关系抽取论文整理,核方法、远程监督的重点都在这里
来源 | CSDN 博客
作者 | Matt_sh,编辑 | Carol
来源 | CSDN云计算(ID:CSDNcloud)
本文是个人阅读文章的笔记整理,没有涉及到深度学习在关系抽取中的应用。
笔记中一部分来自个人解读,一部分来自原文,一部分来自网上摘录。部分笔记还不够完善,后续补上的话重点应该是这几年的前沿论文。
核方法
阅读资源:SVM中的核方法
https://zhuanlan.zhihu.com/p/27445103
1、Dependency Tree Kernels for Relation Extraction
思路:将句子转化为句法依赖树,构建增强依存树(Augmented Dependency Trees),得到一个句子和两个实体的各种特征,定义相应的核函数,计算不同树之间的相似度,最后用SVM进行分类。这种方法的缺点就是很依赖增强依存树的结果。
理由在于依赖树包含了句子中不同成分语法的依赖关系,作者认为具有相似关系的实例也会在其对应的依赖树上有相似的结构。核函数的目的就是找到依赖树之间的相似性。因此,再找到之后,只需将核函数并入SVM中,即可。
实验部分:
使用ACE数据集【只用到其中5个关系,没有用24个】
在SVM中使用不同的核,
K 0 = sparse kernel
K 1 = contiguous kernel
K 2 = bag-of-words kernel
K 3 = K 0 + K 2
K 4 = K 1 + K2
先用二分类的SVM进行关系检测:实体间是否存在关系,再用Libsvm进行关系分类。
进行二分类检测的理由:
Detecting relations is a difficult task for a kernel method because the set of all non-relation instances is extremely heterogeneous, and is therefore difficult to characterize with a similarity metric.
2、A Shortest Path Dependency Kernel for Relation Extraction
在dependency tree的基础上,任务句子中有很多不必要的信息,有人提出最小树的方法,这边作者寻找最短路径的方法来解决。
具体做法:将一个句子构建成一个图,其中单词作为图的节点,依存关系作为图的边。这样我们可以得到两个实体的最短路径,对这个最短路径上的节点的单词、词性、实体类别等特征进行组合就得到了最终特征,最后使用核方法和SVM进行关系分类。
评价:创新点在于求依存关系的最短路径,这跟我们人类推理关系是类似的。缺点就是仍然依赖与所使用的NLP工具的质量,这会影响到模型的准确率。
3、Exploring Various Knowledge in Relation Extraction
本文研究了基于SVM的基于特征的关系抽取中的词汇、句法和语义知识的融合。研究表明,chunking方法对于关系抽取非常有效,并且在句法方面有助于大部分性能的提高,而来自完全句法分析的附加信息对于模型表现增强由局限性。
因此,作者认为(在实验中证实),用于关系提取的完整解析树中的大多数有用信息都是浅层的,可以通过分块来捕获。
实验部分:使用ACE数据集,对其中6个大类(24个子类)建模,因为考虑到m1-m2,m2-m1属于两类,(除了6个对称的关系【“RelativeLocation”, “Associate”, “Other-Relative”, “OtherProfessional”, “Sibling”, and “Spouse”.】),还有一个无的类别,所以总共43的类别,建立一个多分类的模型。
关键结论:
Dependency tree 与 parse tree 对模型的提升有限,原因在于:ACE预料中关系间隔较短,70%以上实体之间的间隔只有一个词。依赖树和解析树特征只能在剩余的远距离关系中发挥作用。然而,尽管我们系统中使用的Collins解析器代表了完全解析的最新技术,但完全解析总是容易出现长距离错误。
某些关系检测与分类会较为困难,比如AT型及其子类的关系。
加入了chunking的结果后,基于特征的方法明显优于核方法。这表明基于特征的方法可以有效地结合来自不同来源(如WordNet和gazetters)的不同特征,从而对关系抽取产生影响。
在误差分布的分析中,结果表明,73%(627/864)的错误源于关系检测,27%(237/864)的错误源于关系表征,其中17.8%(154/864)的错误源于关系类型间的误分类,9.6%(83/864)的错误源于同一关系类型内关系子类的误分类。这说明关系检测是关系抽取的关键。
阅读:chunking(组块分析)
https://blog.csdn.net/Sirow/article/details/89306934
远程监督
阅读:
远程监督关系抽取论文总结https://zhuanlan.zhihu.com/p/39885744
多示例多标签学习http://palm.seu.edu.cn/zhangml/files/cccf09-mil&mll.pdf
深度学习中的MIMLhttps://blog.csdn.net/weixin_41108334/article/details/83048552
1、Distant supervision for relation extraction without labeled data
核心思想:如果一个句子中两个实体存在某种关系,那么其他句子中的这两个实体也很可能在表达这种关系。
在文章中,作者发现基于连续组块的句法特征有较好的表现,有助于远程监督的信息提取。作者使用的是连接特征的办法(词汇句法特征连接起来,没有独立使用,【得益于大样本】)。
因此,就可以在数据库中使用已有的关系,找到大量的实体对,从而找到对应句子标注相应关系。再提取这些句子的词汇、句法、语义特征进行训练,得到关系抽取的模型。而负样本使用随机实体对进行标注。通过这种策略生成训练样本,减少标注,然后再设计特征,训练关系分类器。
优点:可以使用大的数据集,不会过拟合,且相比于无监督学习,得到的关系是确定的。
问题:第一个是假设过于肯定,有时候两个实体一起出现,但并没有表达知识库定义的关系。也有可能两个实体之间存在多种类型关系,那么就无法判断这一个句子中所说的是哪一种关系;另外这种标注方式依赖于NER的性能。【NLP工具】
未来的工作:更简单的、基于chunker的语法特征能否在不增加完全解析开销的情况下得到足够的信息,提高性能。
2、Multi-instance Multi-label Learning for Relation Extraction
这篇文章主要是解决远程监督论文所提到的第一个问题。实体间不止存在一种关系,比如中国-北京。可能是北京在中国,也可能北京是中国首都,也可能是北京面积比中国小。也就是不同句子,可以提取出同一实体,表达不同关系。所以,作者提出用多示例多标签学习来解决这一问题。
这是文章中给出的多示例多标签学习的简单图示:
文章使用具有隐变量的图模型共同对文本中一对实体的所有实例及其所有标签进行建模,然后使用EM算法求解该模型。
关于EM算法,看这个:EM算法解读
https://www.zhihu.com/question/40797593/answer/275171156
开放关系抽取
1、Relation Extraction with Matrix Factorization and Universal Schemas
关于Schemas的总结
https://www.zhihu.com/question/59624229/answer/167115969
思路:本文提出的是通用schema的方法,选择利用开放关系抽取方法获得的关系以及现有数据库中存在的关系,构成一个二维的矩阵。**行**是实体对(来源于现存的数据库以及抽取的文本语料),而**列**对应到到固定Schema关系和开放域关系的连接。矩阵每个元素的值(训练集是0,1),希望能够对于缺失部分进行预测,(测试集给出的是概率形式),所以可以将**行**理解为**用户**,**列**理解为**物品**,类似于协同过滤的方法来解决这个问题。
模型形式:
这是论文中的截图。可以看到,列的来源一部分是OpenIE得到的关系,一部分来源于现有KG,比如freebase。
核心式子:
总结来说,定义了参数的不同部分,各种参数以及权重矩阵。
但问题是,只有正样本,没有负样本。也就是模型学习的是倾向于将不同情况预测为真。
> **Bayesian Personalized Ranking (BPR)**:uses a variant of this ranking:giving observed true facts higher scores than unobserved (true or false) facts (Rendle et al., 2009).
最初解决办法是同远程监督一般,自行构造负样本,但效果不好(对于不同负样本鲁棒性低,而且学习成本变高),所以使用了BPR方法。
要解决的问题:
> How accurately can we fill a database of Universal Schema, and does reasoning jointly across a universal schema help to improve over more isolated approaches?(我们能多准确地填充一个通用模式的数据库,并且跨通用模式的联合推理是否有助于改进更孤立的方法?)
首先数据处理部分,将纽约时报文章预料提取的命名体与freebase的元组进行连接,再过滤筛选。
>Based on this alignment we filter out all relations for which we find fewer than 10 tuples with mentions in text.(基于这种对齐,我们过滤掉所有在文本中提到的少于10个元组的关系。)
接着,构建矩阵。对每个元组t,对应的关系实例$O_t$由两部分组成。$O_t = O_t^{FB}\cup O_t^{PAT}$。
这样就从数据集建立了矩阵。
评估部分,构建PRC曲线。这里计算precision的方法:对每个关系,取前1000个实体对。将前100个集中起来,手工判断其相关性或者真实性。,由此结果计算召回率与准确度。
所以说,开放性关系抽取只是获取数据集的工具,这篇文章的重点还是这个矩阵以及对应的参数估计方法。
【end】
◆
精彩推荐
◆
明晚7点,直播连麦贾扬清,讲讲人工智能在近几年当中的算法和相应系统的演进过程,并从技术角度阐述产品形态和用户场景。参与公开课还有机会向贾扬清老师提问~提交听课笔记还有可能获得阿里马克杯、天猫精灵智能音箱哦~
点击阅读原文,快速报名!
推荐阅读
福利直达!CSDN技术公开课评选进行中
中文版开源!这或许是最经典的Python编程教材
@开发者,这个 GitHub 项目可以褥羊毛!
早期文献中的关系抽取论文整理,赶紧 Mark 起来!
一文读懂拜占庭将军问题
疫情之下,哪些行业正在逆势爆发?
你点的每个“在看”,我都认真当成了AI
相关文章:

freemarker内建函数介绍
Sequence的内置函数1.sequence?first 返回sequence的第一个值。2.sequence?last 返回sequence的最后一个值。3.sequence?reverse 将sequence的现有顺序反转,即倒序排序4.sequence?size 返回sequence的大小5.sequence?sort 将sequence中的对象转化为字符串后顺序…
PowerBuilder 11.x 的重要进步和不足
PowerBuilder 11(以下简称PB)出来有一段时间了,但很多用户对PB11的到底有哪些进步还不是很清楚,由于对PB11缺乏了解和信心,目前用PB11做出像样应用的用户不多,这确实非常遗憾,这里我讲一下我对P…
超赞的PyTorch资源大列表,GitHub标星9k+,中文版也上线了
点击阅读原文,快速报名!作者 | 红色石头来源 | AI有道(ID: redstonewill)自 2017 年 1 月 PyTorch 推出以来,其热度持续上升。PyTorch 能在短时间内被众多研究人员和工程师接受并推崇是因为其有着诸多优点,…
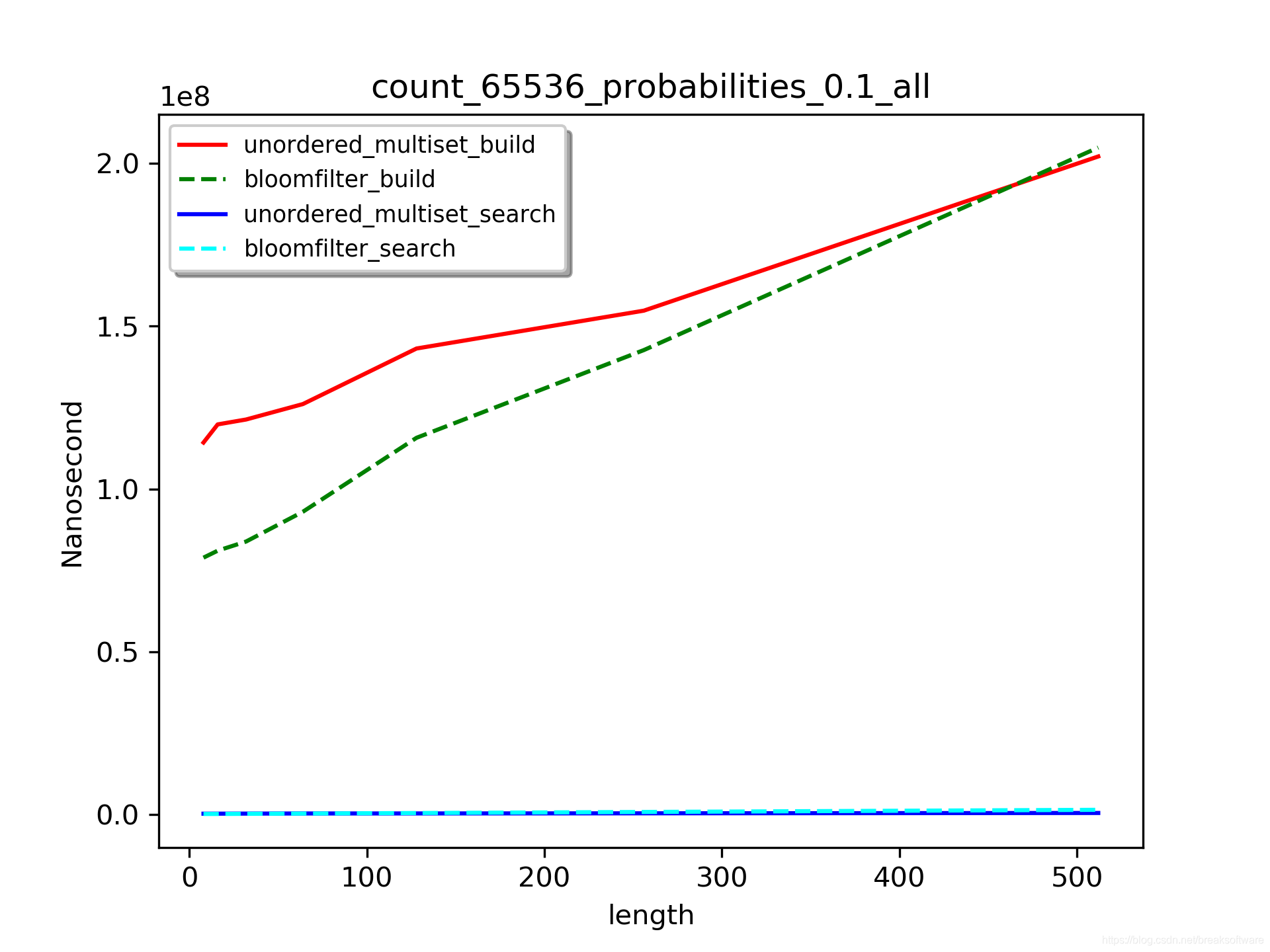
C++拾取——Linux下实测布隆过滤器(Bloom filter)和unordered_multiset查询效率
布隆过滤器是一种判定元素是否存在于集合中的方法。其基本原理是使用哈希方法将数据映射到一个很长的向量上。在维基百科上,它被称为“空间效率和查询时间都远远超过一般的算法”的方法。由于它只保存散列的数据,所以对于很长的数据有着良好的压缩特性&a…
递归思想解决输出目录下的全部文件
刚刚了解了下递归思想 递归就是在方法内调用本方法 下面说一个实际的应用 输出目录下的全部文件,当目录中还有目录时,则进入目录输出里面的文件 import java.io.*; class ShowFile{public static void showfile(File files){if(files.isDirectory()){Fi…

实战之网马解密之shellcode篇
今天上卡卡社区发现里面发了个网马解密的链接,呵呵 顺便试试看能解出来不.呵呵. 相信各位已经对网马有点了解了吧.一般网马都是加密了的.关于什么是网马以及怎么防止网马也不是本文的重点.本文是实战shellcode网马解密.以后的博文会放出常见的网马及其解密.以及常见的解密工具的…
机器学习中的线性回归,你理解多少?
作者丨algorithmia编译 | 武明利,责编丨Carol来源 | 大数据与人工智能(ID: ai-big-data)机器学习中的线性回归是一种来源于经典统计学的有监督学习技术。然而,随着机器学习和深度学习的迅速兴起,因为线性(多…

Golang反射机制的实现分析——reflect.Type类型名称
现在越来越多的java、php或者python程序员转向了Golang。其中一个比较重要的原因是,它和C/C一样,可以编译成机器码运行,这保证了执行的效率。在上述解释型语言中,它们都支持了“反射”机制,让程序员可以很方便的构建一…

设计模式----组合模式UML和实现代码
2019独角兽企业重金招聘Python工程师标准>>> 一、什么是组合模式? 组合模式(Composite)定义:将对象组合成树形结构以表示‘部分---整体’的层次结构。组合模式使得用户对单个对象和组合对象的使用具有一致性. 类型:结构型模式 顺口…

Golang反射机制的实现分析——reflect.Type方法查找和调用
在《Golang反射机制的实现分析——reflect.Type类型名称》一文中,我们分析了Golang获取类型基本信息的流程。本文将基于上述知识和经验,分析方法的查找和调用。(转载请指明出于breaksoftware的csdn博客) 方法 package mainimpor…
太狠!33岁年薪50万:“复工第一天,谢谢裁掉我!” 网友:有底气!
最近脉脉一则帖子炸锅了:某HR发帖称公司以按时下班为由裁员。这种情况下很多人都慌了,大家纷纷把“副业救国”奉为神律。可是你有没有认真的想过,为什么现在大家都需要副业:意外裁员后,房贷能够按时还上不至于“回收”…
SEO内部链接优化的技巧
内部链接是搜索引擎优化中的重要因素之一。思亿欧做的SEO调查发现,国内大部分网站都没有怎么做内部链接优化。这可能是网站管理员并不知晓SEO或者是对内部链接优化不够重视。 内部链接的设计不能是单纯的为了SEO的目的而作内部链接,同时要注意规划一个良…
Ubuntu 15.10安装ns2.35+nam
2019独角兽企业重金招聘Python工程师标准>>> Step1: 更新系统sudo apt-get update #更新源列表sudo apt-get upgrade #更新已经安装的包sudo apt-get dist-upgrade #更新软件,升级系统Step2:安装ns2需要的几个包sudo apt-get install build-essentialsu…
bug诞生记——不定长参数隐藏的类型问题
这个bug的诞生源于项目中使用了一个开源C库。由于对该C库API不熟悉,一个不起眼的错误调用,导致一系列诡异的问题。最终经过调试,我们发现发生了内存覆盖问题。为了直达问题根节,我将问题代码简化如下(转载请指明出于br…
yahoo註冊.com 域名1.99$/年
yahoo註冊.com 域名1.99$/年趕快去註冊吧http://order.sbs.yahoo.com/ds/reviewplanoption?.pYD1&mdom&.srcsbs&.promoBESTDEAL&dzzhen an.com支持paypal付款一個yahoo帳戶只能註冊一個如果覺得續費比較貴,可在註冊兩個月後轉出到godaddy.转载于:h…
Excel弱爆了!这个工具30分钟完成了我一天的工作量,零基础、文科生也能学!...
在大数据浪潮当中,数据分析是这个时代的不二“掘金技能”。我们每一个人,每天无时无刻都在生产数据,一分钟内,微博上新发的数据量超过10万,b站的视频播放量超过600万......这些庞大的数字,意味着什么&#…
Myeclipse快捷键的使用
存盘 Ctrls(肯定知道) 注释代码 Ctrl/ 取消注释 Ctrl\(Eclipse3已经都合并到Ctrl/了) 代码辅助 Alt/ 快速修复 Ctrl1 代码格式化 CtrlShiftf 整理导入 CtrlShifto 切换窗口 Ctrlf6 <可改为ctrltab方便> ctrlshiftM 导入未引用的包 ctrlw 关闭单个窗口 F3 跳转到类、变量的…
PL/SQL三种集合类型的比较
PL/SQL三种集合类型的比较<?xml:namespace prefix o ns "urn:schemas-microsoft-com:office:office" />集合是指在一个程序变量中包含多个值。PL/SQL提供的集合类型如下:Associative Array:TYPE t IS TABLE OF something INDEX BY PLS_INTEGER;N…
夺得WSDM Cup 2020大赛金牌的这份参赛方案,速来get!
近日,在美国休斯敦闭幕的第13届网络搜索与数据挖掘国际会议(WSDM 2020)上,华为云语音语义创新Lab带领的联合团队,摘得WSDM Cup 2020大赛“论文引用意图识别任务”金牌(Gold Medal)。WSDM被誉为全…
bug诞生记——信号(signal)处理导致死锁
这个bug源于项目中一个诡异的现象:代码层面没有明显的锁的问题,但是执行时发生了死锁一样的表现。我把业务逻辑简化为:父进程一直维持一个子进程。(转载请指明出于breaksoftware的csdn博客) 首先我们定义一个结构体Pro…
Linux下SVN服务器支持Apache的http和svnserve独立服务器
2019独角兽企业重金招聘Python工程师标准>>> 说明 服务器操作系统:CentOS 6.6 关闭防火墙,SElinux 实现 1、在服务器上安装配置SVN服务; 2、SVN服务支持svnserve独立服务模式访问; 3、SVN服务支持Apache的http模式访问…

AWS攻略——使用CodeCommit托管代码
除了我们熟悉的github,各大云厂商也有自己的代码托管服务。本文讲解如何在Amazon的CodeCommit中托管代码。(转载请指明出于breaksoftware的csdn博客) 根账户登录 AWS有两种账户登录界面。 IAM账户登录界面 根账户登录界面我们先使用根…
使用alterMIME实现添加message footer功能
1. 安装alterMIME tar zxvf altermime-0.3.8.tar.gz cd altermin3-0.3.8 make make install altermine将被编译安装到/usr/local/bin/2. 使用必备条件:一个运行且配置正常的邮件服务器3. 配置AlterMIME3.1 为altermine创建一个系统帐号,如下&#x…
Facebook最新研究:无需额外训练AI,即可加速NLP任务
作者 | KYLE WIGGERS译者 | Kolen出品 | AI科技大本营(ID:rgznai100)自然语言模型通常要解决两个难题:将句子前缀映射到固定大小的表示形式,并使用这些表示形式来预测文本中的下一个单词。在最近的一篇论文(https://ar…

PgSQL · 特性分析 · full page write 机制
PG默认每个page的大小为8K,PG数据页写入是以page为单位,但是在断电等情况下,操作系统往往不能保证单个page原子地写入磁盘,这样就极有可能导致部分数据块只写到4K(操作系统是一般以4K为单位),这些“部分写”的页面包含…
局域网DVD yum源的制作
今天在网上溜达,看到这篇文章不错,于是就转载过来,感谢原作者的辛苦劳动.源地址:http://blog.chinaunix.net/u3/94782/showart_1953260.html一:两台计算机做实验<?xml:namespace prefix o ns "urn:schemas-microsoft-com:office:office" />1&…
AWS攻略——使用S3托管静态网页
在AWS上有很多部署静态网页的方式,比如使用EC2或者Lightsail。但是不管使用上述哪种方案,都需要预先部署如Nignx或者Apache等Http服务。这对纯前端同学来说可能有点复杂,而AWS提供了更简单的部署方式——只需要提供静态网页文件的“S3网页托管…
2020年涨薪26-30%,能实现吗?18%数据科学家是这么期待的
作者丨Big Cloud编译 | 武明利,责编丨Carol出品 | AI科技大本营(ID:rgznai100)本报告将深入探讨亚太地区各个背景、不同年龄和不同地点的专业人员对2019/2020年的见解。今年贡献最大的地区来自新加坡和澳大利亚。因为这些是我们最大的数据点&…
AWS攻略——使用CodeBuild进行自动化构建和部署静态网页
首先声明下,使用“CodeBuild”部署并不是“正统”的方案,因为AWS提供了“CodeDeploy”。如果不希望引入太多基础设施,可以考虑直接使用CodeBuild进行部署。(转载请指明出于breaksoftware的csdn博客) 创建构建项目 kro…
我们需要什么样的数据架构?
作者 | Stephanie shen编译 | 火火酱,责编丨Carol出品 | AI科技大本营(ID:rgznai100)在大数据和数据科学的新时代,对企业而言,一定要有与业务流程保持一致的中心化数据架构,该架构能随业务增长而扩展&#…