带有 RaspiCam 的 Raspberry Pi 监控和延时摄影摄像机

一、说明
一段时间以来,我一直想构建一个运动激活且具有延时功能的树莓派相机,但从未真正找到我喜欢的案例。我在thingiverse上找到了这个适合树莓派和相机的好案例。它是为特定的鱼眼相机设计的,但从模型来看,我拥有的廉价中国鱼眼手机镜头之一似乎非常适合孔中。
我启动了 tinkercad,用我的卡尺测量了相机外壳内的空间和 RaspiCam 板的厚度,并创建了一个模型来安装官方 RaspiCam。我用两小块灯光师胶带将相机固定在支撑件上,将镜头卡入外壳的孔中,然后将相机滑入外壳。你可以在这里找到我的相机部件
这真的是一个不错的简单项目,任何树莓派和相机外壳都可以使用,您还需要:
- Raspberry Pi 型号 B 或 B+,2 或 3
- Raspberry Pi 摄像头板
- Raspberry Pi 相机电缆
- 按钮 — 我用过这些
- 2 根母跳线
- 手机鱼眼镜头
- SD卡
二、停止按钮
我将几根母跳线焊接到一个小的瞬时开关上,用于停止 pi 以进行监控和延时设置。对于延时摄影软件,我使用的是这个 Adafruit 项目中的代码,其中包括停止按钮的代码。
我已剥离此脚本的延时功能,以便在监控摄像头上使用。因为我希望这两个相机项目在启动时自动启动,所以我选择使用raspbian lite设置两张SD卡,它们会自动启动到监控或延时摄影模式。该按钮连接到 gpio 21 并在 pi 上接地,最后两个引脚位于 USB 端口旁边。
三、运动摄像机软件设置
由于这个项目不需要桌面操作系统,所以我下载了 Raspbian Jessie Lite 映像,并使用 Ubuntu 中的磁盘映像写入器将其安装在 SD 卡上。
启动树莓派后,我使用 raspi-config 扩展文件系统,设置键盘、时间和 wifi 的国际化选项,启用相机,超频 CPU 并启用 SSH。
我做的下一件事是禁用相机 LED,因为我不想让相机指示它已打开。
// Edit the config.txt file sudo nano /boot/config.txt // Add the following line disable_camera_led=1apt 的 motion 标准版本不适用于 RaspiCam 模块,但有一个社区支持的版本,该版本已编译用于 RaspiCam。这里有更多关于维基的信息。
以下是我用于使用最新版本的 Raspbian Jessie Lite 为 RaspiCam 安装自定义运动二进制文件的命令。

// Install the motion prerequisites sudo apt-get install -y libjpeg-dev libavformat56 libavformat-dev libavcodec56 libavcodec-dev libavutil54 libavutil-dev libc6-dev zlib1g-dev libmysqlclient18 libmysqlclient-dev libpq5 libpq-dev // Download and unzip the raspberry pi specific motion binary wget https://www.dropbox.com/s/6ruqgv1h65zufr6/motion-mmal-lowflyerUK-20151114.tar.gz tar -zxvf motion-mmal-lowflyerUK-20151114.tar.gz // Test out the results $ ./motion -c motion-mmalcam-both.conf如果您在运行运动后看到终端中记录的成功消息,请将您的 Web 浏览器指向树莓派端口 8081 的 ip,您应该会看到您的相机流。
四、延时摄影相机软件设置
我从 Adafruit 下载了预构建的 SD 卡映像,我使用 raspi-config 扩展文件系统,设置键盘、时间和 wifi 的国际化选项,超频 CPU 并启用 SSH。
预制卡可以正常工作,启动 pi 并开始拍摄延时图像,按住开关并关闭 pi。我想构建这个项目的pi zero可穿戴版本,但还没有所有的部件。
一旦我有了一堆图像,我就用 FFMPEG 制作了一个视频
ffmpeg -f image2 -i img%06d.jpg time-lapse.mp4这些都是几个不错的树莓派相机项目,不需要很多零件。
相关文章:

Yolov11-detect训练自己的数据集
至此,整个YOLOv11的训练预测阶段完成,与YOLOv8差不多。欢迎各位批评指正。

YOLOv10训练自己的数据集
至此,整个YOLOv10的训练预测阶段完成,与YOLOv8差不多。欢迎各位批评指正。
YOLOv10环境搭建、模型预测和ONNX推理
运行后会在文件yolov10s.pt存放路径下生成一个的yolov10s.onnxONNX模型文件。安装完成之后,我们简单执行下推理命令测试下效果,默认读取。终端,进入base环境,创建新环境。(1)onnx模型转换。

YOLOv7-Pose 姿态估计-环境搭建和推理
终端,进入base环境,创建新环境,我这里创建的是p38t17(python3.8,pytorch1.7)安装pytorch:(网络环境比较差时,耗时会比较长)下载好后打开yolov7-pose源码包。imgpath:需要预测的图片的存放路径。modelpath:模型的存放路径。Yolov7-pose权重下载。打开工程后,进入设置。
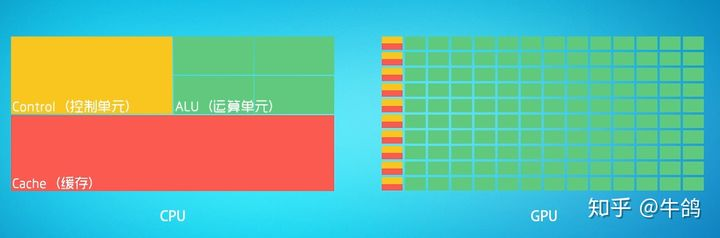
深度学习硬件基础:CPU与GPU
CPU:叫做中央处理器(central processing unit)作为计算机系统的运算和控制核心,是信息处理、程序运行的最终执行单元。[^3]可以形象的理解为有25%的ALU(运算单元)、有25%的Control(控制单元)、50%的Cache(缓存单元)GPU:叫做图形处理器。

YOLOv8-Detect训练CoCo数据集+自己的数据集
至此,整个训练预测阶段完成。此过程同样可以在linux系统上进行,在数据准备过程中需要仔细,保证最后得到的数据准确,最好是用显卡进行训练。有问题评论区见!

基于深度学习的细胞感染性识别与判定
通过引入深度学习技术,我们能够更精准地识别细胞是否受到感染,为医生提供更及时的信息,有助于制定更有效的治疗方案。基于深度学习的方法通过学习大量样本,能够自动提取特征并进行准确的感染性判定,为医学研究提供了更高效和可靠的手段。通过引入先进的深度学习技术,我们能够实现更快速、准确的感染性判定,为医学研究和临床实践提供更为可靠的工具。其准确性和效率将为医学研究带来新的突破,为疾病的早期诊断和治疗提供更可靠的支持。通过大规模的训练,模型能够学到细胞感染的特征,并在未知数据上做出准确的预测。

自定义白平衡调节的步骤 白平衡怎么设置好 白平衡和色温的关系 用什么软件调节白平衡
也就是说,当相机的白平衡数值和色温数值一样时,相机呈现的光源就是纯白光源,拍摄出来的画面就是白色,这就是白平衡的主要作用,通过调整色温和白平衡数值,能改变画面色彩,色温和白平衡数值越接近,画面就越白。白平衡的k值越高,拍摄的画面颜色就越暖/偏黄(它与色温相反,色温是k值越高,画面越冷),k值越低,画面颜色越冷/偏蓝,自定义白平衡能让画面色温校正的很精准,但是操作很复杂。先来说下色温,色温是指光线在不同的能量下,眼睛感受到的颜色变化,简单理解就是光线的颜色,色温计算单位是开尔文(k)。

windows安装conda环境,开发openai应用准备,运行第一个ai程序
作者开发第一个openai应用的环境准备、第一个openai程序调用成功,做个记录,希望帮助新来的你。第一次能成功运行的openai程序,狠开心。
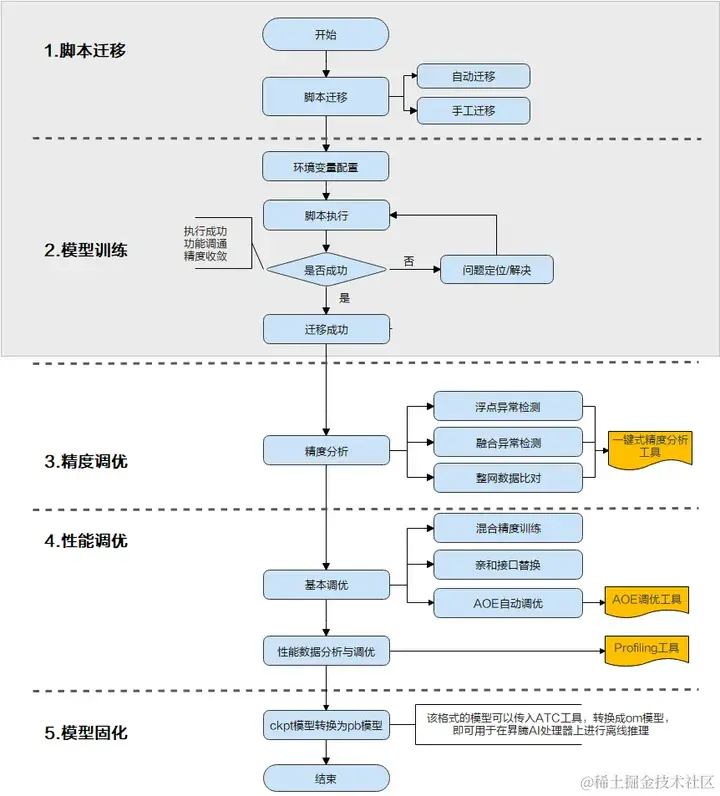
一文详解TensorFlow模型迁移及模型训练实操步骤
当前业界很多训练脚本是基于TensorFlow的Python API进行开发的,默认运行在CPU/GPU/TPU上,为了使这些脚本能够利用昇腾AI处理器的强大算力执行训练,需要对TensorFlow的训练脚本进行迁移。
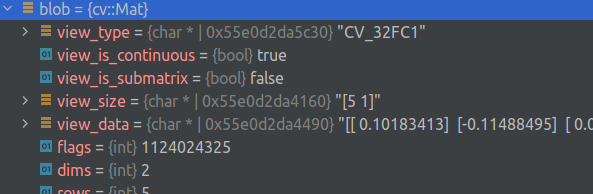
将 OpenCV 与 gdb 驱动的 IDE 结合使用
能力这个漂亮的打印机可以显示元素类型、标志和(可能被截断的)矩阵。众所周知,它可以在 Clion、VS Code 和 gdb 中工作。Clion 示例安装移入 .放在方便的地方,重命名并移动到您的个人文件夹中。将“source”行更改为指向您的路径。如果系统中安装的 python 3 版本与 gdb 中的版本不匹配,请使用完全相同的版本创建一个新的虚拟环境,相应地安装并更改 python3 的路径。用法调试器中以前缀为前缀的字段是为方便起见而添加的伪字段,其余字段保持原样。

改进的yolov5目标检测-yolov5替换骨干网络-yolo剪枝(TensorRT及NCNN部署)
改进的yolov5目标检测-yolov5替换骨干网络-yolo剪枝(TensorRT及NCNN部署)2021.10.30 复现TPH-YOLOv52021.10.31 完成替换backbone为Ghostnet2021.11.02 完成替换backbone为Shufflenetv22021.11.05 完成替换backbone为Mobilenetv3Small2021.11.10 完成EagleEye对YOLOv5系列剪枝支持2021.11.14 完成MQBench对YOLOv5系列量

PyTorch中nn.Module的继承类中方法foward是自动执行的么?
在 PyTorch的 nn.Module中,forward方法并不是自动执行的,但它是在模型进行前向传播时必须调用的一个方法。当你实例化一个继承自torch.nn.Module的自定义类并传入输入数据时,需要通过调用该实例来实现前向传播计算,这实际上会隐式地调用forward方法。
文本挖掘的几种常用的方法
1. 文本预处理:首先对文本数据进行清洗和预处理,如去除停用词(如“的”、“是”等常用词)、标点符号和特殊字符,并进行词干化或词形还原等操作,以减少数据噪声和提取更有意义的特征。3. 文本分类:将文本数据分为不同的类别或标签。文本挖掘是一种通过自动化地发现、提取和分析大量文本数据中的有趣模式、关联和知识的技术。这些示例代码只是简单的演示了各种方法的使用方式,具体的实现还需要根据具体的需求和数据进行适当的调整和优化。8. 文本生成:使用统计模型或深度学习模型生成新的文本,如机器翻译、文本摘要和对话系统等。
智能革命:揭秘AI如何重塑创新与效率的未来
智能革命:揭秘AI如何重塑创新与效率的未来
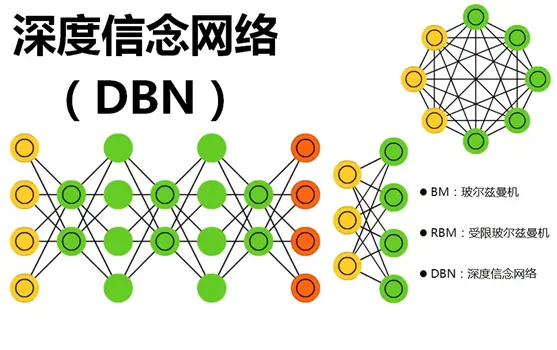
一文搞懂深度信念网络!DBN概念介绍与Pytorch实战
深度信念网络(Deep Belief Networks, DBNs)是一种深度学习模型,代表了一种重要的技术创新,具有几个关键特点和突出能力。首先,DBNs是由多层受限玻尔兹曼机(Restricted Boltzmann Machines, RBMs)堆叠而成的生成模型。这种多层结构使得DBNs能够捕获数据中的高层次抽象特征,对于复杂的数据结构具有强大的表征能力。其次,DBNs采用无监督预训练的方式逐层训练模型。
人工智能在现代科技中的应用和未来发展趋势
未来,深度学习将进一步发展,能够应用于更多的领域,如自动驾驶、智能制造和医疗辅助等。图像识别和计算机视觉:人工智能在图像识别和计算机视觉领域取得了巨大突破,能够自动识别和分类图像中的物体和场景。未来,随着人工智能技术的发展,自动化和机器人技术将实现更高的智能化程度,能够完成更加复杂的任务。语音识别和自然语言处理:人工智能已经实现了高度准确的语音识别技术,使得我们可以通过语音与智能助理交互,如苹果的Siri和亚马逊的Alexa。未来,语音识别技术将变得更加智能和自然,能够理解和回答更加复杂的问题。

在云计算环境中,如何利用 AI 改进云计算系统和数据库系统性能
2023年我想大家讨论最多,热度最大的技术领域就是 AIGC 了,AI绘画的兴起,ChatGPT的火爆,在微软背后推手的 OpenAI 大战 Google几回合后,国内各种的大语言模型产品也随之各家百花齐放,什么文心一言、通义千问、科大讯飞的星火以及华为的盘古等等,一下子国内也涌现出几十种人工智能的大语言模型产品。ChatGPT 爆火之后,你是否有冷静的思考过 AIGC 的兴起对我们有哪些机遇与挑战?我们如何将AI 应用到我们现有的工作学习中?_aigc k8s

神经网络中的分位数回归和分位数损失
分位数回归是一种强大的统计工具,对于那些关注数据分布中不同区域的问题,以及需要更加灵活建模的情况,都是一种有价值的方法。本文将介绍了在神经网络种自定义损失实现分位数回归,并且介绍了如何检测和缓解预测结果的"扁平化"问题。Quantile loss在一些应用中很有用,特别是在金融领域的风险管理问题中,因为它提供了一个在不同分位数下评估模型性能的方法。作者:Shiro Matsumoto。

基于神经网络——鸢尾花识别(Iris)
鸢尾花识别是学习AI入门的案例,这里和大家分享下使用Tensorflow2框架,编写程序,获取鸢尾花数据,搭建神经网络,最后训练和识别鸢尾花。
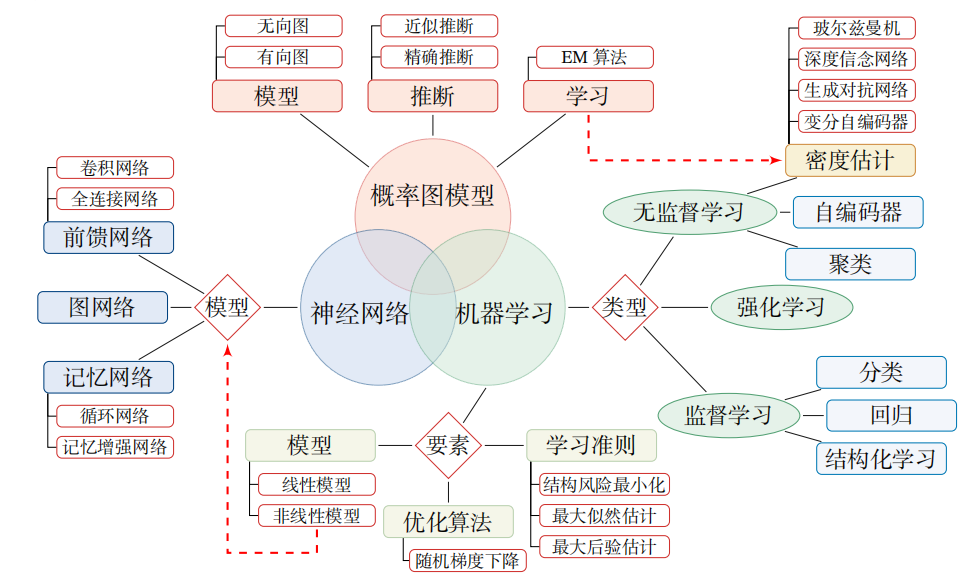
深度学习知识点全面总结
深度学习定义:一般是指通过训练多层网络结构对未知数据进行分类或回归深度学习分类:有监督学习方法——深度前馈网络、卷积神经网络、循环神经网络等; 无监督学习方法——深度信念网、深度玻尔兹曼机,深度自编码器等。深度神经网络的基本思想是通过构建多层网络,对目标进行多层表示,以期通过多层的高层次特征来表示数据的抽象语义信息,获得更好的特征鲁棒性。神经网络的计算主要有两种:前向传播(foward propagation, FP)作用于每一层的输入,通过逐层计算得到输出结果;

为什么深度学习神经网络可以学习任何东西
尽管如此,神经网络在处理一些对计算机而言极具挑战性的任务上表现出色,特别是在需要直觉和模糊逻辑的领域,如计算机视觉和自然语言处理,神经网络已经彻底改变了这些领域的面貌。在探讨神经网络如何学习的过程中,我们首先遇到了一个基本问题:如果我们不完全知道一个函数的形式,只知道它的部分输入和输出值,我们能否对这个函数进行逆向工程?重要的是,只要知道了这个函数,就可以针对任意输入x计算出对应的输出y。一种简单而有力的思考世界的方式,通过结合简单的计算,我们可以让计算机构造任何我们想要的功能,神经网络,从本质上讲,

如何使用JuiceSSH实现手机端远程连接Linux服务器
处于内网的虚拟机如何被外网访问呢?如何手机就能访问虚拟机呢?cpolar+JuiceSSH 实现手机端远程连接Linux虚拟机(内网穿透,手机端连接Linux虚拟机)
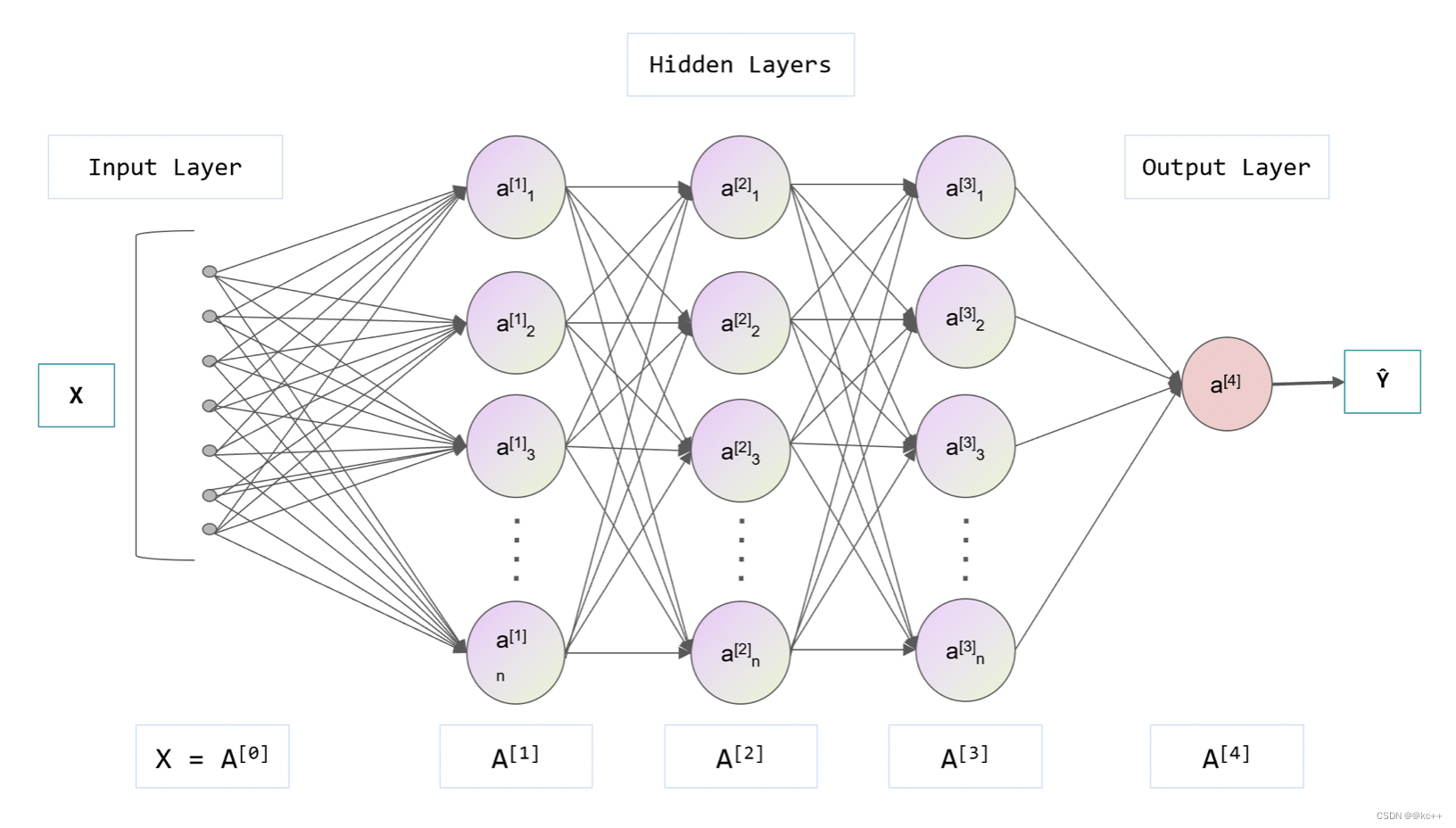
深度学习与神经网络
神经网络是一种模拟人脑神经元行为的计算模型,神经网络由大量的神经元(在计算领域中常被称为“节点”或“单元”)组成,并且这些神经元被分为不同的层,分别为输入层、隐藏层和输出层。每一个神经元都与前一层的所有神经元相连接,连接的强度(或权重)代表了该连接的重要性。神经元接收前一层神经元的信息(这些信息经过权重加权),然后通过激活函数(如Sigmoid、ReLU等)处理,将结果传递到下一层。输入层接收原始数据,隐藏层负责处理这些数据,而输出层则将处理后的结果输出。
程序,进程,线程,超线程之间的联系和区别
当我们谈到计算机程序的执行时,经常会涉及到“程序”,“进程”,“线程”和“超线程”这些概念。通过理解这些概念及其之间的联系和区别,可以帮助我们更好地理解计算机程序的执行方式和并发处理机制。来源:6547网 http://www.6547.cn/blog/442。

绝地求生电脑版的最低配置要求?
更好的方式是通过官方的渠道购买游戏账号,并遵守游戏的规则和使用协议,以保证自己的游戏体验和账号安全性。但请注意,游戏的配置要求可能随着游戏的更新而有所改变,建议您在购买或升级电脑时,参考官方的配置要求以获得最佳游戏体验。如果您的电脑配备了更高性能的处理器,游戏的运行体验将更为流畅。绝地求生是一款较为复杂的游戏,需要较大的内存来加载游戏资源并确保游戏的流畅运行。所以在安装游戏之前,确保您的电脑有足够的存储空间。这些推荐配置可以使您在绝地求生中获得更高的帧率和更好的画面表现,提供更加顺畅和逼真的游戏体验。
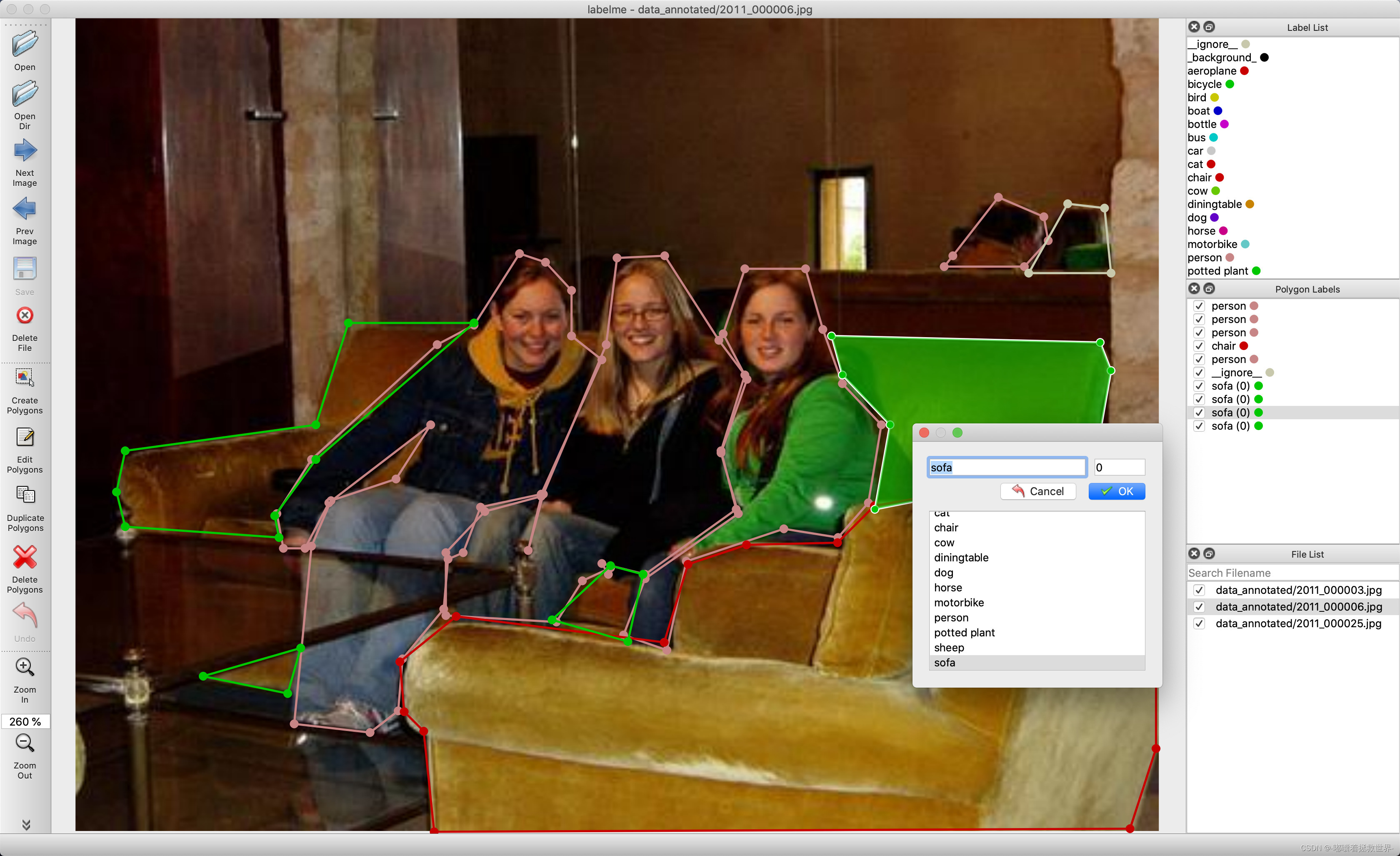
labelme安装与使用教程(内附一键运行包和转格式代码)
Labelme是一个开源的图像标注工具,由麻省理工学院的计算机科学和人工智能实验室(CSAIL)开发。它主要用于创建计算机视觉和机器学习应用所需的标记数据集。LabelMe让用户可以在图片上标注对象和区域,为机器学习模型提供训练数据。它支持多种标注类型,如矩形框、多边形和线条等。它是用 Python 编写的,并使用 Qt 作为其图形界面。
讲解mtrand.RandomState.randint low >= high
第一个例子生成了一个介于 0 和 10 之间(不包括 10)的随机整数,而第二个示例生成了一个形状为 (3, 2) 的二维数组,其中的元素是介于 1 和 100 之间(不包括 100)的随机整数。这样,我们就可以在实际的密码重置场景中使用 generate_reset_code() 函数来生成一个随机验证码,并将其发送给用户进行密码重置操作。这段代码的预期目标是生成一个范围为 [low, high) 的随机整数,即在 5 到 3 之间(不包括 3)生成一个整数。的问题,并生成所需范围内的随机整数。

讲解opencv检测黑色区域
本文介绍了使用OpenCV检测黑色区域的两种方法:阈值方法和颜色范围方法。阈值方法通过将图像转换为灰度图像并应用阈值处理来检测黑色区域。颜色范围方法通过在RGB或HSV颜色空间中定义合适的颜色范围来检测黑色区域。这些方法对于图像处理、目标定位和计算机视觉任务都非常有用。当用OpenCV检测黑色区域的一个实际应用场景是汽车驾驶辅助系统中的车道检测。import cv2# 转换为灰度图像# 应用阈值处理# 查找车道线轮廓# 找出最长的轮廓(假设为车道线)# 拟合多项式曲线。
讲解UserWarning: Update your Conv2D
Conv2D"告警信息是在旧版深度学习框架中使用较新的CNN模型时常见的问题。通过查阅官方文档并根据指导更新代码,我们能够适应新的API、参数或者用法,确保模型的正确性和性能。由于不同的框架和版本有所不同,我们需要根据具体情况来解决这个问题。及时更新框架和代码,保持与最新和推荐的版本保持同步,是进行深度学习研究和开发的重要环节。