Hadoop集群的基本操作(四:Hive的基本操作)
实验 目的 要求 | 目的: (1)掌握数据仓库工具Hive的使用; 要求:
|
实 验 环 境 |
软件版本: 选用Hive的2.1.1版本,软件包名apache-hive-2.1.1-bin.tar.gz; |
练习内容
步骤一:Hive工具安装配置
1、集群的启动;
★ 该项的所有操作步骤使用专门用于集群的用户admin进行。
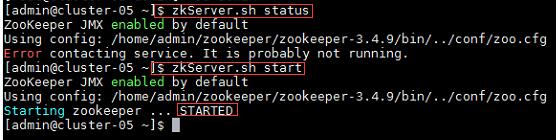
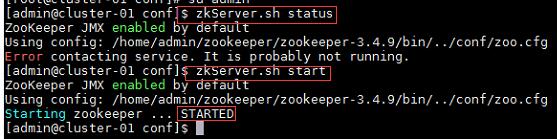
★ 启动HBase集群之前首先确保Zookeeper集群已被开启状态。(实验5台),Zookeeper的启动需要分别在每个计算机的节点上手动启动。如果家目录下执行启动报错,则需要进入zookeeper/bin目录执行启动命令。
★ 启动HBase集群之前首先确保Hadoop集群已被开启状态。 (实验5台)Hadoop只需要在主节点执行启动命令。
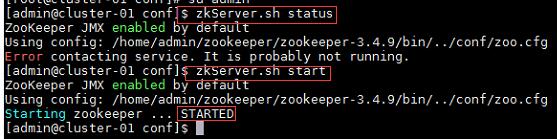
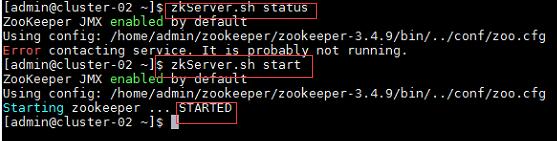
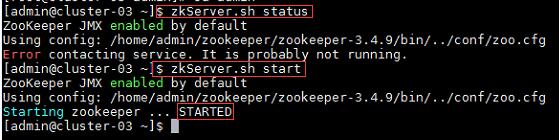
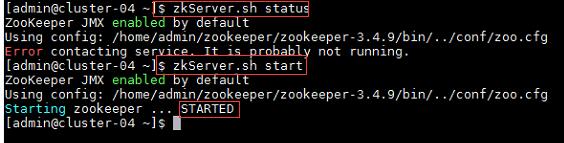
a) 在集群中所有主机上使用命令“zkServer.sh status”查看该节点Zookeeper服务当前的状态,若集群中只有一个“leader”节点,其余的均为“follower”节点,则集群的工作状态正常。如果Zookeeper未启动,则在集群中所有主机上使用命令“zkServer.sh start”启动Zookeeper服务的脚本;
b) 在主节点,查看Java进程信息,若有名为“NameNode”、“ResourceManager”的两个进程,则表示Hadoop集群的主节点启动成功。在每台数据节点,若有名为“DataNode”和“NodeManager”的两个进程,则表示Hadoop集群的数据节点启动成功, 如果不存在以上三个进程,则在主节点使用此命令,启动Hadoop集群。
主节点及备用主节点:


通信节点:



c) 确定Hadoop集群已启动状态,然后在主节点使用此命令,启动HBase集群, 在集群中所有主机上使用命令“jps”;

2、在主节点使用命令“hive”启动Hive,启动成功后能够进入Hive的控制台。
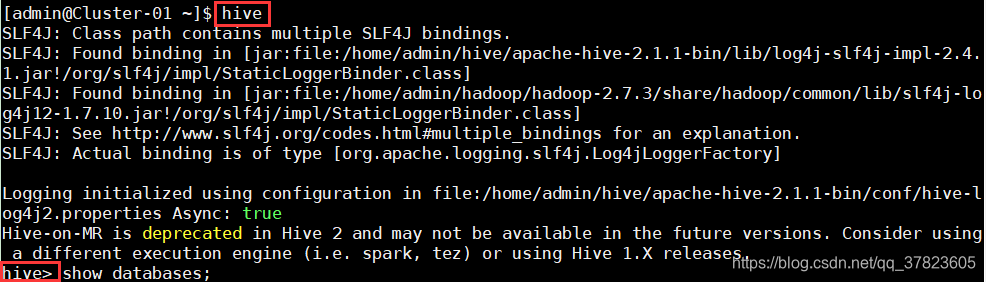
3、在控制台中使用命令“show databases;”查看当前的数据库列表。

练习:
1、启动Hive,Hive常用命令;
命令:
$hive #启动Hive,启动成功后能够进入Hive的控制台
>show databases; #查看当前的数据库列表
>create database test1; #创建数据库
>show databases;
>use test1; #使用数据库
>create table testable(id int,name string,age int,tel string)row format delimited fields terminated by’,’stored as textfile;

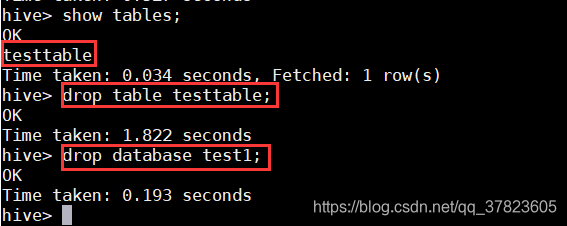
>show tables;
>drop table testable; #删除表
>drop database test1; #删除数据库
2、Hive的数据模型_内部表
-与数据库中的Table在概念上是类似的。
-每一个Table在Hive中都有一个相应的目录存储数据。
-所有的Table数据(不包括External Table)都保存在这个目录中。
练习:
命令:
$hive
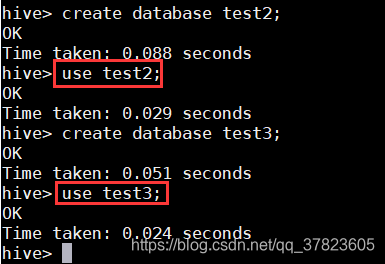
>create database test2;
>use test2;
>create database test3;
>use test3;
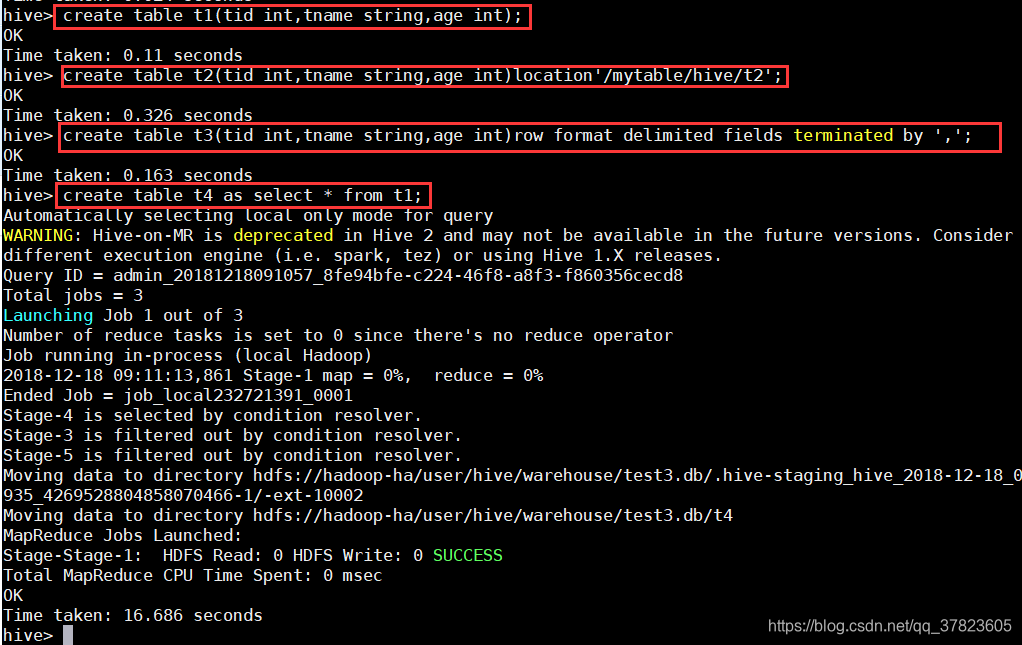
>create table t1(tid int, tname string, age int);
>create table t2(tid int, tname string, age int) location '/mytable/hive/t2';
>create table t3(tid int, tname string, age int) row format delimited fields terminated by ';
>create table t4 as select * from t1;
$ hadoop fs -ls /user/hive/warehouse/

$ hadoop fs -ls /user/hive/warehouse/test2.db
$ hadoop fs -ls /user/hive/warehouse/test2.db/t1

$ hadoop fs -ls /mytable/hive/

>desc t1;
>alter table tl add columns(english int);
>desc t1;
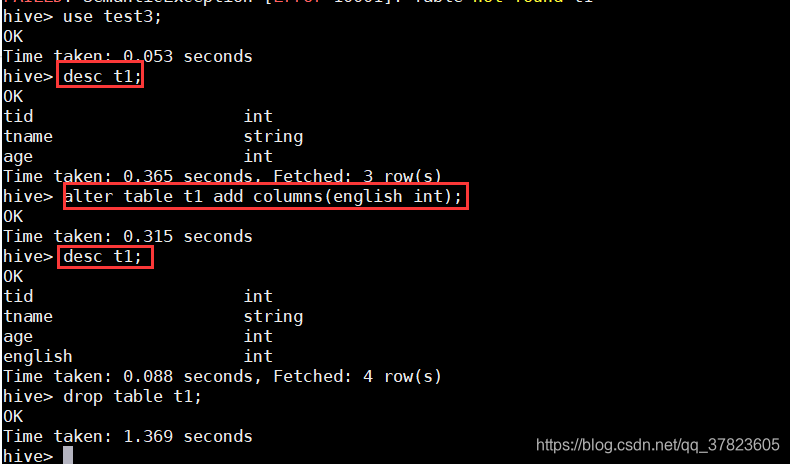
>drop table t1;
$hdfs dfs -ls /user/hive/warehouse/test2db

3、Hive的数据模型_分区表
命令:
$hive
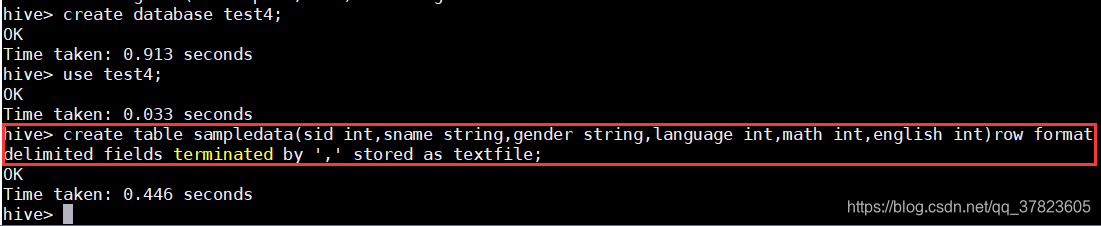
>create database test4;
>use test4;
a)准备数据表;
>create table sampledata (sid int, sname string, gender string, language int,math int, english int) row format delimited fields terminated by,' stored astextfile;
b)准备文件数据;
在admin用户家目录下新建sampledata.txt内容:
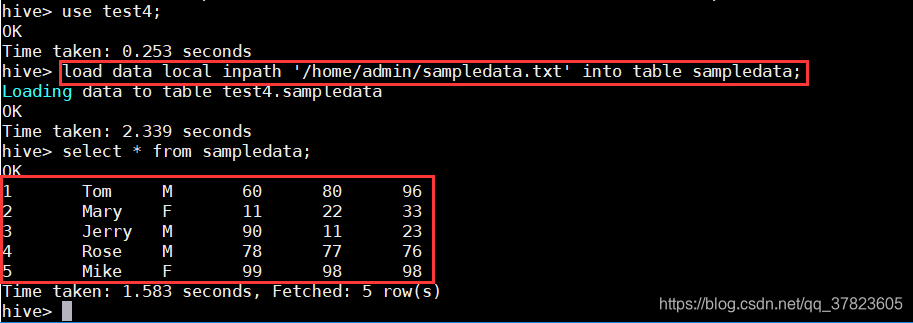
1,Tom,M,60,80,96
2,Mary,F,ll,22,33
3,Jerry,M,90,11,23
4,Rose,M,78,77,76
5,Mike,F,99,98,98
![]()

c)将文本数据插入到数据表;
>load data local inpath ‘/home/admin/sampledata.txt’into table sampledata;
>select * from sampledata;
-partition对应于数据库中的Partition 列的密集索引
-在Hive中, 表中的一个Partition对应于表下的一个目录, 所有的Partition的数据都存储在对应的目录中。
d)创建分区表;
命令:
>create table partition _table(sid int,sname string)partitioned by(gender
string)row format delimited fields terminated by',;
> select*from partition_table;
e)向分区表中插入数据;
命令:
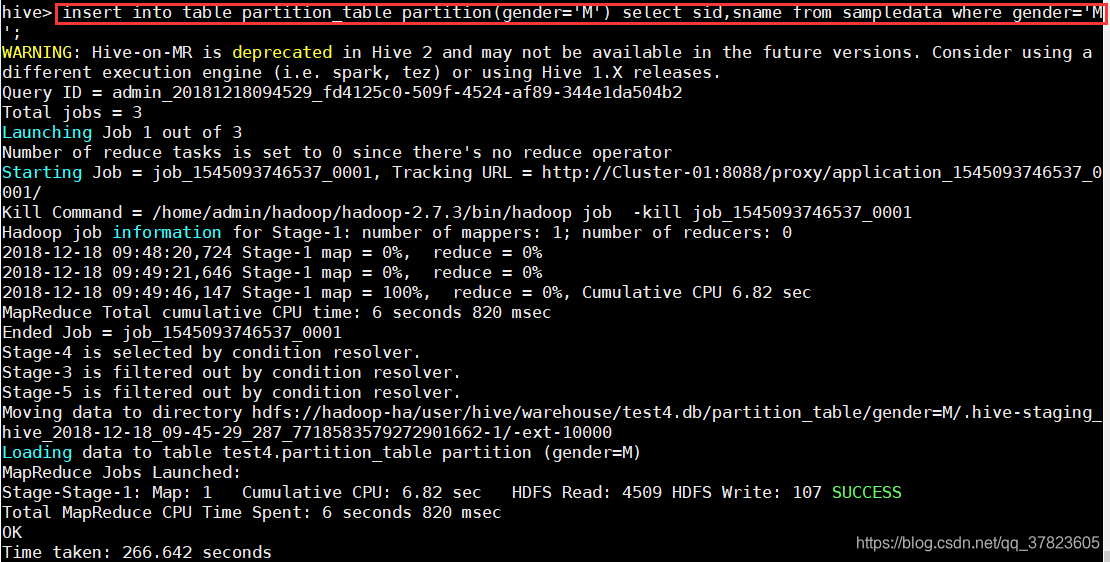
> insert into table partition table partition(gender='M')select sid,sname from sampledata where gender='M';
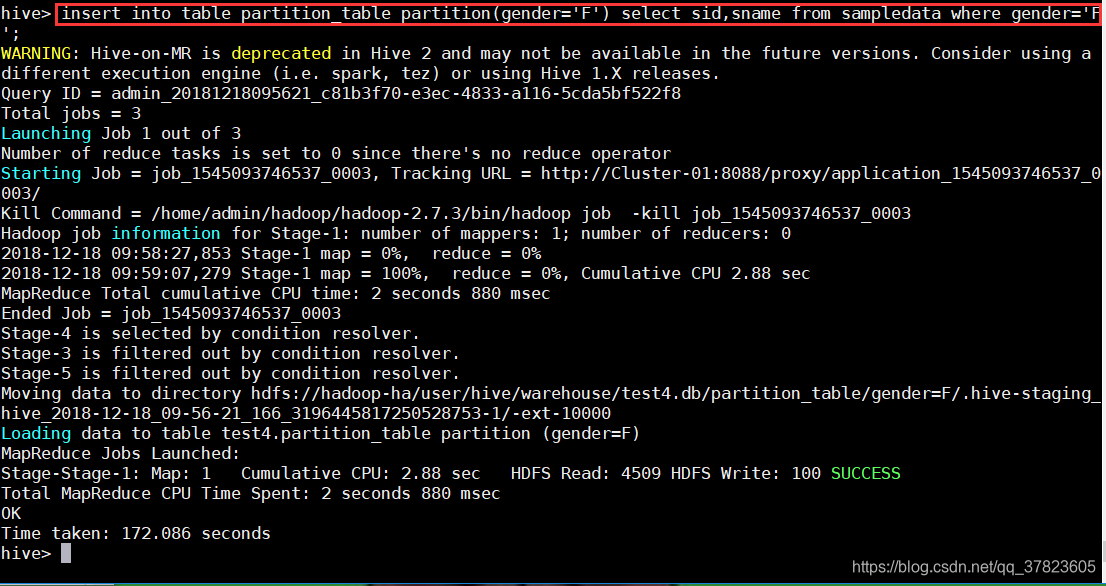
> insert into table partition table partition(gender='F') select sid, sname from sampledata where gender='F';
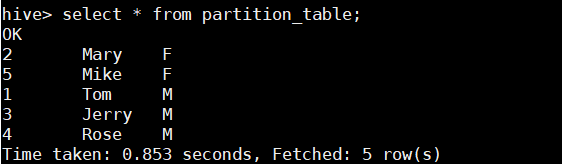
> select*from partition table;
> show partitions partition table; #查看表的分区信息
注:select查询中会扫描整个内容,会消耗大量时间。由于相当多的时候人们只关心表中的一部分数据,故建表时引入了区分概念。

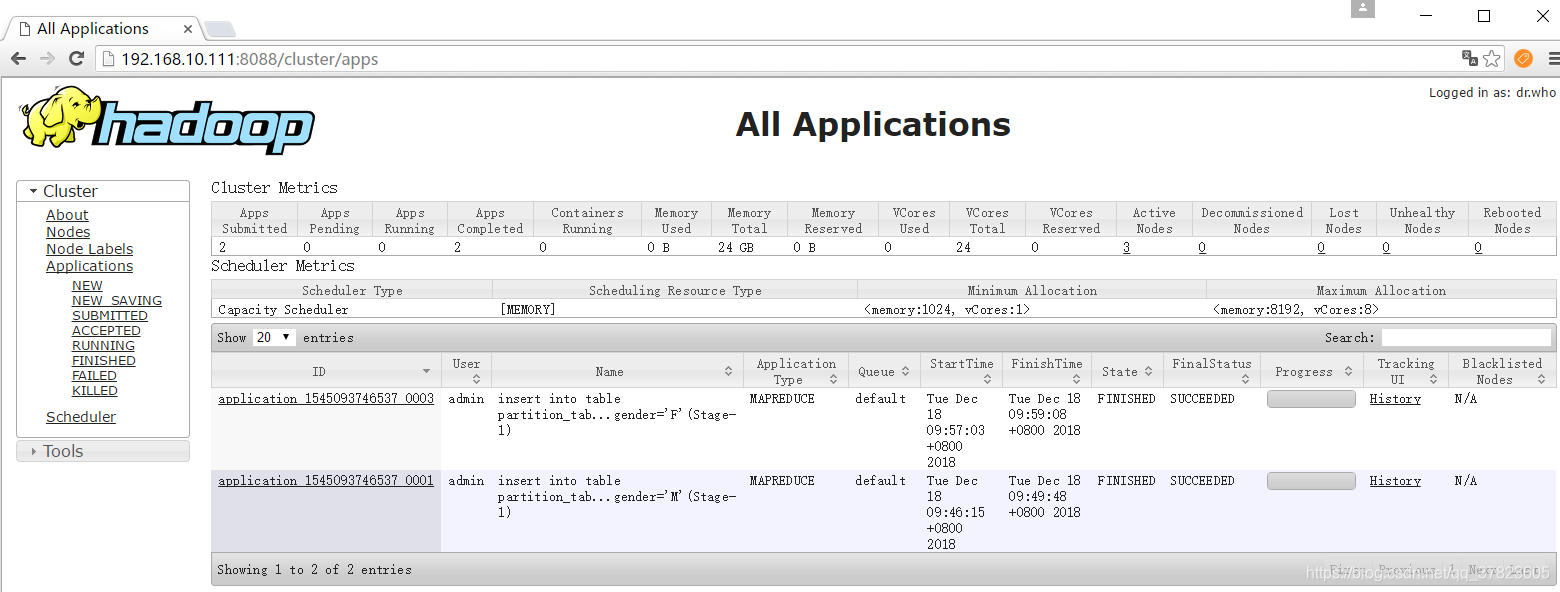
登录http://192.168.10.111:8088/cluster/apps可以查看job执行状态;
4、Hive的数据模型_外部表
外部表(External Table)
-指向已经在HDFS中存在的数据, 可以创建Partition
-它和内部表在元数据的组织上是相同的, 而实际数据的存储则有较大的差异。
-外部表只有一个过程, 加载数据和创建表同时完成, 并不会移动到数据仓库目录中, 只是与外部数据建立一个链接。 当删除一个外部表时,仅删除该链接。
- 准备几张相同数据结构的数据txt文件, 放在HDFS的/input 目录下。
- 在hive下创建一张有相同数据结构的外部表external student,location设置为HDFS的/input 目录。则external_student会自动关连/input下的文件。
- 查询外部表。
- 删除/input目录下的部分文件。
- 查询外部表。 删除的那部分文件数据不存在。
- 将删除的文件放入/input目录。
- 查询外部表。 放入的那部分文件数据重现。
(1)准备数据:
在admin家目录下分别新建studentl.txt内容:
1.Tom,M,60,80,96
2,Mary,F,11,22,33

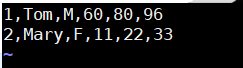
student2.txt内容:
3,Jerry,M,90,11,23
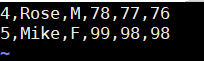
student3.txt内容:
4,Rose,M,78,77,76
5,Mike,F,99,98,98
Shdfs dfs-ls/
$ hdfs dfs-mkdir /input
将文件放入HDFS文件系统
语法:
$hdfs dfs-put localFileName hdfsFileDir
$hdfs dfs-put studentl.txt /input
$hdfs dfs -put student2.txt /input
$hdfs dfs -put student3.txt/input

$hive
>create database test5;
>use test5;
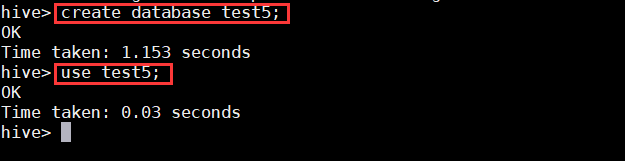
(2)创建外部表
> create table external_student(sid int,sname string,gender string,language int,math int,english int)row format delimited fields terminatedby''location'/input';

(3)查询外部表
>select*from external_student;

(4)删除HDFS上的student1.txt
$ hdfs dfs-rm /input/studentl.txt

(5)查询外部表
>select*from external_student;

(6)将student1.txt 重新放入HDFS input目录下
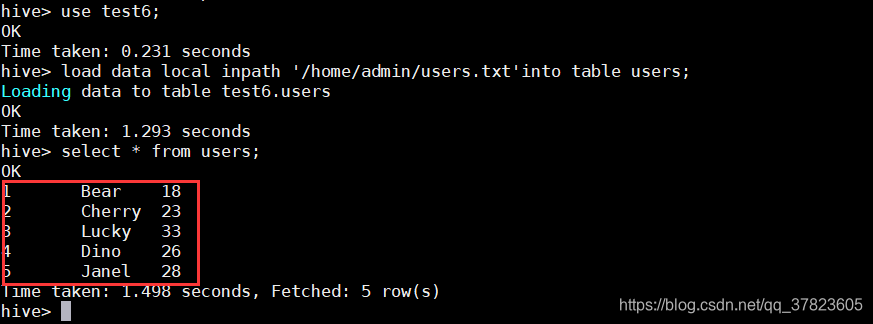
$ hdfs dfs-put student1.txt/input
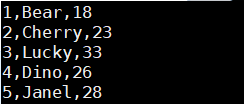
(7)查询外部表
>select*from external_student;
5、Hive的数据模型_桶表
命令:
$hive
>create database test6;
>use test6;

>create table users (sid int,sname string,age int)row delimited fields terminated by’,’;

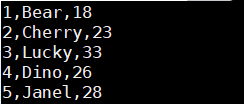
准备文本数据:
在admin用户家目录下新建users.txt内容:
1,Bear,18
2.Cherry,23
3.Lucky,33
4,Dino,26
5,Janel,28

命令:
hive> load data local inpath'/home/admin/users.txt'into table users;
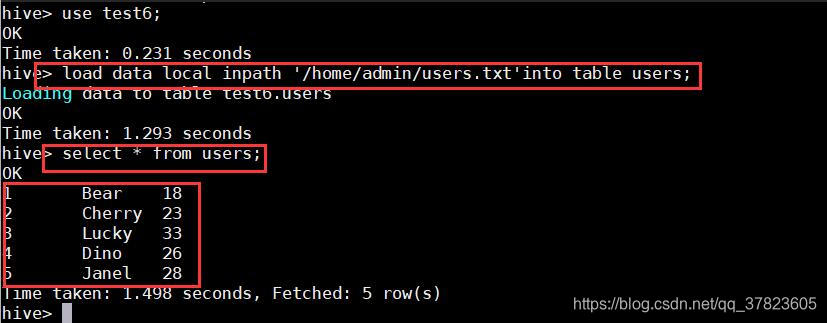
hive> create table bucket_table(sid int,sname string,age int)clustered by
(sname)into 5 buckets row format delimited fields terminated by ',;
hive>insert overwrite table bucket_table SELECT*FROM users;
hive> select*from bucket_table;
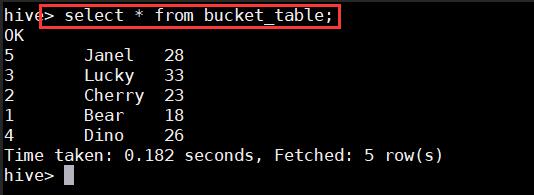
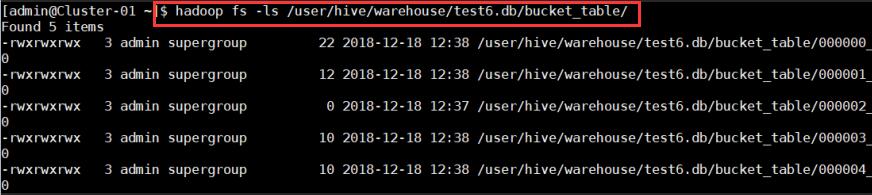
$hadoop fs-ls /user/hive/warehouse/test6.db/bucket_table/
6、Hive的数据模型_视图
语法:
创建视图
Create view viewName as select data from table where condition;
查看视图结构
Desc viewName;
查询视图
Select * from viewName;
删除视图
DROP VIEW [IF EXISTS]view_name
命令:
$hive
>create database test7;
>use test7;
a)创建一个测试表:
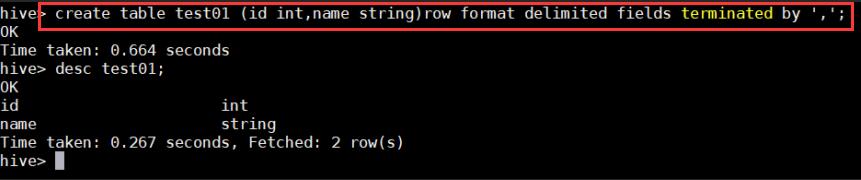
hive> create table testO1(id int,name string)row format delimited fields terminated by';
hive> desc test01;
$ vi datal.txt
1,tom
2.jack

hive>load data local inpath'/home/admin/datal.txt'overwrite into table test01;
hive> select*from test01;

b)创建一个View之前,使用explain命令查看创建View的命令是如何被Hive解释执行的;
hive>explain create view test_view(id,name_length)as select id,length(name)from test01;
hive>explain create view test_view (id,name_length)as select id,length(name)from test;

c)实际创建一个View
hive>create view test_view(id,name_length)as select id,length(name)from test01;
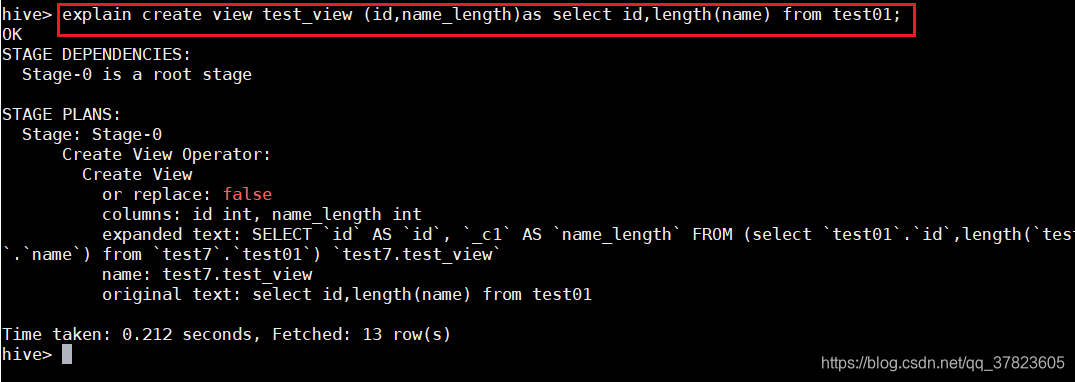
d)执行View之前,先explain查看实际被翻译后的执行过程;
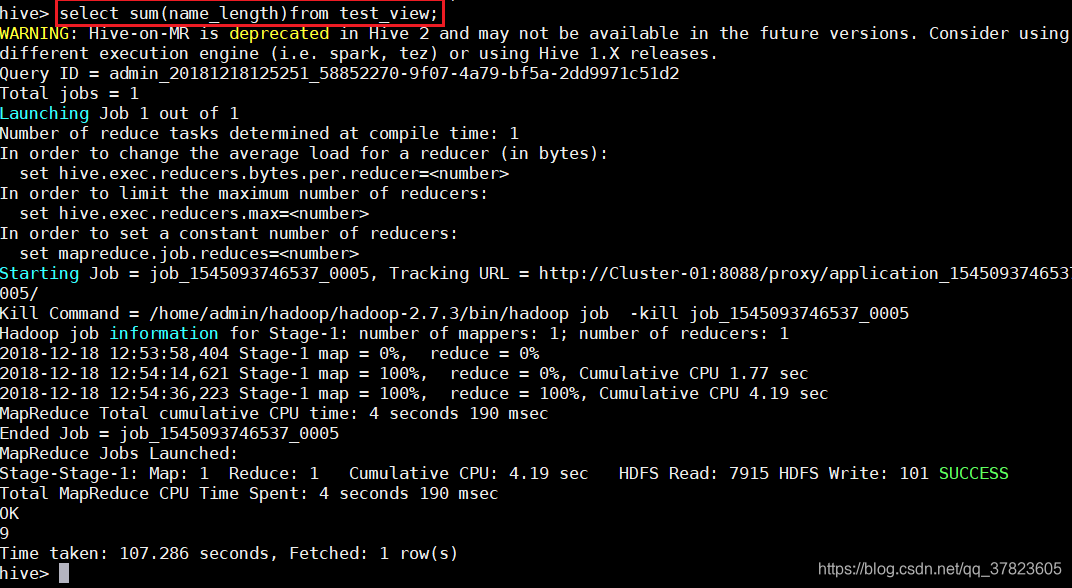
hive>explain select sum(name_length)from test_view;
hive>explain extended select sum(name_length)from test_view;
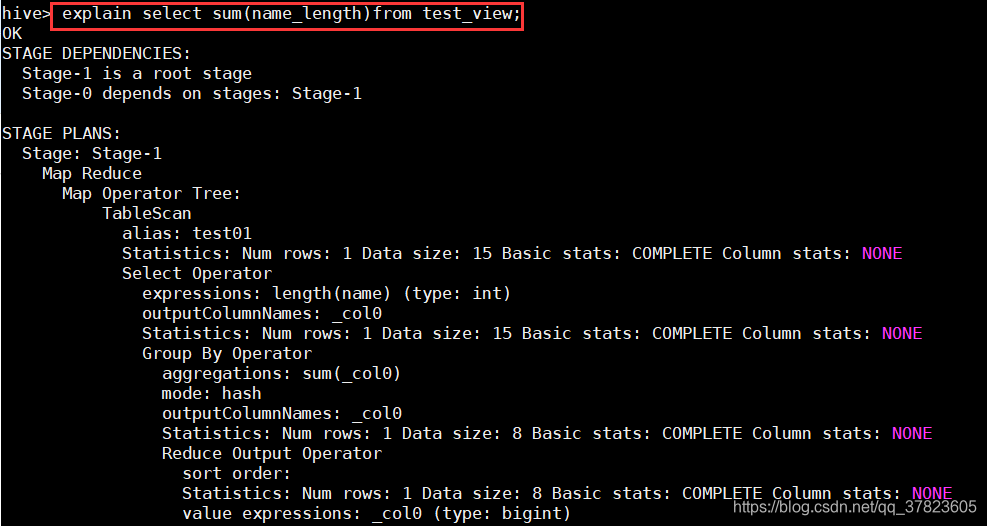
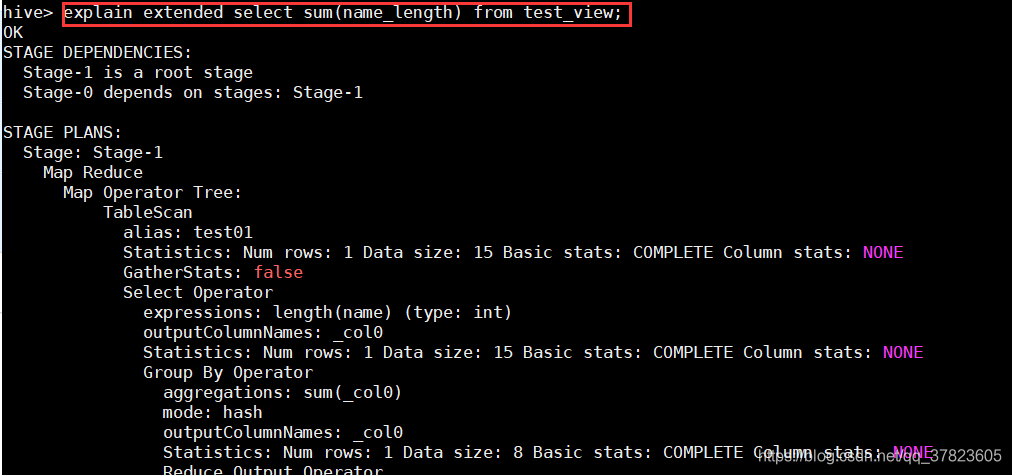
e)最后,对View执行一次查询,显示Stage-1阶段对原始表test进行了MapReduce过程;
hive>select sum(name_length)from test_view;
出现的问题与解决方案
错误1、启动hive : ls: cannot access/home/hadoop/spark-2.2.0-bin-hadoop2.6/lib/spark-assembly-*.jar: No such fileor directory问题
sxc@master ~]$ hivels: cannot access /software/spark/spark-2.2.0-bin-hadoop2.7/lib/spark-assembly-*.jar: No such file or directory17/11/27 13:12:56 WARN conf.HiveConf: HiveConf of name hive.metastore.local does not existLogging initialized using configuration in jar:file:/software/hive/apache-hive-1.2.1-bin/lib/hive-common-1.2.1.jar!/hive-log4j.properties
原因:spark升级到spark2以后,原有lib目录下的大JAR包被分散成多个小JAR包,原来的spark-assembly-*.jar已经不存在,所以hive没有办法找到这个JAR包。
解决方法:
打开hive的安装目录下的bin目录,找到hive文件
找到如下的位置
# add Spark assembly jar to the classpathif [[ -n "$SPARK_HOME" ]]thensparkAssemblyPath=`ls ${SPARK_HOME}/lib/spark-assembly-*.jar`CLASSPATH="${CLASSPATH}:${sparkAssemblyPath}"fi原因:
spark升级到spark2以后,原有lib目录下的大JAR包被分散成多个小JAR包,原来的spark-assembly-*.jar已经不存在,所以hive没有办法找到这个JAR包。
解决办法:把红色部分改为如下的样子就可以了
# add Spark assembly jar to the classpathif [[ -n "$SPARK_HOME" ]]thensparkAssemblyPath=`ls ${SPARK_HOME}/jars/*.jar`CLASSPATH="${CLASSPATH}:${sparkAssemblyPath}"fi知识拓展
HIVE和HBASE区别
1. 两者分别是什么?
Apache Hive是一个构建在Hadoop基础设施之上的数据仓库。通过Hive可以使用HQL语言查询存放在HDFS上的数据。HQL是一种类SQL语言,这种语言最终被转化为Map/Reduce. 虽然Hive提供了SQL查询功能,但是Hive不能够进行交互查询--因为它只能够在Haoop上批量的执行Hadoop。
Apache HBase是一种Key/Value系统,它运行在HDFS之上。和Hive不一样,Hbase的能够在它的数据库上实时运行,而不是运行MapReduce任务。Hive被分区为表格,表格又被进一步分割为列簇。列簇必须使用schema定义,列簇将某一类型列集合起来(列不要求schema定义)。例如,“message”列簇可能包含:“to”, ”from” “date”, “subject”, 和”body”. 每一个 key/value对在Hbase中被定义为一个cell,每一个key由row-key,列簇、列和时间戳。在Hbase中,行是key/value映射的集合,这个映射通过row-key来唯一标识。Hbase利用Hadoop的基础设施,可以利用通用的设备进行水平的扩展。
2. 两者的特点:
Hive帮助熟悉SQL的人运行MapReduce任务。因为它是JDBC兼容的,同时,它也能够和现存的SQL工具整合在一起。运行Hive查询会花费很长时间,因为它会默认遍历表中所有的数据。虽然有这样的缺点,一次遍历的数据量可以通过Hive的分区机制来控制。分区允许在数据集上运行过滤查询,这些数据集存储在不同的文件夹内,查询的时候只遍历指定文件夹(分区)中的数据。这种机制可以用来,例如,只处理在某一个时间范围内的文件,只要这些文件名中包括了时间格式。
HBase通过存储key/value来工作。它支持四种主要的操作:增加或者更新行,查看一个范围内的cell,获取指定的行,删除指定的行、列或者是列的版本。版本信息用来获取历史数据(每一行的历史数据可以被删除,然后通过Hbase compactions就可以释放出空间)。虽然HBase包括表格,但是schema仅仅被表格和列簇所要求,列不需要schema。Hbase的表格包括增加/计数功能。
3. 限制
Hive目前不支持更新操作。另外,由于hive在hadoop上运行批量操作,它需要花费很长的时间,通常是几分钟到几个小时才可以获取到查询的结果。Hive必须提供预先定义好的schema将文件和目录映射到列,并且Hive与ACID不兼容。
HBase查询是通过特定的语言来编写的,这种语言需要重新学习。类SQL的功能可以通过Apache Phonenix实现,但这是以必须提供schema为代价的。另外,Hbase也并不是兼容所有的ACID特性,虽然它支持某些特性。最后但不是最重要的--为了运行Hbase,Zookeeper是必须的,zookeeper是一个用来进行分布式协调的服务,这些服务包括配置服务,维护元信息和命名空间服务。
4. 应用场景
Hive适合用来对一段时间内的数据进行分析查询,例如,用来计算趋势或者网站的日志。Hive不应该用来进行实时的查询。因为它需要很长时间才可以返回结果。
Hbase非常适合用来进行大数据的实时查询。Facebook用Hbase进行消息和实时的分析。它也可以用来统计Facebook的连接数。
5. 总结
Hive和Hbase是两种基于Hadoop的不同技术--Hive是一种类SQL的引擎,并且运行MapReduce任务,Hbase是一种在Hadoop之上的NoSQL 的Key/vale数据库。当然,这两种工具是可以同时使用的。就像用Google来搜索,用FaceBook进行社交一样,Hive可以用来进行统计查询,HBase可以用来进行实时查询,数据也可以从Hive写到Hbase,设置再从Hbase写回Hive。
Hive环境安装之浏览器访问配置
1、下载hive-2.1.1-src.tar.gz
然后进入目录${HIVE_SRC_HOME}/hwi/web,执行打包命令:
#jar -cvf hive-hwi-1.2.2.war *
2、得到hive-hwi-1.2.2.war文件,复制到hive下的lib目录中;
3、修改hive的配置文件hive-site.xml;

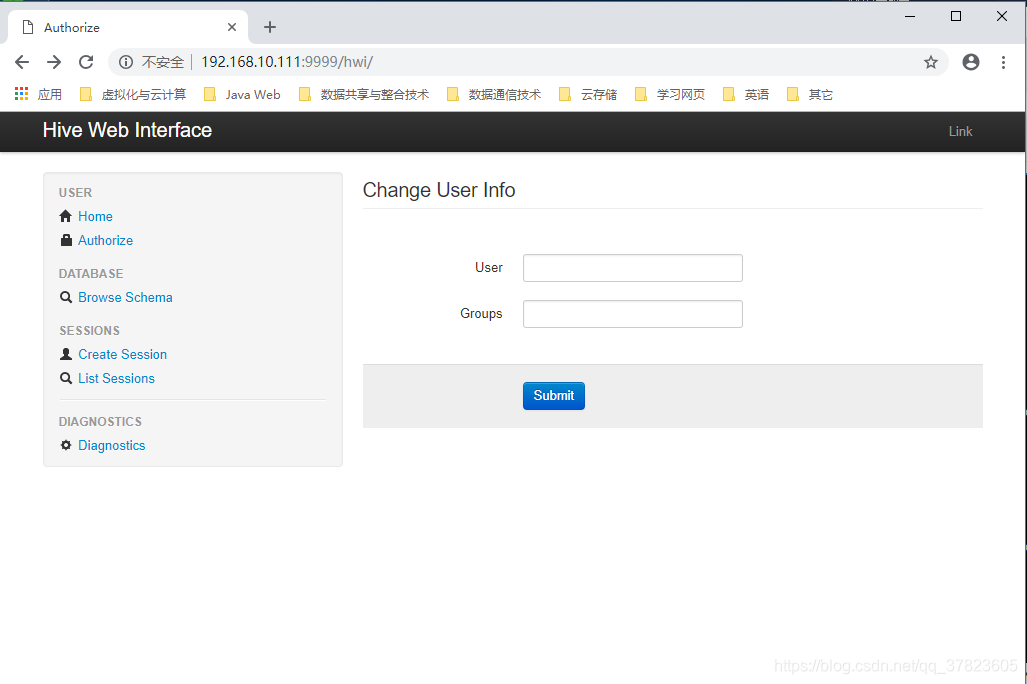
4、启动Hive的web;
命令:$hive –service hwi
5、通过web方式管理Hive;
相关文章:

【转】通过Hibernate将数据 存入oracle数据库例子
一、 Hibernate介绍 Hibernate是基于对象/关系映射(ORM,Object/Relational Mapping)的一个解决方案。ORM方案的思想是将对象模型表示的对象映射到关系型数据库中,或者反之。Hibernate目前是ORM思想在Java中最成功、最强大的实现。…

自动布局按钮排列平均分布
需要实现如下图所示的主页面布局,需要两排按钮,每一排都自动平均分布,Android的话直接用LinearLayout水平布局,并设置layout_weight即可,对于iOS,网上有使用代码实现,感觉略麻烦,我直…

maven3 手动安装本地jar到仓库
安装命令: mvn install:install-file -Dfile{Path/to/your/ojdbc.jar} -DgroupIdcom.oracle -DartifactIdojdbc6 -Dversion11.2.0 -Dpackagingjar我自己安装oracle14.jar 时命令如下:mvn install:install-file -DgroupIdcom.oracle -DartifactIdojdbc14 …
Hadoop集群的基本操作(五:Sqoop的基本操作)
实验 目的 要求 目的: 掌握ETL工具Sqoop的使用;掌握MySQL和HDFS之间的数据转换;要求: 掌握ETL工具Sqoop的使用;能够正常操作数据库、表、数据; 实 验 环 境 五台…
NEWS - InstallShield 2013 SP1发布
2013的这个国庆假期期间,InstallShield厂商Flexerasoftware(中文名:福莱睿)发布了最新版本InstallShield 2013的SP1,由于这个升级包带来一些新的技术支持和变化,所以特地给大家介绍一下: 1. 支持…
iOS 高德导航按返回后报错 解决
最近项目要添加导航功能,用了高德导航SDK,很郁闷每次从地图界面返回前一页面都报错,弄了很久,最终从高德开发者论坛找到一解决方法,可以试一下。 在导航的ViewController的viewWillDisappear中调用如下方法࿰…
Oracle的基本操作(一:子查询与常用函数)
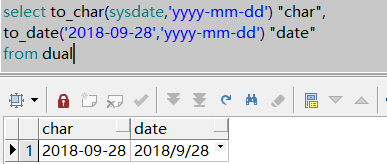
1、描述TO_CHAR和TO_DATE函数的用法。 TO_CHAR(d|n[,fmt]):把日期和数字转换为指定格式(fmt)的字符串; TO_DATE(x[,fmt]):把一个字符串一fmt格式转换为一个日期类型; 举例:select to_char(sysdate,yyyy-mm-dd) "char", to_date(…
易买网的一些增删改查
正如题目所说的一样,今天就来说说易买网中的一些增删改查,主要的功能有注册、用户管理以及商品分类等! 1.注册 1.1 注册涉及到了一个ajax远端技术,主要是用来控制注册用户在数据库中是否存在: <script>$(function(){//焦点移出表单时$("#user…

iOS后台持续定位并定时上传
最近做一个考勤APP,功能很简单,就是一直在后台运行,每隔固定时间向服务器上传一次位置信息。持续运行24小时测试,功能实现。 1.ViewController.h文件: #import <CoreLocation/CoreLocation.h>并实现CLLocationMa…
jQuery UI vs Kendo UI jQuery Mobile vs Kendo UI Mobile
jQuery UI vs Kendo UI http://jqueryuivskendoui.com/#introduction jQuery Mobile vs Kendo UI Mobile http://jqueryuivskendoui.com/#mobile-introduction Kendo UI教程 http://www.cnblogs.com/pangblog/archive/2013/09/10/3313135.html转载于:https://www.cnblogs.com/j…

Oracle的基本操作(二:存储过程)
1、编写一个存储过程,根据输入的工作类型,输入该工作的平均工资。 -- Created on 2018/9/30 by YANXUKUNcreate or replace procedure avgsal(v_job in scott.emp.job%type)isavgsal2 number;beginselect avg(sal) into avgsal2 from scott.emp where j…

web11 Struts处理表单数据
电影网站:www.aikan66.com 项目网站:www.aikan66.com 游戏网站:www.aikan66.com 图片网站:www.aikan66.com 书籍网站:www.aikan66.com 学习网站:www.aikan66.com Java网站:www.aikan66.co…
瀑布流开源这两天
想必第一眼看到 Masonery 效果的人们会和当初的我有同样的感觉,惊艳!尤其是在你双击浏览器标题栏的空白处之后,所有的区块都在默默寻找自己的位置,无论大小,就像上海虹桥火车站涌入地铁的人群。和技术实现无关…
iOS网络请求总结
*说明:文章中HTTP为宏定义的http地址,事例通过app_login.action的接口,通过传递policyNum、plateNum、phoneNum三个参数进行登录操作 一、方法1: Foundation框架 NSURLConnection (1)同步请求:同…
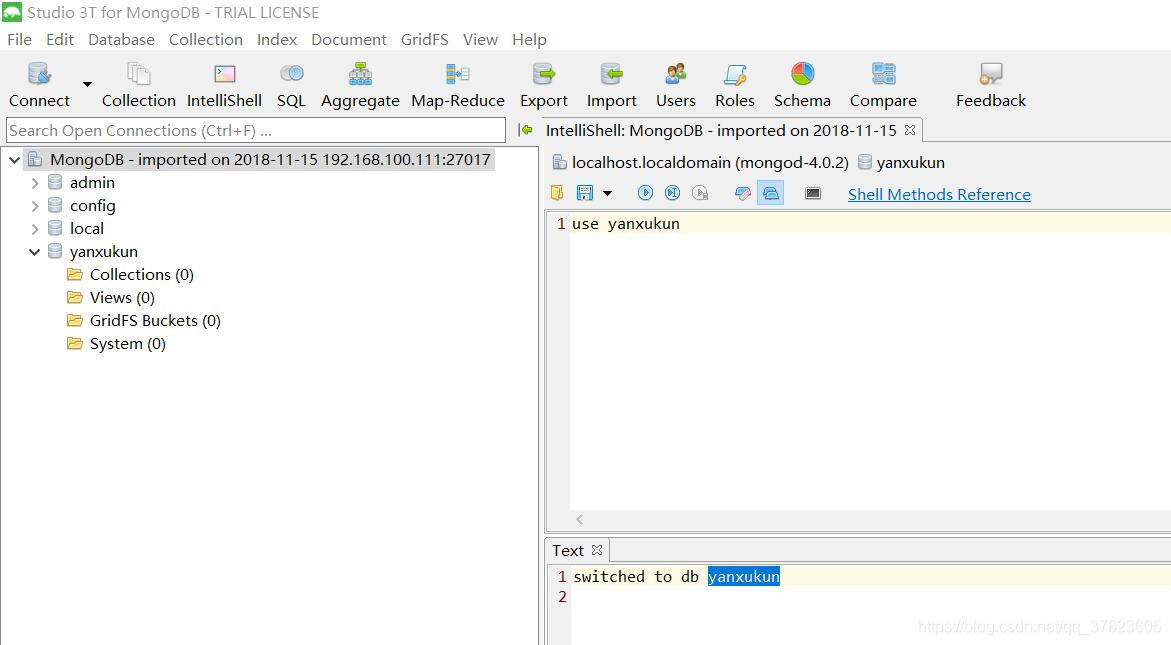
MongoDB数据库(一:基本操作)
1、创建名称为自己姓名拼音缩写的数据库; 2、创建名为姓名拼音缩写col的集合,如dugncol; 3、删除2中的集合,重新创建格式如dugncolnew的集合; 4、在3创建的集合中,插入10条文档数据,要求分别插入…
NYOJ--811--变态最大值
/*Name: NYOJ--811--变态最大值Author: shen_渊 Date: 17/04/17 15:49Description: 看到博客上这道题浏览量最高,原来的代码就看不下去了 o(╯□╰)o */#include<cstring> #include<iostream> #include<algorithm> using namespace std; struct…
扩展的八皇后问题
百度百科:八皇后问题是一个古老而著名的问题,是回溯算法的典型案例。该问题是国际西洋棋棋手马克斯贝瑟尔于1848年提出:在8X8格的国际象棋上摆放八个皇后,使其不能互相攻击,即任意两个皇后都不能处于同一行、同一列或同…
C++ 常用函数方法
/* * 拆分字符串 * 参数: * strData 字符串 * split 分隔符 * 返回: * 返回动态数组std::vector<std::string> ,记得要delete 内存 */ std::vector<std::string>* GetStringArray(char* strData,char* split)…
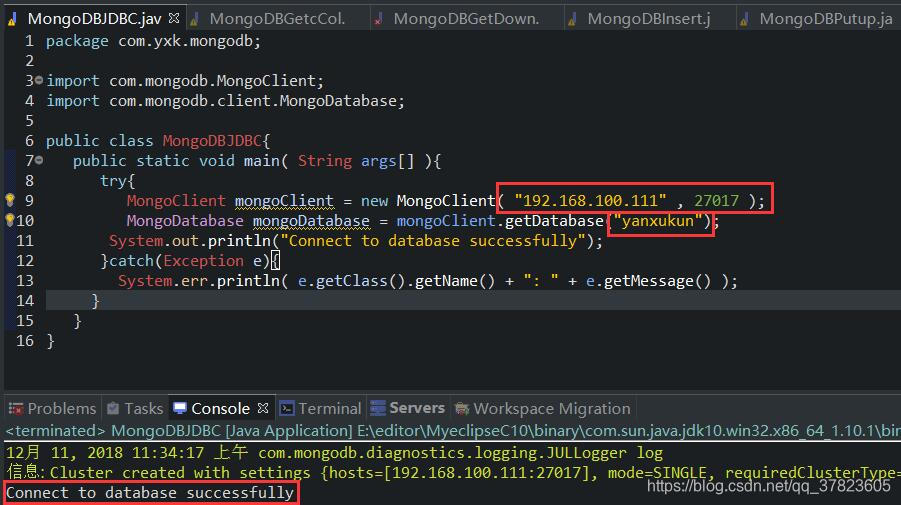
MongoDB数据库(二:高级操作)
练习一、完成使用Java代码连接MOngoDB,创建集合,获取集合,插入文档,检 索所有文档,更新文档,删除第一个文档。 a)连接MOngoDB b)创建集合 c)获取集合 d)插入文档 e)检索所有文档 f)更新文档 g)…
将XML转为HTML
文章参考:http://dreamweaver.abang.com/od/html/a/xml2html3.htm http://www.w3school.com.cn/xml/xml_xsl.asp ParseXML2HTML.xsl:代码如下 1 <?xml version"1.0" encoding"utf-8"?> 2 <xsl:styleshee…

Linux运维相关目录
Linux——相关运维配置文档目录 tcp 三次握手yum 配置你对linux了解多少,Linux 系统结构详解!Linux LAMP环境搭建Centos6.7安装Apache2.4Mysql5.6Apache2.4Linux搭建DNS服务器Nginx概念及基础安装--详细讲解深入NginxNginx的继续深入(日志轮询…
iOS8底部弹出日期选择或自定义选择器的方法
本文需要实现的日期选择器和自定义选择器效果如下: 在iOS8之前,可以通过UIActionSheet来实现,在iOS8之后,可以通过UIAlertController实现,UIAlertController的官方解释如下: A UIAlertController object d…

HDFS_API基本应用
实验 目的 要求 目的: 了解HDFS文件系统;掌握HDFS的架构及核心组件的职能;掌握HDFS数据的读写操作;HDFS常用操作(Shell。Java API)了解Hadoop2.0中HDFS相关的新特性 实 验 环 境 Java jdk 1.8&…
Docker 清理命令集锦
杀死所有正在运行的容器 复制代码代码如下:docker kill $(docker ps -a -q)删除所有已经停止的容器 复制代码代码如下:docker rm $(docker ps -a -q)删除所有未打 dangling 标签的镜像 复制代码代码如下:docker rmi $(docker images -q -f danglingtrue)删除所有镜像 复制代码代…
CentOS 6.4下编译安装MySQL 5.6.14
概述: CentOS 6.4下通过yum安装的MySQL是5.1版的,比较老,所以就想通过源代码安装高版本的5.6.14。 正文: 一:卸载旧版本 使用下面的命令检查是否安装有MySQL Server rpm -qa | grep mysql 有的话通过下面的命令来卸载掉…
iOS实现图片自动轮播展示
一、需要实现的效果如下图1,首页图片自动轮播展示,其中图片从网络异步加载,加载过程用风火轮显示加载中,如图2。 本文参考了以下博客文章: http://www.haodaima.net/art/2687144 http://www.cnblogs.com/xiaobaizhu/a…

Hadoop_MapReduce的基本应用
实验 目的 要求 目的: 了解MapReduce掌握MapReduce编程模型掌握MapReduce常见核心API编程MapReduce开发常用功能 实 验 环 境 Java jdk 1.8;apache-maven-3.6.0;Myeclipse C10;Hadoop集群;练习内容 任务一&…
Android源码编译过程之九鼎开发板
1 build_kernel()2 {3 # 进入源码顶层目录4 cd ${BS_DIR_KERNEL} || return 15 # 编译配置文件6 make ${BS_CONFIG_KERNEL} ARCHarm CROSS_COMPILE${BS_CROSS_TOOLCHAIN_KERNEL} || return 17 # 编译内核uImage(arm架构、交…
eaccelerator 完全手册:配置、控制、API接口
安装官方有很详细的文档 转自 http://www.enjoyphp.com/2010/eaccelerator-manual/ 配置选项 eaccelerator.shm_size指定 eAccelerator 能够使用的共享内存数量,单位: MB. “0″ 代表操作系统默认。默认值为 “0″。 eaccelerator.cache_dir用户磁盘缓存的目录。eAc…
iOS解决键盘阻挡输入框
解决思路:有时用户编辑输入框时,键盘会遮挡输入框,这时候只要将视图整体上移键盘的高度即可,编辑完成后再将视图下移键盘的高度恢复正常显示。 【方法1】 实现UITextField代理UITextFieldDelegat的两个方法textFieldShouldBegin…