基于Numpy构建全连接前馈神经网络进行手写数字识别
文章目录
- (一) 问题描述
- (二) 设计简要描述
- (三) 程序清单
- (四) 结果分析
- (五) 调试报告
- (六) 实验小结
(一) 问题描述
不使用任何机器学习框架,仅仅通过Numpy库构建一个最简单的全连接前馈神经网络,并用该网络识别mnist提供的手写数字体。
(二) 设计简要描述
机器学习的三个基本步骤——
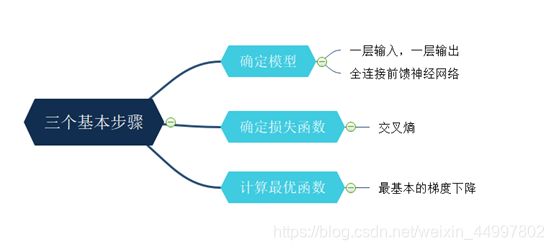
程序设计思路——(此图放大可看清)

(三) 程序清单
import numpy as np
from mnist import load_mnist# sigmoid函数
def sigmoid(x):return 1 / (1 + np.exp(-x))# softmax函数
def softmax(a):exp_a = np.exp(a)sum_exp_a = np.sum(exp_a, axis=1, keepdims=True)y = exp_a / sum_exp_areturn y# 损失函数
# y是神经网络的输出,t是正确解标签
def cross_entropy_error(y, t):delta = 1e-7return -np.sum(t * np.log(y + delta))# 计算并返回数值微分值的代码
def numerical_gradient(f, x):# f是函数,x是自变量h = 1e-4 # 0.0001grad = np.zeros_like(x) # 生成和x形状相同的数组it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite']) # 高效的多维迭代器对象来遍历数组while not it.finished:idx = it.multi_index # 表示进入下一次迭代tmp_val = x[idx]# f(x+h)的计算x[idx] = tmp_val + hfh1 = f(x)# f(x-h)的计算x[idx] = tmp_val - hfh2 = f(x)grad[idx] = (fh1 - fh2) / (2 * h)x[idx] = tmp_val # 还原,因为这里只是计算一下梯度,需要暂时修改x矩阵it.iternext()return gradclass TwoLayerNet:# 模型初始化# size是神经元数量def __init__(self, input_size, hidden_size, output_size, weight_init_std=0.01):# 初始化权重self.params = {}# 第一层的权重self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size) # rand函数根据给定维度生成[0,1)?# 第一层的偏置self.params['b1'] = np.zeros(hidden_size)# 请添加网络第二层的权重和偏置的初始化代码self.params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size)self.params['b2'] = np.zeros(output_size)# 模型前向传播过程def forward(self, x):# 请从参数字典获取网络参数W1, W2, b1, b2 = self.params['W1'], self.params['W2'], self.params['b1'], self.params['b2']# 实现第一层的运算z1 = np.dot(x, W1) + b1h1 = sigmoid(z1)# 请实现第二层的运算h2 = np.dot(h1, W2) + b2 # 注意,第二层的输入x是第一层的输出h1y = softmax(h2) # 第二层的激活函数是softmax而不是sigmoidreturn y# 定义损失函数def loss(self, x, t): # x:输入数据, t:正确标签作为监督数据y = self.forward(x)return cross_entropy_error(y, t)# 计算预测的准确率def accuracy(self, x, t): # 假定输入的数据x和标签t都是mini-batch形式的# 请补充实现模型前向输出的代码y = self.forward(x)# 请补充提取模型预测类别和标签真实类别的代码y = np.argmax(y, axis=1) # argmax()函数的作用是沿着一个轴返回最大值的索引t = np.argmax(t, axis=1)# 请补充计算并返回模型类别预测准确率的代码accuracy = np.sum(y == t) / float(x.shape[0])return accuracy# 通过数值微分的方式计算模型参数的梯度def gradient(self, x, t):# 定义字典形式的参数梯度grads = {}# 请定义需传入numerical_gradient函数的需求梯度的函数loss_W = lambda W: self.loss(x, t)# 请补充通过数值微分的方法计算参数W1、W2、b1、b2的梯度的代码grads['W1'] = numerical_gradient(loss_W, self.params['W1'])grads['b1'] = numerical_gradient(loss_W, self.params['b1'])grads['W2'] = numerical_gradient(loss_W, self.params['W2'])grads['b2'] = numerical_gradient(loss_W, self.params['b2'])# 返回计算出的梯度return gradsif __name__ == '__main__':# 获得MNIST数据集(x_train, t_train), (x_test, t_test) = load_mnist(one_hot_label=True)# 定义训练循环迭代次数iters_num = 10000# 获取训练数据规模train_size = x_train.shape[0]# 定义训练批次大小batch_size = 100# 定义学习率learning_rate = 0.1# 创建记录模型训练损失值的列表train_loss_list = []# 创建记录模型在训练数据集上预测精度的列表train_acc_list = []# 创建记录模型在测试数据集上预测精度的列表test_acc_list = []# 计算一个epoch所需的训练迭代次数(一个epoch定义为所有训练数据都遍历过一次所需的迭代次数)iter_per_epoch = 1MyTwoLayerNet = TwoLayerNet(input_size=784, hidden_size=50, output_size=10) # 实例化TwoLayerNet类创建MyTwoLayerNet对象#训练循环的代码for i in range(iters_num):# 在每次训练迭代内部选择一个批次的数据batch_choose = np.random.choice(train_size, batch_size) # choice()函数的作用是从train_size中随机选出batch_size个x_batch = x_train[batch_choose]t_batch = t_train[batch_choose]# 请补充计算梯度的代码grad = MyTwoLayerNet.gradient(x_batch, t_batch)# 请补充更新模型参数的代码for params in ('W1', 'b1', 'W2', 'b2'):MyTwoLayerNet.params[params] -= learning_rate * grad[params]# 请补充向train_loss_list列表添加本轮迭代的模型损失值的代码loss = MyTwoLayerNet.loss(x_batch, t_batch)train_loss_list.append(loss)# 判断是否完成了一个epoch,即所有训练数据都遍历完一遍if i % iter_per_epoch == 0:# 请补充向train_acc_list列表添加当前模型对于训练集预测精度的代码train_acc = MyTwoLayerNet.accuracy(x_train, t_train)# 请补充向test_acc_list列表添加当前模型对于测试集预测精度的代码test_acc = MyTwoLayerNet.accuracy(x_test, t_test)train_acc_list.append(train_acc)test_acc_list.append(test_acc)# 输出一个epoch完成后模型分别在训练集和测试集上的预测精度以及损失值print("iteration:{} ,train acc:{}, test acc:{} ,loss:{}".format(i, round(train_acc, 3), round(test_acc, 3),round(loss, 2)))
(四) 结果分析
运行约15个小时后的结果

初始精度大约为0.1,因为一共10个数字……
经过如此之长的时间训练精度也只提高到0.2
效果这样差的原因是:
① 没有用上GPU
② 梯度下降算法过于朴素,没有用上反向传播
项目结构

(五) 调试报告
- 权重矩阵的形状不知道如何设置,联想到神经网络的示意图,每层网络之间有多条连线,每个连线对应一个权重,故权重矩阵设置为上一层神经元个数X下一层神经元个数,即
# 第一层的权重
self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size)
# 第二层的权重
self.params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size)
- 训练太慢
将每一次的训练批数设置为1,即
# 计算一个epoch所需的训练迭代次数(一个epoch定义为所有训练数据都遍历过一次所需的迭代次数)
iter_per_epoch = 1
- 写计算梯度的函数时应当注意每算完一个梯度要将矩阵还原
(六) 实验小结
本次实验没有通过深度学习框架,而是主要依靠numpy库构建了一个含有一个隐藏层的神经网络,将交叉熵作为损失函数,在mnist训练集和测试集上分别求精度,更深刻地体会到了神经网络的运作原理,可以改进的地方有:
- 梯度下降方式过于朴素,导致每次训练时间开销大
- 神经网络的形状是写死的,不利于扩展
此外我加深了对机器学习的认识,无论那种类型的神经网络,本质上都可以看作是一个数学函数,其输入输出由具体情景决定,函数的框架在训练前就已经设定好,训练的本质是是通过输出与目标值的比对,不断修改这个函数的参数值,直到输出与目标的差距很小,就可以认为得到了一个较好的模型。
相关文章:

sqlserver 三种恢复模式
sql server数据库提供了三种恢复模式:完整,简单和大容量日志,这些模式决定了sql server如何使用事务日志,如何选择它要记录的操作,以及是否截断日志。截断事务日志是删除己执行事务并把该日志空间让给新事务的过程&…

Confluence 6 配置日志
我们推荐你根据你的需求来配置你自己的 Confluence 日志。你可以有下面 2 种方法来修改你的日志:通过 Confluence 管理员控制台进行配置 – 你的修改仅在本次修改有效,下次重启后将会把所有修改重置。编辑属性文件 – 你的修改将会在下次重启后生效同时针…

最近最近在微软的Mobile Soft factory
最近公司在做PDA项目的开发, 我主要负责Mobile的框架设计和开发。以前都是在做winform程序,对Mobile 的开发 知之甚少,现在突然开始做mobile的项目,压力有点大! 不知该从何处下手,幸好发现微软提供的Mobile…
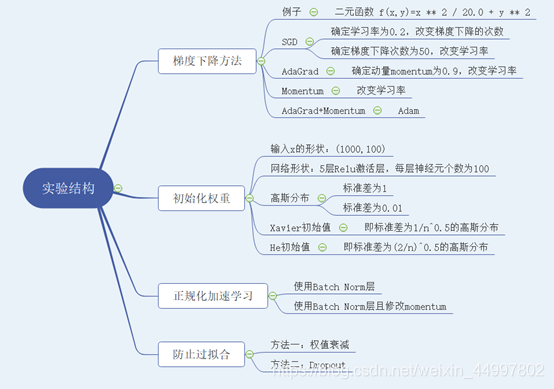
神经网络训练技巧
文章目录一、问题描述二、 设计简要描述三、程序清单四、结果分析五、调试报告六、实验小结一、问题描述 基于二元函数f(x,y)z1/20 x2y2掌握梯度下降和权重初始化的技巧,基于手写体识别掌握正规化和两种防止过拟合的技巧。 二、 设计简要描述 梯度下降方法 1.1.1 …

Unix的轻巧“约取而实得”(上篇)
在经过上机操作实践以及掌握Unix系统相关的基础知识之后,可以说已跨进了迈向成功的门槛。接着要登堂入室,继续专进,就必须更加深入的了解Unix基本命令的功能、使用并掌握一些必备的技巧。这一轮学习会有一定难度,需要强烈的求知欲…
操作系统2--操作系统结构
操作系统结构 操作系统的结构需要从这几个方面来考虑:他为用户提供了哪些服务和界面,系统各个组成部分及其相互关系 操作系统的操作 大致可分为:进程管理,主存管理,文件管理,辅存管理和IO管理 进程管理 进程的创建和结束进程的挂起和恢复进程锁\进程交互\进程死锁的规则内存管理…

Windows环境下启动Mysql服务提示“1067 进程意外终止”的解决方案
2019独角兽企业重金招聘Python工程师标准>>> 在Windows服务里启动Mysql服务时提示“1067 进程意外终止”。 此时我们打开计算机管理查看Windows日志,如下图所示: 完整错误提示如下: The server option lower_case_table_names is …
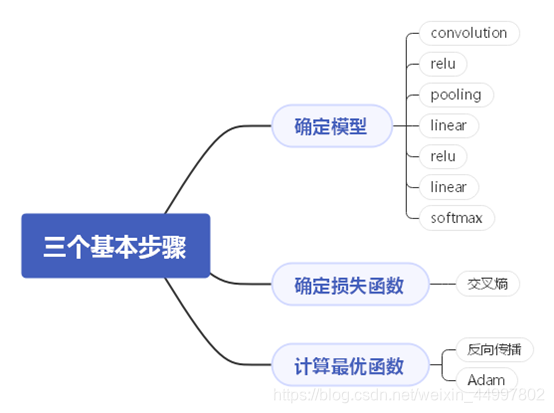
不使用任何框架实现CNN网络
文章目录一、 问题描述二、 设计简要描述三、程序清单四、结果分析五、调试报告六、实验小结一、 问题描述 基于Numpy和函数im2col与col2im来实现一个简单的卷积神经网络,将其用于手写体识别。 二、 设计简要描述 机器学习的三个基本步骤—— 程序设计思路——(…
关于刘冬大侠Spring.NET系列学习笔记3的一点勘正
诚如他第22楼“只因渴求等待”提出的疑问一样,他的下面那一段代码是存在一点点问题的, XElement root XElement.Load(fileName);var objects from obj in root.Elements("object") select obj; 如果照搬照抄刘冬大侠的这段代码那是不会成功读…
什么叫做KDJ指标
什么叫做KDJ指标 KDJ指标的中文名称是随机指数,最早起源于期货市场。 KDJ指标的应用法则KDJ指标是三条曲线,在应用时主要从五个方面进行考虑:KD的取值的绝对数字;KD曲线的形态;KD指标的交叉;KD指标的背离&a…

vim常用命令总结 (转)
在命令状态下对当前行用 (连按两次), 或对多行用n(n是自然数)表示自动缩进从当前行起的下面n行。你可以试试把代码缩进任意打乱再用n排版,相当于一般IDE里的code format。使用ggG可对整篇代码进行排版。 vim 选择文本&…
敏捷过程、极限编程和SCRUM的关系
极限编程是最知名的敏捷开发过程,SCRUM是最经典的极限编程。 层次关系从大到小是:敏捷过程>极限编程>SCRUM
C#双面打印解决方法(打印word\excel\图片)
最近需要按顺序打印word、excel、图片,其中有的需要单面打印,有的双面。网上查了很多方法。主要集中在几个方式解决 1、word的print和excel的printout里设置单双面 2、printdocument里的printsettings的duplex设置单双面 试过之后效果都不好,…
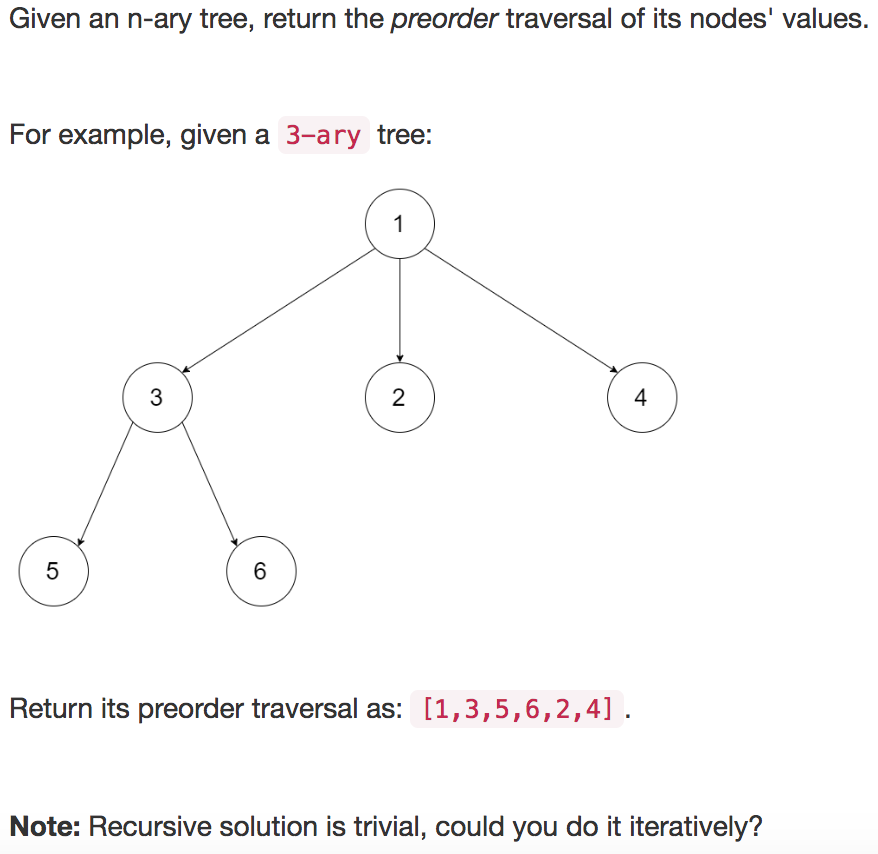
【leetcode】589. N-ary Tree Preorder Traversal
题目如下: 解题思路:凑数题1,话说我这个也是凑数博? 代码如下: class Solution(object):def preorder(self, root):""":type root: Node:rtype: List[int]"""if root None:return []re…
MSDN Visual系列:创建Feature扩展SharePoint列表项或文档的操作菜单项
原文:http://msdn2.microsoft.com/en-us/library/bb418731.aspx在SharePoint中我们可以通过创建一个包含CustomAction元素定义的Feature来为列表项或文档添加一个自定义操作菜单项(Entry Control Block Item)。我们可以添加自定义命令到默认的SharePoint用户界面中。…

评审过程中,A小组发现了5个缺陷,B小组发现了9个缺陷,他们发现的缺陷中有3个是相同的。请问:还有多少个潜在的缺陷没有发现?
分析:这一个“捉-放-捉”问题 背景: 求解: 可以将A看成是第一次捕捉,发现了5个缺陷,全部打上标记 B看成是第二次捕捉,发现了9个缺陷,其中有3个有标记 那么可以算出系统中一共存在的缺陷数量为…
Dell PowerVault TL4000 磁带机卡带问题
最近一段时间Dell PowerVault TL4000 磁带机故障频繁,昨天我在管理系统里面看到Library Status告警:HE: sled blocked, error during sled movement to rotation position Code: 8D 07 ,Dell工程师根据Code: 8D 07判断是磁带卡带了࿰…

【git】git入门之把自己的项目上传到github
1. 首先当然是要有一个GIT账号:github首页 2. 然后在电脑上安装一个git:git首页 注册和安装这里我就不说了。我相信大家做这个都没有问题。 3. 上述两件事情做完了,就登陆到github页面 1)首先我们点标注【1】的小三角,…

Java面试查漏补缺
一、基础 1、&和&&的区别。 【概述】 &&只能用作逻辑与(and)运算符(具有短路功能);但是&可以作为逻辑与运算符(是“无条件与”,即没有短路的功能)…
selenium之frame操作
前言 很多时候定位元素时候总是提示元素定位不到的问题,明明元素就在那里,这个时候就要关注你所定位的元素是否在frame和iframe里面 frame标签包含frameset、frame、iframe三种,frameset和普通的标签一样,不会影响正常的定位&…
(C++)将整型数组所有成员初始化为0的三种简单方法
#include<cstdio> #include<cstring>int main(){//1.方法1 int a[10] {};//2.方法2 int b[10] {0};//3.方法3 注意:需要加 <cstring>头文件 int c[10];memset(c,0,sizeof(c));for(int i0;i<9;i){printf("a[%d]%d\n",i,a[i]);}prin…
(C++)对用户输入的整形数组进行冒泡排序
#include<cstdio>//冒泡排序的本质在于交换 //1.读入数组 //2.排序 //3.输出数组 int main(){int a[10];printf("%s","请依次输入数组的10个整型元素:\n");for(int i0;i<9;i){scanf("%d",&a[i]);} int temp 0;for(int …
U3D的Collider
被tx鄙视的体无完肤,回来默默的继续看书,今天看u3d,试了下collider,发现cube添加了rapidbody和boxcollider后落在terrain后就直接穿过去了... 找了一会原因,看到一个collider的参数说明: 分别选中立方体和树的模型&…
限制程序只打开一个实例(转载)
当我们在做一些管理平台类的程序(比如Windows的任务管理器)时,往往需要限制程序只能打开一个实例。解决这个问题的大致思路很简单,无非是在程序打开的时候判断一下是否有与自己相同的进程开着,如果有,则关闭…
dao.xml
<select id"selectItemkindByPolicyNo" resultMap"BaseResultMap" parameterType"java.util.List"> select * from prpcitemkind kind where kind.PolicyNo in <foreach collection"list" item"item&q…
(C++)字符数组初始化的两种方法
#include<cstdio> //字符数组的两种赋值方法 int main(){//1.方法一char str1[14] {I, ,l,o,v,e, ,m,y, ,m,o,m,.};for(int i 0;i<13;i){printf("%c",str1[i]);}printf("\n");//2.方法二,直接赋值字符串(注意,只有初始化…

SQL Server 中update的小计
update中涉及到多个表的: 1.update TableA set a.ColumnCb.ColumnC from TableA a inner join TableB b on a.ColumnDb.ColumnD 这样是不对的,报错如下: 消息 4104,无法绑定由多个部分组成的标识符 “xxxx” 虽然前面的TableA和后…
MFC中的字符串转换
在VC中有着一大把字符串类型。从传统的char*到std::string到CString,简直是多如牛毛。期间的转换相信也是绕晕了许多的人,我曾就是其中的一个。还好,MS还没有丧失功德心,msdn的一篇文章详细的解析了各种字符串的转换问题ÿ…
tf.nn.relu
tf.nn.relu(features, name None) 这个函数的作用是计算激活函数 relu,即 max(features, 0)。即将矩阵中每行的非最大值置0。 import tensorflow as tfa tf.constant([-1.0, 2.0]) with tf.Session() as sess:b tf.nn.relu(a)print sess.run(b) 以上程序输出的结…
(C++)字符数组的四种输入输出方式
scanf/printf%s getchar()/putchar() 前者不带参数后者带 gets()/puts() 二者都带参数,为一维字符数组或二维字符数组的一维 运用指针scanf/printf或getchar/putchar #include<cstdio> //字符数组的3种输入输出方式int main(){//1.scanf/printf%schar st…