Java爬取解析去哪儿景点信息
前言:这两周在做 Web 课的大作业,顺便琢磨了一下如何使用 Java 从网上获取一些数据,现在写这篇博客记录一下。
PS:这里仅限交流学习用,如利用代码进行恶意攻击他网站,和作者无关!!!
Java爬取解析携程景点信息
网上用 Java 做数据爬取的案例不少,但是很少是能用的,有些是几年前能用,但是现在不行了,有些则是只有一个思路,在上网查阅许多资料之后我琢磨出了一个可行的爬取去哪儿景点信息的方案。
使用工具:
- HttpClient:发出请求
- Jsoup:解析页面
- MyBatis:数据保存
所需 Maven 依赖:
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.20</version></dependency><dependency><groupId>org.mybatis</groupId><artifactId>mybatis</artifactId><version>3.5.4</version></dependency><dependency><groupId>ch.qos.logback</groupId><artifactId>logback-classic</artifactId><version>1.2.3</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>RELEASE</version><scope>test</scope></dependency><dependency><groupId>org.apache.httpcomponents</groupId><artifactId>httpcore</artifactId><version>4.4.14</version></dependency><dependency><groupId>org.apache.httpcomponents</groupId><artifactId>httpclient</artifactId><version>4.5.13</version></dependency><dependency><groupId>commons-httpclient</groupId><artifactId>commons-httpclient</artifactId><version>3.1</version></dependency><dependency><!-- jsoup HTML parser library @ https://jsoup.org/ --><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.11.3</version></dependency><!-- https://mvnrepository.com/artifact/com.squareup.okhttp3/okhttp --><dependency><groupId>com.squareup.okhttp3</groupId><artifactId>okhttp</artifactId><version>4.1.0</version></dependency>
一、发出请求
我这里使用 HttpClient 来发 Get 请求获取我想要的信息,代码如下:
import org.apache.commons.httpclient.DefaultHttpMethodRetryHandler;
import org.apache.commons.httpclient.HttpClient;
import org.apache.commons.httpclient.cookie.CookiePolicy;
import org.apache.commons.httpclient.methods.GetMethod;
import org.apache.commons.httpclient.params.DefaultHttpParams;
import org.apache.commons.httpclient.params.HttpMethodParams;import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;/*** @author 小关同学* @create 2021/11/9*/
public class Request {public static String doGet(String url) {// 输入流InputStream is = null;BufferedReader br = null;String result = null;// 创建httpClient实例HttpClient httpClient = new HttpClient();// 设置http连接主机服务超时时间:15000毫秒// 先获取连接管理器对象,再获取参数对象,再进行参数的赋值httpClient.getHttpConnectionManager().getParams().setConnectionTimeout(15000);// 创建一个Get方法实例对象GetMethod getMethod = new GetMethod(url);// 设置get请求超时为60000毫秒getMethod.getParams().setParameter(HttpMethodParams.SO_TIMEOUT, 60000);// 设置请求重试机制,默认重试次数:3次,参数设置为true,重试机制可用,false相反getMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER, new DefaultHttpMethodRetryHandler(3, true));DefaultHttpParams.getDefaultParams().setParameter("http.protocol.cookie-policy", CookiePolicy.BROWSER_COMPATIBILITY);try {Thread.sleep(5000);// 执行Get方法int statusCode = httpClient.executeMethod(getMethod);System.out.println("请求状态码:"+statusCode);// 判断返回码
// if (statusCode != HttpStatus.SC_OK) {// 如果状态码返回的不是ok,说明失败了,打印错误信息
// System.err.println("Method faild: " + getMethod.getStatusLine());
// } else {// 通过getMethod实例,获取远程的一个输入流is = getMethod.getResponseBodyAsStream();// 包装输入流br = new BufferedReader(new InputStreamReader(is, "UTF-8"));StringBuffer sbf = new StringBuffer();// 读取封装的输入流String temp = null;while ((temp = br.readLine()) != null) {sbf.append(temp).append("\r\n");}result = sbf.toString();
// }} catch (Exception e) {e.printStackTrace();} finally {// 关闭资源if (null != br) {try {br.close();} catch (Exception e) {e.printStackTrace();}}if (null != is) {try {is.close();} catch (Exception e) {e.printStackTrace();}}// 释放连接getMethod.releaseConnection();}return result;}
}这里的发出请求代码网上多得是,我这个是借鉴了网上的代码,然后稍作修改而来的,主要修改了判断返回状态码那里,使得一次请求不成功之后程序不会立即停止,而是继续发出请求,直到获取到想要的数据。
PS:这里按理说最好改一下请求头什么的,来避过反爬机制,但是我懒得改了,就让它那样了(能用就行)。
二、对 HTML 页面进行解析(重点)
对 HTML 页面进行解析的话就要使用 Jsoup 了,这里先介绍一下这个 Jsoup 是什么。
Jsoup 是一款 Java 的 HTML 解析器,可直接解析某个 URL 地址、HTML 文本内容。它提供了一套非常省力的 API,可通过 DOM,CSS 以及类似于 jQuery 的操作方法来取出和操作数据。
Jsoup 的主要功能
- 从一个 URL,文件或字符串中解析 HTML;
- 使用 DOM 或 CSS 选择器来查找、取出数据;
- 可操作 HTML 元素、属性、文本。
我们这里使用 Jsoup 解析前面获取到的 HTML 页面信息,代码如下:
import com.entity.Spot;
import com.entity.SpotDetail;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import java.util.Set;/*** @author 小关同学* @create 2021/11/6* 爬取去哪儿旅行的数据*/
public class SpotDataCrawler {/*** 爬取对应城市景点简介信息* @param city* @return*/public static Set<Spot> requestSpotData(String city, int page) {String ascii = CodeTransition.stringToASCII(city);String target = Request.doGet("http://piao.qunar.com/ticket/list.htm?keyword="+ascii+"®ion=&from=mpl_search_suggest&page="+page);Document root_document = null;assert target != null;//是404页面时,返回nullif (target.contains("<h2>非常抱歉,您访问的页面不存在。</h2>")){return null;}root_document = Jsoup.parse(target);//获取需要数据的divElement e = root_document.getElementById("search-list");//得到网页上的景点列表(包含两个样式集合)Elements yy = e.getElementsByClass("sight_item sight_itempos");Elements yy2 = e.getElementsByClass("sight_item");yy.addAll(yy2);//图片//#search-list > div:nth-child(1) > div > div.sight_item_show > div > a//标题//#search-list > div:nth-child(1) > div > div.sight_item_about > h3 > a//地点//#search-list > div:nth-child(1) > div > div.sight_item_about > div > p > span//简介//#search-list > div:nth-child(1) > div > div.sight_item_about > div > div.intro.color999//热度//#search-list > div:nth-child(1) > div > div.sight_item_about > div > div.clrfix > div > span.product_star_level > em > spanSet<Spot> spotList = new HashSet<>();for (int i = 0; i < yy.size(); i++) {Spot spot = new Spot();//得到每一条景点信息Element Info = yy.get(i);//分析网页得到景点的标题(使用选择器语法来查找元素)//景点名称信息Element nameStr = Info.selectFirst(" div > div.sight_item_about > h3 > a");String name = nameStr.html();spot.setName(name);System.out.println("景点名称:" + name);//景点图片信息Element pictureStr = Info.selectFirst("div > div.sight_item_show > div > a");String picture = pictureStr.html();int index = picture.indexOf(" alt");String url = picture.substring(20,index-1);spot.setPicture(url);System.out.println("景点图片地址:" + url);//价格Element priceStr = Info.selectFirst("div > div.sight_item_pop > table > tbody > tr:nth-child(1) > td > span > em");if (priceStr!=null){String price = priceStr.html();if (!price.isEmpty()){spot.setPrice(Double.parseDouble(price));System.out.println("价格:" + price);}}//景点地点信息Element addressStr = Info.selectFirst(" div > div.sight_item_about > div > p > span");String address = addressStr.html();spot.setArea(address);System.out.println("景点地点:" + address);//景点简介Element infoStr = Info.selectFirst(" div > div.sight_item_about > div > div.intro.color999");String info = infoStr.html();spot.setInfo(info);System.out.println("景点简介:" + info);//景点在网页中对应的id//#search-list > div:nth-child(1) > div > div.sight_item_about > div > p > aElement spotIdInWebStr = Info.selectFirst("div > div.sight_item_about > div > p > a");int start = spotIdInWebStr.toString().indexOf("data-sightid=\"");int end = spotIdInWebStr.toString().indexOf("\">地图");String spotWebId = spotIdInWebStr.toString().substring(start+14,end);spot.setSpotWebId(spotWebId);System.out.println("对应详情页面的id:"+spotWebId);spotList.add(spot);}return spotList;}/*** 爬取景点的详细信息* @param name 景点名称* @param webId 景点对应的webId* @return 返回相关信息*/public static Object[] requestSpotDetailData(String name,int id,String webId){Object[] result = new Object[2];Spot spot = new Spot();List<SpotDetail> list = new ArrayList<>();String ascii = CodeTransition.stringToASCII(name);String url = "http://piao.qunar.com/ticket/detail_" + webId + ".html?st="+ascii+"#from=mpl_search_suggest";String target = Request.doGet(url);assert target != null;//是404页面时,返回nullif (target.contains("<h2>非常抱歉,您访问的页面不存在。</h2>")){System.out.println("非常抱歉,您访问的页面不存在");return null;}Document root_document;root_document = Jsoup.parse(target);//分析网页得到景点的标题(使用选择器语法来查找元素)spot.setId(id);//特色看点->推荐理由(保存在Spot里面)//#mp-charact > div > div.mp-charact-intro > div.mp-charact-desc > p:nth-child(1)//#mp-charact > div > div.mp-charact-intro > div.mp-charact-desc > p:nth-child(2)String reason = "";Element reasonStr1 = root_document.selectFirst("#mp-charact > div:nth-child(1) > div.mp-charact-intro > div.mp-charact-desc > p");if (reasonStr1!=null){reason = reasonStr1.html();}Element reasonStr2 = root_document.selectFirst("#mp-charact > div > div.mp-charact-intro > div.mp-charact-desc > p:nth-child(1)");if (reasonStr2!=null){reason = reasonStr2.html();}spot.setInfoDetail(reason);System.out.println("推荐理由:" + reason);//开放时间Element openTimeStr = root_document.selectFirst("#mp-charact > div:nth-child(1) > div.mp-charact-time > div > div.mp-charact-desc > p");if (openTimeStr!=null){String openTime = openTimeStr.html();spot.setOpenTime(openTime);System.out.println("开放时间:" + openTime);}//景点详细信息//#mp-charact > div:nth-child(2)//#mp-charact > div:nth-child(2)Element infoDetailStr = root_document.selectFirst("#mp-charact > div:nth-child(2)");//如果没有图片等详细介绍if (infoDetailStr==null){result[0] = spot;result[1] = null;return result;}//得到网页上的景点列表(包含两个样式集合)Elements yy = infoDetailStr.getElementsByClass("mp-charact-event");System.out.println(yy.size());for (int i = 0; i < yy.size(); i++) {SpotDetail spotDetail = new SpotDetail();//得到每一条景点信息Element Info = yy.get(i);//#mp-charact > div:nth-child(2) > div:nth-child(3) > div > img//#mp-charact > div:nth-child(2) > div:nth-child(3) > divElement pictureStr = Info.selectFirst("div > img");if (pictureStr!=null){int index = pictureStr.toString().indexOf(">");String pictureUrl = pictureStr.toString().substring(10,index-1);spotDetail.setPicture(pictureUrl);System.out.println("景点图片地址:" + pictureUrl);}//#mp-charact > div:nth-child(2) > div:nth-child(2) > div > div.mp-event-desc > h3Element titleStr = Info.selectFirst("div > div.mp-event-desc > h3");if (titleStr!=null){String title = titleStr.html();spotDetail.setTitle(title);System.out.println("图片标题:"+title);}Element pictureDetailStr = Info.selectFirst("div > div.mp-event-desc > p");if (pictureDetailStr!=null){String pictureDetail = pictureDetailStr.html();spotDetail.setInfo(pictureDetail);System.out.println("图片详情:"+pictureDetail);}list.add(spotDetail);}result[0] = spot;result[1] = list;return result;}public static void main(String[] args) throws InterruptedException {//测试爬取景点简要信息
// for (int i = 1;i <= 10;i++){
// //生成1-10的随机数
// int random = (int)(1+Math.random()*(10-1+1));
// String str = random+"00";
// Thread.sleep(Integer.parseInt(str));
// System.out.println("=======================第"+i+"页=====================");
// Object result = requestSpotData("西安",i);
// if (result==null){
// i--;
// }else{
// System.out.println(result.toString());
// }
// }//测试爬取景点详细信息Object[] param = SpotDataCrawler.requestSpotDetailData("陕西历史博物馆",1,"383907200");System.out.println("===========================分割线==================================");if (param!=null){System.out.println(((Spot)param[0]).toString());for (SpotDetail detail:(List<SpotDetail>)param[1]){System.out.println(detail.toString());}}}}
1、对API查询接口的操作
现在进入了重头戏,首先,根据去哪儿景点查询页面获取到景点查询的API接口,如下图:
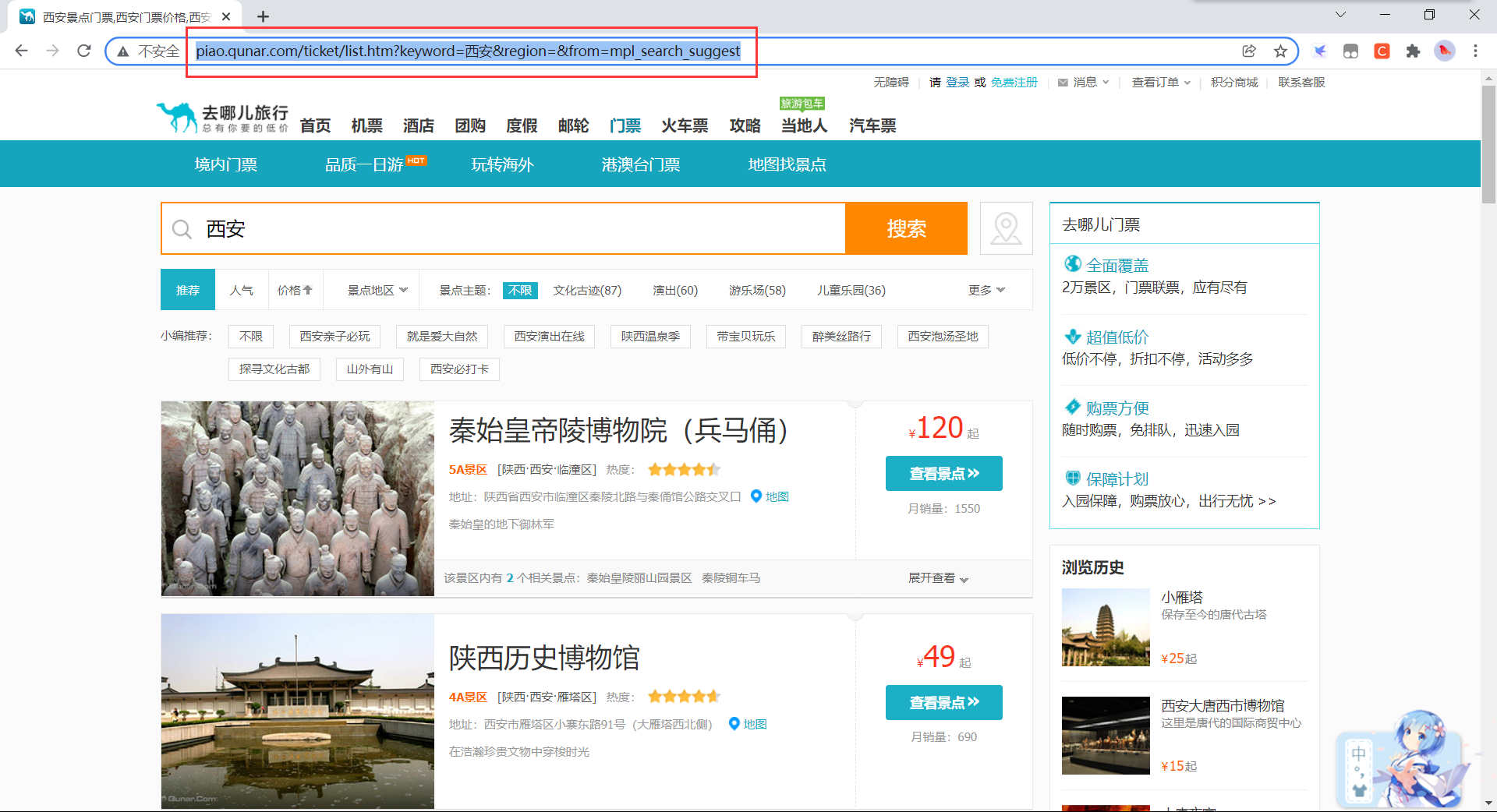
我们可以看到,去哪儿的景点查询API是这样的
http://piao.qunar.com/ticket/list.htm?keyword=要查询景点的UTF-8编码形式®ion=&from=mpl_search_suggest
这里我们要查询的景点是西安,所以得把“西安”这个 keyword 转换为 UTF-8 编码的形式,转换代码如下:
import java.io.UnsupportedEncodingException;
import java.net.URLEncoder;/*** @author 小关同学* @create 2021/11/7* 中文转URL*/
public class CodeTransition {public static String stringToASCII(String param) {String result = "";try {result = URLEncoder.encode(param,"utf-8");} catch (UnsupportedEncodingException e) {e.printStackTrace();}return result;}public static void main(String[] args){System.out.println(stringToASCII("西安"));}}
2、对请求到的页面的解析操作
然后我们来对页面进行解析(这里只做部分讲解),
先将获取到的页面进行解析,如下图:
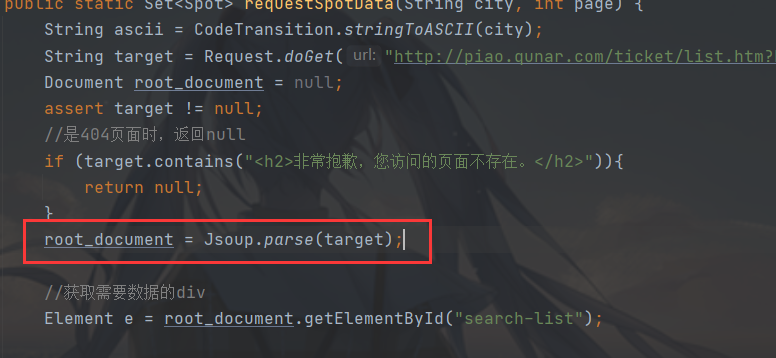
这里使用 Jsoup.parse 方法进行解析,把 String 类型的页面数据解析成 Document 对象,方便我们下一步操作。
3、HTML 中元素的定位
比如我们要获取景点的名称,如下图:
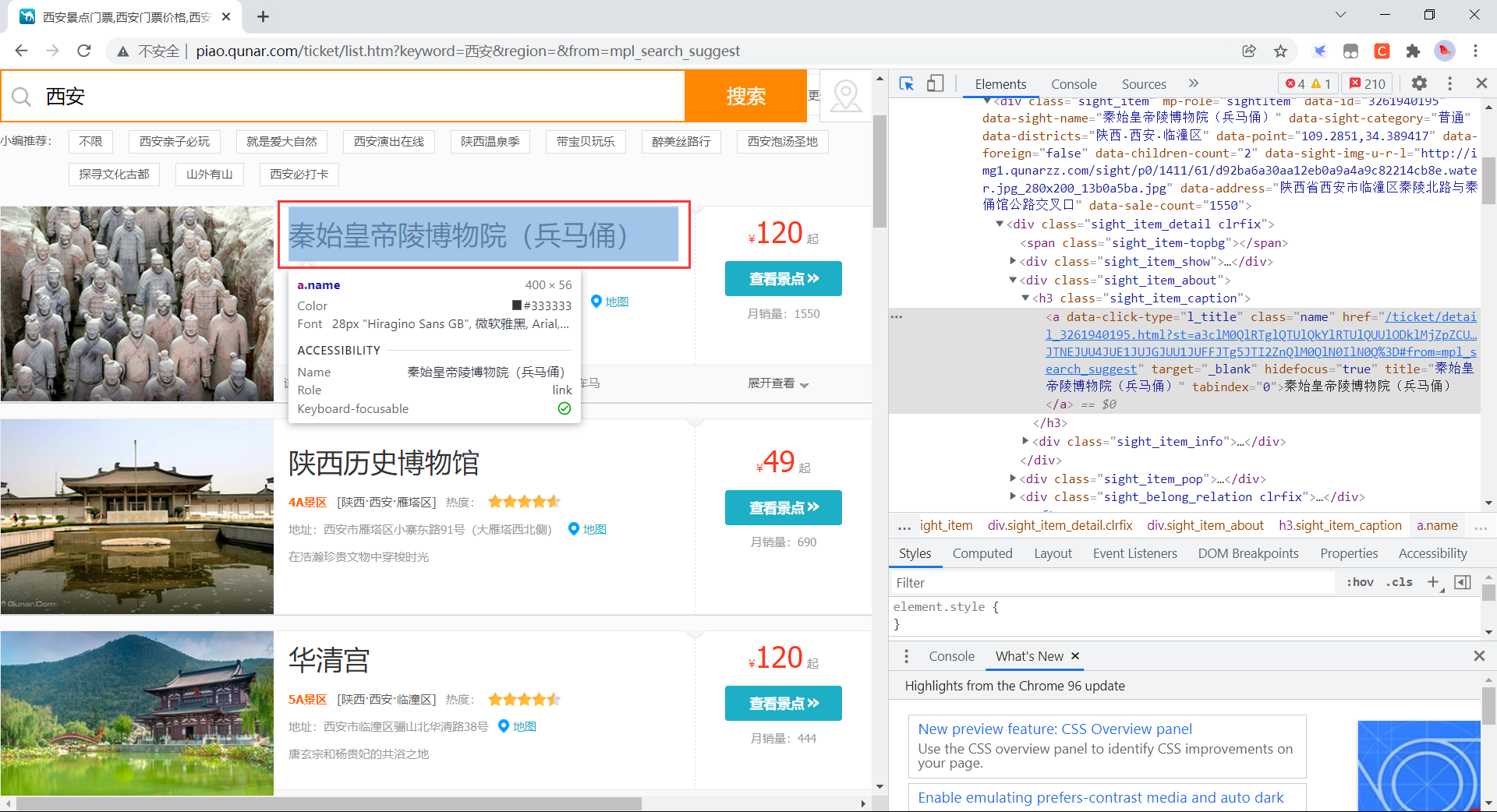
使用浏览器的调试功能定位到相应的 HTML 代码上,然后右键,选择 Copy 下的 Copy Selector 来获取代码在页面中的位置,如下:
#search-list > div:nth-child(1) > div > div.sight_item_about > h3 > a
然后使用 Element 对象定位元素,进而获取到信息,详细的过程我也不讲太多了,自己看代码去。
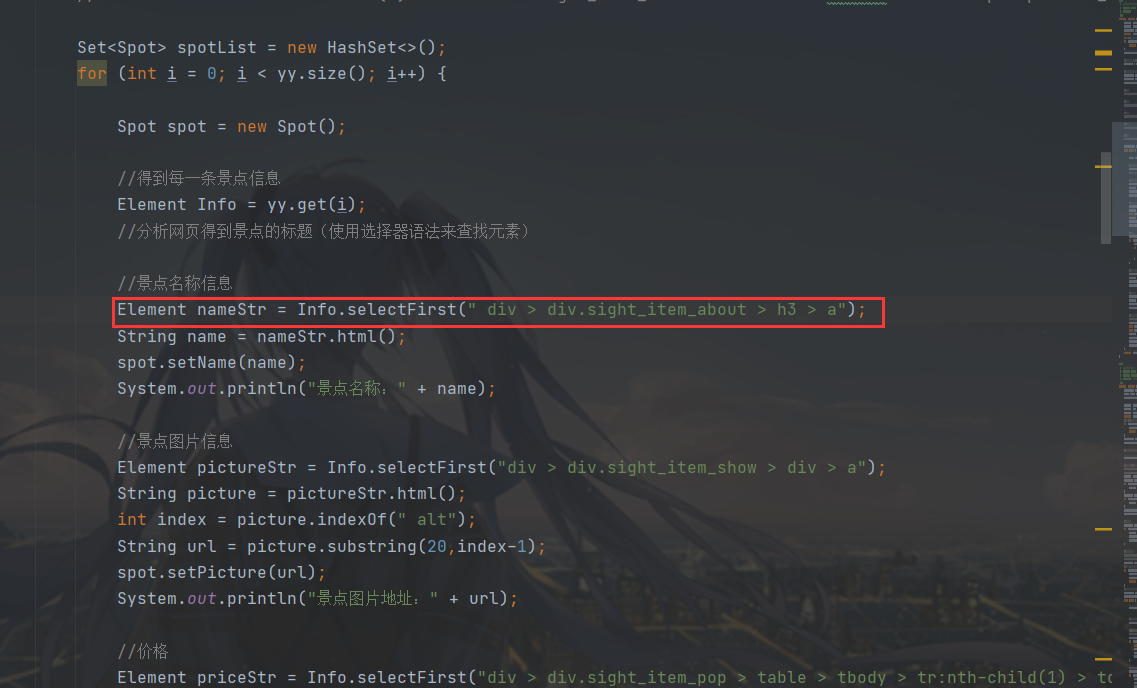
三、保存获取到的数据

现在我们获取并解析得到了数据,我们现在可以把它们放到数据库里面去了,这里我使用了 MyBatis 框架进行数据持久化操作,代码我就不贴了,想看完整代码的去我 Github 上面看。
最后
项目地址如下:
Github 地址:https://github.com/guanchanglong/DataCrawler
麻烦各位可否在看代码的时候顺手给一颗星 ^ _ ^,举手之劳感激不尽。
PS:可以到我的个人博客查看更多内容
个人博客地址:小关同学的博客
相关文章:

用Unity和C#创建在线多人游戏学习教程
MP4 |视频:h264,1280720 |音频:AAC,44.1 KHz,2 Ch 语言:英语中英文字幕(根据原英文字幕机译更准确) |时长:58节课(6h 41m) |大小解压后:6.1 GB 用Unity和C#创建在线多人游戏以及如何创建基于Turn的多人游戏…

bzoj 1040: [ZJOI2008]骑士 树形dp
题目链接 1040: [ZJOI2008]骑士 Time Limit: 10 Sec Memory Limit: 162 MBSubmit: 3054 Solved: 1162[Submit][Status][Discuss]Description Z国的骑士团是一个很有势力的组织,帮会中汇聚了来自各地的精英。他们劫富济贫,惩恶扬善,受到社会…

2022-2028年中国钢桶行业市场研究及前瞻分析报告
【报告类型】产业研究 【报告价格】4500起 【出版时间】即时更新(交付时间约3个工作日) 【发布机构】智研瞻产业研究院 【报告格式】PDF版 本报告介绍了中国钢桶行业市场行业相关概述、中国钢桶行业市场行业运行环境、分析了中国钢桶行业市场行业的…
在windows中创建一个影子用户
在windows中创建一个影子用户(看不到图请下载附件)我们可以在windows操作系统中建立一个影子用户,也就是它是实际存在的,但是不会在登录时或者用户组中显示,我们可以赋予影子用户管理员权限,可以在某些情况下管理员不可用时使用。…
PX4初级教程
链接:https://pan.baidu.com/s/1VIQcOQt-I5-evMx1jnV0ZQ 提取码:8niq
用Unity的视频广告创建2D动作游戏 Create Action 2D Game With Video Ads In Unity
MP4 |视频:h264,1280720 |音频:AAC,44.1 KHz,2 Ch 语言:英语中英文字幕(根据原英文字幕机译更准确) |时长:27场讲座(4h 19m) |大小解压后:2.35 GB Unity 2D游戏开发终极指南 你会学到: 学习使用Unity Tile…
大话设计模式之简单的工厂模式
第一章:代码无错就是优-简单的工厂模式 先建立一个计算类Operation Operation.h文件 interface Operation : NSObjectproperty(nonatomic,assign)double numberA;property(nonatomic,assign)double numberB;end Operation.m文件 implementation Operationend 然后分…
Nginx学习3:反向代理实例
Nginx配置实例-反向代理1 目标 打开浏览器,在浏览器地址栏输入地址 www.123.com,跳转到 liunx 系统 tomcat 主页面中 准备工作 我们在官网下载好tomcat之后,直接将tomcat的压缩包放到相应的目录下编译解压,然后进入tomcat的bi…

2022-2028年中国钢铁智能制造产业竞争现状及发展趋势分析报告
【报告类型】产业研究 【报告价格】4500起 【出版时间】即时更新(交付时间约3个工作日) 【发布机构】智研瞻产业研究院 【报告格式】PDF版 本报告介绍了中国钢铁智能制造行业市场行业相关概述、中国钢铁智能制造行业市场行业运行环境、分析了中国钢…
exchange 2010 search mailbox 的幕后强大功能
铃……….半夜中被一阵急促的手机铃声吵醒,年度服务客户打来电话需要进行邮件的排查和删除工作。问其原因,原来是组织中有人发了一封关于领导的不健康的邮件,并在企业内部进行了转发,领导要求立即找出此类邮件并进行删除。管理员深…
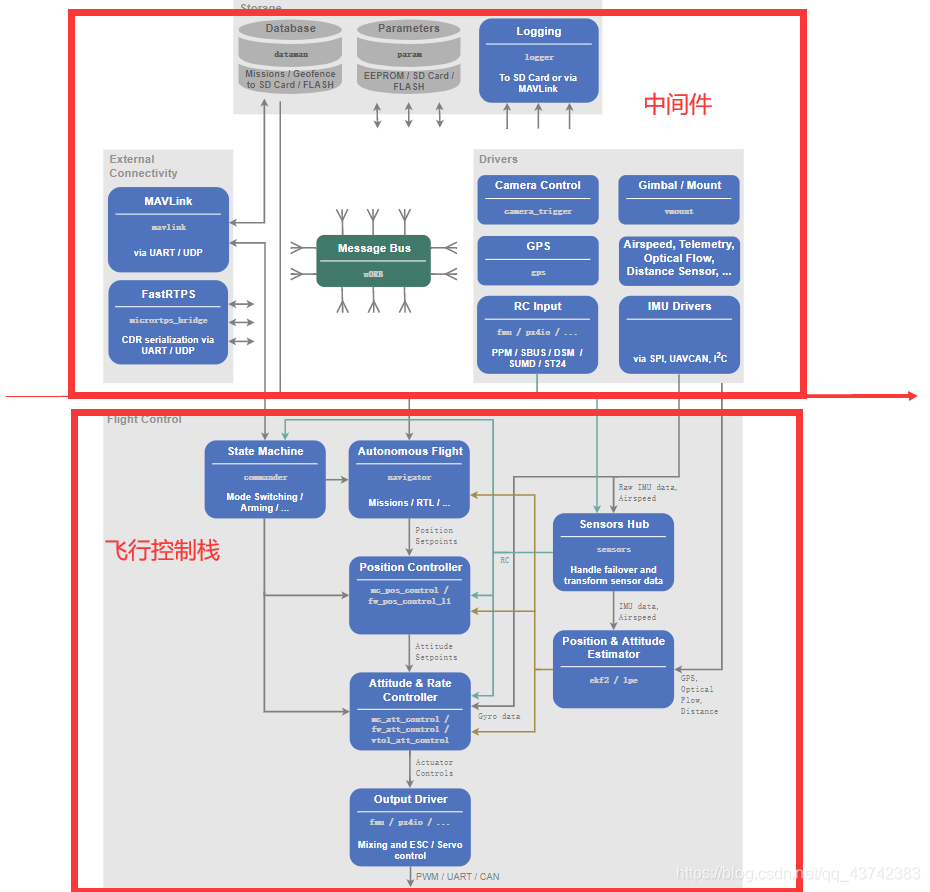
无人机官网介绍
参考官网:http://dev.px4.io/master/en/index.html 程序在运行期间可以通过在shell端输入执行top指令查看哪些模块正在被执行,当运行模块时可以通过输入<moudles name> start/stop来实现模块的使用与停止。 PX4软件架构: 更新速率&am…

Unity从头开始开发增强现实(AR)游戏学习教程
使用Unity 2021构建增强现实飞镖游戏 学习从头开始开发增强现实(AR)游戏,使用AR基金会,货币化,发布游戏玩商店 Build a Augmented Reality Dartboard Game with Unity 2021 你会学到什么 使用Unity2021从头开始学习增强现实。 构建一个AR飞镖…
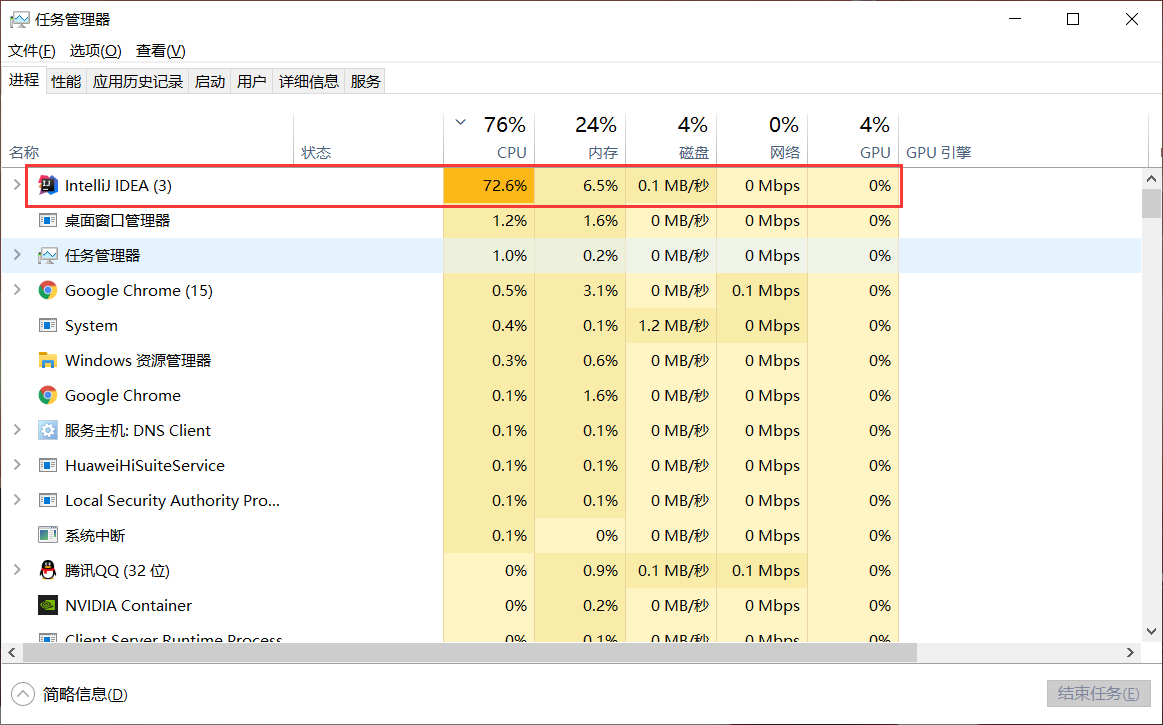
IDEA的CPU占用率高问题解决方法
前言:这段时间发现 IDEA 的 CPU 占用率猛涨,时不时就飙升到百分之7、80,使得敲代码的体验感十分不佳,在经过一番查找之后终于解决了问题,在此记录一下 IDEA的CPU占用率高问题解决方法 问题定位 我们先定位一下为什么I…

消息队列之库存扣减
转载于:https://www.cnblogs.com/work-at-home-helloworld/p/5230894.html

2022-2028年中国钢铁冶炼行业市场研究及前瞻分析报告
【报告类型】产业研究 【报告价格】4500起 【出版时间】即时更新(交付时间约3个工作日) 【发布机构】智研瞻产业研究院 【报告格式】PDF版 本报告介绍了中国钢铁冶炼行业市场行业相关概述、中国钢铁冶炼行业市场行业运行环境、分析了中国钢铁冶炼行…
Microsoft Build 2015
没本事去旧金山,只能默默的守在笔记本前看了…… 首先Azure在全球有19个数据中心了,终于超过亚马逊了,好样的!过去12个月Azure有超过500个新功能上线,每月用户增长9万。Azure将会越来越成熟了,只可惜我现在…
开源飞控PX4简介
介绍: https://docs.px4.io/master/zh/flight_controller/pixhawk4.html无人机飞控基本装配参考: https://docs.px4.io/master/zh/assembly/下载地面站链接(QGC地面站): http://qgroundcontrol.com/downloads/

Unity视觉效果图初学教程 Unity Visual Effects Graph for Beginners
面向初学者的Unity视觉效果图介绍 你会学到: 学生将学习使用视觉效果图来创建效果 MP4 |视频:h264,1280720 |音频:AAC,44.1 KHz,2 Ch 语言:英语中英文字幕(根据原英文字幕机译更准确) |时长:39节课(4h 42m…

nonatomic, retain,weak,strong用法详解
strong weak strong与weak是由ARC新引入的对象变量属性ARC引入了新的对象的新生命周期限定,即零弱引用。如果零弱引用指向的对象被deallocated的话,零弱引用的对象会被自动设置为nil。property(strong) MyClass *myObject;相当于property(retain) MyClas…
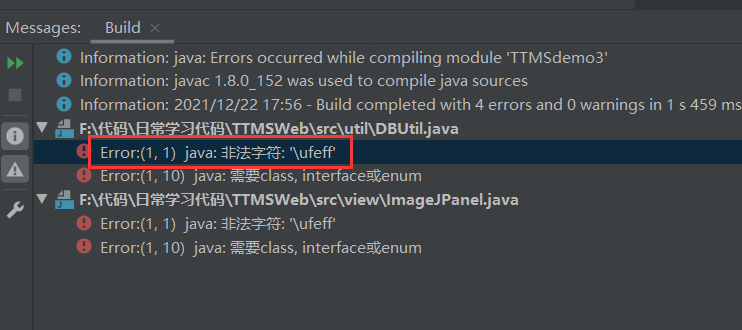
“ Error:(1, 1) java: 非法字符: ‘\ufeff‘ ”错误的解决方法
前言:今天为了做作业,在 github 上面下载了个项目,然后在运行项目时发现报错,在此记录一下 “ Error:(1, 1) java: 非法字符: ‘\ufeff’ ”错误的解决方法 发生原因 这个项目从目录的结构可以很明显地看出是使用 Eclipse 开发的…

2022-2028年中国钢铁电商产业竞争现状及发展前景预测报告
【报告类型】产业研究 【报告价格】4500起 【出版时间】即时更新(交付时间约3个工作日) 【发布机构】智研瞻产业研究院 【报告格式】PDF版 本报告介绍了中国钢铁电商行业市场行业相关概述、中国钢铁电商行业市场行业运行环境、分析了中国钢铁电商行…

java开发webservice的几种方式
为什么80%的码农都做不了架构师?>>> webservice的应用已经越来越广泛了,下面介绍几种在Java体系中开发webservice的方式,相当于做个记录。 1.Axis2 Axis是apache下一个开源的webservice开发组件,出现的算是比较早了&a…
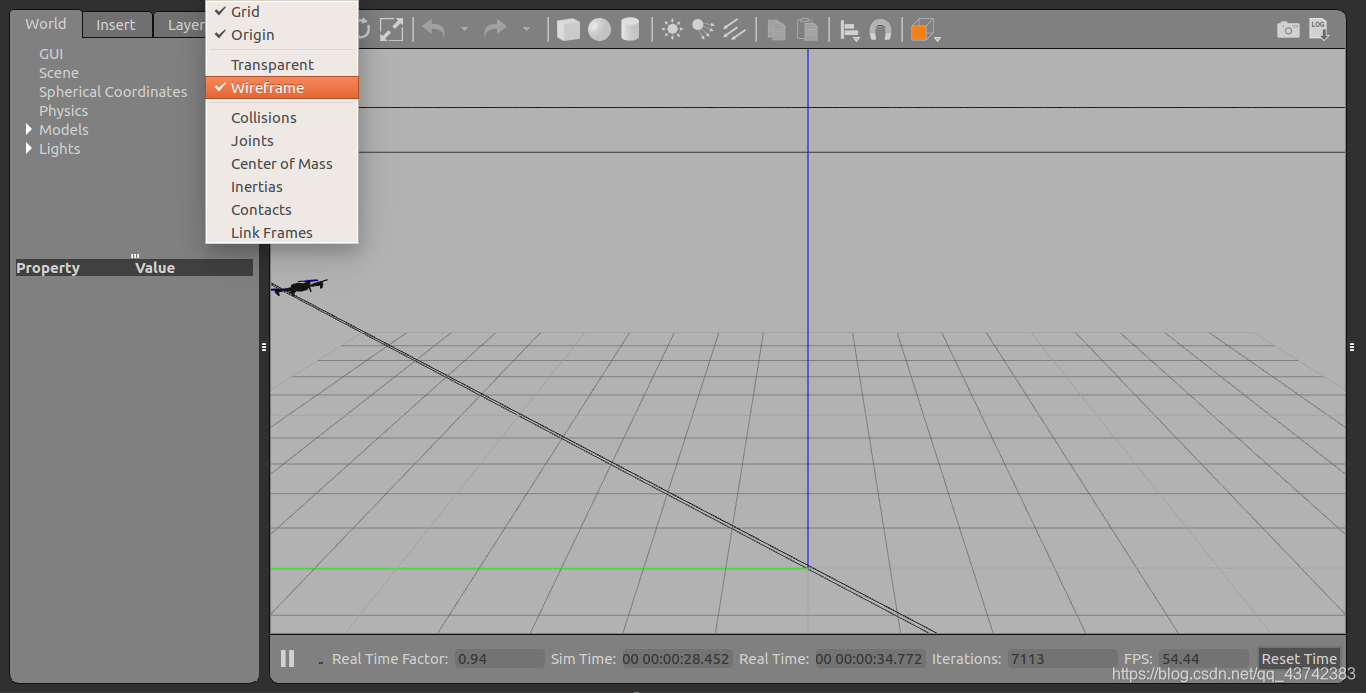
改变gazebo背景颜色
修改这里:
【Unity教程】创建一个完整的驾驶游戏
专业游戏设计 你会学到什么 在unity HDRP创建一个完整的驾驶游戏 定制不同类型的汽车 将人工智能汽车和人工智能航路点系统添加到你的赛道上 添加汽车展厅菜单以解锁和购买新车 在Blender中设计自己的赛道 易于理解的编码使游戏工作 流派:电子学习| MP4 |视频:h264,…

哈夫曼编译码器
前言:又到了学校一年一度的数据结构课设的日子,经不住学弟学妹热心地“询问”我数据结构课设的内容,我就在这里把我之前数据结构课设做的东西总结一下 哈夫曼编译码器 我课设选择的题目是哈夫曼编译码器,类似于我们平时用的解压缩…
Codeforces 629D Babaei and Birthday Cake(树状数组优化dp)
题意: 线段树做法 分析: 因为每次都是在当前位置的前缀区间查询最大值,所以可以直接用树状数组优化。比线段树快了12ms~ 代码: #include<cstdio> #include<cmath> #include<iostream> #include<algorithm>…

2022-2028年中国钢筘行业市场研究及前瞻分析报告
【报告类型】产业研究 【报告价格】4500起 【出版时间】即时更新(交付时间约3个工作日) 【发布机构】智研瞻产业研究院 【报告格式】PDF版 本报告介绍了中国钢筘行业市场行业相关概述、中国钢筘行业市场行业运行环境、分析了中国钢筘行业市场行业的…
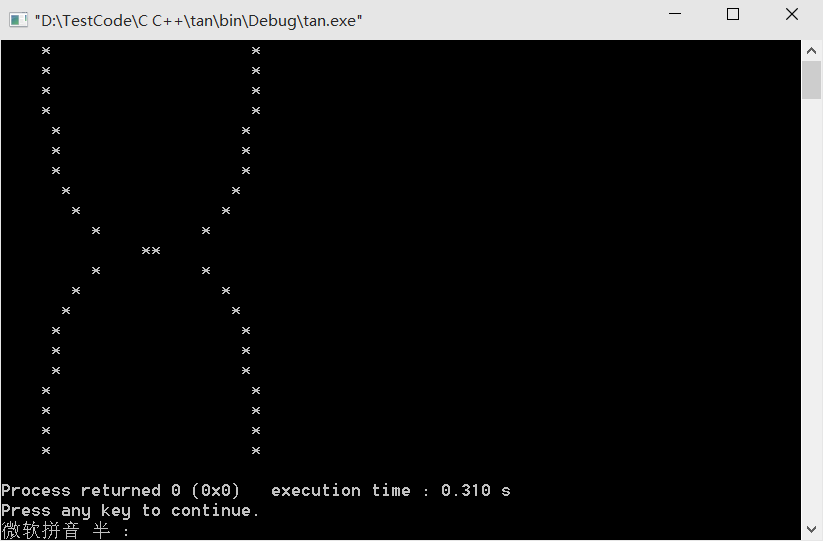
控制台绘制正切曲线
前面介绍了:控制台绘制正弦/余弦曲线 , 控制台绘制正弦曲线和余弦曲线同时显示 下面来看看正切曲线吧,其实也都差不多…… #include <stdio.h> #include <math.h>int main() {double y;int x,k;for(y10;y>-10;y--){katan(y)*7;if(k>0)…
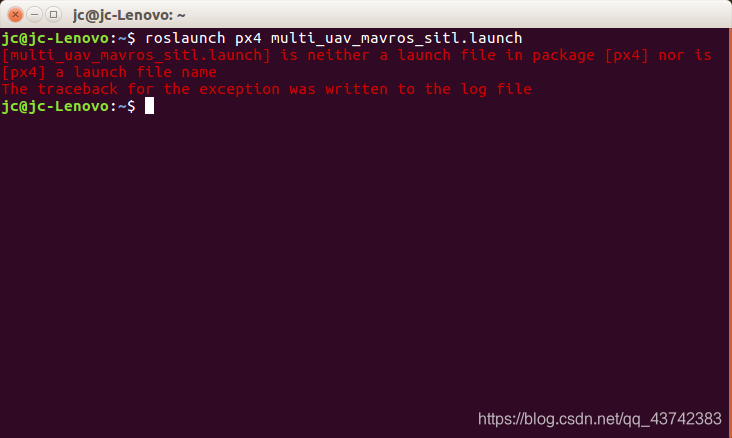
PX4多机ros仿真报错
出现报错: 缺少配置文件,需要添加路径到文件中; 在根目录下打开终端输入: 出现下面一个界面:(蓝色是我添加的) 保存退出; 重新进行刚开始的操作: 使用默认的.launc…

Unity创建2D动作RPG游戏 Create Action 2D RPG Game in Unity
在Unity中创建动作2D RPG游戏 大小解压后:5.69G 时长10h 包含 Udemy Game Asset.unitypackage 源文件 1280X720 MP4 语言:英语中英文字幕(根据原英文字幕机译更准确) 你会学到什么 学习基础来提升C#, 为远程和特殊攻击…