Hadoop集群搭建(五:Hadoop HA集群模式的安装)
实验 目的 要求 | 目的: 1、Hadoop的高可用完全分布模式的安装和验证 要求:
| ||||||||||||||||||
实 验 环 境 |
软件版本: 选用Hadoop的2.7.3版本,软件包名Hadoop-2.7.3.tar.gz 集群规划: * Hadoop的高可用完全分布模式中有HDFS的主节点和数据节点、MapReduce的主节点和任务节点、数据同步通信节点、主节点切换控制节点总共6类服务节点,其中HDFS的主节点、MapReduce的主节点、主节点切换控制节点共用相同主机Cluster-01和Cluster-02,HDFS的数据节点、MapReduce的任务节点共用相同主机Cluster-03、Cluster-04,Cluster-05,数据同步通信节点可以使用集群中的任意主机,但因为其存放的是元数据备份,所以一般不与主节点使用相同主机。 *高可用完全分布模式中需要满足主节点有备用的基本要求, 所以需要两台或以上的主机作为主节点,而完全分布模式中需要满足数据有备份和数据处理能够分布并行的基本要求,所以需要两台或以上的主机作为HDFS的数据节点和MapReduce的任务节点,同时数据同步通信节点工作原理同Zookeeper类似,需要三台或以上的奇数台主机,具体规划如下:
|
实验内容
步骤一:Hadoop基本安装配置
注:1、该项的所有操作步骤使用专门用于集群的用户admin进行;
- 此项只在一台主机操作,然后在下一步骤进行同步安装与配置;
1、创建用于存放Hadoop相关文件的目录,并进入该目录,将软件包解压;
命令:
$mkdir ~/hadoop
$cd ~/hadoop
$tar -xzf ~/setups/Hadoop-2.7.3.tar.gz

2、配置Hadoop相关环境变量;
命令:
$vi ~/.bash_prolife
![]()

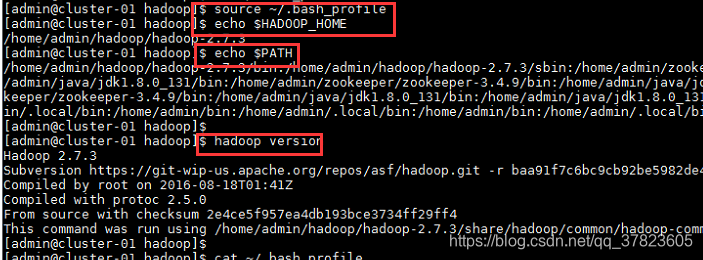
3、使新配置的环境变量立即生效,查看新添加和修改的环境变量是否设置成功,以及环境变量是否正确,验证Hadoop的安装配置是否成功;
命令:
$source ~/.bash_profile
$echo $HADOOP_HOME
$echo $PATH
$hadoop version
步骤二:Zookeeper完全分布模式配置;
注:该项的所有操作步骤使用专门用于集群的用户admin进行;
1、进入Hadoop相关文件的目录,分别创建Hadoop的临时文件目录“tmp”、HDFS的元数据文件目录“name”、HDFS的数据文件目录“data”、Journal的逻辑状态数据目录“journal”;

2、进入Hadoop的配置文件所在目录,对配置文件进行修改,找到配置项“JAVA_HOME”所在行,将其改为以下内容:
Export
JAVA_HOME=/home/admin/java/jdk1.8.0_131
命令:
$cd ~/Hadoop/Hadoop-2.7.3/etc/Hadoop
$vi Hadoop-env.sh

![]()
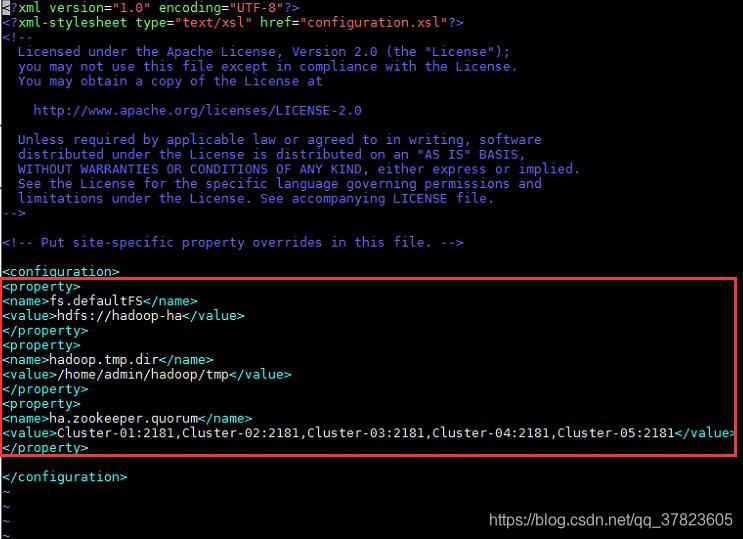
3、对配置文件core-site.xml进行修改,找到标签“<configuration>”所在位置,在其中添加如下红色部分的内容:
<configuration><property><name>fs.defaultFS</name><value>hdfs://hadoop-ha</value></property><property><name>hadoop.tmp.dir</name><value>/home/admin/hadoop/tmp</value></property><property><name>ha.zookeeper.quorum</name><value>Cluster-01:2181,Cluster-02:2181,Cluster-03:2181,Cluster-04:2181,Cluster-05:2181</value></property></configuration>![]()
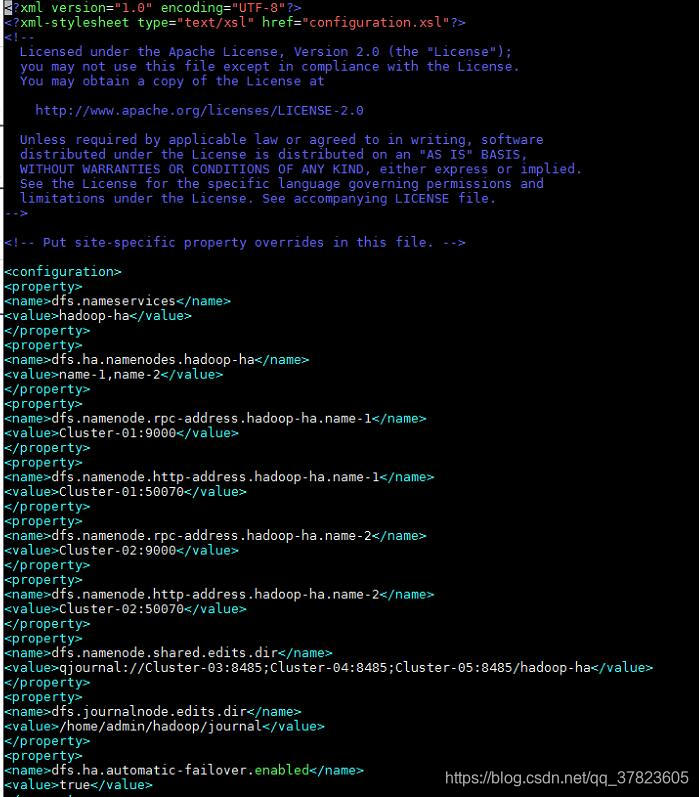
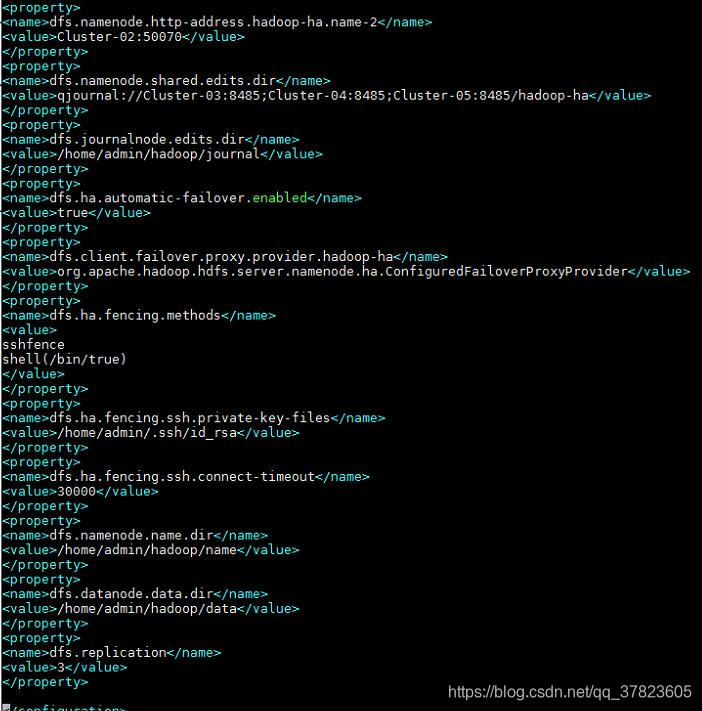
4、对配置文件hdfs-site.xml进行修改,找到标签“<configuration>”所在位置,在其中添加如下红色部分的内容:
<configuration><property><name>dfs.nameservices</name><value>hadoop-ha</value></property><property><name>dfs.ha.namenodes.hadoop-ha</name><value>name-1,name-2</value></property><property><name>dfs.namenode.rpc-address.hadoop-ha.name-1</name><value>Cluster-01:9000</value></property><property><name>dfs.namenode.http-address.hadoop-ha.name-1</name><value>Cluster-01:50070</value></property><property><name>dfs.namenode.rpc-address.hadoop-ha.name-2</name><value>Cluster-02:9000</value></property><property><name>dfs.namenode.http-address.hadoop-ha.name-2</name><value>Cluster-02:50070</value></property><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://Cluster-03:8485;Cluster-04:8485;Cluster-05:8485/hadoop-ha</value></property><property><name>dfs.journalnode.edits.dir</name><value>/home/admin/hadoop/journal</value></property><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property><property><name>dfs.client.failover.proxy.provider.hadoop-ha</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><property><name>dfs.ha.fencing.methods</name><value>sshfenceshell(/bin/true)</value></property><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/home/admin/.ssh/id_rsa</value></property><property><name>dfs.ha.fencing.ssh.connect-timeout</name><value>30000</value></property><property><name>dfs.namenode.name.dir</name><value>/home/admin/hadoop/name</value></property><property><name>dfs.datanode.data.dir</name><value>/home/admin/hadoop/data</value></property><property><name>dfs.replication</name><value>3</value></property></configuration>![]()
5、由模板文件拷贝生成配置文件“mapred-site.xml”
命令:
$cp mapred-site.xml.template mapred-site.xml
$vi mapred-site.xml
找到标签“<configuration>”所在位置,在其中添加如下红色部分的内容:
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property></configuration>
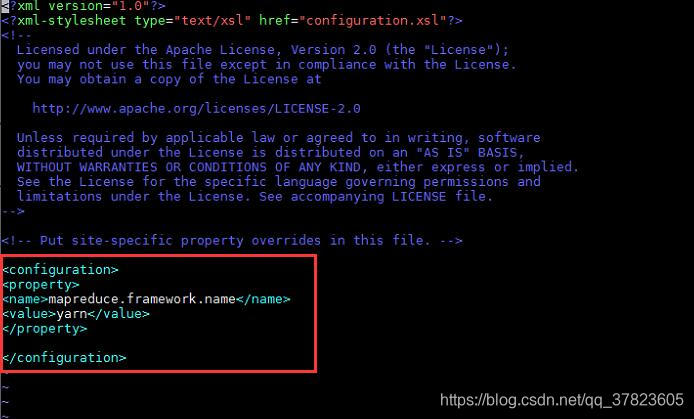
6、对配置文件yarn-site.xml进行修改,找到标签“<configuration>”所在位置,在其中添加如下红色部分的内容:
<configuration><!-- Site specific YARN congfiguration proerties --><property><name>yarn.resourcemanager.ha.enabled</name><value>true</value></property><property><name>yarn.resourcemanager.cluster-id</name><value>yarn-ha</value></property><property><name>yarn.resourcemanager.ha.rm-ids</name><value>resource-1,resource-2</value></property><property><name>yarn.resourcemanager.hostname.resource-1</name><value>Cluster-01</value></property><property><name>yarn.resourcemanager.hostname.resource-2</name><value>Cluster-02</value></property><property><name>yarn.resourcemanager.zk-address</name><value>Cluster-01:2181,Cluster-02:2181,Cluster-03:2181,Cluster-04:2181,Cluster-05:2181</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property></configuration>
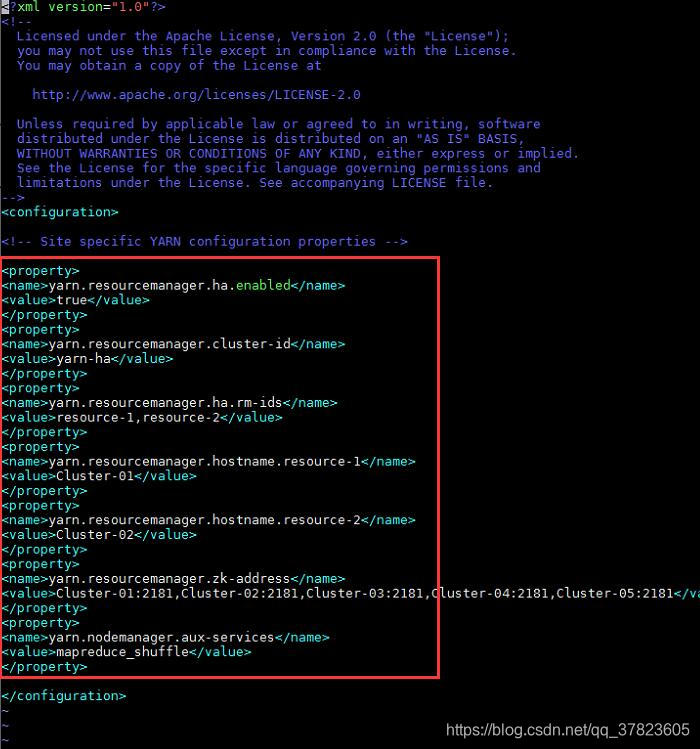
7、对配置文件yarn-env.sh进行修改,找到配置项“JAVA_HOME”所在行,将其改为以下内容:
Export
JAVA_HOME=/home/admin/java/jdk1.8.0_131
![]()
8、对配置文件slaves进行修改,删除文件中原有的所有内容,然后添加集群中所有数据节点的主机名,每行一个主机的主机名,配置格式如下:
Cluster-03
Cluster-04
Cluster-05

步骤三:同步安装和配置;
注:该项的所有操作不受使用准们用于集群的用户admin进行。
1、将“Hadoop”目录和“.bash_profile”文件发给集群中所有主机,发送目标用户为集群专用用户admin,发送目标路径为“/home/admin”,即集群专用用户admin的家目录。
![]()
![]()
![]()
![]()
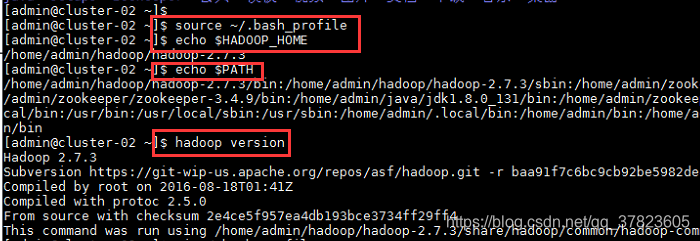
2、使新配置的环境变量立即生效,查看新添加和修改的环境变量是否设置成功,以及环境变量是否正确,验证Hadoop的安装配置是否成功;
命令:
$source ~/.bash_profile
$echo $HADOOP_HOME
$echo $PATH
$hadoop version
步骤四:Hadoop高可用完全分布模式格式化和启动;
注:注意本节格式化内容不可多次执行
注意格式化步骤
该项的所有操作步骤使用专门用于集群的用户admin进行;
1、在所有同步通信节点的主机执行,启动同步通信服务,然后使用命令“jps”查看java进程信息,若有名为“journalNode”的进程,则表示同步通信节点启动成功。
命令:
$hadoop-deamon.sh start journalnode



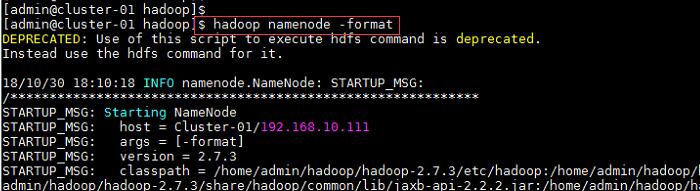
2、在主节点使用此命令,对HDFS进行格式化,若格式化过程中没有报错则表示格式化成功;
命令:
$hadoop namenode -format
3、格式化完成后将“Hadoop”目录下的“name”目录发给集群中所有备用主节点的主机,发送目标用户为集群专用用户admin,即当前与登录用户同名用户,发送目标路径为“/home/admin/hadoop”,即集群专用用户admin家目录下的Hadoop相关文件的目录;
命令:
$scp -r ~/Hadoop/name admin@Cluster-02:/home/admin/Hadoop

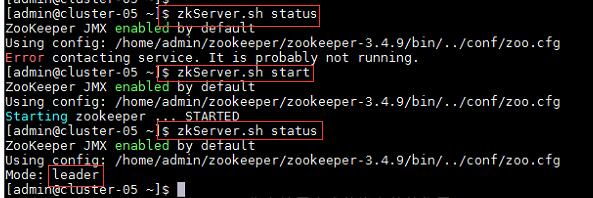
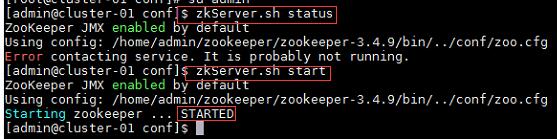
4、在集群中所有主机使用“zkServer.sh status”命令,查看该节点Zookeeper服务当前的状态,若集群中只有一个“leader”节点,其余的均为“follower”节点,则集群的工作状态正常;
如果Zookeeper未启动,则在集群中所有主机使用“zkServer.sh start”命令,启动Zookeeper服务的脚本;
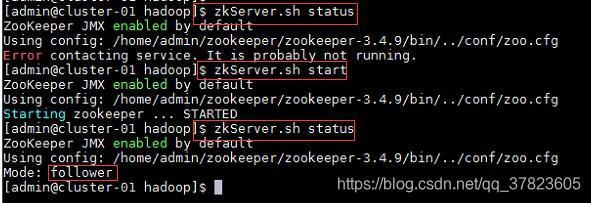
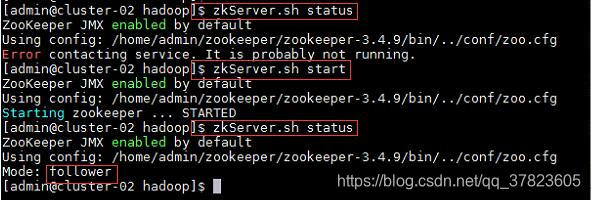
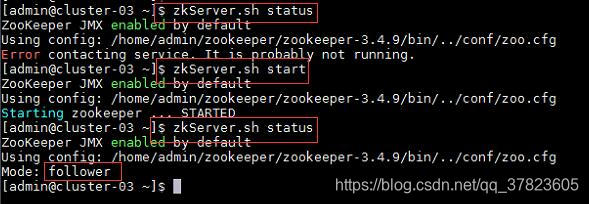
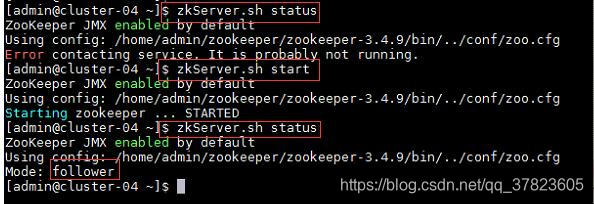
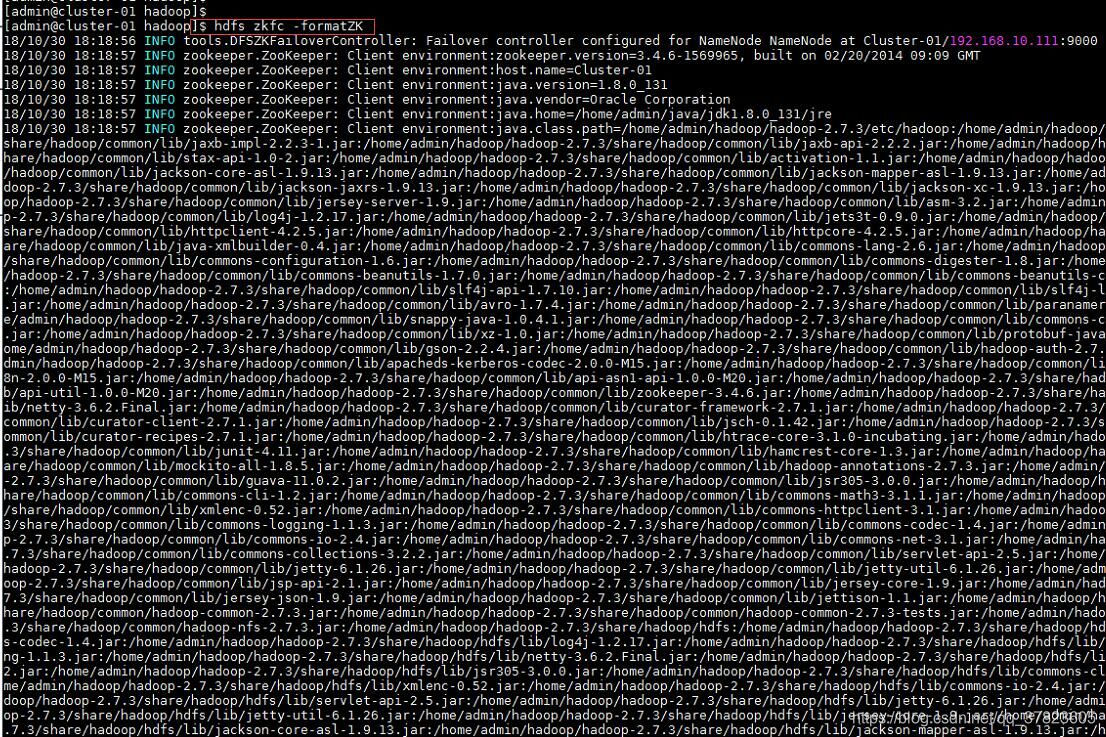
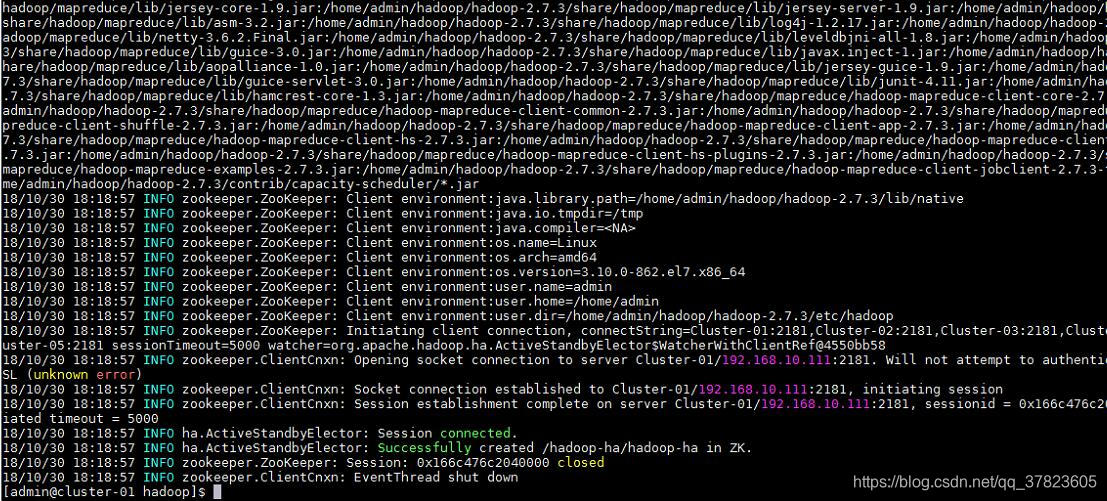
5、在主节点使用“hdfs zkfc -formatZK”命令,对Hadoop集群在Zookeeper中的主节点切换控制信息进行格式化。
6、在所有同步通信节点的主机,使用“Hadoop-daemon.sh stop journalnode”命令,关闭同步通信服务。


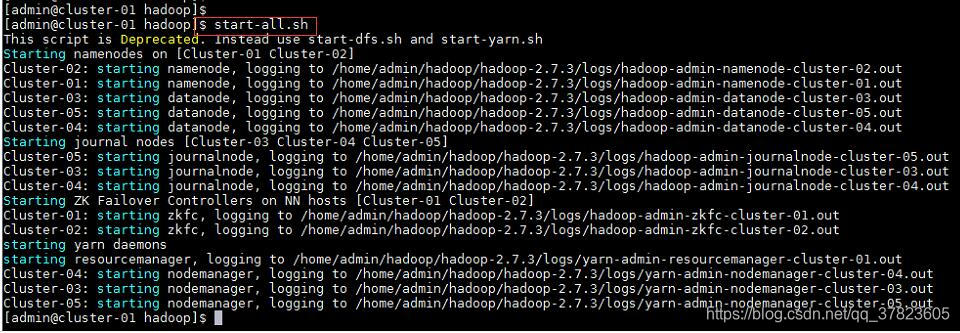
7、在主节点使用“start-all.sh”命令,启动Hadoop集群;
8、在所有备用主节点的主机,使用“yarn-deamon.sh start resourcemanager”命令,启动yarn主节点服务;

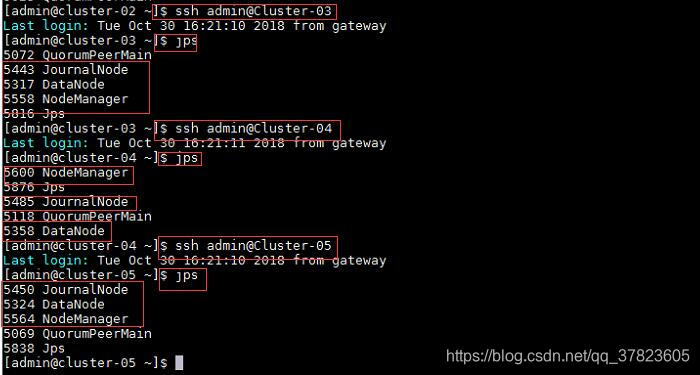
9、在主节点使用命令“jps”查看Java进程信息,若有名为“NameNode”,"ResourceManager”“DFSZKFailoverController”的三个进程,则表示Hadoop集群的主节点启动成功。

10、使用命令“ssh 目标主机名或IP地址”远程登录到所有备用主节点主机,使用命令“jps”查看Java进程信息,若有名为“NameNode”,"ResourceManager”“DFSZKFailoverController”的三个进程,则表示Hadoop集群的备用主节点启动成功。

步骤五:Hadoop高可用完全分布模式启动和验证;
注:该项所有的操作使用专门用于集群的用户admin进行;
1、在Hadoop中创建当前登录用户自己的目录,查看HDFS中的所有文件和目录的结构;
![]()

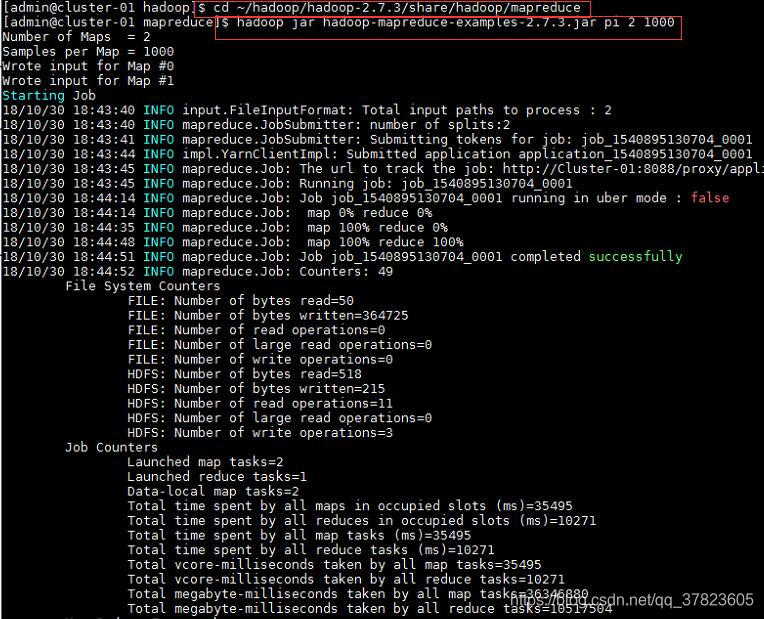
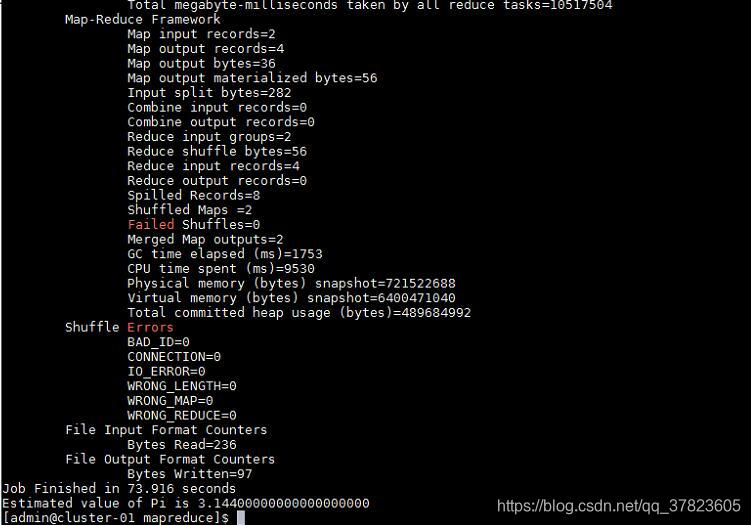
2、进入Hadoop的示例程序包hadoop-mapreduce-examples-2.7.3.jar所在目录;
运行使用蒙地卡罗法计算PI的示例程序;
出现的问题与解决方案
问题:
- Namenode没有启动;

解决方案:
- 格式化namenode,命令“hdfs namenode -format”;
此时向HDFS拷贝文件发现出现如下错误
$hdfs dfs -mkdir -p /home/admin.hadoop
![]()
再次运行jps发现,datanode没有启动。
经过查询资料发现:
当我们使用hdfs namenode -format格式化namenode时,会在namenode数据文件夹(这个文件夹为自己配置文件hdfs-site.xml中dfs.namenode.name.dir的路径)中保存一个current/VERSION文件,记录clusterID,datanode数据文件夹(这个文件夹为自己配置文件中dfs.dataNode.name.dir的路径)中保存的current/VERSION文件中的clustreID的值是第一次格式化保存的clusterID,这样,datanode和namenode之间的ID不一致
所以,在格式化之前先删除 dfs.name.dir指定目录下的所有文件(注意删目录下所有的文件及文件夹而不是删除该目录)
命令:
$hdfs namenode -format
$start-all.sh
$jps
知识拓展
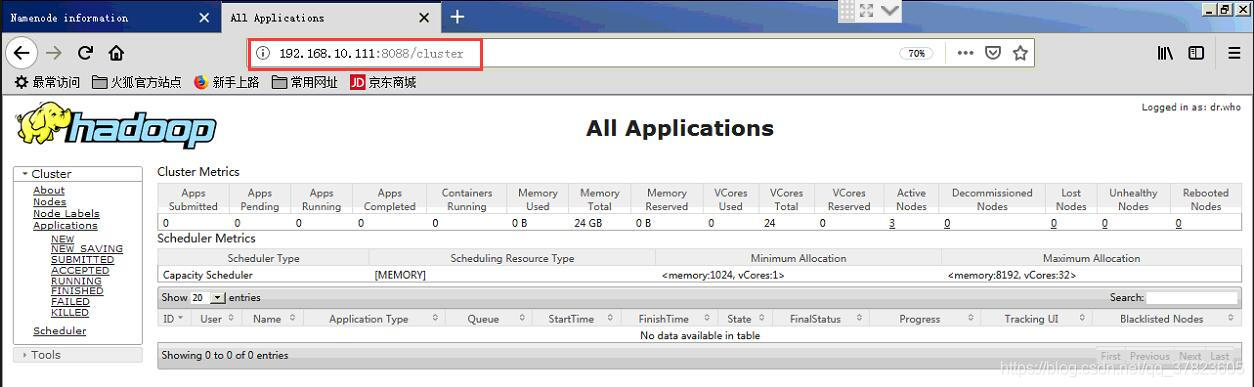
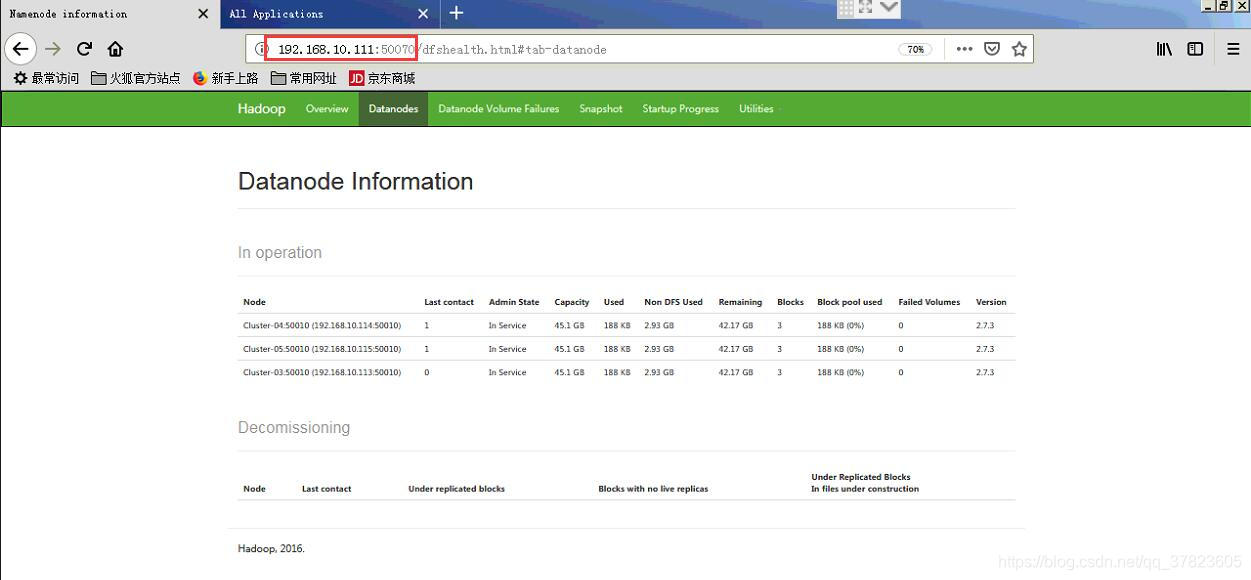
1、使用浏览器访问192.168.10.111:8088,查看并管理Hadoop
2、使用浏览器访问192.168.10.111:50070,查看HDFS情况
3、Hadoop是一种分布式系统的基础构架。
核心是HDFS和MapReduce,hadoop2.0还包括YARN

4、HDFS:Hadoop Distributed FileSystem 分布式文件系统。
//很多时候的数据量超过了单台机器允许存储的范围……故而需要分布式
前身是GFS,谷歌开源的分布式存储系统。
是一个高容错(允许错误发生)的系统,能检测应对硬件故障。
适用于低成本的通用硬件(比如树莓派么)
通过流式数据访问,提供高吞吐量应用程序的访问功能。
5、异常处理:
因为数量多,所以出故障是常态。
【可靠性】存在故障的时候也能较为有效地存储数据。(名字节点故障,数据节点故障,网络断开)
【重新复制】定时会发送“心跳包”检测节点是否健康,失去联系标记为死亡状态,需要重新复制到其他节点。
【数据正确性】校验数据是否有坏块(类似于葡萄的校验?,验证的校验码存储在HDFS命名空间的隐藏文件中)
【元数据失效】FsImage和Editlog是HDFS的核心数据结构。(损坏就崩盘了)名字节点(NameNode)如果崩了就需要人工的干预了。//第二名字节点不支持直接恢复
6、目标
- 数据访问:适合批量处理而非交互式,重点是数据吞吐量而非反应时间
- 大数据:支持大文件,单个文件GB-TB级别
- 简单一致模式:一次写入,多次读,一般写入之后就不再修改了
- 主从结构:一个名字节点和很多数据节点,通常一台机器一个数据节点。
- 硬件故障处理:是设计的核心目标之一
相关文章:
iOS开发业界毒瘤 Hook
原文地址 为什么有这篇博文 不知道何时开始iOS面试开始流行起来询问什么是 Runtime,于是 iOSer 一听 Runtime 总是就提起 MethodSwizzling,开口闭口就是黑科技。但其实如果读者留意过C语言的 Hook 原理其实会发现所谓的钩子都是框架或者语言的设计者预留…

常用rsync命令操作梳理
作为一个运维工程师,经常可能会面对几十台、几百台甚至上千台服务器,除了批量操作外,环境同步、数据同步也是必不可少的技能。说到“同步”,不得不提的利器就是rsync。rsync不但可以在本机进行文件同步,也可以作为远程…

Word英文字符间距太大 中英文输入切换都不行
在Word中输入文字时会遇到这样的情况,就是说中文字符的间距是正常的,但是英文字符间的间距却不正常,总是太宽了,如图: 。 而且这时切换中英文输入都没用,Word的字体设置也正常。后来上网查了下,…

Hadoop集群搭建(六:HBase的安装配置)
实验 目的 要求 目的: 1、HBase的高可用完全分布模式的安装和验证 要求: 完成HBase的高可用完全分布模式的安装;HBase的相关服务进程能够正常的启动;HBase控制台能够正常使用;表创建、数据查询等数据库操作能够正常…
架构师的第一阶段:准备做(Pre-Architecture)
上节说到,做任何事情都可以分为三个阶段:准备做、做、做好。本文,就将进入第一个阶段,准备做阶段。 Pre-Architecture:准备架构 准备架构阶段,最最重要的是弄清楚要做什么东西,即掌握用户需求。…
iOS动画系列之八:使用CAShapeLayer绘画动态流量图
这篇文章通过使用CAShapeLayer和UIBezierPath来画出一个动态显示剩余流量的小动画。 最终实现的效果如下: Paste_Image.png 动态效果图: shapeLayerAni.gif 1. CAShapeLayer 实际中,能够用CALayer完成的任务是比较少的,如果使用这…
hiho_1139_二分+bfs搜索
题目 给定N个点和M条边,从点1出发,到达点T。寻找路径上边的个数小于等于K的路径,求出所有满足条件的路径中最长边长度的最小值。 题目链接:二分 最小化最大值,考虑采用二分搜索。对所有的边长进行排序,二分&#x…

Hadoop集群搭建(七:MySQL的安装配置)
实验 目的 要求 目的: 1、掌握MySQL在集群平台中的安装 要求: 完成MySQL的集群版的安装;MySQL集群的相关服务进程能够正常启动;MySQL集群的SQL服务能够作为系统服务开机自动启动;MySQL客户端能够远程连接MySQL集群的…

如何在VMware虚拟机上安装Linux操作系统(Ubuntu)
作为初学者想变为计算机大牛非一朝一夕,但掌握基本的计算机操作和常识却也不是多么难的事情。所以作为一名工科男,为了把握住接近女神的机会,也为了避免当白痴,学会装系统吧!of course为避免把自己的电脑作为牺牲品&am…

cf #363 b
B. One Bombtime limit per test1 secondmemory limit per test256 megabytesinputstandard inputoutputstandard outputYou are given a description of a depot. It is a rectangular checkered field of n m size. Each cell in a field can be empty (".") or…
swift-video-generator:图片加音频生成视频及多视频合并库及演示
阅读 80收藏 92017-11-07原文链接:github.com腾讯云学生优惠套餐,985高校学习云计算的主力机型,2G2核,1M带宽系统盘(Linux 50G/Windows 50G)免费赠送50GB对象存储空间还有.cn域名一年使用权!不要…

Hadoop集群搭建(八:Hive的安装配置)
实验 目的 要求 目的: (1)掌握数据仓库工具Hive的安装和配置; 要求: 完成Hive工具的安装和配置;Hive工具能够正常启动运行;Hive控制台命令能够正常使用;能够正常操作数据库、表、…
iOS 富文本编辑工厂, 让书写更简便.
由于最近常用富文本, 在编辑一个富文本时需要操作很多的属性, 书写起来很不方便. 所以我将这些相关属性整理并使用链式方式将它简化了一下. 效果请看下面Demo. 项目工程 实现很简单, 我嘴太笨, 这里就不介绍了, 如有兴趣直接看源码吧. 同时可以通过cocoapods来使用它. pod SJAt…
ORACLE 数据的逻辑组成
数据块(block)Oracle数据块(Data Block)是一组连续的操作系统块。分配数据库块大小是在Oracle数据库创建时设置的,数据块是Oracle读写的基本单位。数据块的大小一般是操作系统块大小的整数倍,这样可以避免不…
Java 的zip压缩和解压缩
Java 的zip压缩和解压缩好久没有来这写东西了,今天中秋节,有个东西想拿出来分享,一来是工作中遇到的问题,一来是和csdn问候一下,下面就分享一个Java中的zip压缩技术,代码实现比较简单,代码如下:…
Hadoop集群搭建(九:各服务的启动)
1、查看Zookeeper服务状态,若集群中只有一个"leader"节点, 其余的均为"follower"节点,则集群的工作状态正常 $zkServer.sh status 2、在集群中所有主机上使用此命令,启动Zookeeper服务 $zkServer.sh start…
iOS 后台下载及管理库
说起下载第一个想起的就是ASI。一年前接手的新项目是核心功能是视频相关业务,在修改和解决视频下载相关的问题的时候让我体会到了ASI的下载的强大。后来新需求需要视频后台下载,使用NSURLSession的时候,更加深刻的体会到了ASI的强大好用。后来…
(转) 使用Speech SDK 5.1文字转音频
下载地址: http://www.microsoft.com/en-us/download/details.aspx?id10121 SeppchSDK51.exe 语音合成引擎 SpeechSDK51LangPack.exe 支持日语和简体中文需要这个支持。 SpeechSDK51MSM.exe 如果要将引擎作为产品的一部分发布需要这个。 Sp5TTintXP.exe XP下Mike和…
IE8下面的line-height的bug
当line-height小于正常值时,超出的部分将被剪裁掉转载于:https://www.cnblogs.com/jsingleegg/p/js_ie8.html

Hadoop集群的基本操作(一:HDFS操作及MapReduce程序练习)
实验 目的 要求 目的: 理解HDFS在Hadoop体系结构中的角色;熟练使用HDFS操作常用的Shell命令;了解Hadoop集群MapReduce程序的简单使用;(上传WordCount的jar执行程序;使用WordCount进行MapReduce计算&#x…
iOS实现动态区域裁剪图片
阅读 249收藏 322017-11-29原文链接:github.com想自己动手搭建一个 Discuz 论坛?试试腾讯云上实验室吧https://cloud.tencent.com/developer/labs 裁剪图片功能在很多上传图片的场景里都需要用到,一方面应用服务器可能对图片的尺寸大小有限制…
每天CookBook之JavaScript-062
鼠标进入事件鼠标离开事件<!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>062</title> </head> <body> <div><img src"001" alt"001"><img src…
spring + Quartz定时任务配置
<bean id"exportBatchFileTask" class"com.ydcn.pts.task.ExportBatchFileTask"></bean><bean id"readBatchFileTask" class"com.ydcn.pts.task.ReadBatchFileResultTask"></bean><!-- 生成开卡档…
Hadoop集群的基本操作(二:HBase的基本操作)
实验 目的 要求 目的: 1、HBase的基本应用 要求: 完成HBase的高可用完全分布模式的安装;HBase的相关服务进程能够正常的启动;HBase控制台能够正常使用;表创建、数据查询等数据库操作能够正常进行; …
Abaqus用户子程序umat的学习
Abaqus用户子程序umat的学习 说明:在文件中,!后面的内容为注释内容。本文为学习心得,很多注释是自己摸索得到。如有不正确的地方,敬请指正。 ! —————————————————————————— ! 1、为何需要…
PHP:isset()-检测变量是否被设置
isset()-检测变量是否被设置 bool isset(mixed $var [, mixed $...]),检查变量是否被设置,并且不是NULL。var,要检测的变量,...其他变量,允许有多个变量。 返回值:如果var存在并且不是NULL,则返回TRUE&…
Android通过ShareSDK实现新浪微博分享
ShareSDK社会化分享的官方说明:是中国最大的APP内分享服务提供商,ShareSDK社会化分享,全面支持微信,微博,QQ空间,来往,易信,Facebook等国内外40个平台。 ShareSDK官方网站ÿ…

Hadoop集群的基本操作(三:HBase的基本操作)
实验 目的 要求 目的: MySQL数据库的基本命令;MySQL数据库中使用SQL语句;MySQL数据库中数据库,表,数据的操作;要求: 完成MySQL的集群版的安装;MySQL集群的相关服务进程能够正常启…
iOS通过Plist保存离线调试日志
最近需要测试APP在iPhone没连接USB情况下定位时间间隔的情况,固把nslog的日志信息保存成本地Plist文件,以便测试结束后查阅运行时的日志。 一、新建一个保存日志的方法,参数为每次定位成功的时间(作为key),…
关于变量名前面加m的问题
为什么很多人写代码会在变量名前面加一个小写的m? 上大学那会儿就对这个问题感到很好奇。于是网上到处搜,有人说是member的意思。于是后来一直就这么认为。 最近在读Android源码,发现很多系统变量命名时都加了m,而有的变量又没有加…