PyTorch基础与简单应用:构建卷积神经网络实现MNIST手写数字分类
文章目录
- (一) 问题描述
- (二) 设计简要描述
- (三) 程序清单
- (四) 结果分析
- (五) 调试报告
- (六) 实验小结
- (七) 参考资料
(一) 问题描述
构建卷积神经网络实现MNIST手写数字分类。
(二) 设计简要描述
机器学习的三个基本步骤——
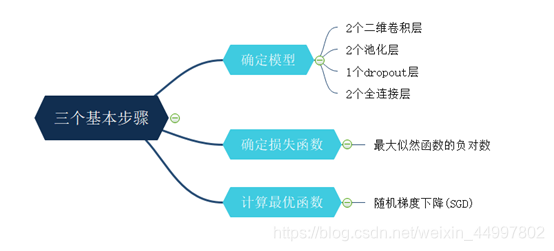
程序设计思路——(此图放大可看清)

(三) 程序清单
import torch
import torchvision
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optimn_epochs = 3 # 定义了学习算法在整个训练数据集中的工作次数
batch_size_train = 64 # 1 <批量大小<训练集的大小 严格来说这个算小批量梯度下降,而不是SGD
batch_size_test = 1000
learning_rate = 0.01
momentum = 0.5 # Momentum可以加速 SGD, 并且抑制震荡
'''可以使得梯度方向不变的维度上速度变快,梯度方向有所改变的维度上的更新速度变慢'''
log_interval = 10
random_seed = 1
torch.manual_seed(random_seed)train_loader = torch.utils.data.DataLoader(torchvision.datasets.MNIST('./data/', train=True, download=True,transform=torchvision.transforms.Compose([torchvision.transforms.ToTensor(), # 用于将图片转换成Tensor格式的数据,并且进行了标准化处理torchvision.transforms.Normalize( # Normalize()用均值和标准偏差对张量图像进行归一化(0.1307,), (0.3081,)) # Normalize()转换使用的值0.1307和0.3081是MNIST数据集的全局平均值和标准偏差])),batch_size=batch_size_train, shuffle=True)
test_loader = torch.utils.data.DataLoader(torchvision.datasets.MNIST('./data/', train=False, download=True,transform=torchvision.transforms.Compose([torchvision.transforms.ToTensor(),torchvision.transforms.Normalize((0.1307,), (0.3081,))])),batch_size=batch_size_test, shuffle=True)# 看看一批数据的形状
'''examples = enumerate(test_loader)
batch_idx, (example_data, example_targets) = next(examples)
print(example_targets)
print(example_data.shape)'''# 查看MNIST数据集中的图片
'''fig = plt.figure()
for i in range(6):plt.subplot(2, 3, i + 1)plt.tight_layout()plt.imshow(example_data[i][0], cmap='gray', interpolation='none')plt.title("Ground Truth: {}".format(example_targets[i]))plt.xticks([])plt.yticks([])
plt.show()'''class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(1, 10, kernel_size=5) # 三个参数的意思分别是:输入信号的通道,卷积产生的通道,卷积核的尺寸self.conv2 = nn.Conv2d(10, 20, kernel_size=5)self.conv2_drop = nn.Dropout2d() # 随机将输入张量中整个通道设置为0self.fc1 = nn.Linear(320, 50) # 全连接层采用线性函数self.fc2 = nn.Linear(50, 10) # 第一个参数是输入样本的大小,第二个是输出def forward(self, x): # forward()传递定义了使用给定的层和函数计算输出的方式x = F.relu(F.max_pool2d(self.conv1(x), 2)) # relu:Rectified Linear Unit,修正线性单元,是一种非线性激活函数x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))x = x.view(-1, 320)x = F.relu(self.fc1(x))x = F.dropout(x, training=self.training)x = self.fc2(x)return F.log_softmax(x) # softmax:输出是每个分类被取到的概率# 初始化网络和优化器
network = Net()
optimizer = optim.SGD(network.parameters(), lr=learning_rate, # SGD:Stochastic Gradient Descentmomentum=momentum)train_losses = []
train_counter = []
test_losses = []
test_counter = [i * len(train_loader.dataset) for i in range(n_epochs + 1)]
del test_counter[0]def train(epoch):network.train()for batch_idx, (data, target) in enumerate(train_loader):optimizer.zero_grad()output = network(data)loss = F.nll_loss(output, target)loss.backward()optimizer.step()if batch_idx % log_interval == 0:print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(epoch, batch_idx * len(data), len(train_loader.dataset),100. * batch_idx / len(train_loader), loss.item()))train_losses.append(loss.item())train_counter.append((batch_idx * 64) + ((epoch - 1) * len(train_loader.dataset)))torch.save(network.state_dict(), './model.pth')torch.save(optimizer.state_dict(), './optimizer.pth')def test():network.eval()test_loss = 0correct = 0with torch.no_grad():for data, target in test_loader:output = network(data)test_loss += F.nll_loss(output, target, size_average=False).item()pred = output.data.max(1, keepdim=True)[1]correct += pred.eq(target.data.view_as(pred)).sum()test_loss /= len(test_loader.dataset)test_losses.append(test_loss)print('\nTest set: Avg. loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(test_loss, correct, len(test_loader.dataset),100. * correct / len(test_loader.dataset)))for epoch in range(1, n_epochs + 1):train(epoch)test()fig = plt.figure()
plt.plot(train_counter, train_losses, color='blue')
plt.scatter(test_counter, test_losses, color='red')
plt.legend(['Train Loss', 'Test Loss'], loc='upper right')
plt.xlabel('number of training examples seen')
plt.ylabel('negative log likelihood loss')
plt.show()(四) 结果分析
一批训练数据是一个形状张量

意味着有1000个例子的28x28像素的灰度(即没有rgb通道)训练结果与测试结果
蓝色为训练集上损失值
红色为一轮训练后测试集上的损失值
一共训练了三轮

模型精度
第一轮训练后测试集上的精度

第二轮训练后测试集上的精度

第三轮训练后测试集上的精度

(五) 调试报告
- 在PyTorch中,构建网络的一个好方法是为我们希望构建的网络创建一个新类,再在类中导入一些子模块,以获得更具可读性的代码。
- 报错:ValueError: x and y must be the same size
定位:plt.scatter(test_counter, test_losses, color=‘red’)
分析:打印出test_counter和test_losses,发现test_counter多一个元素0
解决:在test_counter = [i * len(train_loader.dataset) for i in range(n_epochs + 1)]下面加一行
del test_counter[0] - 增加Dropout layers
其作用是随机将输入张量中部分元素设置为0。对于每次前向调用,被置0的元素都是随机的。
作用是可以提高特征图之间的独立程度,防止过拟合。
(六) 实验小结
- 本次实验使用了PyTorch框架,在实验指导书和官方文档的帮助下训练了一个精度还算不错的卷积神经网络模型,由两个卷积层一个dropout层两个池化层两个全连接层构成。
- 弄清了epoch和batch的区别,epoch是对于整个训练集而言要训练多少次,取值范围是1到正无穷,batch是训练的最小单元,假设总样本量为total,batch_size的取值在1~total之间,一个epoch会进行total/batch_size回训练。
(七) 参考资料
CSDN博客:https://blog.csdn.net/sxf1061700625/article/details/105870851
PyTorch官方文档:https://pytorch-cn.readthedocs.io/zh/latest/
相关文章:

from selenium.webdriver.support.ui import Select
from selenium.webdriver.support.ui import SelectSelect(d.find_element_by_id(ukey_开户行)).first_selected_option.text转载于:https://www.cnblogs.com/paisen/p/3669272.html
rocketmq-flink
https://github.com/apache/rocketmq-externals/tree/master/rocketmq-flink https://issues.apache.org/jira/browse/ROCKETMQ-82
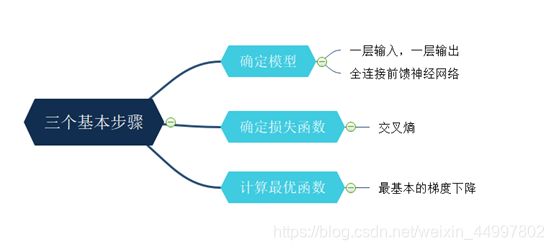
基于Numpy构建全连接前馈神经网络进行手写数字识别
文章目录(一) 问题描述(二) 设计简要描述(三) 程序清单(四) 结果分析(五) 调试报告(六) 实验小结(一) 问题描述 不使用任何机器学习框架,仅仅通过Numpy库构建一个最简单的全连接前馈神经网络,并用该网络识别mnist提供的手写数字体。 (二) 设计简要描述…
sqlserver 三种恢复模式
sql server数据库提供了三种恢复模式:完整,简单和大容量日志,这些模式决定了sql server如何使用事务日志,如何选择它要记录的操作,以及是否截断日志。截断事务日志是删除己执行事务并把该日志空间让给新事务的过程&…

Confluence 6 配置日志
我们推荐你根据你的需求来配置你自己的 Confluence 日志。你可以有下面 2 种方法来修改你的日志:通过 Confluence 管理员控制台进行配置 – 你的修改仅在本次修改有效,下次重启后将会把所有修改重置。编辑属性文件 – 你的修改将会在下次重启后生效同时针…

最近最近在微软的Mobile Soft factory
最近公司在做PDA项目的开发, 我主要负责Mobile的框架设计和开发。以前都是在做winform程序,对Mobile 的开发 知之甚少,现在突然开始做mobile的项目,压力有点大! 不知该从何处下手,幸好发现微软提供的Mobile…
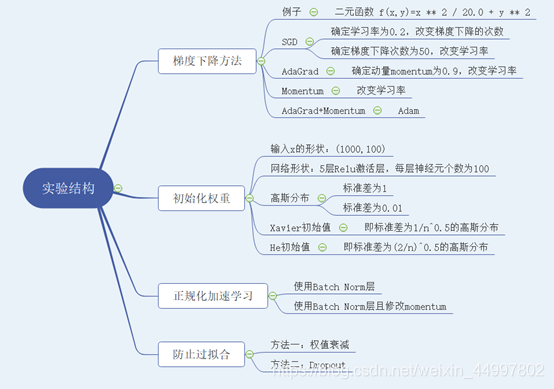
神经网络训练技巧
文章目录一、问题描述二、 设计简要描述三、程序清单四、结果分析五、调试报告六、实验小结一、问题描述 基于二元函数f(x,y)z1/20 x2y2掌握梯度下降和权重初始化的技巧,基于手写体识别掌握正规化和两种防止过拟合的技巧。 二、 设计简要描述 梯度下降方法 1.1.1 …

Unix的轻巧“约取而实得”(上篇)
在经过上机操作实践以及掌握Unix系统相关的基础知识之后,可以说已跨进了迈向成功的门槛。接着要登堂入室,继续专进,就必须更加深入的了解Unix基本命令的功能、使用并掌握一些必备的技巧。这一轮学习会有一定难度,需要强烈的求知欲…
操作系统2--操作系统结构
操作系统结构 操作系统的结构需要从这几个方面来考虑:他为用户提供了哪些服务和界面,系统各个组成部分及其相互关系 操作系统的操作 大致可分为:进程管理,主存管理,文件管理,辅存管理和IO管理 进程管理 进程的创建和结束进程的挂起和恢复进程锁\进程交互\进程死锁的规则内存管理…

Windows环境下启动Mysql服务提示“1067 进程意外终止”的解决方案
2019独角兽企业重金招聘Python工程师标准>>> 在Windows服务里启动Mysql服务时提示“1067 进程意外终止”。 此时我们打开计算机管理查看Windows日志,如下图所示: 完整错误提示如下: The server option lower_case_table_names is …
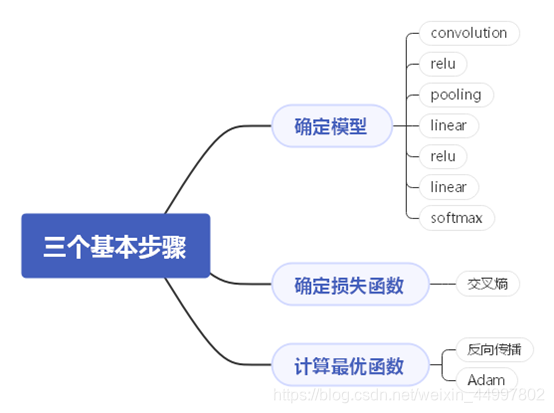
不使用任何框架实现CNN网络
文章目录一、 问题描述二、 设计简要描述三、程序清单四、结果分析五、调试报告六、实验小结一、 问题描述 基于Numpy和函数im2col与col2im来实现一个简单的卷积神经网络,将其用于手写体识别。 二、 设计简要描述 机器学习的三个基本步骤—— 程序设计思路——(…
关于刘冬大侠Spring.NET系列学习笔记3的一点勘正
诚如他第22楼“只因渴求等待”提出的疑问一样,他的下面那一段代码是存在一点点问题的, XElement root XElement.Load(fileName);var objects from obj in root.Elements("object") select obj; 如果照搬照抄刘冬大侠的这段代码那是不会成功读…
什么叫做KDJ指标
什么叫做KDJ指标 KDJ指标的中文名称是随机指数,最早起源于期货市场。 KDJ指标的应用法则KDJ指标是三条曲线,在应用时主要从五个方面进行考虑:KD的取值的绝对数字;KD曲线的形态;KD指标的交叉;KD指标的背离&a…

vim常用命令总结 (转)
在命令状态下对当前行用 (连按两次), 或对多行用n(n是自然数)表示自动缩进从当前行起的下面n行。你可以试试把代码缩进任意打乱再用n排版,相当于一般IDE里的code format。使用ggG可对整篇代码进行排版。 vim 选择文本&…
敏捷过程、极限编程和SCRUM的关系
极限编程是最知名的敏捷开发过程,SCRUM是最经典的极限编程。 层次关系从大到小是:敏捷过程>极限编程>SCRUM
C#双面打印解决方法(打印word\excel\图片)
最近需要按顺序打印word、excel、图片,其中有的需要单面打印,有的双面。网上查了很多方法。主要集中在几个方式解决 1、word的print和excel的printout里设置单双面 2、printdocument里的printsettings的duplex设置单双面 试过之后效果都不好,…
【leetcode】589. N-ary Tree Preorder Traversal
题目如下: 解题思路:凑数题1,话说我这个也是凑数博? 代码如下: class Solution(object):def preorder(self, root):""":type root: Node:rtype: List[int]"""if root None:return []re…
MSDN Visual系列:创建Feature扩展SharePoint列表项或文档的操作菜单项
原文:http://msdn2.microsoft.com/en-us/library/bb418731.aspx在SharePoint中我们可以通过创建一个包含CustomAction元素定义的Feature来为列表项或文档添加一个自定义操作菜单项(Entry Control Block Item)。我们可以添加自定义命令到默认的SharePoint用户界面中。…

评审过程中,A小组发现了5个缺陷,B小组发现了9个缺陷,他们发现的缺陷中有3个是相同的。请问:还有多少个潜在的缺陷没有发现?
分析:这一个“捉-放-捉”问题 背景: 求解: 可以将A看成是第一次捕捉,发现了5个缺陷,全部打上标记 B看成是第二次捕捉,发现了9个缺陷,其中有3个有标记 那么可以算出系统中一共存在的缺陷数量为…
Dell PowerVault TL4000 磁带机卡带问题
最近一段时间Dell PowerVault TL4000 磁带机故障频繁,昨天我在管理系统里面看到Library Status告警:HE: sled blocked, error during sled movement to rotation position Code: 8D 07 ,Dell工程师根据Code: 8D 07判断是磁带卡带了࿰…

【git】git入门之把自己的项目上传到github
1. 首先当然是要有一个GIT账号:github首页 2. 然后在电脑上安装一个git:git首页 注册和安装这里我就不说了。我相信大家做这个都没有问题。 3. 上述两件事情做完了,就登陆到github页面 1)首先我们点标注【1】的小三角,…

Java面试查漏补缺
一、基础 1、&和&&的区别。 【概述】 &&只能用作逻辑与(and)运算符(具有短路功能);但是&可以作为逻辑与运算符(是“无条件与”,即没有短路的功能)…
selenium之frame操作
前言 很多时候定位元素时候总是提示元素定位不到的问题,明明元素就在那里,这个时候就要关注你所定位的元素是否在frame和iframe里面 frame标签包含frameset、frame、iframe三种,frameset和普通的标签一样,不会影响正常的定位&…
(C++)将整型数组所有成员初始化为0的三种简单方法
#include<cstdio> #include<cstring>int main(){//1.方法1 int a[10] {};//2.方法2 int b[10] {0};//3.方法3 注意:需要加 <cstring>头文件 int c[10];memset(c,0,sizeof(c));for(int i0;i<9;i){printf("a[%d]%d\n",i,a[i]);}prin…
(C++)对用户输入的整形数组进行冒泡排序
#include<cstdio>//冒泡排序的本质在于交换 //1.读入数组 //2.排序 //3.输出数组 int main(){int a[10];printf("%s","请依次输入数组的10个整型元素:\n");for(int i0;i<9;i){scanf("%d",&a[i]);} int temp 0;for(int …
U3D的Collider
被tx鄙视的体无完肤,回来默默的继续看书,今天看u3d,试了下collider,发现cube添加了rapidbody和boxcollider后落在terrain后就直接穿过去了... 找了一会原因,看到一个collider的参数说明: 分别选中立方体和树的模型&…
限制程序只打开一个实例(转载)
当我们在做一些管理平台类的程序(比如Windows的任务管理器)时,往往需要限制程序只能打开一个实例。解决这个问题的大致思路很简单,无非是在程序打开的时候判断一下是否有与自己相同的进程开着,如果有,则关闭…
dao.xml
<select id"selectItemkindByPolicyNo" resultMap"BaseResultMap" parameterType"java.util.List"> select * from prpcitemkind kind where kind.PolicyNo in <foreach collection"list" item"item&q…
(C++)字符数组初始化的两种方法
#include<cstdio> //字符数组的两种赋值方法 int main(){//1.方法一char str1[14] {I, ,l,o,v,e, ,m,y, ,m,o,m,.};for(int i 0;i<13;i){printf("%c",str1[i]);}printf("\n");//2.方法二,直接赋值字符串(注意,只有初始化…

SQL Server 中update的小计
update中涉及到多个表的: 1.update TableA set a.ColumnCb.ColumnC from TableA a inner join TableB b on a.ColumnDb.ColumnD 这样是不对的,报错如下: 消息 4104,无法绑定由多个部分组成的标识符 “xxxx” 虽然前面的TableA和后…