Hadoop集群的基本操作(一:HDFS操作及MapReduce程序练习)
实验 目的 要求 | 目的:
(上传WordCount的jar执行程序;使用WordCount进行MapReduce计算) 要求:
| ||||||||||||||||||
实 验 环 境 实 验 环 境 |
集群规划: * Hadoop的高可用完全分布模式中有HDFS的主节点和数据节点、MapReduce的主节点和任务节点、数据同步通信节点、主节点切换控制节点总共6类服务节点,其中HDFS的主节点、MapReduce的主节点、主节点切换控制节点共用相同主机Cluster-01和Cluster-02,HDFS的数据节点、MapReduce的任务节点共用相同主机Cluster-03、Cluster-04,Cluster-05,数据同步通信节点可以使用集群中的任意主机,但因为其存放的是元数据备份,所以一般不与主节点使用相同主机。 *高可用完全分布模式中需要满足主节点有备用的基本要求, 所以需要两台或以上的主机作为主节点,而完全分布模式中需要满足数据有备份和数据处理能够分布并行的基本要求,所以需要两台或以上的主机作为HDFS的数据节点和MapReduce的任务节点,同时数据同步通信节点工作原理同Zookeeper类似,需要三台或以上的奇数台主机,具体规划如下:
|
练习内容
练习一:熟悉常用的HDFS操作;
1、向HDFS中上传任意文本文件,如果指定的文件在HDFS中已经存在,由于用户指定是追加到原有文件末尾还是覆盖原有的文件;(追加文件内容以编程方式进行)

2、从HDFS中下载指定文件,如果本地文件与要下载的文件名称相同,则自动对下载的文件重命名;

3、将HDFS中指定文件的内容输出到终端中;

4、显示HDFS中指定的文件的读写权限、大小、创建时间、路径等信息;

5、给定HDFS中某一个目录,输出改目录下的所有文件的读写权限、大小、创建时间、路径等信息,如果该文件是目录,则递归输出该目录下所有文件相关信息;

6、提供一个HDFS内的文件的路径,对该文件进行创建和删除操作。如果文件所在目录不存在,则自动创建目录;

7、提供一个HDFS的目录的路径,对该目录进行创建和删除操作,创建目录时,如果目录文件所在目录不存在则自动创建相应的目录;删除目录时,由用户指定当该目录不为空时是否还删除该目录;

8、向HDFS中指定的文件追加内容,由用户指定内容追加到原有文件的开头或者结尾;


练习二:MapReduce-WordCount程序练习;
1、上传jar包;
1.1、现在以“admin”普通用户登录“Master。Hadoop”服务器。即在主节点操作;
a)创建本地示例文件;
首先在“/home/admin”目录下创建文件夹“file”.
命令:
$mkdir ~/file
![]()
接着创建两个文本文件file1.txt和file2.txt。
使fiel1.txt内容为“Hello World”,而file2.txt的内容为“Hello Hadoop”。
命令:
$cd file
$echo “Hello World”>file1.txt
$echo “Hello Hadoop”>file2.txt

b)在HDFS上创建输入文件夹;
命令:
$hadoop fs -mkdir input
![]()
c)上传本地file中文件到集群的input目录下;
命令:
$hadoop fs -put ~/file/file*.txt input
$hadoop fs -ls input

1.2、上传jar包
先使用Xftp工具把WordCount的jar执行程序包,上传到“~/hadoop/hadoop-2.7.3/share/Hadoop/mapreduce”目录下;
命令:
$ls

2、示例运行;
2.1、在集群上运行WordCount程序;
注:以input作为输入目录,output目录作为输出目录。
命令:
$hadoop jar ~/ hadoop/hadoop-2.7.3/share/Hadoop/mapreduce/Hadoop-0.20.2-examples.jar wordcount input output


Hadoop命令会启动一个JVM来运行达个MapReduce程序,并自动获得Hadoop的配置,同时把类的路径(及其依赖关系)加入到Hadoop的库中。
以上就是Hadoop Job的运行记录,从达里可以看到,达个Job被赋予了一个ID号:job_1533748123309_0002,而且得知输入文件有两个(Totalinput paths to process:2),同时还可以了解map的输入输出记录(record数及字节数),以及reduce输入输出记录。比如说,在本例中,map的task数量是2个,reduce的task数量是一个。map的输入record数是2个,输出record数是4个等信息。
2.2、查看结果;
a)查看HDFS上output目录内容;
命令:
$hadoop fs -ls output
从上图中知道生成了两个文件,我们的结果在“part-r-00000”中。
b)查看结果输出文件内容;
命令:
$hadoop fs -cat output/part-r-00000

3、Hadoop的Web验证练习;
3.1、使用浏览器访问192.168.10.111:8088,ResourceManager状态查看;

3.2、使用浏览器访问192.168.10.111:50070,查看HDFS情况;

3.3、使用浏览器访问192.168.10.112:50070,在从节点上查看NodeManager信息:

出现的问题与解决方案
问题:
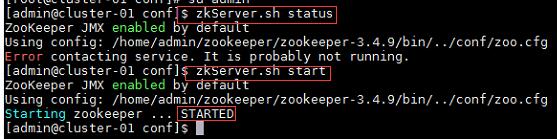
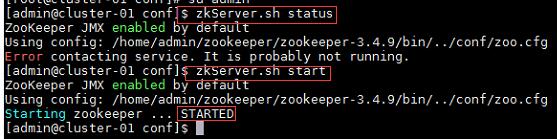
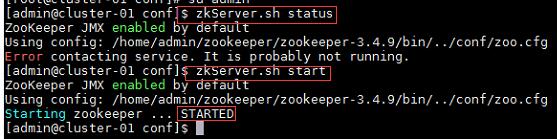
1、Namenode没有启动;

2、在使用 -rmr 递归删除命令时报错;
3、追加到文件的开头(-copyFromLocal)
a)如图,向HDSFS中的file2.txt中导file2.txt的类容,提示文件已经存在,直接写一个不存在的文件file3.txt,发现导入成功,再次向file3.txt导入类容,又提示文件已经存在

b).hadoop fs -copyFromLocal -f产看文件file2.txt中的类容

向文件fil2.txt 导入类容,然后产看,发现文件中之前的类容被覆盖了
解决方案:
- 格式化namenode,命令“hdfs namenode -format”;
- -rmr命令不适配CentOS7环境,应改为“-rm -R”;
- a)此方法只适用于把一个文件中的类容导入到一个不存在的文件中;
b) 此方法导入到文件开头时会覆盖源文件类容;
知识拓展
1、Hadoop是一种分布式系统的基础构架。
核心是HDFS和MapReduce,hadoop2.0还包括YARN

2、HDFS:Hadoop Distributed FileSystem 分布式文件系统。
//很多时候的数据量超过了单台机器允许存储的范围……故而需要分布式
前身是GFS,谷歌开源的分布式存储系统。
是一个高容错(允许错误发生)的系统,能检测应对硬件故障。
适用于低成本的通用硬件(比如树莓派么)
通过流式数据访问,提供高吞吐量应用程序的访问功能。
3、异常处理:
因为数量多,所以出故障是常态。
【可靠性】存在故障的时候也能较为有效地存储数据。(名字节点故障,数据节点故障,网络断开)
【重新复制】定时会发送“心跳包”检测节点是否健康,失去联系标记为死亡状态,需要重新复制到其他节点。
【数据正确性】校验数据是否有坏块(类似于葡萄的校验?,验证的校验码存储在HDFS命名空间的隐藏文件中)
【元数据失效】FsImage和Editlog是HDFS的核心数据结构。(损坏就崩盘了)名字节点(NameNode)如果崩了就需要人工的干预了。//第二名字节点不支持直接恢复
4、目标
- 数据访问:适合批量处理而非交互式,重点是数据吞吐量而非反应时间
- 大数据:支持大文件,单个文件GB-TB级别
- 简单一致模式:一次写入,多次读,一般写入之后就不再修改了
- 主从结构:一个名字节点和很多数据节点,通常一台机器一个数据节点。
- 硬件故障处理:是设计的核心目标之一
相关文章:
iOS实现动态区域裁剪图片
阅读 249收藏 322017-11-29原文链接:github.com想自己动手搭建一个 Discuz 论坛?试试腾讯云上实验室吧https://cloud.tencent.com/developer/labs 裁剪图片功能在很多上传图片的场景里都需要用到,一方面应用服务器可能对图片的尺寸大小有限制…

每天CookBook之JavaScript-062
鼠标进入事件鼠标离开事件<!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>062</title> </head> <body> <div><img src"001" alt"001"><img src…
spring + Quartz定时任务配置
<bean id"exportBatchFileTask" class"com.ydcn.pts.task.ExportBatchFileTask"></bean><bean id"readBatchFileTask" class"com.ydcn.pts.task.ReadBatchFileResultTask"></bean><!-- 生成开卡档…
Hadoop集群的基本操作(二:HBase的基本操作)
实验 目的 要求 目的: 1、HBase的基本应用 要求: 完成HBase的高可用完全分布模式的安装;HBase的相关服务进程能够正常的启动;HBase控制台能够正常使用;表创建、数据查询等数据库操作能够正常进行; …
Abaqus用户子程序umat的学习
Abaqus用户子程序umat的学习 说明:在文件中,!后面的内容为注释内容。本文为学习心得,很多注释是自己摸索得到。如有不正确的地方,敬请指正。 ! —————————————————————————— ! 1、为何需要…
PHP:isset()-检测变量是否被设置
isset()-检测变量是否被设置 bool isset(mixed $var [, mixed $...]),检查变量是否被设置,并且不是NULL。var,要检测的变量,...其他变量,允许有多个变量。 返回值:如果var存在并且不是NULL,则返回TRUE&…
Android通过ShareSDK实现新浪微博分享
ShareSDK社会化分享的官方说明:是中国最大的APP内分享服务提供商,ShareSDK社会化分享,全面支持微信,微博,QQ空间,来往,易信,Facebook等国内外40个平台。 ShareSDK官方网站ÿ…

Hadoop集群的基本操作(三:HBase的基本操作)
实验 目的 要求 目的: MySQL数据库的基本命令;MySQL数据库中使用SQL语句;MySQL数据库中数据库,表,数据的操作;要求: 完成MySQL的集群版的安装;MySQL集群的相关服务进程能够正常启…
iOS通过Plist保存离线调试日志
最近需要测试APP在iPhone没连接USB情况下定位时间间隔的情况,固把nslog的日志信息保存成本地Plist文件,以便测试结束后查阅运行时的日志。 一、新建一个保存日志的方法,参数为每次定位成功的时间(作为key),…
关于变量名前面加m的问题
为什么很多人写代码会在变量名前面加一个小写的m? 上大学那会儿就对这个问题感到很好奇。于是网上到处搜,有人说是member的意思。于是后来一直就这么认为。 最近在读Android源码,发现很多系统变量命名时都加了m,而有的变量又没有加…
谷歌推出情境感知API
在 Google I/O 2016 大会上,我们宣布推出新的 Google Awareness API,让您的应用可以利用快照和围栏智能应对用户情境,并且仅需占用极少量的系统资源。 所有开发者均可以通过 Google Play 服务获取 Google Awareness API。 利用 7 种不同类型的…
Hadoop集群的基本操作(四:Hive的基本操作)
实验 目的 要求 目的: (1)掌握数据仓库工具Hive的使用; 要求: 掌握数据仓库Hive的使用;能够正常操作数据库、表、数据; 实 验 环 境 五台独立PC式虚…
【转】通过Hibernate将数据 存入oracle数据库例子
一、 Hibernate介绍 Hibernate是基于对象/关系映射(ORM,Object/Relational Mapping)的一个解决方案。ORM方案的思想是将对象模型表示的对象映射到关系型数据库中,或者反之。Hibernate目前是ORM思想在Java中最成功、最强大的实现。…

自动布局按钮排列平均分布
需要实现如下图所示的主页面布局,需要两排按钮,每一排都自动平均分布,Android的话直接用LinearLayout水平布局,并设置layout_weight即可,对于iOS,网上有使用代码实现,感觉略麻烦,我直…

maven3 手动安装本地jar到仓库
安装命令: mvn install:install-file -Dfile{Path/to/your/ojdbc.jar} -DgroupIdcom.oracle -DartifactIdojdbc6 -Dversion11.2.0 -Dpackagingjar我自己安装oracle14.jar 时命令如下:mvn install:install-file -DgroupIdcom.oracle -DartifactIdojdbc14 …
Hadoop集群的基本操作(五:Sqoop的基本操作)
实验 目的 要求 目的: 掌握ETL工具Sqoop的使用;掌握MySQL和HDFS之间的数据转换;要求: 掌握ETL工具Sqoop的使用;能够正常操作数据库、表、数据; 实 验 环 境 五台…
NEWS - InstallShield 2013 SP1发布
2013的这个国庆假期期间,InstallShield厂商Flexerasoftware(中文名:福莱睿)发布了最新版本InstallShield 2013的SP1,由于这个升级包带来一些新的技术支持和变化,所以特地给大家介绍一下: 1. 支持…
iOS 高德导航按返回后报错 解决
最近项目要添加导航功能,用了高德导航SDK,很郁闷每次从地图界面返回前一页面都报错,弄了很久,最终从高德开发者论坛找到一解决方法,可以试一下。 在导航的ViewController的viewWillDisappear中调用如下方法࿰…
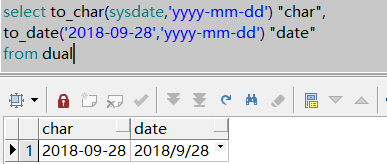
Oracle的基本操作(一:子查询与常用函数)
1、描述TO_CHAR和TO_DATE函数的用法。 TO_CHAR(d|n[,fmt]):把日期和数字转换为指定格式(fmt)的字符串; TO_DATE(x[,fmt]):把一个字符串一fmt格式转换为一个日期类型; 举例:select to_char(sysdate,yyyy-mm-dd) "char", to_date(…
易买网的一些增删改查
正如题目所说的一样,今天就来说说易买网中的一些增删改查,主要的功能有注册、用户管理以及商品分类等! 1.注册 1.1 注册涉及到了一个ajax远端技术,主要是用来控制注册用户在数据库中是否存在: <script>$(function(){//焦点移出表单时$("#user…

iOS后台持续定位并定时上传
最近做一个考勤APP,功能很简单,就是一直在后台运行,每隔固定时间向服务器上传一次位置信息。持续运行24小时测试,功能实现。 1.ViewController.h文件: #import <CoreLocation/CoreLocation.h>并实现CLLocationMa…
jQuery UI vs Kendo UI jQuery Mobile vs Kendo UI Mobile
jQuery UI vs Kendo UI http://jqueryuivskendoui.com/#introduction jQuery Mobile vs Kendo UI Mobile http://jqueryuivskendoui.com/#mobile-introduction Kendo UI教程 http://www.cnblogs.com/pangblog/archive/2013/09/10/3313135.html转载于:https://www.cnblogs.com/j…

Oracle的基本操作(二:存储过程)
1、编写一个存储过程,根据输入的工作类型,输入该工作的平均工资。 -- Created on 2018/9/30 by YANXUKUNcreate or replace procedure avgsal(v_job in scott.emp.job%type)isavgsal2 number;beginselect avg(sal) into avgsal2 from scott.emp where j…

web11 Struts处理表单数据
电影网站:www.aikan66.com 项目网站:www.aikan66.com 游戏网站:www.aikan66.com 图片网站:www.aikan66.com 书籍网站:www.aikan66.com 学习网站:www.aikan66.com Java网站:www.aikan66.co…
瀑布流开源这两天
想必第一眼看到 Masonery 效果的人们会和当初的我有同样的感觉,惊艳!尤其是在你双击浏览器标题栏的空白处之后,所有的区块都在默默寻找自己的位置,无论大小,就像上海虹桥火车站涌入地铁的人群。和技术实现无关…
iOS网络请求总结
*说明:文章中HTTP为宏定义的http地址,事例通过app_login.action的接口,通过传递policyNum、plateNum、phoneNum三个参数进行登录操作 一、方法1: Foundation框架 NSURLConnection (1)同步请求:同…
MongoDB数据库(一:基本操作)
1、创建名称为自己姓名拼音缩写的数据库; 2、创建名为姓名拼音缩写col的集合,如dugncol; 3、删除2中的集合,重新创建格式如dugncolnew的集合; 4、在3创建的集合中,插入10条文档数据,要求分别插入…
NYOJ--811--变态最大值
/*Name: NYOJ--811--变态最大值Author: shen_渊 Date: 17/04/17 15:49Description: 看到博客上这道题浏览量最高,原来的代码就看不下去了 o(╯□╰)o */#include<cstring> #include<iostream> #include<algorithm> using namespace std; struct…
扩展的八皇后问题
百度百科:八皇后问题是一个古老而著名的问题,是回溯算法的典型案例。该问题是国际西洋棋棋手马克斯贝瑟尔于1848年提出:在8X8格的国际象棋上摆放八个皇后,使其不能互相攻击,即任意两个皇后都不能处于同一行、同一列或同…
C++ 常用函数方法
/* * 拆分字符串 * 参数: * strData 字符串 * split 分隔符 * 返回: * 返回动态数组std::vector<std::string> ,记得要delete 内存 */ std::vector<std::string>* GetStringArray(char* strData,char* split)…