《深入理解Java虚拟机》(第二版)学习3:垃圾收集器
垃圾收集器
如果说收集算法是内存回收的方法论,那么垃圾收集器就是内存回收的具体实现。
我们这里讨论的收集器主要是基于JDK 1.7 Update 14之后的 Hotspot VM 。
Serial 收集器
Serial 收集器是最基本、发展历史最悠久的收集器,曾经(在 JDK 1.3.1 之前)是虚拟机新生代收集的唯一选择。
这个收集器是一个单线程的收集器,但它“单线程”的意义并不仅仅说明它只会使用一个 CPU 或者一条收集线程去完成垃圾收集工作,更重要的是在它进行垃圾收集时,必须暂停其他所有的工作线程,直到它收集结束,如下图:
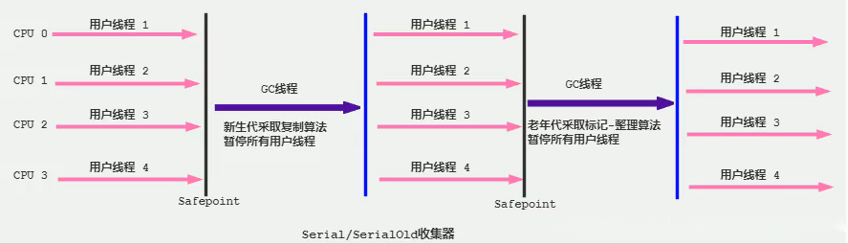
优点:
简单而高效(与其他收集器的单线程比),对于限定单个 CPU 的环境来说,Serial 收集器由于没有线程交互的开销,专心做垃圾收集自然可以获得更高的单线程收集效率。
Serial 收集器对于运行在 Client 模式下的虚拟机来说是一个很好的选择。
Serial Old 收集器
Serial Old 是 Serial 收集器的老年代版本,它同样是一个单线程收集器,使用“标记-整理”算法。
这个收集器的主要意义也是在于给 Client 模式下的虚拟机使用。
如果在 Server 模式下,那么它还有两大用途:
- 在 JDK 1.5 以及之前的版本中与 Parallel Scavenge 收集器搭配使用
- 作为 CMS 收集器的后备预案,在并发收集发生 Concurrent Mode Failure 时使用
ParNew 收集器
ParNew 收集器其实就是 Serial 收集器的多线程版本,除了使用多条线程进行垃圾收集之外,其余行为包括 Serial 收集器可用的所有控制参数、收集算法、Stop The World、对象分配原则、回收策略等都与 Serial 收集器完全一样。ParNew 收集器工作过程如下图:
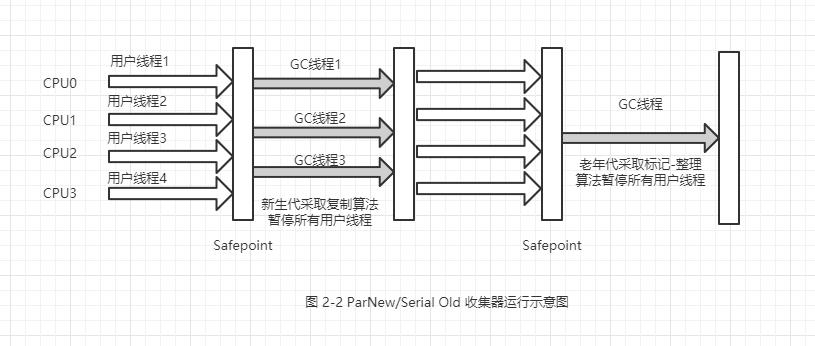
ParNew 收集器是许多运行在 Server 模式下的虚拟机中首选的新生代收集器,其中有一个与性能无关但很重要的原因是,除了 Serial 收集器外,目前只有它能与 CMS 收集器配合工作。
ParNew 收集器默认开启的收集线程数与 CPU 的数量相同,在 CPU 非常多(譬如32个)的环境下,可以使用 -XX:ParallelGCThreads 参数来限制垃圾收集的线程数。
Parallel Scavenge 收集器
Parallel Scavenge 收集器是一个新生代收集器,它也是使用复制算法的收集器,又是并行的多线程收集器…看上去和 ParNew 都一样,那它有什么特别之处呢?
不同点:
- CMS 等收集器:尽可能地缩短垃圾收集时用户线程的停顿时间;
- Parallel Scavenge 收集器:达到一个可控制的吞吐量(Throughput)。
所谓吞吐量就是 CPU 用于运行用户代码的时间与 CPU 总消耗时间的比值,即吞吐量 = 运行用户代码时间 / (运行用户代码时间+垃圾收集时间),虚拟机总共运行了100分钟,其中垃圾收集花费掉1分钟,那吞吐量就是99%。
高吞吐量可以高效的利用CPU时间,尽快完成程序的运算任务,(意味着暂停时间可能长一些)主要适合那些在后台计算而不需要交互的任务。因此,常见在服务器环境中使用。例如,那些执行批处理、订单处理、工资支付、科学计算的应用程序。
因此,Parallel Scavenge 收集器也被称为“吞吐量优先的垃圾”收集器。
参数说明
-XX:MaxGCPauseMillis
控制最大垃圾收集停顿时间(即 STW 时间)。允许的值是一个大于0的毫秒数,收集器将尽可能地保证内存回收花费的时间不超过设定值。我们也不要把这个值设置得太小,GC 停顿时间缩短是以牺牲吞吐量和新生代空间来换取的,停顿时间在下降,但吞吐量也降下来了-XX:GCTimeRatio
设置吞吐量大小。允许的值是一个大于0且小于100的整数,也就是垃圾收集时间占总时间的比率,相当于是吞吐量的倒数。如果把此参数设置为19,那允许的最大 GC 时间就占总时间的 5%(即1 / (1+19)),默认值为99,就是允许大于1%(即 1 / (1+99))的垃圾收集时间。MaxGCPauseMIllis 越大,这个比例就越高。-XX:+UseAdaptiveSizePolicy
设置 Parallel Scavenge 收集器具有 GC 自适应的调节策略(GC Ergonomics)。
在这种模式下,年轻代的大小、Eden 和 Survivor 的比例、晋升老年代的对象年龄等参数会被自动调整,以达到在堆大小、吞吐量和停顿时间之间的平衡点。在手动调优比较困难的场合,可以直接使用这种自适应的方式,仅指定虚拟机的最大堆、目标的吞吐量(GCTimeRatio)和停顿时间(MaxGCPauseMIllis),让虚拟机自己完成调优工作。
特点
- 吞吐量优先
- 具有 GC 自适应的调节策略,虚拟机自己完成调优工作
Parallel Old 收集器
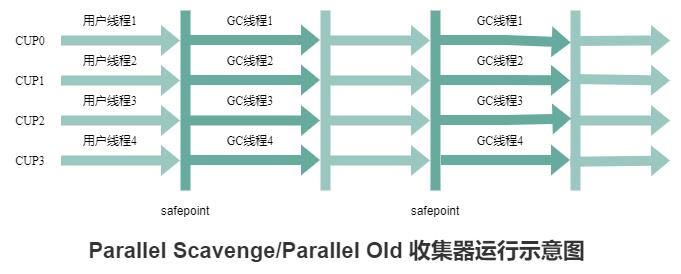
Parallel Old 收集器是 Parallel Scavenge 收集器的老年代版本,使用多线程和“标记-整理”算法。
在这个收集器推出之前(JDK 1.6 之前),新生代的 Parallel Scavenge 收集器一直处于一种比较尴尬的状态。
原因是,如果新生代选择了 Parallel Scavenge 收集器,老年代除了 Serial Old(PS MarkSweep)收集器外别无选择(因为 Parallel Scavenge 收集器无法与 CMS 收集器配合工作)。由于老年代 Serial Old 收集器在服务端应用性能上的“拖累”(单线程的 Serial Old 无法充分利用服务器多 CPU 的处理能力),使用了 Parallel Scavenge 收集器也未必能在整体应用上获得吞吐量最大化的效果。
Parallel Old 收集器的工作流程如下图所示:
CMS 收集器
CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器,它在一些文档中也被称为并发低停顿收集器(Concurrent Low Pause Collector)。
CMS 是 Hotspot 虚拟机中第一款真正意义上的并发(Concurrent)收集器,它第一次实现了让垃圾收集线程与用户线程(基本上)同时工作。
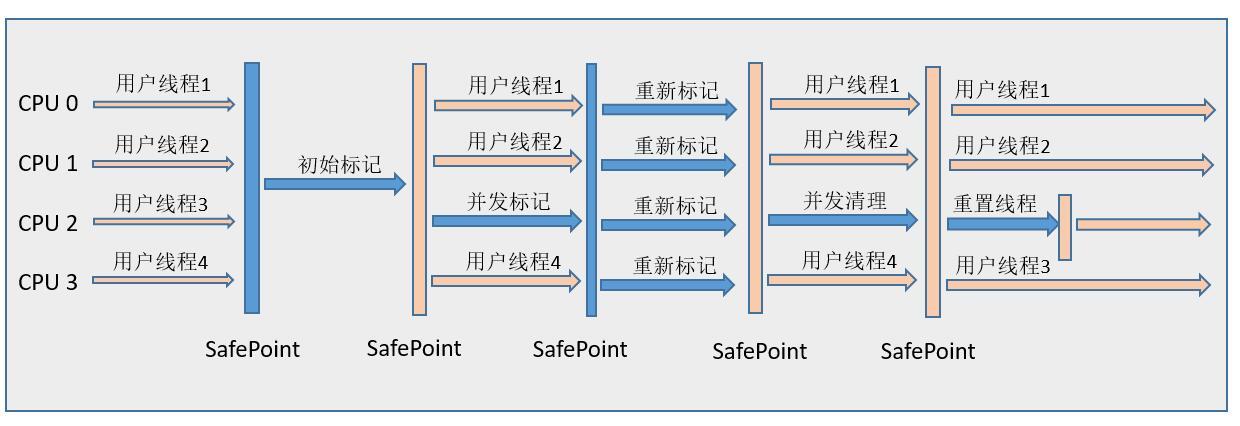
从名字(包含“Mark Sweep”)上就可以看出, CMS 收集器是基于“标记-清除”算法实现的,它的运作过程分为7个步骤(书上作者只说了4个…):
- 初始标记(CMS initial mark),会导致 STW
- 并发标记(CMS concurrent mark),与用户线程同时运行
- 预清理(CMS concurrent preclean),与用户线程同时运行
- 可被终止的预清理(CMS concurrent abortable preclean),与用户线程同时运行
- 重新标记(CMS remark),会导致 STW
- 并发清除(CMS concurrent sweep),与用户线程同时运行
- 并发重置状态等待下次CMS的触发(CMS concurrent reset),与用户线程同时运行
执行过程如下图:
初始标记
这是 CMS中 两次“Stop TheWorld”事件中的一次。这一步的作用是标记存活的对象,有两部分:
- 标记老年代中所有的 GC Roots 对象,如下图节点 1 ;
- 标记新生代中活着的对象引用到的老年代的对象(指的是新生代中还存活的引用类型对象,引用指向老年代中的对象)如下图节点 2 和 3
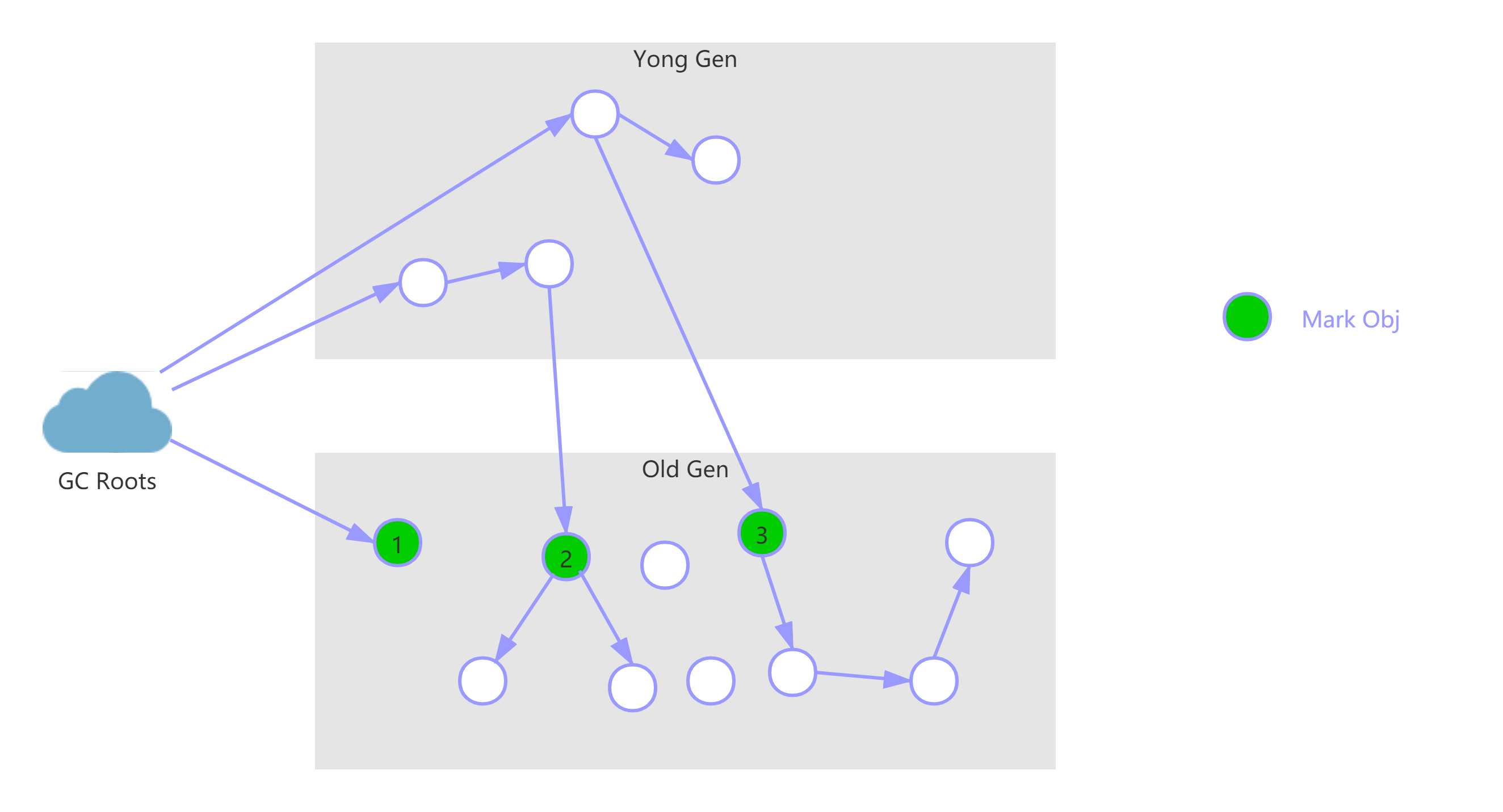
这里引入一个概念:跨代引用
跨代引用是指新生代中存在对老年代对象的引用,或者老年代中存在对新生代的引用。
一般来说,每个分代的垃圾回收器都希望各扫门前雪,只标记自己分代的存活对象,比如 Young GC 时,当 GC 线程遇到引用指向老年代时就会停止遍历,因为它只负责回收新生代的内存空间,不需要去访问老年代对象,而 CMS 收集器却不是这样。
Card Marking
在 Young GC 时,为了找到跨代引用,通常有这几个方法:
- 当对象引用路径指向老年代时继续遍历老年代对象找到跨代引用
- 线性地扫描老年代对象,标记跨代引用,用顺序读代替离散读
- 从程序开始运行,就使用一个集合记录所有跨代引用的创建,在 Young GC 时扫描这个集合里指向新生代的跨代引用
前两种方式都需要在 Young GC 时去遍历老年代对象,因为老年代存活对象多,工作量太大,JVM 使用的是第三种方式。
跨代引用如何产生的?
对于老年代到年轻代的跨代引用(a->b),产生条件有两种,
一是 GC 线程把对象 a 从新生代移动到了老年代,
二是 a 本身是老年代对象,应用线程修改了 a 的引用指向了年轻代的 b( 对于新生代到老年代的跨代引用就只有第二种情况)。
对于 GC 线程本身创建的跨代引用,可以直接由 GC 线程在创建时记录,所以问题就变成了:如何记录应用线程修改对象引用时创建的跨代引用?
在 JVM 中再次使用分治法,将老年代划分成多个 Card(和 linux 内存 page 类似),每个 Card 大约是512K。
只要 Card 内对象引用被应用线程修改,就把 Card 标记为 Dirty。然后 Young GC 时会扫描老年代中 Dirty Card 对应的内存区域,记录其中的跨代引用,这种方式被称为 Card Marking。
JVM 通过写屏障(write barrier)来实现监控程序线程对引用的修改,并且标记对应 Card,写屏障工作方式和代理模式类似,具体来说是通过在引用赋值指令执行时,添加对了 Card Table 的修改指令。
小结:JVM 使用 Card Marking 的方式,避免了 Young GC 时扫描整个老年代存活对象,付出的代价是在每次修改引用时添加额外的汇编指令实现写屏障,和额外的内存来保存 Card Table。
并发标记
从“初始标记”阶段标记的对象开始找出所有存活的对象;
因为是并发运行的,在运行期间会发生新生代的对象晋升到老年代、或者是直接在老年代分配对象、再或者更新老年代对象的引用关系等等,对于这些对象,都是需要进行重新标记的,否则有些对象就会被遗漏,发生漏标的情况。为了提高重新标记的效率,该阶段会把上述对象所在的 Card 标识为 Dirty,后续只需扫描这些 Dirty Card 的对象,避免扫描整个老年代。
并发标记阶段只负责将引用发生改变的 Card 标记为 Dirty 状态,不负责处理。
如下图所示,也就是节点1、2、3,最终找到了节点4和5。
并发标记的特点是和应用程序线程同时运行。并不是老年代的所有存活对象都会被标记,因为标记的同时应用程序会改变一些对象的引用等。
由于这个阶段是和用户线程并发的,可能会导致“concurrent mode failure”。如果 CMS 并发标记过程中出现了 concurrent mode failure 的话那么接下来就会做一次 mark sweep compact 的 Full GC,这个是完全Stop The World的。
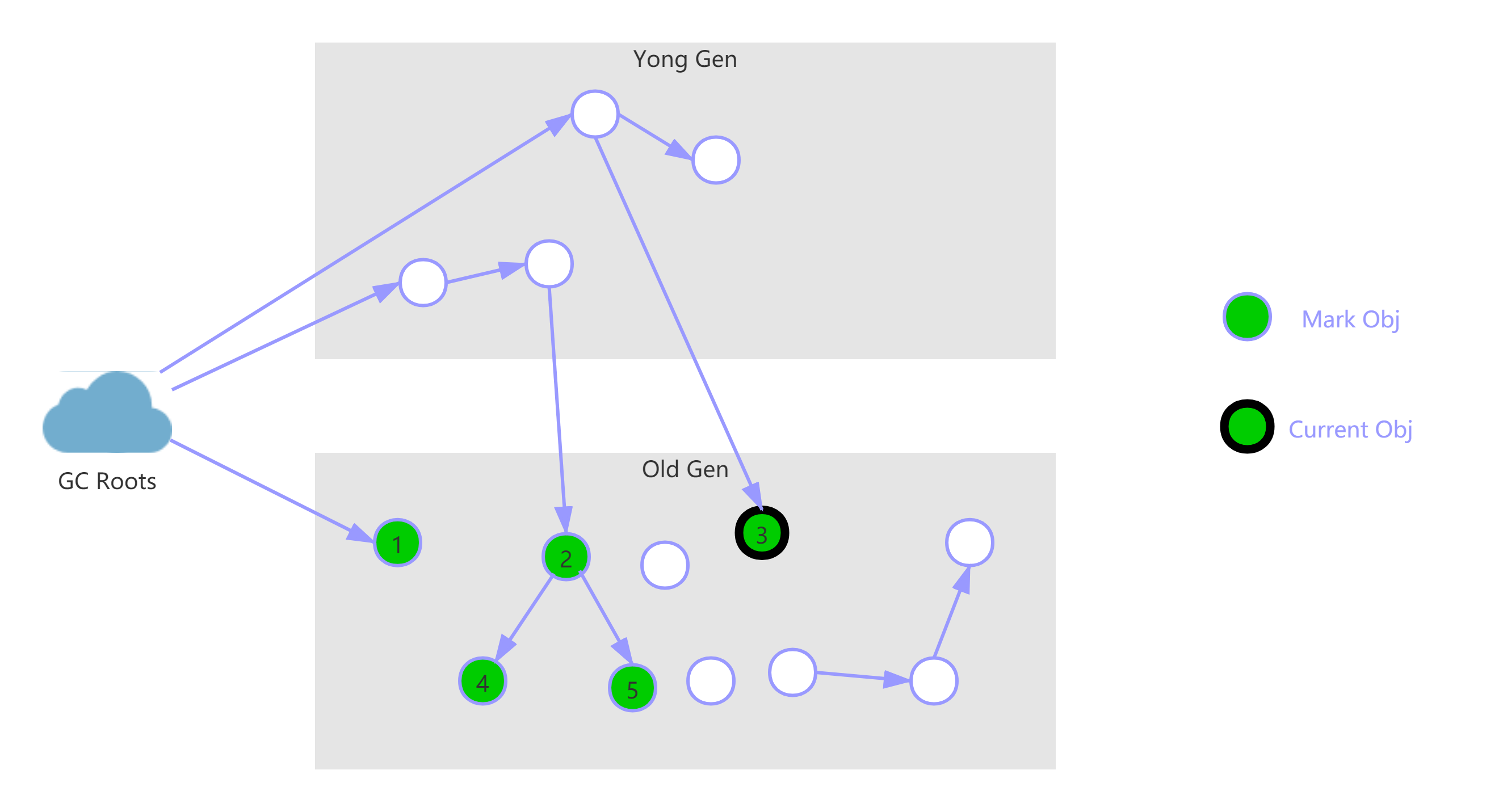
预清理阶段
前一个阶段已经说明,不能标记出老年代全部的存活对象,是因为标记的同时应用程序会改变一些对象引用,这个阶段就是用来处理前一个阶段因为引用关系改变导致没有标记到的存活对象的,它会扫描所有标记为 Dirty 的 Card。
如下图所示,在并发清理阶段,节点3的引用指向了6,则会把节点3的 Card 标记为 Dirty;
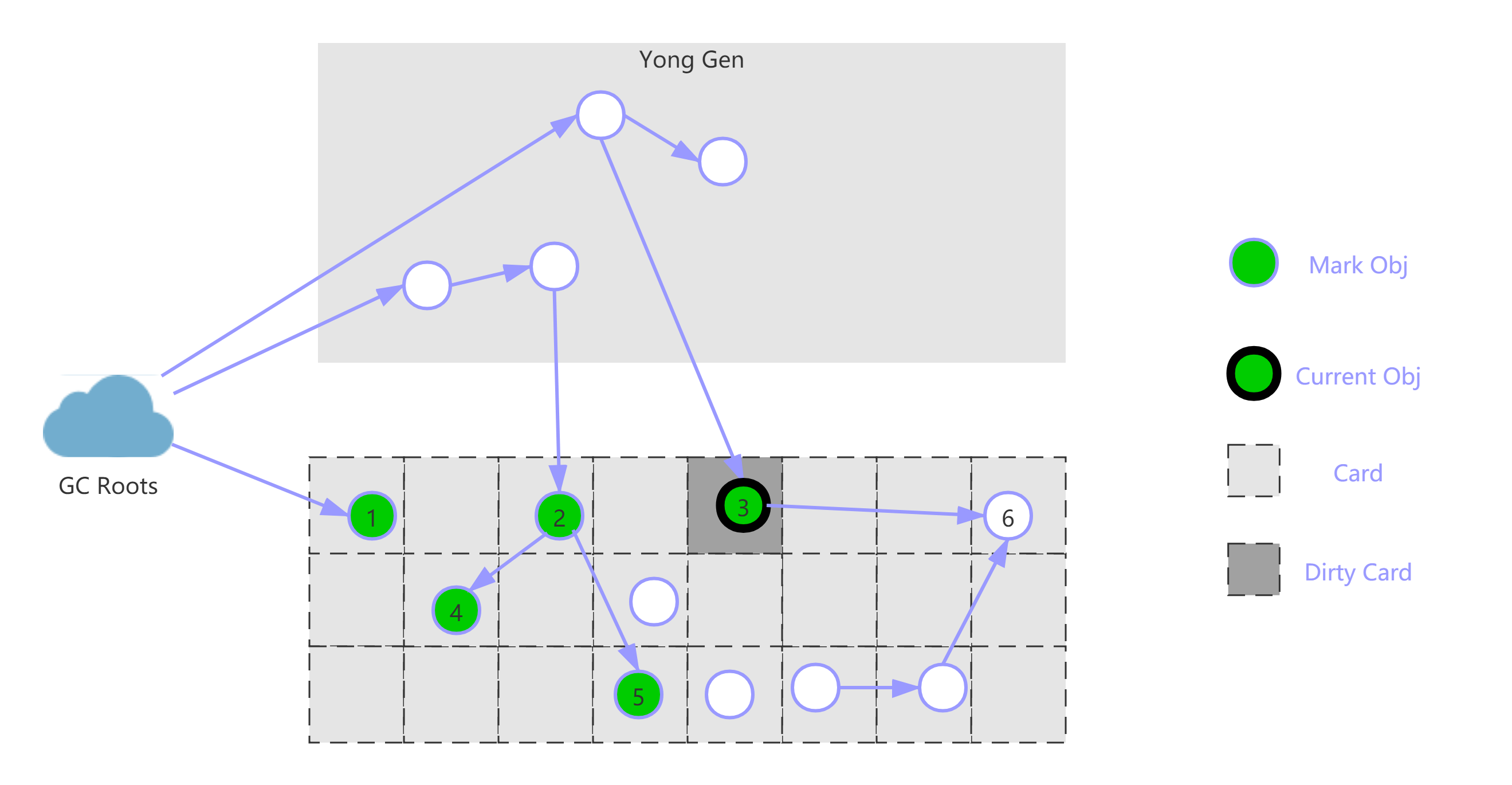
最后将6标记为存活,如下图所示:
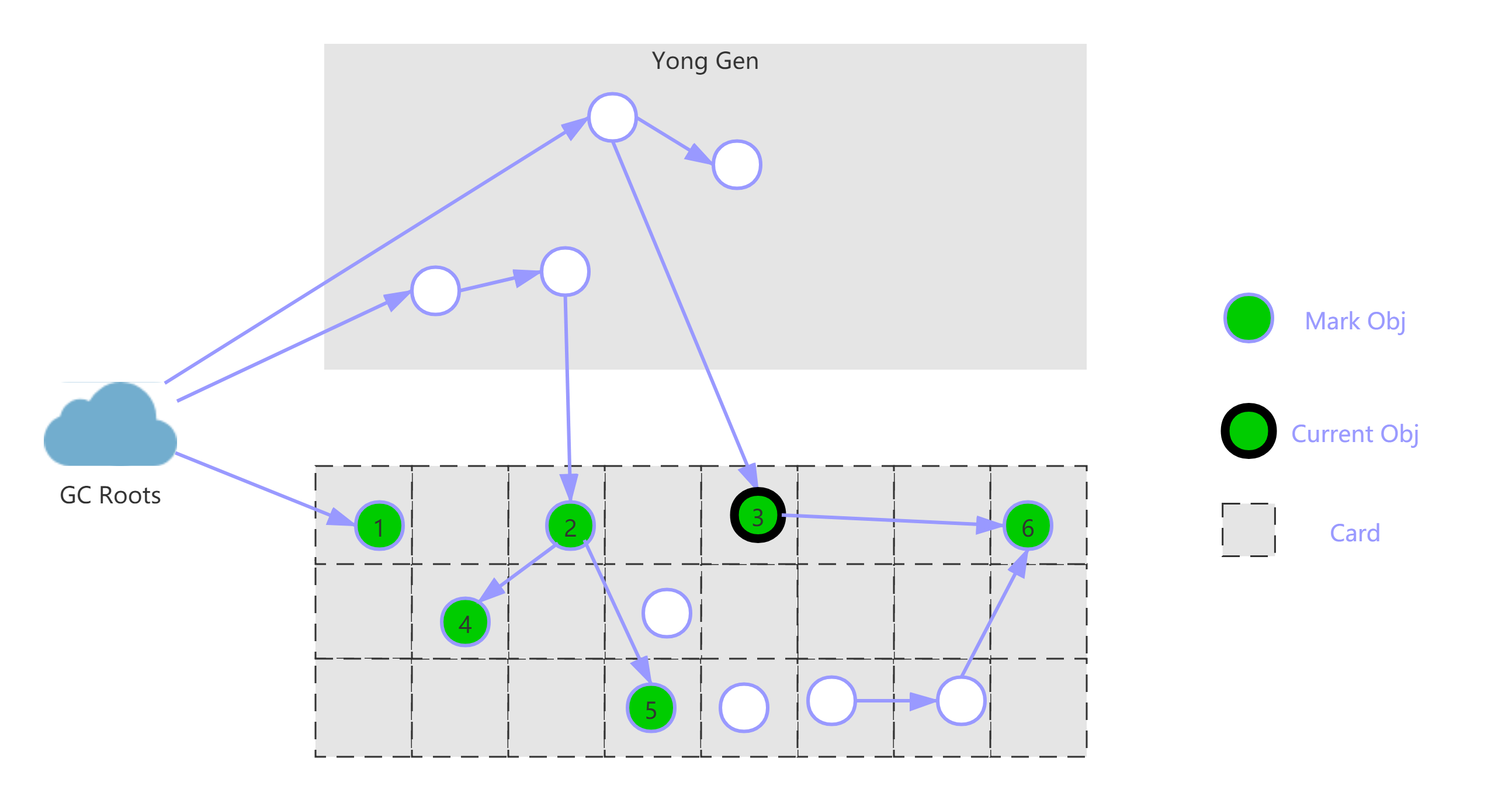
可终止的预处理
这个阶段尝试着去承担下一个阶段 Final Remark 阶段足够多的工作。这个阶段持续的时间依赖很多因素,由于这个阶段是重复的做相同的事情直到发生 abort 的条件(比如:重复的次数、多少量的工作、持续的时间等等)之一才会停止。
PS:此阶段最大持续时间为5秒,之所以可以持续5秒,另外一个原因也是为了期待这5秒内能够发生一次 Young GC,清理新生代的引用,使得下个阶段的重新标记阶段、扫描新生代指向老年代的引用的时间减少。
重新标记
这个阶段会导致第二次 Stop The Word,该阶段的任务是完成标记整个年老代的所有的存活对象。
这个阶段,重新标记的内存范围是整个堆,包含 Young Gen 和 Old Gen。
为什么要扫描新生代呢?
因为对于老年代中的对象,如果被新生代中的对象引用,那么就会被视为存活对象,即使新生代的对象已经不可达了,也会使用这些不可达的对象当做 CMS 的“GC Root”,来扫描老年代;
因此对于新生代来说,引用了老年代中对象的新生代的对象,也会被新生代视作“GC Root”。
当此阶段耗时较长的时候,可以加入参数 -XX:+CMSScavengeBeforeRemark,在重新标记之前,先执行一次 Young GC,回收掉新生代的无用的对象,并将对象放入 Survivor 区或晋升到老年代,这样再进行新生代扫描时,只需要扫描 Survivor 区的对象即可,一般 Survivor 区非常小,这大大减少了扫描时间。
由于之前的预处理阶段是与用户线程并发执行的,这时候可能新生代的对象对老年代的引用已经发生了很多改变,这个时候,remark 阶段要花很多时间处理这些改变,会导致很长 Stop The Word,所以通常 CMS 尽量运行 Final Remark 阶段在年轻代是足够干净的时候。
另外,还可以开启并行收集:-XX:+CMSParallelRemarkEnabled。
并发清除
通过以上5个阶段的标记,老年代所有存活的对象已经被标记并且现在要通过 Garbage Collector 采用清扫的方式回收那些不能用的对象了。
这个阶段主要是清除那些没有标记的对象并且回收空间;
由于 CMS 并发清除阶段用户线程还在运行着,伴随程序运行自然就还会有新的垃圾不断产生,这一部分垃圾出现在标记过程之后,CMS 无法在当次收集中处理掉它们,只好留待下一次 GC 时再清理掉。这一部分垃圾就称为“浮动垃圾”。
由于整个过程中耗时最长的并发标记和并发清除过程收集器线程都可以与用户线程一起工作,所以,从总体上来说,CMS 收集器的内存回收过程是与用户线程一起并发执行的。
CMS 收集器的优点
- 并发收集
- 低停顿
CMS 收集器的缺点
对 CPU 资源非常敏感
CMS 收集器对 CPU 资源非常敏感。在并发阶段,它虽然不会导致用户线程变慢,但是因为占用了一部分线程(或者说 CPU 资源)而导致应用程序变慢,总吞吐量会降低。CMS 默认启动的回收线程数是(CPU 数量+3) / 4 ,也就是当 CPU 在4个以上时,,并发回收时垃圾收集线程占用不少于 25% 的 CPU 资源,并且随着 CPU 数量的增加而下降。
为了应对这种情况,虚拟机提供了一种称为“增量式并发收集器”(Incremental Concurrent Mark Sweep / i-CMS)的 CMS 收集器变种,就是在并发标记和并发清除的时候让GC线程和用户线程交替运行,尽量减少GC 线程独占资源的时间,这样整个垃圾收集的过程会变长,但是对用户程序的影响会减少。(效果不明显,现在已经不再提倡用户使用)
无法处理浮动垃圾
CMS 收集器无法处理浮动垃圾(Floating Garbage),可能会出现“Concurrent Mode Failure”失败而导致另一次 Full GC 的产生。
浮动垃圾我们之前在并发清除提到过,是由于在清除过程中程序还在运行着,运行着也就会不断产生新的垃圾,这一部分垃圾出现在标记过程之后,CMS 无法在当次收集中处理掉它们,只好留待下一次 GC 时再清理掉。
也是因为在垃圾收集阶段用户线程还需要继续运行,那就还需要预留有足够的内存空间给用户线程使用,因此 CMS 收集器不能像其他收集器那样等到老年代几乎完全被填满了再进行收集,需要预留一部分空间提供并发收集时的程序运行使用。
我们可以设置-XX:CMSInitiatingOccupancyFraction参数的值来设置 CMS 收集器的启动阀值,在JDK 1.6中,CMS 收集器的启动阀值已经提升到92%。
要是 CMS 运行期间预留的内存无法满足程序需要,就会出现一次“Concurrent Mode Failure”失败,这时虚拟机将启动后备预案:临时启动 Serial Old 收集器来重新进行老年代的垃圾收集,这样停顿时间就很长了。所以说,参数-XX:CMSInitiatingOccupancyFraction设置得太高很容易导致大量的“Concurrent Mode Failure”失败,性能反而降低。
GC 结束时会产生大量空间碎片
前面我们说过,CMS 收集器是基于“标记-清除”算法实现的,这意味着在收集结束时会有大量空间碎片产生。空间碎片太多的时候,将会给大对象的分配带来很大的麻烦,往往会出现老年代还有很大的空间剩余,但是无法找到足够大的连续空间来分配当前对象的,只能提前触发 Full GC。
为了解决空间碎片这个问题,CMS 收集器提供了一个 -XX:+UseCMSCompactAtFullCollection 开关参数(默认就是开启的),用于在 CMS 收集器顶不住要进行 Full GC 时开启内存碎片的合并整理过程,内存整理的过程是无法并发的,空间碎片问题没有了,但停顿时间不得不变长。
虚拟机设计者还提供了另一个参数 -XX:CMSFullGCBeforeCompaction,这个参数是用于设置执行多少次不压缩的 Full GC 后,跟着来一次带压缩的(默认值为0,表示每次进入 Full GC 时都进行碎片整理)。
空间碎片问题的具体实例
在 Minor GC 过程中,Survivor Unused 可能不足以容纳 Eden 和另一个 Survivor 中的存活对象, 那么多余的将被移到老年代, 称为过早提升(Premature Promotion),这会导致老年代中短期存活对象的增长, 可能会引发严重的性能问题。
再进一步,如果老年代满了, Minor GC 后会进行 Full GC, 这将导致遍历整个堆, 称为提升失败(Promotion Failure)。
在进行 Minor GC 时,Survivor Space 放不下,对象只能放入老年代,而此时老年代因为碎片太多,新生代要转移到老年代的对象也比较大,找不到一块连续的内存区域存放这个对象导致的。
过早提升的原因:
- Survivor 空间太小,容纳不下全部的运行时短生命周期的对象。
如果是这个原因,可以尝试将Survivor调大,否则端生命周期的对象提升过快,导致老年代很快就被占满,从而引起频繁的full gc; - 对象太大,Survivor 和 Eden 没有足够大的空间来存放这些大对象。
提升失败的原因:
当提升的时候,发现老年代也没有足够的连续空间来容纳该对象。为什么是没有足够的连续空间而不是空闲空间呢?
老年代容纳不下提升的对象有两种情况:
- 老年代空闲空间不够用了;
- 老年代虽然空闲空间很多,但是碎片太多,没有连续的空闲空间存放该对象。
解决方法
- 如果是因为内存碎片导致的大对象提升失败,CMS 需要进行空间整理压缩;
- 如果是因为提升过快导致的,说明 Survivor 空闲空间不足,那么可以尝试调大 Survivor;
- 如果是因为老年代空间不够导致的,尝试将 CMS 触发的阈值调低。
CMS部分的内容借鉴了:
https://zhuanlan.zhihu.com/p/150696908
https://www.jianshu.com/p/86e358afdf17
G1 收集器
G1 收集器是一款面向服务端应用的垃圾收集器。G1 最大的特点是引入分区的思路,弱化了分代的概念,合理利用垃圾收集各个周期的资源,解决了其他收集器甚至 CMS 的众多缺陷。
G1 收集器具有以下的特点:
- 并行与并发:G1 能充分利用多 CPU 、多核环境下的硬件优势,使用多个 CPU (CPU 或者 CPU 核心)来缩短 Stop-The-World 停顿时间,部分其他收集器原本需要停顿 Java 线程执行的 GC 动作,G1 收集器仍然能通过并发的方式让 Java 程序继续执行。
- 分代收集:与其他收集器一样,分代概念在 G1 中依然得以保留。虽然 G1 可以不需要其他收集器配合就能独立管理整个 GC 堆,但它能够采用不同方式去处理新创建的对象和已经存活了一段时间、熬过多次 GC 的旧对象以获取更好的收集效果。
- 空间整合:与 CMS 的“标记-清理”算法不同,G1 从整体来看是基于“标记-整理”算法实现的收集器,从局部(两个 Region 之间)上来看是基于“复制”算法实现的,但无论如何,这两种算法都意味着 G1 运作期间不会产生内存空间碎片,收集后能提供规整的可用内存。这种特性有利于程序长时间运行,分配大对象时不会因为无法找到连续内存空间而提前触发下一次 GC。
- 可预测的停顿:这是 G1 相对 CMS 的另一大优势,降低停顿时间是 G1 和 CMS 共同的关注点,但 G1 除了追求降低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为 M 毫秒的时间段内,消耗在垃圾收集上的时间不得超过 N 毫秒,这几乎已经是实时 Java(RTSJ)的垃圾收集器的特征了。
剩下的内容等我回去看看关于 G1 收集器的文献再补上,《深入理解 Java 虚拟机》(第二版)这本书关于 G1 收集器说的太浅了(可能是第二版太老了)…
PS:也可以到我的个人博客查看更多内容
个人博客地址:小关同学的博客
相关文章:

2016寒假训练3
题目链接 A CodeForces 362A Two Semiknights Meet 题意:在一个棋盘中有两个定义了特殊走法的棋子,同时移动他们,问是否会相遇(只能在合法的位置)。 做法:直接暴力dfs处理出这两个棋子到达各个位置的时间&a…
2015化妆品行业如何进行微信公众号营销
对比其他行业发展特点发现化妆品行业具有以下特点: 1、化妆品行业呈现节日、电商促销影响明显、口碑评价关注度高、女性网民占比高冲动消费多、整体用户年轻化等特点。 2、化妆品行业即使在各行业发展低迷期依然保持良好发展势头。 3、化妆品商家的顾客回头率高。 4…
在新建好的ROS空间里面添加功能包
第一步:创建功能包 cd catkin_ws打开src ~/catkin_ws/src新建文件夹名字 catkin_create_pkg (文件加名字) roscpp rospy std_msgs打开新建文件夹中的src ~/catkin_ws/src/(新建文件夹名字)/src输入: gedit 文件.cpp返回工作空间: 执行catkin build 编译后即可执行

Revit的Enscape基本培训(2021) Enscape Essential Training for Revit (2021)
MP4 |视频:h264,1280720 |音频:AAC,44.1 KHz,2 Ch 语言:英语中英文字幕(根据原英文字幕机译更准确) |时长:2h 53m |大小解压后:2.23 GB 含课程练习文件 如果您使用Revit,您可能需要学习Enscape&…
设计模式学习2:单例模式
单例模式 所谓类的单例设计模式,就是采取一定的方法保证在整个的软件系统中,对某个类只能存在一个对象实例,并且该类只提供一个取得其对象实例的方法(静态方法)。 比如Hibernate的SessionFactory,它充当数据存储源的代理…
数据库插入时,标识列插入显式值
当 IDENTITY_INSERT 设置为 OFF 时,不能为表 CU_GiftExchange 中的标识列插入显式值。SET IDENTITY_INSERT [dbo].[CU_GiftExchange] ONGO转载于:https://blog.51cto.com/hezun/1631849
Ubuntu终端显示文本让选择确定,OK等等
问题1:首先按下"TAB"键,会看到选中文本"确定","OK"然后按下回车键,即可!

Unity安卓游戏开发:打造7款2D 3D游戏 Unity Android Game Development : Build 7 2D 3D Games
流派:电子学习| MP4 |视频:h264,1280720 |音频:AAC,44.1 KHz 语言:英语中英文字幕(根据原英文字幕机译更准确) |大小:15.4 GB |时长:32h 55m Unity游戏开发与设计,用C# & Unity学习Unity安卓游戏开发(更…
唯一索引和普通索引的选择
前言:最近在研究阿里的开发手册中关于 MySQL 的一些规定,所以来记录一下学习中的心得 唯一索引和普通索引的选择 【强制】业务上具有唯一特性的字段,即使是组合字段,也必须建成唯一索引。 说明:不要以为唯一索引影响了…
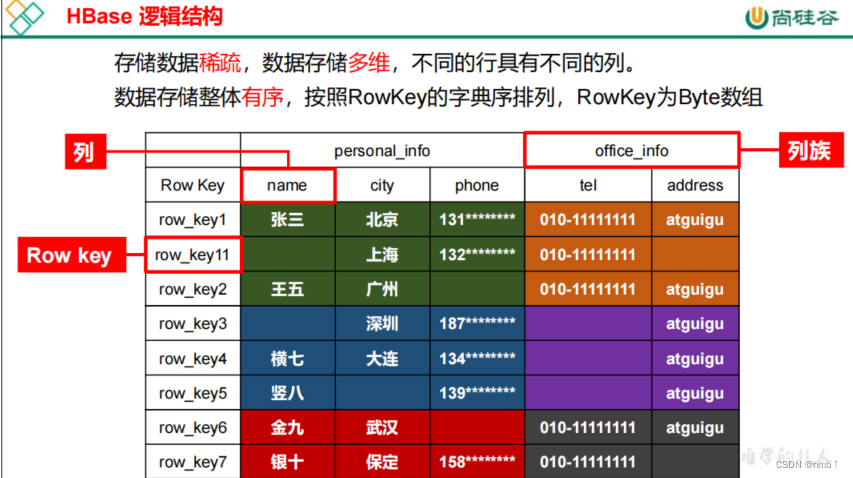
Springboot整合HBase——大数据技术之HBase2.x
Apache HBase 是以hdfs为数据存储的,一种分布式、可扩展的noSql数据库。是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。HBase使用与BigTable(BigTable是一个稀疏的、分布式的、持久化的多维排序map)非常相似的数据模型。用户将数据行存储在带标签的表中。数据行具有可排序的键和任意数量的列。该表存储稀疏,因此如果用户喜欢,同一表中的行可以具有疯狂变化的列。

一个合格的Java选手必须要掌握的并发锁知识
Java内置锁:基于Java语法层面(关键词)实现的锁,主要是根据Java语义来实现,最典型的应用就是synchronized。Java显式锁:基于JDK层面实现的锁,主要是根据基于Lock接口和ReadWriteLock接口,以及统一的AQS基础同步器等来实现,最典型的有ReentrantLock。使用方式:synchronized关键字互斥锁主要有作用于对象方法上面,作用于类静态方法上面,作用于对象方法里面,作用于类静态方法里面等4种方式。

终于有人把Web 3.0和元宇宙讲明白了
分散的数据网络使个人数据(例如个人的健康数据、农民的作物数据或汽车的位置和性能数据)出售或交换成为可能,与此同时,不会失去对数据的所有权控制、放弃数据隐私或依赖第三方平台来管理数据。Web 3.0的目标是在创作者经济中取得更好的平衡。互联网第二次迭代(Web 2.0)的缺陷,加上公有区块链技术的诞生,帮助我们朝着更加去中心化的Web 3.0 迈进,元宇宙和更广泛的去中心化网络都是关于现实世界和虚拟世界的融合。此时的网络中不再是静态内容,而是动态的内容,用户现在可以与发布在网络上的内容进行交互。
ubuntu下安装 python 常用软件
1、用于科学计算的常用包: sudo apt-get install python-numpy python-scipy python-matplotlib ipython ipython-notebook python-pandas python-sympy python-nose 包括,numpy, scipy, matplotlib, ipython, ipython-notebook, pandas, sympy, nose 2、…

《团队项目开发之三对一维环形数组的求解》
《团队项目开发之三对一维环形数组的求解》 设计思想:通过把数组的长度扩大为原来的一倍,相当于新数组是由对原来的数组重复了一遍后而组成的,这样保证了数组以环状的形式,按照数组中每个数字的位序依次对它们可能形成的最大子数组…

PX4修改线程内存大小
当编译时出现错误: 在CMakeLists.txt文件中修改内存大小 px4_add_module(#下面添加文件夹名字MODULE modules__position_control#下面添加线程名字MAIN a#线程内存大小STACK_MAIN 4000SRCS#添加文件夹里面.cpp文件main.cppDEPENDS)修改后,再次编译就不…

Blender液体烟与火VFX特效制作教程 Blender VFX Liquid Smoke Fire
流派:电子学习| MP4 |视频:h264,1280720 |音频:AAC,48.0 KHz 语言:英语|大小:6.60 GB |时长:7h 44m Blender了解三维模型如何创建模拟和动画的简单方法 你会学到什么 完成创建两个鬼魅万圣节场景的完整指南,包括模拟和全动画元素 使用Blender…
Ajax+SpringBoot+Thymeleaf使用中遇到的跳转页面问题
前言:这周在使用 AjaxThymeleaf 时遇到一个问题,折腾了我很久,在此记录一下 AjaxSpringBootThymeleaf使用中遇到的跳转页面问题 问题描述 我的目的:通过 Ajax 获取数据,并通过 Model 渲染 View ,实现跳转…
数据库分离 脱机
数据库分离:一般默认情况下数据库在联机状态下我们不能对数据库文件进行任何复制删除等操作,如果将数据库分离的话就可以对数据文件进行复制、剪切、删除等操作了。一般想直接备份数据文件,就先分离数据库,之后把数据文件复制到别…

年卡在手,城墙我走: 记葡萄城控件团队建设
上个周六,赶着春天的尾巴,《葡萄城控件业务团队》进行了一次有趣的团队建设:西安城墙半日游。 拿到《2015陕西旅游年票一卡通》,还是小小激动一下,据说有888个景点可以免费游玩呢。 从葡萄城到西安南门,这个…

PX4代码框架
src:目录是源码目录存放所有的源码,源码的查看都应该在这里。 mavlink:是MAvlink的库目录,源码要调用这个库,如果我们要修改和添加MAVLINLK消息ID也是在这个目录下面。 NuttX:是NuttX的系统库,…

Houdini魔法特效制作学习教程
大小解压后:12.1G 1920X1080 mp4 语言:英语中英文字幕 Houdini已经成为特效行业的热门工具。 谁运用它的力量,谁就势不可挡。 魔法咒语、科幻盾牌和电磁脉冲冲击波。掌握特效的艺术元素是这里的目标,我们将指导您完成它。 魔法通常…
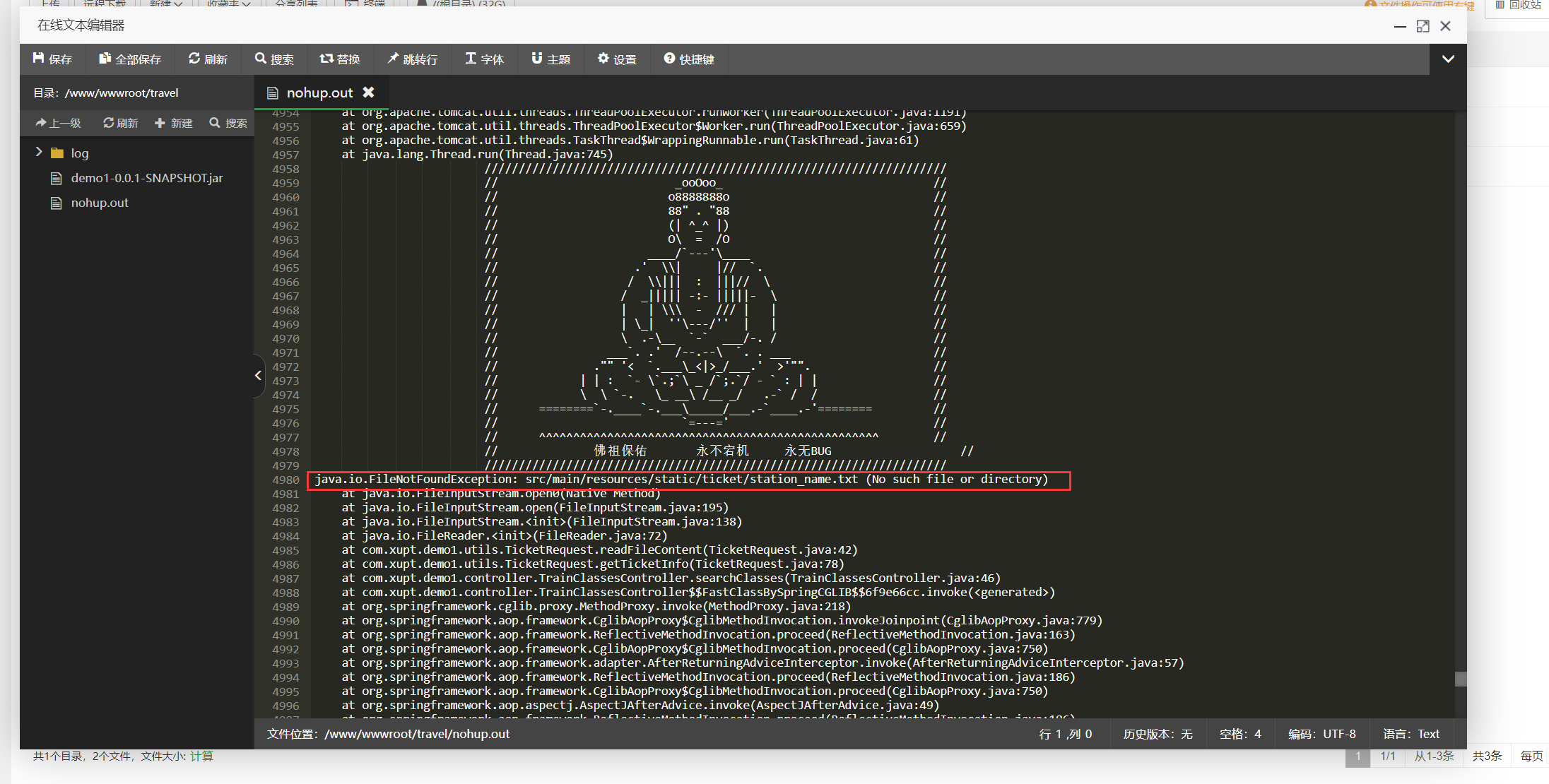
关于SpringBoot项目通过jar包启动之后无法读取项目根路径静态资源
前言:这个是昨天晚上在部署一个项目的时候发现的,在此记录一下 关于SpringBoot项目通过jar包启动之后无法读取项目根路径静态资源 问题描述 在部署了一个项目之后,打开项目页面进行测试,发现有一个查询页面查询失败了࿰…
JavaScript高级程序设计(第3版)第六章读书笔记
第六章 面向对象的程序设计 1. 数据属性 [[Configurable]]:表示能否通过delete删除属性从而重新定义属性。默认值为true。 [[Enumerable]]:表示能否通过for-in循环返回属性。默认值为true。 [[Writable]]:表示能否修改属性的值,默…

2022-2028年中国钢丸行业市场行情监测及未来前景规划报告
【报告类型】产业研究 【报告价格】4500起 【出版时间】即时更新(交付时间约3个工作日) 【发布机构】智研瞻产业研究院 【报告格式】PDF版 本报告介绍了中国钢丸行业市场行业相关概述、中国钢丸行业市场行业运行环境、分析了中国钢丸行业市场行业的…

[MySQL]Every derived table must have its own alias
2019独角兽企业重金招聘Python工程师标准>>> 关于这条报错信息,意思是指每个派生出来的表都必须有一个自己的别名。 _mysql_exceptions.OperationalError: (1248, Every derived table must have its own alias) 如下两条select语句可以说明这个问题&am…
Java爬取解析去哪儿景点信息
前言:这两周在做 Web 课的大作业,顺便琢磨了一下如何使用 Java 从网上获取一些数据,现在写这篇博客记录一下。 PS:这里仅限交流学习用,如利用代码进行恶意攻击他网站,和作者无关!!&a…

用Unity和C#创建在线多人游戏学习教程
MP4 |视频:h264,1280720 |音频:AAC,44.1 KHz,2 Ch 语言:英语中英文字幕(根据原英文字幕机译更准确) |时长:58节课(6h 41m) |大小解压后:6.1 GB 用Unity和C#创建在线多人游戏以及如何创建基于Turn的多人游戏…
bzoj 1040: [ZJOI2008]骑士 树形dp
题目链接 1040: [ZJOI2008]骑士 Time Limit: 10 Sec Memory Limit: 162 MBSubmit: 3054 Solved: 1162[Submit][Status][Discuss]Description Z国的骑士团是一个很有势力的组织,帮会中汇聚了来自各地的精英。他们劫富济贫,惩恶扬善,受到社会…

2022-2028年中国钢桶行业市场研究及前瞻分析报告
【报告类型】产业研究 【报告价格】4500起 【出版时间】即时更新(交付时间约3个工作日) 【发布机构】智研瞻产业研究院 【报告格式】PDF版 本报告介绍了中国钢桶行业市场行业相关概述、中国钢桶行业市场行业运行环境、分析了中国钢桶行业市场行业的…
在windows中创建一个影子用户
在windows中创建一个影子用户(看不到图请下载附件)我们可以在windows操作系统中建立一个影子用户,也就是它是实际存在的,但是不会在登录时或者用户组中显示,我们可以赋予影子用户管理员权限,可以在某些情况下管理员不可用时使用。…