Hadoop运行模式 之 伪分布式运行模式
什么是伪分布式模式?它与本地运行模式以及完全分布式模式有什么区别?
伪分布式的配置信息,完全是按照完全分布式的模式去搭建的,但是它只有一台服务器,可以用于学习和测试,真正的开发中不可以使用。
目录
一、使用软件
二、启动HDFS并运行MapReduce程序
1、配置集群
2、启动集群
3、查看集群
4、操作集群
5、注意
三、启动Yarn并运行MapReduce程序
1、配置集群
2、启动集群
3、操作集群
四、配置历史服务器
1、配置mapred-site.xml
2、启动历史服务器
3、查看历史服务器是否启动
4、查看JobHistory
五、配置日志的聚集
1、关闭NodeManager 、ResourceManager和HistoryManager
2、配置yarn-site.xml
3、启动NodeManager 、ResourceManager和HistoryManager
4、删除HDFS上已经存在的输出文件
5、执行WordCount程序
6、查看日志
六、配置文件说明
一、使用软件
1、VMware15.5
2、centos6.4(64位)
3、java1.8.0_144(64位)
4、hadoop 2.7.2
二、启动HDFS并运行MapReduce程序
1、配置集群
配置文件都在该目录下 : /opt/module/hadoop-2.7.2/etc/hadoop
(善于利用tab键)
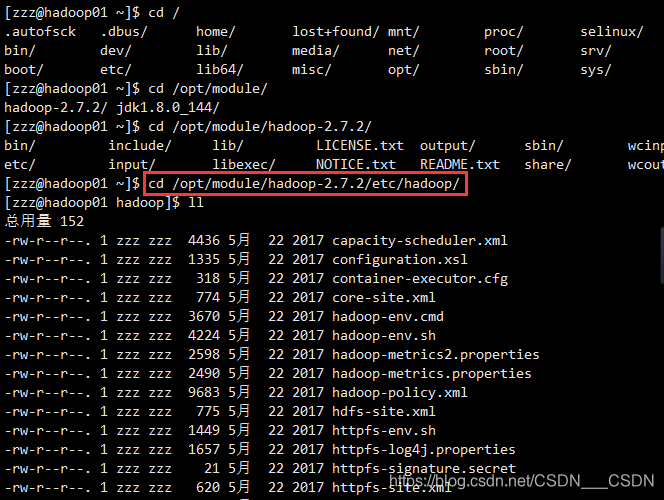
(1)配置:hadoop-env.sh
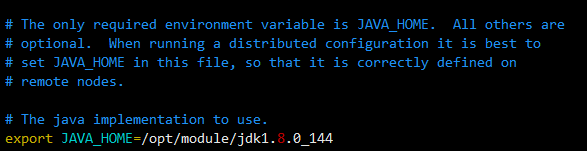
hadoop-env.sh:修改JAVA_HOME的路径
(2)配置:core-site.xml
其中的hadoop01的位置根据自己的主机名进行相应的修改
hadoop.tmp.dir:hadoop运行时产生文件的存储目录。之后的很多框架默认的存储路径是:/tmp/hadoop-${user.name},但是一般不会把数据存放在系统的tmp目录下,修改到当前工程的路径下。
修改了这一块之后,运行本地模式会报错,因为协议发生了变化,默认的是file:///

<configuration><!-- 指定HDFS中NameNode的地址 --><property><name>fs.defaultFS</name><value>hdfs://hadoop01:9000</value></property><!-- 指定Hadoop运行时产生文件的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop-2.7.2/data/tmp</value></property>
</configuration>(3)配置:hdfs-site.xml
hdfs-site.xml:指定HDFS副本的数量(默认值是3),副本:同时在3台机器上存储了同一份的数据,任何一台节点的数据挂掉,那么还有两份,还会在另一台服务器上增加这个节点,始终保证这个集群上的副本是3。副本的多少取决去机器的性能
<configuration><!-- 指定HDFS副本的数量 --><property><name>dfs.replication</name><value>1</value></property>
</configuration>2、启动集群
(1)格式化NameNode
格式化NameNode,第一次启动时格式化,以后不要总是格式化,因为格式化一次,就把集群上的数据全部清空了。在格式化的过程当中,如果有任何提示你已经格式化过,是否重新格式化,遇到任何的提示,就应该需要重新格式化,
bin/hdfs namenode -format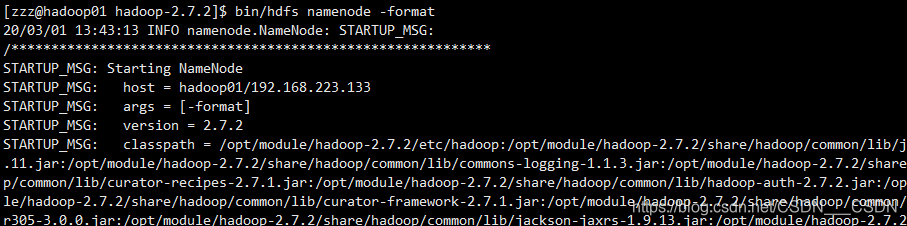
(2)启动NameNode
sbin目录下,hadoop-daemon.sh是hadoop的守护进程,它可以启动hadoop的NamdeNode,启动Hadoop的DataNode
sbin/hadoop-daemon.sh start namenode
(3)启动DataNode
sbin/hadoop-daemon.sh start datanode
3、查看集群
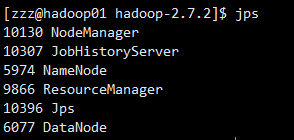
(1)使用jps
查看是否启动了,使用jps的命令,如果提示jps不生效,则可能是jdk安装的问题,或者是没有source /etc/profile
(2)web端查看(注意修改成自己的ip)
http://192.168.223.133:50070/dfshealth.html#tab-overview

(3)查看产生的Log日志

4、操作集群
(1)在HDFS问价系统上创建一个input文件夹
bin/hdfs dfs -mkdir -p /user/zzz/input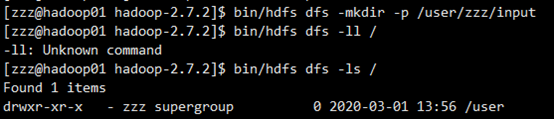
(2)将测试文件内容上传到文件系统
这里的input文件也可以自己创建一个
bin/hdfs dfs -put wcinput/wc.input /user/zzz/input/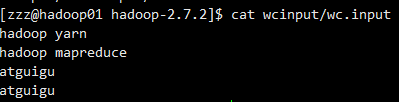
(3)查看上传文件是否正确
可以看到文件夹下有刚刚上传的wc.input文件
bin/hdfs dfs -ls /user/zzz/input/bin/hdfs dfs -cat /user/zzz/input/wc.input
(4)运行MapReduce程序
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/zzz/input/ /user/zzz/output
(5)查看输出结果
命令行查看 或者 web端查看
bin/hdfs dfs -cat /user/zzz/output/p*
(6)将输出文件内容下载到本地
bin/hdfs dfs -get /user/zzz/output/part-r-00000 ./wcoutput/(7)删除输出结果
bin/hdfs dfs -rm -r /user/zzz/output
5、注意
【关于NameNode需要注意什么?】
在格式化之前,要确定DataNode和NameNode的进程是否退出,再删除data和logs文件夹,对于第一次格式化不存在这个问题。
格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。所以,格式NameNode时,一定要先删除data数据和log日志,然后再格式化NameNode。


三、启动Yarn并运行MapReduce程序
Yarn由四个部分组成,ResourceManager(RM),NodeManager(NM),ApplicationMaster(AM),Container
1、配置集群
配置文件都在该目录下 : /opt/module/hadoop-2.7.2/etc/hadoop
(善于利用tab键)
(1)配置yarn-env.sh
echo $JAVA_HOME
(2)配置yarn-site.xml
<configuration><!-- Site specific YARN configuration properties --><!-- Reducer获取数据的方式 --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 指定YARN的ResourceManager的地址 --><property><name>yarn.resourcemanager.hostname</name><value>hadoop01</value></property>
</configuration>
(3)配置mapred-env.sh
和(1)一样,配置JAVA_HOME

(4)配置(对mapred-site.xml.template重新命名为) mapred-site.xml
mv mapred-site.xml.template mapred-site.xml![]()

<configuration><!-- 指定MR运行在YARN上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>
2、启动集群
(1)启动前必须保证NameNode,DataNode已启动
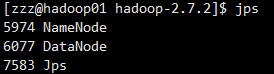
(2)启动ResourceManager
sbin/yarn-daemon.sh start resourcemanager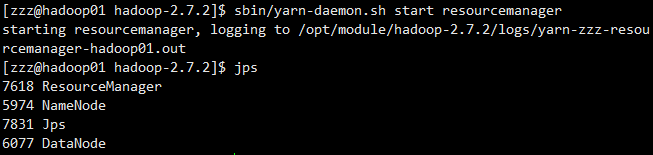
(3)启动NodeManager
sbin/yarn-daemon.sh start nodemanager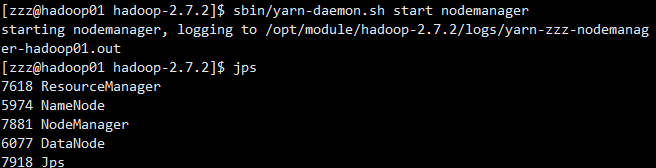
3、操作集群
(1)Yarn浏览器页面查看
http://192.168.223.133:8088/cluster

(2)删除文件系统上的output文件
bin/hdfs dfs -rm -R /user/atguigu/output
(3)执行MapReduce程序
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/zzz/input/ /user/zzz/ouput
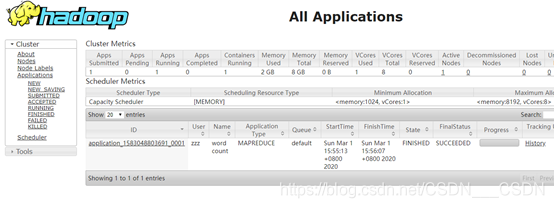
(4)查看运行结果
bin/hdfs dfs -cat /user/zzz/ouput/*
四、配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。
1、配置mapred-site.xml
![]()
在里面增加如下
<!-- 历史服务器端地址 --><property><name>mapreduce.jobhistory.address</name><value>hadoop01:10020</value></property><!-- 历史服务器web端地址 --><property><name>mapreduce.jobhistory.webapp.address</name><value>hadoop01:19888</value></property>
2、启动历史服务器
所有的启动脚本都在 /opt/module/hadoop-2.7.2/sbin 目录下
sbin/mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to /opt/module/hadoop-2.7.2/logs/mapred-zzz-historyserver-hadoop01.out3、查看历史服务器是否启动
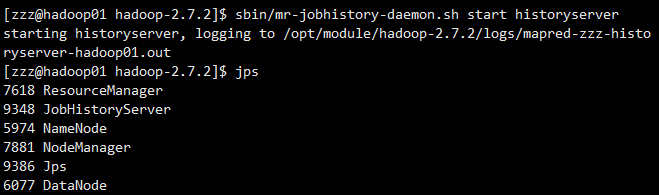
4、查看JobHistory
查看url:http://192.168.223.133:19888/jobhistory/,点击具体的JobID,会看到更加详细的页面

左侧栏:
Counters会记录你整个系统运行情况的各种技术信息
Configuration:配置信息
Map Tasks:包括Map阶段的名称,状态,开始时间,结束时间等
Reduce Tasks:包括Reduce阶段的名称,状态,开始时间,结束时间等

![]()

五、配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryManager
开启日志聚集功能具体步骤如下:
1、关闭NodeManager 、ResourceManager和HistoryManager
sbin/mr-jobhistory-daemon.sh stop historyserver
sbin/yarn-daemon.sh stop nodemanager
sbin/yarn-daemon.sh stop resourcemanager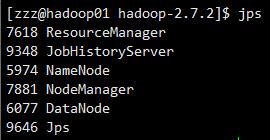

2、配置yarn-site.xml

![]()
![]()

3、启动NodeManager 、ResourceManager和HistoryManager
sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemon.sh start nodemanager
sbin/mr-jobhistory-daemon.sh start historyserver
4、删除HDFS上已经存在的输出文件

5、执行WordCount程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/zzz/input /user/zzz/output

6、查看日志

http://192.168.223.133:19888/jobhistory点击具体的JobID,点击logs,就可以看到更为具体的日志
进入/opt/module/hadoop-2.7.2/logs查看也可以。
六、配置文件说明
1、core-site.xml
HDFS中NameNode地址,指定Hadoop运行时产生文件的存储目录
2、hdfs-site.xml
指定HDFS副本的数量
3、yarn-site.xml(yarn目前只用到NodeManager,ResourceManager)
Reducer获取数据的方式,指定YARN的ResourceManager的地址,日志聚集功能使能,日志保留时间设置
4、mapred-site.xml
指定MR运行在YARN上(默认是local),历史服务器端地址,历史服务器web端地址
相关文章:
【C++】【一】结构体数组
demo7:函数份文件编写 swap.h #include <iostream> using namespace std;//函数的声明 void swap(int a, int b); swap.cpp #include "swap.h"//函数的定义 void swap(int a, int b) {int temp a;a b;b temp;cout << "a " << a …

Message、Handler、Message Queue、Looper之间的关系
2019独角兽企业重金招聘Python工程师标准>>> 在单线程模型下,为了解决线程通信问题,Android设计了一个通信机制。Message Queue(消息队列), 线程间的通信可以通过Message Queue、Handler和Looper进行信息交换。下面将对它们进行逐…

在linux中只将“桌面”修改成“Desktop”而系统仍然使用中文
在安装好centos系统以后,它的Desktop,Downloads等文件夹都是中文的,桌面,下载等,这样在使用cd命令时特别不方便 解决方法一:下载一个中文输入法,安装 解决方法二: 修改il8n文件&a…

Zabbix 3.0 从入门到精通(zabbix使用详解)
第1章 zabbix监控 1.1 为什么要监控 在需要的时刻,提前提醒我们服务器出问题了 当出问题之后,可以找到问题的根源 网站/服务器 的可用性 1.1.1 网站可用性 在软件系统的高可靠性(也称为可用性,英文描述为HA,High Avail…

MacBook如何用Parallels Desktop安装windows7/8
虽然MacBook真的很好用,不过在天朝的国情下,有很多软件还是仅支持IE和windows系统下才有。所以有必要为自己的MacBook装一个windows版本的系统,之前试过用Boot Camp来建立分区和安装win7,之后自己又用Parallels Desktop安装过win8…
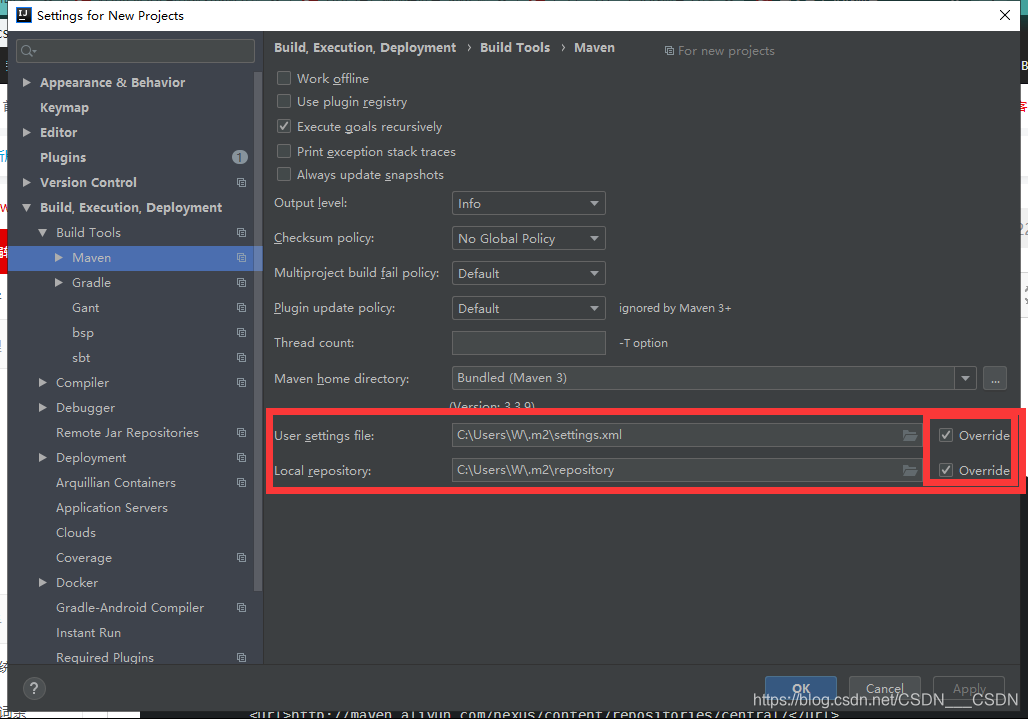
在IDEA 中为Maven 配置阿里云镜像源
打开IntelliJ IDEA->Settings ->Build, Execution, Deployment -> Build Tools > Maven 注意要勾选上override 自己创建一个settings.xml文件, 内容如下 <settings xmlns"http://maven.apache.org/SETTINGS/1.0.0"xmlns:xsi"http:/…

【匹配算法】渐进一致采样 PROSAC(PROgressive SAmple Consensus)
方法简介 渐进一致采样法1 (PROSAC) 是对经典的 RANSAC2 中采样的一种优化。相比经典的 RANSAC 方法均匀地从整个集合中采样,PROSAC 方法是从不断增大的最佳对应点集合中进行采样的。所以这种方法可以节省计算量,提高运行速度。 论文:https:…

阿里巴巴开源的 Blink 实时计算框架真香
Blink 开源了有一段时间了,竟然没发现有人写相关的博客,其实我已经在我的知识星球里开始写了,今天来看看 Blink 为什么香? 我们先看看 Blink 黑色版本: 对比下 Flink 版本你就知道黑色版本多好看了。 你上传 jar 包的时…
【地图API】收货地址详解2
上次讲解的方法是: 在地图中心点添加一个标注,每次拖动地图就获取地图中心点,再把标注的位置设置为地图中心点。可参考教程:http://www.cnblogs.com/milkmap/p/6126424.html 可能有开发者觉得,这个算法会有“延时”&am…
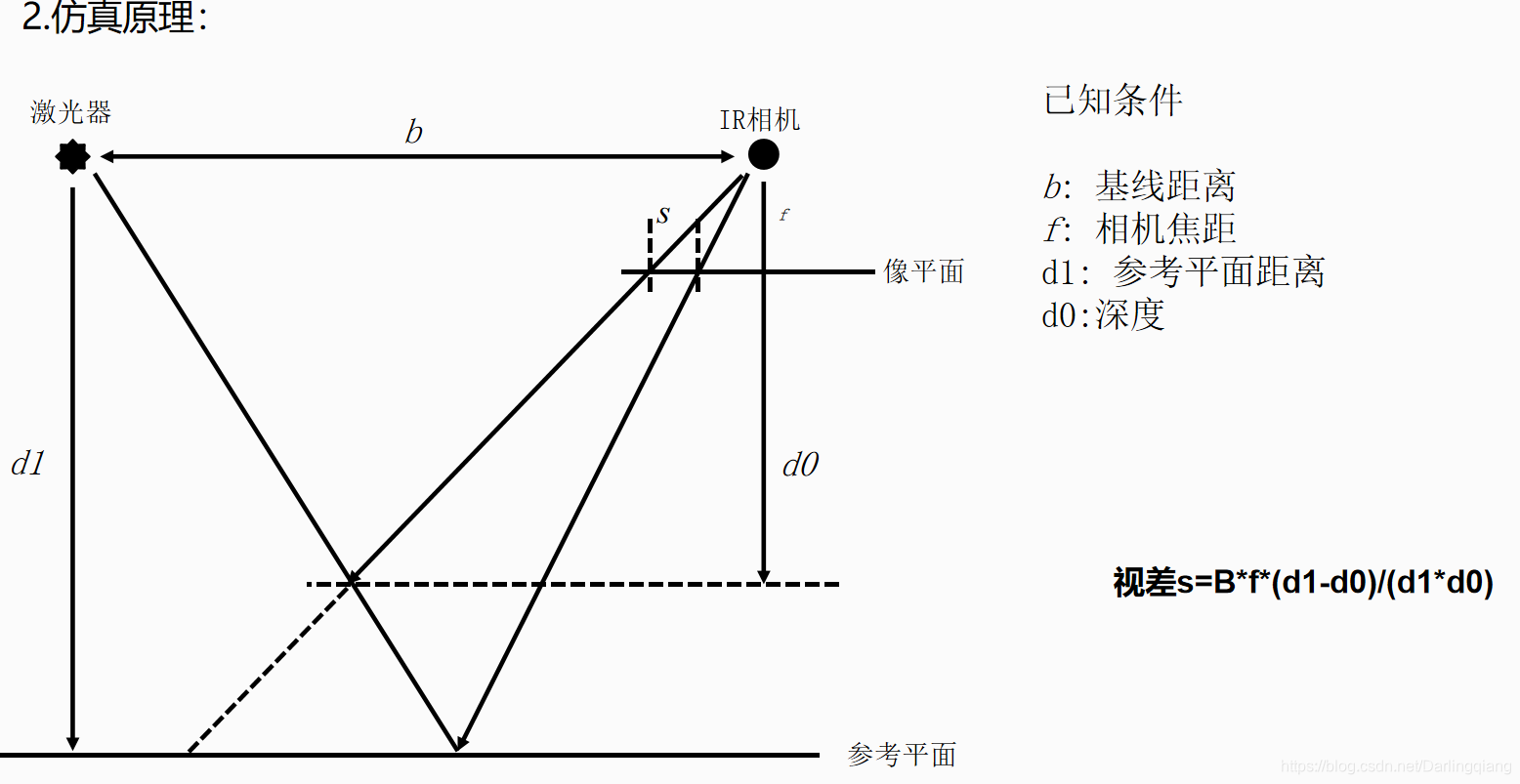
MATLAB【十三】————仿真函数记录以及matlab变成小结
part one:matlab 编程小结。 1.char 与string的区别,char使用的单引号 ‘’ ,string使用的是双引号“”。 2.一般标题中的输出一定要通过 num2str 处理,画图具体的图像细节参考:https://blog.csdn.net/Darlingqiang/ar…

IDEA HDFS客户端准备
在此之前:先进行在IDEA 中为Maven 配置阿里云镜像源 1、将资料包中的压缩包解压到一个没有中文的目录下 2、配置HADOOP_HOME环境变量 3、配置Path环境变量 4、创建一个Maven工程HDFSClientDemo 5、在pom.xml中添加依赖 <dependencies><dependency><g…
12 Java面向对象之多态
JavaSE 基础之十二12 Java面向对象之多态 ① 多态的概念及分类 多态的概念:对象的多种表现形式和能力多态的分类 1. 静态多态:在编译期间,程序就能决定调用哪个方法。方法的重载就表现出了静态多态。 2. 动态多态:在程序运行…
MATLAB【十四】————遍历三层文件夹操作
文件夹遍历 clear; clc; close all;%% crop the im into 256*256 num 0; %% num1 内缩3个像素 num 2 内缩6个像素 load(qualitydata1.mat) load(qualitydata2.mat)[data1_m,data1_n] size(qualitydata1); [data2_m,data2_n] size(qualitydata2);%% read image_name …

LoadRunner监控Linux
有的linux机器上安装rpc后会保存如下: test -z "/usr/local/sbin" || mkdir -p -- . "/usr/local/sbin"/bin/install -c rpc.rstatd /usr/local/sbin/rpc.rstatd make[2]: Nothing to be done for install-data-am. make[2]: Leaving directory…
scala while循环中断
Scala内置控制结构特地去掉了break和continue,是为了更好的适应函数化编程,推荐使用函数式的风格解决break和contine的功能,而不是一个关键字。 如何实现continue的效果 Scala内置控制结构特地也去掉了continue,是为了更好的适应…
05-04-查看补丁更新报告
《系统工程师实战培训》 -05-部署补丁管理服务器 -04-查看补丁更新报告 作者:学 无 止 境QQ交流群:454544014///安装报表工具(在100-Admin01上面安装如下工具,方便查看WSUS更新补丁报告!)Microsoft System CLR Types f…
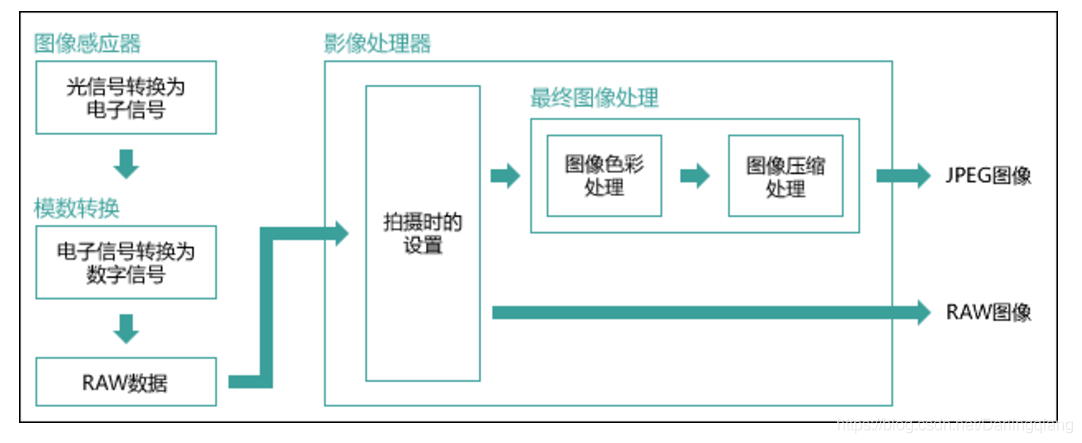
ISP【三】———— raw读取、不同格式图片差异
part zero: 如何处理.raw格式数据,读取和转化 matlab读取raw图 (mark读取图片尺寸和位数均可设置,图片尺寸M,N,图片数据类型8bit,16bit改成uint16) clear; clc; close all; % % rotpath imread(D:\matlab\ncc_ive…
深度学习 - 相关名词概念
2019独角兽企业重金招聘Python工程师标准>>> Neural Network 神经网络 Weights 权重 Bias 偏移 Activation Function 激活函数, 用于调整每个神经的输出, 有如下几个常用的函数种类 ReLU Sigmoid Optimizer 优化器 Adam Input Layer, Hidden Layer, Output Layer 输…
HDFS的API操作
准备工作:IDEA > HDFS客户端准备 目录 文件上传 文件下载 文件夹删除 修改文件名称 查看文件详情 文件和文件夹的判断 完整代码 文件上传 注意conf.set("dfs.replication","2");的位置,位置不一样,设置的副本…
微信小程序-锚点定位+内容滑动控制导航选中
之前两篇文章分别介绍了锚点定位和滑动内容影响导航选中,这里我们就结合起来,实现这两个功能! 思路不再多说,直接上干货! WXML <view class"navigateBox"><view class"title"><ima…
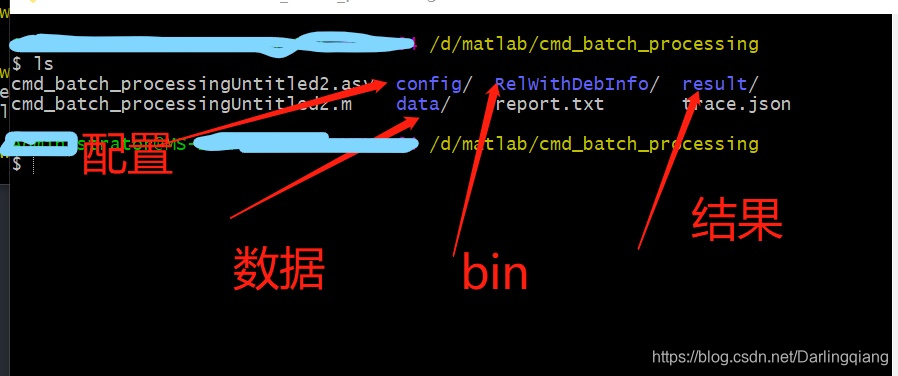
MATLAB【十四】————调用深度库生成exe,批量运行三层文件夹下图片,保存结果
运行路径:D:\matlab\cmd_batch_processing 文件夹架构: clear; clc; close all;%% crop the im into 256*256oriDataPath D:\matlab\cmd_batch_processing\data\; targetPathOri D:\matlab\cmd_batch_processing\result\;report_path D:\matlab\cm…
JDK1.8学习
2019独角兽企业重金招聘Python工程师标准>>> List<OrderGoodsDetail> olist BeanMapper.mapList(list,OrderGoodsDetail.class);List<String> list2 Arrays.asList("123", "45634", "7892", "abch", "s…
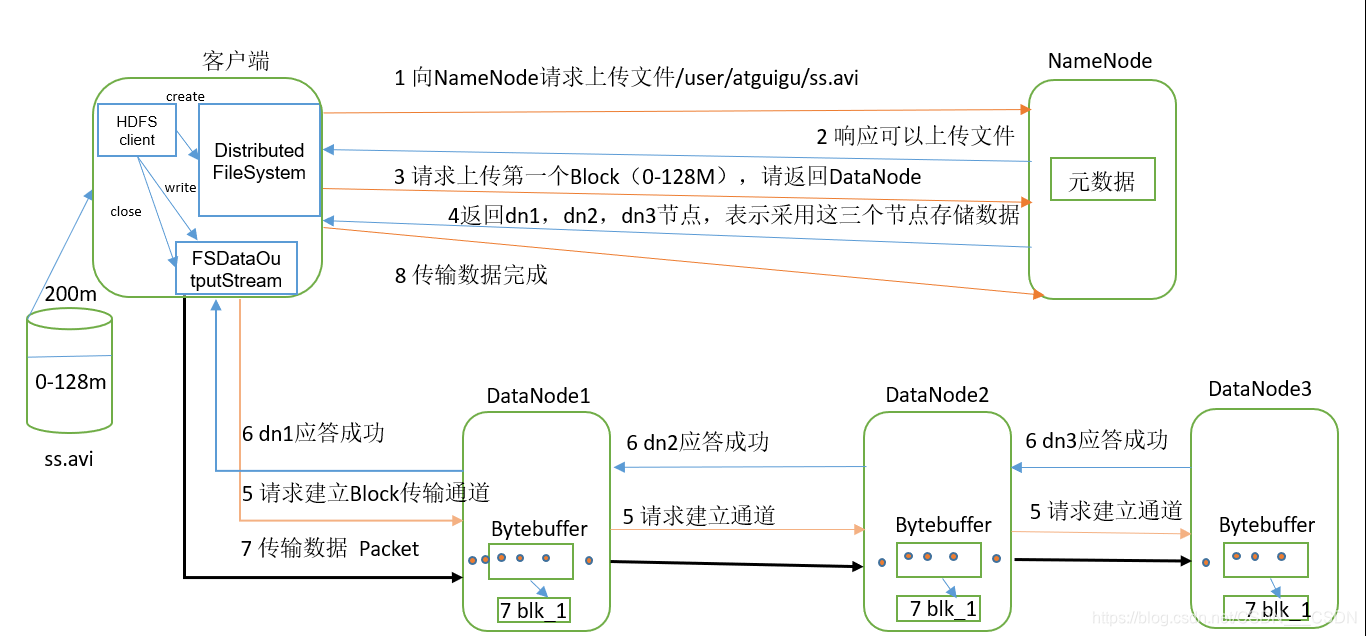
HDFS的数据流
目录 HDFS写数据流程 剖析文件写入 网络拓扑-节点距离计算 机架感知(副本存储节点选择) Hadoop2.7.2 副本节点选择 HDFS读数据流程 HDFS写数据流程 剖析文件写入 1)客户端通过Distributed FileSystem模块向NameNode请求上传文件&#x…
Js----闭包
1、闭包的概念:(我找了很多,看大家的理解) A:闭包是指可以包含自由(未绑定到特定对象)变量的代码块; 这些变量不是在这个代码块内或者任何全局上下文中定义的,而是在定义代码块的环境中定义(局部…
【C++】【四】企业链表
// 企业链表.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。 // 链表改进版 企业常用#include <iostream> #include<stdlib.h>//链表小节点 不包含数据域 typedef struct linknode {struct linknode* next; }linknode; //链表节点 数据指…

GoldenGate的Logdump工具使用简介
Logdump工具是GoldenGate提供的一个用于查询、分析、过滤、查看和保存存储在trail文件或extract文件中的数据的工具。1、启动Logdump工具[oraclerhel6 ~]$ cd /ogg [oraclerhel6 ogg]$ ./logdumpOracle GoldenGate Log File Dump Utility for Oracle Version 12.2.0.1.1 OGGCOR…

scala惰性函数
惰性计算(尽可能延迟表达式求值)是许多函数式编程语言的特性。惰性集合在需要时提供其元素,无需预先计算它们,这带来了一些好处。首先,您可以将耗时的计算推迟到绝对需要的时候。其次,您可以创造无限个集合…
计算机组成原理-第3章-3.1
|--总线:本质上就是一组连线,通路 |--发展过程: 分散连接时代: 运算器为中心 ↓ 存储器为中心 ↓ 中断,DMA的出现修正 ↓ 依旧无法解决效率问题 总线连接时代: 以CPU为核心,双总线:M…
【C++】【三】单向链表
// 单向链表.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。 //#include <iostream> #include<stdlib.h>typedef struct LINKNODE {void* data;struct LINKNODE* next; }linknode;typedef struct LINKLIST {LINKNODE* head;int size; }lin…
gulp相关说明
1.当你按下ctrls 或切换到浏览器,浏览器将会会自动刷新 如果你修改的是html文件将会刷新网页如果你修改的是css或less,这个less文件或css文件将会被重载而不是刷新整个页面(这个特性在写单页面应用时尤为实用)2.模板引入 考虑以下…