Numpy入门教程:练习作业02
背景
什么是 NumPy 呢?
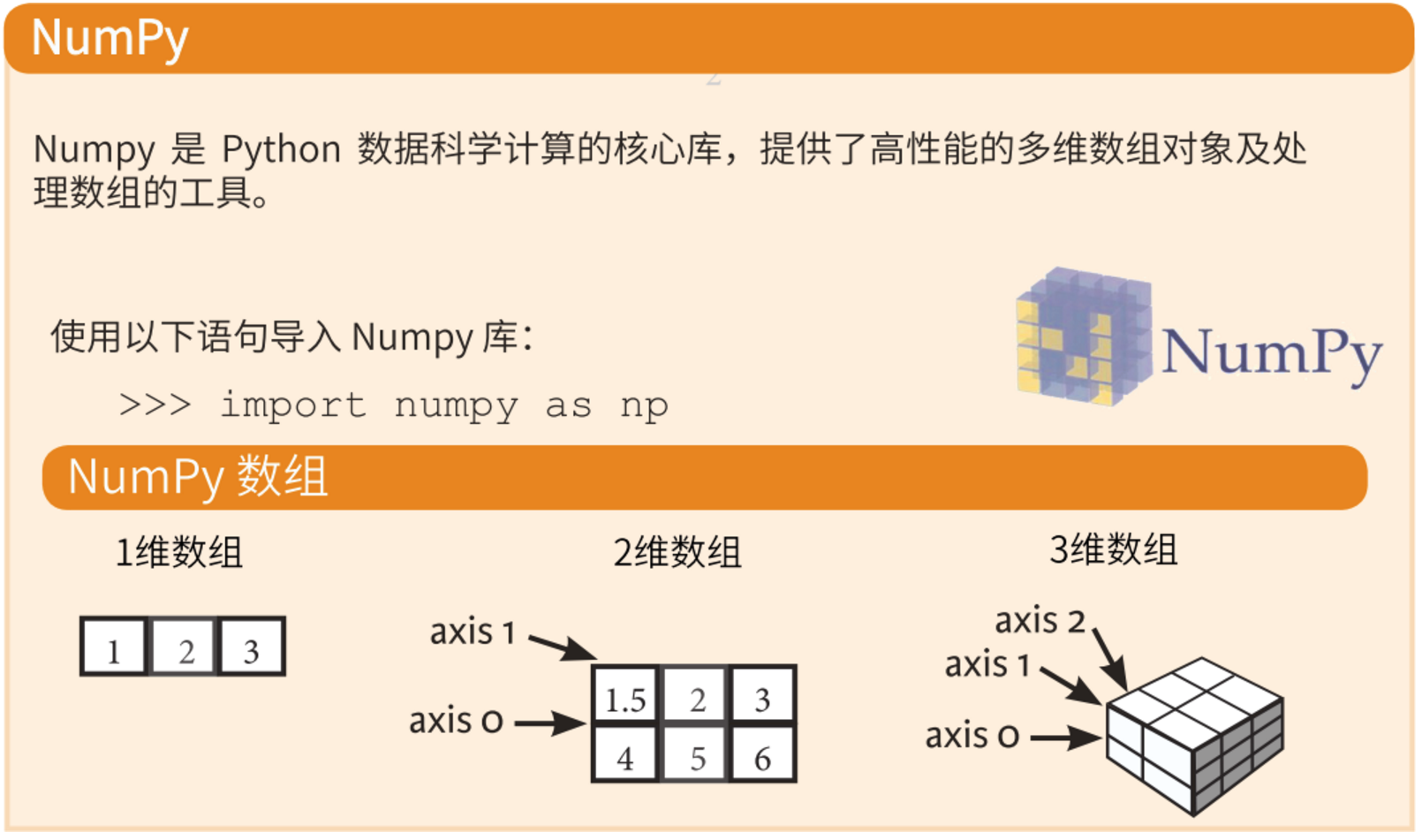
NumPy 这个词来源于两个单词 – Numerical和Python。其是一个功能强大的 Python 库,可以帮助程序员轻松地进行数值计算,通常应用于以下场景:
- 执行各种数学任务,如:数值积分、微分、内插、外推等。因此,当涉及到数学任务时,它形成了一种基于 Python 的 MATLAB 的快速替代。
- 计算机中的图像表示为多维数字数组。NumPy 提供了一些优秀的库函数来快速处理图像。例如,镜像图像、按特定角度旋转图像等。
- 在编写机器学习算法时,需要对矩阵进行各种数值计算。如:矩阵乘法、求逆、换位、加法等。NumPy 数组用于存储训练数据和机器学习模型的参数。
练习作业
本次练习使用 鸢尾属植物数据集.\iris.data,在这个数据集中,包括了三类不同的鸢尾属植物:Iris Setosa,Iris Versicolour,Iris Virginica。每类收集了50个样本,因此这个数据集一共包含了150个样本。
- sepallength:萼片长度
- sepalwidth:萼片宽度
- petallength:花瓣长度
- petalwidth:花瓣宽度
以上四个特征的单位都是厘米(cm)。
sepallength sepalwidth petallength petalwidth species
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2 Iris-setosa
.. ... ... ... ... ...
145 6.7 3.0 5.2 2.3 Iris-virginica
146 6.3 2.5 5.0 1.9 Iris-virginica
147 6.5 3.0 5.2 2.0 Iris-virginica
148 6.2 3.4 5.4 2.3 Iris-virginica
149 5.9 3.0 5.1 1.8 Iris-virginica[150 rows x 5 columns]
21. 导入鸢尾属植物数据集,保持文本不变。
【知识点:输入和输出】
- 如何导入存在数字和文本的数据集?
【答案】
import numpy as npoutfile = r'.\iris.data'
iris_data = np.loadtxt(outfile, dtype=object, delimiter=',', skiprows=1)
print(iris_data[0:10])
# [['5.1' '3.5' '1.4' '0.2' 'Iris-setosa']
# ['4.9' '3.0' '1.4' '0.2' 'Iris-setosa']
# ['4.7' '3.2' '1.3' '0.2' 'Iris-setosa']
# ['4.6' '3.1' '1.5' '0.2' 'Iris-setosa']
# ['5.0' '3.6' '1.4' '0.2' 'Iris-setosa']
# ['5.4' '3.9' '1.7' '0.4' 'Iris-setosa']
# ['4.6' '3.4' '1.4' '0.3' 'Iris-setosa']
# ['5.0' '3.4' '1.5' '0.2' 'Iris-setosa']
# ['4.4' '2.9' '1.4' '0.2' 'Iris-setosa']
# ['4.9' '3.1' '1.5' '0.1' 'Iris-setosa']]
22. 求出鸢尾属植物萼片长度的平均值、中位数和标准差(第1列,sepallength)
【知识点:统计相关】
- 如何计算numpy数组的均值,中位数,标准差?
【答案】
import numpy as npoutfile = r'.\iris.data'
sepalLength = np.loadtxt(outfile, dtype=float, delimiter=',', skiprows=1, usecols=[0])
print(sepalLength[0:10])
# [5.1 4.9 4.7 4.6 5. 5.4 4.6 5. 4.4 4.9]print(np.mean(sepalLength))
# 5.843333333333334print(np.median(sepalLength))
# 5.8print(np.std(sepalLength))
# 0.8253012917851409
23. 创建一种标准化形式的鸢尾属植物萼片长度,其值正好介于0和1之间,这样最小值为0,最大值为1(第1列,sepallength)。
【知识点:统计相关】
- 如何标准化数组?
【答案】
import numpy as npoutfile = r'.\iris.data'
sepalLength = np.loadtxt(outfile, dtype=float, delimiter=',', skiprows=1, usecols=[0])# 方法1
aMax = np.amax(sepalLength)
aMin = np.amin(sepalLength)
x = (sepalLength - aMin) / (aMax - aMin)
print(x[0:10])
# [0.22222222 0.16666667 0.11111111 0.08333333 0.19444444 0.30555556
# 0.08333333 0.19444444 0.02777778 0.16666667]# 方法2
x = (sepalLength - aMin) / np.ptp(sepalLength)
print(x[0:10])
# [0.22222222 0.16666667 0.11111111 0.08333333 0.19444444 0.30555556
# 0.08333333 0.19444444 0.02777778 0.16666667]
24. 找到鸢尾属植物萼片长度的第5和第95百分位数(第1列,sepallength)。
【知识点:统计相关】
- 如何找到numpy数组的百分位数?
【答案】
import numpy as npoutfile = r'.\iris.data'
sepalLength = np.loadtxt(outfile, dtype=float, delimiter=',', skiprows=1, usecols=[0])
x = np.percentile(sepalLength, [5, 95])
print(x) # [4.6 7.255]
25. 把iris_data数据集中的20个随机位置修改为np.nan值。
【知识点:随机抽样】
- 如何在数组中的随机位置修改值?
【答案】
import numpy as npoutfile = r'.\iris.data'# 方法1
iris_data = np.loadtxt(outfile, dtype=object, delimiter=',', skiprows=1)
i, j = iris_data.shape
np.random.seed(20200621)
iris_data[np.random.randint(i, size=20), np.random.randint(j, size=20)] = np.nan
print(iris_data[0:10])
# [['5.1' '3.5' '1.4' '0.2' 'Iris-setosa']
# ['4.9' '3.0' '1.4' '0.2' 'Iris-setosa']
# ['4.7' '3.2' '1.3' '0.2' 'Iris-setosa']
# ['4.6' '3.1' '1.5' '0.2' 'Iris-setosa']
# ['5.0' '3.6' '1.4' '0.2' 'Iris-setosa']
# ['5.4' nan '1.7' '0.4' 'Iris-setosa']
# ['4.6' '3.4' '1.4' '0.3' 'Iris-setosa']
# ['5.0' '3.4' '1.5' '0.2' 'Iris-setosa']
# ['4.4' '2.9' '1.4' '0.2' nan]
# ['4.9' '3.1' '1.5' '0.1' 'Iris-setosa']]# 方法2
iris_data = np.loadtxt(outfile, dtype=object, delimiter=',', skiprows=1)
i, j = iris_data.shape
np.random.seed(20200620)
iris_data[np.random.choice(i, size=20), np.random.choice(j, size=20)] = np.nan
print(iris_data[0:10])
# [['5.1' '3.5' '1.4' '0.2' 'Iris-setosa']
# ['4.9' '3.0' '1.4' '0.2' 'Iris-setosa']
# ['4.7' '3.2' '1.3' '0.2' 'Iris-setosa']
# ['4.6' '3.1' '1.5' '0.2' 'Iris-setosa']
# [nan '3.6' '1.4' '0.2' 'Iris-setosa']
# ['5.4' '3.9' '1.7' '0.4' 'Iris-setosa']
# ['4.6' '3.4' '1.4' '0.3' 'Iris-setosa']
# ['5.0' '3.4' '1.5' '0.2' 'Iris-setosa']
# ['4.4' '2.9' '1.4' '0.2' 'Iris-setosa']
# ['4.9' '3.1' '1.5' nan 'Iris-setosa']]
26. 在iris_data的sepallength中查找缺失值的个数和位置(第1列)。
【知识点:逻辑函数、搜索】
- 如何在numpy数组中找到缺失值的位置?
【答案】
import numpy as npoutfile = r'.\iris.data'
iris_data = np.loadtxt(outfile, dtype=float, delimiter=',', skiprows=1, usecols=[0, 1, 2, 3])
i, j = iris_data.shape
np.random.seed(20200621)
iris_data[np.random.randint(i, size=20), np.random.randint(j, size=20)] = np.nan
sepallength = iris_data[:, 0]
x = np.isnan(sepallength)
print(sum(x)) # 6
print(np.where(x))
# (array([ 26, 44, 55, 63, 90, 115], dtype=int64),)
27. 筛选具有 sepallength(第1列)< 5.0 并且 petallength(第3列)> 1.5 的 iris_data行。
【知识点:搜索】
- 如何根据两个或多个条件筛选numpy数组?
【答案】
import numpy as npoutfile = r'.\iris.data'
iris_data = np.loadtxt(outfile, dtype=float, delimiter=',', skiprows=1, usecols=[0, 1, 2, 3])
sepallength = iris_data[:, 0]
petallength = iris_data[:, 2]
index = np.where(np.logical_and(petallength > 1.5, sepallength < 5.0))print(iris_data[index])
# [[4.8 3.4 1.6 0.2]
# [4.8 3.4 1.9 0.2]
# [4.7 3.2 1.6 0.2]
# [4.8 3.1 1.6 0.2]
# [4.9 2.4 3.3 1. ]
# [4.9 2.5 4.5 1.7]]
28. 选择没有任何 nan 值的 iris_data行。
【知识点:逻辑函数、搜索】
- 如何从numpy数组中删除包含缺失值的行?
【答案】
import numpy as npoutfile = r'.\iris.data'
iris_data = np.loadtxt(outfile, dtype=float, delimiter=',', skiprows=1, usecols=[0, 1, 2, 3])
i, j = iris_data.shape
np.random.seed(20200621)
iris_data[np.random.randint(i, size=20), np.random.randint(j, size=20)] = np.nan
x = iris_data[np.sum(np.isnan(iris_data), axis=1) == 0]
print(x[0:10])
# [[5.1 3.5 1.4 0.2]
# [4.9 3. 1.4 0.2]
# [4.7 3.2 1.3 0.2]
# [4.6 3.1 1.5 0.2]
# [5. 3.6 1.4 0.2]
# [4.6 3.4 1.4 0.3]
# [5. 3.4 1.5 0.2]
# [4.9 3.1 1.5 0.1]
# [5.4 3.7 1.5 0.2]
# [4.8 3.4 1.6 0.2]]
29. 计算 iris_data 中sepalLength(第1列)和petalLength(第3列)之间的相关系数。
【知识点:统计相关】
- 如何计算numpy数组两列之间的相关系数?
【答案】
import numpy as npoutfile = r'.\iris.data'
iris_data = np.loadtxt(outfile, dtype=float, delimiter=',', skiprows=1, usecols=[0, 1, 2, 3])
sepalLength = iris_data[:, 0]
petalLength = iris_data[:, 2]# 方法1
m1 = np.mean(sepalLength)
m2 = np.mean(petalLength)
cov = np.dot(sepalLength - m1, petalLength - m2)
std1 = np.sqrt(np.dot(sepalLength - m1, sepalLength - m1))
std2 = np.sqrt(np.dot(petalLength - m2, petalLength - m2))
print(cov / (std1 * std2)) # 0.8717541573048712# 方法2
x = np.mean((sepalLength - m1) * (petalLength - m2))
y = np.std(sepalLength) * np.std(petalLength)
print(x / y) # 0.8717541573048712# 方法3
x = np.cov(sepalLength, petalLength, ddof=False)
y = np.std(sepalLength) * np.std(petalLength)
print(x[0, 1] / y) # 0.8717541573048716# 方法4
x = np.corrcoef(sepalLength, petalLength)
print(x)
# [[1. 0.87175416]
# [0.87175416 1. ]]
30. 找出iris_data是否有任何缺失值。
【知识点:逻辑函数】
- 如何查找给定数组是否具有空值?
【答案】
import numpy as npoutfile = r'.\iris.data'
iris_data = np.loadtxt(outfile, dtype=float, delimiter=',', skiprows=1, usecols=[0, 1, 2, 3])
x = np.isnan(iris_data)
print(np.any(x)) # False
31. 在numpy数组中将所有出现的nan替换为0。
【知识点:逻辑函数】
- 如何在numpy数组中用0替换所有缺失值?
【答案】
import numpy as npoutfile = r'.\iris.data'
iris_data = np.loadtxt(outfile, dtype=float, delimiter=',', skiprows=1, usecols=[0, 1, 2, 3])
i, j = iris_data.shape
np.random.seed(20200621)
iris_data[np.random.randint(i, size=20), np.random.randint(j, size=20)] = np.nan
iris_data[np.isnan(iris_data)] = 0
print(iris_data[0:10])
# [[5.1 3.5 1.4 0.2]
# [4.9 3. 1.4 0.2]
# [4.7 3.2 1.3 0.2]
# [4.6 3.1 1.5 0.2]
# [5. 3.6 1.4 0.2]
# [5.4 0. 1.7 0.4]
# [4.6 3.4 1.4 0.3]
# [5. 3.4 1.5 0.2]
# [4.4 2.9 0. 0.2]
# [4.9 3.1 1.5 0.1]]
32. 找出鸢尾属植物物种中的唯一值和唯一值出现的数量。
【知识点:数组操作】
- 如何在numpy数组中查找唯一值的计数?
【答案】
import numpy as npoutfile = r'.\iris.data'
iris_data = np.loadtxt(outfile, dtype=object, delimiter=',', skiprows=1, usecols=[4])
x = np.unique(iris_data, return_counts=True)print(x)
# (array(['Iris-setosa', 'Iris-versicolor', 'Iris-virginica'], dtype=object), array([50, 50, 50], dtype=int64))
33. 将 iris_data 的花瓣长度(第3列)以形成分类变量的形式显示。定义:Less than 3 --> ‘small’;3-5 --> ‘medium’;’>=5 --> ‘large’。
【知识点:统计相关】
- 如何将数字转换为分类(文本)数组?
【答案】
import numpy as npoutfile = r'.\iris.data'
iris_data = np.loadtxt(outfile, dtype=float, delimiter=',', skiprows=1, usecols=[0, 1, 2, 3])
petal_length_bin = np.digitize(iris_data[:, 2], [0, 3, 5, 10])
label_map = {1: 'small', 2: 'medium', 3: 'large', 4: np.nan}
petal_length_cat = [label_map[x] for x in petal_length_bin]
print(petal_length_cat[0:10])
# ['small', 'small', 'small', 'small', 'small', 'small', 'small', 'small', 'small', 'small']
34. 在 iris_data 中创建一个新列,其中 volume 是 (pi x petallength x sepallength ^ 2)/ 3。
【知识点:数组操作】
- 如何从numpy数组的现有列创建新列?
【答案】
import numpy as npoutfile = r'.\iris.data'
iris_data = np.loadtxt(outfile, dtype=object, delimiter=',', skiprows=1)
sepalLength = iris_data[:, 0].astype(float)
petalLength = iris_data[:, 2].astype(float)
volume = (np.pi * petalLength * sepalLength ** 2) / 3
volume = volume[:, np.newaxis]
iris_data = np.concatenate([iris_data, volume], axis=1)
print(iris_data[0:10])
# [['5.1' '3.5' '1.4' '0.2' 'Iris-setosa' 38.13265162927291]
# ['4.9' '3.0' '1.4' '0.2' 'Iris-setosa' 35.200498485922445]
# ['4.7' '3.2' '1.3' '0.2' 'Iris-setosa' 30.0723720777127]
# ['4.6' '3.1' '1.5' '0.2' 'Iris-setosa' 33.238050274980004]
# ['5.0' '3.6' '1.4' '0.2' 'Iris-setosa' 36.65191429188092]
# ['5.4' '3.9' '1.7' '0.4' 'Iris-setosa' 51.911677007917746]
# ['4.6' '3.4' '1.4' '0.3' 'Iris-setosa' 31.022180256648003]
# ['5.0' '3.4' '1.5' '0.2' 'Iris-setosa' 39.269908169872416]
# ['4.4' '2.9' '1.4' '0.2' 'Iris-setosa' 28.38324242763259]
# ['4.9' '3.1' '1.5' '0.1' 'Iris-setosa' 37.714819806345474]]
35. 随机抽鸢尾属植物的种类,使得Iris-setosa的数量是Iris-versicolor和Iris-virginica数量的两倍。
【知识点:随机抽样】
- 如何在numpy中进行概率抽样?
【答案】
import numpy as npspecies = np.array(['Iris-setosa', 'Iris-versicolor', 'Iris-virginica'])
species_out = np.random.choice(species, 10000, p=[0.5, 0.25, 0.25])
print(np.unique(species_out, return_counts=True))
# (array(['Iris-setosa', 'Iris-versicolor', 'Iris-virginica'], dtype='<U15'), array([4927, 2477, 2596], dtype=int64))
当前活动
我是 终身学习者“老马”,一个长期践行“结伴式学习”理念的 中年大叔。
我崇尚分享,渴望成长,于2010年创立了“LSGO软件技术团队”,并加入了国内著名的开源组织“Datawhale”,也是“Dre@mtech”、“智能机器人研究中心”和“大数据与哲学社会科学实验室”的一员。
愿我们一起学习,一起进步,相互陪伴,共同成长。
后台回复「搜搜搜」,随机获取电子资源!
欢迎关注,请扫描二维码:

相关文章:
PowerShell 导入 SQL Server 的 PS 模块
接触过UNIX或者Linux 的朋友都知道此类系统有着功能强大、无所不能的壳程序,称之为Shell。微软公司于2006年第四季度正式发布PowerShell,它的出现标志着, 微软公司向服务器领域迈出了重要的一步, 不仅提供简便的图形化操作界面,同时提供类似于Unix, Linu…

ARM嵌入式操作系统启动
任何一个操作系统的启动都至少关注两个方面:1,程序运行栈的初始化。2,处理器外设的初始化。 在ARMv6以及以前的体系结构中,定义了七种模式分别为&…
Html5 aside标签的用法和作用
aside元素用来定义当前页面或者文章的附属信息部分,它可以包含与当前页面或主要内容相关的引用、侧边栏、广告、导航条等其他类似的有别于主要内容的部分。 aside元素的用法主要分为两种。 ● 被包含在article元素内作为主要内容的附属信息。 ● 在article元素之外使…
Numpy入门教程:10. 统计相关
背景 什么是 NumPy 呢? NumPy 这个词来源于两个单词 – Numerical和Python。其是一个功能强大的 Python 库,可以帮助程序员轻松地进行数值计算,通常应用于以下场景: 执行各种数学任务,如:数值积分、微分、…
Windows 7+Code::Blocks+wxWidgets实录(一)
环境配置篇 玩过Linux的人应该对Code::Blocks和wxWidgets并不陌生。 Code::Blocks是一款非常有名的代码编辑器,在linux下用不惯vim的话,这是个不错的选择。但千万不要把它和编译器混淆,CB本身并没有独立编译程序的功能,需要调用系…
技巧:两部解决U盘安装windows 7
第一步:准备一个4G的U盘并使用disk part 工具制作成引导盘1、在运行中输入cmd 回车2、在黑色的命令提示符界面中输入Diskpart3、插入U盘 并输入List Disk查看4、输入Select Disk 1 (选择你的U盘所在的标识)5、输入clean 清除旧的信息6、输入c…

报Java面授班有哪些优势
java技术在互联网行业的高速发展,让很多人都开始学习java技术,大家都想知道学习java技术面授班好还是网络班好,小编觉得当然是面授班比较好,下面小编就带大家来详细的了解一下报Java面授班有哪些优势? 报Java面授班有哪…
刻意练习:Python基础 -- Task13. datetime模块详解
datetime模块 datetime 是 Python 中处理日期的标准模块,它提供了 4 种对日期和时间进行处理的类:datetime、date、time 和 timedelta。 datetime类 class datetime(date):def __init__(self, year, month, day, hour, minute, second, microsecond, t…
关于java和c的选择结构和循环结构
java和c在这些结构上确实没区别。 另学会一个小技巧,在编辑界面选中段落之后按tab可以整体后移选中的段落,再按shifttab可以将选中的段落前移。转载于:https://www.cnblogs.com/hloli/archive/2012/03/15/2398675.html
从控制器到驱动器的WD——硬盘巨头启示录之西数篇
WD(Western Digital,西部数据)公司创立的时间比希捷公司还早近10年,但作为硬盘驱动器供应商的历史可不算长。1970年4月23日,一家名为General Digital(通用数字)的公司诞生了,其最初是…

java程序员入门先学什么开发者工具
学习java编程语言,那么开发工具是肯定少不了的,程序员入门基础中开发工具是一定要学会的,可以帮助开发者们提高开发效率、更优雅的写代码。由于开发者涉及的技术领域众多,以后端开发者的视角盘点平时可能用得到的工具,…
Numpy入门教程:11. 时间日期和时间增量
序言 什么是 NumPy 呢? NumPy 这个词来源于两个单词 – Numerical和Python。其是一个功能强大的 Python 库,可以帮助程序员轻松地进行数值计算,通常应用于以下场景: 执行各种数学任务,如:数值积分、微分、…
C#事件的发送方和接收方(订阅方)
C#事件的发送方和接收方(订阅方)基于Windows的应用程序也是基于消息的,Windows使用预定义消息与应用程序通讯。.NET Framework将Windows消息封装在事件中,可以把事件作为对象之间的通讯介质。事件发送方:发送事件的对象…
后台管理界面模版
http://www.cssmoban.com/cssthemes/houtaimoban/index_3.shtml转载于:https://www.cnblogs.com/hellojesson/p/7805516.html

选择PMP培训学校需要注意哪些
选择PMP培训学校需要注意哪些?如今各大职场对于项目管理这个岗位都是非常有需求的,有需求就有市场,PMP培训相关证书在市面上频繁出现,想要选择PMP培训学校需要注意哪些呢?来看看下面的详细介绍。 首先,我们来详细的了解一下什么…

绝对实用 NAT + VLAN +ACL管理企业网络
在企业中,要实现所有的员工都能与互联网进行通信,每个人各使用一个公网地址是很不现实的。一般,企业有1个或几个公网地址,而企业有几十、几百个员工。要想让所有的员工使用这仅有的几个公网地址与互联网通信该怎么做呢?…

javascript 常用功能總結
1.路径符号的含义 src"/js/jquery.js"、"../"这个斜杠是绝对路径的意思,表示的是网站根目录. 其他的如"./ " 、 "../" 、 "jquery.js" 、 "js/jquery.js"等等表示的都是相对当前网页的路径,…
学习资源:在线学习 Python(一)
背景 Python 是一种通用编程语言,其在科学计算和机器学习领域具有广泛的应用。如果我们打算利用 Python 来执行机器学习的代码,那么对 Python 有一些基本的了解就是至关重要的。 如果我们希望熟悉 Python 基本语法结构,但不希望在本地安装I…

什么BRIEF算法?BRIEF算法详解
BRIEF是一种特征描述子提取算法,并非特征点的提取算法,一种生成二值化描述子的算法,不提取代价低,匹配只需要使用简单的汉明距离(Hamming Distance)利用比特之间的异或操作就可以完成。因此,时间代价低,空间…
OpenLayers 动态添加标记(Marker)和信息窗(Popup)
方式一:使用marker方式 1、在地图上添加标记图层 var markers newOpenLayers.Layer.Markers("Markers"); map.addLayer(markers);//地图初始化添加 2、动态添加标记和Popup方法: //add map initial methodmap.events.register(click, this, fu…

Bag标签之中的一个行代码实行中文分词实例2
例1: 分词(返回以逗号隔开每一个词带上引號的词组。gap",",quotes""或quotes") 单引號 <bag idpPage act2words namewords gap"," quotes"">我喜欢黄色高领T恤衫</bag>…
学习资源:在线学习 Python(二)
背景 Python 是一种通用编程语言,其在科学计算和机器学习领域具有广泛的应用。如果我们打算利用 Python 来执行机器学习的代码,那么对 Python 有一些基本的了解就是至关重要的。 如果我们希望熟悉 Python 基本语法结构,但不希望在本地安装I…

Java培训完可以应用在什么领域
java技术在互联网行业一直都是非常有发展前景的,很多小伙伴都想知道“Java培训完可以应用在什么领域”这个问题,下面小编就来为大家做下详细的介绍。 Java培训完可以应用在什么领域?java的应用非常的广泛,可以用来在开发软件工具、嵌入式…

技术图文:Matlab VS. Numpy 矩阵基本运算
背景 前段时间在知识星球上立了一个Flag,至少写10篇关于 Python,Matlab 和 C# 对比的总结。 这是第 3 篇,对比 Matlab 与 Numpy 在矩阵基本运算方面的区别与联系。 虽然 Numpy 定义了 matrix 类型,使用该 matrix 类型创建的是矩…
Improve Performance and Reduce Memory with PVRTC Textures and Cocos2d
转载自:http://www.uchidacoonga.com/2011/07/pvrtc-textures-and-cocos2d/ Hello everyone! A few months have passed since I posted Simple Platformer Using Cocos2d and Box2d with Collision Detection. I have received many positive feedbacks and intere…

VDI序曲二十三 制作OFFICE 2003应用程序虚拟化序列
APP-V平台由三个重要组件构成:APP-V排序器、用于虚拟应用程序交付和管理的APP-V管理和流式处理服务器以及APP-V客户端。并且在虚拟环境中不会包含不必要的文件和设置,让IT管理员按需交付应用程序软件。 我们之前在一台干净的PC上做好了“捕获鸟笼”&…

零基础学Java程序有什么好的建议
java技术的快速发展,引起了很多人的关注,尤其是一些零基础人群,都想通过学习java技术来改善自己的职业,那么零基础学Java程序有什么好的建议呢?来看看下面的详细介绍。 零基础学Java程序有什么好的建议? 1.选择对的书籍…
Numpy入门教程:12. 线性代数
背景 什么是 NumPy 呢? NumPy 这个词来源于两个单词 – Numerical和Python。其是一个功能强大的 Python 库,可以帮助程序员轻松地进行数值计算,通常应用于以下场景: 执行各种数学任务,如:数值积分、微分、…
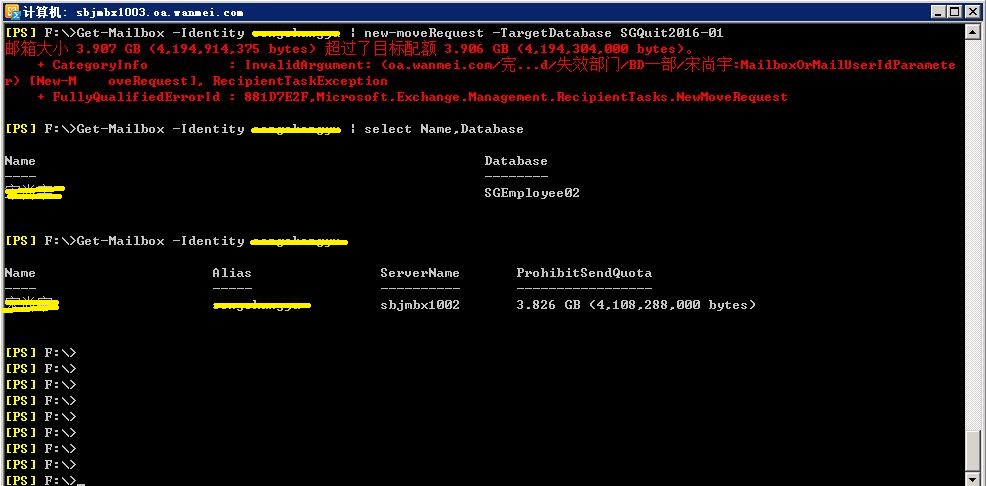
Exchange 2010 移动邮箱时提示超过了目标配额
在使用 new-moveRequest 移动邮箱时,提示超过了目标配额。解决过程如下: 经查看,此邮箱配额为 3.826G ,由于邮箱实际比配额大,因此移动时出现下面的错误 找到该用户,邮箱设置-存储配额,最下面的…

什么是URL?协议头,路径和端口是什么意思?
URL(Uniform Resource Locator,统一资源定位符)是互联网上标准资源的地址,互联网上每个文件(即资源)都有一个唯一的URL,它包含了文件的位置以及浏览器处理方式等信息。 URL地址由协议头、服务器地址、文件路径三部分组成。比如,一…