二分类任务:确定一个人是否年收入超过5万美元
文章目录
- 一、 问题描述
- 二、 设计简要描述
- 三、 程序清单
- 四、 结果分析
- 五、 调试报告
- 六、 实验总结
一、 问题描述
学会使用学习到的概率生成模型相关的知识,找出各类别最佳的高斯分布,从而达到通过输入测试,完成二分类任务,成功预测是否该用户年薪达到50k美元。
二、 设计简要描述
机器学习的三个基本步骤——

程序设计思路——

三、 程序清单
# 基于概率生成模型的二分类任务——确定一个人的年收入是否超过50k美元
import pandas as pd
import numpy as np
import csv# 1. 数据预处理
# 1.1 读取数据
train_data = pd.read_csv("./train.csv")
test_data = pd.read_csv("./test.csv")
# 1.2 输入数据格式化处理
# 1.2.1 去除字符串数值前面的空格
str_cols = [1, 3, 5, 6, 7, 8, 9, 13, 14] # 这些列的属性值是字符串
for col in str_cols:# iloc()是根据行号索引,参数中逗号前表示所有行,逗号后表示col所在列# train_data.iloc[:, col] = train_data.iloc[:, col].map(lambda x: x.stripe())pass# 训练集共有15列,测试集共有14列if col != 14:#test_data.iloc[:, col] = test_data.iloc[:, col].map(lambda x: x.stripe())pass# map() 会根据提供的函数对指定序列做映射# lambda x:表示是一个匿名函数# .stripe()表示去除首尾的空格
# 1.2.2 将问号替换
# “workclass”的“?”修改为“Private”
train_data['workclass'][train_data['workclass'] == "?"] = 'Private'
test_data['workclass'][train_data['workclass'] == "?"] = 'Private'
# “occupation”的“?”修改为“other”
train_data['occupation'][train_data['occupation'] == "?"] = 'other'
test_data['occupation'][test_data['occupation'] == "?"] = 'other'# 1.2.3 对字符数据进行编码
'''对原始数据进行编码处理,将所有数据信息均使用数字来表示,
方便使用于本次实验中训练。其中采用的编码方式为标签编码'''
# 训练集处理
# 放置每一列的encoderfrom sklearn.preprocessing import LabelEncoder # 该类的作用是将离散型的数据转换成 0 到 n − 1 之间的数train_label_encoder = []
train_encoded_set = np.empty(train_data.shape) # .shape用于读出矩阵的形状,empty()用于返回形状一样的多维数组,元素为随机产生的数字
# 对于每一列
for col in range(train_data.shape[1]):encoder = None# 对于该列的每一行# 字符型数据if train_data.iloc[:, col].dtype == object:encoder = LabelEncoder()train_encoded_set[:, col] = encoder.fit_transform(train_data.iloc[:, col])# 数值型数据# 连续的特征属性直接采用原值else:train_encoded_set[:, col] = train_data.iloc[:, col]train_label_encoder.append(encoder)train_encoded_data = train_encoded_set # 编码后的训练集,和原数据形状一样
# 测试集处理(完全同训练集)
# 放置每一列的encoder
test_label_encoder = []
test_encoded_set = np.empty(test_data.shape)
for col in range(test_data.shape[1]):encoder = None# 字符型数据if test_data.iloc[:, col].dtype == object:encoder = LabelEncoder()test_encoded_set[:, col] = encoder.fit_transform(test_data.iloc[:, col])# 数值型数据else:test_encoded_set[:, col] = test_data.iloc[:, col]test_label_encoder.append(encoder)test_encoded_data = test_encoded_set# 1.3 划分训练集为训练集和验证集
from sklearn.model_selection import train_test_split # train_test_split()函数是用来随机划分样本数据为训练集和测试集的,优点是减少人为因素# y为处理好的训练集的最后一列,X为训练集除去y的部分
X, y = train_encoded_data[:, :-1], train_encoded_data[:, -1]
# 完整模板:train_X,test_X,train_y,test_y = train_test_split(train_data,train_target,test_size=0.3,random_state=5)
# train_data:待划分样本数据
# train_target:待划分样本数据的结果(标签)
# test_size:测试数据占样本数据的比例,若整数则样本数量
# random_state:设置随机数种子,保证每次都是同一个随机数。若为0或不填,则每次得到数据都不一样
# X_train, X_val, y_train, y_val分别为训练集参数、验证集参数、训练集结果、测试集结果
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.1, random_state=50)# 2. 将预处理好数据的加载到模型中,然后将其标准化
# mean()函数功能:求取均值
# axis = 0:压缩行,对各列求均值,返回 1* n 矩阵
# reshape(1, -1)使得数据集变成一列,-1为任意正整数的通配符
train_mean = np.mean(X_train, axis=0).reshape(1, -1)
# std()函数的功能是计算标准差
train_std = np.std(X_train, axis=0).reshape(1, -1)train_data = X_train# 3. 实现后验概率模型
'''分别求得后验概率中两类别的均值,以及共享的协方差,
计算出model的一些参数之后,化简公式就可以得到其属于某一类的概率计算公式'''
class_0_id = [] # 存放标签为0的训练集行数
class_1_id = [] # 存放标签为1的训练集行数
for i in range(len(y_train)):if y_train[i] == 0:class_0_id.append(i)else:class_1_id.append(i)# 训练集按照标签不同被分成两部分
class_0 = train_data[class_0_id]
class_1 = train_data[class_1_id]# n是属性的维数,均值为一个n维的向量,协方差矩阵为n*n
n = class_0.shape[1]
cov_0 = np.zeros((n, n))
cov_1 = np.zeros((n, n))# 求两类别的均值
mean_0 = np.mean(class_0, axis=0).reshape(1, -1) # mean_0 是一个n为的列向量,每一维都是一个属性的均值
mean_1 = np.mean(class_1, axis=0).reshape(1, -1)# 分别求各自的协方差
for i in range(class_0.shape[0]):# dot()函数求的是矩阵的点积或一维数组的内积# transpose()函数的作用是调换行和列的索引值cov_0 += np.dot(np.transpose(class_0[i] - mean_0), (class_0[i] - mean_0)) / class_0.shape[0]for i in range(class_1.shape[0]):cov_1 += np.dot(np.transpose(class_1[i] - mean_1), (class_1[i] - mean_1)) / class_1.shape[0]# 共享的协方差
cov = (cov_0 * class_0.shape[0] + cov_1 * class_1.shape[0]) / (class_0.shape[0] + class_1.shape[0])from numpy.linalg import inv # 矩阵求逆w = np.transpose(((mean_0 - mean_1)).dot(inv(cov)))
b = (-0.5) * (mean_0).dot(inv(cov)).dot(mean_0.T) + 0.5 * (mean_1).dot(inv(cov)).dot(mean_1.T) + np.log(float(class_0.shape[0]) / class_1.shape[0])# 4. 利用模型对验证集预测
'''利用训练集训练得到的模型也就是概率计算公式对验证集的测试数据进行计算,
然后根据验证集的真实结果进行对比,得到模型的精确率'''
val_array = np.empty([X_val.shape[0], 1], dtype=float)
for i in range(X_val.shape[0]):z = X_val[i, :].dot(w) + bz *= (-1)val_array[i][0] = 1 / (1 + np.exp(z))
val_result = np.clip(val_array, 1e-8, 1 - (1e-8))
# 将预测结果转换为0、1
val_answser = np.ones([val_result.shape[0], 1], dtype=int)
for i in range(val_result.shape[0]):# 概率大于0.5的,划分为类别0if val_result[i] > 0.5:val_answser[i] = 0# 计算验证集的精确度
right_num = 0
for i in range(len(val_answser)):if val_answser[i] == y_val[i]:right_num += 1
# 精确度为预测正确的个数除以总个数
print("验证集上的准确率为:",right_num / len(val_answser))# 5. 对测试集进行预测
test_array = np.empty([test_encoded_data.shape[0], 1], dtype=float)
for i in range(test_encoded_data.shape[0]):z = test_encoded_data[i, :].dot(w) + bz *= (-1)test_array[i][0] = 1 / (1 + np.exp(z))
test_result = np.clip(test_array, 1e-8, 1 - (1e-8))
test_answer = np.ones([test_result.shape[0], 1], dtype=int)
for i in range(test_result.shape[0]):if test_result[i] > 0.5:test_answer[i] = 0# 6. 保存预测结果到文件中
# 6.1 仅保存结果
predict_result_file = open('./predict_result.csv', 'w', newline='')
writer = csv.writer(predict_result_file)
writer.writerow(('id', 'label'))
for i in range(test_answer.shape[0]):writer.writerow([i + 1, test_answer[i][0]])
predict_result_file.close()# 6.2 保存预测结果到原测试文件中
# 修改0、1值为<=50K、>50K
predict_answer = []
for i in range(len(test_answer)):if test_answer[i] == 0:predict_answer.append(' <=50K')else:predict_answer.append(' >50K')# 保存预测结果到文件中
source_file = './test.csv' # person.csv包括id,name,age三个列
predict_file = pd.read_csv(source_file, low_memory=False) # 读取csv,设置low_memory=False防止内存不够时报警告
predict_file['income'] = predict_answer # 增加新的列company# 以下保存指定的列到新的csv文件,index=0表示不为每一行自动编号,header=1表示行首有字段名称
predict_file.to_csv('./predict.csv', index=0, header=1)
四、 结果分析
- 验证集上的准确率
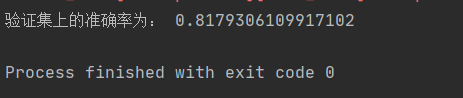
- 结果

- 更直观的结果

分析:结果符合预期
五、 调试报告
- 报错:AttributeError: ‘str’ object has no attribute ‘stripe’
定位:train_data.iloc[:, col] = train_data.iloc[:, col].map(lambda x: x.stripe())
分析:这一行的作用是,对指定列的所有行的数据进行处理,去掉字符串数值前后的空格
解决:换一种去除空格的方法
replace主要用于字符串的替换replace(old, new, count)
六、 实验总结
- 收获了很多数据处理相关知识
① 对于一个矩阵,shape[0]表示行数,shape[1]表示列数
② 对于[:, col]这种表达,以逗号为界,前面表示行信息,后面表示列信息
③ map()函数表示根据提供的函数对指定序列做映射
④ map()函数有lambda x:表示是一个匿名函数
⑤ Python提供了非常好用的矩阵替换信息,如
train_data['workclass'][train_data['workclass'] == "?"] = 'Private'
表示对于’workclass’这一栏凡是值为"?"都替换为’Private’
⑥ from sklearn.preprocessing import LabelEncoder
该类的作用是将离散型的数据转换成 0 到 n-1 之间的数
⑦ np.mean(class_0, axis=0)中class_0表示被求均值的矩阵,axis=0表示对矩阵的每一列求均值,最终得到一个行向量
⑧ reshape(1, -1)使得数据集变成一列,-1为任意正整数的通配符
⑨ 学会了使用csv.writer给数据添加一行
- 进一步加深了对理论知识的理解
在做实验之前只知道生成模型用到了高斯分布,但不是特别理解。实验中理解高斯分布在这里是一种假设,基于这种假设加上最大似然估计的思想,方才求得模型的参数,用于验证集和测试集的预测。
相关文章:

Android Splash界面支持用户点击 直接进入主界面
转载请注明出处:http://blog.csdn.net/lmj623565791/article/details/23613403 现在大部分APP都有Splash界面,下面列一下Splash页面的几个作用: 1、展示logo,提高公司形象 2、初始化数据 (拷贝数据到SD) 3、提高用户体验 4、连接服务器是否有…
Python爬一下抖音上小姐姐的视频~
image.png在简书也码了1W多字了,发现还是爬虫类的文章看的人多。 算法工程师现在都啥价位了,你们还在看爬虫→_→ 介绍 这次爬的是当下大火的APP--抖音,批量下载一个用户发布的所有视频。 各位也应该知道,抖音只有移动端ÿ…
哈哈,我的博客开通啦,欢迎光临~~~~~~~~~~~~
毕业快一年了,参加工作一年多了,几多苦闷,几多快乐。用某某人的话说就是“痛苦并快乐着!”。工作了,才发现现实和理想真的有差距啊!但我将直面“惨淡”的程序人生。希望与同龄人,不同龄人共勉。…
逻辑回归:确定一个人是否年收入超过5万美元
文章目录1. 问题描述2. 设计简要描述3. 程序清单4. 结果分析5. 调试报告6. 实验小结1. 问题描述 学会使用学习到的逻辑回归的知识,手动使用梯度下降方法,通过给定的相关数据来完成年薪是否高于50k的二分类预测任务。 2. 设计简要描述 机器学习的三个基…
【特征匹配】ORB原理与源码解析
相关 : Fast原理与源码解析 Brief描述子原理与源码解析 Harris原理与源码解析 http://blog.csdn.net/luoshixian099/article/details/48523267 ORB特征提取详解 ORB特征点检测 为了满足实时性的要求,前面文章中介绍过快速提取特征点算法Fast,以及特征描述子Brief。…
C# 的三种序列化方法
序列化是将一个对象转换成字节流以达到将其长期保存在内存、数据库或文件中的处理过程。它的主要目的是保存对象的状态以便以后需要的时候使用。与其相反的过程叫做反序列化。 序列化一个对象 为了序列化一个对象,我们需要一个被序列化的对象,一个容纳被…
DotNetNuke(DNN)网站发布、部署、迁移和重建
DotNetNuke(DNN)网站本质上是一个ASP.NET网站,由网站文件(也就是website目录)和数据库组成的,所以,“发布、部署、迁移和重建”实际上也就是把网站文件和数据库文件拷贝到服务器上并修改相应设置的过程。对于"发布…
PyTorch基础与简单应用:构建卷积神经网络实现MNIST手写数字分类
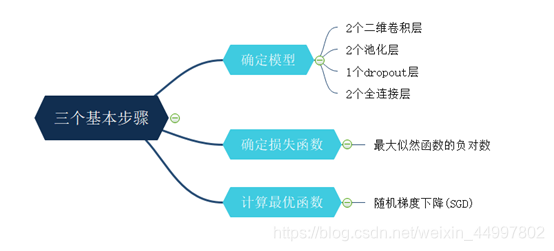
文章目录(一) 问题描述(二) 设计简要描述(三) 程序清单(四) 结果分析(五) 调试报告(六) 实验小结(七) 参考资料(一) 问题描述 构建卷积神经网络实现MNIST手写数字分类。 (二) 设计简要描述 机器学习的三个基本步骤—— 程序设计思路——(此图放大可看清) (三) 程序清单 …
from selenium.webdriver.support.ui import Select
from selenium.webdriver.support.ui import SelectSelect(d.find_element_by_id(ukey_开户行)).first_selected_option.text转载于:https://www.cnblogs.com/paisen/p/3669272.html
rocketmq-flink
https://github.com/apache/rocketmq-externals/tree/master/rocketmq-flink https://issues.apache.org/jira/browse/ROCKETMQ-82
基于Numpy构建全连接前馈神经网络进行手写数字识别
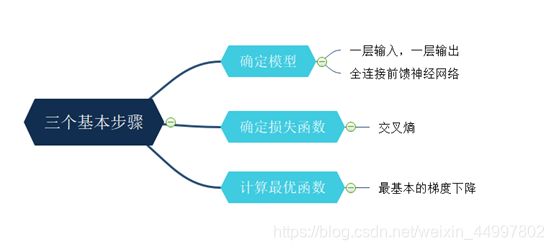
文章目录(一) 问题描述(二) 设计简要描述(三) 程序清单(四) 结果分析(五) 调试报告(六) 实验小结(一) 问题描述 不使用任何机器学习框架,仅仅通过Numpy库构建一个最简单的全连接前馈神经网络,并用该网络识别mnist提供的手写数字体。 (二) 设计简要描述…
sqlserver 三种恢复模式
sql server数据库提供了三种恢复模式:完整,简单和大容量日志,这些模式决定了sql server如何使用事务日志,如何选择它要记录的操作,以及是否截断日志。截断事务日志是删除己执行事务并把该日志空间让给新事务的过程&…

Confluence 6 配置日志
我们推荐你根据你的需求来配置你自己的 Confluence 日志。你可以有下面 2 种方法来修改你的日志:通过 Confluence 管理员控制台进行配置 – 你的修改仅在本次修改有效,下次重启后将会把所有修改重置。编辑属性文件 – 你的修改将会在下次重启后生效同时针…

最近最近在微软的Mobile Soft factory
最近公司在做PDA项目的开发, 我主要负责Mobile的框架设计和开发。以前都是在做winform程序,对Mobile 的开发 知之甚少,现在突然开始做mobile的项目,压力有点大! 不知该从何处下手,幸好发现微软提供的Mobile…
神经网络训练技巧
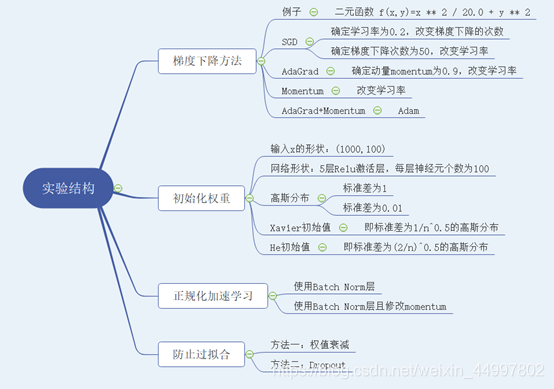
文章目录一、问题描述二、 设计简要描述三、程序清单四、结果分析五、调试报告六、实验小结一、问题描述 基于二元函数f(x,y)z1/20 x2y2掌握梯度下降和权重初始化的技巧,基于手写体识别掌握正规化和两种防止过拟合的技巧。 二、 设计简要描述 梯度下降方法 1.1.1 …

Unix的轻巧“约取而实得”(上篇)
在经过上机操作实践以及掌握Unix系统相关的基础知识之后,可以说已跨进了迈向成功的门槛。接着要登堂入室,继续专进,就必须更加深入的了解Unix基本命令的功能、使用并掌握一些必备的技巧。这一轮学习会有一定难度,需要强烈的求知欲…
操作系统2--操作系统结构
操作系统结构 操作系统的结构需要从这几个方面来考虑:他为用户提供了哪些服务和界面,系统各个组成部分及其相互关系 操作系统的操作 大致可分为:进程管理,主存管理,文件管理,辅存管理和IO管理 进程管理 进程的创建和结束进程的挂起和恢复进程锁\进程交互\进程死锁的规则内存管理…

Windows环境下启动Mysql服务提示“1067 进程意外终止”的解决方案
2019独角兽企业重金招聘Python工程师标准>>> 在Windows服务里启动Mysql服务时提示“1067 进程意外终止”。 此时我们打开计算机管理查看Windows日志,如下图所示: 完整错误提示如下: The server option lower_case_table_names is …
不使用任何框架实现CNN网络
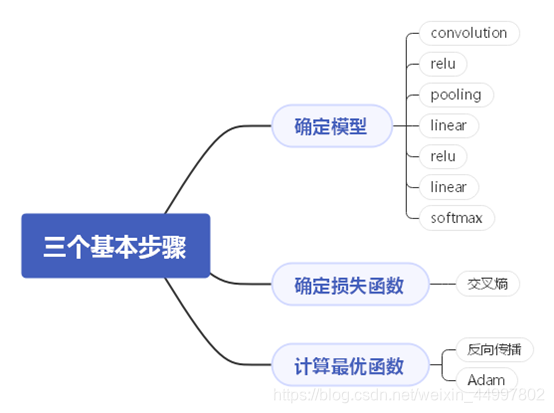
文章目录一、 问题描述二、 设计简要描述三、程序清单四、结果分析五、调试报告六、实验小结一、 问题描述 基于Numpy和函数im2col与col2im来实现一个简单的卷积神经网络,将其用于手写体识别。 二、 设计简要描述 机器学习的三个基本步骤—— 程序设计思路——(…
关于刘冬大侠Spring.NET系列学习笔记3的一点勘正
诚如他第22楼“只因渴求等待”提出的疑问一样,他的下面那一段代码是存在一点点问题的, XElement root XElement.Load(fileName);var objects from obj in root.Elements("object") select obj; 如果照搬照抄刘冬大侠的这段代码那是不会成功读…
什么叫做KDJ指标
什么叫做KDJ指标 KDJ指标的中文名称是随机指数,最早起源于期货市场。 KDJ指标的应用法则KDJ指标是三条曲线,在应用时主要从五个方面进行考虑:KD的取值的绝对数字;KD曲线的形态;KD指标的交叉;KD指标的背离&a…

vim常用命令总结 (转)
在命令状态下对当前行用 (连按两次), 或对多行用n(n是自然数)表示自动缩进从当前行起的下面n行。你可以试试把代码缩进任意打乱再用n排版,相当于一般IDE里的code format。使用ggG可对整篇代码进行排版。 vim 选择文本&…
敏捷过程、极限编程和SCRUM的关系
极限编程是最知名的敏捷开发过程,SCRUM是最经典的极限编程。 层次关系从大到小是:敏捷过程>极限编程>SCRUM
C#双面打印解决方法(打印word\excel\图片)
最近需要按顺序打印word、excel、图片,其中有的需要单面打印,有的双面。网上查了很多方法。主要集中在几个方式解决 1、word的print和excel的printout里设置单双面 2、printdocument里的printsettings的duplex设置单双面 试过之后效果都不好,…
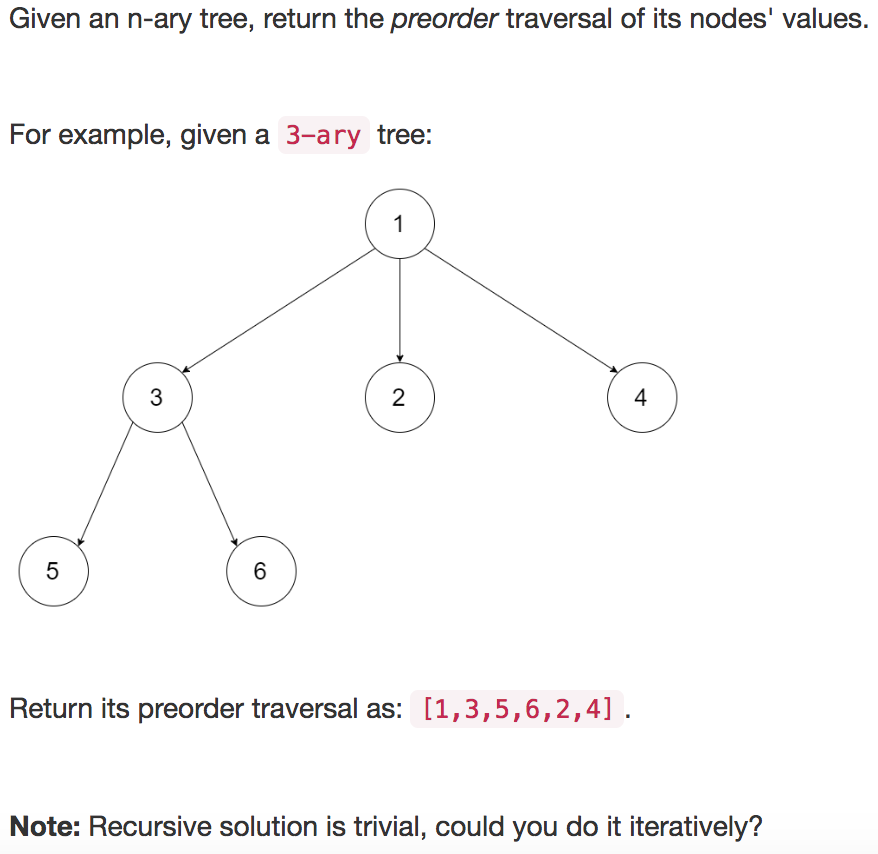
【leetcode】589. N-ary Tree Preorder Traversal
题目如下: 解题思路:凑数题1,话说我这个也是凑数博? 代码如下: class Solution(object):def preorder(self, root):""":type root: Node:rtype: List[int]"""if root None:return []re…
MSDN Visual系列:创建Feature扩展SharePoint列表项或文档的操作菜单项
原文:http://msdn2.microsoft.com/en-us/library/bb418731.aspx在SharePoint中我们可以通过创建一个包含CustomAction元素定义的Feature来为列表项或文档添加一个自定义操作菜单项(Entry Control Block Item)。我们可以添加自定义命令到默认的SharePoint用户界面中。…

评审过程中,A小组发现了5个缺陷,B小组发现了9个缺陷,他们发现的缺陷中有3个是相同的。请问:还有多少个潜在的缺陷没有发现?
分析:这一个“捉-放-捉”问题 背景: 求解: 可以将A看成是第一次捕捉,发现了5个缺陷,全部打上标记 B看成是第二次捕捉,发现了9个缺陷,其中有3个有标记 那么可以算出系统中一共存在的缺陷数量为…
Dell PowerVault TL4000 磁带机卡带问题
最近一段时间Dell PowerVault TL4000 磁带机故障频繁,昨天我在管理系统里面看到Library Status告警:HE: sled blocked, error during sled movement to rotation position Code: 8D 07 ,Dell工程师根据Code: 8D 07判断是磁带卡带了࿰…

【git】git入门之把自己的项目上传到github
1. 首先当然是要有一个GIT账号:github首页 2. 然后在电脑上安装一个git:git首页 注册和安装这里我就不说了。我相信大家做这个都没有问题。 3. 上述两件事情做完了,就登陆到github页面 1)首先我们点标注【1】的小三角,…

Java面试查漏补缺
一、基础 1、&和&&的区别。 【概述】 &&只能用作逻辑与(and)运算符(具有短路功能);但是&可以作为逻辑与运算符(是“无条件与”,即没有短路的功能)…