神经网络训练技巧
文章目录
- 一、问题描述
- 二、 设计简要描述
- 三、程序清单
- 四、结果分析
- 五、调试报告
- 六、实验小结
一、问题描述
基于二元函数f(x,y)=z=1/20 x2+y2掌握梯度下降和权重初始化的技巧,基于手写体识别掌握正规化和两种防止过拟合的技巧。
二、 设计简要描述
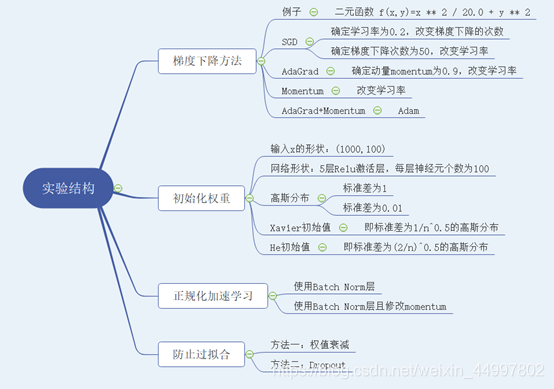
- 梯度下降方法
1.1.1 对于SGD模型,固定初始坐标,确定学习率为0.2,改变梯度下降的次数
需要改动的代码 for i in range(50):
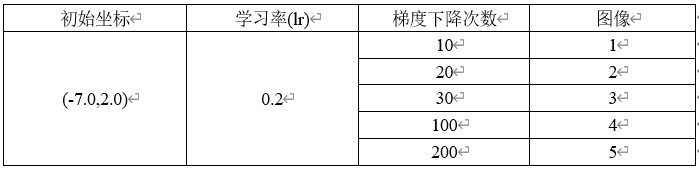

图1

图2

图3

图4

图5
1.1.2 对于SGD模型,固定初始坐标,确定梯度下降次数为50,改变学习率
需要改动的代码 optimizer = SGD(lr=0.7)
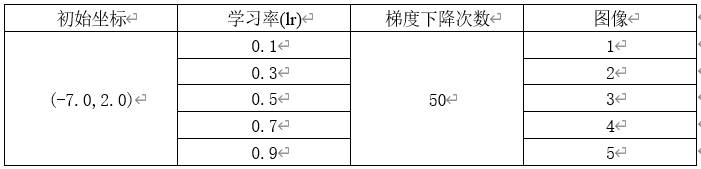

图1

图2

图3
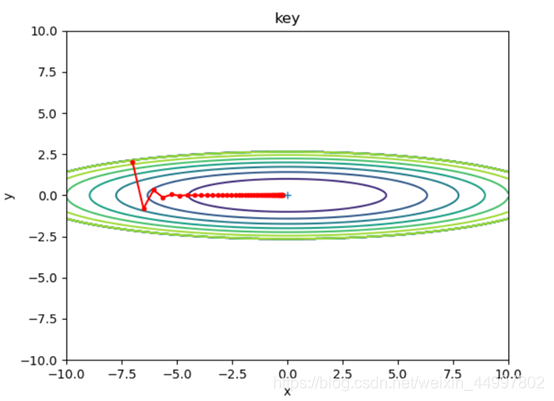
图4

图5
1.2 对于Momentum模型,固定初始坐标,确定动量momentum为0.9,改变学习率
需要改变的代码 optimizer = Momentum(lr=0.5,momentum=0.9)
初始坐标 学习率(lr) 动量(momentum) 图像


图1
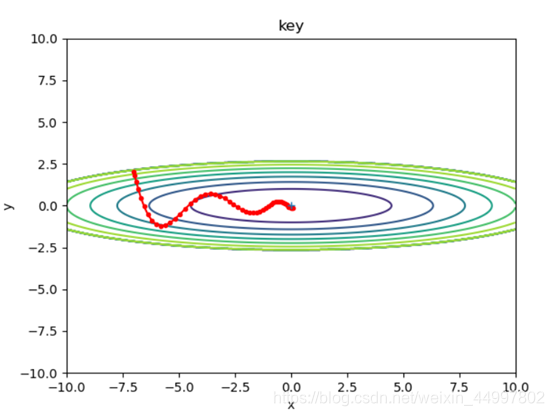
图2

图3

图4
1.3 对于AdaGrad模型,固定初始坐标,改变学习率
需要改变的代码行 optimizer = AdaGrad(lr=0.5)


图1

图2

图3
- 初始化权重
2.1 五层网络初始权重是标准差为1的高斯分布,其每一层的激活值分布情况
关键代码 w = np.random.randn(node_num, node_num) * 1

2.2 五层网络初始权重是标准差为0.01的高斯分布,其每一层的激活值分布情况
关键代码 w = np.random.randn(node_num, node_num) * 0.01

2.3 五层网络初始权重值为Xavier初始值,其每一层的激活值分布情况
关键代码 w = np.random.randn(node_num, node_num) / np.sqrt(node_num)

2.4 五层网络初始权重值为He初始值,其每一层的激活值分布情况
关键代码 w = np.random.randn(node_num, node_num) / np.sqrt(node_num/2)

3.正则化
3.1 不使用batch norm层

3.2 使用batch norm层

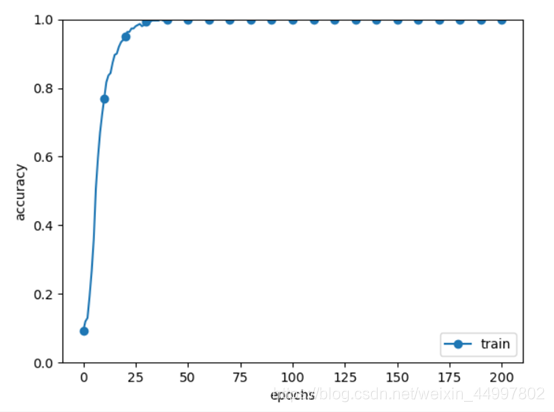
图1

图2

图3

图4
4.正则化
4.1 过拟合的结果,无权重衰减,无dropout

4.2 有权重衰减,无dropout

主要修改代码行
def __init__(self, input_size, hidden_size_list, output_size,activation='relu', weight_init_std='relu', weight_decay_lambda=0.1):# 使用权重衰减self.weight_decay_lambda = weight_decay_lambda在损失函数中添加
# 使用权重衰减weight_decay = 0for idx in range(1, self.hidden_layer_num + 2):W = self.params['W' + str(idx)]weight_decay += 0.5 * self.weight_decay_lambda * np.sum(W ** 2)
return self.last_layer.forward(y, t) + weight_decaygradient函数修改for idx in range(1, self.hidden_layer_num + 2):grads['W' + str(idx)] = self.layers['Linear' + str(idx)].dW + self.weight_decay_lambda * self.params['W' + str(idx)]grads['b' + str(idx)] = self.layers['Linear' + str(idx)].db
4.3 无权重衰减,有dropout

主要修改代码行
def __init__(self, input_size, hidden_size_list, output_size,activation='relu', weight_init_std='relu', weight_decay_lambda=0,use_dropout=True, dropout_ration=0.2):#添加dropout层self.use_dropout = use_dropout在定义生成层时添加
if self.use_dropout:self.layers['Dropout' + str(idx)] = Dropout(dropout_ration)
三、程序清单

AdaGrad.py
import numpy as npclass AdaGrad:def __init__(self, lr=0.01):self.lr = lrself.h = Nonedef step(self, params, grads):if self.h is None:self.h = {}for key, val in params.items():self.h[key] = np.zeros_like(val)for key in params.keys():self.h[key] += grads[key] * grads[key]params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
Momentum.py
import numpy as npclass Momentum:"""Momentum SGD"""def __init__(self, lr=0.01, momentum=0.9):self.lr = lrself.momentum = momentumself.v = Nonedef step(self, params, grads):# 初始化速度vif self.v is None:self.v = {}for key, val in params.items():self.v[key] = np.zeros_like(val)for key in params.keys():self.v[key] = self.momentum * self.v[key] - self.lr * grads[key]params[key] += self.v[key]
MultiLayerNet2.py是修改后的网络层代码,综合了三四两部分
import numpy as npclass BatchNormalization:def __init__(self, gamma, beta, momentum=0.3, running_mean=None, running_var=None):self.gamma = gammaself.beta = betaself.momentum = momentumself.input_shape = None # Conv层的情况下为4维,全连接层的情况下为2维# 测试时使用的平均值和方差self.running_mean = running_meanself.running_var = running_var# backward时使用的中间数据self.batch_size = Noneself.xc = Noneself.std = Noneself.dgamma = Noneself.dbeta = Nonedef forward(self, x, train_flg=True):self.input_shape = x.shape#将每一个样本由三维数组转换为一维数组if x.ndim != 2:N, C, H, W = x.shapex = x.reshape(N, -1)#在__forward方法中完成BatchNorm函数的前向传播out = self.__forward(x, train_flg)return out.reshape(*self.input_shape)def __forward(self, x, train_flg):if self.running_mean is None:N, D = x.shapeself.running_mean = np.zeros(D)self.running_var = np.zeros(D)if train_flg:mu = x.mean(axis=0)xc = x - muvar = np.mean(xc**2, axis=0)std = np.sqrt(var + 10e-7)xn = xc / stdself.batch_size = x.shape[0]self.xc = xcself.xn = xnself.std = stdself.running_mean = self.momentum * self.running_mean + (1 - self.momentum) * muself.running_var = self.momentum * self.running_var + (1 - self.momentum) * varelse:xc = x - self.running_meanxn = xc / ((np.sqrt(self.running_var + 10e-7)))out = self.gamma * xn + self.betareturn outdef backward(self, dout):if dout.ndim != 2:N, C, H, W = dout.shapedout = dout.reshape(N, -1)dx = self.__backward(dout)dx = dx.reshape(*self.input_shape)return dxdef __backward(self, dout):dbeta = dout.sum(axis=0)dgamma = np.sum(self.xn * dout, axis=0)dxn = self.gamma * doutdxc = dxn / self.stddstd = -np.sum((dxn * self.xc) / (self.std * self.std), axis=0)dvar = 0.5 * dstd / self.stddxc += (2.0 / self.batch_size) * self.xc * dvardmu = np.sum(dxc, axis=0)dx = dxc - dmu / self.batch_sizeself.dgamma = dgammaself.dbeta = dbetareturn dx
四、结果分析
梯度下降方法
结论一:SGD模型,当学习率固定,梯度下降的次数过少时,f(x,y)无法到达最小值
结论二:SGD模型,当梯度下降的次数固定,增大学习率,每次改变的位置跨度越大。学习率过小时,可能无法到达最低点。
结论三:Momentum确实能够加速收敛、减小震荡,但是要注意设置较小的学习率。
结论四:AdaGrad由于其自身不断减小学习率的特性,可以在最初把学习率设置为一个较大的值。初始化权重
结论:为了解决梯度消失问题,本次实验提供了3中有效的解决方案:
①仍采用高斯分布,但将权重的标准差设为0.01
②使用Xavier权重初始值
③使用He权重初始值
从实验结果可以看出,如果认为各层的激活值越集中于0.5,越不容易发生梯度消失,那么三者的有效性是依次递减的。正则化
结论:对比实验结果可以看出正则化作为有效的加速学习的方法,在momentum值设置为0.9时可以达到加速效果,在0.9以下则不能。防止过拟合
结论:从实验结果可以看出,使用权重衰减的方法和添加dropout层都不失为防止过拟合的好方法,但运行添加了dropout层的程序明显慢很多,且从结果上来看也降低了学习速度。
五、调试报告
控制台报错
Traceback (most recent call last):
File “E:/project/pythonProject/07_trainingSkills/Function.py”, line 23, in
optimizer = Momentum(lr=0.01, momentum=0.9)
TypeError: ‘module’ object is not callable
原因:导包的方式不对
解决:将import Momentum改成from Momentum import Momentum运行Adam模型时控制台报错
Traceback (most recent call last):
File “E:/project/pythonProject/07_trainingSkills/Function.py”, line 44, in
optimizer.step(params, grads)
File “E:\project\pythonProject\07_trainingSkills\Adam.py”, line 26, in step
self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key])
KeyError: ‘y’
原因:没有’y’这个键学会使用numpy.random.randn(d0, d1, …, dn)函数构建不同数学期望μ和方差σ^2的正态分布

学会使用subplot函数确定子图表的位置
前两个参数把空间分成其乘积块数
第三个参数不可以大于前两个参数的乘积

控制台报错
ImportError: cannot import name ‘MultiLayerNet’ from partially initialized module ‘MultiLayerNet’ (most likely due to a circular import)
解决:将所有类移到同一级目录下控制台报错
Compressed file ended before the end-of-stream marker was reached
原因:数据包导到一半停止了
解决:用之前实验下载好的数据包将其覆盖控制台报错
TypeError: forward() takes 2 positional arguments but 3 were given
原因:实际上是全连接层求反向传播只要一个参数而传入了两个
解决:最后一层还是用SoftmaxWithLoss层模拟过拟合的部分,写好网络类后第一次运行结果是这样的

分析:编码方式有问题
解决:中途因为控制台报错改成了独热编码,但实际应该为
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)加入了dropout层并设置dropout_ration=0.2后学习效率并不如指导书上一样高,而是

分析:忘记修改predict函数
解决:predict函数修改前后分别为
前
def predict(self, x):for layer in self.layers.values():x = layer.forward(x)return x
后
def predict(self, x, train_flg=False):for key, layer in self.layers.items():if "Dropout" in key or "BatchNorm" in key:x = layer.forward(x, train_flg)else:x = layer.forward(x)return x
修改后的实验结果为

学习效率仍是很低,再分析指导书上的应该是同时用上了batch norm和dropout
于是将参数use_dropout设置为True

六、实验小结
本次实验在实验五六的基础上,通过对比实验的方式,学习了几种不同的梯度下降方式,初始化权重方式,加速网络学习的方式以及防止过拟合的方式。遇到的困难主要是第四部分防止过拟合的网络构建。
相关文章:

Unix的轻巧“约取而实得”(上篇)
在经过上机操作实践以及掌握Unix系统相关的基础知识之后,可以说已跨进了迈向成功的门槛。接着要登堂入室,继续专进,就必须更加深入的了解Unix基本命令的功能、使用并掌握一些必备的技巧。这一轮学习会有一定难度,需要强烈的求知欲…

操作系统2--操作系统结构
操作系统结构 操作系统的结构需要从这几个方面来考虑:他为用户提供了哪些服务和界面,系统各个组成部分及其相互关系 操作系统的操作 大致可分为:进程管理,主存管理,文件管理,辅存管理和IO管理 进程管理 进程的创建和结束进程的挂起和恢复进程锁\进程交互\进程死锁的规则内存管理…

Windows环境下启动Mysql服务提示“1067 进程意外终止”的解决方案
2019独角兽企业重金招聘Python工程师标准>>> 在Windows服务里启动Mysql服务时提示“1067 进程意外终止”。 此时我们打开计算机管理查看Windows日志,如下图所示: 完整错误提示如下: The server option lower_case_table_names is …
不使用任何框架实现CNN网络
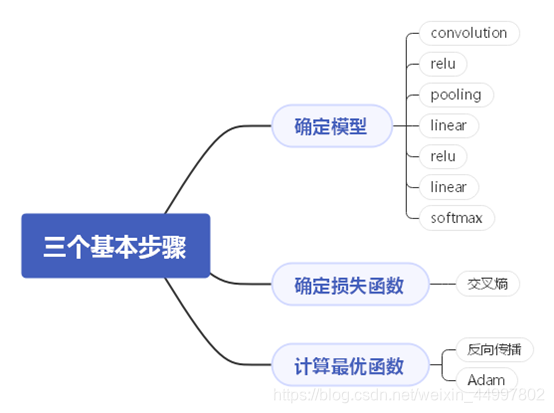
文章目录一、 问题描述二、 设计简要描述三、程序清单四、结果分析五、调试报告六、实验小结一、 问题描述 基于Numpy和函数im2col与col2im来实现一个简单的卷积神经网络,将其用于手写体识别。 二、 设计简要描述 机器学习的三个基本步骤—— 程序设计思路——(…
关于刘冬大侠Spring.NET系列学习笔记3的一点勘正
诚如他第22楼“只因渴求等待”提出的疑问一样,他的下面那一段代码是存在一点点问题的, XElement root XElement.Load(fileName);var objects from obj in root.Elements("object") select obj; 如果照搬照抄刘冬大侠的这段代码那是不会成功读…
什么叫做KDJ指标
什么叫做KDJ指标 KDJ指标的中文名称是随机指数,最早起源于期货市场。 KDJ指标的应用法则KDJ指标是三条曲线,在应用时主要从五个方面进行考虑:KD的取值的绝对数字;KD曲线的形态;KD指标的交叉;KD指标的背离&a…

vim常用命令总结 (转)
在命令状态下对当前行用 (连按两次), 或对多行用n(n是自然数)表示自动缩进从当前行起的下面n行。你可以试试把代码缩进任意打乱再用n排版,相当于一般IDE里的code format。使用ggG可对整篇代码进行排版。 vim 选择文本&…
敏捷过程、极限编程和SCRUM的关系
极限编程是最知名的敏捷开发过程,SCRUM是最经典的极限编程。 层次关系从大到小是:敏捷过程>极限编程>SCRUM
C#双面打印解决方法(打印word\excel\图片)
最近需要按顺序打印word、excel、图片,其中有的需要单面打印,有的双面。网上查了很多方法。主要集中在几个方式解决 1、word的print和excel的printout里设置单双面 2、printdocument里的printsettings的duplex设置单双面 试过之后效果都不好,…
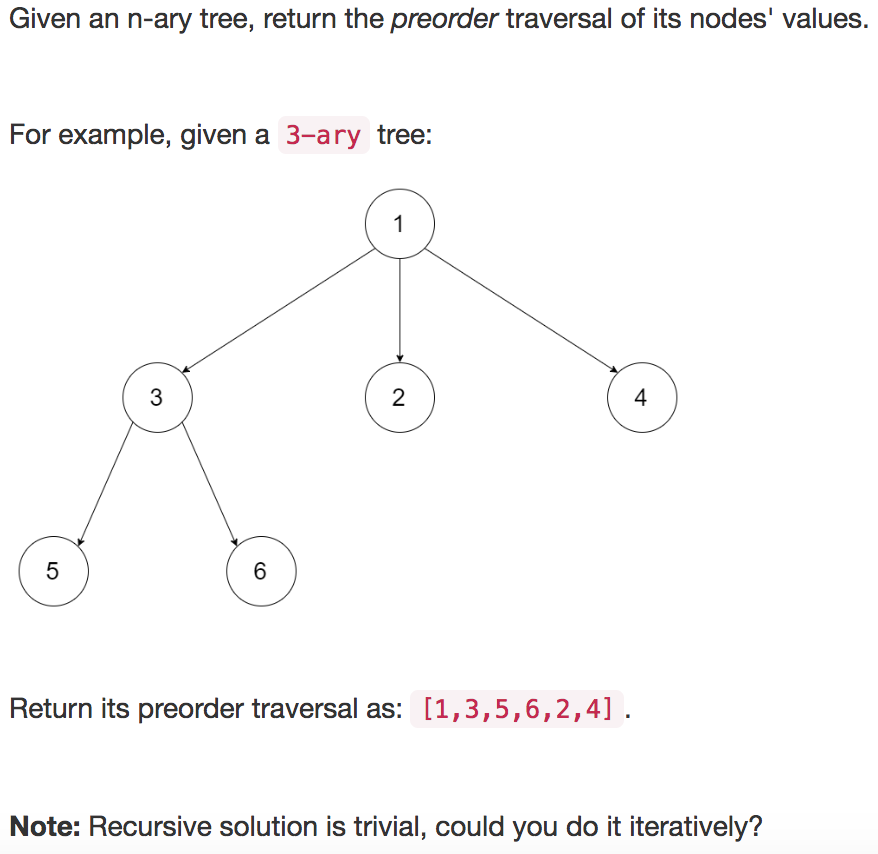
【leetcode】589. N-ary Tree Preorder Traversal
题目如下: 解题思路:凑数题1,话说我这个也是凑数博? 代码如下: class Solution(object):def preorder(self, root):""":type root: Node:rtype: List[int]"""if root None:return []re…
MSDN Visual系列:创建Feature扩展SharePoint列表项或文档的操作菜单项
原文:http://msdn2.microsoft.com/en-us/library/bb418731.aspx在SharePoint中我们可以通过创建一个包含CustomAction元素定义的Feature来为列表项或文档添加一个自定义操作菜单项(Entry Control Block Item)。我们可以添加自定义命令到默认的SharePoint用户界面中。…

评审过程中,A小组发现了5个缺陷,B小组发现了9个缺陷,他们发现的缺陷中有3个是相同的。请问:还有多少个潜在的缺陷没有发现?
分析:这一个“捉-放-捉”问题 背景: 求解: 可以将A看成是第一次捕捉,发现了5个缺陷,全部打上标记 B看成是第二次捕捉,发现了9个缺陷,其中有3个有标记 那么可以算出系统中一共存在的缺陷数量为…
Dell PowerVault TL4000 磁带机卡带问题
最近一段时间Dell PowerVault TL4000 磁带机故障频繁,昨天我在管理系统里面看到Library Status告警:HE: sled blocked, error during sled movement to rotation position Code: 8D 07 ,Dell工程师根据Code: 8D 07判断是磁带卡带了࿰…

【git】git入门之把自己的项目上传到github
1. 首先当然是要有一个GIT账号:github首页 2. 然后在电脑上安装一个git:git首页 注册和安装这里我就不说了。我相信大家做这个都没有问题。 3. 上述两件事情做完了,就登陆到github页面 1)首先我们点标注【1】的小三角,…

Java面试查漏补缺
一、基础 1、&和&&的区别。 【概述】 &&只能用作逻辑与(and)运算符(具有短路功能);但是&可以作为逻辑与运算符(是“无条件与”,即没有短路的功能)…
selenium之frame操作
前言 很多时候定位元素时候总是提示元素定位不到的问题,明明元素就在那里,这个时候就要关注你所定位的元素是否在frame和iframe里面 frame标签包含frameset、frame、iframe三种,frameset和普通的标签一样,不会影响正常的定位&…
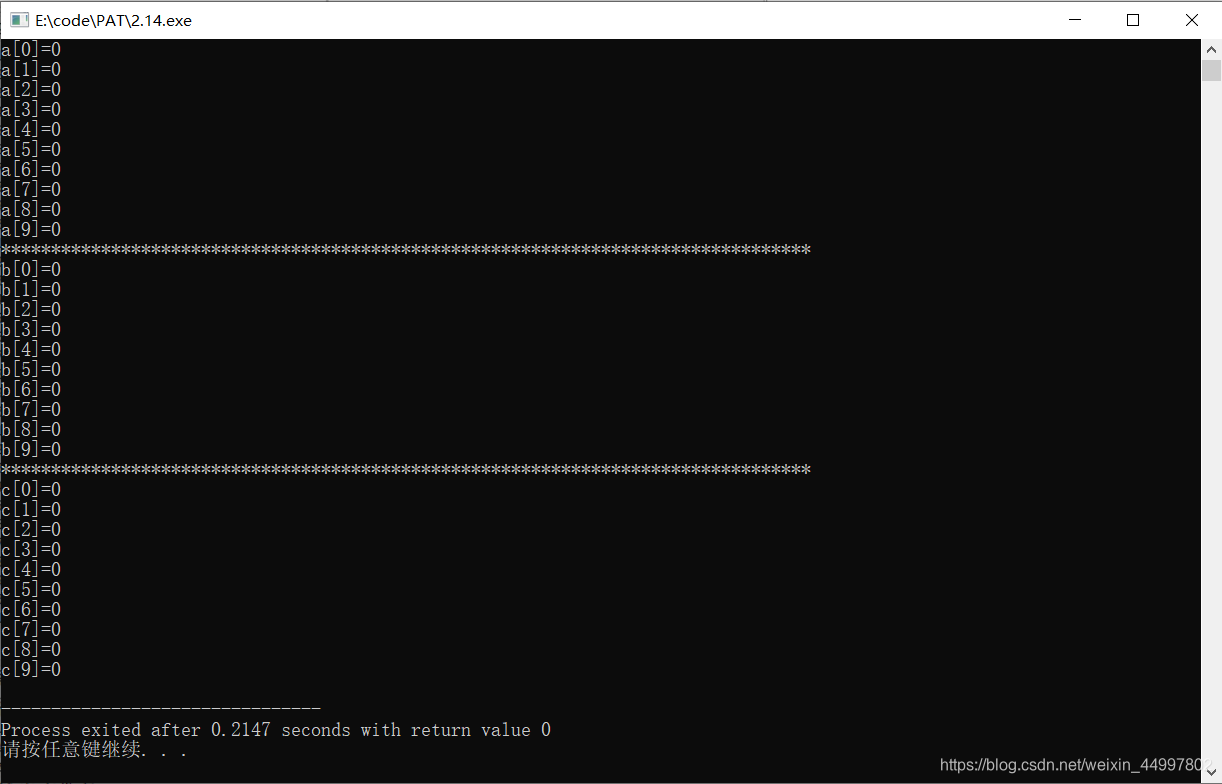
(C++)将整型数组所有成员初始化为0的三种简单方法
#include<cstdio> #include<cstring>int main(){//1.方法1 int a[10] {};//2.方法2 int b[10] {0};//3.方法3 注意:需要加 <cstring>头文件 int c[10];memset(c,0,sizeof(c));for(int i0;i<9;i){printf("a[%d]%d\n",i,a[i]);}prin…
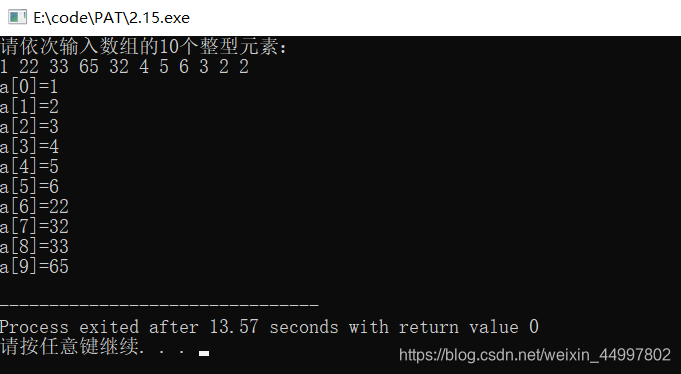
(C++)对用户输入的整形数组进行冒泡排序
#include<cstdio>//冒泡排序的本质在于交换 //1.读入数组 //2.排序 //3.输出数组 int main(){int a[10];printf("%s","请依次输入数组的10个整型元素:\n");for(int i0;i<9;i){scanf("%d",&a[i]);} int temp 0;for(int …
U3D的Collider
被tx鄙视的体无完肤,回来默默的继续看书,今天看u3d,试了下collider,发现cube添加了rapidbody和boxcollider后落在terrain后就直接穿过去了... 找了一会原因,看到一个collider的参数说明: 分别选中立方体和树的模型&…
限制程序只打开一个实例(转载)
当我们在做一些管理平台类的程序(比如Windows的任务管理器)时,往往需要限制程序只能打开一个实例。解决这个问题的大致思路很简单,无非是在程序打开的时候判断一下是否有与自己相同的进程开着,如果有,则关闭…
dao.xml
<select id"selectItemkindByPolicyNo" resultMap"BaseResultMap" parameterType"java.util.List"> select * from prpcitemkind kind where kind.PolicyNo in <foreach collection"list" item"item&q…
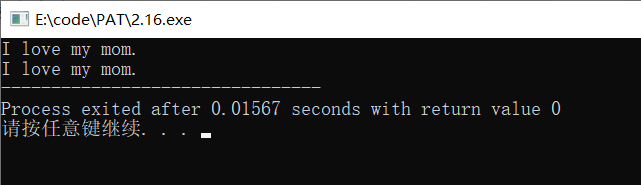
(C++)字符数组初始化的两种方法
#include<cstdio> //字符数组的两种赋值方法 int main(){//1.方法一char str1[14] {I, ,l,o,v,e, ,m,y, ,m,o,m,.};for(int i 0;i<13;i){printf("%c",str1[i]);}printf("\n");//2.方法二,直接赋值字符串(注意,只有初始化…

SQL Server 中update的小计
update中涉及到多个表的: 1.update TableA set a.ColumnCb.ColumnC from TableA a inner join TableB b on a.ColumnDb.ColumnD 这样是不对的,报错如下: 消息 4104,无法绑定由多个部分组成的标识符 “xxxx” 虽然前面的TableA和后…
MFC中的字符串转换
在VC中有着一大把字符串类型。从传统的char*到std::string到CString,简直是多如牛毛。期间的转换相信也是绕晕了许多的人,我曾就是其中的一个。还好,MS还没有丧失功德心,msdn的一篇文章详细的解析了各种字符串的转换问题ÿ…
tf.nn.relu
tf.nn.relu(features, name None) 这个函数的作用是计算激活函数 relu,即 max(features, 0)。即将矩阵中每行的非最大值置0。 import tensorflow as tfa tf.constant([-1.0, 2.0]) with tf.Session() as sess:b tf.nn.relu(a)print sess.run(b) 以上程序输出的结…
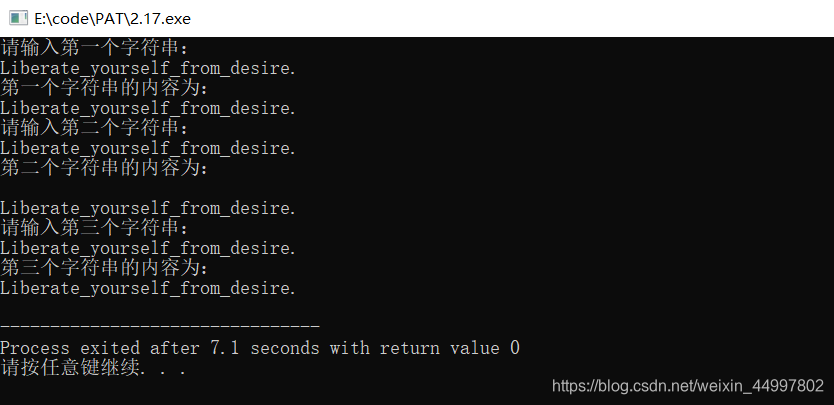
(C++)字符数组的四种输入输出方式
scanf/printf%s getchar()/putchar() 前者不带参数后者带 gets()/puts() 二者都带参数,为一维字符数组或二维字符数组的一维 运用指针scanf/printf或getchar/putchar #include<cstdio> //字符数组的3种输入输出方式int main(){//1.scanf/printf%schar st…

css制作对话框
当你发现好多图都能用css画出来的时候,你就会觉得css很有魅力了。//我是这么觉得的,先不考虑什么兼容问题 像漫画里出现的对话框,往往都是一个对话框然后就加入一个箭头指向说话的那一方,来表示这个内容是谁述说的。 今天认真学了…

Git相关二三事(git reflog 和彩色branch)【转】
转自:https://www.jianshu.com/p/3622ed542c3b 背景 git太常用了,虽然,用起来不难,但也有很多小技巧的东西... 1. 后悔药 哪天不小心,写完代码,没commit,直接reset了或者checkout了,怎么办&…

MS SQL入门基础:备份和恢复系统数据库
系统数据库保存了有关SQL Server 的许多重要数据信息,这些数据的丢失将给系统带来极为严重的后果,所以我们也必须对系统数据库进行备份。这样一旦系统或数据库失败,则可以通过恢复来重建系统数据库。在SQL Server 中重要的系统数据库主要有ma…
(C++)输入输出字符矩阵(二维字符数组)的三种方法
想输出一个这样的字符矩阵 CSU ZJU PKUscanf和printf #include<cstdio> #include<cmath>int main(){char schools[3][3];printf("请输入:\n");for(int i0;i<2;i){scanf("%s",schools[i]);}printf("以下为输出:…