SpringBoot整合Kafka (一)

目录
文章目录
一、介绍
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景,比如基于hadoop的批处理系统、低延迟的实时系统、Storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,用scala语言编写,Linkedin于2010年贡献给了Apache基金会并成为顶级开源 项目
二、主要功能
1.消息系统: Kafka 和传统的消息系统(也称作消息中间件)都具备系统解耦、冗余存储、流量削峰、缓冲、异步通信、扩展性、可恢复性等功能。与此同时,Kafka 还提供了大多数消息系统难以实现的消息顺序性保障及回溯消费的功能。
2.存储系统: Kafka 把消息持久化到磁盘,相比于其他基于内存存储的系统而言,有效地降低了数据丢失的风险。也正是得益于 Kafka 的消息持久化功能和多副本机制,我们可以把 Kafka 作为长期的数据存储系统来使用,只需要把对应的数据保留策略设置为“永久”或启用主题的日志压缩功能即可。
3.日志收集:一个公司可以用Kafka收集各种服务的log,通过kafka以统一接口服务的方式开放给各种\nconsumer,例如hadoop、Hbase、Solr等。
三、Kafka基本概念
kafka是一个分布式的,分区的消息(官方称之为commit log)服务。它提供一个消息系统应该具备的功能,但是确有着独特的设计。首先,让我们来看一下基础的消息(Message)相关术语:
Broker
消息中间件处理节点,一个Kafka节点就是一个broker,一 个或者多个Broker可以组成一个Kafka集群
Topic
Kafka根据topic对消息进行归类,发布到Kafka集群的每条 消息都需要指定一个topic
Producer
消息生产者,向Broker发送消息的客户端 Consumer 消息消费者,从Broker读取消息的客户端
ConsumerGroup
每个Consumer属于一个特定的Consumer Group,一条消息可以被多个不同的Consumer Group消费,但是一个ConsumerGroup中只能有一个Consumer能够消费该消息
Partition
物理上的概念,一个topic可以分为多个partition,每个 partition内部消息是有序的
四、Spring Boot整合Kafka的demo
1、构建项目
1.1、引入依赖
<dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> </dependency>
1.2、YML配置
spring: kafka: bootstrap-servers: 192.168.147.200:9092 # 设置 Kafka Broker 地址。如果多个,使用逗号分隔。 producer: # 消息提供者key和value序列化方式 key-serializer: org.apache.kafka.common.serialization.StringSerializer value-serializer: org.apache.kafka.common.serialization.StringSerializer retries: 3 # 生产者发送失败时,重试发送的次数 consumer: # 消费端反序列化方式 key-deserializer: org.apache.kafka.common.serialization.StringDeserializer value-deserializer: org.apache.kafka.common.serialization.StringDeserializer group-id: demo # 用来唯一标识consumer进程所在组的字符串,如果设置同样的group id,表示这些processes都是属于同一个consumer group,默认:""
1.3、生产者简单生产
@Autowired private KafkaTemplate kafkaTemplate; @Test void contextLoads() { ListenableFuture listenableFuture = kafkaTemplate.send("test01-topic", "Hello Wolrd test"); System.out.println("发送完成"); }
1.4、消费者简单消费
@Component public class TopicConsumer { @KafkaListener(topics = "test01-topic") public void readMsg(String msg){ System.out.println("msg = " + msg); } }
2、生产者\n\n
2.1、Kafka生产者消息监听
@Component public class KafkaSendResultHandler implements ProducerListener { private static final Logger log = LoggerFactory.getLogger(KafkaSendResultHandler.class); @Override public void onSuccess(ProducerRecord producerRecord, RecordMetadata recordMetadata) { log.info("Message send success : " + producerRecord.toString()); } @Override public void onError(ProducerRecord producerRecord, Exception exception) { log.info("Message send error : " + producerRecord.toString()); } }
2.2、生产者写入分区策略
我们知道,kafka中每个topic被划分为多个分区,那么生产者将消息发送到topic时,具体追加到哪个分区呢?这就是所谓的分区策略,Kafka 为我们提供了默认的分区策略,同时它也支持自定义分区策略。
指定写入分区
100条数据全部写入到2号分区
for (int i = 0; i < 100; i++) { ListenableFuture listenableFuture = kafkaTemplate.send("demo03-topic",2,null, "toString"); listenableFuture.addCallback(new ListenableFutureCallback() { @Override public void onFailure(Throwable ex) { System.out.println("发送失败"); } @Override public void onSuccess(Object result) { SendResult sendResult = (SendResult) result; int partition = sendResult.getRecordMetadata().partition(); String topic = sendResult.getRecordMetadata().topic(); System.out.println("topic:"+topic+",分区:" + partition); } }); Thread.sleep(1000); }
根据key写入分区
String key = "kafka-key"; System.out.println("根据key计算分区:" + (key.hashCode() % 3)); for (int i = 0; i < 10; i++) { ListenableFuture listenableFuture = kafkaTemplate.send("demo03-topic", key, "toString"); listenableFuture.addCallback(new ListenableFutureCallback() { @Override public void onFailure(Throwable ex) { System.out.println("发送失败"); } @Override public void onSuccess(Object result) { SendResult sendResult = (SendResult) result; int partition = sendResult.getRecordMetadata().partition(); String topic = sendResult.getRecordMetadata().topic(); System.out.println("topic:" + topic + ",分区:" + partition); } }); Thread.sleep(1000); }
随机选择分区
for (int i = 0; i < 10; i++) { ListenableFuture listenableFuture = kafkaTemplate.send("demo03-topic", "toString"); listenableFuture.addCallback(new ListenableFutureCallback() { @Override public void onFailure(Throwable ex) { System.out.println("发送失败"); } @Override public void onSuccess(Object result) { SendResult sendResult = (SendResult) result; int partition = sendResult.getRecordMetadata().partition(); String topic = sendResult.getRecordMetadata().topic(); System.out.println("topic:" + topic + ",分区:" + partition); } }); Thread.sleep(1000); }
2.3、带回调的生产者
kafkaTemplate提供了一个回调方法addCallback,我们可以在回调方法中监控消息是否发送成功 或 失败时做补偿处理
for (int i = 0; i < 100; i++) { ListenableFuture listenableFuture = kafkaTemplate.send("demo03-topic",2,null, "toString"); listenableFuture.addCallback(new ListenableFutureCallback() { @Override public void onFailure(Throwable ex) { System.out.println("发送失败"); } @Override public void onSuccess(Object result) { SendResult sendResult = (SendResult) result; int partition = sendResult.getRecordMetadata().partition(); String topic = sendResult.getRecordMetadata().topic(); System.out.println("topic:"+topic+",分区:" + partition); } }); Thread.sleep(1000); }
以上是简单的Spring Boot整合kafka的示例,可以根据自己的实际需求进行调整。
相关文章:

Rust XTask 模式介绍与应用
XTask(扩展任务)是一种在Rust项目中定义和执行自定义构建任务的方式。它通过创建一个独立的Rust库或二进制项目来封装这些任务,利用Rust语言的强类型、安全性和跨平台能力,使得构建流程更加健壮、可读和可维护。
spring.factories文件的作用
即spring.factories文件是帮助spring-boot项目包以外的bean(即在pom文件中添加依赖中的bean)注册到spring-boot项目的spring容器中。在Spring Boot启动时,它会扫描classpath下所有的spring.factories文件,加载其中的自动配置类,并将它们注入到Spring ApplicationContext中,使得项目能够自动运行。spring.factories文件是Spring Boot自动配置的核心文件之一,它的作用是。

7min到40s:SpringBoot 启动优化实践
然后重点排查这些阶段的代码。先看下。

SpringBoot系列教程之Bean之指定初始化顺序的若干姿势
之前介绍了@Order注解的常见错误理解,它并不能指定 bean 的加载顺序,那么问题来了,如果我需要指定 bean 的加载顺序,那应该怎么办呢?本文将介绍几种可行的方式来控制 bean 之间的加载顺序。

SpringBoot接口防抖(防重复提交)的一些实现方案
作为一名老码农,在开发后端Java业务系统,包括各种管理后台和小程序等。在这些项目中,我设计过单/多租户体系系统,对接过许多开放平台,也搞过消息中心这类较为复杂的应用,但幸运的是,我至今还没有遇到过线上系统由于代码崩溃导致资损的情况。这其中的原因有三点:一是业务系统本身并不复杂;二是我一直遵循某大厂代码规约,在开发过程中尽可能按规约编写代码;三是经过多年的开发经验积累,我成为了一名熟练工,掌握了一些实用的技巧。啥是防抖所谓防抖,一是防用户手抖,二是防网络抖动。
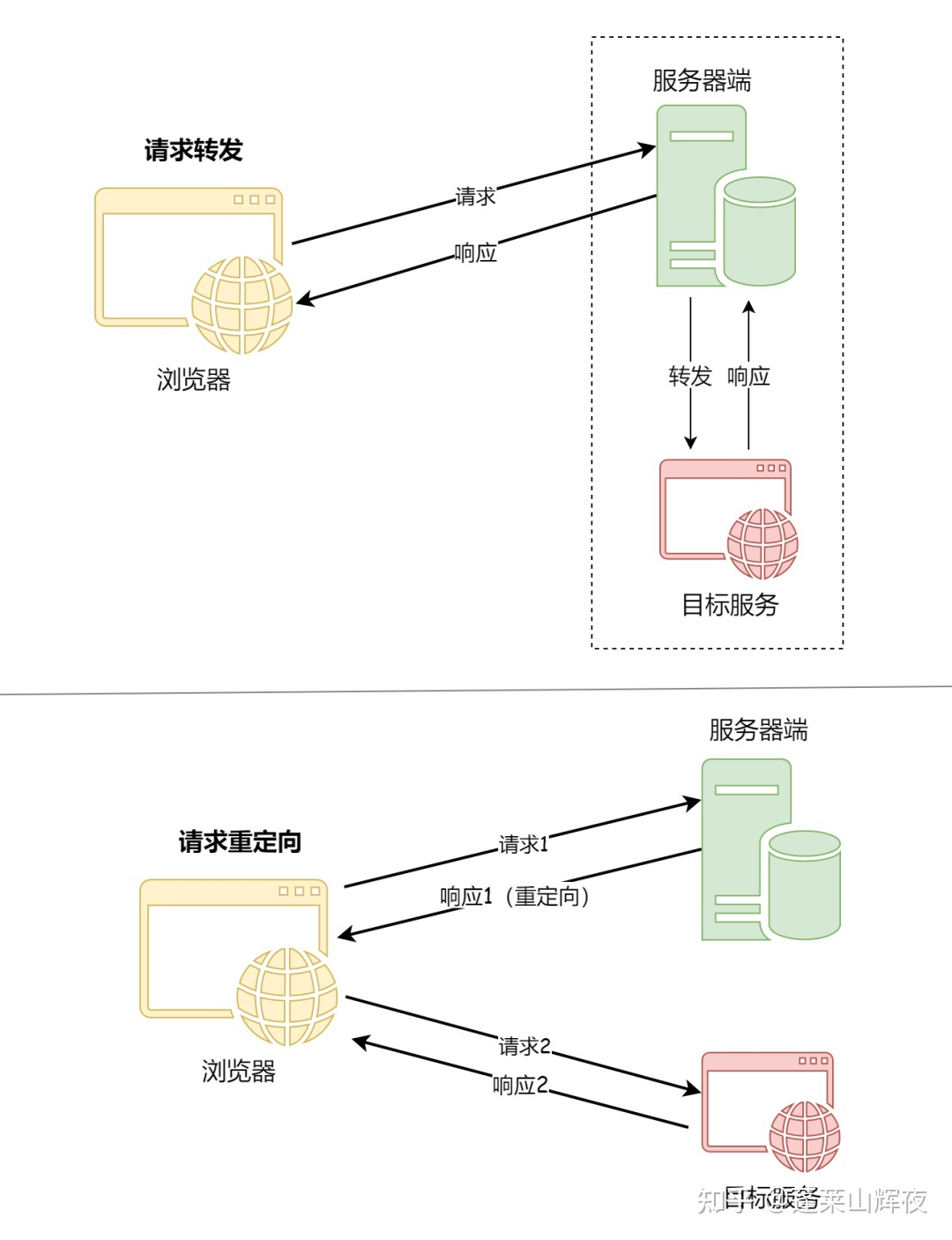
SpringBoot请求转发与重定向
但是可能由于B网址相对于A网址过于复杂,这样搜索引擎就会觉得网址A对用户更加友好,因而在重定向之后任然显示旧的网址A,但是显示网址B的内容。在平常使用手机的过程当中,有时候会发现网页上会有浮动的窗口,或者访问的页面不是正常的页面,这就可能是运营商通过某种方式篡改了用户正常访问的页面。重定向,是指在Nginx中,重定向是指通过修改URL地址,将客户端的请求重定向到另一个URL地址的过程,Nginx中实现重定向的方式有多种,比如使用rewrite模块、return指令等。使用场景:在返回视图的前面加上。

SpringBoot 中实现订单30分钟自动取消的策略
在电商和其他涉及到在线支付的应用中,通常需要实现一个功能:如果用户在生成订单后的一定时间内未完成支付,系统将自动取消该订单。本文将详细介绍基于Spring Boot框架实现订单30分钟内未支付自动取消的几种方案,并提供实例代码。
SpringBoot 优雅实现超大文件上传,通用方案
通俗的说,你把要上传的东西上传,服务器会先做MD5校验,如果服务器上有一样的东西,它就直接给你个新地址,其实你下载的都是服务器上的同一个文件,想要不秒传,其实只要让MD5改变,就是对文件本身做一下修改(改名字不行),例如一个文本文件,你多加几个字,MD5就变了,就不会秒传了。分片上传,就是将所要上传的文件,按照一定的大小,将整个文件分隔成多个数据块(我们称之为Part)来进行分别上传,上传完之后再由服务端对所有上传的文件进行汇总整合成原始的文件。
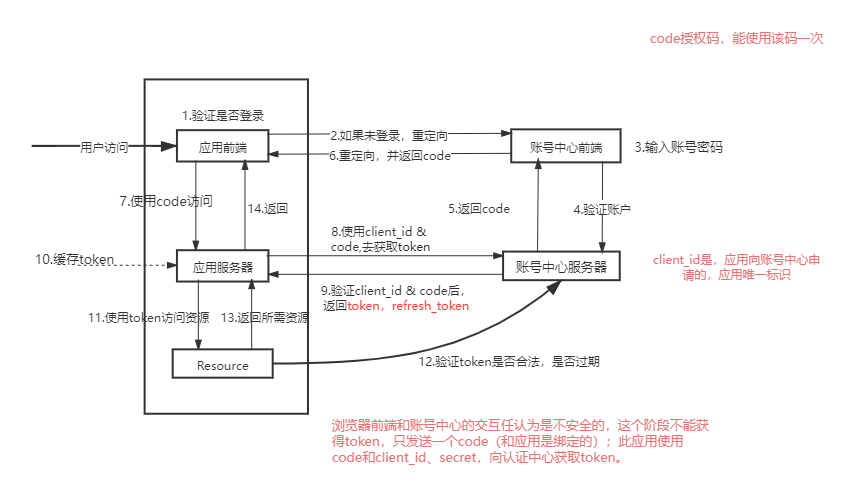
Springboot + oauth2 单点登录 - 原理篇
OAuth 协议为用户资源的授权提供了一个安全的、开放而又简易的标准,允许用户授权第三方移动应用访问他们存储在另外的服务提供者上的信息,而不需要将用户名和密码提供给第三方移动应用或分享他们数据的所有内容,OAuth2.0是OAuth协议的延续版本,但不向后兼容OAuth 1.0即完全废止了OAuth1.0。授权码模式(authorization code)密码模式(resource owner password credentials)客户端模式(client credentials) 不常用。
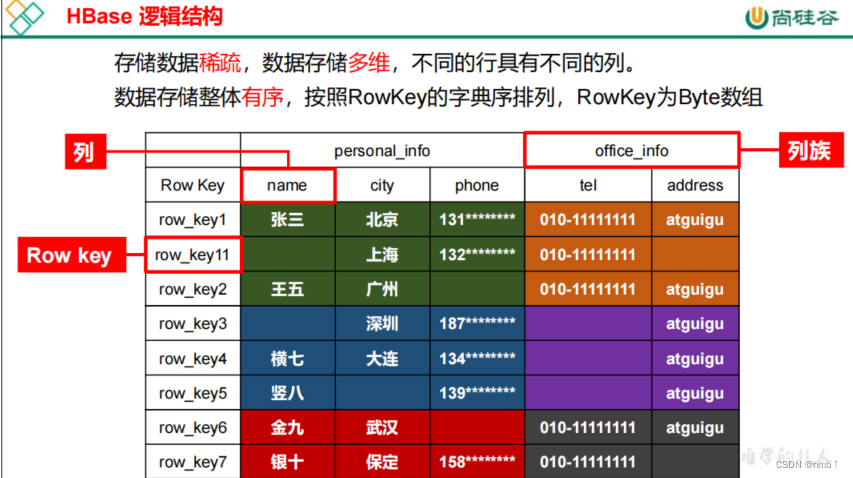
Springboot整合HBase——大数据技术之HBase2.x
Apache HBase 是以hdfs为数据存储的,一种分布式、可扩展的noSql数据库。是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。HBase使用与BigTable(BigTable是一个稀疏的、分布式的、持久化的多维排序map)非常相似的数据模型。用户将数据行存储在带标签的表中。数据行具有可排序的键和任意数量的列。该表存储稀疏,因此如果用户喜欢,同一表中的行可以具有疯狂变化的列。

Docker部署SpringBoot项目详细部署过程
Docker可比喻成一个装应用的容器,将应用及其依赖文件、数据等打包在容器内,直接运行容器即可把应用运行起来,而无需关心环境配置问题。 本文记录个人学习Docker的总结内容,安装、配置和部署等内容,在过程中,应注意命令不要写错,加上Docker插件等问题,若出现理解不到位的地方,请多指出。

spring和springboot、springMVC有什么区别?
今天来聊一下,刚在面试中被问到的一个经典问题Spring 提供了广泛的功能用于企业级应用开发Spring Boot 简化了 Spring 应用的开发和部署Spring MVC 则是专注于构建 Web 应用的 MVC 框架在使用时,你可以根据项目需求选择合适的组件或组合使用它们。在很多现代的 Spring 应用中,特别是微服务架构中,Spring Boot 和 Spring MVC 经常一起使用。好了,以上就是本文的全部内容,如有问题欢迎留言讨论。
Spring AOP 技术实现原理
Spring AOP的实现基于代理模式,通过代理对象来包装目标对象,实现切面逻辑的注入。通过本文,我们深入了解了Spring AOP是如何基于JDK动态代理和CGLIB代理技术实现的。通过详细的示例演示,希望读者能更清晰地理解Spring AOP的底层原理,并在实际项目中灵活应用这一强大的技术。
Spring Boot整合日期转换器(Converter)和拦截器(HandlerInterceptor)
配置文件形式针对框架进行个性化定制,例如:拦截器,类型转化器等等。WebMvcConfigurer配置类其实是。内部的一种配置方式,采用。
Java基本数据类型/包装类/对象/数组默认值
不管程序有没有显示的初始化,Java 虚拟机都会先自动给它初始化为默认值。1、整数类型(byte、short、int、long)的基本类型变量的默认值为0。2、单精度浮点型(float)的基本类型变量的默认值为0.0f。3、双精度浮点型(double)的基本类型变量的默认值为0.0d。4、字符型(char)的基本类型变量的默认为 “/u0000”。5、布尔性的基本类型变量的默认值为 false。6、引用类型的变量是默认值为 null。7、数组引用类型的变量的默认值为 null。
SpringBoot 使用过滤器、拦截器、切面(AOP),及其之间的区别和执行顺序
Servlet(Server Applet),全称是Java Servlet,是提供基于协议请求/响应服务的Java类。在JavaEE中是Servlet规范,即是指Java语言实现的一个接口,广义的Servlet是指任何实现了这个Servlet接口的Java类,一般人们理解是后者。是什么。
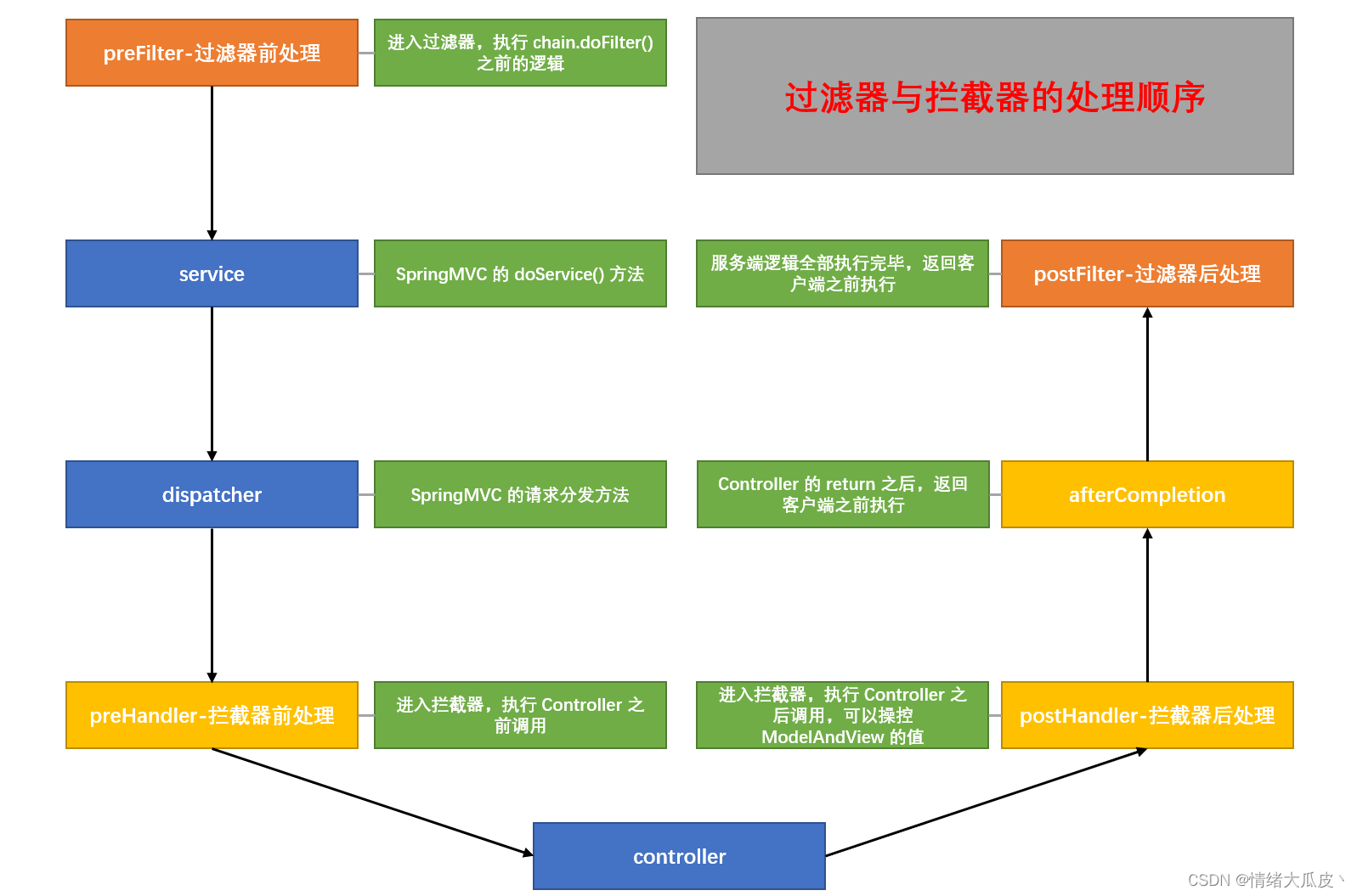
【总结】SpringBoot 中过滤器、拦截器、监听器的基本使用
拦截器是在面向切面编程中应用的,就是在你的service或者一个方法前调用一个方法,或者在方法后调用一个方法。是基于JAVA的反射机制。1)预处理preHandle()方法用户发送请求时,先执行preHandle()方法。会先按照顺序执行所有拦截器的preHandle方法,一直遇到return false为止,比如第二个preHandle方法是return false,则第三个以及以后所有拦截器都不会执行。若都是return true,则执行用户请求的url方法。2)后处理postHandle()方法。
Springboot支付宝沙箱支付---完整详细步骤
两种方式进行配置。这里我采取的是默认方式: 开发者如需使用系统默认密钥/证书,可在开发信息中选择系统默认密钥。注意:使用API在线调试工具调试OpenAPI必须使用系统默认密钥。
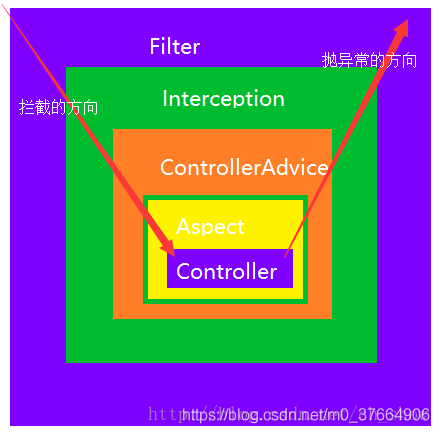
SpringBoot--过滤器/拦截器/AOP--区别/使用/顺序
本文介绍SpringMVC(SpringBoot)中的过滤器、拦截器、AOP的区别及其用法。 如果监听器、过滤器、 拦截器、 AOP都存在,则它们的执行顺序为:监听器 => 过滤器=> 拦截器=> AOP。

websocket介绍并模拟股票数据推流
Websockt是一种网络通信协议,允许客户端和服务器双向通信。最大的特点就是允许服务器主动推送数据给客户端,比如股票数据在客户端实时更新,就能利用websocket。
Spring boot 3 集成rocketmq-spring-boot-starter解决版本不一致问题
根据上篇文章使用Docker安装RocketMQ并启动之后,有个隐患详情见下文。如何解决rocketmq 和spring boot 3.x集成问题
最简单的设计模式是单例?
单例模式可以说是Java中最简单的设计模式,但同时也是技术面试中频率极高的面试题。因为它不仅涉及到设计模式,还包括了关于线程安全、内存模型、类加载等机制。所以说它是最简单的吗?

大数据Hadoop、HDFS、Hive、HBASE、Spark、Flume、Kafka、Storm、SparkStreaming这些概念你是否能理清?
hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。Hadoop是大数据开发的重要框架,是一个由Apache基金会所开发的分布式系统基础架构,其核心是HDFS和MapReduce,HDFS为海量的数据提供了存储,MapReduce为海量的数据提供了计算,在Hadoop2.x时 代,增加 了Yarn,Yarn只负责资 源 的 调 度。当计算模型比较适合流式时,storm的流式处理,省去了批处理的收集数据的时间;
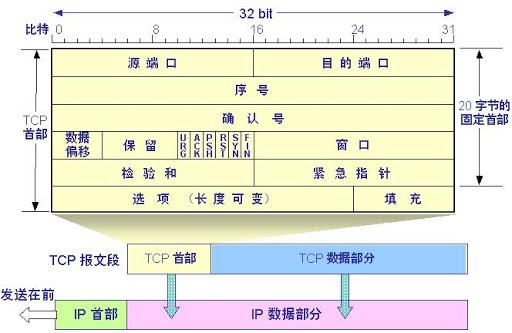
TCP中的三次握手和四次挥手
我们知道TCP是运输层的面向连接的可靠的传输协议。**面向连接的**,指的就是在两个进程发送数据之前,必须先相互“握手”,确保两进程可以进行连接。并且这个传输是点对点的,即一个TCP连接中只有一个发送方和接收方;**可靠的**,指的是在任何网络情况下,在TCP传输中数据都将完整的发送到接收方。
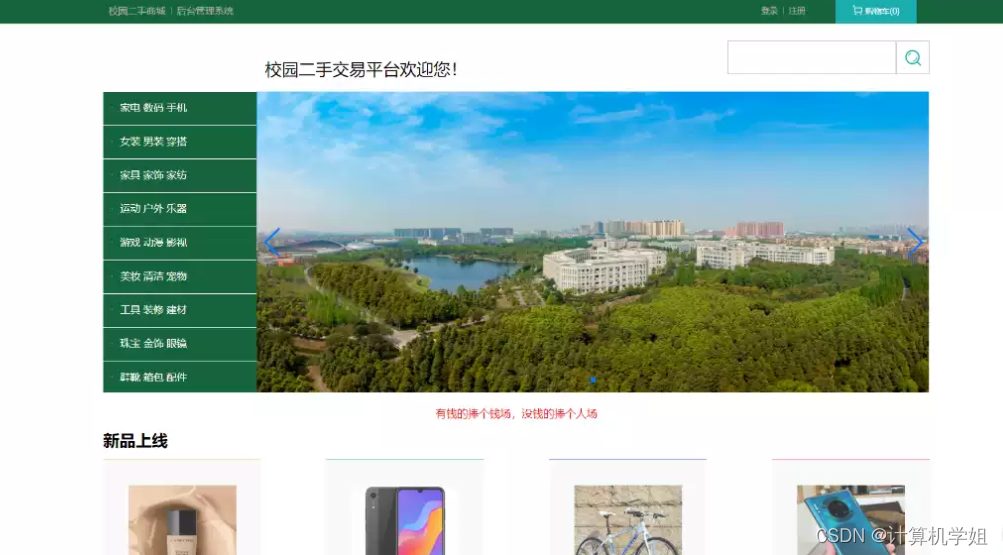
基于SpringBoot的校园二手闲置交易平台
基于SpringBoot的校园二手闲置交易平台的设计与实现~
SpringBoot 中获取 Request 的四种方法
Controller中获取request对象后,如果要在其他方法中(如service方法、工具类方法等)使用request对象,需要在调用这些方法时将request对象作为参数传入。如果其他方法(如工具类中static方法)需要使用request对象,则需要在调用这些方法时将request参数传递进去。下面介绍的方法4,则可以直接在诸如工具类中的static方法中使用request对象(当然在各种Bean中也可以使用)。该方法实现的原理是,在Controller方法开始处理请求时,对象是方法参数,相当于。
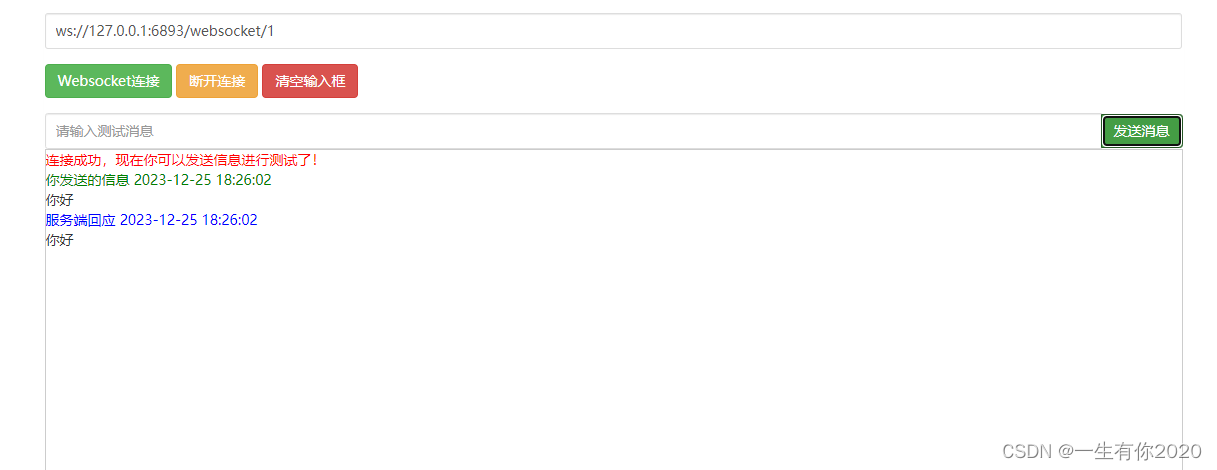
springboot对接WebSocket实现消息推送
项目上线需要https请求,把请求地址换成wss,需要通过nginx配置转发,再443端口加上如下配置。请求地址更换成wss://域名/wss/websocket/或者播放指定的音频文件,播放音频需要浏览器设置可以发放声音。2.增加配置WebSocketConfig.java。7.增加消息推送语音播放_文本转语音。3.创建一个WebSocket实例。6.前端对接WebSocket。4.修改启动类,添加注解。8.如何修改成wss请求。5.测试一下推送消息。
java中代理的实现并在spring的应用
Java代理机制是一种在运行时创建一个代理对象来代替原始对象的方法。代理对象通常用于在调用原始对象的方法之前或之后执行一些额外的操作,例如日志记录、性能监控等。
基于SpringBoot整合RocketMQ异步发送短信功能
上一篇文章记录了 RocketMQ 整体架构、安装部署、应用场景这三个内容。熟悉了 RocketMQ 相关核心概念后,本文记录基于 SpringBoot 整合 RocketMQ 异步发送短信功能,其中会引入阿里云短信服务相关内容。
java并发编程九 ABA 问题及解决,原子数组和字段更新
它指的是一个共享变量的值在操作期间从A变为B,然后再从B变回A,而CAS操作可能会错误地认为没有其他线程修改过这个值。AtomicStampedReference 可以给原子引用加上版本号,追踪原子引用整个的变化过程,如: A -> B -> A ->C,通过AtomicStampedReference,我们可以知道,引用变量中途被更改了几次。只要有其它线程【动过了】共享变量,那么自己的 cas 就算失败,这时,仅比较值是不够的,需要再加一个版本号 AtomicStampedReference。