BigData NoSQL —— ApsaraDB HBase数据存储与分析平台概览
一、引言
时间到了2019年,数据库也发展到了一个新的拐点,有三个明显的趋势:
越来越多的数据库会做云原生(CloudNative),会不断利用新的硬件及云本身的优势打造CloudNative数据库,国内以阿里云的Cloud HBase、POLARDB为代表,此块文章会有一定的引述,但不是本文的重点。
NoSQL正在解决BigData领域的问题。根据Forrester NoSQL的报告,BigData NoSQL是提供 存储、计算处理、支持水平扩展、Schemaless以及灵活的数据模型,特别提到需要支持复杂计算,一般通过集成Spark或者实现单独的计算引擎实现。Cassandra商业化公司Datastax提供的产品是直接在Cassandra之上集成了Spark,另外ScyllaDB公司首页的宣传语就是The Real-Time Big Data Database。大数据的5V特性,包括 Volume:数据量大,包括采集、存储和计算的量都非常大;Variety:种类和来源多样化,包括结构化、半结构化和非结构化数据;Value:数据价值密度相对较低,或者说是浪里淘沙却又弥足珍贵;Velocity:数据增长速度快,处理速度也快,时效性要求高;Veracity:数据的准确性和可信赖度,即数据的质量需要高。5V特性可以使用BigData NoSQL数据库很好的满足,且又能满足实时的写入,分析及展现。
越来越多的公司或者产品都是融合多个能力,Strapdata公司把Cassandra及ElasticSearch的能力融合在一起;Datastax直接在Cassandra之上集成了Spark;SQLServer也是融合了Spark,打造Native Spark满足DB计算能力外延的商业诉求。
阿里云HBase经过公共云两年(单独的HBase在阿里内部已经发展快9年)的发展,融合开源Apache HBase、Apache Phoenix、Apache Spark、Apache Solr等开源项目,再加上一系列自研特性,满足 【一体化数据处理平台,提供一站式能力】 , 基本架构如下:
我们是站在Apache巨人的肩膀上,自研了 ApsaraDB Filesystem、HBase冷热分离、SearchIndex、SparkOnX、BDS等模块,优化了HBase、Phoenix、Spark等内核一些patch,并反馈到社区,维护打造了多模服务、数据工作台等一些列的平台能力。自研部分是我们平台核心的核心竞争力,每一层每一个组件都是我们精心打造,满足客户数据驱动业务的实际需求。为了降低客户的准入门槛,我们在Github上提供了Demo支持:aliyun-apsaradb-hbase-demo,欢迎大家关注,并贡献代码。接下来笔者会介绍各层,力求简单通俗,文中有大量的链接以衍生阅读。
二、业务视角及数据流
作为一个存储计算平台,价值在满足不同的业务需求。见下图:
此图描述了数据的来源、通道到沉淀到云HBase平台,再通过平台提供的Spark引擎去挖掘价值反馈给业务系统。此类似一个循环系统,在阿里内部形象称为【业务数据化,再数据业务化】。

结合架构图及业务图,此平台融合了 存储(包括实时存储及离线存储)、计算、检索等技术。整个系统都打造在ApsaraDB Filesystem统一文件层之上,把检索通过Phoenix的SearchIndex包装以降低易用性,打造领域引擎满足领域的需求,内置BDS(数据通道)实时归档数据到列存,再通过Spark引擎挖掘价值。
详细参考:【选择阿里云数据库HBase版十大理由请添加链接描述】
三、统一文件访问层
ApsaraDB Filesystem(简称ADB FS)以Hadoop FileSystem API为基础构建了云HBase生态文件层底座。面向HBase生态提供了无感知的混合存储能力,极大简化了HBase生态接入云端多存储形态的复杂环境。支持OSS、阿里云HDFS、基于云盘或者本地盘构建的HDFS以及基于共享云盘构建的系统。每种分布式文件系统所用的硬件不同、成本不同、延迟不同、吞吐量不同(这里不展开)。我们可以不断扩展,只要添加一个实现xxxFileSystem即可。基于OSS直接实现的FS是无法具备原子性的元数据管理能力的,实现方案是在HDFS的namenode存元数据,实际的存储存放在OSS之上。对Rename操作只需要移动元数据,所以非常轻量。

四、HBase KV层
HBase是基于Bigtable在hadoop社区的开源实现,提供了如:稀疏宽表、TTL、动态列等特性。HBase在阿里已经发展9年,已经有数位PMC及Committer,可以说在国内阿里在HBase的影响力还是数一数二的。社区也有不少的Patch也是阿里贡献。在18年,云HBase首家商业化了HBase2.0,并贡献了数十个BugFix给社区。有不少客户单独使用HBase API满足业务需求,也有不少客户使用Phoenix NewSQL层,NewSQL层提升易用性及提供了很多好用的功能。在HBase层面,除了修复社区的Bug以外,也做了几个较大的特性。
在对比关系型数据方面,HBase也有天然的优势,参考:对比MySQL,一文看透HBase的能力及使用场景
冷热分离
冷热分离可以降低存储成本66%左右。广泛应用于车联网、冷日志等场景下。我们把冷数据存放到OSS之上,且用户还可以使用HBase的API访问。基本原理是:把Hlog存在HDFS之上,再把冷的HFile存放在OSS之上。
GC优化
GC一直是Java应用中讨论的一个热门话题,尤其在像HBase这样的大型在线存储系统中,大堆下(百GB)的GC停顿延迟产生的在线实时影响,成为内核和应用开发者的一大痛点。平台实现了CCSMap新的内存存储结构,结合offheap及新的ZenGC等一列的优化,在生产环境young GC时间从120ms减少到15ms,在实验室进一步降低到5ms左右。可以参考文章:如何降低90%Java垃圾回收时间?以阿里HBase的GC优化实践为例
五、检索层
HBase底层基于LSM,擅长前缀匹配和范围查找,数据模型上属于行存,大范围扫描数据对系统影响很大。我们知道,用户的需求往往是各式各样,不断变化的。对于要求高TPS,高并发,查询业务比较固定且简单的场景,HBase可以很好满足。更复杂一些,当用户对同一张表的查询条件组合有固定多个时,可以通过二级索引的方式来解决,但是二级索引有写放大问题,索引数量不能太多,一般建议不超过10个。当面对更复杂的查询模式,比如自由条件组合,模糊查询,全文查询等,用当前的索引技术是无法满足的,需要寻求新的解决方案。我们容易想到,搜索引擎,比如Lucene、Solr以及ElasticSearch,是专门面向复杂查询场景的。为了应对各种复杂的查询需求,搜索引擎运用到了大量跟LSM Tree十分不同的索引技术,比如倒排、分词、BKD Tree做数值类型索引、roaring bitmap实现联合索引、DocValues增强聚合和排序等。使用搜索引擎的技术来增强HBase的查询能力是一个十分值得深入探索的技术方向。
当前用户要想实现,复杂查询,只能重新购买新的搜索集群,通过导数据的方式将数据导入到新的搜索服务中。这种方式存在很多这样那样的问题:维护成本比较高,需要购买在线数据库,分析数据库和数据传输服务;学习门槛高,需要同时熟悉至少上诉三种服务;无法保证实时性,在线库入库和检索库入库效率不匹配;数据冗余存储,在线库索引数据和结果数据设计的所有数据都需要导入;数据一致性难保证,数据乱序问题十分常见,特别是对于分布式在线库更是如此。云HBase引入Solr,并在产品和内核上做了一系列工作,将其打造成统一的产品体验,一揽子解决了前述所有问题。用户在控制台上一键可以开通检索服务,参考文章:云HBase发布全文索引服务,轻松应对复杂查询。

检索服务的架构如上图所示,最底层是分布式文件系统的统一抽象,HBase的数据和Solr中的数据都会存储在分布式文件系统中。最上层是分布式协调服务Zookeeper,HBase、Indexer、Solr都是基于其实现分布式功能。Indexer实现了存量HBase数据的批量导入功能,有针对性地实现了数据批量导入的分布式作业机制。Indexer服务也实现了实时数据的异步同步功能,利用HBase的后台Replication机制,Indexer实现了Fake HBase功能,接收到HBase的数据后,将其转换为Solr的document,并写入solr。针对HBase写入速度比Solr快的问题,我们设计并实现了反压机制,可以将Solr中数据的延迟控制在用户设定的时间范围内,该机制同时也避免了HLog消费速度过慢的堆积问题。实时同步和批量导入可以同时运行,我们通过保序的时间戳保证了数据的最终一致性。为了提高产品的易用性,我们还基于Phoenix 实现了检索服务的SQL封装,并在存储查询等方面做了一系列优化升级,该部分在下个章节将会介绍。
六、NewSQL Phoenix
Phoenix是HBase之上的SQL层,Phoenix让HBase平台从NoSQL直接进化到了NewSQL。在HBase的基础之上,再支持了Schema、Secondary Indexes、View 、Bulk Loading(离线大规模load数据)、Atomic upsert、Salted Tables、Dynamic Columns、Skip Scan等特性。目前云上最大客户有200T左右,且50%+的客户都开通了Phoenix SQL服务。我们修复了社区数十个Bug及提了不少新特性,团队也拥有1位Committer及数位contributor。在18年我们在充分测试的基础上,先于社区正式商业化了Phoenix5.0,并支持了QueryServer,支持轻量的JDBC访问。同时,社区的5.0.1也将由我们推动发布。
Phoenix本身我们做了一系列稳定性,性能等方面的优化升级,主要有:客户端优化MetaCache机制,大数据量简单查询性能提升一个数量级;索引表回查主表,使用lookupjoin的方式优化,性能提升5到7倍;轻客户端优化batch commit,性能提升2到3倍;解决Phoenix时区问题,提高易用性,降低数据一致性问题概率;禁用DESC,扫全表等有风险功能;实现大批量数据导入的Bulkload功能;等等。这些稳定性和性能方面的提升,在用户侧得到了很好的反馈。

Phoenix目前基本的架构如图所示,我们让Phoenix支持了HBase和Solr双引擎,用户可以使用SQL实现对HBase和Solr数据的管理和查询,大大提高了系统的易用性。Solr和HBase之间的同步机制可以参考上节。在支持复杂查询方面,我们设计并实现了一种新的索引:Search Index,使用方式跟Phoenix的Global Index类似,主要区别在于Search Index的索引数据存储在Solr里面,而Global Index的索引数据是一张单独的HBase表。直接通过SQL管理Search Index的生命周期、数据同步和状态,自动映射数据字段类型,并通过SQL支持复杂查询,这极大降低了用户的使用门槛。Search Index可以统一根据HBase和Solr的特性做优化,由于原表在HBase中可以通过RowKey高效查询,Solr中只需要存储作为查询条件的字段的索引数据,查询字段的原数据不需要存储在Solr中,表中的非查询字段则完全不需要存储到Solr中。相对于用户单独购买检索产品,并同步数据的方案,Search Index可以大大降低存储空间。同时,根据索引特性,Phoenix在做执行计划优化时,可以动态选择最优的索引方案。
我们还打造了一个系列的文章,这些文章是很多国内用户熟悉和学习Phoenix的入门资料,在社区里面也收获了较高的影响力,参考 Phoenix入门到精通
七、多模领域层
数据类型有表格、文档、宽表、图、时序、时空等不同的类型。云HBase之上打造了 HGraphDB分布式图层、OpenTSDB分布式时序层、Ganos分布式空间层,分别满足3大子场景的诉求。每个都是分布式的组件,具备PB级别的存储、高并发读写及无限扩展的能力。
HGraphDB
HGraphDB是云HBase完全自研的组件。HGraphDB基于Tinker pop3实现,支持集成Tinker pop3全套软件栈以及Gremlin语言。HGraphDB是一个OLTP图库,支持schema以及顶点和边的增删改查还有图的遍历。图数据库HGraphDB介绍
OpenTSDB
OpenTSDB是社区在HBase的基础之上提供的时序引擎,以HBase为底座,满足PB级别的时序存储需求。团队做了大量优化,为了提升稳定性,其中【时间线压缩优化】是一个比较重要的优化,见:云HBase之OpenTSDB时序引擎压缩优化
Ganos
Ganos取名于大地女神盖亚(Gaea)和时间之神柯罗诺斯(Chronos),代表着“时空” 结合。Ganos空间算子增强、时空索引增强、GeoSQL扩展等,与Spark结合支持大规模遥感空间数据在线分析与管理。详细参考文章:阿里云时空数据库引擎HBase Ganos上线,场景、功能、优势全解析
八、列式存储
行列混合HTAP一直是各大数据库梦寐追求大统一的技术,类似于M理论想统一量子力学与万有引力。目前看起来一份存储难以满足各种诉求,通用的做法是行存与列存的数据分开存,实现手段一种是通过同步的方案把行存的数据再转存一份列存,另一种是通过raft等变种协议的手段实现行列副本同时存在。
HBase擅长在线查询场景,底层的HFile格式实际还是行存,直接Spark分析HBase表在大范围查询的情况下性能一般(Spark On HBase也有很多优化点)。在这样的背景下我们构建了HBase的实时HLog增量同步归档到列存的链路,来有效满足用户对于HBase数据分析的需求。列存的压缩比比行存高,增加部分存储成本,有效的增强分析能力,用户是能够接受的。HBase搭配列存可以有效的驱动用户业务的发展,列存分析后的结果数据回流到HBase支持业务,让用户业务在HBase平台中快速迭代。在列存之中,也有类似LSM的 Delta+全量的,比如Kudu以及 Delta Lake。云HBase参考了Delta Lake及Parquet技术,提供更加高效的一体化分析。
Parquet
Parquet的灵感来自于2010年Google发表的Dremel论文,文中介绍了一种支持嵌套结构的存储格式,并且使用了列式存储的方式提升查询性能,目前Parquet已经是大数据领域最有代表性的列存方式,广泛应用于大数据数据仓库的基础建设。
Delta
Delta原本是Spark的商业公司Databriks在存储方面做的闭源特性,偏向实时读写,已于近期开源,核心是解决了大数据分析场景中常见的数据更新的问题。具体做法按列式格式写数据加快分析读,增量更新数据 delta 则采取行式写入支持事务和多版本,然后系统通过后台不断地进行合并。
一键同步
用户可以根据自身的业务需求进行转存,对于对实时性要求比较高的用户,可以选择实时同步的方式,BDS服务会实时解析HLog并转存到Delta,用户可以通过Spark对Delta直接进行查询;而对于离线场景的转存,用户可以在控制台上根据自身业务需要进行配置,可以自定义在业务低峰期进行转存,也可以选择是否进行增量和全量合并,后台调度系统会自动触发转存逻辑。
九、分析层
在云HBase平台里面沉淀了不少数据,或者在进入云HBase平台的数据需要流ETL,参考业界的通用做法,目前最流行的计算引擎是Spark,我们引入Apache Spark来满足平台的数据处理需求。Spark采取的是DAG的执行引擎,支持SQL及编程语言,比传统的MR快100倍,另外支持流、批、机器学习、支持SQL&Python&Scala等多种编程语言。云HBase平台提供的能力有流式的ETL、Spark on HBase(也包括其它数据库)及HBase数据转为列存后的分析。为了满足Spark低成本运行的需求,我们即将支持Serverless的能力。Spark在数据库之间,处于一个胶水的作用,平台通过Spark打造数据处理的闭环系统以核心客户的核心问题,比如点触科技的游戏大数据平台
支持流式处理
大部分的系统之中,数据经过中间件之后需要一些预处理再写入到HBase之中,一般需要流的能力。Spark Streaming提供秒级别的流处理能力,另外Structured Streaming可以支持更低时延。平台支持Kafka、阿里云LogHub、DataHub等主要的消息通道。关于很多从业者关心的Spark跟Flink对比的问题,其一,Flink基于pipeline模式的流比Spark基于mini batch的流在延迟上要低,功能上也更强大,但是大部分用户很难用到毫秒级和高阶功能,Spark的流满足了大部分场景;其二,Spark生态要比Flink成熟,影响力也更大。
Spark On X
分析层不仅仅支持HBase、Phoenix以外,也包括POALRDB、MySQL、SQLServer、PG、Redis、MongoDB等系统。比如:归档POLARDB数据做分析,Spark On X支持schema映射、算子下推、分区裁剪、列裁剪、BulkGet、优先走索引等优化。算子下推可以减少拉取DB的数据量,以及减少DB的运算压力,从而提高Spark On X的运算性能。HBase一般存储海量数据,单表可达千亿、万亿行数据,Spark On HBase的rowkey过滤字段下推到HBase,查询性能可达毫秒级别。
十、数据工作台
在线DB一般是业务系统连接DB的,但离线的作业与在线的平台不一样,需要提供Job的管理及离线定时运行,另外还需要支持交互式运行。在云HBase平台上,我们提供了 【数据工作台】来满足这一需求。数据工作台能力有:资源管理、作业管理、工作流、回话管理、交互式查询、及作业的告警。作业可以是jar包、python脚本、SQL脚本等;工作流可以把多个作业关联在一起,并可以周期性或者指定固定时间运行;回话管理可以启动一个在线的交互式Spark回话满足交互式查询的诉求;交互式查询可以满足在线运行 sql脚本、python及scala脚本。


十一、DBaaS
云HBase构建了一整套的管理系统,支持全球部署、监控报警(包括云监控及原生自带监控页面)、在线扩容、安全白名单、VPC网络隔离、在线修改配置、公网访问、小版本在线一键升级、分阶段低峰期MajorCompaction优化、自动检测集群可用状态紧急报警人工干预、磁盘容量水位报警等等运维操作及自动化优化。 平台提供7*24小时人工答疑及咨询,可直接咨询钉钉号 云HBase答疑。除此之外,打造了2大企业级特性,备份恢复、BDS服务
备份恢复
HBase的数据也是客户的核心资产,为了保障客户的数据不被意外删除(经常是用户自己误删)时,我们内置了备份恢复的服务。此服务是直接独立于HBase内核,单独进程保障的。基本原理是全量数据拉HFile,增量数据拉Hlog。满足了数百TB数据的备份恢复,实时备份的延迟时间在数分钟以内。数据恢复可以满足按照时间点恢复,数百TB规模的集群基本在2天内完成恢复。不管是备份还是恢复都不影响原来的集群继续提供服务。其中细节点也较多,可以参考访问:云HBase备份恢复,为云HBase数据安全保驾护航
BDS服务
数据迁移是一个重的事项,尤其当类似如HBase数十TB数据的迁移。我们专门为云HBase打造数据迁移的服务,命名为BDS。此服务满足各类数据迁移及同步的场景,包括自建HBase集群迁移上阿里云HBase、跨地域迁移,例如从青岛机房迁移到北京机房、HBase1.x升级HBase2.x、网络环境经典网络切换成VPC等
十二、后记
存储、检索、分析是BigData三大核心的能力,也是BigData NoSQL着力打造的核心能力,通过深度整合,更好解决客户风控、画像等数据驱动业务的问题。阿里云云HBase团队,基于云上环境的种种特性,打造了Native的众多优势,目前服务了数千家中小型企业。另外,为了服务中国广大的开发者,自从18年5月,发起成立了【中国HBase技术社区】,举办线下meetup 9场次,邀请内外部嘉宾数十人,报名2801人,公众号1.1w人,直播观看2.1+w人,影响数万企业。特别为开发者提供免费版新人1个月的免费试用,以方便其开发学习以及交流。
未来,我们将继续紧紧贴合云上用户需求打磨产品,打造核心竞争力,提升易用性,保障系统稳定性,以及引入Serverless特性以进一步降低成本。
If not now, when? If not me, who?
转载于:https://blog.51cto.com/14031893/2398524
相关文章:

ubuntu clion 创建桌面快捷方式
ubuntu clion 创建桌面快捷方式 首先在终端下输入 cd /usr/share/applications/进入applications目录下,建立一个clion.desktop文件 sudo touch clion.desktop然后在vim命令下编辑该文件 sudo vim clion.desktop进入vim后,按i插入开始编辑该文件&…

Flex 布局:语法篇
2019独角兽企业重金招聘Python工程师标准>>> 布局的传统解决方案,基于盒状模型,依赖 display 属性 position 属性 float 属性。它对于那些特殊布局非常不方便,比如,垂直居中就不容易实现。 2009年,W3C 提…
特征运动点估计
cv::Mat getRansacMat(const std::vector<cv::DMatch>& matches, const std::vector<cv::KeyPoint>& keypoints1, const std::vector<cv::KeyPoint>& keypoints2, std::vector<cv::DMatch>& outMatches) {// 转换特征点格式std::vecto…

Vue+Element-ui+二级联动封装组件
通过父子组件传值 父组件: 1 <template>2 <linkage :citysList"citysList" :holder"holder" saveId"saveId"></linkage>3 </template>4 <script>5 import linkage from ./common/linkage6 export de…
MOG2 成员函数参数设定
pMOG2->setDetectShadows(true); // 背景模型影响帧数 默认为500 pMOG2->setHistory(1000); // 模型匹配阈值 pMOG2->setVarThreshold(50); // 阴影阈值 pMOG2->setShadowThreshold(0.7);前景中模型参数,设置为0表示背景,255为前景ÿ…

webpack 大法好 ---- 基础概念与配置(1)
再一次见面! Light 还是太太太懒了,距离上一篇没啥营养的文章已经过去好多天。今天为大家介绍介绍 webpack 最基本的概念,以及简单的配置,让你能快速得搭建一个可用的 webpack 开发环境。 webpack的安装 webpack 运行于 node 环境…

Zookeeper迁移(扩容/缩容)
zookeeper选举原理在迁移前有必要了解zookeeper的选举原理,以便更科学的迁移。快速选举FastLeaderElectionzookeeper默认使用快速选举,在此重点了解快速选举:向集群中的其他zookeeper建立连接,并且只有myid比对方大的连接才会被接…
SVO Without ROS环境搭建
Installation: Plain CMake (No ROS) 首先,建立工作目录:workspace,然后把下面的需要的都在该目录下进行. mkdir workspace cd workspace Boost - c Librairies (thread and system are needed) sudo apt-get install libboost-all-dev Eige…
BackgroundSubtractorGMG 背景建模
#include <opencv2/bgsegm.hpp> #include <opencv2/video.hpp> #include <opencv2/opencv.hpp> #include <iostream> #include <sstream> using namespace cv; using namespace std; using namespace bgsegm; // GMG目标建模检测 void detectBac…
启动webpack-dev-server只能本机访问的解决办法
修改package.json的dev启动设置,增加--host 0.0.0.0启动后localhost更换为本机IP即可访问
TCP/IP:IP选项处理
引言 IP输入函数要对IP 进行选项处理,。RFC791和1122规定了IP选项和处理规则。一个IP首部可以跟40个字节的选项。 选项格式 选项的格式,分为两种类型,单字节和多字节。 ip_dooptions函数 这个函数用于判断分组转发。用常量位移访问IP选项字段…
【SVO2.0 安装编译】Ubuntu 20.04 + Noetic
ways one 链接: https://pan.baidu.com/s/1ZAkeD64wjFsDHfpCm1CB1w 提取码: kxx2 (downloads and use idirectly) ways two: [SVO2-OPEN: https://github.com/uzh-rpg/rpg_svo_pro_open](https://github.com/DEARsunshine/rpg_svo_pro_open)git挂梯子 如果各位终端无法挂梯…
人眼目标检测初始化
// 初始化摄像头读取视频流cv::VideoCapture cap(0);// 宽高设置为320*256cap.set(CV_CAP_PROP_FRAME_WIDTH, 320);cap.set(CV_CAP_PROP_FRAME_HEIGHT, 256);// 读取级联分类器// 文件存放在opencv\sources\data\haarcascades bool flagGlasses false;if(flagGlasses){face_ca…
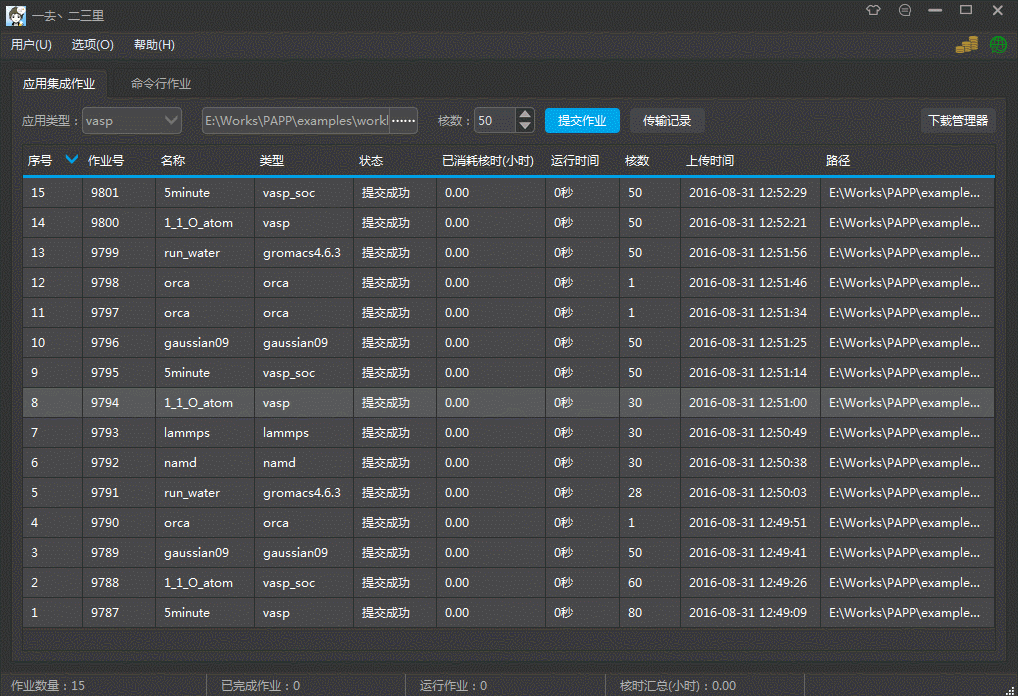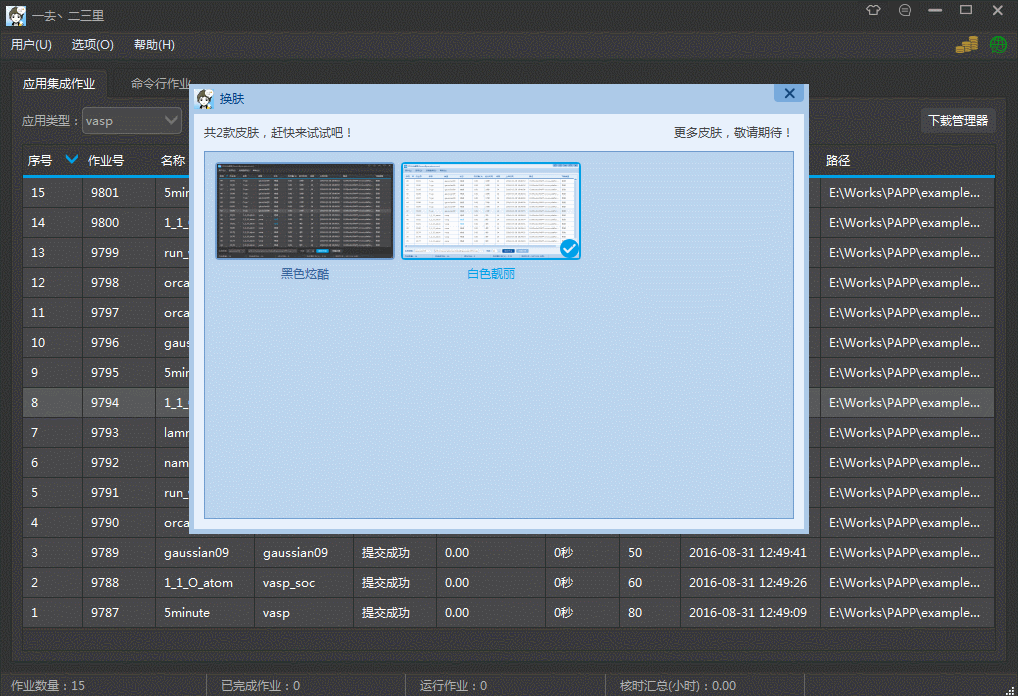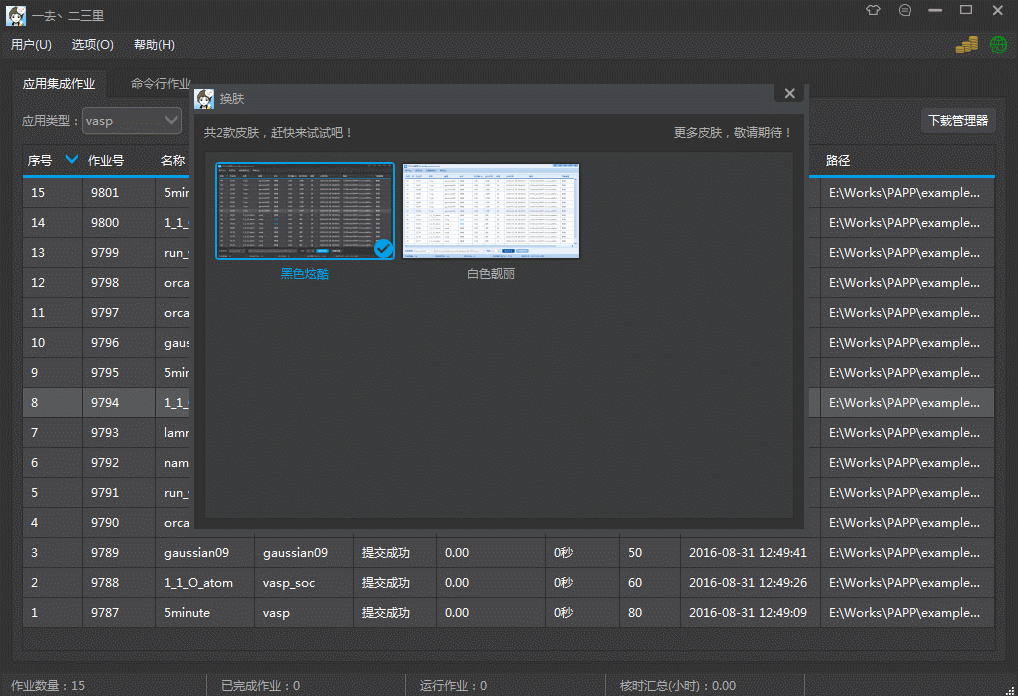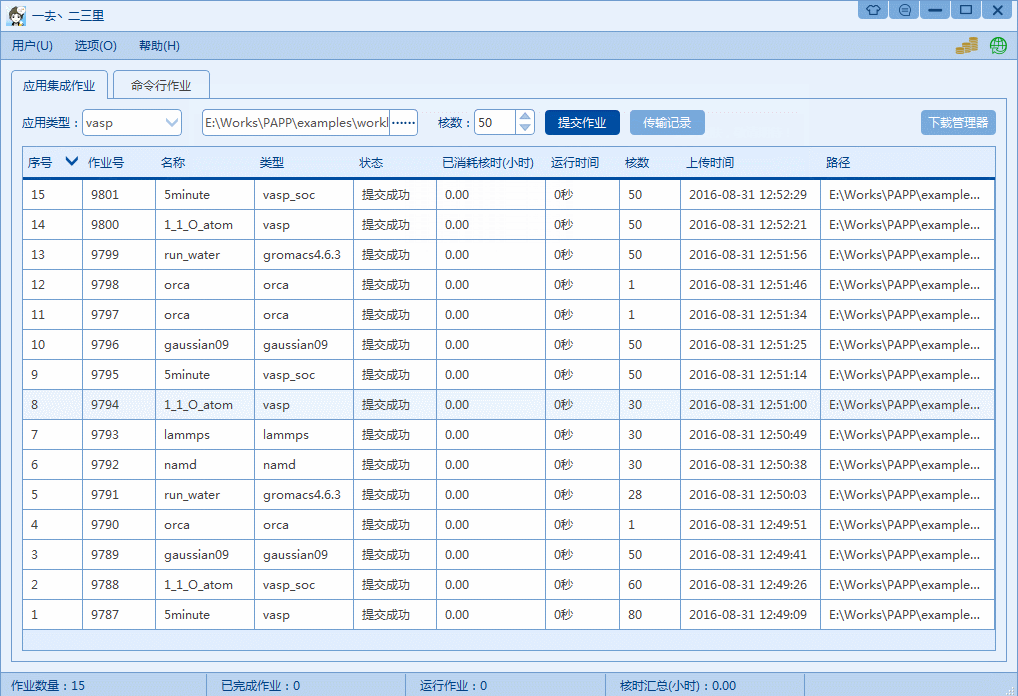
Qt之界面换肤
简述 常用的软件基本都有换肤功能,例如:QQ、360、迅雷等。换肤其实很简单,并没有想象中那么难,利用前面分享过的QSS系列文章,沃我们完全可以实现各种样式的定制! 简述实现原理效果新建QSS文件编写QSS代码加…
mongDB的常用操作总结
目录 常用查询:查询一条数据查询子元素集合:image.idgte: 大于等于,lte小于等于...查询字段不存在的数据not查询数量:常用更新更新第一条数据的一个字段:更新一条数据的多个字段:常用删除删除:常用查询: 查询一条数据 精确匹配is Query(Criteria.where("id").is(id))…
【GTSAM】GTSAM学习
1 what GTSAM ? GTSAM 是一个在机器人领域和计算机视觉领域用于平滑(smoothing)和建图(mapping)的C库。它与g2o不同的是,g2o采用稀疏矩阵的方式求解一个非线性优化问题,而GTSAM是采用因子图(f…
人脸、人眼检测与跟踪
#include <opencv2/opencv.hpp> #include <iostream> #include <vector> using namespace cv;CascadeClassifier face_cascade; CascadeClassifier eye_cascade;// 人眼检测 int detectEye(cv::Mat& im, cv::Mat& tpl, cv::Rect& rect) {std::v…
linux下jdk简单配置记录
记录哈,搭建环境的时候,copy使用方便。 vim /etc/profile export JAVA_HOME/usr/java/jdk1.7.0_79export PATH$JAVA_HOME/bin:$PATHexport CLASSPATH.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jarexport JRE_HOME$JAVA_HOME/jreexport LANGzh_CN.UT…
Ubuntu中Could not get lock /var/lib/dpkg/lock解决方案
关于Ubuntu中Could not get lock /var/lib/dpkg/lock解决方案 转载于:https://www.cnblogs.com/daemonFlY/p/10916812.html
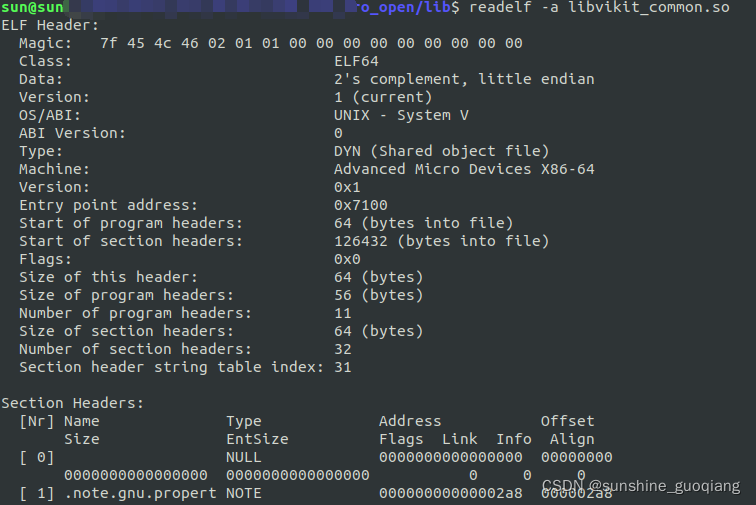
so库方法原理
动态库 So库,又动态名库,是Linux下最常见的文件之一,是一种ELF文件。这种so库是程序运行时,才会将这些需要的代码拷贝到对应的内存中。但程序运行时,这些地址早已经确定,那程序引用so库中的这些代码地址如…
上传图片,多图上传,预览功能,js原生无依赖
最近很好奇前端的文件上传功能,因为公司要求做一个支持图片预览的图片上传插件,所以自己搜了很多相关的插件,虽然功能很多,但有些地方不能根据公司的想法去修改,而且需要依赖jQuery或Bootstrap库,所以我就想…
springboot 简单自定义starter - beetl
使用idea新建springboot项目beetl-spring-boot-starter 首先添加pom依赖 packaging要设置为jar不能设置为pom<packaging>jar</packaging> <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web&…
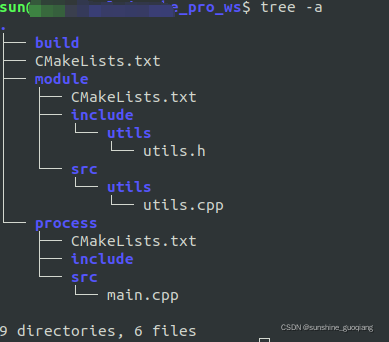
cmake生成so包并调用(C++project,build,cmake)
1. 目录结构 2 . downloads 2.1 build module process CMakeLists.txt > cmake_minimum_required(VERSION 3.5)if(CMAKE_COMPILER_IS_GNUCC)message("COMPILER IS GNUCC")ADD_DEFINITIONS ( -stdc11 ) endif(CMAKE_COMPILER_IS_GNUCC)SET(CMAKE_CXX_FLAGS_DEBU…
人眼模板匹配自动跟踪
void trackEye(cv::Mat& im, cv::Mat& tpl, cv::Rect& rect) {// 人眼位置cv::Size pSize(rect.width * 2, rect.height * 2);// 矩形区域cv::Rect tRect(rect pSize - cv::Point(pSize.width/2, pSize.height/2));tRect & cv::Rect(0, 0, im.cols, im.rows);…
前端碎碎念 之 nextTick, setTimeout 以及 setImmediate 三者的执行顺序
『前端碎碎念』系列会记录我平时看书或者看文章遇到的问题,一般都是比较基础但是容易遗忘的知识点,你也可能会在面试中碰到。 我会查阅一些资料并可能加上自己的理解,来记录这些问题。更多文章请前往我的个人博客这个问题是有关执行顺序和Eve…
bat 将war文件转换成ear文件
1、无需拷贝war文件,自动获取war set path%path%;D:\jdk\jdk1.6.0_31\bin;C:\Program Files\7-Zip del **0001-controller.war del **0001-controllerEAR.ear copy ..\target\**0001-controller-0.0.1-SNAPSHOT.war **0001-controller.war rem 7z d -tzip **0001-co…
cmake语法【一】
一、Cmake 简介 cmake 是一个跨平台、开源的构建系统。它是一个集软件构建、测试、打包于一身的软件。它使用与平台和编译器独立的配置文件来对软件编译过程进行控制。 二、常用命令 指定 cmake 的最小版本 cmake_minimum_required(VERSION 3.4.1)这行命令是可选的ÿ…
RHEL6.3安装vsftpd
1、下载vsftpd,可以从官网(http://vsftpd.beasts.org)下载,也可以百度搜索[rootlocalhost vsftpd]# wget http://down1.chinaunix.net/distfiles/vsftpd-3.0.2.tar.gz2、解压压缩包并进入解压出来的目录[rootlocalhost vsftpd]# t…
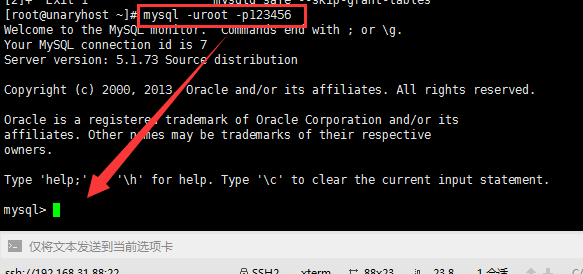
创建mysql数据库,在新数据库中创建表,再尝试删除表
创建之前,先登录数据库存 mysql -u 账号 -p密码 登录完成后,展示一下已存在的数据库 show databases; 创建数据库 create database test111; 然后展示一下数据库,如下 show databases; 使用数据库 use test; 在test数据库里面看一下已存在的…
cmake:在各级目录之间共享变量(cmake cache变量)
摘要: 本文记录一下 CMake 变量的定义、原理及其使用。CMake 变量包含 Normal Variables、Cache Variables。通过 set 指令可以设置两种不同的变量。也可以在 CMake 脚本中使用和设置环境变量。set(ENV{} …),本文重点讲述 CMake 脚本语言特有的两种变量。 正文&am…