carol
出品 | AI科技大本营(ID:rgznai100)
如今,机器学习和计算机视觉已成为一种热潮。我们都看过关于自动驾驶汽车和面部识别的新闻,可能会想象建立自己的计算机视觉模型有多酷。然而,进入这个领域并不总是那么容易,尤其是在没有很强的数学背景的情况下。如果你只想做一些小的实验,像PyTorch和TensorFlow这样的库可能会很枯燥。
在本教程中,作者提供了一种简单的方法,任何人都可以使用几行代码构建全功能的对象检测模型。更具体地说,我们将使用Detecto,这是一个在PyTorch之上构建的Python软件包,可简化该过程并向所有级别的程序员开放。
快速简单的例子
为了演示如何简单地使Detecto,让我们加载一个预先训练的模型,并对以下图像进行推断:
首先,使用pip下载Detecto软件包:
pip3 install detectofrom detectoimport core, utils, visualizeimage = utils.read_image('fruit.jpg')model = core.Model()labels, boxes, scores = model.predict_top(image)
visualize.show_labeled_image(image, boxes, labels)运行此文件后(如果你的计算机上没有启用CUDA的GPU,可能会花费几秒钟;稍后再进行介绍),你应该会看到类似下面的图:
作者仅用了5行代码就完成了所有工作,真的是太棒了。下面是我们每步中分别做的:
1)导入Detecto模块
2)读入图像
3)初始化预训练模型
4)在图像上生成最高预测
5)为预测绘图
绘制我们的预测
Detecto使用来自PyTorch模型动物园中的Faster R-CNN ResNet-50 FPN,它能够检测大约80种不同的物体,例如动物,车辆,厨房用具等。但是,如果你想要检测自定义对象,例如可口可乐与百事可乐罐,斑马与长颈鹿,该怎么办呢?
这时你会发现,在自定义数据集上训练探测器模型同样简单; 同样,你只需要5行代码,以及现有的数据集或花一些时间标记图像。
构建自定义数据集
在本教程中,作者将从头开始构建自己的数据集。建议你也这样做,但是如果你想跳过这一步,你可以在这里下载一个示例数据集(从斯坦福的Dog数据集修改)。
对于我们的数据集,我们将训练我们的模型来检测来自RoboSub竞赛的水下外星人,蝙蝠和女巫,如下所示:
理想情况下,每个类至少需要100张图像。好在每张图像中可以有多个对象,所以理论上,如果每张图像包含你想要检测的每类对象,那么你可以总共获得100张图像。另外,如果你有视频素材,Detico可以轻松地将这些视频素材分割成可用于数据集的图像:
from detecto.utilsimport split_videosplit_video('video.mp4','frames/', step_size=4)上面的代码在“video.mp4”中每第4帧拍摄一次,并将其另存为JPEG文件存在“frames”文件夹中。
生成训练数据集后,应该具有一个类似于以下内容的文件夹:
images/
| image0.jpg
| image1.jpg
| image2.jpg
| ...如果需要的话,你还可以使用另一个文件夹,其中包含一组验证图像。
现在是耗时的部分:标记。Detecto支持PASCAL VOC格式,其中具有XML文件,其中包含图像中每个对象的标签和位置数据。要创建这些XML文件,可以使用开源LabelImg工具,如下所示:
pip3 install labelImg # Download LabelImg using pip
labelImg # Launch the application现在,你应该会看到一个弹出窗口。单击左侧“打开目录”按钮,然后选择想要标记的图像文件夹。如果一切正常,你应该会看到类似以下内容:
要绘制边界框,请单击左侧菜单栏中的图标(或使用键盘快捷键“w”)。然后,你可以在对象周围拖动一个框并编写/选择标签:
标记完图像后,请使用CTRL+S或CMD+S保存XML文件(为简便起见,你可以使用自动填充的默认文件位置和名称)。要标记下一张图像,请单击“下一张图像”(或使用键盘快捷键“d”)。
整个数据集处理完毕之后,你的文件夹应如下所示:
images/
| image0.jpg
| image0.xml
| image1.jpg
| image1.xml
| ...我们已经准备好开始训练我们的对象检测模型了!
访问GPU
首先,检查你的计算机是否具有启用CUDA的GPU。由于深度学习需要大量处理能力,因此在通常的CPU上进行训练可能会非常缓慢。值得庆幸的是,大多数现代深度学习框架(例如PyTorch和Tensorflow)都可以在GPU上运行,从而使处理速度更快。确保已经下载了PyTorch(如果你安装了Detecto,应该已经下载了),然后运行以下两行代码:
import torchprint(torch.cuda.is_available())如果打印True,那你可以跳到下一部分。如果显示False,不要担心。请按照以下步骤创建Google Colaboratory笔记本,这是一个在线编码环境,带有免费可用的GPU。对于本教程,你将只在Google Drive文件夹中工作,而不是在计算机上工作。
1)登录到Google Drive
2)创建一个名为“Detecto Tutorial”的文件夹并导航到该文件夹
3)将你的训练图像(和/或验证图像)上传到此文件夹
4)右键单击,转到“更多”,然后单击“Google Colaboratory”:
你现在应该看到这样的界面:
5)根据需要给笔记本起个名字,然后转到“编辑”->“笔记本设置”->“硬件加速器”,然后选择“GPU”
6)输入以下代码以“装入”你的云端硬盘,将目录更改为当前文件夹,然后安装Detecto:
import os
from google.colabimport drivedrive.mount('/content/drive')os.chdir('/content/drive/My Drive/Detecto Tutorial')!pip install detecto为了确保一切正常,你可以创建一个新的代码单元,然后输入!ls以检查你是否处于正确的目录中。
训练自定义模型
最后,我们现在可以在自定义数据集上训练模型了。如前所述,这是容易的部分。它只需要4行代码:
让我们再次分解一下我们每行代码所做的工作:
1、导入的Detecto模块
2、从“images”文件夹(包含我们的JPEG和XML文件)创建了一个数据集
3、初始化模型检测自定义对象(外星人,蝙蝠和女巫)
4、在数据集上训练我们的模型
根据数据集的大小,这可能需要10分钟到1个小时以上的时间来运行,因此请确保你的程序在完成上述语句后不会立即退出(例如:你使用的是Jupyter / Colab笔记本,它在活动时保留状态)。
使用训练好的模型
现在你已经有了训练好的模型,让我们在一些图像上对其进行测试。要从文件路径读取图像,可以使用detecto.utils模块中的read_image函数(也可以使用上面创建的数据集中的图像):
# Specify the path to your image
image = utils.read_image('images/image0.jpg')
predictions = model.predict(image)# predictions format: (labels, boxes, scores)
labels, boxes, scores = predictions# ['alien', 'bat', 'bat']
print(labels)# xmin ymin xmax ymax
# tensor([[ 569.2125, 203.6702, 1003.4383, 658.1044],
# [ 276.2478, 144.0074, 579.6044, 508.7444],
# [ 277.2929, 162.6719, 627.9399, 511.9841]])
print(boxes)# tensor([0.9952, 0.9837, 0.5153])
print(scores)正像你看到的,模型的预测方法返回一个由3个元素组成的元组:标签,方框和分数。在上面的示例中,此模型在坐标[569、204、1003、658](框[0])处预测了一个外星人(标签[0]),其置信度为0.995(得分[0])。
根据这些预测,我们可以使用detecto.visualize模块绘制结果。例如:
visualize.show_labeled_image(image, boxes, labels)
将上面的代码与收到的图像和预测一起运行将产生如下所示的内容:
如果你有一个视频,你可以在它上面运行对象检测:
visualize.detect_video(model,'input.mp4','output.avi')
这将获取一个名为“input.mp4”的视频文件,并根据给定模型的预测结果生成一个“output.avi”文件。如果你使用VLC或其他视频播放器打开此文件,应该会看到一些希望看到的结果!
最后,你可以从文件中保存和加载模型,从而可以保存进度并稍后返回:
model.save('model_weights.pth')# ... Later ...model = core.Model.load('model_weights.pth', ['alien','bat','witch'])高级用法
你会发现Detecto不仅限于5行代码。举例来说,这个模型没有你希望的那么好。我们可以尝试通过使用Torchvision转换来扩展我们的数据集并定义一个自定义数据加载器来提高其性能:
from torchvisionimport transformsaugmentations = transforms.Compose([transforms.ToPILImage(),transforms.RandomHorizontalFlip(0.5),transforms.ColorJitter(saturation=0.5),transforms.ToTensor(),utils.normalize_transform(),
])dataset = core.Dataset('images/', transform=augmentations)loader = core.DataLoader(dataset, batch_size=2, shuffle=True)此代码对数据集中的图像应用了随机的水平翻转和饱和效果,从而增加了数据的多样性。然后,我们使用batch_size = 2定义一个数据加载对象;我们将其传递给model.fit而不是Dataset,这样来告诉我们的模型是对2张图像进行批量训练,而不是默认的1张。
如果你之前创建了单独的验证数据集,那么现在是在训练期间加载它的时候了。通过提供验证数据集,fit方法将返回每个时期的损失列表,如果verbose = True,则会在训练过程中将其打印出来。以下代码块演示了这一点,并自定义了其他几个训练参数:
import matplotlib.pyplotas pltval_dataset = core.Dataset('validation_images/')losses = model.fit(loader, val_dataset, epochs=10, learning_rate=0.001,lr_step_size=5, verbose=True)plt.plot(losses)
plt.show()损失的结果图应或多或少地减少:
为了更具有灵活性和对模型的控制,你可以完全绕过Detecto。你可以根据需要随意调整model.get_internal_model方法返回使用的基础模型。
结论
在本教程中,作者展示了计算机视觉和对象检测不需要具有挑战性。你所需要的是一点时间和耐心来处理标记的的数集。
如果你对进一步探索感兴趣的话,请查看Detecto on GitHub或访问文档以获取更多教程和用例!
原文:
https://hackernoon.com/build-a-custom-trained-object-detection-model-with-5-lines-of-code-y08n33vi
(*本文由AI科技大本营翻译,转载请微信联系1092722531)
【end】
◆
精彩推荐
◆
技术战“疫”,贾扬清、李飞飞要给程序员直播讲AI技术!
2月18日、2月20日晚7点,阿里云CIO学院攻“疫”技术课程正式开启。您将获得与达摩院数据库首席科学家 、阿里巴巴集团副总裁、ACM 杰出科学家李飞飞,Caffe之父、ONNX创始人、阿里巴巴集团副总裁贾扬清,阿里巴巴集团副总裁、阿里 CIO 学院院长胡臣杰等顶级技术专家直播互动的机会。
推荐阅读
福利直达!CSDN技术公开课评选进行中
“一百万行Python代码对任何人都足够了”
从技术风口到行业应用,开启区块链与产业深度融合之路
大神如何一招完美解决Hadoop集群无法正常关闭的问题!| 博文精选
疫情之下,哪些行业正在逆势爆发?
疫情肆虐之下,阿里巴巴的攻与防!
你点的每个“在看”,我都认真当成了AI
相关文章:

SQL操作全集
SQL操作全集 下列语句部分是Mssql语句,不可以在access中使用。 SQL分类: DDL—数据定义语言(CREATE,ALTER,DROP,DECLARE) DML—数据操纵语言(SELECT,DELETE,UPDATE,INSERT) DCL—数据…
css3媒体查询实现网站响应式布局
响应式建筑设计、响应式家具设计、响应式办公设计,这些词可能是已有的专业名词,也可能是我自己想出来的一些名词。因为在生活中,我们常常会见到很多让人惊叹的设计,为什么同一套东西经过不同的方式变化之后会给人不同的使用感受和…
流行于机器学习竞赛的Boosting,这篇文章讲的非常全了
作者 | AISHWARYA SINGH译者 | 武明利,责编 | Carol出品 | AI科技大本营(ID:rgznai100)你能说出至少两种机器学习中的 Boosting 吗?Boosting 已经存在了很多年,然而直到最近它们才成为机器学习社区的主流。那么&#x…
并行计算——OpenMP加速矩阵相乘
OpenMP是一套基于共享内存方式的多线程并发编程库。第一次接触它大概在半年前,也就是研究cuda编程的那段时间。OpenMP产生的线程运行于CPU上,这和cuda不同。由于GPU的cuda核心非常多,可以进行大量的并行计算,所以我们更多的谈论的…
JavaScript继承详解(四)
文章截图 - 更好的排版 在本章中,我们将分析Douglas Crockford关于JavaScript继承的一个实现 - Classical Inheritance in JavaScript。 Crockford是JavaScript开发社区最知名的权威,是JSON、JSLint、JSMin和ADSafe之父,是《JavaScript: The …
C语言:在屏幕上输出信息
#include<stdio.h>int main(){printf ("This is a C program.\n");printf("welcome to bit\n");return 0;}结果:This is a C program.welcome to bitPress any key to continue转载于:https://blog.51cto.com/yaoyaolx/1715542
Colly源码解析——框架
Colly是一个使用golang实现的数据抓取框架,我们可以使用它快速搭建类似网络爬虫这样的应用。本文我们将剖析其源码,以探析其中奥秘。(转载请指明出于breaksoftware的csdn博客) Collector是Colly的核心结构体,其中包含了…
未经任何测试的源代码开放
未经任何测试的源代码开放 http://files.cnblogs.com/TextEditor/TextBoxEx.rar 这个代码只是一个Demo. 请将一个Vb.net的代码放在C盘下面,并且改名为Test.txt,然后使用菜单的Open来打开文件。 有任何问题,请在这里留言。 C#的上色还没有完成…

助力企业抗疫,360金融推出免费AI语音机器人
复工潮来临之际,为帮助各大企业进行高效的内部防疫宣传、员工行程信息收集以及快速生成公司内部防疫排班表,360金融针对复工企业的需求痛点推出了AI语音机器人,以助力企业更高效的防疫、抗疫。 针对复工企业的需求痛点,360金融人…

实现strncat
函数原型char *strncat(char *front,char *back,size_t count)参数说明back为源字符串,front为目的字符串,count为指定的back中的前count个字符。 所在库名#include <string.h>函数功能把back所指字符串的前count个字符添加到front结尾处&a…
Colly源码解析——结合例子分析底层实现
通过《Colly源码解析——框架》分析,我们可以知道Colly执行的主要流程。本文将结合http://go-colly.org上的例子分析一些高级设置的底层实现。(转载请指明出于breaksoftware的csdn博客) 递归深度 以下例子截取于Basic c : colly.NewCollecto…

无限路由 DI-624+A 详细介绍
无线路由器硬件安装设置图解1、确认宽带线路正常:无线宽带路由器可以让您将家中的计算机共享高速宽带网络连结至互联网;但在此之前,您必须先具备一部基于以太网络的Cable/DSL Modem(使用RJ-45 接头),并确定您的宽带网络在只有连接…
教你如何编写第一个爬虫
2019年不管是编程语言排行榜还是在互联网行业,Python一直备受争议,到底是Java热门还是Python热门也是一直让人争吵的话题。随着信息时代的迭代更新,人工智能的兴起,Python编程语言也随之被人们广泛学习,Python数据分析…
【BZOJ】3542: DZY Loves March
题意 \(m * m\)的网格,有\(n\)个点。\(t\)个询问:操作一:第\(x\)个点向四个方向移动了\(d\)个单位。操作二:询问同行同列其他点到这个点的曼哈顿距离和。强制在线。(\(n \le 10^5,m \le 10^{18}\)ÿ…
Gin源码解析和例子——路由
Gin是一个基于golang的net包实现的网络框架。从github上,我们可以看到它相对于其他框架而言,具有优越的性能。本系列将从应用的角度来解析其源码。(转载请指明出于breaksoftware的csdn博客) 本文我们将分析其路由的原理。先看个例…
一文讲透推荐系统提供web服务的2种方式
作者丨gongyouliu编辑丨zandy来源 | 大数据与人工智能(ID: ai-big-data)推荐系统是一种信息过滤技术,通过从用户行为中挖掘用户兴趣偏好,为用户提供个性化的信息,减少用户的找寻时间,降低用户的决策成本&am…
jQuery遍历json数组怎么整。。。
{"options":"[{\"text\":\"王家湾\",\"value\":\"9\"},{\"text\":\"李家湾\",\"value\":\"10\"},{\"text\":\"邵家湾\",\"value\":\"13\…
述说C#中的值类型和引用类型的千丝万缕
关于值类型和引用类型方面的博客和文章可以说是汗牛充栋了,今天无意中又复读了一下这方面的知识,感觉还是有许多新感悟的,就此时间分享一下: CLR支持两种类型:值类型和引用类型,看起来FCL的大多数类型是引用…

Gin源码解析和例子——中间件(middleware)
在《Gin源码解析和例子——路由》一文中,我们已经初识中间件。本文将继续探讨这个技术。(转载请指明出于breaksoftware的csdn博客) Gin的中间件,本质是一个匿名回调函数。这和绑定到一个路径下的处理函数本质是一样的。 再以Engin…
DNS简单配置
DNS的原理就不说了,这里只是做个简单的配置,也是方便自己记忆,在这里还要十分感谢redking老大的教程!要安装的bind* 、caching-nameserver 包1、/var/named/chroot/etc/named.conf这个文件需要自己创建options { listen-on…
关系抽取论文整理,核方法、远程监督的重点都在这里
来源 | CSDN 博客作者 | Matt_sh,编辑 | Carol来源 | CSDN云计算(ID:CSDNcloud)本文是个人阅读文章的笔记整理,没有涉及到深度学习在关系抽取中的应用。笔记中一部分来自个人解读,一部分来自原文࿰…
freemarker内建函数介绍
Sequence的内置函数1.sequence?first 返回sequence的第一个值。2.sequence?last 返回sequence的最后一个值。3.sequence?reverse 将sequence的现有顺序反转,即倒序排序4.sequence?size 返回sequence的大小5.sequence?sort 将sequence中的对象转化为字符串后顺序…
PowerBuilder 11.x 的重要进步和不足
PowerBuilder 11(以下简称PB)出来有一段时间了,但很多用户对PB11的到底有哪些进步还不是很清楚,由于对PB11缺乏了解和信心,目前用PB11做出像样应用的用户不多,这确实非常遗憾,这里我讲一下我对P…
超赞的PyTorch资源大列表,GitHub标星9k+,中文版也上线了
点击阅读原文,快速报名!作者 | 红色石头来源 | AI有道(ID: redstonewill)自 2017 年 1 月 PyTorch 推出以来,其热度持续上升。PyTorch 能在短时间内被众多研究人员和工程师接受并推崇是因为其有着诸多优点,…
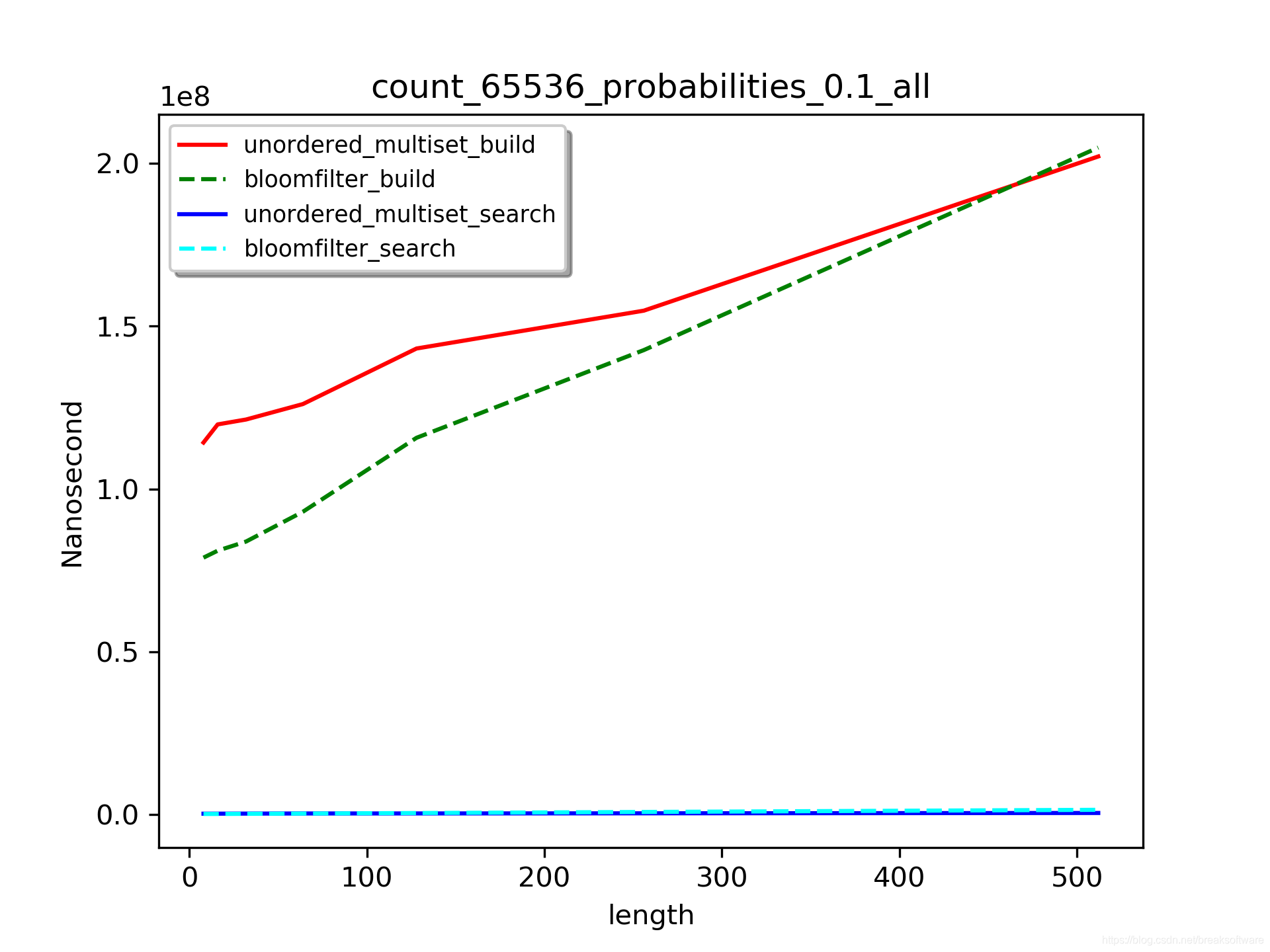
C++拾取——Linux下实测布隆过滤器(Bloom filter)和unordered_multiset查询效率
布隆过滤器是一种判定元素是否存在于集合中的方法。其基本原理是使用哈希方法将数据映射到一个很长的向量上。在维基百科上,它被称为“空间效率和查询时间都远远超过一般的算法”的方法。由于它只保存散列的数据,所以对于很长的数据有着良好的压缩特性&a…
递归思想解决输出目录下的全部文件
刚刚了解了下递归思想 递归就是在方法内调用本方法 下面说一个实际的应用 输出目录下的全部文件,当目录中还有目录时,则进入目录输出里面的文件 import java.io.*; class ShowFile{public static void showfile(File files){if(files.isDirectory()){Fi…

实战之网马解密之shellcode篇
今天上卡卡社区发现里面发了个网马解密的链接,呵呵 顺便试试看能解出来不.呵呵. 相信各位已经对网马有点了解了吧.一般网马都是加密了的.关于什么是网马以及怎么防止网马也不是本文的重点.本文是实战shellcode网马解密.以后的博文会放出常见的网马及其解密.以及常见的解密工具的…
机器学习中的线性回归,你理解多少?
作者丨algorithmia编译 | 武明利,责编丨Carol来源 | 大数据与人工智能(ID: ai-big-data)机器学习中的线性回归是一种来源于经典统计学的有监督学习技术。然而,随着机器学习和深度学习的迅速兴起,因为线性(多…

Golang反射机制的实现分析——reflect.Type类型名称
现在越来越多的java、php或者python程序员转向了Golang。其中一个比较重要的原因是,它和C/C一样,可以编译成机器码运行,这保证了执行的效率。在上述解释型语言中,它们都支持了“反射”机制,让程序员可以很方便的构建一…

设计模式----组合模式UML和实现代码
2019独角兽企业重金招聘Python工程师标准>>> 一、什么是组合模式? 组合模式(Composite)定义:将对象组合成树形结构以表示‘部分---整体’的层次结构。组合模式使得用户对单个对象和组合对象的使用具有一致性. 类型:结构型模式 顺口…