讲解mtrand.RandomState.randint low >= high
目录
讲解 mtrand.RandomState.randint(low >= high) 的问题
讲解 mtrand.RandomState.randint(low >= high) 的问题
在使用NumPy进行随机数生成时,我们常常会使用 mtrand.RandomState.randint(low, high) 函数来生成指定范围内的随机整数。然而,在使用这个函数时,有一个非常容易犯错的地方,就是将 low 参数设置大于或等于 high 参数。 让我们来看一个简单的示例代码:
pythonCopy code
import numpy as np
np.random.seed(42)
low = 5
high = 3
result = np.random.randint(low, high)
print(result)这段代码的预期目标是生成一个范围为 [low, high) 的随机整数,即在 5 到 3 之间(不包括 3)生成一个整数。然而,当我们运行这段代码时,它却输出了一个随机整数。 这是因为在 NumPy 中, randint 函数允许 low 参数大于或等于 high 参数,并且在这种情况下默认会将两者互换。因此,我们实际上传入的是 np.random.randint(high, low),而非我们预期的范围。 上述代码的实际效果等价于:
pythonCopy code
import numpy as np
np.random.seed(42)
low = 3
high = 5
result = np.random.randint(low, high)
print(result)这样就可以得到我们期望的结果了。但是通常情况下,我们不希望按照预期的方式生成随机数,这就涉及到了一个潜在的错误。 为了避免这样的错误,我们应该始终注意传入参数的顺序,并确保 low 参数小于 high 参数。如果我们想要生成闭区间 [low, high] 内的随机整数,可以将 high 的值增加1,即使用 np.random.randint(low, high+1)。 希望通过这篇文章的讲解,你能够对 mtrand.RandomState.randint(low >= high) 这个容易犯错的问题有所了解,并在编程过程中避免这类错误。
当我们处理实际应用场景时,经常需要生成一定范围内的随机整数。下面是一个示例代码,涉及实际应用场景和解决方法:
pythonCopy code
import numpy as np
# 生成密码重置验证码
def generate_reset_code():
low = 1000
high = 9999
code = np.random.randint(low, high+1)
return code
reset_code = generate_reset_code()
print(reset_code)在这个示例中,我们使用了函数 generate_reset_code() 来生成一个4位数的密码重置验证码。我们将 low 参数设置为 1000,将 high 参数设置为 9999,这样我们将生成一个闭区间 [1000, 9999] 内的随机整数。通过调用 np.random.randint(low, high+1) 函数,可以确保我们生成的验证码在指定的范围内。 这样,我们就可以在实际的密码重置场景中使用 generate_reset_code() 函数来生成一个随机验证码,并将其发送给用户进行密码重置操作。 需要注意的是,为了避免在生成随机数时出现 low >= high 的错误,我们将 high 参数增加 1,并调用 np.random.randint(low, high+1) 函数来确保生成的随机整数在闭区间 [low, high] 内。 通过这个示例代码,我们可以理解在实际应用场景中如何正确使用 np.random.randint() 函数,避免 low >= high 的问题,并生成所需范围内的随机整数。
RandomState.randint 函数是 NumPy 库中的一个随机数生成函数,用于生成指定范围内的随机整数。它可以通过 mtrand.RandomState.randint(low, high, size=None, dtype=int) 的方式调用。 参数说明:
- low:表示生成随机整数范围的下界,必须是整数类型。
- high:表示生成随机整数范围的上界,必须是整数类型。生成的随机整数结果将包括 low,但不包括 high。
- size:表示生成的随机整数的形状,可以是一个整数或一个正整数元组。默认为 None,返回一个随机整数。
- dtype:表示生成随机整数的数据类型,默认为 int。 返回值: RandomState.randint 函数会生成一个给定形状和数据类型的随机数数组,数组的元素是从指定范围 [low, high) 内的随机整数。 示例代码:
pythonCopy code
import numpy as np
# 生成一个随机整数
random_num = np.random.randint(0, 10)
print(random_num)
# 生成一个形状为 (3, 2) 的二维随机整数数组
random_arr = np.random.randint(1, 100, size=(3, 2))
print(random_arr)在上述示例代码中,我们使用 RandomState.randint 函数生成了随机整数。第一个例子生成了一个介于 0 和 10 之间(不包括 10)的随机整数,而第二个示例生成了一个形状为 (3, 2) 的二维数组,其中的元素是介于 1 和 100 之间(不包括 100)的随机整数。 你可以根据具体的需求来调整 low、high、size 和 dtype 参数的值,以生成适合你应用的随机整数数组。
相关文章:

Yolov11-detect训练自己的数据集
至此,整个YOLOv11的训练预测阶段完成,与YOLOv8差不多。欢迎各位批评指正。

YOLOv10训练自己的数据集
至此,整个YOLOv10的训练预测阶段完成,与YOLOv8差不多。欢迎各位批评指正。

ModuleNotFoundError: No module named ‘qcloud_cos‘
是腾讯云提供的一个Python SDK,用于与腾讯云对象存储(COS)服务进行交互。使用pip安装qcloud_cos报以下错误。这个错误表示Python无法找到名为。
YOLOv10环境搭建、模型预测和ONNX推理
运行后会在文件yolov10s.pt存放路径下生成一个的yolov10s.onnxONNX模型文件。安装完成之后,我们简单执行下推理命令测试下效果,默认读取。终端,进入base环境,创建新环境。(1)onnx模型转换。

YOLOv7-Pose 姿态估计-环境搭建和推理
终端,进入base环境,创建新环境,我这里创建的是p38t17(python3.8,pytorch1.7)安装pytorch:(网络环境比较差时,耗时会比较长)下载好后打开yolov7-pose源码包。imgpath:需要预测的图片的存放路径。modelpath:模型的存放路径。Yolov7-pose权重下载。打开工程后,进入设置。

Math: Math.atan() 与 Math.atan2() 计算两点间连线的夹角
Math.atan2()函数返回点(x,y)和原点(0,0)之间直线的倾斜角.那么如何计算任意两点间直线的倾斜角呢?只需要将两点x,y坐标分别相减得到一个新的点(x2-x1,y2-y1).然后利用他求出角度就可以了.使用下面的一个转换可以实现计算出两点间连线的夹角.然而,Math.atan()只能返回一个角度值,因此确定他的角度非常的复杂,而且,90度和270度的正切是无穷大,因为除数为零,我们也是比较难以处理的~!angel为一个角度的弧度值,slope为直线的斜率,是一个数字,这个数字可以是负的。

Integer.toHexString(b & 0xff)理解以及& 0xff什么意思
首先toHexString传的参数应该是int类型32位,此处传的是byte类型8位,所以前面需要补24个0。然后& 0xff 就是把前面24个0去掉只要后8位。toHexString(b & 0xff)相当于做了一次位的与运算,将前24位字符省略,将后8位保留。是两个十六进制的数,每个f用二进制表示是1111,所以占四位(bit),两个f()占八位(bit),八位(bit)也就是一个字节(byte).这个方法是把字节(转换成了int)以16进制的方式显示。我的理解是这样,如有不对欢迎指正!

python安装成功的图标_ubuntu下:安装anaconda、环境配置、软件图标的创建、成功启动anaconda图形界面...
Ubuntu安装anaconda常见的四大问题:目录1、介绍2、安装anaconda3、环境配置4、软件图标的创建5、成功启动anaconda图形界面1、介绍先介绍一下anaconda和python的关系:初学者所安装的python2/3只是python的环境,没有python的工具包&a…
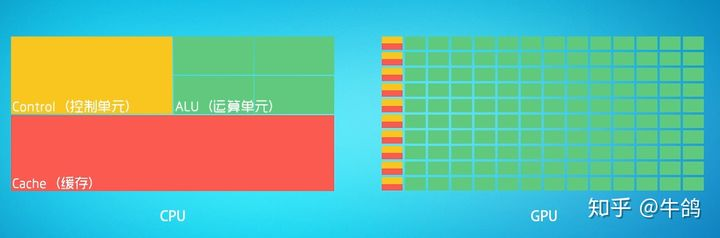
深度学习硬件基础:CPU与GPU
CPU:叫做中央处理器(central processing unit)作为计算机系统的运算和控制核心,是信息处理、程序运行的最终执行单元。[^3]可以形象的理解为有25%的ALU(运算单元)、有25%的Control(控制单元)、50%的Cache(缓存单元)GPU:叫做图形处理器。

YOLOv8-Detect训练CoCo数据集+自己的数据集
至此,整个训练预测阶段完成。此过程同样可以在linux系统上进行,在数据准备过程中需要仔细,保证最后得到的数据准确,最好是用显卡进行训练。有问题评论区见!

CSS局限属性contain:优化渲染性能的利器
在网页开发中,优化渲染性能是一个重要的目标。CSS局限属性contain是一个强大的工具,可以帮助我们提高网页的渲染性能。本文将介绍contain属性的基本概念、用法和优势,以及如何使用它来优化网页的渲染过程。

【OpenCV】在Linux上使用OpenCvSharp
OpenCvSharp是一个OpenCV的 .Net wrapper,应用最新的OpenCV库开发,使用习惯比EmguCV更接近原始的OpenCV,该库采用LGPL发行,对商业应用友好。
Java中的方法重载和方法重写有什么区别?
Java中的方法重载(Overloading)和方法重写(Overriding)都是面向对象编程中的重要概念,但它们之间有一些区别。方法重载是指在同一个类中,可以定义多个具有相同名称但参数列表不同的方法。这些方法具有不同的参数类型、参数个数或参数顺序。在调用重载方法时,Java编译器会根据传递给方法的参数类型和数量来选择要调用的正确方法。方法重载主要用于解决方法的命名冲突和提高代码的可读性和可维护性。
python基础使用之变量,表达式,语句
PYTHON基础知识系列之变量、表达式、语句

python基础小知识:引用和赋值的区别
通过引用,就可以在程序范围内任何地方传递大型对象而不必在途中进行开销巨大的赋值操作。不过需要注意的是,这种赋值仅能做到顶层赋值,如果出现嵌套的情况下仍不能进行深层赋值。赋值与引用不同,复制后会产生一个新的对象,原对象修改后不会影响到新的对象。如果在原位置修改这个可变对象时,可能会影响程序其他位置对这个对象的引用

基于深度学习的细胞感染性识别与判定
通过引入深度学习技术,我们能够更精准地识别细胞是否受到感染,为医生提供更及时的信息,有助于制定更有效的治疗方案。基于深度学习的方法通过学习大量样本,能够自动提取特征并进行准确的感染性判定,为医学研究提供了更高效和可靠的手段。通过引入先进的深度学习技术,我们能够实现更快速、准确的感染性判定,为医学研究和临床实践提供更为可靠的工具。其准确性和效率将为医学研究带来新的突破,为疾病的早期诊断和治疗提供更可靠的支持。通过大规模的训练,模型能够学到细胞感染的特征,并在未知数据上做出准确的预测。

Python自动化实战之接口请求的实现
作为一位过来人也是希望大家少走一些弯路,如果你不想再体验一次学习时找不到资料,没人解答问题,坚持几天便放弃的感受的话,在这里我给大家分享一些自动化测试的学习资源,希望能给你前进的路上带来帮助。
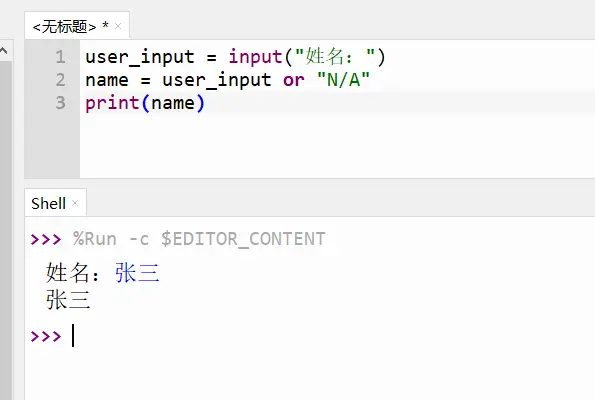
Python中如何简化if...else...语句
我们通常在Python中采用if...else..语句对结果进行判断,根据条件来返回不同的结果,如下面的例子。这段代码是一个简单的Python代码片段,让用户输入姓名并将其赋值给变量user_input。我们能不能把这几行代码进行简化,优化代码的执行效率呢?以下是对各行代码的解读。这里使用了or这个逻辑运算符,当user_input不为空时,user_input为真,name就被赋于user_input的值。采用这种方法可以轻松实现if...else语句的简化。我们可以使用一行简短的代码来实现上面的任务。

Java数据结构与算法:排序算法之插入排序
插入排序是一种基础的比较排序算法,其核心思想是将待排序的序列分为两部分,一部分是已排序的,另一部分是未排序的。在未排序部分选择一个元素,插入到已排序部分的适当位置,以此类推,直到所有元素都被排序完毕。插入排序的实现简单直观,是初学者入门排序算法的绝佳选择。
Java数据结构与算法:排序算法之归并排序
归并排序是一种基于分治思想的排序算法,它将待排序的序列划分成若干个子序列,分别进行排序,最后再合并成一个有序的序列。这一过程通过递归实现,直到每个子序列中只有一个元素,即可认为其已经有序。随后,通过两两合并有序序列,最终完成整个序列的排序。
Java数据结构与算法:排序算法之选择排序
选择排序是一种基础的比较排序算法,其核心思想是通过多次遍历待排序的元素,每次找到最小(或最大)的元素,放到已排序的序列的末尾(或开头)。尽管选择排序不如一些高级排序算法在性能上优越,但它的思想清晰、实现简单,是学习排序算法的重要一步。
Java数据结构与算法:排序算法之冒泡排序
冒泡排序是一种基础的比较排序算法,其核心思想是多次遍历待排序的元素,通过不断交换相邻的元素,使得最大(或最小)的元素逐步移动到正确的位置。虽然它在效率上不如一些高级排序算法,但其实现简单,是学习排序算法的绝佳入门。
Java数据结构与算法:排序算法之快速排序
快速排序是一种基于分治思想的排序算法,通过选取一个基准元素,将序列分成两个子序列,分别对左右两个子序列进行排序,从而达到整个序列有序的目的。快速排序的关键在于分区(Partition),即将序列分成两部分,使得左边的元素都小于基准元素,右边的元素都大于基准元素。
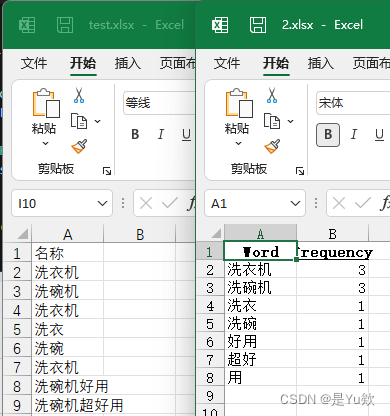
一键式Excel分词统计工具:如何轻松打包Python脚本为EXE
最近,表姐遇到了一个挑战:需要从Excel文件中统计出经过分词处理的重复字段,但由于数据隐私问题,这些Excel文件不能外传。这种情况下,直接使用Excel内置功能好像是行不通的,需要借助Python脚本来实现。为了解决这个问题,我写了一个简单的数据分析和自动化办公脚本,以方便使用。想象一下,即使电脑上没有安装Python,也能通过一个简单的EXE文件轻松完成工作,这是多么方便!因此,我决定不仅要写出这个脚本,还要学会如何将其打包成一个独立的EXE文件。这样,无需Python环境的电脑也能直接运行它
深入三目运算符:JavaScript、C++ 和 Python 比较
三目运算符是编程中常用的条件表达式,它允许我们根据条件选择不同的值。我们将通过具体的例子分别介绍 JavaScript、C++ 和 Python 中的三目运算符,以便更好地理解它们的用法和特性。JavaScript 示例// 例子: 根据条件选择不同的值var x = 10;var y = 20;"x 大于 y" : "x 不大于 y";在这个例子中,如果x大于y,则result的值为 “x 大于 y”,否则为 “x 不大于 y”。C++ 示例// 例子: 根据条件选择不同的值。

python实现网络爬虫代码_python如何实现网络爬虫
2、【find()】和【find_all()】方法可以遍历这个html文件,提取指定信息。return soup.find_all(string=re.compile( '百度' )) #结合正则表达式,实现字符串片段匹配。print(res) #打印输出[root@localhost demo]# python3 demo1.py。[root@localhost demo]# vim demo.py#web爬虫学习 -- 分析。r.raise_for_status() #如果状态码不是200,产生异常。
详细讲解Python中的aioschedule定时任务操作
aioschedule 是一个基于 asyncio 的 Python 库,用于在异步应用程序中进行任务调度。它提供了一种方便的方式来安排和执行异步任务,类似于传统的 schedule 库,但适用于异步编程。
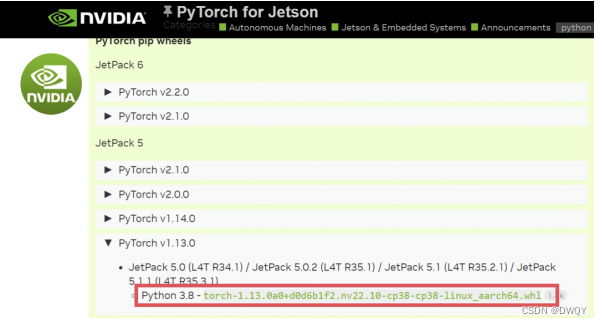
Jetson AGX Orin安装archiconda、Pytorch
Jetson AGX Orin安装archiconda、Pytorch

pandas进行数据计算时如何处理空值的问题?
我们在处理数据时经常会遇到空值的问题,比如有个学生某科弃考但是其他科有成绩的话,计算总分时便需要解决空值计算的问题
如何用pthon连接mysql和mongodb数据库【极简版】
发现宝藏 前言 1. 连接mysql 1.1 安装 PyMySQL 1.2 导入 PyMySQL 1.3 建立连接 1.4 创建游标对象 1.5 执行查询 1.6 关闭连接 1.7 完整示例 2. 连接mongodb 2.1 安装 PyMongo 2.2 导入 PyMongo 2.3 建立连接 2.4