MySQL运行在docker容器中会损失多少性能
前言
自从使用docker以来,就经常听说MySQL数据库最好别运行在容器中,性能会损失很多。一些之前没使用过容器的同事,对数据库运行在容器中也是忌讳莫深,甚至只要数据库跑在容器中出现性能问题时,首先就把问题推到容器上。
那么到底会损失多少,性能损失会很多吗?
为此我装了两个MySQL,版本都是8.0.34。一个用官网二进制包安装,另一个用docker hub的MySQL镜像安装。两个MySQL都运行在同一台机器,但不同时运行,先后运行测试。测试工具用的sysbench,运行在另一台机器。
提前声明:测试流程比较简单,只是用sysbench测了混合读写场景,测试次数也较少,不具有权威性。感兴趣的话,可以自行完善测试流程。
如果对后文没什么兴趣,这里也可以直接说结论:单表百万级以下时,非容器和容器的性能差异并不多。单表千万级时,容器MySQL大概会损耗10% ~ 20%的性能。
| 应用 | 版本 | 备注 |
|---|---|---|
| Debian | 12.0 | 操作系统。4C16G |
| docker | 20.10.17 | 容器运行时 |
| MySQL(非docker) | 8.0.34 | 基于官方的二进制安装包 |
| MySQL(docker) | 8.0.34 | 使用docker hub的镜像 |
| sysbench | 1.0.20 | 压测工具 |
MySQL配置
MySQL安装后创建测试用的sysbench用户和sysbench数据库,调整innodb_buffer_pool_size为2GB。
docker容器的网络配置为bridge,挂载数据目录。
sysbench命令
- 准备数据
sysbench --db-driver=mysql --mysql-host=192.168.3.21 --mysql-port=3306 --mysql-user=sysbench --mysql-password=123456 --mysql-db=sysbench --table_size=10000000 --tables=20 --threads=4 oltp_read_write prepare
- 执行测试
sysbench --db-driver=mysql --mysql-host=192.168.3.21 --mysql-port=3306 --mysql-user=sysbench --mysql-password=123456 --mysql-db=sysbench --time=300 --threads=8 --report-interval=10 oltp_read_write run
- 清理测试数据
sysbench --db-driver=mysql --mysql-host=192.168.3.21 --mysql-port=3306 --mysql-user=sysbench --mysql-password=123456 --mysql-db=sysbench --table_size=10000000 --tables=20 --threads=4 oltp_read_write cleanup
测试结果
单表1000w数据,20张表,测试4次。
| MySQL运行环境 | 测试序列 | 总SQL执行数 | 每秒SQL数 | 每秒事务数 | 延迟时间(平均) | 延迟时间(95%) |
|---|---|---|---|---|---|---|
| 非容器 | 1 | 3798093 | 12658.84 | 632.78 | 12.64 | 20.00 |
| 非容器 | 2 | 3914578 | 13047.91 | 652.28 | 12.26 | 17.01 |
| 非容器 | 3 | 4059867 | 13531.79 | 676.46 | 11.82 | 15.55 |
| 非容器 | 4 | 3772390 | 12574.00 | 628.58 | 12.72 | 19.65 |
| 容器 | 1 | 3230678 | 10768.41 | 538.28 | 14.86 | 26.20 |
| 容器 | 2 | 3538573 | 11794.68 | 589.62 | 13.57 | 19.29 |
| 容器 | 3 | 3567943 | 11892.56 | 594.50 | 13.45 | 17.63 |
| 容器 | 4 | 3616204 | 12053.53 | 602.58 | 13.27 | 17.32 |
平均统计:
| MySQL运行环境 | 总SQL执行数 | 每秒SQL数 | 每秒事务数 | 延迟时间(平均) | 延迟时间(95%) |
|---|---|---|---|---|---|
| 非容器 | 3,886,232 | 12,953.14 | 647.53 | 12.36 | 18.05 |
| 容器 | 3,488,350 | 11,627.3 | 581.25 | 13.79 | 20.11 |
| 环比 | -10.24% | -10.24% | -10.24% | +11.57% | +11.41% |
在测千万级数据量之前,测过几轮几十万级的数据量,非容器和容器版的MySQL并没有多大区别。当数据量逐渐增多时,差异就愈加明显。目前测单表1000w已经出现10%左右的性能损耗,如果单表数据继续增大,性能损耗应该也会更多。
相关文章:

【Docker】Docker与Kubernetes:区别与优势对比
一种革新性的容器技术一、Docker与Kubernetes简介二、架构和部署模型1. Docker 部署模型2. 构建 Docker 镜像3. 运行容器4. 编排工具三、可移植性和可扩展性1. 可移植性(Portability):2. 可扩展性(Scalability):四、管理和编排能力五、生态系统和社区支持
微信小程序完整实现微信支付功能(SpringBoot和小程序)
然后到提供前端调用支付路由的类,WechatController类,注意我这里路由拼接的有/wechat/pay/notify,这个要和之前配置yml文件的支付回调函数一样,要不然不行。不久前给公司实现支付功能,折腾了一阵子,终于实现了,微信支付对于小白来说真的很困难,特别是没有接触过企业级别开发的大学生更不用说,因此尝试写一篇我如何从小白实现微信小程序支付功能的吧,使用的后端是SpringBoot。效果如下,这里因为我的手机不能截图支付页面,所以用的开发者工具支付的效果,都是一样的。4.前端(小程序端)

IT行业哪个方向比较好就业?
文章浏览阅读12次。在IT行业中,就业前景好的方向有很多,以下是一些比较热门的:
通过内网穿透本地MariaDB数据库,实现在公网环境下使用navicat图形化工具
文章浏览阅读113次,点赞50次,收藏40次。cpolar安装成功后,双击打开cpolar【或者在浏览器上访问本地9200端口 127.0.0.1:9200】,使用cpolar邮箱账号登录 web UI管理界面,如果还没有注册cpolar账号的话,点击免费注册,会跳到cpolar官网注册一个账号就可以了.在浏览器上访问9200端口,http://127.0.0.1:9200/,登录cpolar web ui管理界面,点击左侧仪表盘的隧道管理——隧道列表,找到mariaDB隧道,点击右侧的编辑。修改隧道信息,将保留成功的固定tcp地址配置到隧道中。

MySQL数据库索引以及使用唯一索引实现幂等性
一次和多次请求某一个资源对于资源本身应该具有同样的结果任意多次执行对资源本身所产生的影响均与一次执行的影响相同。

PVE 下虚拟机 Ubuntu 无法进入恢复模式的解决方案——提取原有系统文件
问题说明 某天重启虚拟机 Ubuntu,发现虚拟机只有容器IP,桥接的接口在虚拟机显示状态为 DOWN: 想重启进入恢复模式,却发现恢复模式一直花屏,无法使用: 没有办法了,只能想办法提取原有系统内原有文件。 解决方案 定位虚拟机编号: 找到虚拟机主硬盘: SSH 登录宿主机,执行以下命令 ls -

Nginx 核心配置文 nginx.conf介绍
文章浏览阅读38次。我们都知道浏览器中可以显示的内容有HTML、XML、GIF等种类繁多的文件、媒体等资源,浏览器为了区分这些资源,就需要使用MIME Type。所以说MIME Type是网络资源的媒体类型。Nginx作为web服务器,也需要能够识别前端请求的资源类型。在Nginx的配置文件中,默认有两行配置:用来配置Nginx响应前端请求默认的MIME类型。语法默认值位置在default_type之前还有一句。

如何快速本地搭建悟空CRM结合内网穿透工具高效远程办公
如何快速本地搭建悟空CRM结合内网穿透工具高效远程办公。

Kafka 集群如何实现数据同步?
哈喽大家好,我是咸鱼 最近这段时间比较忙,将近一周没更新文章,再不更新我那为数不多的粉丝量就要库库往下掉了 T﹏T 刚好最近在学 Kafka,于是决定写篇跟 Kafka 相关的文章(文中有不对的地方欢迎大家指出) 考虑到有些小伙伴可能是第一次接触 Kafka ,所以先简单介绍一下什么是 Kafka
使用 Hexo 搭建个人博客并部署到云服务器
目录1 整体流程2. 本地环境准备2.1 安装 Node.js 和 Git2.2 安装 Hexo3. 服务端环境准备3.1 Nginx 环境配置3.1.1 安装 Nginx3.1.2 更改 Nginx 配置文件3.2 Node.js 环境配置3.3 Git 环境配置3.3.1 安装 Git3.3.2
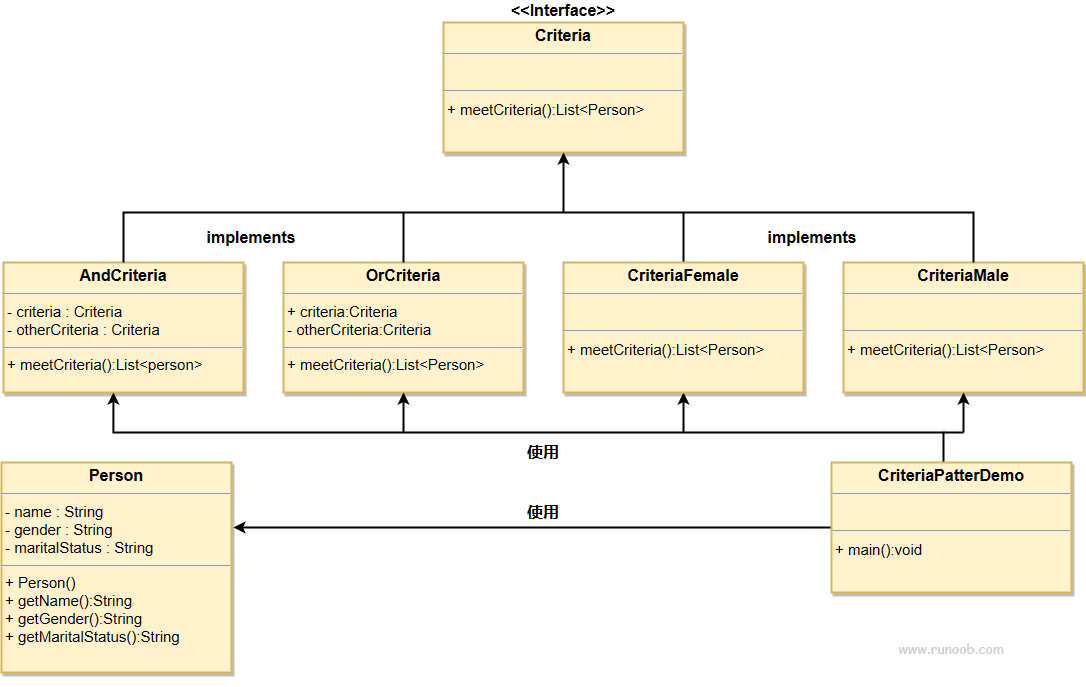
过滤器模式 rust和java的实现
文章浏览阅读301次。我们将创建一个 Person 对象、Criteria 接口和实现了该接口的实体类,来过滤 Person 对象的列表。我们制作一个Person实体类,Criteria为标准条件,CriteriaMale等为实现的具体判断器,是需要为person类使用meetCriteria方法便可以进行不同条件的判断。我们制作一个Person实体类,Criteria为标准条件,CriteriaMale等为实现的具体判断器,是需要为person类使用meetCriteria方法便可以进行不同条件的判断。

python最流行的适合计算积分和微分方程的库
SciPy有一个子模块scipy.integrate,包含多种数值积分方法,如牛顿哥特法(quad)、梯形法(trapz)、辛普森法(simps)等

c语言如何生成随机数以及设置随机数的范围
这篇文章介绍c语言如何生成随机数以及设置随机数的范围。本文主要介绍了rand函数、srand函数、以及time函数和时间戳的概念和如何控制随机数的范围。下一篇文章将介绍利用随机数和循环来写一个猜数字游戏。

Java虚拟机的垃圾回收机制
在Java语言中不再被任何引用所指向的对象被称为垃圾,这也是非常容易理解的,因为我们在对对象进行创建时,就需要给出一个对象引用变量用于指向我们在堆内存中创建的对象,所以如果一个对象没有被任何引用变量所指向的话,那么我们也就获取不到对象,也就没有办法对对象进行操作,这个对象自然就成了垃圾。引用计数算法判断对象是否为垃圾时比较方便快捷只是根据计数器中的值进行判断,但是会在每个对象的对象头中添加属性占用额外的空间,并且引用变量每一次指向对象都需要对对象的属性进行更新操作,占用大量的时间。为什么需要回收垃圾?
require()、import、import()有哪些区别?
require()、import、import()是我们常用的引入模块的三种方式,代码中几乎处处用到。如果对它们存在模糊,就会在工作过程中不断产生困惑,更无法做到对它们的使用挥洒自如。今天我们来一起捋一下,它们之间有哪些区别? 一、前世今生 学一个东西,先弄清楚它为什么会出现、它的发展历史、它是做什

如何保护电动汽车充电站免受网络攻击
文章浏览阅读228次。从电动汽车、传感器、充电站和支持基础设施的设计阶段开始就强调安全性作为首要任务。
Vite4+Typescript+Vue3+Pinia 从零搭建(3) - vite配置
项目代码同步至码云 weiz-vue3-template 关于vite的详细配置可查看 vite官方文档,本文简单介绍vite的常用配置。 初始内容 项目初建后,vite.config.ts 的默认内容如下: import { defineConfig } from 'vite' i
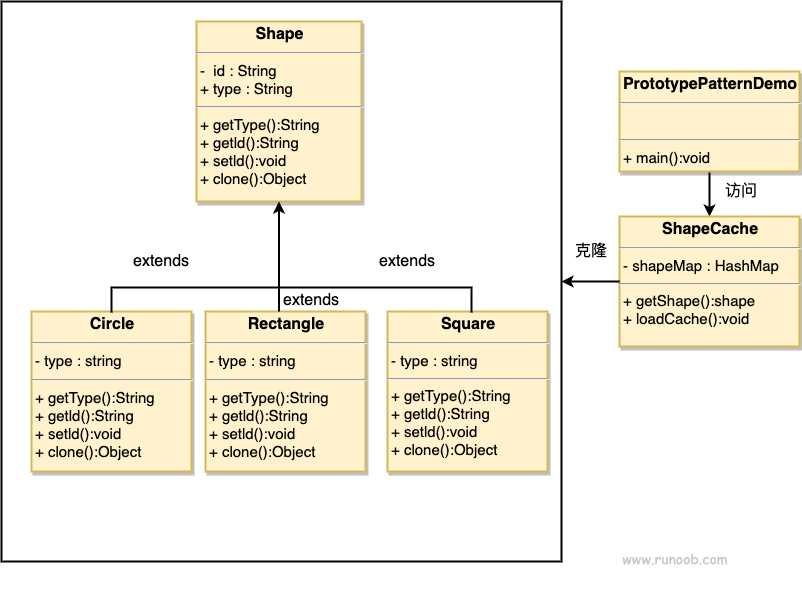
原型模式 rust和java的实现
文章浏览阅读218次。意图:用原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象。主要解决:在运行期建立和删除原型。何时使用: 1、当一个系统应该独立于它的产品创建,构成和表示时。2、当要实例化的类是在运行时刻指定时,例如,通过动态装载。3、为了避免创建一个与产品类层次平行的工厂类层次时。4、当一个类的实例只能有几个不同状态组合中的一种时。建立相应数目的原型并克隆它们可能比每次用合适的状态手工实例化该类更方便一些。如何解决:利用已有的一个原型对象,快速地生成和原型对象一样的实例。关键代码。
c语言const修饰变量与assert断言详解
const修饰变量与assert断言详解,const修饰变量。作用:const用于修饰变量使其不能再被修改。

Linux如何修改主机名(hostname)(亲测可用)
文章浏览阅读1k次。要想在虚拟机的 Linux 系统内部改变主机名(hostname),需要通过系统的配置来修改。文件,将其中引用旧主机名的条目更新为新主机名。文件,并将里面的内容替换为新主机名。但是大多数情况可能无需更改,除非在。文件里做了什么硬编码骚操作🤣。替换为想要设置的新主机名。或者使用文本编辑器手动编辑。需要重新设置主机名。

Linux下内网穿透实现云原生观测分析工具的远程访问
夜莺监控是一款开源云原生观测分析工具,采用 All-in-One 的设计理念,集数据采集、可视化、监控告警、数据分析于一体,与云原生生态紧密集成,提供开箱即用的企业级监控分析和告警能力。夜莺于 2020 年 3 月 20 日,在 github 上发布 v1 版本,已累计迭代 100 多个版本。本地部署后,为解决无法远程访问的难题,今天我们介绍如何实现让本地nightingale 结合cpolar 内网穿透工具实现 远程也可以访问,提高运维效率.
Java Lambda 表达式笔记
文章浏览阅读71次。Lambda 表达式,也可称为闭包.Lambda 允许把函数作为一个方法的参数(函数作为参数传递进方法中)。

JavaScript中如何终止forEach循环?
在JavaScript中,forEach方法是用于遍历数组的,通常没有直接终止循环的机制。然而,我们可以使用一些技巧来模拟终止forEach循环。以下是几种常见的方法

Docker本地部署Drupal并实现公网访问
文章浏览阅读498次,点赞35次,收藏33次。Dupal是一个强大的CMS,适用于各种不同的网站项目,从小型个人博客到大型企业级门户网站。它的学习曲线可能相对较陡,但一旦熟悉了它的工作方式,用户就能够充分利用其功能和灵活性。在本文中,我们将介绍如何使用Docker快速部署Drupal,并且结合cpolar内网穿透工具实现公网远程访问首先,您需要在您的机器上安装Docker,并且启动,可以按照Docker官方文档中的说明进行安装。
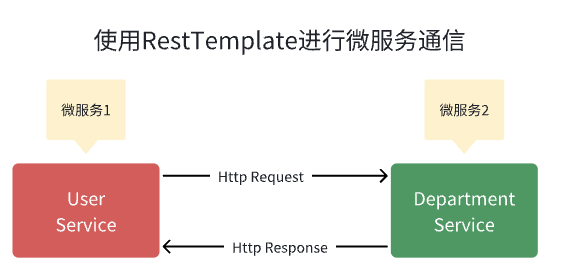
如何使用 RestTemplate 进行 Spring Boot 微服务通信示例
概述 下面我们将学习如何创建多个 Spring boot 微服务以及如何使用 RestTemplate 类在多个微服务之间进行同步通信。 微服务通信有两种风格: 同步通讯 异步通信 同步通讯 在同步通信的情况下,客户端发送请求并等待服务的响应。这里重要的一点是协议(HTTP/HTTPS)是同步的,客

win10 通过wmic命令行设置系统环境变量
而通过编程修改系统环境变量,需要调用注册表API或调用wmi API接口,都有些过于麻烦。此时,如果通过system函数,直接调用批处理文件,则只需要一行代码。批处理中,分别给出了创建环境变量,修改环境变量,删除环境变量的demo。可以根据需要调整批处理文件。在系统维护或编写程序过程中,经常需要对系统环境变量进行设置、修改、删除炒作。注:修改系统环境变量,需要有管理员权限。
c#操作mongodb数据库工具类
新建c#项目,在nuget中引入MongoDB.Driver驱动,然后新建一个MongoDBToolHelper类,将下面代码复制进去 using MongoDB.Bson; using MongoDB.Bson.Serialization; using MongoDB.Driver; using

Redis查看集群状态有节点显示fail,连接失败
现有6台redis,为集群,3主3从,由于两台服务器故障重装系统之后进行重新安装2台redis,安装完成之后。查询当前redis状态,发现有存留的节点,但连接为fai。将新建的两台redis启动,保证配置文件一致。查询fail节点的node_id。将新建的两台redis设为从节点。登录新建的两台redis服务器。先通过ID删掉无用的节点。

SpringBoot整合Kafka (二)
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景,比如基于hadoop的批处理系统、低延迟的实时系统、Storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,用scala语言编写,Linkedin于2010年贡献给了Apache基金会并成为顶级开源 项目。

SpringBoot整合Kafka (一)
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景,比如基于hadoop的批处理系统、低延迟的实时系统、Storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,用scala语言编写,Linkedin于2010年贡献给了Apache基金会并成为顶级开源 项目。