程序,进程,线程,超线程之间的联系和区别
当我们谈到计算机程序的执行时,经常会涉及到“程序”,“进程”,“线程”和“超线程”这些概念。以下是它们之间的联系和区别:
- 程序:程序是一组指令的集合,用于实现特定的功能。它是静态的,存在于磁盘上,直到被加载到内存中执行。
- 进程:进程是程序的一次执行实例。它是动态的,存在于内存中,并且拥有一个或多个线程。进程具有独立于其他进程的地址空间,系统资源和状态。每个进程都有自己的内存空间和系统资源副本,并且由操作系统进行管理。
- 线程:线程是进程的基本执行单元,负责执行进程的指令。一个进程可以包含多个线程,这些线程共享同一个进程的内存空间和系统资源。线程的创建、切换和销毁的开销通常比进程小,因此线程成为实现并发执行的一种有效方式。
- 超线程:超线程是一种技术,允许一个物理处理器同时执行多个线程,从而提高了处理器的利用率。超线程技术通过复制处理器的一些资源(如寄存器和状态)来实现同时执行多个线程。虽然每个线程可以独立地执行,但它们共享处理器的计算资源。超线程技术可以在一定程度上提高程序的执行效率,但并不是所有的程序都能从中受益。
联系与区别:
- 联系:
- 程序、进程和线程都与计算机程序的执行相关。
- 进程和线程都与程序的并发执行有关。
- 区别:
- 程序是静态的,存在于磁盘上;而进程和线程是动态的,存在于内存中。
- 进程拥有独立的内存空间和系统资源;而线程则共享同一个进程的资源。
- 超线程允许一个物理处理器同时执行多个线程,以提高处理器的利用率。
通过理解这些概念及其之间的联系和区别,可以帮助我们更好地理解计算机程序的执行方式和并发处理机制。
来源:6547网 http://www.6547.cn/blog/442
相关文章:

Yolov11-detect训练自己的数据集
至此,整个YOLOv11的训练预测阶段完成,与YOLOv8差不多。欢迎各位批评指正。

YOLOv10训练自己的数据集
至此,整个YOLOv10的训练预测阶段完成,与YOLOv8差不多。欢迎各位批评指正。
YOLOv10环境搭建、模型预测和ONNX推理
运行后会在文件yolov10s.pt存放路径下生成一个的yolov10s.onnxONNX模型文件。安装完成之后,我们简单执行下推理命令测试下效果,默认读取。终端,进入base环境,创建新环境。(1)onnx模型转换。

YOLOv7-Pose 姿态估计-环境搭建和推理
终端,进入base环境,创建新环境,我这里创建的是p38t17(python3.8,pytorch1.7)安装pytorch:(网络环境比较差时,耗时会比较长)下载好后打开yolov7-pose源码包。imgpath:需要预测的图片的存放路径。modelpath:模型的存放路径。Yolov7-pose权重下载。打开工程后,进入设置。

Math: Math.atan() 与 Math.atan2() 计算两点间连线的夹角
Math.atan2()函数返回点(x,y)和原点(0,0)之间直线的倾斜角.那么如何计算任意两点间直线的倾斜角呢?只需要将两点x,y坐标分别相减得到一个新的点(x2-x1,y2-y1).然后利用他求出角度就可以了.使用下面的一个转换可以实现计算出两点间连线的夹角.然而,Math.atan()只能返回一个角度值,因此确定他的角度非常的复杂,而且,90度和270度的正切是无穷大,因为除数为零,我们也是比较难以处理的~!angel为一个角度的弧度值,slope为直线的斜率,是一个数字,这个数字可以是负的。

Integer.toHexString(b & 0xff)理解以及& 0xff什么意思
首先toHexString传的参数应该是int类型32位,此处传的是byte类型8位,所以前面需要补24个0。然后& 0xff 就是把前面24个0去掉只要后8位。toHexString(b & 0xff)相当于做了一次位的与运算,将前24位字符省略,将后8位保留。是两个十六进制的数,每个f用二进制表示是1111,所以占四位(bit),两个f()占八位(bit),八位(bit)也就是一个字节(byte).这个方法是把字节(转换成了int)以16进制的方式显示。我的理解是这样,如有不对欢迎指正!
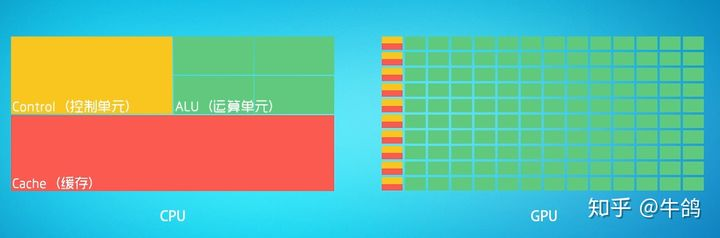
深度学习硬件基础:CPU与GPU
CPU:叫做中央处理器(central processing unit)作为计算机系统的运算和控制核心,是信息处理、程序运行的最终执行单元。[^3]可以形象的理解为有25%的ALU(运算单元)、有25%的Control(控制单元)、50%的Cache(缓存单元)GPU:叫做图形处理器。

YOLOv8-Detect训练CoCo数据集+自己的数据集
至此,整个训练预测阶段完成。此过程同样可以在linux系统上进行,在数据准备过程中需要仔细,保证最后得到的数据准确,最好是用显卡进行训练。有问题评论区见!

CSS局限属性contain:优化渲染性能的利器
在网页开发中,优化渲染性能是一个重要的目标。CSS局限属性contain是一个强大的工具,可以帮助我们提高网页的渲染性能。本文将介绍contain属性的基本概念、用法和优势,以及如何使用它来优化网页的渲染过程。

基于深度学习的细胞感染性识别与判定
通过引入深度学习技术,我们能够更精准地识别细胞是否受到感染,为医生提供更及时的信息,有助于制定更有效的治疗方案。基于深度学习的方法通过学习大量样本,能够自动提取特征并进行准确的感染性判定,为医学研究提供了更高效和可靠的手段。通过引入先进的深度学习技术,我们能够实现更快速、准确的感染性判定,为医学研究和临床实践提供更为可靠的工具。其准确性和效率将为医学研究带来新的突破,为疾病的早期诊断和治疗提供更可靠的支持。通过大规模的训练,模型能够学到细胞感染的特征,并在未知数据上做出准确的预测。

Java数据结构与算法:排序算法之插入排序
插入排序是一种基础的比较排序算法,其核心思想是将待排序的序列分为两部分,一部分是已排序的,另一部分是未排序的。在未排序部分选择一个元素,插入到已排序部分的适当位置,以此类推,直到所有元素都被排序完毕。插入排序的实现简单直观,是初学者入门排序算法的绝佳选择。
Java数据结构与算法:排序算法之归并排序
归并排序是一种基于分治思想的排序算法,它将待排序的序列划分成若干个子序列,分别进行排序,最后再合并成一个有序的序列。这一过程通过递归实现,直到每个子序列中只有一个元素,即可认为其已经有序。随后,通过两两合并有序序列,最终完成整个序列的排序。
Java数据结构与算法:排序算法之选择排序
选择排序是一种基础的比较排序算法,其核心思想是通过多次遍历待排序的元素,每次找到最小(或最大)的元素,放到已排序的序列的末尾(或开头)。尽管选择排序不如一些高级排序算法在性能上优越,但它的思想清晰、实现简单,是学习排序算法的重要一步。
Java数据结构与算法:排序算法之冒泡排序
冒泡排序是一种基础的比较排序算法,其核心思想是多次遍历待排序的元素,通过不断交换相邻的元素,使得最大(或最小)的元素逐步移动到正确的位置。虽然它在效率上不如一些高级排序算法,但其实现简单,是学习排序算法的绝佳入门。
Java数据结构与算法:排序算法之快速排序
快速排序是一种基于分治思想的排序算法,通过选取一个基准元素,将序列分成两个子序列,分别对左右两个子序列进行排序,从而达到整个序列有序的目的。快速排序的关键在于分区(Partition),即将序列分成两部分,使得左边的元素都小于基准元素,右边的元素都大于基准元素。
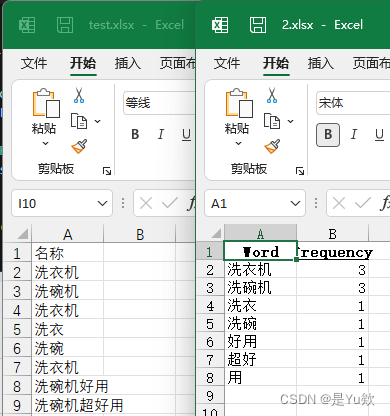
一键式Excel分词统计工具:如何轻松打包Python脚本为EXE
最近,表姐遇到了一个挑战:需要从Excel文件中统计出经过分词处理的重复字段,但由于数据隐私问题,这些Excel文件不能外传。这种情况下,直接使用Excel内置功能好像是行不通的,需要借助Python脚本来实现。为了解决这个问题,我写了一个简单的数据分析和自动化办公脚本,以方便使用。想象一下,即使电脑上没有安装Python,也能通过一个简单的EXE文件轻松完成工作,这是多么方便!因此,我决定不仅要写出这个脚本,还要学会如何将其打包成一个独立的EXE文件。这样,无需Python环境的电脑也能直接运行它
Java中 && 和|| 在同一个 if 里面使用 会出现啥问题&Java中运算符“|”和“||”以及“&”和“&&”区别
如果在同一个 if 语句中同时使用 && 和 || 运算符,可能会导致逻辑错误。这样就会导致逻辑错误,当 a 为 false,b 为 true 时,输出结果会是 “Goodbye”,而不是我们期望的 “Hello World”。假设有两个布尔类型的变量 a 和 b,我们要判断当 a 为 true 或者 b 为 true 时输出 “Hello World”,否则输出 “Goodbye”。:不论运算符左侧为true还是false,右侧语句都会进行判断,下面代码。

【MATLAB】 SSA奇异谱分析信号分解算法
SSA奇异谱分析(Singular Spectrum Analysis)是一种处理非线性时间序列数据的方法,可以对时间序列进行分析和预测。它基于构造在时间序列上的特定矩阵的奇异值分解(SVD),可以从一个时间序列中分解出趋势、振荡分量和噪声。具体流程如下:根据原始时间序列构建轨迹矩阵X XX。对矩阵X进行奇异值分解:X = ∑ i = 1 r σ i U i V i T X=\sum_{i=1}^{r} \sigma_i U_i V_{i}^TX=∑i=1rσiUiViT。

windows安装conda环境,开发openai应用准备,运行第一个ai程序
作者开发第一个openai应用的环境准备、第一个openai程序调用成功,做个记录,希望帮助新来的你。第一次能成功运行的openai程序,狠开心。

ArrayList底层的实现原理
ArrayList底层的实现原理 ArrayList底层是用动态数组实现的 ArrayList初始化容量为0,当第一次添加数据的时候才会初始化为10。 ArrayList在进行扩容的时候是原来容量的1.5倍,每次扩容都需要拷贝数组。 ArrayList在添加数据的时候 确保数组已使用长度size+1之后足够存下下一个数据 计算数组的容量,如果当前数组已使用长度+1后的大于当前的数组长度,则调用grow方法扩容(原来的1.5倍) 确保新增的数据有地方存储之后,则将新
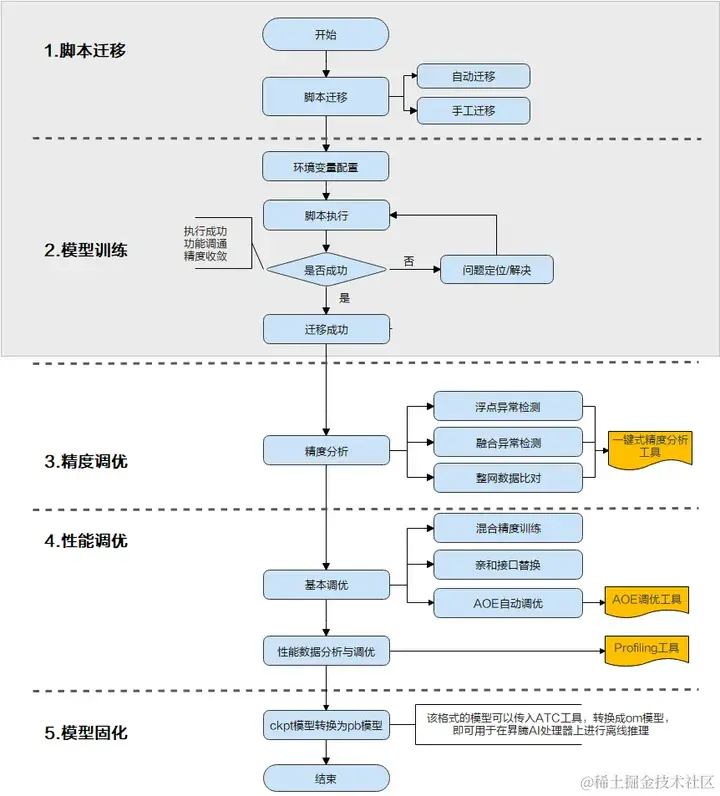
一文详解TensorFlow模型迁移及模型训练实操步骤
当前业界很多训练脚本是基于TensorFlow的Python API进行开发的,默认运行在CPU/GPU/TPU上,为了使这些脚本能够利用昇腾AI处理器的强大算力执行训练,需要对TensorFlow的训练脚本进行迁移。
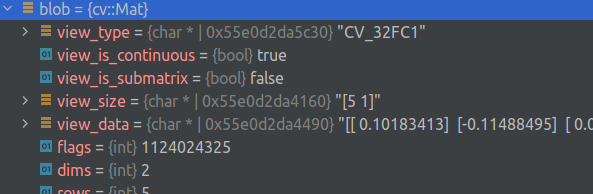
将 OpenCV 与 gdb 驱动的 IDE 结合使用
能力这个漂亮的打印机可以显示元素类型、标志和(可能被截断的)矩阵。众所周知,它可以在 Clion、VS Code 和 gdb 中工作。Clion 示例安装移入 .放在方便的地方,重命名并移动到您的个人文件夹中。将“source”行更改为指向您的路径。如果系统中安装的 python 3 版本与 gdb 中的版本不匹配,请使用完全相同的版本创建一个新的虚拟环境,相应地安装并更改 python3 的路径。用法调试器中以前缀为前缀的字段是为方便起见而添加的伪字段,其余字段保持原样。

改进的yolov5目标检测-yolov5替换骨干网络-yolo剪枝(TensorRT及NCNN部署)
改进的yolov5目标检测-yolov5替换骨干网络-yolo剪枝(TensorRT及NCNN部署)2021.10.30 复现TPH-YOLOv52021.10.31 完成替换backbone为Ghostnet2021.11.02 完成替换backbone为Shufflenetv22021.11.05 完成替换backbone为Mobilenetv3Small2021.11.10 完成EagleEye对YOLOv5系列剪枝支持2021.11.14 完成MQBench对YOLOv5系列量
PyTorch中nn.Module的继承类中方法foward是自动执行的么?
在 PyTorch的 nn.Module中,forward方法并不是自动执行的,但它是在模型进行前向传播时必须调用的一个方法。当你实例化一个继承自torch.nn.Module的自定义类并传入输入数据时,需要通过调用该实例来实现前向传播计算,这实际上会隐式地调用forward方法。
文本挖掘的几种常用的方法
1. 文本预处理:首先对文本数据进行清洗和预处理,如去除停用词(如“的”、“是”等常用词)、标点符号和特殊字符,并进行词干化或词形还原等操作,以减少数据噪声和提取更有意义的特征。3. 文本分类:将文本数据分为不同的类别或标签。文本挖掘是一种通过自动化地发现、提取和分析大量文本数据中的有趣模式、关联和知识的技术。这些示例代码只是简单的演示了各种方法的使用方式,具体的实现还需要根据具体的需求和数据进行适当的调整和优化。8. 文本生成:使用统计模型或深度学习模型生成新的文本,如机器翻译、文本摘要和对话系统等。
智能革命:揭秘AI如何重塑创新与效率的未来
智能革命:揭秘AI如何重塑创新与效率的未来

Leetcode算法系列| 11. 盛最多水的容器
给定一个长度为 n 的整数数组 height。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i])。找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。返回容器可以储存的最大水量。说明:你不能倾斜容器。
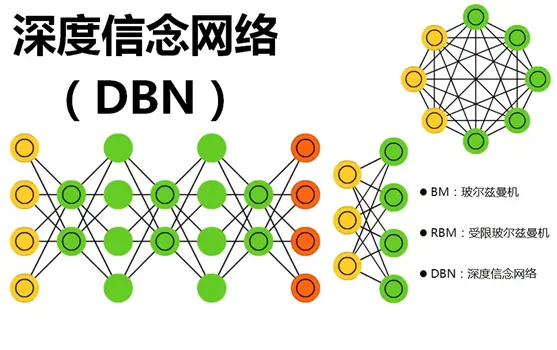
一文搞懂深度信念网络!DBN概念介绍与Pytorch实战
深度信念网络(Deep Belief Networks, DBNs)是一种深度学习模型,代表了一种重要的技术创新,具有几个关键特点和突出能力。首先,DBNs是由多层受限玻尔兹曼机(Restricted Boltzmann Machines, RBMs)堆叠而成的生成模型。这种多层结构使得DBNs能够捕获数据中的高层次抽象特征,对于复杂的数据结构具有强大的表征能力。其次,DBNs采用无监督预训练的方式逐层训练模型。
人工智能在现代科技中的应用和未来发展趋势
未来,深度学习将进一步发展,能够应用于更多的领域,如自动驾驶、智能制造和医疗辅助等。图像识别和计算机视觉:人工智能在图像识别和计算机视觉领域取得了巨大突破,能够自动识别和分类图像中的物体和场景。未来,随着人工智能技术的发展,自动化和机器人技术将实现更高的智能化程度,能够完成更加复杂的任务。语音识别和自然语言处理:人工智能已经实现了高度准确的语音识别技术,使得我们可以通过语音与智能助理交互,如苹果的Siri和亚马逊的Alexa。未来,语音识别技术将变得更加智能和自然,能够理解和回答更加复杂的问题。

在云计算环境中,如何利用 AI 改进云计算系统和数据库系统性能
2023年我想大家讨论最多,热度最大的技术领域就是 AIGC 了,AI绘画的兴起,ChatGPT的火爆,在微软背后推手的 OpenAI 大战 Google几回合后,国内各种的大语言模型产品也随之各家百花齐放,什么文心一言、通义千问、科大讯飞的星火以及华为的盘古等等,一下子国内也涌现出几十种人工智能的大语言模型产品。ChatGPT 爆火之后,你是否有冷静的思考过 AIGC 的兴起对我们有哪些机遇与挑战?我们如何将AI 应用到我们现有的工作学习中?_aigc k8s