GEMM性能提升200倍,AutoKernel算子优化工具正式开源
作者 | OPEN AI LAB 研究员 吕春莹
出品 | AI科技大本营
头图 | CSDN下载自视觉中国
随着AI技术的快速发展,深度学习在各个领域得到了广泛应用。深度学习模型能否成功在终端落地应用,满足产品需求,一个关键的指标就是神经网络模型的推理性能。于是,一大波算法工程师为了算法的部署转岗算子优化工程师。然而,优化代码并不是一件简单的事,它要求工程师既要精通计算机体系架构,又要熟悉算法的计算流程,于是,稍微有经验的深度学习推理优化工程师都成了各家公司争抢的“香饽饽”。相关人才少,但需求多,算子优化自动化成为了未来的一大趋势。
为了方便更多的工程师进行推理优化,一个致力于降低优化门槛,提升优化开发效率的算子自动优化工具AutoKernel宣布正式开源!
AutoKernel特色:
低门槛: 无需底层优化汇编的知识门槛
简单易用: 提供docker环境,无需安装环境,plugin一键集成到推理框架Tengine
高效率: 无需手写优化汇编,一键生成优化代码,一键部署
AutoKernel使用业界广泛使用的自动代码生成项目Halide,通过输入计算描述和调度策略,自动生成底层代码。AutoKernel支持以plugin的形式,将生成的自动优化算子一键部署到推理框架Tengine中。
下面,本教程将带领大家一步步优化矩阵乘法GEMM。无需手工撸代码,编写繁杂冗长的底层汇编代码,只需十几行简洁的调度代码。
在详细讲解优化步骤前,我们先谈谈优化的本质。我们在谈”优化“的时候,计算机底层做了什么?优化的”瓶颈“是什么?为什么通过一波”优化操作“,性能就能提升呢?AutoKernel使用的Halide是如何实现自动优化的呢?
要解答这些疑问,我们需要了解一下硬件的基础的体系结构,了解硬件如何工作,才能在软件上实现算法的时候,尽可能去考虑利用硬件的一些特性,来做到高效的、极致的优化。
上图是典型的存储理器层次结构:主存容量大,访问速度慢,寄存器和缓存读取速度快,但容量有限。在寄存器的层级上,CPU可以在一个时钟周期内访问它们,如果CPU去访问外部的DDR的话,延迟是非常大的,大概是200个时钟周期左右。如果CPU去访问cache的话,一般需要6到12个cycle就够了。所以,一个很重要的一个优化宗旨是:优化内存访问,充分利用寄存器和高速缓存去存数据。
第二个优化宗旨则是提高并行性:充分利用SIMD进行指令向量化和多核心并行。大部分现代CPU支持SIMD(Single Instruction Multiple Data,单指令流多数据流)。在同一个CPU循环中,SIMD可在多个值上同时执行相同的运算/指令。如果我们在4个数据点上进行向量化,一次计算四个数据,理论上就可以实现4倍的加速。
运行环境搭建
AutoKernel提供了docker镜像,docker里已经配置好运行环境,进入docker即可直接运行demo代码:
# 拉取镜像docker pull openailab/autokernel# 启动容器,进入开发环境docker run -it openailab/autokernel /bin/bash# 获取代码git clone https://github.com/OAID/AutoKernel.gitcd AutoKernel/doc/tutorials/data/
目录下的build.sh是demo的执行脚本,运行需要指定优化步骤step,可选的step是从1 到7,其中step= 1 是默认不优化的,step=7是最极致优化的。
优化效果
# 执行demo./build.sh 1./build.sh 7
下图展示了在Intel(R) Core(TM) i9-9900K CPU @ 3.60GHz的电脑上的优化效果,无需手工撸代码,无需编写繁杂冗长的底层汇编代码,只需十几行简洁的调度代码, 就能性能优化200+倍~
优化步骤
以下是更为详细的优化步骤:
STEP1
第一个步骤是不带任何优化的。用Halide语言直接描述GEMM的计算过程。
Var x,y; RDom k(0, K); Func gemm("gemm"); gemm(x, y) += A(k, y) * B(x, k);
计算M=N=K=640的矩阵乘法。运行脚本第一个参数指定step=1。耗时结果如下:
root@bd3faab0f079:/AutoKernel/doc/tutorials/data# ./06_build.sh 1step = 1M N K = 640 640 640 err 0.00 [rep 50] autokernel | blas 240.8523 ms 1.1376 ms
STEP2
这一步我们采用分块tile。分块的目的是为了充分利用缓存。如果原来的循环较大,tile分块改成小块数据去计算,可以使得每次计算的数据都比较舒适地呆在缓存里,不用经历重复的驱逐(在缓存中重复的添加和删除数据)。分块后进行reorder操作,交换两个嵌套循环的顺序,目的是最内层的内存访问友好。我们按照x,y维度划分成16x8的小分块去计算:
.gemm.update() .tile(x, y, xo, yo, xi, yi, 16, 8) .reorder(xi, yi, k, xo, yo);
执行结果如下:
root@bd3faab0f079:/AutoKernel/doc/tutorials/data# ./06_build.sh 2step = 2M N K = 640 640 640 err 0.00 [rep 50] halide | blas 81.8148 ms 1.1281 ms
性能从240ms优化到82ms,提升了近3倍。
STEP3
我们在上一步的基础上增加向量化vectorize。向量化是把几个标量计算(scale)转换为一个向量计算(vector),充分利用SIMD向量指令。大部分现代CPU支持SIMD(Single Instruction Multiple Data,单指令流多数据流)。在同一个CPU循环中,SIMD可在多个值上同时执行相同的运算/指令。
gemm.update() .tile(x, y, xo, yo, xi, yi, 16, 8) .reorder(xi, yi, k, xo, yo) .vectorize(xi, 8);
执行结果:
root@bd3faab0f079:/AutoKernel/doc/tutorials/data# ./06_build.sh 3step = 3M N K = 640 640 640 err 0.00 [rep 50] autokernel | blas 27.5433 ms 1.1445 ms
性能从82ms优化到27ms,又加速了接近3倍。可以看到,围绕前面提到的两条优化宗旨:优化内存访问和提高并行性,从step1到step3,性能已经提升了近9倍。
STEP4
调度策略在step3的基础上增加并行化parallel。对一个循环并行化是把循环的每次迭代分给多个线程或者处理器去同时处理,每个线程处理通过代码段(loop body),但是处理不同的数据。
gemm(x, y) += A(k, y) * B(x, k); gemm.update() .tile(x, y, xo, yo, xi, yi, 16, 8) .reorder(xi, yi, k, xo, yo) .vectorize(xi, 8) .parallel(yo);
执行结果:
root@bd3faab0f079:/home/chunying/AutoKernel/doc/tutorials# ./06_build.sh 4step = 4M N K = 640 640 640 err 0.00 [rep 50] autokernel | blas 7.2605 ms 1.1605 ms
增加并行化后,build.sh默认指定四线程,性能直接翻了近4倍,从27ms到7.3ms.
STEP5
调度策略在上一步的基础上增加unroll展开。如果循环体内的语句没有数据相关依赖,循环展开可以增加并发执行的机会,使得更充分利用寄存器,减少循环时每个操作内存加载和保存的次数。
gemm.update() .tile(x, y, xo, yo, xi, yi, 16, 8) .reorder(xi, yi, k, xo, yo) .vectorize(xi, 8) .parallel(yo) .unroll(xi) .unroll(yi,2);
执行结果:
root@bd3faab0f079:/AutoKernel/doc/tutorials/data# ./06_build.sh 5step = 5M N K = 640 640 640 err 0.00 [rep 50] autokernel | blas 4.7617 ms 1.1597 ms
unroll展开后,性能从7.3ms优化到4.8ms.
STEP6
前面的分块成 16 x 8的小kernel, 这一步先划分成 16 x 32的分块,然后把每个分块再分成 16 x 8的子分块。我们把最外层的两层循环合并到一层,并对这一层进行并行化。这一步计算描述多了一个prod函数来定义子分块的计算,prod函数的计算公式和总的gemm是一样的,我们通过 compute_at指定在 yi维度之下计算prod,则prod计算的是 16x8的小kernel, 大致逻辑如下:
总的代码如下:
Func prod; prod(x, y) += A(k, y) * B(x, k); gemm(x, y) = prod(x, y); gemm.tile(x, y, xi, yi, 16, 32) .fuse(x, y, xy).parallel(xy) .split(yi, yi, yii, 4) .vectorize(xi, 8) .unroll(xi) .unroll(yii); prod.compute_at(gemm, yi) .vectorize(x, 8).unroll(y); prod.update() .reorder(x, y, k) .vectorize(x, 8) .unroll(x) .unroll(y) .unroll(k, 2);
执行结果
root@bd3faab0f079:/AutoKernel/doc/tutorials/data# ./06_build.sh 6step = 6M N K = 640 640 640 err 0.00 [rep 50] autokernel | blas 3.1824 ms 1.1373 ms
这一步距离STEP1性能已经优化了近80倍了,性能越来越接近OpenBlas了。
STEP 7
这一步添加的操作是对矩阵B进行数据重排,使得在计算小kernel 16x8时,内存读取更顺畅。因为小kernel的x维度是按照16划分的,因此重排数据B的x维度也是按照16重排。
总的代码如下:
Func B_interleave("B"), Bs("Bs"); Bs(x, y, xo) = B(xo * 16 + x, y); B_interleave(x, y) = Bs(x % 16, y, x / 16); Func prod; prod(x, y) += A(k, y) * B_interleave(x, k); gemm(x, y) = prod(x, y); gemm.tile(x, y, xi, yi, 16, 32)
.fuse(x, y, xy).parallel(xy) .split(yi, yi, yii, 4) .vectorize(xi, 8) .unroll(xi) .unroll(yii); prod.compute_at(gemm, yi) .vectorize(x, 8).unroll(y); prod.update() .reorder(x, y, k) .vectorize(x, 8) .unroll(x) .unroll(y) .unroll(k, 2); Bs.compute_root() .split(y, yo, yi, 16) .reorder(x, yi, xo, yo) .unroll(x)
.vectorize(yi).parallel(yo, 4);
执行结果:
root@bd3faab0f079:/AutoKernel/doc/tutorials/data# ./06_build.sh 7step = 7M N K = 640 640 640 err 0.00 [rep 50] autokernel | blas 1.1957 ms 1.1425 ms
至此,我们的每一步调优策略始终都围绕两条优化宗旨“优化内存访问”,“提高并行性”展开优化,到最后性能已经与OpenBlAS差不多了,距离STEP1已经加速了200+倍了。
项目地址:
https://github.com/OAID/AutoKernel/
更多精彩推荐赠书 | 实现病人数据自动分析建模,Python能做的比你想象得更多
为什么苹果M1芯片这么快?
实战|手把手教你用Python爬取存储数据,还能自动在Excel中可视化
常说的「缓存穿透」和「击穿」是什么
C语言能够被替换吗?
相关文章:

MySQL的log_bin和sql_log_bin 到底有什么区别?
2019独角兽企业重金招聘Python工程师标准>>> log_bin:二进制日志。 二进制日志的作用: 1:数据恢复 如果你的数据库出问题了,而你之前有过备份,那么可以看日志文件,找出是哪个命令导致你的数据库出问题了&a…

Ajax实现在textbox中输入内容,动态从数据库中模糊查询显示到下拉框中
功能:在textbox中输入内容,动态从数据库模糊查询显示到下拉框中,以供选择1.建立一aspx页面,html代码 <HTML><HEAD><title>WebForm1</title><SCRIPT language"javascript">//城市-------…
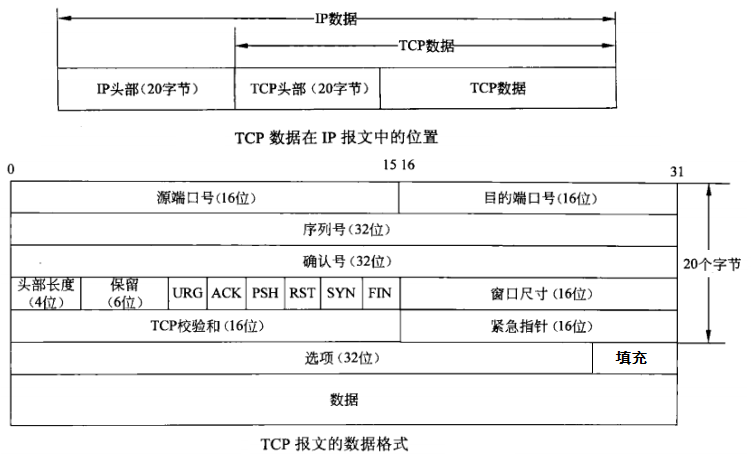
数据连接linux网络编程之TCP/IP基础(四):TCP连接的建立和断开、滑动窗口
在写这篇文章之前,xxx已经写过了几篇关于改数据连接主题的文章,想要了解的朋友可以去翻一下之前的文章 一、TCP段格式: TCP的段格式如下图所示 源端口号与目标端口号 源端口号和目标端口号,加上IP首部的源IP地址和目标IP地址唯一确定一个TCP连…
鲲鹏高校行太原站来袭,两大课程一站式掌握未来潮流
未来是算力比拼的时代,也是属于象牙塔中莘莘学子们的时代。北京时间12月14日,为了进一步培养计算产业人才,拓展鲲鹏产业生态影响力,由中北大学信息商务学院主办,山西鲲鹏生态创新中心承办的鲲鹏高校行系列活动在中北大…

R语言通过loess去除某个变量对数据的影响
当我们想研究不同sample的某个变量A之间的差异时,往往会因为其它一些变量B对该变量的固有影响,而影响不同sample变量A的比较,这个时候需要对sample变量A进行标准化之后才能进行比较。标准化的方法是对sample 的 A变量和B变量进行loess回归&am…

Ajax实现DataGrid/DataList动态ToolTip
1.建立一aspx页面,html代码2.cs代码 usingSystem.Data.SqlClient;usingSystem.IO;protectedvoidPage_Load(objectsender, EventArgs e) { if (!Page.IsPostBack) { BindData(); } if (ID ! "") …

语言模型自然语言处理[置顶] 哥伦比亚大学 自然语言处理 公开课 授课讲稿 翻译(四)...
每日一贴,今天的内容关键字为语言模型自然语言处理 媒介:灵机一动看了一个自然语言处理公开课,大牛柯林斯讲解的。认为很好,就自己动手把它的讲稿翻译成中文。一方面,希望通过这个翻译过程,让自己更加理解大牛的讲解内…
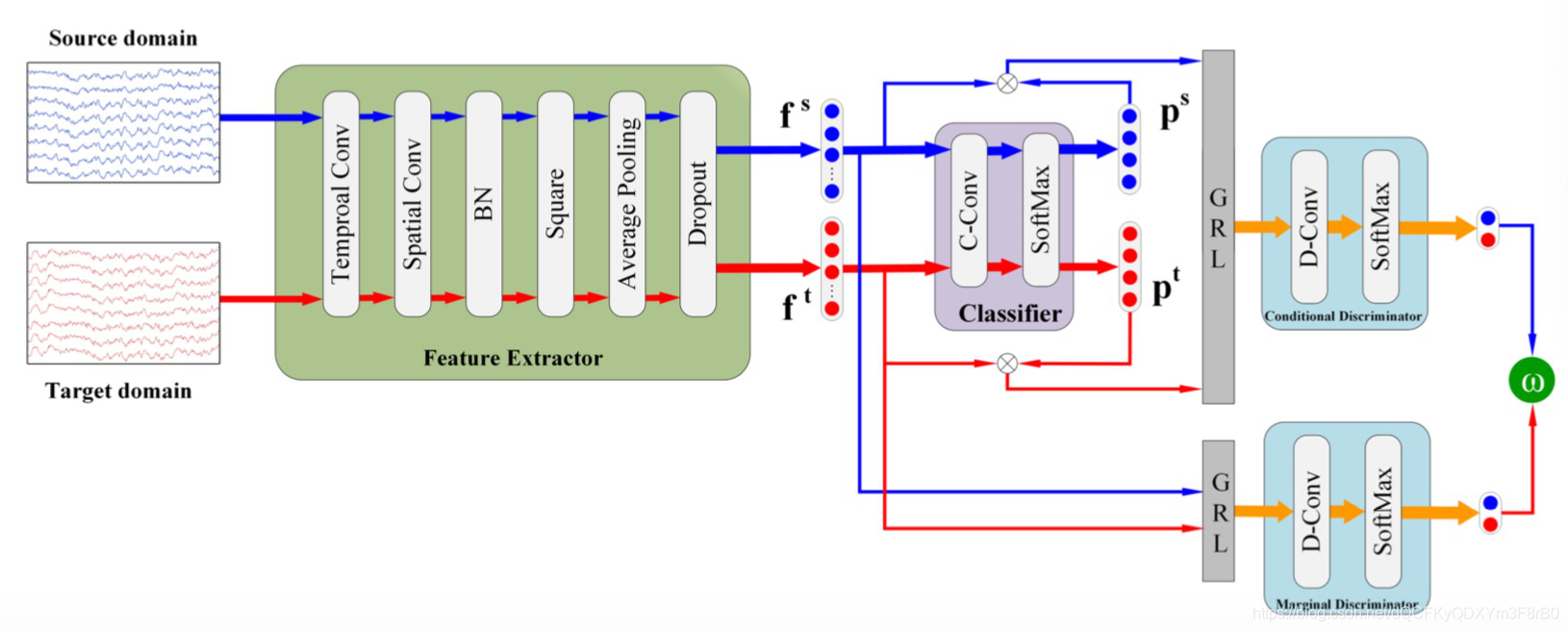
腾讯天衍实验室夺世界机器人大赛双冠军,新算法突破脑机接口瓶颈
日前,“2020世界机器人大赛-BCI脑控机器人大赛”公布成绩,腾讯天衍实验室和天津大学高忠科教授团队组成的C2Mind战队,经过多轮赛程的激烈比拼,实力入围BCI脑控机器人大赛“运动想象范式”赛题决赛,最终成功斩获技术赛“…
免费的私人代码托管(bitbucket) 和 常用git指令
转自 http://blog.csdn.net/nzing/article/details/24452475 今天想找个免费的私人代码托管平台,github,googlecode, SourceForge都不行,后来发现bitbucket(https://bitbucket.org/),注册时,如果不多于5个人…

Ajax简单示例之改变下拉框动态生成表格
1.建立一个aspx页面,html代码<html xmlns"http://www.w3.org/1999/xhtml"><head runat"server"><title>Untitled Page</title><script type"text/javascript">var xmlHttp; function createXML…

for语句内嵌例题与个人理解
例题1:画出一个高度为3的等腰三角形. 编写程序: #include<stdio.h> main() { int a,b,c,h; h3; \\h为高度,赋值常量3. for(a1;a<h;a) …

2020百度云秀最新成绩单,AI Cloud活跃客户数同比去年增长65%
12月17日,“ABC SUMMIT 2020百度云智峰会”在北京举行。大会以“智者先行”为主题,百度CTO王海峰展现了518新战略后百度智能云取得的最新成绩和产业智能化成果。“云智一体”成百度智能云独特的竞争力,在各行各业加快规模化落地。本届大会首次…
构建之法读后感part6
这个星期看完了构建之法的第六章,看了第六章之后了解到敏捷开发以用户的需求进化为核心,采用迭代、循序渐进的方法进行软件开发。在敏捷 开发中,软件项目在构建初期被切分成多个子项目,各个子项目的成果都经过测试,具备…

Ajax实现无刷新三联动下拉框
1.html代码<HTML><HEAD><title>Ajax实现无刷新三联动下拉框</title><meta content"Microsoft Visual Studio .NET 7.1"name"GENERATOR"><meta content"C#"name"CODE_LANGUAGE"><meta content&…
用算法改造过的植物肉,有兴趣试试么?
来源 | HyperAI超神经责编 | 晋兆雨头图 | CSDN 下载自视觉中国本月初,麦当劳宣布,将于 2021 年推出植物肉全新产品线 McPlant,新品品类将包括汉堡、鸡肉替代品以及早餐三明治。事实上,麦当劳并不是尝试植物基产品的首家快餐店&am…
浅谈软件自动化集成测试的流程
浅谈自动化集成测试相信从事软件测试专业的同行很早就知道了自动化的测试技术,也许大家也很想知道具体的软件自动化具体的运行实施过程。本人学识尚欠,目前无法对综合的软件自动化的测试进行阐述,但是本人通过不同的书籍对软件自动化的集成测…
web聊天室总结
前言: 最近在写一个聊天室的项目,前端写了挺多的JS(function),导致有点懵比,出了BUG,也迟迟找不到。所以昨天把写过的代码总结了一下,写成博客。 项目背景 参考博客: http://www.cnblogs.com/alex3714/articles/533763…
概率图论PGM的D-Separation(D分离)
为什么80%的码农都做不了架构师?>>> 本文大部分来自:http://www.zhujun.me/d-separation-separation-d.html 其中找了一些资料发现原文中阻塞(block)中(b)部分有出路,黑体部分修改…
CSDN湘苗培优|高起点步入职场,快人一步!
课程了解3个培养阶段结束后,让你具备:解决问题能力、交付能力、有经验。系统基础训练(阶段一)•内容:程序逻辑基础、计算机原理、操作系统工作原理、C语言(掌握内存的分配)、密码学、信息论、概…
php与Ajax实例
****************AJAX的学习要有JavaScript、HTML、CSS等基本的Web开发能力**************** [AJAX介绍] Ajax是使用客户端脚本与Web服务器交换数据的Web应用开发方法。Web页面不用打断交互流程进行重新加裁,就可以动态地更新。使用Ajax,用户可以创建…
[转]构建基于WCF Restful Service的服务
本文转自:http://www.cnblogs.com/scy251147/p/3566638.html 前言 传统的Asmx服务,由于遵循SOAP协议,所以返回内容以xml方式组织。并且客户端需要添加服务端引用才能使用(虽然看到网络上已经提供了这方面的Dynamic Proxyÿ…

Ajax使用初步
Ajax定义为“Asynchronous JavaScript XML”的简称,也就是异步的JavaScript和XML处理。从原理上看,主要是Ajax可以通过调用HttpRequest实现与服务器的异步通讯,并最终在网页中实现丰富友好的用户界面Ajax使用初步,配置步骤1.把Aj…
AI化身监工,上班还能摸鱼吗?
来源 | 人民数字FINTECH责编 | 晋兆雨头图 | CSDN 下载自视觉中国俗话说“上班摸鱼一时爽,一直摸鱼一直爽。”上班族这群“时间管理大师们”往往能在上班的时间中挤出一半的时间来摸鱼:在距离上班时间的最后一分钟打卡,午饭时间未到就打开各大…
解决“安装程序无法定位现有系统分区,也无法创建新的系统分区”的方法
使用老毛桃PE格式化C盘后安装Win7出现“安装程序无法定位现有系统分区,也无法创建新的系统分区”的错误。本文给出了我遇到该情况的解决办法,亲身经历,绝非抄袭。 在网上看了好多办法,都无效。最后竟然用下面的方法成功了: 1. 使用…
Linux 上 12 个高效的文本过滤命令
在这篇文章中,我们将会看一些 Linux 中的过滤器命令行工具。过滤器是一个程序,它从标准输入读取数据,在数据上执行操作,然后把结果写到标准输出。 因此,它可以用来以强大的方式处理信息,例如重新结构化输出…
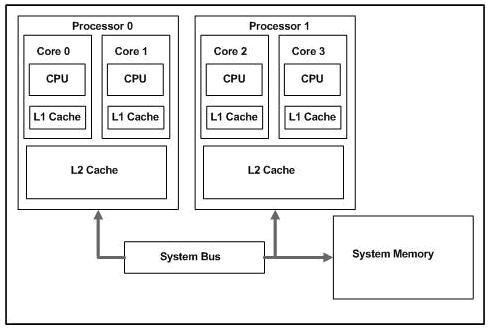
linux在多核处理器上的负载均衡原理
原文出处:http://donghao.org/uii/ 【原理】 现在互联网公司使用的都是多CPU(多核)的服务器了,Linux操作系统会自动把任务分配到不同的处理器上,并尽可能的保持负载均衡。那Linux内核是怎么做到让各个CPU的压力均匀的呢…
完全免费,简化版Plotly推出,秒绘各类可视化图表
作者 | Peter来源 | Python编程时光今天给大家推荐一个可视化神器 - Plotly_express ,上手非常的简单,基本所有的图都只要一行代码就能绘出一张非常酷炫的可视化图。以下是这个神器的详细使用方法,文中附含大量的 GIF 动图示例图。环境准备本…
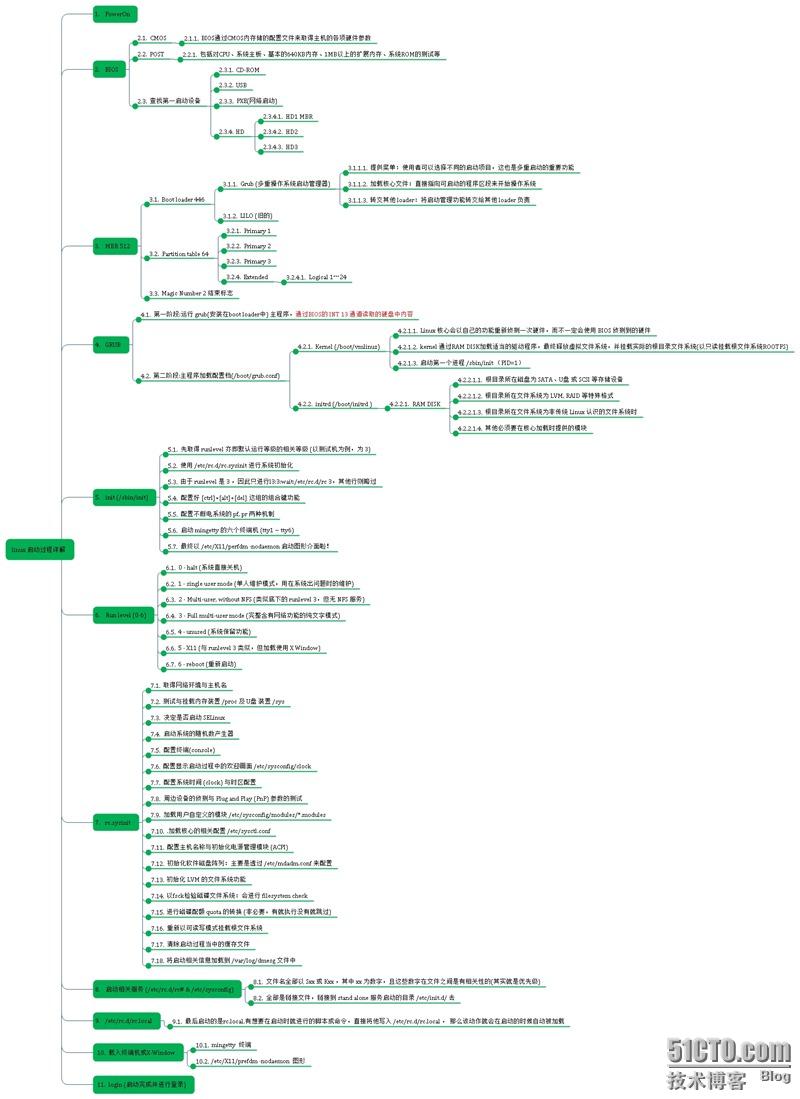
Linux 启动过程详解
说明:由于图片太大,上传博客的图片是jpg格式的有点失真,看不清楚,可以双击打开查看,有朋友想看高清,无码,无水印的大图(png格式)请下载附件!转载于:https://b…
java web项目优化记录:优化考试系统
考试系统在进行压力測试时发现,并发量高之后出现了button无反应。试题答案不能写到数据库的问题,于是针对这些核心问题,进行了优化。 数据库方面: Select语句:Select * from TEB_VB_XZTRecord改为select 必须的列 form…
深度学习中的注意力机制(三)
作者 | 蘑菇先生来源 | NewBeeNLP原创出品 深度学习Attenion小综述系列:深度学习中的注意力机制(一) 深度学习中的注意力机制(二)目前深度学习中热点之一就是注意力机制(Attention Mechanismsÿ…