linux在多核处理器上的负载均衡原理
原文出处:http://donghao.org/uii/
【原理】
现在互联网公司使用的都是多CPU(多核)的服务器了,Linux操作系统会自动把任务分配到不同的处理器上,并尽可能的保持负载均衡。那Linux内核是怎么做到让各个CPU的压力均匀的呢?
做一个负载均衡机制,重点在于:
1. 何时检查并调整负载情况?
2. 如何调整负载?
先看第一个问题。
如果让我这样的庸俗程序员来设计,我第一个想到的就是每隔一段时间检查一次负载是否均衡,不均则调整之,这肯定不是最高效的办法,但肯定是实现上最简单的。实际上,2.6.20版linux kernel的确使用软中断来定时调整多CPU上的压力(调用函数run_rebalance_domains),每秒1次。
但每秒一次还是不能满足要求,对很多应用来说,1秒太长了,一秒钟内如果发生负载失衡对很多web应用都是不能接受的,何况其他实时应用。最好kernel能够紧跟进程的变化来调整。
那么,好,我们在进程创建和进程exit的时候检查并调整负载呢?可以,但是不完整,一个进程创建以后如果频繁的睡眠、醒来、睡眠、醒来,它这样折腾对CPU的负载是有影响的,你就不管它了吗?说到底,我们其实关注的是进程是否在使用CPU,而不是它是否诞生了。所以,我们应该在进程睡眠和醒来这两个时间点检查CPU们的负载。
再看第二个问题,怎么调整负载呢?从最繁忙的那个CPU上挪一个进程到最闲的那个CPU上,如果负载还不均衡,就再挪一个进程,如果还不均衡,继续挪....这也是个最笨的方法,但它却真的是linux CPU负载均衡的核心,不过实际的算法在此基础上有很多细化。对于Intel的CPU,压缩在同一个chip上的多核是共享同一个L2的(如下图,里面的一个Processor其实就是一个chip),如果任务能尽可能的分配在同一个chip上,L2 cache就可以继续使用,这对运行速度是有帮助的。所以除非“很不均衡”,否则尽量不要把一个chip上的任务挪到其他chip上。
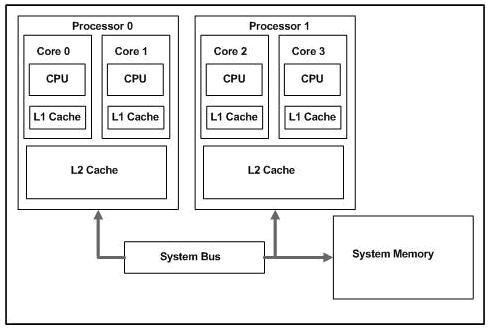
于是,为了应对这种CPU core之间的异质性——在不同的core之间迁移任务,代价不同——Linux kernel引入了sched_domain和sched_group的概念。sched_domain和sched_group的具体原理,可参考刘勃的文章和英文资料。
【代码剖析】
SMP负载均衡检查或调整在两个内核函数里发生:
1. schedule()。当进程调用了sleep、usleep、poll、epoll、pause时,也就是调用了可能睡去的操作时都会转为内核代码里对schedule()函数的调用。
2. try_to_wake_up() 。说白了就是进程刚才睡了,现在要醒来,那醒来以后跑在哪个CPU上呢?这个选择CPU的过程,也就是负载均衡的过程。
我们先看schedule()的代码,我们忽略函数前面那些和负载均衡无关的代码(本文代码以内核2.6.20版为准):
[kernel/sched.c --> schedule() ]
相关文章:
完全免费,简化版Plotly推出,秒绘各类可视化图表
作者 | Peter来源 | Python编程时光今天给大家推荐一个可视化神器 - Plotly_express ,上手非常的简单,基本所有的图都只要一行代码就能绘出一张非常酷炫的可视化图。以下是这个神器的详细使用方法,文中附含大量的 GIF 动图示例图。环境准备本…
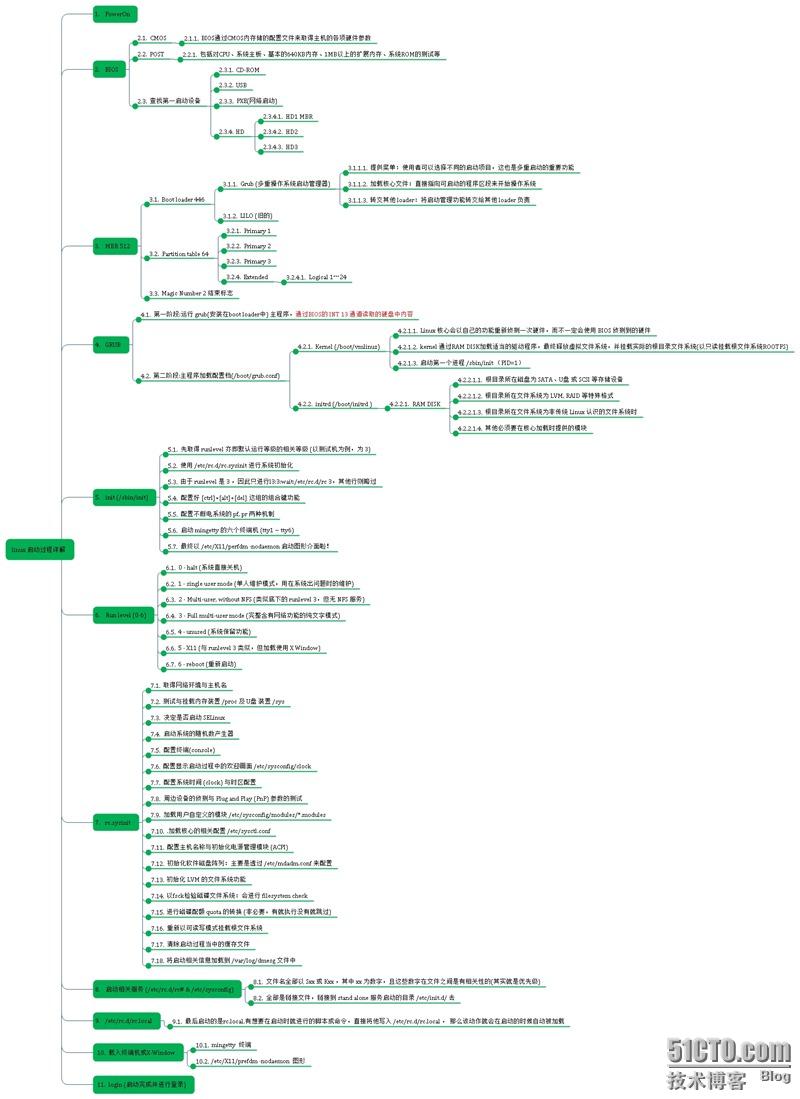
Linux 启动过程详解
说明:由于图片太大,上传博客的图片是jpg格式的有点失真,看不清楚,可以双击打开查看,有朋友想看高清,无码,无水印的大图(png格式)请下载附件!转载于:https://b…

java web项目优化记录:优化考试系统
考试系统在进行压力測试时发现,并发量高之后出现了button无反应。试题答案不能写到数据库的问题,于是针对这些核心问题,进行了优化。 数据库方面: Select语句:Select * from TEB_VB_XZTRecord改为select 必须的列 form…
深度学习中的注意力机制(三)
作者 | 蘑菇先生来源 | NewBeeNLP原创出品 深度学习Attenion小综述系列:深度学习中的注意力机制(一) 深度学习中的注意力机制(二)目前深度学习中热点之一就是注意力机制(Attention Mechanismsÿ…
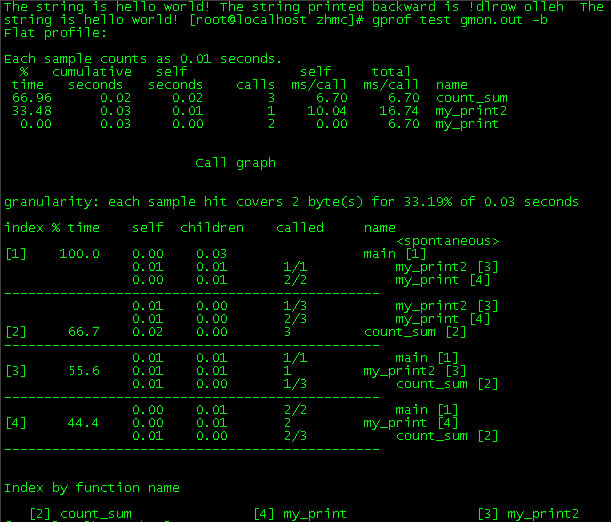
程序分析工具gprof介绍
程序分析是以某种语言书写的程序为对象,对其内部的运作流程进行分析。程序分析的目的主要有三点:一是通过程序内部各个模块之间的调用关系,整体上把握程序的运行流程,从而更好地理解程序,从中汲取有价值的内容。二是以…

hadoop源码datanode序列图
2019独角兽企业重金招聘Python工程师标准>>> 转载于:https://my.oschina.net/u/572882/blog/134796
HDU 2206 IP的计算(字符串处理)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid2206 Problem Description在网络课程上,我学到了非常多有关IP的知识。IP全称叫网际协议,有时我们又用IP来指代我们的IP网络地址,如今IPV4下用一个32位无符号整数来表示&#…
有规律格式化文本文件插入数据库
现有以下文本文件: *理光(深圳)工业发展有限公司(D15)(位于福田区)1.厨师1名;男;30岁以下;高中以上学历;中式烹调师中级以上,需备齐身份证/毕业证/流动人口婚育证明原件及复印件1份.经公司体检不合格者将不予录用,不合格者体检费自理.福利及待遇:工作时…
java使用uploadify上传文件
一、简介Uploadify是JQuery的一个上传插件,实现的效果非常不错,带进度显示;可以上传多个文件;详细的使用方法网上有很多,建议到官网参考,这里仅仅展示其使用的效果;官网:www.uploadi…

微软亚洲研究院成立OpenNetLab,探索以“数据为中心”AI网络研究新范式!
2020年12月18日,微软亚洲研究院宣布联合清华大学、北京大学、南京大学、兰州大学、新加坡国立大学、首尔国立大学等多所亚洲地区高校,成立OpenNetLab开放网络平台联盟。 OpenNetLab官网地址:https://opennetlab.org/ 通过为研究人员提供通用的…
圆角文本框的制作
把border:0px;outline:none;就可以清除边框。然后在外面放一个圆角div,文本框在div内居中的话能够,设置行高和text-align:center。或者也能够在背景图上放文本框。
微软收购 GitHub 两年后,大咖共论开源新生态
头图 | CSDN 下载自视觉中国被微软收购两年的GitHub,现在怎么样了?据《 2020 年度 GitHub Octoverse 报告》显示,GitHub 上开发者数量达到 5600 万,新增 6000 万个存储库以及 19 亿个 contribution。GitHub 预计到 2025 年&#x…
网页中如何获取客户端系统已安装的所有字体?
如何获取系统字体?1.首先在需要获取系统字体的网页<body>后加入以下代码:<DIV style"LEFT: 0px; POSITION: absolute; TOP: 0px"><OBJECT ID"dlgHelper" CLASSID"clsid:3050f819-98b5-11cf-bb82-00aa00bdce0b&q…

Web开发常见的软件架构
Web开发常见的软件架构 一、看需求分析,看产品PRD:Product Requirement Document 二、根据PRD和产品原型建数据库表,注意三范式要求,用工具到处数据库关系图,并快速地理清数据库思路 三、搭建项目架构,常用三层,自动…
thinkphp整合系列之gulp实现前端自动化
这又是一个一次整合终身受益;不止是终身;换个项目同样可以很方便复用;不信你看另一个项目: thinkphp整合系列之gulp实现前端自动化 虽然我等叫php程序猿;但是不可避免的是要跟html打交道的;而且php这么容易…

网上几种常见校验码图片分析
前几天受刺激了,准备把CSDN的校验码图片修改。就上网找了一些参考示例。和分析了一些校验码的功能。不敢独享,整理到一起,跟大家分享。 至于CSDN新的校验码写法,不是这里面的任何一种。也不是网上可以找到的。这个不好公开&#…
语言都是相通的,学好一门语言,再学第二门语言就很简单,记录一下我复习c语言的过程。...
语言都是相通的,学好一门语言,再学第二门语言就很简单,记录一下我复习c语言的过程。为了将本人的python培训提高一个层次,本人最近买了很多算法的书.这个书上的代码基本都是c语言实现的,c语言很久没有用了,…
百度飞桨全新升级:重磅推出PaddleHelix平台、开源框架V2.0RC,硬件生态路线图全公开...
12月20日,WAVE SUMMIT2020深度学习开发者峰会在北京举办。本届峰会,百度飞桨带来八大全新发布与升级,有支持前沿技术探索和应用的生物计算平台PaddleHelix螺旋桨,开发更加便捷的飞桨开源框架2.0 RC版,端云协同的AI集成…
Java解压zip文件(文本)压缩包
2019独角兽企业重金招聘Python工程师标准>>> 说明:由于我们的日志收集到指定服务器上,会按天压缩成一个zip格式的压缩包,但是有时候需要对这些日志进行处理,人工解压在处理,显示对于大量的日志处理是不行的…
Asp.Net 动态生成验证码
我们在设计用户登录模块时,经常会用到验证码,可以有效地防止黑客软件的恶意破解,现公开我常用的验证码的源代码,生成效果如图:。使用方法:1、在Web项目中添加一个类,如“CreateImage.cs”&#…
Hyper-v 3.0虚拟化平台群集共享磁盘无法failover的故障
碰到一个hyper-v 3.0虚拟化平台和HP存储的兼容性问题,放出来和大家分享一下。平台:windows server 2012 RTMhyper-v 3.0故障现象:生产虚拟平台宿主机意外重启,且重启后一块存储磁盘变成脱机状态,进一步测试发现宿主机上…
2020年中国AI算力报告发布:超大算法模型挑战之下,公共AI算力基建是关键
随着人工智能算法突飞猛进的发展,越来越多的模型训练需要巨量的算力支撑才能快速有效地实施。目前,如AlphaFold、GPT-3等模型已经逼近人工智能的算力极限,GPT-3的模型尺寸增大到了1750亿,数据量也达到了惊人的45TB。一方面&#x…

Spring中使用Log4j记录日志
以下内容引用自http://wiki.jikexueyuan.com/project/spring/logging-with-log4j.html: 例子: pom.xml: <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"x…
象 DEV-Club 那样的彩色校验码
要读懂这些代码主要是要了解ASP中操作二进制数据的对象ADODB.Stream!本程序主要用的就是Adodb.Stream,如果你有这个基础,就可以进一步添加更多的功能如加入杂点,渐变底色,数字行列错位,笔画短点,…
北斗时钟在国内各行业的应用前景
北斗时钟在国内各行业的应用前景 北斗时钟(GPS标准同步钟,GPS对时设备,北斗时间服务器)以北斗卫星信号作为时间源,同时可选GPS、IRIG-B码、OCX0、铷原子钟、CDMA信号等时钟源,对时精度达20nS。 上海锐呈电气有限公司产品采用表…
寻找长沙“科技之星”,CSDN星城大巡礼
2020年,长沙市委主要领导发出“软件产业再出发”的号召,并颁布了软件三年行动计划。今年5月,CSDN作为专业的IT社区,与长沙高新区签约,将全国总部落户长沙,这一战略决策,让CSDN与长沙的联结进一步…
DevDays2012 开发者日中文版资料下载
DevDays2012开发者日中文版资料已经上传到ADN网站,如果你是ADN会员,可以从下面地址下载:http://adn.autodesk.com/adn/servlet/item?siteID4814862&id21105549 作者:峻祁连邮箱:junqilian163.com 出处:…
对人脑而言,阅读计算机代码和阅读语言有何不同?
作者 | Anne Trafton 翻译 | 火火酱,责编 | 晋兆雨 出品 | AI科技大本营 头图 | 付费下载于视觉中国 神经科学家们发现,人类在解读代码时会激活一个通用的大脑区域网络,但不会激活语言处理中心。 就某些方面而言,学习计算机编程和学习一门新语…
如何在asp.net中动态生成验证码
现在越来越多的网站喜欢搞个验证码出来,而且各个语言基本上都能做到,今天我来一个C#写的! using System;using System.Collections;using System.ComponentModel;using System.Data;using System.Drawing;using System.Web;using System.Web…
http_build_query用法
2019独角兽企业重金招聘Python工程师标准>>> http_build_query (PHP 5) http_build_query -- 生成 url-encoded 之后的请求字符串 描述string http_build_query ( array formdata [, string numeric_prefix] ) 使用给出的关联(或下标)数组生…