深度学习中的注意力机制(三)
作者 | 蘑菇先生
来源 | NewBeeNLP原创出品
深度学习Attenion小综述系列:
深度学习中的注意力机制(一)
深度学习中的注意力机制(二)
目前深度学习中热点之一就是注意力机制(Attention Mechanisms)。Attention源于人类视觉系统,当人类观察外界事物的时候,一般不会把事物当成一个整体去看,往往倾向于根据需要选择性的去获取被观察事物的某些重要部分,比如我们看到一个人时,往往先Attend到这个人的脸,然后再把不同区域的信息组合起来,形成一个对被观察事物的整体印象。
「同理,Attention Mechanisms可以帮助模型对输入的每个部分赋予不同的权重,抽取出更加关键及重要的信息,使模型做出更加准确的判断,同时不会对模型的计算和存储带来更大的开销,这也是Attention Mechanism应用如此广泛的原因」
本部分介绍Attention机制的各种变体。包括但不限于:
「基于强化学习的注意力机制」:选择性的Attend输入的某个部分
「全局&局部注意力机制」:其中,局部注意力机制可以选择性的Attend输入的某些部分
「多维度注意力机制」:捕获不同特征空间中的Attention特征。
「多源注意力机制」:Attend到多种源语言语句
「层次化注意力机制」:word->sentence->document
「注意力之上嵌一个注意力」:和层次化Attention有点像。
「多跳注意力机制」:和前面两种有点像,但是做法不太一样。且借助残差连接等机制,可以使用更深的网络构造多跳Attention。使得模型在得到下一个注意力时,能够考虑到之前的已经注意过的词。
「使用拷贝机制的注意力机制」:在生成式Attention基础上,添加具备拷贝输入源语句某部分子序列的能力。
「基于记忆的注意力机制」:把Attention抽象成Query,Key,Value三者之间的交互;引入先验构造记忆库。
「自注意力机制」:自己和自己做attention,使得每个位置的词都有全局的语义信息,有利于建立长依赖关系。
Multi-step Attention
NIPS2017:Convolutional Sequence to Sequence Learning[1]
2017年,FaceBook Research在论文《Convolutional Sequence to Sequence Learning》提出了完全基于CNN来构建Seq2Seq模型。Motivation在于,以往的自然语言处理领域,包括 seq2seq 任务中,大多数都是通过RNN来实现。这是因为RNN的链式结构,能够很好地应用于处理序列信息。
但是,RNN也存在着劣势:一个是由于RNN运行时是将序列的信息逐个处理,不能实现并行操作,导致运行速度慢;另一个是传统的RNN并不能很好地处理句子中的结构化信息,或者说更复杂的关系信息,同时对于长语句中词依赖关系的捕捉不够好。
相比之下,CNN的优势就凸显出来。最重要的一点就是,CNN能够并行处理数据,计算更加高效。此外,CNN是层级结构,与循环网络建模的链结构相比,层次结构提供了一种较短的路径来捕获词之间远程的依赖关系,因此也可以更好地捕捉更复杂的关系, 具体而言低层的卷积网络可以捕获邻近的词之间的关系;高层的卷积网络以低层的卷积网络的输出作为输入,可以捕获远程的词之间的关系。
另外,作者在Decoder中,使用了multi-step attention,即,在 decoder 的每一个卷积层都会进行 attention 操作,并将结果输入到下一层。有点类似于人做阅读理解时,会反复去原文中寻找是否有合适的答案(且每次寻找时,理解会加深,找的更准)。当然,这种多跳机制在下文所述的End-to-End Memory Networks中实际上已经有所体现了。
直接上模型图:(英文翻译成德文,从上到下看)
Embedding Layer
word embedding+position embedding。
Convolutional Block Structure
层级的卷积块结构,通过层级叠加能够得到远距离的两个词之间的关系信息,encoder和decoder都由多层的Convolutional Block叠加而成。每层由1个Block构成,且“卷积计算+非线性计算+残差连接”看作一个Convolutional Block。
「卷积计算时」,以单词 为中心的窗口 内 个 维的embedding词全部concat在一起,得到输入 ;卷积核矩阵为 ,可以理解为每个卷积核大小为 ,一共有2d个卷积核,卷积完的输出 ;
「非线性运算时」,采用了门控结构(GLU),计算公式为: , 其中 是非线性运算, 是门控函数。也就是说上述2d个卷积核,卷积得到的前d个元素构成的向量为A,后d个元素构成的向量为B,且B作为门控函数的输入。 的输出也是d维的。
「残差连接时」(GLU的右侧),直接加上单词 的embedding得到一个Block的输出。作者为了保证卷积的输出长度和输入长度一致,添加了padding策略。这样多个Blocks可以叠加在一起。Decoder最后一层Block的输出经过softmax全连接层得到下一个词的概率。
Multi-step Attention
上面描述还未使用到Attention,只不过用多层卷积块分别提取了Encoder表示和Decoder表示,Decoder还未用到Encoder的信息。Multi-step意味着Decoder每一个卷积层都会进行Attention。
首先将Decoder经过卷积层提取到的特征表示和前一个已经预测的输出词的embedding结合在一起,
再和Encoder最后一个Block提取的特征表示 ( 是Encoder最后一个Block)求Attention(点乘+softmax),记做 。
接着计算上下文向量,除了利用 ,还利用了对应单词的embedding,则
最后将 加到Decoder的特征表示上 上(),作为Block的输出,且是Decoder下一个Block的输入。
如此,在Decoder每一个卷积层都会进行 attention 的操作,得到的结果输入到下一层卷积层,这就是多跳注意机制multi-hop attention。这样做的好处是使得模型在得到下一个注意力时,能够考虑到之前的已经注意过的词。
Attention with Pointer/Copying mechanism
NIPS2015:Pointer Networks[2]
ACL2016:Incorporating Copying Mechanism in Sequence-to-Sequence Learning[3]
ACL2017:Get To The Point: Summarization with Pointer-Generator Networks[4]
Pointer Networks
首先是“NIPS2015:Pointer Network“。作者想解决的是「输出序列语句中每个元素是离散的单词,且该元素和输入序列语句中每个位置相对应」的应用场景(an output sequence with elements that are discrete tokens corresponding to positions in an input sequence,说白了就是拷贝),如寻找凸包(比如训练的时候最多4个顶点,后来遇到10个顶点的几何图形就解决不了了)等。
这种场景的特点是,「输出序列的词汇表」会随着「输入序列长度」的改变而改变,也就是说对很多样例而言,「out-of-vocabulary」现象是经常存在的。传统的seq2seq模型无法解决该问题,因为对于这类问题,输出往往是输入集合的子集,且输出的类别词汇表是可变的。基于这种特点,作者考虑能不能找到一种结构类似编程语言中的指针,每个指针对应输入序列的一个元素,从而我们可以直接操作输入序列而不需要特意「设定」输出词汇表。
作者给出的答案是指针网络(Pointer Networks)。Pointer Networks的核心思想在于,直接将「输入序列」对应的Attention Score向量作为Pointer指针来选择输入序列的一部分作为输出,因为Attention可以衡量不同输入序列token的重要性程度(而先前的Attention Score用于加权encoder的隐状态并得到一个上下文向量用于Decoder阶段)。
总结一下,传统的带有注意力机制的seq2seq模型的运行过程是这样的,先使用encoder部分对输入序列进行编码,然后对编码后的向量做attention,最后使用decoder部分对attention后的向量进行解码从而得到预测结果。但是作为Pointer Networks,得到预测结果的方式便是输出一个概率分布,也即所谓的指针。换句话说,传统带有注意力机制的seq2seq模型输出的是针对「输出词汇表」的一个概率分布,而Pointer Networks输出的则是针对「输入文本序列」的概率分布。直接优化该概率分布的交叉熵损失即可。
接着我们先介绍下ACL2017应用Pointer Network的文章“Get To The Point: Summarization with Pointer-Generator Networks“,这篇文章略好懂一些。作者提出了Pointer-Generator模型,在传统的Attention Encoder-Decoder基础上加入了Pointer Network+Coverage技术来解决文本摘要的seq2seq模型存在的两大缺陷:
模型容易不准确地再现事实细节,也就是说模型生成的摘要不准确;
往往会重复,也就是会重复生成一些词或者句子。模型结构如下:
这里主要介绍Pointer Networks部分。作者对Pointer Networks应用的思想非常直观,就是用它来「复制」源文本中的单词。简单来说,在每一次预测的时候,通过传统seq2seq模型的预测(即softmax层的结果)可以得到针对「词汇表」的概率分布(图中绿色柱形图),然后通过Pointer Networks可以得到针对「输入序列」的概率分布(图中蓝色柱形图),对二者做并集就可以得到结合了输入文本中词汇和预测词汇表的一个概率分布(最终结果的柱形图中的“2-0”这个词不在预测词汇表中,它来自「输入文本」),这样一来模型就有可能直接从输入文本中「复制」一些词到输出结果中。
当然,直接这样操作未必会有好的结果,因此作者又加入了一个 来作为soft概率。Pgen的作用可以这样理解:决定当前预测是直接从源文本中复制一个词过来还是从词汇表中生成一个词出来,二者通过插值combine起来。
其中, 根据上下文向量,decoder层隐状态,decoder输入,经过1层MLP+sigmoid得到。 是Decoder输出层得到的词汇表中 的概率,则是对输入序列中, 词对应的attention值加起来(可能多次出现)。
Copying Mechanism
最后是ACL2016的文章“Incorporating Copying Mechanism in Sequence-to-Sequence Learning”,几乎和ACL2017文章思想一样。文章创新点包括3个部分:
预测:基于两种模式的混合概率模型预测下一个词的概率分布。包括:Generation-Mode,用来根据词汇表生成词汇,计算词汇表词的生成概率;Copy-Mode,用来直接复制「输入序列」中的一些词,计算源语句序列词被拷贝的概率。最后预测时,二者概率相加(上一篇文章根据 插值,这里直接相加)。因此,该模型具备解决OOV问题的能力。
Decoder隐状态的更新:传统的Seq2Seq模型在Decoder层计算下一个时刻的隐状态时,使用的信息包括前一时刻隐状态,attention后的上下文状态,前一时刻已经预测的输出词的embedding。而该模型中,还使用了「前一时刻已经预测的输出词在源语句Encoder中对应的特定位置的隐状态」(因为前一时刻的输出词可能是来自于源语句序列的拷贝,故在Encoder中有对应的隐状态)。
Encoder隐状态的使用方式:传统的Seq2Seq模型对于Encoder隐状态的使用只包括Attention Read,即转成attentional上下文向量在Decoder中使用,这可以看做是「Content-based Addressing」。而本文还加了一种使用方式Selective Read,也就是上述"Decoder隐状态更新"中所述,会使用前一时刻已经预测的输出词在源语句Encoder中对应的特定位置的隐状态,这种方式可以看做「Location-based Addressing」(伴随着信息的流动,下一个位置的信息在预测下一个Decoder隐状态时会被关注,因此Location-based Addressing使得模型具备拷贝源语句某个连续「子序列」的能力)。模型结构如下:
上图解读分成3部分,首先令Encoder得到的所有hidden state为矩阵 。目前要预测当前时刻的输出词 Jebara。
左侧和常规的Attention模型一致,在预测此刻输出词"Jebara"时,使用前一时刻的Decoder隐状态 和 求Attention,该Attention得分向量作为源语句每个词的概率分布(文中好像用的是 ,那这个应该是未更新前的)。
右侧下半部分,根据 ,, , 更新此刻的Decoder状态 。重点是前一时刻输出词 (Tony)除了它的embedding之外,作者还考虑了如果前一时刻的输出词是输入序列某个位置的词,例如Tony就是输入序列的词,那么利用Attention向量对这些输入词的Encoder hidden state进行加权作为对输入序列的Selective Read(此处是Tony,但是Tony可能出现多次;如果没有出现,那么这部分为空,退化为传统的方法)。然后将Tony的Embedding和Selective Read连接在一起作为 。最后一起经过LSTM/GRU得到此刻的 。
最后右侧上半部分,Decoder根据生成模式和拷贝模式计算下一个词的概率分布。词语分成3大部分,源序列输入词,词汇表词,未知词(统一设置成UNK)。下一个词概率分布:
其中,第一个式子是生成模式(g),对应右上图左侧;第二个词时拷贝模式(c),对应右上图右侧。具体不同模式词汇的概率分布都是先根据得分模型(MLP)计算不同词的得分,再进行softmax得到分布;生成模式得分模型依赖于上一步计算的 和输出词的embedding表示;拷贝模式得分模型依赖于 和输入词的hidden state(M中某列)。 所有计算情况如下图所示,图中 就是得分模型。
图中, 是源序列输入词; 是词汇表的词;unk是未知词。某个输出词可能属于上述4种情况中的一种。
Summary
本文主要对基本的Attention机制以及Attention的变体方面的工作进行了梳理。我们不难发现Attention机制简单,优雅,效果好,沟通了输入和输出之间的联系,易于推广和应用到多种多样的任务和场景中,如计算机视觉,NLP,推荐系统,搜索引擎等等。
除此之外,我们可以回顾下早期的一些奠基性的工作,注意力机制的好处在于很容易融入到其他早期的一些工作当中,来进一步提升早期成果,例如,将注意力机制引入到早期词预训练过程中,作为特征提取器,来提升预训练的效果,这在今年NLP工作中尤为突出(e.g.,BERT)。还比如,可以将注意力机制用于模型融合;或者将注意力机制引入到门限函数的设计中(e.g.,GRU中代替遗忘门等)。
总之,Attention机制的易用性和有效性,使得很容易引入到现有的很多工作中,也很容易的应用到各种各样的实际业务或场景当中。另外Attention的改进工作包括了,覆盖率(解决重复或丢失信息的问题),引入马尔科夫性质(前一时刻Attention会影响下一时刻的Attention,实际上多跳注意力能够解决该问题),引入监督学习(例如手动对齐或引入预训练好的强有力的对齐模型来解决Attention未对齐问题)等等。
参考资料
[1]NIPS2017:Convolutional Sequence to Sequence Learning:
https://arxiv.org/pdf/1705.03122.pdf
[2]NIPS2015:Pointer Networks:
https://papers.nips.cc/paper/5866-pointer-networks.pdf
[3]ACL2016:Incorporating Copying Mechanism in Sequence-to-Sequence Learning:
http://aclweb.org/anthology/P16-1154
[4]ACL2017:Get To The Point: Summarization with Pointer-Generator Networks:
https://nlp.stanford.edu/pubs/see2017get.pdf
更多精彩推荐AI化身监工,上班还能摸鱼吗?
再不参与就晚了!!2020年结束前最后一波内测福利!人人有份!
赠书 | 实现病人数据自动分析建模,Python能做的比你想象得更多
为什么苹果M1芯片这么快?
揭秘 AWS 基础架构底层运维和构建之道!
相关文章:
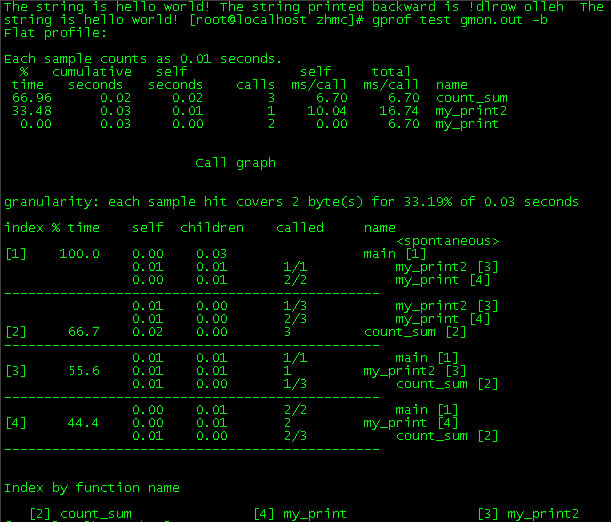
程序分析工具gprof介绍
程序分析是以某种语言书写的程序为对象,对其内部的运作流程进行分析。程序分析的目的主要有三点:一是通过程序内部各个模块之间的调用关系,整体上把握程序的运行流程,从而更好地理解程序,从中汲取有价值的内容。二是以…

hadoop源码datanode序列图
2019独角兽企业重金招聘Python工程师标准>>> 转载于:https://my.oschina.net/u/572882/blog/134796

HDU 2206 IP的计算(字符串处理)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid2206 Problem Description在网络课程上,我学到了非常多有关IP的知识。IP全称叫网际协议,有时我们又用IP来指代我们的IP网络地址,如今IPV4下用一个32位无符号整数来表示&#…
有规律格式化文本文件插入数据库
现有以下文本文件: *理光(深圳)工业发展有限公司(D15)(位于福田区)1.厨师1名;男;30岁以下;高中以上学历;中式烹调师中级以上,需备齐身份证/毕业证/流动人口婚育证明原件及复印件1份.经公司体检不合格者将不予录用,不合格者体检费自理.福利及待遇:工作时…
java使用uploadify上传文件
一、简介Uploadify是JQuery的一个上传插件,实现的效果非常不错,带进度显示;可以上传多个文件;详细的使用方法网上有很多,建议到官网参考,这里仅仅展示其使用的效果;官网:www.uploadi…

微软亚洲研究院成立OpenNetLab,探索以“数据为中心”AI网络研究新范式!
2020年12月18日,微软亚洲研究院宣布联合清华大学、北京大学、南京大学、兰州大学、新加坡国立大学、首尔国立大学等多所亚洲地区高校,成立OpenNetLab开放网络平台联盟。 OpenNetLab官网地址:https://opennetlab.org/ 通过为研究人员提供通用的…
圆角文本框的制作
把border:0px;outline:none;就可以清除边框。然后在外面放一个圆角div,文本框在div内居中的话能够,设置行高和text-align:center。或者也能够在背景图上放文本框。
微软收购 GitHub 两年后,大咖共论开源新生态
头图 | CSDN 下载自视觉中国被微软收购两年的GitHub,现在怎么样了?据《 2020 年度 GitHub Octoverse 报告》显示,GitHub 上开发者数量达到 5600 万,新增 6000 万个存储库以及 19 亿个 contribution。GitHub 预计到 2025 年&#x…
网页中如何获取客户端系统已安装的所有字体?
如何获取系统字体?1.首先在需要获取系统字体的网页<body>后加入以下代码:<DIV style"LEFT: 0px; POSITION: absolute; TOP: 0px"><OBJECT ID"dlgHelper" CLASSID"clsid:3050f819-98b5-11cf-bb82-00aa00bdce0b&q…

Web开发常见的软件架构
Web开发常见的软件架构 一、看需求分析,看产品PRD:Product Requirement Document 二、根据PRD和产品原型建数据库表,注意三范式要求,用工具到处数据库关系图,并快速地理清数据库思路 三、搭建项目架构,常用三层,自动…
thinkphp整合系列之gulp实现前端自动化
这又是一个一次整合终身受益;不止是终身;换个项目同样可以很方便复用;不信你看另一个项目: thinkphp整合系列之gulp实现前端自动化 虽然我等叫php程序猿;但是不可避免的是要跟html打交道的;而且php这么容易…

网上几种常见校验码图片分析
前几天受刺激了,准备把CSDN的校验码图片修改。就上网找了一些参考示例。和分析了一些校验码的功能。不敢独享,整理到一起,跟大家分享。 至于CSDN新的校验码写法,不是这里面的任何一种。也不是网上可以找到的。这个不好公开&#…
语言都是相通的,学好一门语言,再学第二门语言就很简单,记录一下我复习c语言的过程。...
语言都是相通的,学好一门语言,再学第二门语言就很简单,记录一下我复习c语言的过程。为了将本人的python培训提高一个层次,本人最近买了很多算法的书.这个书上的代码基本都是c语言实现的,c语言很久没有用了,…
百度飞桨全新升级:重磅推出PaddleHelix平台、开源框架V2.0RC,硬件生态路线图全公开...
12月20日,WAVE SUMMIT2020深度学习开发者峰会在北京举办。本届峰会,百度飞桨带来八大全新发布与升级,有支持前沿技术探索和应用的生物计算平台PaddleHelix螺旋桨,开发更加便捷的飞桨开源框架2.0 RC版,端云协同的AI集成…
Java解压zip文件(文本)压缩包
2019独角兽企业重金招聘Python工程师标准>>> 说明:由于我们的日志收集到指定服务器上,会按天压缩成一个zip格式的压缩包,但是有时候需要对这些日志进行处理,人工解压在处理,显示对于大量的日志处理是不行的…
Asp.Net 动态生成验证码
我们在设计用户登录模块时,经常会用到验证码,可以有效地防止黑客软件的恶意破解,现公开我常用的验证码的源代码,生成效果如图:。使用方法:1、在Web项目中添加一个类,如“CreateImage.cs”&#…
Hyper-v 3.0虚拟化平台群集共享磁盘无法failover的故障
碰到一个hyper-v 3.0虚拟化平台和HP存储的兼容性问题,放出来和大家分享一下。平台:windows server 2012 RTMhyper-v 3.0故障现象:生产虚拟平台宿主机意外重启,且重启后一块存储磁盘变成脱机状态,进一步测试发现宿主机上…
2020年中国AI算力报告发布:超大算法模型挑战之下,公共AI算力基建是关键
随着人工智能算法突飞猛进的发展,越来越多的模型训练需要巨量的算力支撑才能快速有效地实施。目前,如AlphaFold、GPT-3等模型已经逼近人工智能的算力极限,GPT-3的模型尺寸增大到了1750亿,数据量也达到了惊人的45TB。一方面&#x…

Spring中使用Log4j记录日志
以下内容引用自http://wiki.jikexueyuan.com/project/spring/logging-with-log4j.html: 例子: pom.xml: <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"x…
象 DEV-Club 那样的彩色校验码
要读懂这些代码主要是要了解ASP中操作二进制数据的对象ADODB.Stream!本程序主要用的就是Adodb.Stream,如果你有这个基础,就可以进一步添加更多的功能如加入杂点,渐变底色,数字行列错位,笔画短点,…
北斗时钟在国内各行业的应用前景
北斗时钟在国内各行业的应用前景 北斗时钟(GPS标准同步钟,GPS对时设备,北斗时间服务器)以北斗卫星信号作为时间源,同时可选GPS、IRIG-B码、OCX0、铷原子钟、CDMA信号等时钟源,对时精度达20nS。 上海锐呈电气有限公司产品采用表…
寻找长沙“科技之星”,CSDN星城大巡礼
2020年,长沙市委主要领导发出“软件产业再出发”的号召,并颁布了软件三年行动计划。今年5月,CSDN作为专业的IT社区,与长沙高新区签约,将全国总部落户长沙,这一战略决策,让CSDN与长沙的联结进一步…
DevDays2012 开发者日中文版资料下载
DevDays2012开发者日中文版资料已经上传到ADN网站,如果你是ADN会员,可以从下面地址下载:http://adn.autodesk.com/adn/servlet/item?siteID4814862&id21105549 作者:峻祁连邮箱:junqilian163.com 出处:…
对人脑而言,阅读计算机代码和阅读语言有何不同?
作者 | Anne Trafton 翻译 | 火火酱,责编 | 晋兆雨 出品 | AI科技大本营 头图 | 付费下载于视觉中国 神经科学家们发现,人类在解读代码时会激活一个通用的大脑区域网络,但不会激活语言处理中心。 就某些方面而言,学习计算机编程和学习一门新语…
如何在asp.net中动态生成验证码
现在越来越多的网站喜欢搞个验证码出来,而且各个语言基本上都能做到,今天我来一个C#写的! using System;using System.Collections;using System.ComponentModel;using System.Data;using System.Drawing;using System.Web;using System.Web…
http_build_query用法
2019独角兽企业重金招聘Python工程师标准>>> http_build_query (PHP 5) http_build_query -- 生成 url-encoded 之后的请求字符串 描述string http_build_query ( array formdata [, string numeric_prefix] ) 使用给出的关联(或下标)数组生…
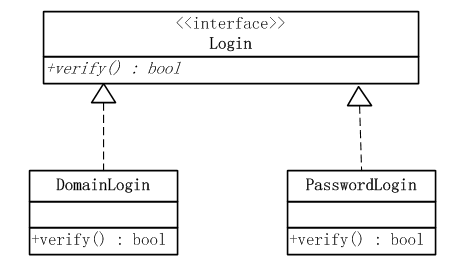
《JAVA与模式》之简单工厂模式
在阎宏博士的《JAVA与模式》一书中开头是这样描述简单工厂模式的:简单工厂模式是类的创建模式,又叫做静态工厂方法(Static Factory Method)模式。简单工厂模式是由一个工厂对象决定创建出哪一种产品类的实例。 那么简单工厂模式是…

ASP.NET MVC上传文件----uploadify的使用
课程设计需要实现上传文件模块,本来ASP.NET是有内置的控件,但是ASP.NET MVC没有,所以就有两种方法:自定义和采用第三方插件。由于时间的关系,故采用第三方插件:uploadify。 uploadify的使用必须下载相应的文件,下载地址…
QQ验证码识别源代码(C#/NET1.1)
using system; namespace qq { /// <summary> /// yzm 的摘要说明。 /// </summary> public class yzm { public yzm(public system.drawing.bitmap pic) { this.bp pic; } /// <summary> /// 将一个int值存入到4个字节的字节数组(从高地址开始…
身限辞退风波,Google AI 掌门人 Jeff Dean 不误折桂 IEEE 冯诺依曼奖
【CSDN 编者按】在 AI 圈,除了平常说的“人工智障”,“机器学习不学习”之类的,就数 Jeff Dean 的段子流传最多最广了。像什么”编译器从来不给Jeff编译警告,而是Jeff警告编译器“、“所有的指针都是指向 Jeff Dean 的”、“Jeff …