Lucene.net中文分词探究
一、中文分词方式:
中文分词几种常用的方式:
A. 单字分词
单字分词,顾名思义,就是按照中文一个字一个字地进行分词。如:我们是中国人,效果:我/们/是/中/国/人。
B. 二分法
二分法,就是按两个字进行切分。如:我们是中国人,效果:我们/们是/是中/中国/国人。
C. 词库分词
词库分词,就是按某种算法构造词然后去匹配已建好的词库集合,如果匹配到就切分出来成为词语。通常词库分词被认为是最理想的中文分词算法如:我们是中国人,通成效果为:我们/是/中国/中国人。
二、Lucene.net中五种中文分词效果探究
在Lucene.net中有很多种分词器,不同分词器使用了不同的分词算法,有不同的分词效果,满足不同的需求!在这里主要是看看其中五中分词器用来对中文切词的效果。五中分词器分别为:StandardTokenizer,CJKTokenizer,ChinessTokenizer,LowerCaseTokenizer,WhitespaceTokenizer;
下面就来测试一下它们切词的效果:
测试目标:是否支持中文词语,英文单词,邮件,IP地址,标点符号,数字,数学表达式的切割。
测试文字:“我们是中国人; 我们 是 人;we are chiness; 172.16.34.172;youpeizun@126.com;#$*;85*34;58 69”
测试StandardTokenizer的分词情况如下: 我/ 们/ 是/ 中/ 国/ 人/ 我/ 们/ 是/ 人/ we/ are/ chiness/ 172.16.34.172/ youpeizun@126.com/ 85/ 34/ 58/ 69/ 测试CJKTokenizer的分词情况如下: 我们/ 们是/ 是中/ 中国/ 国人/ 我们/ 是/ 人/ we/ chiness/ 172/ 16/ 34/ 172/ youpe izun/ 126/ com/ #/ 85/ 34/ 58/ 69/ 测试ChinessTokenizer的分词情况如下: 我/ 们/ 是/ 中/ 国/ 人/ 我/ 们/ 是/ 人/ we/ are/ chiness/ 172/ 16/ 34/ 172/ youp eizun/ 126/ com/ 85/ 34/ 58/ 69/ 测试LowerCaseTokenizer的分词情况如下: 我们是中国人/我们/是/人/we/are/chiness/youpeizun/com/ 测试WhitespaceTokenizer的分词情况如下: 我们是中国人;/我们/是/人;we/are/chiness;/172.16.34.172;youpeizun@126.com;#$*;85* 34;58/69/ |
测试代码:
一、中文分词方式:
 using System;using System.Collections.Generic;using System.Text;using Lucene.Net.Analysis.Standard;using Lucene.Net.Analysis;using Lucene.Net.Index;using Lucene.Net.Documents;using System.IO;using Lucene.Net.Analysis.Cn;using Lucene.Net.Analysis.CJK;//date:11-02-2007//home page:http://www.cnblogs.com/xuanfeng//author:peizunyounamespace TokenizerTest
using System;using System.Collections.Generic;using System.Text;using Lucene.Net.Analysis.Standard;using Lucene.Net.Analysis;using Lucene.Net.Index;using Lucene.Net.Documents;using System.IO;using Lucene.Net.Analysis.Cn;using Lucene.Net.Analysis.CJK;//date:11-02-2007//home page:http://www.cnblogs.com/xuanfeng//author:peizunyounamespace TokenizerTest

 {
{ class TokenizerTest
class TokenizerTest
 { static void Main(string[] args) { string testText = "我们是中国人; 我们 是 人;we are chiness; 172.16.34.172;youpeizun@126.com;#$*;85*34;58 69"; Console.WriteLine("测试文字:"+testText); Console.WriteLine("测试StandardTokenizer的分词情况如下:"); TestStandardTokenizer(testText); Console.WriteLine("测试CJKTokenizer的分词情况如下:"); TestCJKTokenizer(testText); Console.WriteLine("测试ChinessTokenizer的分词情况如下:"); TestChinessTokenizer(testText); Console.WriteLine("测试LowerCaseTokenizer的分词情况如下:"); TestLowerCaseTokenizer(testText); Console.WriteLine("测试WhitespaceTokenizer的分词情况如下:"); TestWhitespaceTokenizer(testText); Console.Read();
{ static void Main(string[] args) { string testText = "我们是中国人; 我们 是 人;we are chiness; 172.16.34.172;youpeizun@126.com;#$*;85*34;58 69"; Console.WriteLine("测试文字:"+testText); Console.WriteLine("测试StandardTokenizer的分词情况如下:"); TestStandardTokenizer(testText); Console.WriteLine("测试CJKTokenizer的分词情况如下:"); TestCJKTokenizer(testText); Console.WriteLine("测试ChinessTokenizer的分词情况如下:"); TestChinessTokenizer(testText); Console.WriteLine("测试LowerCaseTokenizer的分词情况如下:"); TestLowerCaseTokenizer(testText); Console.WriteLine("测试WhitespaceTokenizer的分词情况如下:"); TestWhitespaceTokenizer(testText); Console.Read(); } static void TestStandardTokenizer(string text) { TextReader tr = new StringReader(text); StandardTokenizer st = new StandardTokenizer(tr); while (st.Next() != null) { Console.Write(st.token.ToString()+"/ "); } Console.WriteLine(); } static void TestCJKTokenizer(string text) { TextReader tr = new StringReader(text); int end = 0; CJKAnalyzer cjkA = new CJKAnalyzer(); TokenStream ts = cjkA.TokenStream(tr); while(end<text.Length) { Lucene.Net.Analysis.Token t = ts.Next(); end = t.EndOffset(); Console.Write(t.TermText()+"/ "); } Console.WriteLine(); } static void TestChinessTokenizer(string text) { TextReader tr = new StringReader(text); ChineseTokenizer ct = new ChineseTokenizer(tr); int end = 0; Lucene.Net.Analysis.Token t; while(end<text.Length) { t = ct.Next(); end = t.EndOffset(); Console.Write(t.TermText()+"/ "); } Console.WriteLine(); } static void TestLowerCaseTokenizer(string text) { TextReader tr = new StringReader(text); SimpleAnalyzer sA = new SimpleAnalyzer(); //SimpleAnalyzer使用了LowerCaseTokenizer分词器 TokenStream ts = sA.TokenStream(tr); Lucene.Net.Analysis.Token t; while((t=ts.Next())!=null) { Console.Write(t.TermText()+"/"); } Console.WriteLine(); } static void TestWhitespaceTokenizer(string text) { TextReader tr = new StringReader(text); WhitespaceAnalyzer sA = new WhitespaceAnalyzer(); TokenStream ts = sA.TokenStream(tr); Lucene.Net.Analysis.Token t; while ((t = ts.Next()) != null) { Console.Write(t.TermText() + "/"); } Console.WriteLine(); } }
} static void TestStandardTokenizer(string text) { TextReader tr = new StringReader(text); StandardTokenizer st = new StandardTokenizer(tr); while (st.Next() != null) { Console.Write(st.token.ToString()+"/ "); } Console.WriteLine(); } static void TestCJKTokenizer(string text) { TextReader tr = new StringReader(text); int end = 0; CJKAnalyzer cjkA = new CJKAnalyzer(); TokenStream ts = cjkA.TokenStream(tr); while(end<text.Length) { Lucene.Net.Analysis.Token t = ts.Next(); end = t.EndOffset(); Console.Write(t.TermText()+"/ "); } Console.WriteLine(); } static void TestChinessTokenizer(string text) { TextReader tr = new StringReader(text); ChineseTokenizer ct = new ChineseTokenizer(tr); int end = 0; Lucene.Net.Analysis.Token t; while(end<text.Length) { t = ct.Next(); end = t.EndOffset(); Console.Write(t.TermText()+"/ "); } Console.WriteLine(); } static void TestLowerCaseTokenizer(string text) { TextReader tr = new StringReader(text); SimpleAnalyzer sA = new SimpleAnalyzer(); //SimpleAnalyzer使用了LowerCaseTokenizer分词器 TokenStream ts = sA.TokenStream(tr); Lucene.Net.Analysis.Token t; while((t=ts.Next())!=null) { Console.Write(t.TermText()+"/"); } Console.WriteLine(); } static void TestWhitespaceTokenizer(string text) { TextReader tr = new StringReader(text); WhitespaceAnalyzer sA = new WhitespaceAnalyzer(); TokenStream ts = sA.TokenStream(tr); Lucene.Net.Analysis.Token t; while ((t = ts.Next()) != null) { Console.Write(t.TermText() + "/"); } Console.WriteLine(); } } }
}中文分词几种常用的方式:
A. 单字分词
单字分词,顾名思义,就是按照中文一个字一个字地进行分词。如:我们是中国人,效果:我/们/是/中/国/人。
B. 二分法
二分法,就是按两个字进行切分。如:我们是中国人,效果:我们/们是/是中/中国/国人。
C. 词库分词
词库分词,就是按某种算法构造词然后去匹配已建好的词库集合,如果匹配到就切分出来成为词语。通常词库分词被认为是最理想的中文分词算法如:我们是中国人,通成效果为:我们/是/中国/中国人。
二、Lucene.net中五种中文分词效果探究
在Lucene.net中有很多种分词器,不同分词器使用了不同的分词算法,有不同的分词效果,满足不同的需求!在这里主要是看看其中五中分词器用来对中文切词的效果。五中分词器分别为:StandardTokenizer,CJKTokenizer,ChinessTokenizer,LowerCaseTokenizer,WhitespaceTokenizer;
下面就来测试一下它们切词的效果:
测试目标:是否支持中文词语,英文单词,邮件,IP地址,标点符号,数字,数学表达式的切割。
测试文字:“我们是中国人; 我们 是 人;we are chiness; 172.16.34.172;youpeizun@126.com;#$*;85*34;58 69”
测试StandardTokenizer的分词情况如下: 我/ 们/ 是/ 中/ 国/ 人/ 我/ 们/ 是/ 人/ we/ are/ chiness/ 172.16.34.172/ youpeizun@126.com/ 85/ 34/ 58/ 69/ 测试CJKTokenizer的分词情况如下: 我们/ 们是/ 是中/ 中国/ 国人/ 我们/ 是/ 人/ we/ chiness/ 172/ 16/ 34/ 172/ youpe izun/ 126/ com/ #/ 85/ 34/ 58/ 69/ 测试ChinessTokenizer的分词情况如下: 我/ 们/ 是/ 中/ 国/ 人/ 我/ 们/ 是/ 人/ we/ are/ chiness/ 172/ 16/ 34/ 172/ youp eizun/ 126/ com/ 85/ 34/ 58/ 69/ 测试LowerCaseTokenizer的分词情况如下: 我们是中国人/我们/是/人/we/are/chiness/youpeizun/com/ 测试WhitespaceTokenizer的分词情况如下: 我们是中国人;/我们/是/人;we/are/chiness;/172.16.34.172;youpeizun@126.com;#$*;85* 34;58/69/ |
测试代码:
测试代代码下载
using System;using System.Collections.Generic;using System.Text;using Lucene.Net.Analysis.Standard;using Lucene.Net.Analysis;using Lucene.Net.Index;using Lucene.Net.Documents;using System.IO;using Lucene.Net.Analysis.Cn;using Lucene.Net.Analysis.CJK;//date:11-02-2007//home page:http://www.cnblogs.com/xuanfeng//author:peizunyounamespace TokenizerTest{ class TokenizerTest { static void Main(string[] args) { string testText = "我们是中国人; 我们 是 人;we are chiness; 172.16.34.172;youpeizun@126.com;#$*;85*34;58 69"; Console.WriteLine("测试文字:"+testText); Console.WriteLine("测试StandardTokenizer的分词情况如下:"); TestStandardTokenizer(testText); Console.WriteLine("测试CJKTokenizer的分词情况如下:"); TestCJKTokenizer(testText); Console.WriteLine("测试ChinessTokenizer的分词情况如下:"); TestChinessTokenizer(testText); Console.WriteLine("测试LowerCaseTokenizer的分词情况如下:"); TestLowerCaseTokenizer(testText); Console.WriteLine("测试WhitespaceTokenizer的分词情况如下:"); TestWhitespaceTokenizer(testText); Console.Read(); } static void TestStandardTokenizer(string text) { TextReader tr = new StringReader(text); StandardTokenizer st = new StandardTokenizer(tr); while (st.Next() != null) { Console.Write(st.token.ToString()+"/ "); } Console.WriteLine(); } static void TestCJKTokenizer(string text) { TextReader tr = new StringReader(text); int end = 0; CJKAnalyzer cjkA = new CJKAnalyzer(); TokenStream ts = cjkA.TokenStream(tr); while(end<text.Length) { Lucene.Net.Analysis.Token t = ts.Next(); end = t.EndOffset(); Console.Write(t.TermText()+"/ "); } Console.WriteLine(); } static void TestChinessTokenizer(string text) { TextReader tr = new StringReader(text); ChineseTokenizer ct = new ChineseTokenizer(tr); int end = 0; Lucene.Net.Analysis.Token t; while(end<text.Length) { t = ct.Next(); end = t.EndOffset(); Console.Write(t.TermText()+"/ "); } Console.WriteLine(); } static void TestLowerCaseTokenizer(string text) { TextReader tr = new StringReader(text); SimpleAnalyzer sA = new SimpleAnalyzer(); //SimpleAnalyzer使用了LowerCaseTokenizer分词器 TokenStream ts = sA.TokenStream(tr); Lucene.Net.Analysis.Token t; while((t=ts.Next())!=null) { Console.Write(t.TermText()+"/"); } Console.WriteLine(); } static void TestWhitespaceTokenizer(string text) { TextReader tr = new StringReader(text); WhitespaceAnalyzer sA = new WhitespaceAnalyzer(); TokenStream ts = sA.TokenStream(tr); Lucene.Net.Analysis.Token t; while ((t = ts.Next()) != null) { Console.Write(t.TermText() + "/"); } Console.WriteLine(); } }}三、 五中分词器代码设计探究
从下面分词器代码设计中的静态结构图可以清晰的看出其继承关系。无论是哪个分词器,其分词最终实现的算法都是在Next()方法,想深入了解,请看其相关源码。
三、 五中分词器代码设计探究
从下面分词器代码设计中的静态结构图可以清晰的看出其继承关系。无论是哪个分词器,其分词最终实现的算法都是在Next()方法,想深入了解,请看其相关源码。
相关文章:
httpd服务相关实验
实验环境: CentOS6.8 1、连接测试: 在/etc/httpd/conf/httpd.conf telnet 172.16.252.242 80 GET /index.html HTTP/1.1 Host: 172.16.252.242 # KeepAlive: Whether or not to allow persistent connections (more than # one request per connection).…

WMI使用集锦
1.WMI简介WMI是英文Windows Management Instrumentation的简写,它的功能主要是:访问本地主机的一些信息和服务,可以管理远程计算机(当然你必须要拥有足够的权限),比如:重启,关机&…

基于Ubuntu交叉编译FFmpeg Windows SDK
写在前面 FFmpeg是一个开源且跨平台的音视频解决方案,集采集、转码、流式化为一身,项目的libavcodec编解码模块和libavformat媒体格式模块,支持非常非常丰富的编解码格式和容器封装格式,是做媒体相关开发工作必须要掌握和借鉴的一…
未来2年,程序员如何吊打高学历工程师?服气!
人工智能已成为新时代的风向标,如果你是对人工智能感兴趣的互联网工作者、大学生、研究生并期望在 AI 方向发展,建议你一定要深入学习一下人工智能。因为,未来将是人工智能的时代!为什么会有这个判断呢?第一࿰…

元素宽高的获取
elem.clientWidth/Height 获取某个元素可视区的宽高(不包括边框); elem.offsetWidth/Height 获取某个元素的宽高(计算边框); 当元素有padding值时,上面两个方法获取的值都包括padding。 doc…
VC++技术内幕(三)
C*View <- Cview <- CWnd <- Cobject C*View 两个最重要的基类:CView和CWnd,CWnd提供了C*View的”窗口属性”,CView则提供了它和应用程序框架其他部分间的联系。 在视窗内绘图: OnDraw成员函数: 是CView类中的虚成员函数…
用ASP.NET如何读取NT用户名
公司有个最近要开发一个小系统,是采用ASP.NET开发,现在被一难题卡住了. 需实现功能: 用户登录进来后系统自动取得用户名,这样就不用用户再登录了, 方便用户使用,并根据用户名取他的权限. 难点: 现在读NT用户名读不倒. 折腾了大半…
《赛博朋克2077》是捏脸游戏?上科大学生社团开发了一款赛博“滤镜”
作者 | eEhyQx出品 | AI科技大本营现象级大作《赛博朋克2077》终于没有跳票顺利发布了!你通关了吗?来自上海科技大学的学生社团GeekPie打造了一款全新的“滤镜”,CyberMe。只需上传一张照片,一秒将你带入夜之城!上传一…
vue父组件调用子组件的方法
vue组件与组件通信有如下几种情况: 平行组件父组件与子组件子组件与父组件它们之间通信有几种方法有: props自定义事件vuex今天我们聊一下父组件调用子组件的一种方法 parent.vue <template><div><h1>我是父组件</h1><child …

Ajax无刷新实现图片切换特效
1.页面cs代码usingSystem;usingSystem.Data;usingSystem.Configuration;usingSystem.Web;usingSystem.Web.Security;usingSystem.Web.UI;usingSystem.Web.UI.WebControls;usingSystem.Web.UI.WebControls.WebParts;usingSystem.Web.UI.HtmlControls;usingAjaxPro;publicpartial…
授权管理【学习笔记】《卓有成效的管理者》 第二章 掌握自己的时间
每日一贴,今天的内容关键字为授权管理 比拟《领导力》那本书,德鲁克这本书可操作性更强一些。 管理别人之前,先管理好自己;管理好自己,首先是管理好自己的时光。其实个人时光管理,有专门的书籍,在公司里&am…
再不参与就晚了!!2020年结束前最后一波内测福利!人人有份!
各位程序猿们都下载CSDN官方出品的插件了吧?什么?还有不知道插件是什么的同学??你错过了太多!更酷更高效的浏览器插件,一键万能操作,新标签页极简个性,让你的工作效率UP UP UP&#…

Node.js Express 框架 Express
Express 简介 Express 是一个简洁而灵活的 node.js Web应用框架, 提供了一系列强大特性帮助你创建各种 Web 应用,和丰富的 HTTP 工具。 使用 Express 可以快速地搭建一个完整功能的网站。 Express 框架核心特性: 可以设置中间件来响应 HTTP 请求。 定义…

Ajax实现无刷新树
1.建立一个aspx页面html代码<html xmlns"http://www.w3.org/1999/xhtml"><head id"Head1"runat"server"><title>小山</title><link type"text/css"href"../../Styles/tree_css/tree.css"rel&quo…
GEMM性能提升200倍,AutoKernel算子优化工具正式开源
作者 | OPEN AI LAB 研究员 吕春莹出品 | AI科技大本营头图 | CSDN下载自视觉中国随着AI技术的快速发展,深度学习在各个领域得到了广泛应用。深度学习模型能否成功在终端落地应用,满足产品需求,一个关键的指标就是神经网络模型的推理性能。于…

MySQL的log_bin和sql_log_bin 到底有什么区别?
2019独角兽企业重金招聘Python工程师标准>>> log_bin:二进制日志。 二进制日志的作用: 1:数据恢复 如果你的数据库出问题了,而你之前有过备份,那么可以看日志文件,找出是哪个命令导致你的数据库出问题了&a…

Ajax实现在textbox中输入内容,动态从数据库中模糊查询显示到下拉框中
功能:在textbox中输入内容,动态从数据库模糊查询显示到下拉框中,以供选择1.建立一aspx页面,html代码 <HTML><HEAD><title>WebForm1</title><SCRIPT language"javascript">//城市-------…
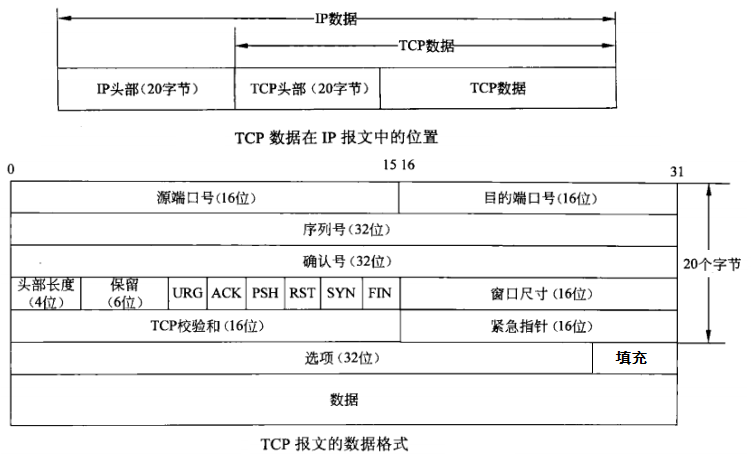
数据连接linux网络编程之TCP/IP基础(四):TCP连接的建立和断开、滑动窗口
在写这篇文章之前,xxx已经写过了几篇关于改数据连接主题的文章,想要了解的朋友可以去翻一下之前的文章 一、TCP段格式: TCP的段格式如下图所示 源端口号与目标端口号 源端口号和目标端口号,加上IP首部的源IP地址和目标IP地址唯一确定一个TCP连…
鲲鹏高校行太原站来袭,两大课程一站式掌握未来潮流
未来是算力比拼的时代,也是属于象牙塔中莘莘学子们的时代。北京时间12月14日,为了进一步培养计算产业人才,拓展鲲鹏产业生态影响力,由中北大学信息商务学院主办,山西鲲鹏生态创新中心承办的鲲鹏高校行系列活动在中北大…

R语言通过loess去除某个变量对数据的影响
当我们想研究不同sample的某个变量A之间的差异时,往往会因为其它一些变量B对该变量的固有影响,而影响不同sample变量A的比较,这个时候需要对sample变量A进行标准化之后才能进行比较。标准化的方法是对sample 的 A变量和B变量进行loess回归&am…

Ajax实现DataGrid/DataList动态ToolTip
1.建立一aspx页面,html代码2.cs代码 usingSystem.Data.SqlClient;usingSystem.IO;protectedvoidPage_Load(objectsender, EventArgs e) { if (!Page.IsPostBack) { BindData(); } if (ID ! "") …

语言模型自然语言处理[置顶] 哥伦比亚大学 自然语言处理 公开课 授课讲稿 翻译(四)...
每日一贴,今天的内容关键字为语言模型自然语言处理 媒介:灵机一动看了一个自然语言处理公开课,大牛柯林斯讲解的。认为很好,就自己动手把它的讲稿翻译成中文。一方面,希望通过这个翻译过程,让自己更加理解大牛的讲解内…
腾讯天衍实验室夺世界机器人大赛双冠军,新算法突破脑机接口瓶颈
日前,“2020世界机器人大赛-BCI脑控机器人大赛”公布成绩,腾讯天衍实验室和天津大学高忠科教授团队组成的C2Mind战队,经过多轮赛程的激烈比拼,实力入围BCI脑控机器人大赛“运动想象范式”赛题决赛,最终成功斩获技术赛“…
免费的私人代码托管(bitbucket) 和 常用git指令
转自 http://blog.csdn.net/nzing/article/details/24452475 今天想找个免费的私人代码托管平台,github,googlecode, SourceForge都不行,后来发现bitbucket(https://bitbucket.org/),注册时,如果不多于5个人…

Ajax简单示例之改变下拉框动态生成表格
1.建立一个aspx页面,html代码<html xmlns"http://www.w3.org/1999/xhtml"><head runat"server"><title>Untitled Page</title><script type"text/javascript">var xmlHttp; function createXML…
for语句内嵌例题与个人理解
例题1:画出一个高度为3的等腰三角形. 编写程序: #include<stdio.h> main() { int a,b,c,h; h3; \\h为高度,赋值常量3. for(a1;a<h;a) …

2020百度云秀最新成绩单,AI Cloud活跃客户数同比去年增长65%
12月17日,“ABC SUMMIT 2020百度云智峰会”在北京举行。大会以“智者先行”为主题,百度CTO王海峰展现了518新战略后百度智能云取得的最新成绩和产业智能化成果。“云智一体”成百度智能云独特的竞争力,在各行各业加快规模化落地。本届大会首次…
构建之法读后感part6
这个星期看完了构建之法的第六章,看了第六章之后了解到敏捷开发以用户的需求进化为核心,采用迭代、循序渐进的方法进行软件开发。在敏捷 开发中,软件项目在构建初期被切分成多个子项目,各个子项目的成果都经过测试,具备…

Ajax实现无刷新三联动下拉框
1.html代码<HTML><HEAD><title>Ajax实现无刷新三联动下拉框</title><meta content"Microsoft Visual Studio .NET 7.1"name"GENERATOR"><meta content"C#"name"CODE_LANGUAGE"><meta content&…
用算法改造过的植物肉,有兴趣试试么?
来源 | HyperAI超神经责编 | 晋兆雨头图 | CSDN 下载自视觉中国本月初,麦当劳宣布,将于 2021 年推出植物肉全新产品线 McPlant,新品品类将包括汉堡、鸡肉替代品以及早餐三明治。事实上,麦当劳并不是尝试植物基产品的首家快餐店&am…