教你如何编写第一个爬虫
2019年不管是编程语言排行榜还是在互联网行业,Python一直备受争议,到底是Java热门还是Python热门也是一直让人争吵的话题。
随着信息时代的迭代更新,人工智能的兴起,Python编程语言也随之被人们广泛学习,Python数据分析、Python web全栈、Python自动化运维等等都很受欢迎,其中还包括了Python爬虫。但是很对人觉得Python爬虫是违法的行为,也在怀疑自己到底要不要学爬虫,之前有一篇文章特别火,就是只因写了一段爬虫,公司 200 多人被抓!》,文章里写了因为一名技术人员因爬取数据被抓,那么爬虫真的违法吗?今天我们来探索一下。
目前互联网世界针对爬虫这一块已经通过自身的协议建立起一定的道德规范(Robots协议),但法律部分还在建立和完善中。那么Robots协议是什么呢?
1
Robots协议
Robots协议(爬虫协议)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。该协议是国际互联网界通行的道德规范,虽然没有写入法律,但是每一个爬虫都应该遵守这项协议。
下面以淘宝网的robots.txt为例进行介绍。
User-agent: Baiduspider #百度爬虫引擎
Allow: /article #允许访问/article.htm、/article/12345.com
Allow: /oshtml
Allow: /ershou
Disallow: /product/ #禁止访问/product/12345.com
Disallow: / #禁止访问除Allow规定页面外的其他所有页面User-Agent: Googlebot #谷歌爬虫引擎
Allow: /article
Allow: /oshtml
Allow: /product #允许访问/product.htm、/product/12345.com
Allow: /spu
Allow: /dianpu
Allow: /wenzhang
Allow: /oversea
Disallow: /
在上面的robots文件中,淘宝网对用户代理为百度爬虫引擎进行了规定。
以Allow项的值开头的URL是允许robot访问的。例如,Allow:/article允许百度爬虫引擎访问/article.htm、/article/12345.com等。
以Disallow项为开头的链接是不允许百度爬虫引擎访问的。例如,Disallow:/product/不允许百度爬虫引擎访问/product/12345.com等。
最后一行,Disallow:/禁止百度爬虫访问除了Allow规定页面外的其他所有页面。
因此,当你在百度搜索“淘宝”的时候,搜索结果下方的小字会出现:“由于该网站的robots.txt文件存在限制指令(限制搜索引擎抓取),系统无法提供该页面的内容描述”,如图所示。百度作为一个搜索引擎,良好地遵守了淘宝网的robot.txt协议,所以你是不能从百度上搜索到淘宝内部的产品信息的。
淘宝的Robots协议对谷歌爬虫的待遇则不一样,和百度爬虫不同的是,它允许谷歌爬虫爬取产品的页面Allow:/product。因此,当你在谷歌搜索“淘宝iphone7”的时候,可以搜索到淘宝中的产品,如图所示。
当你爬取网站数据时,无论是否仅供个人使用,都应该遵守Robots协议。
加入VIP会员,上百本电子书、上千门课程等你免费学
2
网络爬虫的约束
除了上述Robots协议之外,我们使用网络爬虫的时候还要对自己进行约束:过于快速或者频密的网络爬虫都会对服务器产生巨大的压力,网站可能封锁你的IP,甚至采取进一步的法律行动。因此,你需要约束自己的网络爬虫行为,将请求的速度限定在一个合理的范围之内。
爬取网站的时候需要限制自己的爬虫,遵守Robots协议和约束网络爬虫程序的速度;在使用数据的时候必须遵守网站的知识产权。
所以只要你合理利用就不会违法,爬虫还是可以学的哦,毕竟爬虫对数据分析真的非常有用,那么爬虫该怎么学呢?今天来教大家编写一个简单的爬虫!
3
编写第一个简单的爬虫
第一步:获取页面
#!/usr/bin/python
# coding: utf-8import requests #引入包requests
link = "http://www.santostang.com/" #定义link为目标网页地址
# 定义请求头的浏览器代理,伪装成浏览器
headers = {'User-Agent' : 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}r = requests.get(link, headers= headers) #请求网页
print (r.text) #r.text是获取的网页内容代码
上述代码就能获取博客首页的HTML代码,HTML是用来描述网页的一种语言,也就是说网页呈现的内容背后都是HTML代码。如果你对HTML不熟悉的话,可以先去w3school(http://www.w3school.com.cn/html/index.asp)学习一下,大概花上几个小时就可以了解HTML。
在上述代码中,首先import requests引入包requests,之后获取网页。
(1)首先定义link为目标网页地址。
(2)之后用headers来定义请求头的浏览器代理,进行伪装
(3)r是requests的Response回复对象,我们从中可以获取想要的信息。r.text是获取的网页内容代码。
运行上述代码得到的结果如图所示。
第二步:提取需要的数据
#!/usr/bin/python
# coding: utf-8import requests
from bs4 import BeautifulSoup #从bs4这个库中导入BeautifulSouplink = "http://www.santostang.com/"
headers = {'User-Agent' : 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r = requests.get(link, headers= headers)soup = BeautifulSoup(r.text, "html.parser") #使用BeautifulSoup解析#找到第一篇文章标题,定位到class是"post-title"的h1元素,提取a,提取a里面的字符串,strip()去除左右空格
title = soup.find("h1", class_="post-title").a.text.strip()
print (title)
在获取整个页面的HTML代码后,我们需要从整个网页中提取第一篇文章的标题。
这里用到BeautifulSoup这个库对页面进行解析,BeautifulSoup将会在第4章进行详细讲解。首先需要导入这个库,然后把HTML代码转化为soup对象,接下来用soup.find(“h1”,class_=“post-title”).a.text.strip()得到第一篇文章的标题,并且打印出来
soup.find(“h1”,class_=“post-title”).a.text.strip()的意思是,找到第一篇文章标题,定位到class是"post-title"的h1元素,提取a元素,提取a元素里面的字符串,strip()去除左右空格。
对初学者来说,使用BeautifulSoup从网页中提取需要的数据更加简单易用。
那么,我们怎么从那么长的代码中准确找到标题的位置呢?
这里就要隆重介绍Chrome浏览器的“检查(审查元素)”功能了。下面介绍找到需要元素的步骤。
步骤01
使用Chrome浏览器打开博客首页www.santostang.com。右击网页页面,在弹出的快捷菜单中单击“检查”命令,如图所示。
步骤02
出现如下图所示的审查元素页面。单击左上角的鼠标键按钮,然后在页面上单击想要的数据,下面的Elements会出现相应的code所在的地方,就定位到想要的元素了。
步骤03
在代码中找到标蓝色的地方,为echarts学习笔记(2)–同一页面多图表。我们可以用soup.find("h1",class_="post-title").a.text.strip()提取该博文的标题。
第三步:存储数据
import requests
from bs4 import BeautifulSoup #从bs4这个库中导入BeautifulSouplink = "http://www.santostang.com/"
headers = {'User-Agent' : 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r = requests.get(link, headers= headers)soup = BeautifulSoup(r.text, "html.parser") #使用BeautifulSoup解析
title = soup.find("h1", class_="post-title").a.text.strip()
print (title)# 打开一个空白的txt,然后使用f.write写入刚刚的字符串title
with open('title_test.txt', "a+") as f:f.write(title)
存储到本地的txt文件非常简单,在第二步的基础上加上2行代码就可以把这个字符串保存在text中,并存储到本地。txt文件地址应该和你的Python文件放在同一个文件夹。
返回文件夹,打开title.txt文件,其中的内容如图所示。
以上就是编写第一个爬虫的方法,你们学会了吗?暂时没学会也没关系,你可以慢慢学哦~以上内容自《Python网络爬虫从入门到实践(第2版)》【文末有福利】往下拉!
扫码加入VIP会员免费读
内容简介:
使用Python编写网络爬虫程序获取互联网上的大数据是当前的热门专题。本书内容包括三部分:基础部分、进阶部分和项目实践。基础部分(第1~7章)主要介绍爬虫的三个步骤——获取网页、解析网页和存储数据,并通过诸多示例的讲解,让读者能够从基础内容开始系统性地学习爬虫技术,并在实践中提升Python爬虫水平。进阶部分(第8~13章)包括多线程的并发和并行爬虫、分布式爬虫、更换IP等,帮助读者进一步提升爬虫水平。项目实践部分(第14~17章)使用本书介绍的爬虫技术对几个真实的网站进行抓取,让读者能在读完本书后根据自己的需求写出爬虫程序。
推荐理由:
基础知识+完整的知识模块+4个实践案例的教学,让读者快速掌握爬虫程序的编写,快速成长为爬虫高手
更多Python好书推荐
以上书籍均已加入到VIP会员卡权益,只要拥有这张VIP会员卡即可免费阅读上百本电子书,还有上千门优质课程免费看哦,快扫码查看!
福利
参与方式:只要在本文留言参与话题“技术书籍上,你会选择购买纸质书籍还是电子书籍,为什么呢?”即可有机会获得价值129元的可擦笔记本一个,只有2个名额哦~
获奖公布时间:2月21日14:00
如果可以的话也可扫码入群一起交流学习哦~电子书的任何问题都可以在群里沟通!
点击“阅读原文”,上百本电子书等你免费读!
你点的每一个在看,我认真当成了喜欢
相关文章:

【BZOJ】3542: DZY Loves March
题意 \(m * m\)的网格,有\(n\)个点。\(t\)个询问:操作一:第\(x\)个点向四个方向移动了\(d\)个单位。操作二:询问同行同列其他点到这个点的曼哈顿距离和。强制在线。(\(n \le 10^5,m \le 10^{18}\)ÿ…
Gin源码解析和例子——路由
Gin是一个基于golang的net包实现的网络框架。从github上,我们可以看到它相对于其他框架而言,具有优越的性能。本系列将从应用的角度来解析其源码。(转载请指明出于breaksoftware的csdn博客) 本文我们将分析其路由的原理。先看个例…
一文讲透推荐系统提供web服务的2种方式
作者丨gongyouliu编辑丨zandy来源 | 大数据与人工智能(ID: ai-big-data)推荐系统是一种信息过滤技术,通过从用户行为中挖掘用户兴趣偏好,为用户提供个性化的信息,减少用户的找寻时间,降低用户的决策成本&am…
jQuery遍历json数组怎么整。。。
{"options":"[{\"text\":\"王家湾\",\"value\":\"9\"},{\"text\":\"李家湾\",\"value\":\"10\"},{\"text\":\"邵家湾\",\"value\":\"13\…
述说C#中的值类型和引用类型的千丝万缕
关于值类型和引用类型方面的博客和文章可以说是汗牛充栋了,今天无意中又复读了一下这方面的知识,感觉还是有许多新感悟的,就此时间分享一下: CLR支持两种类型:值类型和引用类型,看起来FCL的大多数类型是引用…

Gin源码解析和例子——中间件(middleware)
在《Gin源码解析和例子——路由》一文中,我们已经初识中间件。本文将继续探讨这个技术。(转载请指明出于breaksoftware的csdn博客) Gin的中间件,本质是一个匿名回调函数。这和绑定到一个路径下的处理函数本质是一样的。 再以Engin…
DNS简单配置
DNS的原理就不说了,这里只是做个简单的配置,也是方便自己记忆,在这里还要十分感谢redking老大的教程!要安装的bind* 、caching-nameserver 包1、/var/named/chroot/etc/named.conf这个文件需要自己创建options { listen-on…
关系抽取论文整理,核方法、远程监督的重点都在这里
来源 | CSDN 博客作者 | Matt_sh,编辑 | Carol来源 | CSDN云计算(ID:CSDNcloud)本文是个人阅读文章的笔记整理,没有涉及到深度学习在关系抽取中的应用。笔记中一部分来自个人解读,一部分来自原文࿰…
freemarker内建函数介绍
Sequence的内置函数1.sequence?first 返回sequence的第一个值。2.sequence?last 返回sequence的最后一个值。3.sequence?reverse 将sequence的现有顺序反转,即倒序排序4.sequence?size 返回sequence的大小5.sequence?sort 将sequence中的对象转化为字符串后顺序…
PowerBuilder 11.x 的重要进步和不足
PowerBuilder 11(以下简称PB)出来有一段时间了,但很多用户对PB11的到底有哪些进步还不是很清楚,由于对PB11缺乏了解和信心,目前用PB11做出像样应用的用户不多,这确实非常遗憾,这里我讲一下我对P…
超赞的PyTorch资源大列表,GitHub标星9k+,中文版也上线了
点击阅读原文,快速报名!作者 | 红色石头来源 | AI有道(ID: redstonewill)自 2017 年 1 月 PyTorch 推出以来,其热度持续上升。PyTorch 能在短时间内被众多研究人员和工程师接受并推崇是因为其有着诸多优点,…
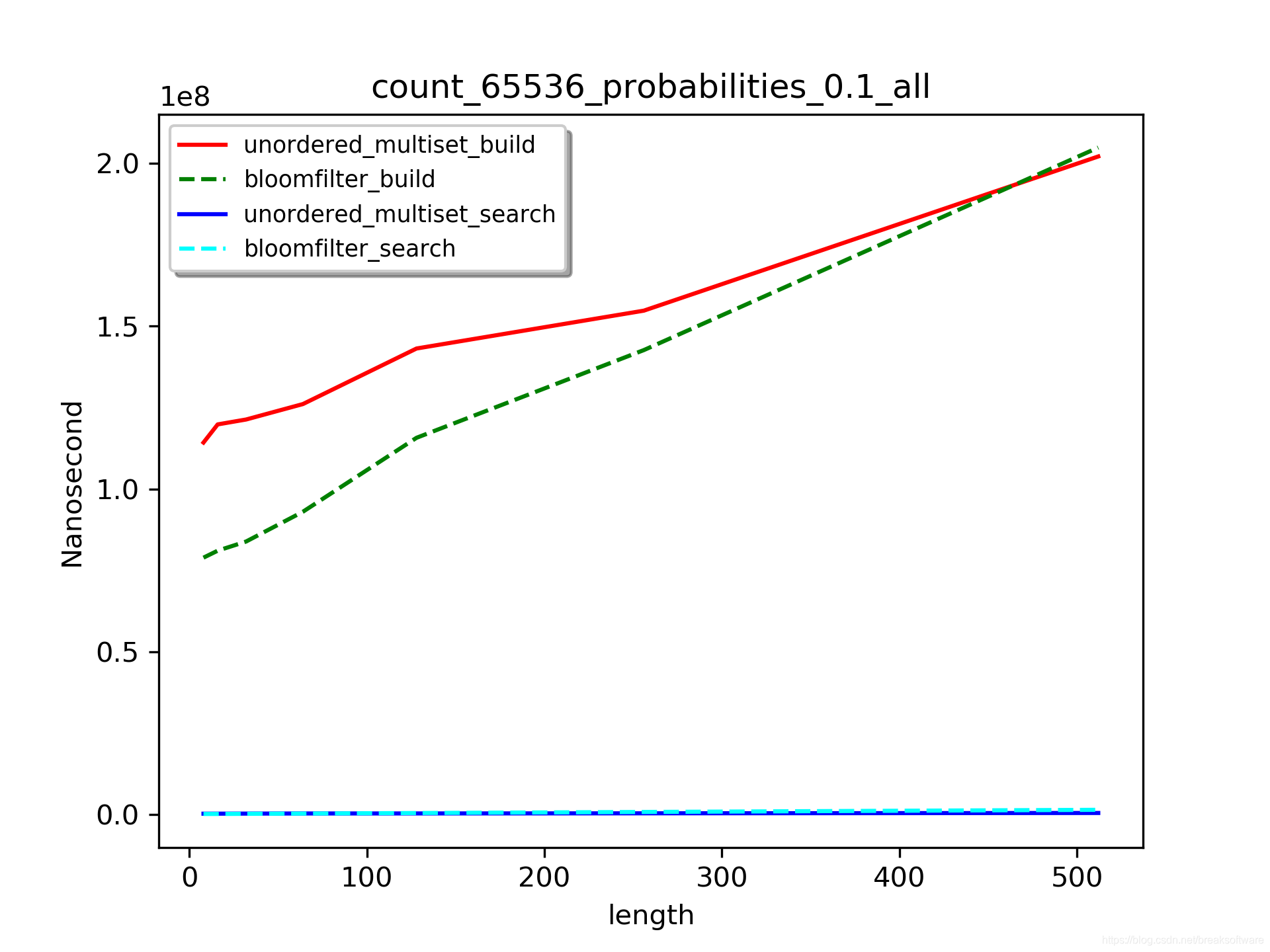
C++拾取——Linux下实测布隆过滤器(Bloom filter)和unordered_multiset查询效率
布隆过滤器是一种判定元素是否存在于集合中的方法。其基本原理是使用哈希方法将数据映射到一个很长的向量上。在维基百科上,它被称为“空间效率和查询时间都远远超过一般的算法”的方法。由于它只保存散列的数据,所以对于很长的数据有着良好的压缩特性&a…
递归思想解决输出目录下的全部文件
刚刚了解了下递归思想 递归就是在方法内调用本方法 下面说一个实际的应用 输出目录下的全部文件,当目录中还有目录时,则进入目录输出里面的文件 import java.io.*; class ShowFile{public static void showfile(File files){if(files.isDirectory()){Fi…

实战之网马解密之shellcode篇
今天上卡卡社区发现里面发了个网马解密的链接,呵呵 顺便试试看能解出来不.呵呵. 相信各位已经对网马有点了解了吧.一般网马都是加密了的.关于什么是网马以及怎么防止网马也不是本文的重点.本文是实战shellcode网马解密.以后的博文会放出常见的网马及其解密.以及常见的解密工具的…
机器学习中的线性回归,你理解多少?
作者丨algorithmia编译 | 武明利,责编丨Carol来源 | 大数据与人工智能(ID: ai-big-data)机器学习中的线性回归是一种来源于经典统计学的有监督学习技术。然而,随着机器学习和深度学习的迅速兴起,因为线性(多…

Golang反射机制的实现分析——reflect.Type类型名称
现在越来越多的java、php或者python程序员转向了Golang。其中一个比较重要的原因是,它和C/C一样,可以编译成机器码运行,这保证了执行的效率。在上述解释型语言中,它们都支持了“反射”机制,让程序员可以很方便的构建一…

设计模式----组合模式UML和实现代码
2019独角兽企业重金招聘Python工程师标准>>> 一、什么是组合模式? 组合模式(Composite)定义:将对象组合成树形结构以表示‘部分---整体’的层次结构。组合模式使得用户对单个对象和组合对象的使用具有一致性. 类型:结构型模式 顺口…

Golang反射机制的实现分析——reflect.Type方法查找和调用
在《Golang反射机制的实现分析——reflect.Type类型名称》一文中,我们分析了Golang获取类型基本信息的流程。本文将基于上述知识和经验,分析方法的查找和调用。(转载请指明出于breaksoftware的csdn博客) 方法 package mainimpor…
太狠!33岁年薪50万:“复工第一天,谢谢裁掉我!” 网友:有底气!
最近脉脉一则帖子炸锅了:某HR发帖称公司以按时下班为由裁员。这种情况下很多人都慌了,大家纷纷把“副业救国”奉为神律。可是你有没有认真的想过,为什么现在大家都需要副业:意外裁员后,房贷能够按时还上不至于“回收”…
SEO内部链接优化的技巧
内部链接是搜索引擎优化中的重要因素之一。思亿欧做的SEO调查发现,国内大部分网站都没有怎么做内部链接优化。这可能是网站管理员并不知晓SEO或者是对内部链接优化不够重视。 内部链接的设计不能是单纯的为了SEO的目的而作内部链接,同时要注意规划一个良…
Ubuntu 15.10安装ns2.35+nam
2019独角兽企业重金招聘Python工程师标准>>> Step1: 更新系统sudo apt-get update #更新源列表sudo apt-get upgrade #更新已经安装的包sudo apt-get dist-upgrade #更新软件,升级系统Step2:安装ns2需要的几个包sudo apt-get install build-essentialsu…
bug诞生记——不定长参数隐藏的类型问题
这个bug的诞生源于项目中使用了一个开源C库。由于对该C库API不熟悉,一个不起眼的错误调用,导致一系列诡异的问题。最终经过调试,我们发现发生了内存覆盖问题。为了直达问题根节,我将问题代码简化如下(转载请指明出于br…
yahoo註冊.com 域名1.99$/年
yahoo註冊.com 域名1.99$/年趕快去註冊吧http://order.sbs.yahoo.com/ds/reviewplanoption?.pYD1&mdom&.srcsbs&.promoBESTDEAL&dzzhen an.com支持paypal付款一個yahoo帳戶只能註冊一個如果覺得續費比較貴,可在註冊兩個月後轉出到godaddy.转载于:h…
Excel弱爆了!这个工具30分钟完成了我一天的工作量,零基础、文科生也能学!...
在大数据浪潮当中,数据分析是这个时代的不二“掘金技能”。我们每一个人,每天无时无刻都在生产数据,一分钟内,微博上新发的数据量超过10万,b站的视频播放量超过600万......这些庞大的数字,意味着什么&#…
Myeclipse快捷键的使用
存盘 Ctrls(肯定知道) 注释代码 Ctrl/ 取消注释 Ctrl\(Eclipse3已经都合并到Ctrl/了) 代码辅助 Alt/ 快速修复 Ctrl1 代码格式化 CtrlShiftf 整理导入 CtrlShifto 切换窗口 Ctrlf6 <可改为ctrltab方便> ctrlshiftM 导入未引用的包 ctrlw 关闭单个窗口 F3 跳转到类、变量的…
PL/SQL三种集合类型的比较
PL/SQL三种集合类型的比较<?xml:namespace prefix o ns "urn:schemas-microsoft-com:office:office" />集合是指在一个程序变量中包含多个值。PL/SQL提供的集合类型如下:Associative Array:TYPE t IS TABLE OF something INDEX BY PLS_INTEGER;N…
夺得WSDM Cup 2020大赛金牌的这份参赛方案,速来get!
近日,在美国休斯敦闭幕的第13届网络搜索与数据挖掘国际会议(WSDM 2020)上,华为云语音语义创新Lab带领的联合团队,摘得WSDM Cup 2020大赛“论文引用意图识别任务”金牌(Gold Medal)。WSDM被誉为全…
bug诞生记——信号(signal)处理导致死锁
这个bug源于项目中一个诡异的现象:代码层面没有明显的锁的问题,但是执行时发生了死锁一样的表现。我把业务逻辑简化为:父进程一直维持一个子进程。(转载请指明出于breaksoftware的csdn博客) 首先我们定义一个结构体Pro…
Linux下SVN服务器支持Apache的http和svnserve独立服务器
2019独角兽企业重金招聘Python工程师标准>>> 说明 服务器操作系统:CentOS 6.6 关闭防火墙,SElinux 实现 1、在服务器上安装配置SVN服务; 2、SVN服务支持svnserve独立服务模式访问; 3、SVN服务支持Apache的http模式访问…

AWS攻略——使用CodeCommit托管代码
除了我们熟悉的github,各大云厂商也有自己的代码托管服务。本文讲解如何在Amazon的CodeCommit中托管代码。(转载请指明出于breaksoftware的csdn博客) 根账户登录 AWS有两种账户登录界面。 IAM账户登录界面 根账户登录界面我们先使用根…