Colly源码解析——框架
Colly是一个使用golang实现的数据抓取框架,我们可以使用它快速搭建类似网络爬虫这样的应用。本文我们将剖析其源码,以探析其中奥秘。(转载请指明出于breaksoftware的csdn博客)
Collector是Colly的核心结构体,其中包含了用户对框架行为的定义。一般情况下,我们可以使用NewCollector方法构建一个它的指针
// NewCollector creates a new Collector instance with default configuration
func NewCollector(options ...func(*Collector)) *Collector {c := &Collector{}c.Init()for _, f := range options {f(c)}c.parseSettingsFromEnv()return c
}第4行调用了Init方法初始化了Collector的一些成员。然后遍历并调用不定长参数,这些参数都是函数类型——func(*Collector)。我们看个例子
c := colly.NewCollector(// Visit only domains: coursera.org, www.coursera.orgcolly.AllowedDomains("coursera.org", "www.coursera.org"),// Cache responses to prevent multiple download of pages// even if the collector is restartedcolly.CacheDir("./coursera_cache"),)
AllowedDomains和CacheDir都返回一个匿名函数,其逻辑就是将Collector对象中对应的成员设置为指定的值
// AllowedDomains sets the domain whitelist used by the Collector.
func AllowedDomains(domains ...string) func(*Collector) {return func(c *Collector) {c.AllowedDomains = domains}
}Collector中绝大部分成员均有对应的方法,而且它们的名称(函数名和成员名)也一致。但是其中只有3个方法——ParseHTTPErrorResponse、AllowURLRevisit和IgnoreRobotsTxt比较特殊,因为它们没有参数。如果被调用,则对应的Collector成员会被设置为true
// AllowURLRevisit instructs the Collector to allow multiple downloads of the same URL
func AllowURLRevisit() func(*Collector) {return func(c *Collector) {c.AllowURLRevisit = true}
}再回到NewCollector函数,其最后一个逻辑是调用parseSettingsFromEnv方法。从名称我们可以看出它是用于解析环境变量的。将它放在最后是可以理解的,因为后面执行的逻辑可以覆盖前面的逻辑。这样我们可以让环境变量对应的设置生效。
func (c *Collector) parseSettingsFromEnv() {for _, e := range os.Environ() {if !strings.HasPrefix(e, "COLLY_") {continue}pair := strings.SplitN(e[6:], "=", 2)if f, ok := envMap[pair[0]]; ok {f(c, pair[1])} else {log.Println("Unknown environment variable:", pair[0])}}
}它从os.Environ()中获取系统环境变量,然后遍历它们。对于以COLLY_开头的变量,找到其在envMap中的对应方法,并调用之以覆盖之前设置的Collector成员变量值。envMap是一个<string,func>的映射,它是包内全局的。
var envMap = map[string]func(*Collector, string){"ALLOWED_DOMAINS": func(c *Collector, val string) {c.AllowedDomains = strings.Split(val, ",")},"CACHE_DIR": func(c *Collector, val string) {c.CacheDir = val},
……初始化完Collector,我们就可以让其发送请求。目前Colly公开了5个方法,其中3个是和Post相关的:Post、PostRaw和PostMultipart。一个Get请求方法:Visit。以及一个用户可以高度定制的方法:Request。这些方法底层都调用了scrape方法。比如Visit的实现是
func (c *Collector) Visit(URL string) error {return c.scrape(URL, "GET", 1, nil, nil, nil, true)
}scrape
scrape方法是需要我们展开分析的。因为它是Colly库中两个最重要的方法之一。
// scrape method
func (c *Collector) scrape(u, method string, depth int, requestData io.Reader, ctx *Context, hdr http.Header, checkRevisit bool) error {if err := c.requestCheck(u, method, depth, checkRevisit); err != nil {return err}首先requestCheck方法检测一些和递归深度以及URL相关的信息
func (c *Collector) requestCheck(u, method string, depth int, checkRevisit bool) error {if u == "" {return ErrMissingURL}if c.MaxDepth > 0 && c.MaxDepth < depth {return ErrMaxDepth}Collector的MaxDepth默认设置为0,即不用比较深度。如果它被设置值,则递归深度不可以超过它。
然后检测URL是否在被禁止的URL过滤器中。如果在,则返回错误。
if len(c.DisallowedURLFilters) > 0 {if isMatchingFilter(c.DisallowedURLFilters, []byte(u)) {return ErrForbiddenURL}}之后检测URL是否在准入的URL过滤器中。如果不在,则返回错误
if len(c.URLFilters) > 0 {if !isMatchingFilter(c.URLFilters, []byte(u)) {return ErrNoURLFiltersMatch}}最后针对GET请求,检查其是否被请求过。
if checkRevisit && !c.AllowURLRevisit && method == "GET" {h := fnv.New64a()h.Write([]byte(u))uHash := h.Sum64()visited, err := c.store.IsVisited(uHash)if err != nil {return err}if visited {return ErrAlreadyVisited}return c.store.Visited(uHash)}return nil
}通过这些检测后,scrape会对URL组成进行分析补齐
// scrape methodparsedURL, err := url.Parse(u)if err != nil {return err}if parsedURL.Scheme == "" {parsedURL.Scheme = "http"}然后针对host进行精确匹配(在requestCheck中,是对URL使用正则进行匹配)。先检测host是否在被禁止的列表中,然后检测其是否在准入的列表中。
// scrape methodif !c.isDomainAllowed(parsedURL.Host) {return ErrForbiddenDomain}func (c *Collector) isDomainAllowed(domain string) bool {for _, d2 := range c.DisallowedDomains {if d2 == domain {return false}}if c.AllowedDomains == nil || len(c.AllowedDomains) == 0 {return true}for _, d2 := range c.AllowedDomains {if d2 == domain {return true}}return false
}通过上面检测,还需要检查是否需要遵从Robots协议
// scrape methodif !c.IgnoreRobotsTxt {if err = c.checkRobots(parsedURL); err != nil {return err}}所有检测通过后,就需要填充请求了
// scrape methodif hdr == nil {hdr = http.Header{"User-Agent": []string{c.UserAgent}}}rc, ok := requestData.(io.ReadCloser)if !ok && requestData != nil {rc = ioutil.NopCloser(requestData)}req := &http.Request{Method: method,URL: parsedURL,Proto: "HTTP/1.1",ProtoMajor: 1,ProtoMinor: 1,Header: hdr,Body: rc,Host: parsedURL.Host,}setRequestBody(req, requestData)第5~8行,使用类型断言等方法,将请求的数据(requestData)转换成io.ReadCloser接口数据。setRequestBody方法则是根据数据(requestData)的原始类型,设置Request结构中的GetBody方法
func setRequestBody(req *http.Request, body io.Reader) {if body != nil {switch v := body.(type) {case *bytes.Buffer:req.ContentLength = int64(v.Len())buf := v.Bytes()req.GetBody = func() (io.ReadCloser, error) {r := bytes.NewReader(buf)return ioutil.NopCloser(r), nil}case *bytes.Reader:req.ContentLength = int64(v.Len())snapshot := *vreq.GetBody = func() (io.ReadCloser, error) {r := snapshotreturn ioutil.NopCloser(&r), nil}case *strings.Reader:req.ContentLength = int64(v.Len())snapshot := *vreq.GetBody = func() (io.ReadCloser, error) {r := snapshotreturn ioutil.NopCloser(&r), nil}}if req.GetBody != nil && req.ContentLength == 0 {req.Body = http.NoBodyreq.GetBody = func() (io.ReadCloser, error) { return http.NoBody, nil }}}
}这种抽象方式,使得不同类型的requestData都可以通过统一的GetBody方法获取内容。目前Colly中发送数据有3种复合结构,分别是:map[string]string、requestData []byte和map[string][]byte。对于普通的Post传送map[string]string数据,Colly会使用createFormReader方法将其转换成Reader结构指针
func createFormReader(data map[string]string) io.Reader {form := url.Values{}for k, v := range data {form.Add(k, v)}return strings.NewReader(form.Encode())
}如果是一个二进制切片,则使用bytes.NewReader直接将其转换为Reader结构指针
如果是map[string][]byte,则是Post数据的Multipart结构,使用createMultipartReader方法将其转换成Buffer结构指针。
func createMultipartReader(boundary string, data map[string][]byte) io.Reader {dashBoundary := "--" + boundarybody := []byte{}buffer := bytes.NewBuffer(body)buffer.WriteString("Content-type: multipart/form-data; boundary=" + boundary + "\n\n")for contentType, content := range data {buffer.WriteString(dashBoundary + "\n")buffer.WriteString("Content-Disposition: form-data; name=" + contentType + "\n")buffer.WriteString(fmt.Sprintf("Content-Length: %d \n\n", len(content)))buffer.Write(content)buffer.WriteString("\n")}buffer.WriteString(dashBoundary + "--\n\n")return buffer
}回到scrape方法中,数据准备结束,开始正式获取数据
// scrape methodu = parsedURL.String()c.wg.Add(1)if c.Async {go c.fetch(u, method, depth, requestData, ctx, hdr, req)return nil}return c.fetch(u, method, depth, requestData, ctx, hdr, req)
}通过第4行我们可以看到,可以通过Async参数决定是否异步的获取数据。
fetch
在解析fetch方法前,我们要先介绍Collector的几个回调函数
htmlCallbacks []*htmlCallbackContainerxmlCallbacks []*xmlCallbackContainerrequestCallbacks []RequestCallbackresponseCallbacks []ResponseCallbackerrorCallbacks []ErrorCallbackscrapedCallbacks []ScrapedCallback以requestCallbacks为例,Colly提供了OnRequest方法用于注册回调。由于这些回调函数通过切片保存,所以可以多次调用注册方法。(即不是覆盖之前的注册回调)
// OnRequest registers a function. Function will be executed on every
// request made by the Collector
func (c *Collector) OnRequest(f RequestCallback) {c.lock.Lock()if c.requestCallbacks == nil {c.requestCallbacks = make([]RequestCallback, 0, 4)}c.requestCallbacks = append(c.requestCallbacks, f)c.lock.Unlock()
}用户则可以使用下面方法进行注册
// Before making a request print "Visiting ..."c.OnRequest(func(r *colly.Request) {fmt.Println("Visiting", r.URL.String())})这些回调会被在handleOnXXXX类型的函数中被调用。调用的顺序和注册的顺序一致。
func (c *Collector) handleOnResponse(r *Response) {if c.debugger != nil {c.debugger.Event(createEvent("response", r.Request.ID, c.ID, map[string]string{"url": r.Request.URL.String(),"status": http.StatusText(r.StatusCode),}))}for _, f := range c.responseCallbacks {f(r)}
}每次调用fetch方法都会构建一个全新Request结构。
// fetch method
func (c *Collector) fetch(u, method string, depth int, requestData io.Reader, ctx *Context, hdr http.Header, req *http.Request) error {defer c.wg.Done()if ctx == nil {ctx = NewContext()}request := &Request{URL: req.URL,Headers: &req.Header,Ctx: ctx,Depth: depth,Method: method,Body: requestData,collector: c,ID: atomic.AddUint32(&c.requestCount, 1),}这儿注意一下3~5行ctx(上下文)的构建逻辑。如果传入的ctx为nil,则构建一个新的,否则使用老的。这就意味着Request结构体(以及之后出现的Response结构体)中的ctx可以是每次调用fetch时全新产生的,也可以是各个Request公用的。我们回溯下ctx的调用栈,发现只有func (c *Collector) Request(……)方法使用的不是nil
func (c *Collector) Request(method, URL string, requestData io.Reader, ctx *Context, hdr http.Header) error {return c.scrape(URL, method, 1, requestData, ctx, hdr, true)
}这也就意味着,调用Visit、Post、PostRaw和PostMultipart方法在每次调用fetch时都会产生一个新的上下文。
由于Context存在被多个goroutine共享访问的可能性,所以其定义了读写锁进行保护
type Context struct {contextMap map[string]interface{}lock *sync.RWMutex
}再回到fetch方法。数据填充完毕后,就提供了一次给用户干预之后流程的机会
// fetch methodc.handleOnRequest(request)if request.abort {return nil}
之前我们讲解过,handleOnRequest调用的是用户通过OnRequest注册个所有回调函数。如果用户在该回调中调用了下面方法,则之后的流程都不走了。
// Abort cancels the HTTP request when called in an OnRequest callback
func (r *Request) Abort() {r.abort = true
}如果用户没用终止执行,则开始发送请求
// fetch methodif method == "POST" && req.Header.Get("Content-Type") == "" {req.Header.Add("Content-Type", "application/x-www-form-urlencoded")}if req.Header.Get("Accept") == "" {req.Header.Set("Accept", "*/*")}origURL := req.URLresponse, err := c.backend.Cache(req, c.MaxBodySize, c.CacheDir)对于这次请求,不管是否出错都会触发用户定义的Error回调
// fetch methodif err := c.handleOnError(response, err, request, ctx); err != nil {return err}在handleOnError函数中,回调函数会接收到err原因,所以用户自定义的错误处理函数需要通过该值来做区分。
for _, f := range c.errorCallbacks {f(response, err)}return err正常请求后,fetch会使用ctx和修复后的request填充到response中
// fetch methodif req.URL != origURL {request.URL = req.URLrequest.Headers = &req.Header}if proxyURL, ok := req.Context().Value(ProxyURLKey).(string); ok {request.ProxyURL = proxyURL}atomic.AddUint32(&c.responseCount, 1)response.Ctx = ctxresponse.Request = requesterr = response.fixCharset(c.DetectCharset, request.ResponseCharacterEncoding)if err != nil {return err}最后在一系列调用用户回调中结束fetch
// fetch methodc.handleOnResponse(response)err = c.handleOnHTML(response)if err != nil {c.handleOnError(response, err, request, ctx)}err = c.handleOnXML(response)if err != nil {c.handleOnError(response, err, request, ctx)}c.handleOnScraped(response)return err
}相关文章:

未经任何测试的源代码开放
未经任何测试的源代码开放 http://files.cnblogs.com/TextEditor/TextBoxEx.rar 这个代码只是一个Demo. 请将一个Vb.net的代码放在C盘下面,并且改名为Test.txt,然后使用菜单的Open来打开文件。 有任何问题,请在这里留言。 C#的上色还没有完成…

助力企业抗疫,360金融推出免费AI语音机器人
复工潮来临之际,为帮助各大企业进行高效的内部防疫宣传、员工行程信息收集以及快速生成公司内部防疫排班表,360金融针对复工企业的需求痛点推出了AI语音机器人,以助力企业更高效的防疫、抗疫。 针对复工企业的需求痛点,360金融人…

实现strncat
函数原型char *strncat(char *front,char *back,size_t count)参数说明back为源字符串,front为目的字符串,count为指定的back中的前count个字符。 所在库名#include <string.h>函数功能把back所指字符串的前count个字符添加到front结尾处&a…
Colly源码解析——结合例子分析底层实现
通过《Colly源码解析——框架》分析,我们可以知道Colly执行的主要流程。本文将结合http://go-colly.org上的例子分析一些高级设置的底层实现。(转载请指明出于breaksoftware的csdn博客) 递归深度 以下例子截取于Basic c : colly.NewCollecto…

无限路由 DI-624+A 详细介绍
无线路由器硬件安装设置图解1、确认宽带线路正常:无线宽带路由器可以让您将家中的计算机共享高速宽带网络连结至互联网;但在此之前,您必须先具备一部基于以太网络的Cable/DSL Modem(使用RJ-45 接头),并确定您的宽带网络在只有连接…
教你如何编写第一个爬虫
2019年不管是编程语言排行榜还是在互联网行业,Python一直备受争议,到底是Java热门还是Python热门也是一直让人争吵的话题。随着信息时代的迭代更新,人工智能的兴起,Python编程语言也随之被人们广泛学习,Python数据分析…
【BZOJ】3542: DZY Loves March
题意 \(m * m\)的网格,有\(n\)个点。\(t\)个询问:操作一:第\(x\)个点向四个方向移动了\(d\)个单位。操作二:询问同行同列其他点到这个点的曼哈顿距离和。强制在线。(\(n \le 10^5,m \le 10^{18}\)ÿ…
Gin源码解析和例子——路由
Gin是一个基于golang的net包实现的网络框架。从github上,我们可以看到它相对于其他框架而言,具有优越的性能。本系列将从应用的角度来解析其源码。(转载请指明出于breaksoftware的csdn博客) 本文我们将分析其路由的原理。先看个例…
一文讲透推荐系统提供web服务的2种方式
作者丨gongyouliu编辑丨zandy来源 | 大数据与人工智能(ID: ai-big-data)推荐系统是一种信息过滤技术,通过从用户行为中挖掘用户兴趣偏好,为用户提供个性化的信息,减少用户的找寻时间,降低用户的决策成本&am…
jQuery遍历json数组怎么整。。。
{"options":"[{\"text\":\"王家湾\",\"value\":\"9\"},{\"text\":\"李家湾\",\"value\":\"10\"},{\"text\":\"邵家湾\",\"value\":\"13\…
述说C#中的值类型和引用类型的千丝万缕
关于值类型和引用类型方面的博客和文章可以说是汗牛充栋了,今天无意中又复读了一下这方面的知识,感觉还是有许多新感悟的,就此时间分享一下: CLR支持两种类型:值类型和引用类型,看起来FCL的大多数类型是引用…

Gin源码解析和例子——中间件(middleware)
在《Gin源码解析和例子——路由》一文中,我们已经初识中间件。本文将继续探讨这个技术。(转载请指明出于breaksoftware的csdn博客) Gin的中间件,本质是一个匿名回调函数。这和绑定到一个路径下的处理函数本质是一样的。 再以Engin…
DNS简单配置
DNS的原理就不说了,这里只是做个简单的配置,也是方便自己记忆,在这里还要十分感谢redking老大的教程!要安装的bind* 、caching-nameserver 包1、/var/named/chroot/etc/named.conf这个文件需要自己创建options { listen-on…
关系抽取论文整理,核方法、远程监督的重点都在这里
来源 | CSDN 博客作者 | Matt_sh,编辑 | Carol来源 | CSDN云计算(ID:CSDNcloud)本文是个人阅读文章的笔记整理,没有涉及到深度学习在关系抽取中的应用。笔记中一部分来自个人解读,一部分来自原文࿰…
freemarker内建函数介绍
Sequence的内置函数1.sequence?first 返回sequence的第一个值。2.sequence?last 返回sequence的最后一个值。3.sequence?reverse 将sequence的现有顺序反转,即倒序排序4.sequence?size 返回sequence的大小5.sequence?sort 将sequence中的对象转化为字符串后顺序…
PowerBuilder 11.x 的重要进步和不足
PowerBuilder 11(以下简称PB)出来有一段时间了,但很多用户对PB11的到底有哪些进步还不是很清楚,由于对PB11缺乏了解和信心,目前用PB11做出像样应用的用户不多,这确实非常遗憾,这里我讲一下我对P…
超赞的PyTorch资源大列表,GitHub标星9k+,中文版也上线了
点击阅读原文,快速报名!作者 | 红色石头来源 | AI有道(ID: redstonewill)自 2017 年 1 月 PyTorch 推出以来,其热度持续上升。PyTorch 能在短时间内被众多研究人员和工程师接受并推崇是因为其有着诸多优点,…
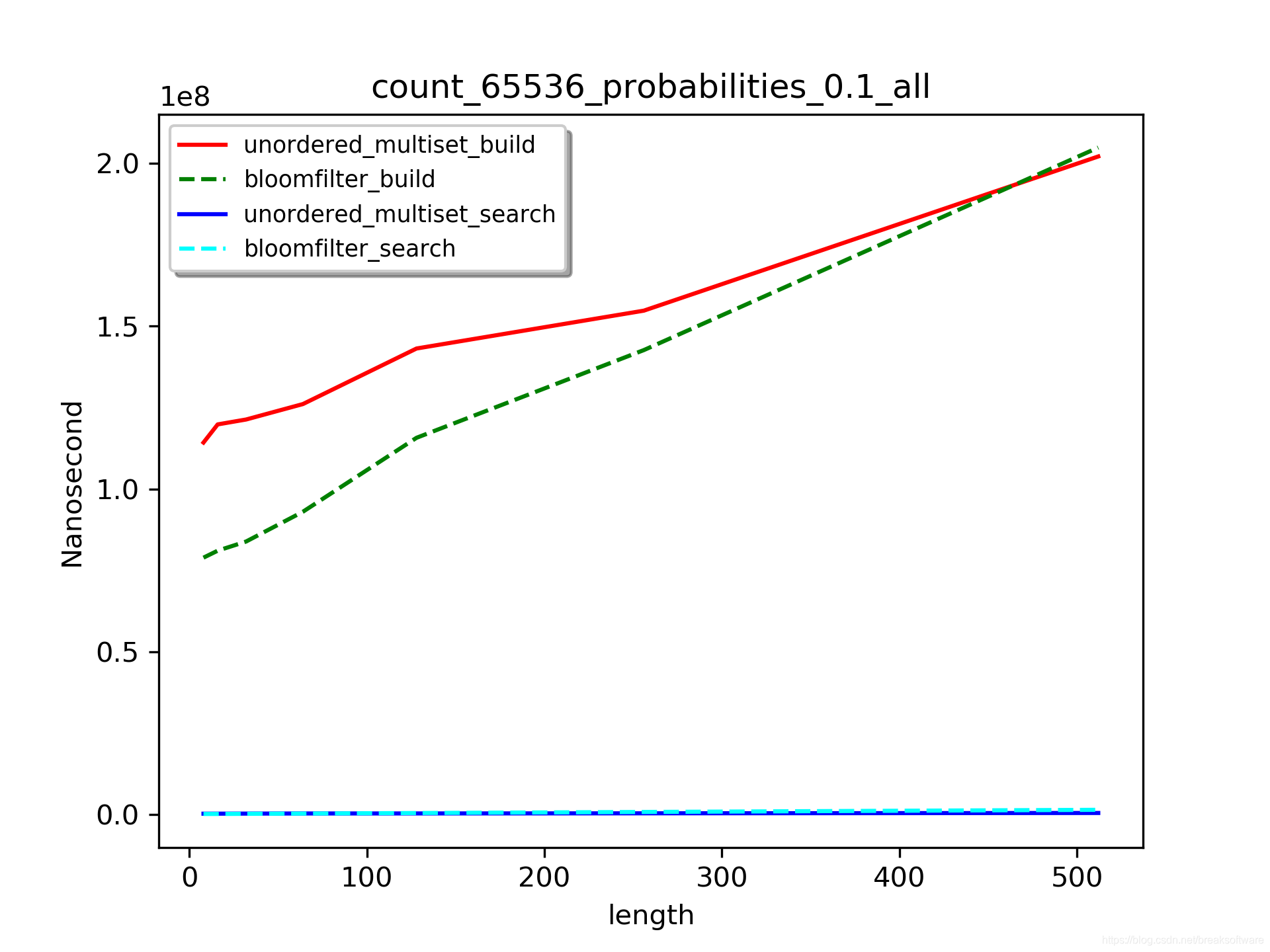
C++拾取——Linux下实测布隆过滤器(Bloom filter)和unordered_multiset查询效率
布隆过滤器是一种判定元素是否存在于集合中的方法。其基本原理是使用哈希方法将数据映射到一个很长的向量上。在维基百科上,它被称为“空间效率和查询时间都远远超过一般的算法”的方法。由于它只保存散列的数据,所以对于很长的数据有着良好的压缩特性&a…
递归思想解决输出目录下的全部文件
刚刚了解了下递归思想 递归就是在方法内调用本方法 下面说一个实际的应用 输出目录下的全部文件,当目录中还有目录时,则进入目录输出里面的文件 import java.io.*; class ShowFile{public static void showfile(File files){if(files.isDirectory()){Fi…

实战之网马解密之shellcode篇
今天上卡卡社区发现里面发了个网马解密的链接,呵呵 顺便试试看能解出来不.呵呵. 相信各位已经对网马有点了解了吧.一般网马都是加密了的.关于什么是网马以及怎么防止网马也不是本文的重点.本文是实战shellcode网马解密.以后的博文会放出常见的网马及其解密.以及常见的解密工具的…
机器学习中的线性回归,你理解多少?
作者丨algorithmia编译 | 武明利,责编丨Carol来源 | 大数据与人工智能(ID: ai-big-data)机器学习中的线性回归是一种来源于经典统计学的有监督学习技术。然而,随着机器学习和深度学习的迅速兴起,因为线性(多…

Golang反射机制的实现分析——reflect.Type类型名称
现在越来越多的java、php或者python程序员转向了Golang。其中一个比较重要的原因是,它和C/C一样,可以编译成机器码运行,这保证了执行的效率。在上述解释型语言中,它们都支持了“反射”机制,让程序员可以很方便的构建一…

设计模式----组合模式UML和实现代码
2019独角兽企业重金招聘Python工程师标准>>> 一、什么是组合模式? 组合模式(Composite)定义:将对象组合成树形结构以表示‘部分---整体’的层次结构。组合模式使得用户对单个对象和组合对象的使用具有一致性. 类型:结构型模式 顺口…

Golang反射机制的实现分析——reflect.Type方法查找和调用
在《Golang反射机制的实现分析——reflect.Type类型名称》一文中,我们分析了Golang获取类型基本信息的流程。本文将基于上述知识和经验,分析方法的查找和调用。(转载请指明出于breaksoftware的csdn博客) 方法 package mainimpor…
太狠!33岁年薪50万:“复工第一天,谢谢裁掉我!” 网友:有底气!
最近脉脉一则帖子炸锅了:某HR发帖称公司以按时下班为由裁员。这种情况下很多人都慌了,大家纷纷把“副业救国”奉为神律。可是你有没有认真的想过,为什么现在大家都需要副业:意外裁员后,房贷能够按时还上不至于“回收”…
SEO内部链接优化的技巧
内部链接是搜索引擎优化中的重要因素之一。思亿欧做的SEO调查发现,国内大部分网站都没有怎么做内部链接优化。这可能是网站管理员并不知晓SEO或者是对内部链接优化不够重视。 内部链接的设计不能是单纯的为了SEO的目的而作内部链接,同时要注意规划一个良…
Ubuntu 15.10安装ns2.35+nam
2019独角兽企业重金招聘Python工程师标准>>> Step1: 更新系统sudo apt-get update #更新源列表sudo apt-get upgrade #更新已经安装的包sudo apt-get dist-upgrade #更新软件,升级系统Step2:安装ns2需要的几个包sudo apt-get install build-essentialsu…
bug诞生记——不定长参数隐藏的类型问题
这个bug的诞生源于项目中使用了一个开源C库。由于对该C库API不熟悉,一个不起眼的错误调用,导致一系列诡异的问题。最终经过调试,我们发现发生了内存覆盖问题。为了直达问题根节,我将问题代码简化如下(转载请指明出于br…
yahoo註冊.com 域名1.99$/年
yahoo註冊.com 域名1.99$/年趕快去註冊吧http://order.sbs.yahoo.com/ds/reviewplanoption?.pYD1&mdom&.srcsbs&.promoBESTDEAL&dzzhen an.com支持paypal付款一個yahoo帳戶只能註冊一個如果覺得續費比較貴,可在註冊兩個月後轉出到godaddy.转载于:h…
Excel弱爆了!这个工具30分钟完成了我一天的工作量,零基础、文科生也能学!...
在大数据浪潮当中,数据分析是这个时代的不二“掘金技能”。我们每一个人,每天无时无刻都在生产数据,一分钟内,微博上新发的数据量超过10万,b站的视频播放量超过600万......这些庞大的数字,意味着什么&#…