Flink1.7.2 sql 批处理示例
Flink1.7.2 sql 批处理示例
源码
- https://github.com/opensourceteams/flink-maven-scala
概述
- 本文为Flink sql Dataset 示例
- 主要操作包括:Scan / Select,as (table),as (column),limit,Where / Filter,between and (where),Sum,min,max,avg,
- (group by ),group by having,distinct,INNER JOIN,left join,right join,full outer join,union,unionAll,INTERSECT
in,EXCEPT,insert into
SELECT
Scan / Select
- 功能描述: 查询一个表中的所有数据
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.scanimport org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._object Run {def main(args: Array[String]): Unit = {//得到批环境val env = ExecutionEnvironment.getExecutionEnvironmentval dataSet = env.fromElements(("小明",15,"男"),("小王",45,"男"),("小李",25,"女"),("小慧",35,"女"))//得到Table环境val tableEnv = TableEnvironment.getTableEnvironment(env)//注册tabletableEnv.registerDataSet("user1",dataSet,'name,'age,'sex)tableEnv.sqlQuery(s"select name,age FROM user1").first(100).print()/*** 输出结果** 小明,15* 小王,45* 小李,25* 小慧,35*/}}- 输出结果
小明,15
小王,45
小李,25
小慧,35
as (table)
- 功能描述: 给表名取别称
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.scanimport org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._object Run {def main(args: Array[String]): Unit = {//得到批环境val env = ExecutionEnvironment.getExecutionEnvironmentval dataSet = env.fromElements(("小明",15,"男"),("小王",45,"男"),("小李",25,"女"),("小慧",35,"女"))//得到Table环境val tableEnv = TableEnvironment.getTableEnvironment(env)//注册tabletableEnv.registerDataSet("user1",dataSet,'name,'age,'sex)tableEnv.sqlQuery(s"select t1.name,t1.age FROM user1 as t1").first(100).print()/*** 输出结果** 小明,15* 小王,45* 小李,25* 小慧,35*/}}- 输出结果
小明,15
小王,45
小李,25
小慧,35
as (column)
- 功能描述: 给表名取别称
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.scanimport org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._object Run {def main(args: Array[String]): Unit = {//得到批环境val env = ExecutionEnvironment.getExecutionEnvironmentval dataSet = env.fromElements(("小明",15,"男"),("小王",45,"男"),("小李",25,"女"),("小慧",35,"女"))//得到Table环境val tableEnv = TableEnvironment.getTableEnvironment(env)//注册tabletableEnv.registerDataSet("user1",dataSet,'name,'age,'sex)tableEnv.sqlQuery(s"select name a,age as b FROM user1 ").first(100).print()/*** 输出结果** 小明,15* 小王,45* 小李,25* 小慧,35*/}}- 输出结果
小明,15
小王,45
小李,25
小慧,35
limit
- 功能描述:查询一个表的数据,只返回指定的前几行(争对并行度而言,所以并行度不一样,结果不一样)
- scala 程序
package com.opensourceteams.mo`dule.bigdata.flink.example.sql.dataset.operations.limitimport org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._object Run {def main(args: Array[String]): Unit = {//得到批环境val env = ExecutionEnvironment.getExecutionEnvironmentenv.setParallelism(2)val dataSet = env.fromElements(("小明",15,"男"),("小王",45,"男"),("小李",25,"女"),("小慧",35,"女"))//得到Table环境val tableEnv = TableEnvironment.getTableEnvironment(env)//注册tabletableEnv.registerDataSet("user1",dataSet,'name,'age,'sex)/*** 先排序,按age的降序排序,输出前100位结果,注意是按同一个并行度中的数据进行排序,也就是同一个分区*/tableEnv.sqlQuery(s"select name,age FROM user1 ORDER BY age desc LIMIT 100 ").first(100).print()/*** 输出结果 并行度设置为2** 小明,15* 小王,45* 小慧,35* 小李,25*//*** 输出结果 并行度设置为1** 小王,45* 小慧,35* 小李,25* 小明,15*/}}
- 输出结果
小明,15
小王,45
小慧,35
小李,25Where / Filter
- 功能描述:列加条件过滤表中的数据
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.whereimport org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._object Run {def main(args: Array[String]): Unit = {//得到批环境val env = ExecutionEnvironment.getExecutionEnvironmentval dataSet = env.fromElements(("小明",15,"男"),("小王",45,"男"),("小李",25,"女"),("小慧",35,"女"))//得到Table环境val tableEnv = TableEnvironment.getTableEnvironment(env)//注册tabletableEnv.registerDataSet("user1",dataSet,'name,'age,'sex)tableEnv.sqlQuery(s"select name,age,sex FROM user1 where sex = '女'").first(100).print()/*** 输出结果* * 小李,25,女* 小慧,35,女*/}}- 输出结果
小李,25,女
小慧,35,女between and (where)
- 功能描述: 过滤列中的数据, 开始数据 <= data <= 结束数据
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.whereBetweenAndimport org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._object Run {def main(args: Array[String]): Unit = {//得到批环境val env = ExecutionEnvironment.getExecutionEnvironmentval dataSet = env.fromElements(("小明",15,"男"),("小王",45,"男"),("小李",25,"女"),("小慧",35,"女"))//得到Table环境val tableEnv = TableEnvironment.getTableEnvironment(env)//注册tabletableEnv.registerDataSet("user1",dataSet,'name,'age,'sex)tableEnv.sqlQuery(s"select name,age,sex FROM user1 where age between 20 and 35").first(100).print()/*** 结果** 小李,25,女* 小慧,35,女*/}}- 输出结果
小李,25,女
小慧,35,女
Sum
- 功能描述: 求和所有数据
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.aggregations.sumimport org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._object Run {def main(args: Array[String]): Unit = {//得到批环境val env = ExecutionEnvironment.getExecutionEnvironmentval dataSet = env.fromElements(("小明",15,"男",1500),("小王",45,"男",4000),("小李",25,"女",800),("小慧",35,"女",500))//得到Table环境val tableEnv = TableEnvironment.getTableEnvironment(env)//注册tabletableEnv.registerDataSet("user1",dataSet,'name,'age,'sex,'salary)//汇总所有数据tableEnv.sqlQuery(s"select sum(salary) FROM user1").first(100).print()/*** 输出结果** 6800*/}}- 输出结果
6800
max
- 功能描述: 求最大值
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.aggregations.maximport org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._object Run {def main(args: Array[String]): Unit = {//得到批环境val env = ExecutionEnvironment.getExecutionEnvironmentval dataSet = env.fromElements(("小明",15,"男",1500),("小王",45,"男",4000),("小李",25,"女",800),("小慧",35,"女",500))//得到Table环境val tableEnv = TableEnvironment.getTableEnvironment(env)//注册tabletableEnv.registerDataSet("user1",dataSet,'name,'age,'sex,'salary)//汇总所有数据tableEnv.sqlQuery(s"select max(salary) FROM user1 ").first(100).print()/*** 输出结果** 4000*/}}- 输出结果
4000
min
- 功能描述: 求最小值
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.aggregations.minimport org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._object Run {def main(args: Array[String]): Unit = {//得到批环境val env = ExecutionEnvironment.getExecutionEnvironmentval dataSet = env.fromElements(("小明",15,"男",1500),("小王",45,"男",4000),("小李",25,"女",800),("小慧",35,"女",500))//得到Table环境val tableEnv = TableEnvironment.getTableEnvironment(env)//注册tabletableEnv.registerDataSet("user1",dataSet,'name,'age,'sex,'salary)tableEnv.sqlQuery(s"select min(salary) FROM user1 ").first(100).print()/*** 输出结果** 500*/}}- 输出结果
500
sum (group by )
- 功能描述: 按性别分组求和
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.aggregations.groupimport org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._object Run {def main(args: Array[String]): Unit = {//得到批环境val env = ExecutionEnvironment.getExecutionEnvironmentval dataSet = env.fromElements(("小明",15,"男",1500),("小王",45,"男",4000),("小李",25,"女",800),("小慧",35,"女",500))//得到Table环境val tableEnv = TableEnvironment.getTableEnvironment(env)//注册tabletableEnv.registerDataSet("user1",dataSet,'name,'age,'sex,'salary)//汇总所有数据tableEnv.sqlQuery(s"select sex,sum(salary) FROM user1 group by sex").first(100).print()/*** 输出结果* * 女,1300* 男,5500*/}}- 输出结果
女,1300
男,5500
group by having
- 功能描述:
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.aggregations.group_havingimport org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._object Run {def main(args: Array[String]): Unit = {//得到批环境val env = ExecutionEnvironment.getExecutionEnvironmentval dataSet = env.fromElements(("小明",15,"男",1500),("小王",45,"男",4000),("小李",25,"女",800),("小慧",35,"女",500))//得到Table环境val tableEnv = TableEnvironment.getTableEnvironment(env)//注册tabletableEnv.registerDataSet("user1",dataSet,'name,'age,'sex,'salary)//分组统计,having是分组条件查询tableEnv.sqlQuery(s"select sex,sum(salary) FROM user1 group by sex having sum(salary) >1500").first(100).print()/*** 输出结果* * */}}- 输出结果
男,5500
distinct
- 功能描述: 去重一列或多列
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.aggregations.distinctimport org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._object Run {def main(args: Array[String]): Unit = {val env = ExecutionEnvironment.getExecutionEnvironmentval dataSet = env.fromElements(("a",15,"male"),("a",45,"female"),("d",25,"male"),("c",35,"female"))val tableEnv = TableEnvironment.getTableEnvironment(env)tableEnv.registerDataSet("user1",dataSet,'name,'age,'sex)/*** 对数据去重*/tableEnv.sqlQuery("select distinct name FROM user1 ").first(100).print()/*** 输出结果** a* c* d*/}}- 输出结果
a
c
d
join
INNER JOIN
- 功能描述: 连接两个表,按指定的列,两列都存在值才输出
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.join.innerJoinimport org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._object Run {def main(args: Array[String]): Unit = {//得到批环境val env = ExecutionEnvironment.getExecutionEnvironmentval dataSet = env.fromElements((1,"小明",15,"男",1500),(2,"小王",45,"男",4000),(3,"小李",25,"女",800),(4,"小慧",35,"女",500))val dataSetGrade = env.fromElements((1,"语文",100),(2,"数学",80),(1,"外语",50) )//得到Table环境val tableEnv = TableEnvironment.getTableEnvironment(env)//注册tabletableEnv.registerDataSet("user",dataSet,'id,'name,'age,'sex,'salary)tableEnv.registerDataSet("grade",dataSetGrade,'userId,'name,'fraction)//内连接,两个表// tableEnv.sqlQuery("select * FROM `user` INNER JOIN grade on `user`.id = grade.userId ")tableEnv.sqlQuery("select `user`.*,grade.name,grade.fraction FROM `user` INNER JOIN grade on `user`.id = grade.userId ").first(100).print()/*** 输出结果* 2,小王,45,男,4000,数学,80* 1,小明,15,男,1500,语文,100* 1,小明,15,男,1500,外语,50*/}}- 输出结果
2,小王,45,男,4000,数学,80
1,小明,15,男,1500,语文,100
1,小明,15,男,1500,外语,50
left join
- 功能描述:连接两个表,按指定的列,左表中存在值就一定输出,右表如果不存在,就显示为空
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.join.leftJoinimport org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._object Run {def main(args: Array[String]): Unit = {//得到批环境val env = ExecutionEnvironment.getExecutionEnvironmentval dataSet = env.fromElements((1,"小明",15,"男",1500),(2,"小王",45,"男",4000),(3,"小李",25,"女",800),(4,"小慧",35,"女",500))val dataSetGrade = env.fromElements((1,"语文",100),(2,"数学",80),(1,"外语",50) )//得到Table环境val tableEnv = TableEnvironment.getTableEnvironment(env)//注册tabletableEnv.registerDataSet("user",dataSet,'id,'name,'age,'sex,'salary)tableEnv.registerDataSet("grade",dataSetGrade,'userId,'name,'fraction)//左连接,拿左边的表中的每一行数据,去关联右边的数据,如果有相同的匹配数据,就都匹配出来,如果没有,就匹配一条,不过右边的数据为空tableEnv.sqlQuery("select `user`.*,grade.name,grade.fraction FROM `user` LEFT JOIN grade on `user`.id = grade.userId ").first(100).print()/*** 输出结果** 1,小明,15,男,1500,语文,100* 1,小明,15,男,1500,外语,50* 2,小王,45,男,4000,数学,80* 4,小慧,35,女,500,null,null* 3,小李,25,女,800,null,null***/}}- 输出结果
1,小明,15,男,1500,语文,100
1,小明,15,男,1500,外语,50
2,小王,45,男,4000,数学,80
4,小慧,35,女,500,null,null
3,小李,25,女,800,null,null
right join
- 功能描述:连接两个表,按指定的列,右表中存在值就一定输出,左表如果不存在,就显示为空
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.join.rightJoinimport org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._object Run {def main(args: Array[String]): Unit = {//得到批环境val env = ExecutionEnvironment.getExecutionEnvironmentval dataSet = env.fromElements((1,"小明",15,"男",1500),(2,"小王",45,"男",4000),(3,"小李",25,"女",800),(4,"小慧",35,"女",500))val dataSetGrade = env.fromElements((1,"语文",100),(2,"数学",80),(1,"外语",50),(10,"外语",90) )//得到Table环境val tableEnv = TableEnvironment.getTableEnvironment(env)//注册tabletableEnv.registerDataSet("user",dataSet,'id,'name,'age,'sex,'salary)tableEnv.registerDataSet("grade",dataSetGrade,'userId,'name,'fraction)//左连接,拿左边的表中的每一行数据,去关联右边的数据,如果有相同的匹配数据,就都匹配出来,如果没有,就匹配一条,不过右边的数据为空tableEnv.sqlQuery("select `user`.*,grade.name,grade.fraction FROM `user` RIGHT JOIN grade on `user`.id = grade.userId ").first(100).print()/*** 输出结果** 1,小明,15,男,1500,外语,50* 1,小明,15,男,1500,语文,100* 2,小王,45,男,4000,数学,80* null,null,null,null,null,外语,90***/}}- 输出结果
1,小明,15,男,1500,外语,50
1,小明,15,男,1500,语文,100
2,小王,45,男,4000,数学,80
null,null,null,null,null,外语,90
full outer join
- 功能描述: 连接两个表,按指定的列,只要有一表中存在值就一定输出,另一表如果不存在就显示为空
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.join.fullOuterJoinimport org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._object Run {def main(args: Array[String]): Unit = {//得到批环境val env = ExecutionEnvironment.getExecutionEnvironmentval dataSet = env.fromElements((1,"小明",15,"男",1500),(2,"小王",45,"男",4000),(3,"小李",25,"女",800),(4,"小慧",35,"女",500))val dataSetGrade = env.fromElements((1,"语文",100),(2,"数学",80),(1,"外语",50),(10,"外语",90) )//得到Table环境val tableEnv = TableEnvironment.getTableEnvironment(env)//注册tabletableEnv.registerDataSet("user",dataSet,'id,'name,'age,'sex,'salary)tableEnv.registerDataSet("grade",dataSetGrade,'userId,'name,'fraction)//左,右,全匹配所有数据tableEnv.sqlQuery("select `user`.*,grade.name,grade.fraction FROM `user` FULL OUTER JOIN grade on `user`.id = grade.userId ").first(100).print()/*** 输出结果*** 3,小李,25,女,800,null,null* 1,小明,15,男,1500,外语,50* 1,小明,15,男,1500,语文,100* 2,小王,45,男,4000,数学,80* 4,小慧,35,女,500,null,null* null,null,null,null,null,外语,90****/}}- 输出结果
3,小李,25,女,800,null,null
1,小明,15,男,1500,外语,50
1,小明,15,男,1500,语文,100
2,小王,45,男,4000,数学,80
4,小慧,35,女,500,null,null
null,null,null,null,null,外语,90
Set Operations
union
- 功能描述: 连接两个表中的数据,会去重
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.setOperations.unionimport org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._object Run {def main(args: Array[String]): Unit = {//得到批环境val env = ExecutionEnvironment.getExecutionEnvironmentval dataSet = env.fromElements((1,"小明",15,"男",1500),(2,"小王",45,"男",4000),(3,"小李",25,"女",800),(4,"小慧",35,"女",500))val dataSet2 = env.fromElements((1,"小明",15,"男",1500),(2,"小王",45,"男",4000),(30,"小李",25,"女",800),(40,"小慧",35,"女",500))//得到Table环境val tableEnv = TableEnvironment.getTableEnvironment(env)//注册tabletableEnv.registerDataSet("user",dataSet,'id,'name,'age,'sex,'salary)tableEnv.registerDataSet("t2",dataSet2,'id,'name,'age,'sex,'salary)/*** union 连接两个表,会去重*/tableEnv.sqlQuery("select * from ("+"select t1.* FROM `user` as t1 ) " ++ " UNION "+ " ( select t2.* FROM t2 )").first(100).print()/*** 输出结果** 30,小李,25,女,800* 40,小慧,35,女,500* 2,小王,45,男,4000* 4,小慧,35,女,500* 3,小李,25,女,800* 1,小明,15,男,1500**/}}- 输出结果
30,小李,25,女,800
40,小慧,35,女,500
2,小王,45,男,4000
4,小慧,35,女,500
3,小李,25,女,800
1,小明,15,男,1500
unionAll
- 功能描述: 连接两表中的数据,不会去重
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.setOperations.unionAllimport org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._object Run {def main(args: Array[String]): Unit = {//得到批环境val env = ExecutionEnvironment.getExecutionEnvironmentval dataSet = env.fromElements((1,"小明",15,"男",1500),(2,"小王",45,"男",4000),(3,"小李",25,"女",800),(4,"小慧",35,"女",500))val dataSet2 = env.fromElements((1,"小明",15,"男",1500),(2,"小王",45,"男",4000),(30,"小李",25,"女",800),(40,"小慧",35,"女",500))//得到Table环境val tableEnv = TableEnvironment.getTableEnvironment(env)//注册tabletableEnv.registerDataSet("user",dataSet,'id,'name,'age,'sex,'salary)tableEnv.registerDataSet("t2",dataSet2,'id,'name,'age,'sex,'salary)/*** union 连接两个表,不会去重*/tableEnv.sqlQuery("select * from ("+"select t1.* FROM `user` as t1 ) " ++ " UNION ALL "+ " ( select t2.* FROM t2 )").first(100).print()/*** 输出结果** 1,小明,15,男,1500* 2,小王,45,男,4000* 3,小李,25,女,800* 4,小慧,35,女,500* 1,小明,15,男,1500* 2,小王,45,男,4000* 30,小李,25,女,800* 40,小慧,35,女,500**/}}- 输出结果
1,小明,15,男,1500
2,小王,45,男,4000
3,小李,25,女,800
4,小慧,35,女,500
1,小明,15,男,1500
2,小王,45,男,4000
30,小李,25,女,800
40,小慧,35,女,500
INTERSECT
- 功能描述: INTERSECT 连接两个表,找相同的数据(相交的数据,重叠的数据)
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.setOperations.intersectimport org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._object Run {def main(args: Array[String]): Unit = {//得到批环境val env = ExecutionEnvironment.getExecutionEnvironmentval dataSet = env.fromElements((1,"小明",15,"男",1500),(2,"小王",45,"男",4000),(3,"小李",25,"女",800),(4,"小慧",35,"女",500))val dataSet2 = env.fromElements((1,"小明",15,"男",1500),(2,"小王",45,"男",4000),(30,"小李",25,"女",800),(40,"小慧",35,"女",500))//得到Table环境val tableEnv = TableEnvironment.getTableEnvironment(env)//注册tabletableEnv.registerDataSet("user",dataSet,'id,'name,'age,'sex,'salary)tableEnv.registerDataSet("t2",dataSet2,'id,'name,'age,'sex,'salary)/*** INTERSECT 连接两个表,找相同的数据(相交的数据,重叠的数据)*/tableEnv.sqlQuery("select * from ("+"select t1.* FROM `user` as t1 ) " ++ " INTERSECT "+ " ( select t2.* FROM t2 )").first(100).print()/*** 输出结果** 1,小明,15,男,1500* 2,小王,45,男,4000**/}}- 输出结果
1,小明,15,男,15002,小王,45,男,4000
in
- 功能描述: 子查询
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.setOperations.inimport org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._object Run {def main(args: Array[String]): Unit = {//得到批环境val env = ExecutionEnvironment.getExecutionEnvironmentval dataSet = env.fromElements((1,"小明",15,"男",1500),(2,"小王",45,"男",4000),(3,"小李",25,"女",800),(4,"小慧",35,"女",500))val dataSet2 = env.fromElements((1,"小明",15,"男",1500),(2,"小王",45,"男",4000),(30,"小李",25,"女",800),(40,"小慧",35,"女",500))//得到Table环境val tableEnv = TableEnvironment.getTableEnvironment(env)//注册tabletableEnv.registerDataSet("user",dataSet,'id,'name,'age,'sex,'salary)tableEnv.registerDataSet("t2",dataSet2,'id,'name,'age,'sex,'salary)/*** in ,子查询*/tableEnv.sqlQuery("select t1.* FROM `user` t1 where t1.id in " +" (select t2.id from t2) ").first(100).print()/*** 输出结果** 1,小明,15,男,1500* 2,小王,45,男,4000**/}}- 输出结果
1,小明,15,男,15002,小王,45,男,4000
EXCEPT
- 功能描述: EXCEPT 连接两个表,找不相同的数据(不相交的数据,不重叠的数据)
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.setOperations.exceptimport org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._object Run {def main(args: Array[String]): Unit = {//得到批环境val env = ExecutionEnvironment.getExecutionEnvironmentval dataSet = env.fromElements((1,"小明",15,"男",1500),(2,"小王",45,"男",4000),(3,"小李",25,"女",800),(4,"小慧",35,"女",500))val dataSet2 = env.fromElements((1,"小明",15,"男",1500),(2,"小王",45,"男",4000),(30,"小李",25,"女",800),(40,"小慧",35,"女",500))//得到Table环境val tableEnv = TableEnvironment.getTableEnvironment(env)//注册tabletableEnv.registerDataSet("user",dataSet,'id,'name,'age,'sex,'salary)tableEnv.registerDataSet("t2",dataSet2,'id,'name,'age,'sex,'salary)/*** EXCEPT 连接两个表,找不相同的数据(不相交的数据,不重叠的数据)*/tableEnv.sqlQuery("select * from ("+"select t1.* FROM `user` as t1 ) " ++ " EXCEPT "+ " ( select t2.* FROM t2 )").first(100).print()/*** 输出结果** 3,小李,25,女,800* 4,小慧,35,女,500**/}}- 输出结果
3,小李,25,女,8004,小慧,35,女,500
DML
insert into
- 功能描述:将一个表中的数据(source),插入到 csv文件中(sink)
- scala程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.insertimport org.apache.flink.api.scala.typeutils.Types
import org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.core.fs.FileSystem.WriteMode
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._
import org.apache.flink.api.scala._
import org.apache.flink.table.sinks.CsvTableSink
import org.apache.flink.api.common.typeinfo.TypeInformationobject Run {def main(args: Array[String]): Unit = {//得到批环境val env = ExecutionEnvironment.getExecutionEnvironmentval dataSet = env.fromElements(("小明",15,"男"),("小王",45,"男"),("小李",25,"女"),("小慧",35,"女"))//得到Table环境val tableEnv = TableEnvironment.getTableEnvironment(env)//注册tabletableEnv.registerDataSet("user1",dataSet,'name,'age,'sex)// create a TableSinkval csvSink = new CsvTableSink("sink-data/csv/a.csv",",",1,WriteMode.OVERWRITE);val fieldNames = Array("name", "age", "sex")val fieldTypes: Array[TypeInformation[_]] = Array(Types.STRING, Types.INT, Types.STRING)tableEnv.registerTableSink("t2",fieldNames,fieldTypes,csvSink)tableEnv.sqlUpdate(s" insert into t2 select name,age,sex FROM user1 ")env.execute()/*** 输出结果* a.csv** 小明,15,男* 小王,45,男* 小李,25,女* 小慧,35,女*/}}- 输出数据 a.csv
小明,15,男
小王,45,男
小李,25,女
小慧,35,女Scan
- 功能描述:
- scala 程序
- 输出结果
相关文章:
ISP 【一】————boost标准库使用——批量读取保存文件 /boost第三方库的使用及其cmake添加,图像gramma
CMakeLists.txt文件中需要添加第三方库,并企鹅在CMakeLists.txt中添加 include_directories(${PROJECT_SOURCE_DIR}/../3party/gflags-2.2.2/include) link_directories(${PROJECT_SOURCE_DIR}/../3party/boost-1.73.0/lib-import) target_link_libraries( gram…

简单ajax类, 比较小, 只用ajax功能时, 可以考虑它
忘了哪儿转来的了, 不时的能够用上, 留存一下<script language"javascript" type"text/javascript"> /***var ajaxAjax();/*get使用方式* /ajax.get("php_server.php?id1&namexxx", function(data){ alert(data); //d…
Hadoop 三大发行版本
Hadoop三大发行版本:Apache、Cloudera、Hortonworks。 Apache版本最原始(最基础)的版本,对于入门学习最好。 Cloudera在大型互联网企业中用的较多。 Hortonworks文档较好。 1. Apache Hadoop 官网地址:http://had…
MongoDB主动撤回SSPL的开源许可申请
2018年10月,MongoDB将其开源协议更换为SSPL,虽然在当时引起了很大的争议,但是MongoDB始终坚信SSPL符合符合开源计划的批准标准,并向Open Source Initiative (以下简称OSI)提交了申请。不过,近日…
MATLAB【八】———— matlab 读取单个(多个)文件夹中所有图像
0.matlab 移动(复制)文件到另一个文件夹 sourcePath .\Square_train; targetPath .\Square_test; fileList dir(sourcePath); for k 3 :5: length(fileList) movefile([sourcePath,\,fileList(k).name],targetPath); end %copyfile([sourcePat…

JAVA IO学习
2019独角兽企业重金招聘Python工程师标准>>> 很多初学者接触IO时,总是感觉东西太多,杂乱的分不清楚。其实里面用到了装饰器模式封装,把里面的接口梳理一下之后,就会觉得其实蛮清晰的 相关的接口和类 接口或类描述Input…
Java面向对象三大特征 之 多态性
1、理解多态性:可以理解为一个事物的多种形态 2、对象的多态性:父类的引用指向子类的对象(子类的对象赋给父类的引用) 3、多态的使用:虚拟方法的调用 子类中定义了与父类同名同参数的方法(重写ÿ…
Bootstrap3基础 btn-group-vertical 按钮组(横着、竖着排列)
内容参数OS Windows 10 x64 browser Firefox 65.0.2 framework Bootstrap 3.3.7 editor Visual Studio Code 1.32.1 typesetting Markdowncode <!DOCTYPE html> <html lang"zh-CN"><head><meta charset&quo…
ISP【二】————camera ir图
1. 加串解串芯片作用? A: 加串和解串是成对出现的,串行器在模组内,将并行信号转换为串行信号,然后用一根线可以实现远距离传输。sensor输出的raw data如果不加串,需要8根线传输,很难传输很远&a…
Hadoop运行模式 之 本地运行模式
Hadoop的运行模式包括:本地模式、伪分布式模式以及完全分布式模式 Hadoop官网地址:https://hadoop.apache.org/ 本次使用的Hadoop的版本是2.7.2 官网文档:https://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-common/Single…
一些使用Vim的小技巧
7.增加注释(一个操作应用在多行)比如需要增加#或者是//这种注释:Ctrl v 定位到开始行,然后选定需要的行,然后执行 I命令,然后输入 # 或 //,然后按 Esc键两次,即可把注释操作应用到所…

SpringBoot注解大全 转
2019年3月17日22:30:10 一、注解(annotations)列表 SpringBootApplication:包含了ComponentScan、Configuration和EnableAutoConfiguration注解。其中ComponentScan让spring Boot扫描到Configuration类并把它加入到程序上下文。 Configuration 等同于spring的XML配置…
MATLAB【九】————ICP算法实现
1.ICP推导与求解 https://zhuanlan.zhihu.com/p/35893884 2.算法实现: % 程序说明:输入data_source和data_target两个点云,找寻将data_source映射到data_targe的旋转和平移参数 clear; close all; clc; %% 参数配置 kd 1; inlier_ratio …
Centos 7环境下源码安装PostgreSQL数据库
马上就要去实习了,工作内容是搞数据仓库方面的,用的是postgresql关系型数据库,于是自己先来了解下这种数据的用法,之后说说这个数据库和MySQL的关系和区别。 1.Postgresql简介 看了下官网上的介绍,全球最高级的开源关系…
Oracle job procedure 存储过程定时任务
Oracle job procedure 存储过程定时任务 oracle job有定时执行的功能,可以在指定的时间点或每天的某个时间点自行执行任务。 一、查询系统中的job,可以查询视图 --相关视图 select * from dba_jobs; select * from all_jobs; select * from user_jobs; -…
Hadoop运行模式 之 伪分布式运行模式
什么是伪分布式模式?它与本地运行模式以及完全分布式模式有什么区别? 伪分布式的配置信息,完全是按照完全分布式的模式去搭建的,但是它只有一台服务器,可以用于学习和测试,真正的开发中不可以使用。 目录…
【C++】【一】结构体数组
demo7:函数份文件编写 swap.h #include <iostream> using namespace std;//函数的声明 void swap(int a, int b); swap.cpp #include "swap.h"//函数的定义 void swap(int a, int b) {int temp a;a b;b temp;cout << "a " << a …
Message、Handler、Message Queue、Looper之间的关系
2019独角兽企业重金招聘Python工程师标准>>> 在单线程模型下,为了解决线程通信问题,Android设计了一个通信机制。Message Queue(消息队列), 线程间的通信可以通过Message Queue、Handler和Looper进行信息交换。下面将对它们进行逐…

在linux中只将“桌面”修改成“Desktop”而系统仍然使用中文
在安装好centos系统以后,它的Desktop,Downloads等文件夹都是中文的,桌面,下载等,这样在使用cd命令时特别不方便 解决方法一:下载一个中文输入法,安装 解决方法二: 修改il8n文件&a…

Zabbix 3.0 从入门到精通(zabbix使用详解)
第1章 zabbix监控 1.1 为什么要监控 在需要的时刻,提前提醒我们服务器出问题了 当出问题之后,可以找到问题的根源 网站/服务器 的可用性 1.1.1 网站可用性 在软件系统的高可靠性(也称为可用性,英文描述为HA,High Avail…

MacBook如何用Parallels Desktop安装windows7/8
虽然MacBook真的很好用,不过在天朝的国情下,有很多软件还是仅支持IE和windows系统下才有。所以有必要为自己的MacBook装一个windows版本的系统,之前试过用Boot Camp来建立分区和安装win7,之后自己又用Parallels Desktop安装过win8…
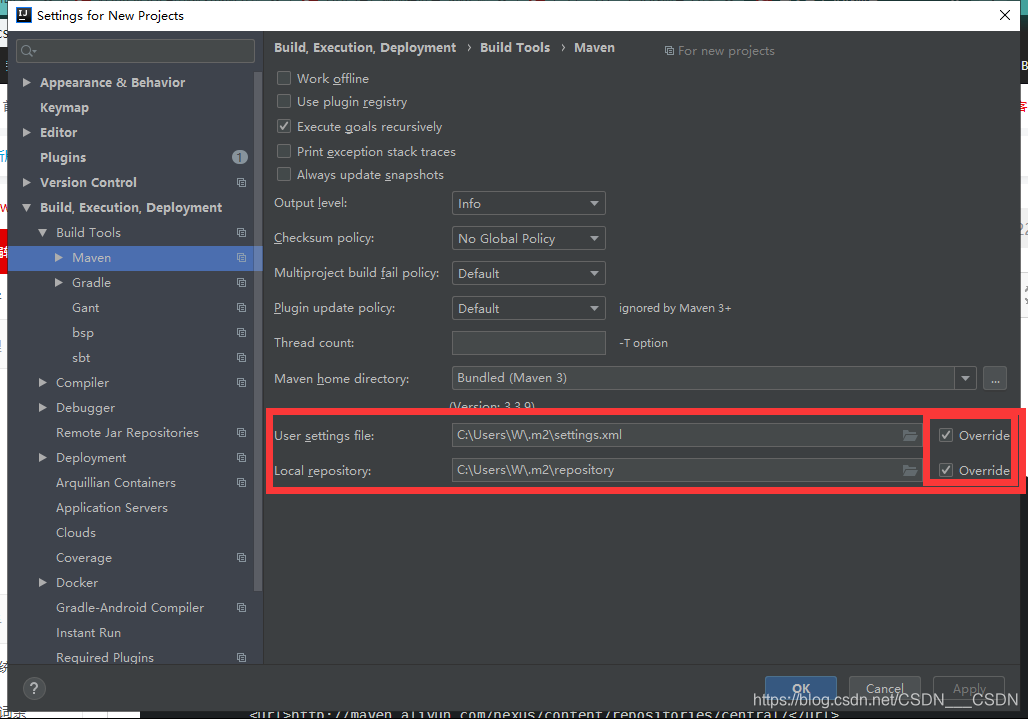
在IDEA 中为Maven 配置阿里云镜像源
打开IntelliJ IDEA->Settings ->Build, Execution, Deployment -> Build Tools > Maven 注意要勾选上override 自己创建一个settings.xml文件, 内容如下 <settings xmlns"http://maven.apache.org/SETTINGS/1.0.0"xmlns:xsi"http:/…

【匹配算法】渐进一致采样 PROSAC(PROgressive SAmple Consensus)
方法简介 渐进一致采样法1 (PROSAC) 是对经典的 RANSAC2 中采样的一种优化。相比经典的 RANSAC 方法均匀地从整个集合中采样,PROSAC 方法是从不断增大的最佳对应点集合中进行采样的。所以这种方法可以节省计算量,提高运行速度。 论文:https:…
阿里巴巴开源的 Blink 实时计算框架真香
Blink 开源了有一段时间了,竟然没发现有人写相关的博客,其实我已经在我的知识星球里开始写了,今天来看看 Blink 为什么香? 我们先看看 Blink 黑色版本: 对比下 Flink 版本你就知道黑色版本多好看了。 你上传 jar 包的时…
【地图API】收货地址详解2
上次讲解的方法是: 在地图中心点添加一个标注,每次拖动地图就获取地图中心点,再把标注的位置设置为地图中心点。可参考教程:http://www.cnblogs.com/milkmap/p/6126424.html 可能有开发者觉得,这个算法会有“延时”&am…
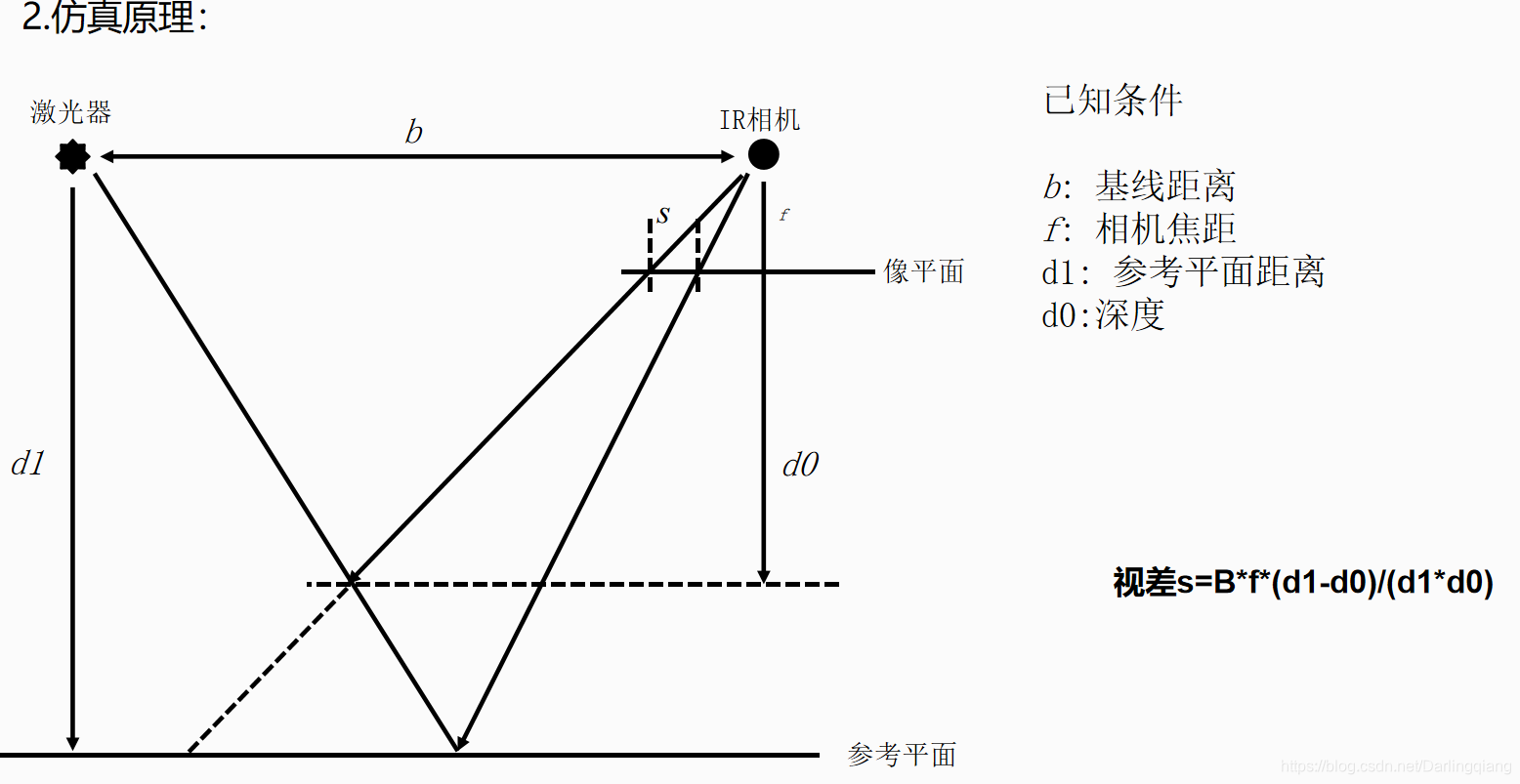
MATLAB【十三】————仿真函数记录以及matlab变成小结
part one:matlab 编程小结。 1.char 与string的区别,char使用的单引号 ‘’ ,string使用的是双引号“”。 2.一般标题中的输出一定要通过 num2str 处理,画图具体的图像细节参考:https://blog.csdn.net/Darlingqiang/ar…

IDEA HDFS客户端准备
在此之前:先进行在IDEA 中为Maven 配置阿里云镜像源 1、将资料包中的压缩包解压到一个没有中文的目录下 2、配置HADOOP_HOME环境变量 3、配置Path环境变量 4、创建一个Maven工程HDFSClientDemo 5、在pom.xml中添加依赖 <dependencies><dependency><g…
12 Java面向对象之多态
JavaSE 基础之十二12 Java面向对象之多态 ① 多态的概念及分类 多态的概念:对象的多种表现形式和能力多态的分类 1. 静态多态:在编译期间,程序就能决定调用哪个方法。方法的重载就表现出了静态多态。 2. 动态多态:在程序运行…
MATLAB【十四】————遍历三层文件夹操作
文件夹遍历 clear; clc; close all;%% crop the im into 256*256 num 0; %% num1 内缩3个像素 num 2 内缩6个像素 load(qualitydata1.mat) load(qualitydata2.mat)[data1_m,data1_n] size(qualitydata1); [data2_m,data2_n] size(qualitydata2);%% read image_name …

LoadRunner监控Linux
有的linux机器上安装rpc后会保存如下: test -z "/usr/local/sbin" || mkdir -p -- . "/usr/local/sbin"/bin/install -c rpc.rstatd /usr/local/sbin/rpc.rstatd make[2]: Nothing to be done for install-data-am. make[2]: Leaving directory…