Hadoop集群搭建(六:HBase的安装配置)
实验 目的 要求 | 目的: 1、HBase的高可用完全分布模式的安装和验证 要求:
| ||||||||||||||||||
实 验 环 境 实 验 环 境 |
软件版本: 选用HBase的1.2.3版本,软件包名hbase-1.2.3-bin.tar.gz 集群规划: * HBase有主节点和Region节点2类服务节点,高可用完全分布模式中需要满足主节点有备用的基本要求,所以需要两台或以上的主机作为主节点,而完全分布模式中需要满足Region有备份和数据处理能够分布并行的基本要求,所以要求两台或以上的主机作为Region节点,具体规划如下:
|
实验内容
步骤一:HBase基本安装配置
注:1、该项的所有操作步骤使用专门用于集群的用户admin进行;
2、此项只在一台主机操作,然后在下一步骤进行同步安装与配置;
1、首先,HBase软件包“hbase-1.2.3-bin.tar.gz”我们已经上传到用户家目录的“setups”目录下。然后进行解压和环境变量设置;
命令:
$mkdir ~/hbase
$cd ~/hbase
$tar -xzf ~/setups/hbase-1.2.3-bin.tar.gz

2、配置Hadoop相关环境变量;
命令:
$vi ~/.bash_prolife
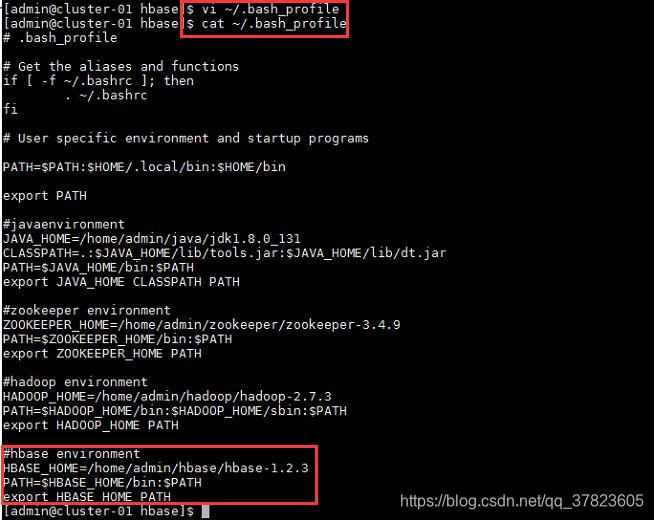
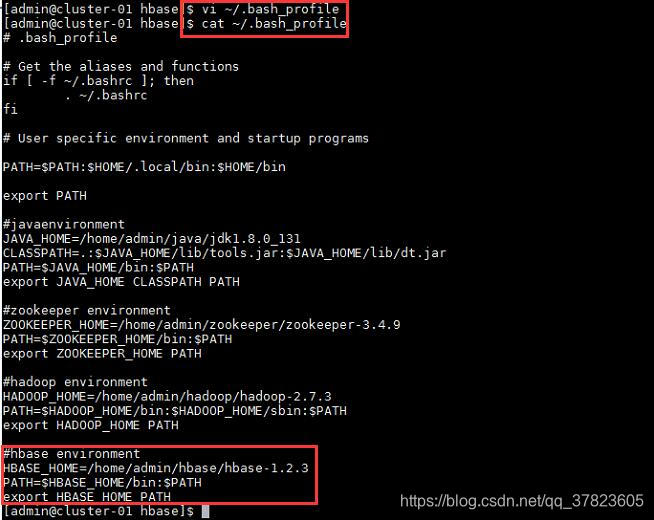
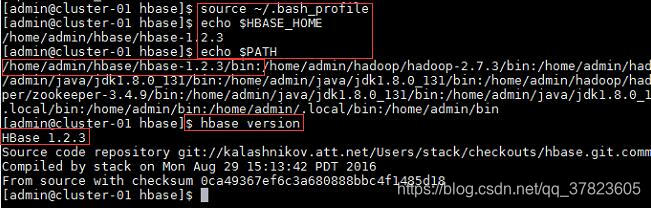
2、使新配置的环境变量立即生效,查看新添加和修改的环境变量是否设置成功,以及环境变量是否正确,验证Hadoop的安装配置是否成功;
命令:
$source ~/.bash_profile
$echo $HBASE_HOME
$echo $PATH
$hbase version
步骤二:HBase高可用完全分布模式配置;
注:该项的所有操作步骤使用专门用于集群的用户admin进行;
1、进入Hbase相关文件的目录,分别创建Hbase的元数据文件目录“tmp”和HDFS的日志文件目录“logs”、进入Hbase的配置文件所在目录;
命令:
$cd ~/hbase
$mkdir tmp logs
$cd ~/hbase/hbase-1.2.3/conf

2、进入Hbase的配置文件所在目录,对配置文件进行修改。
![]()
a)找到配置项“JAVA_HOME”所在行,将其改为以下内容:
export
JAVA_HOME=/home/admin/java/jdk1.8.0_131
![]()
b)找到配置项“HBASE_CLASSPATH”,该项用于指定Hadoop的配置文件所在的路径,将其值改为一下内容:
export
HBASE_CLASSPATH=/home/admin/Hadoop/Hadoop-2.7.3/etc/Hadoop
![]()
c)找到配置项“HBASE_LOG_DIR”,该项用于指定HBase的日志文件的本地存放路径,将其值改为以下内容:
export
HBASE_LOG_DIR=/home/admin/hbase/logs
![]()
d)找到配置项“HBASE_MANAGES_ZK”,该项用于关闭HBase自带的Zookeeper组件,将其值改为一下内容:
export
HBASE_MANAGES_ZK=false
![]()
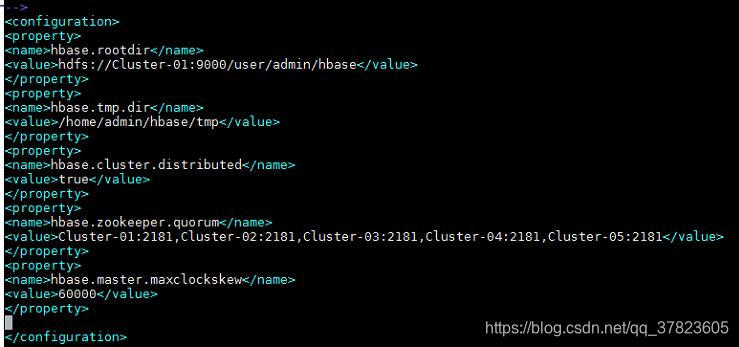
3、对配置文件hbase-site.xml进行修改,找到标签“<configuration>”所在位置,在其中添加如下红色部分的内容:
<configuration><property><name>hbase.rootdir</name><value>hdfs://Cluster-01:9000/user/admin/hbase</value></property><property><name>hbase.tmp.dir</name><value>/home/admin/hbase/tmp</value></property><property><name>hbase.cluster.distributed</name><value>true</value></property><property><name>hbase.zookeeper.quorum</name><value>Cluster-01:2181,Cluster-02:2181,Cluster-03:2181,Cluster-04:2181,Cluster-05:2181</value></property><property><name>hbase.master.maxclockskew</name><value>60000</value></property></configuration>![]()
4、对配置文件regionservers进行修改,删除文件中原有的所有内容,然后添加集群中所有数据节点的主机名,每行一个主机的主机名,配置格式如下:
Cluster-03
Cluster-04
Cluster-05

5、创建配置文件“backup-masters”,并对配置文件进行修改。添加集群中所有备用节点的主机名,每行一个主机的主机名,配置格式如下:
Cluster-02

步骤三:同步安装配置以及系统时间;
注:该项的所有操作不受使用准们用于集群的用户admin进行。
1、将“hbase”目录和“.bash_profile”文件发给集群中所有主机,发送目标用户为集群专用用户admin,即当前与登录用户同名的用户,发送目标路径为“/home/admin”,即集群专用用户admin的家目录。
![]()
![]()
![]()
![]()
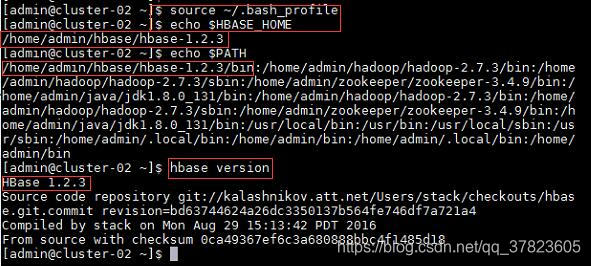
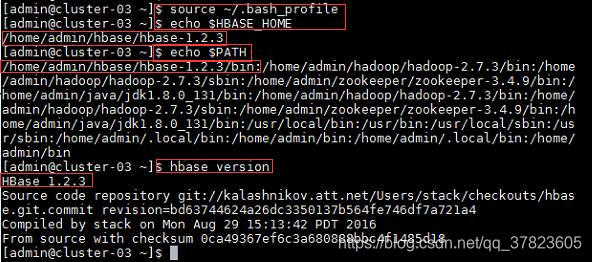
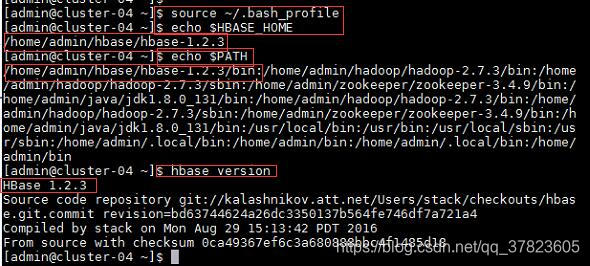
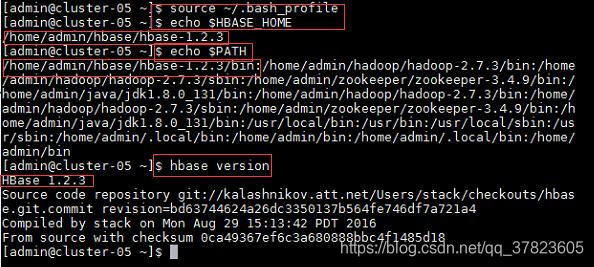
2、使新配置的环境变量立即生效,查看新添加和修改的环境变量是否设置成功,以及环境变量是否正确,验证Hbase的安装配置是否成功;
命令:
$source ~/.bash_profile
$echo $HBASE_HOME
$echo $PATH
$hbase version
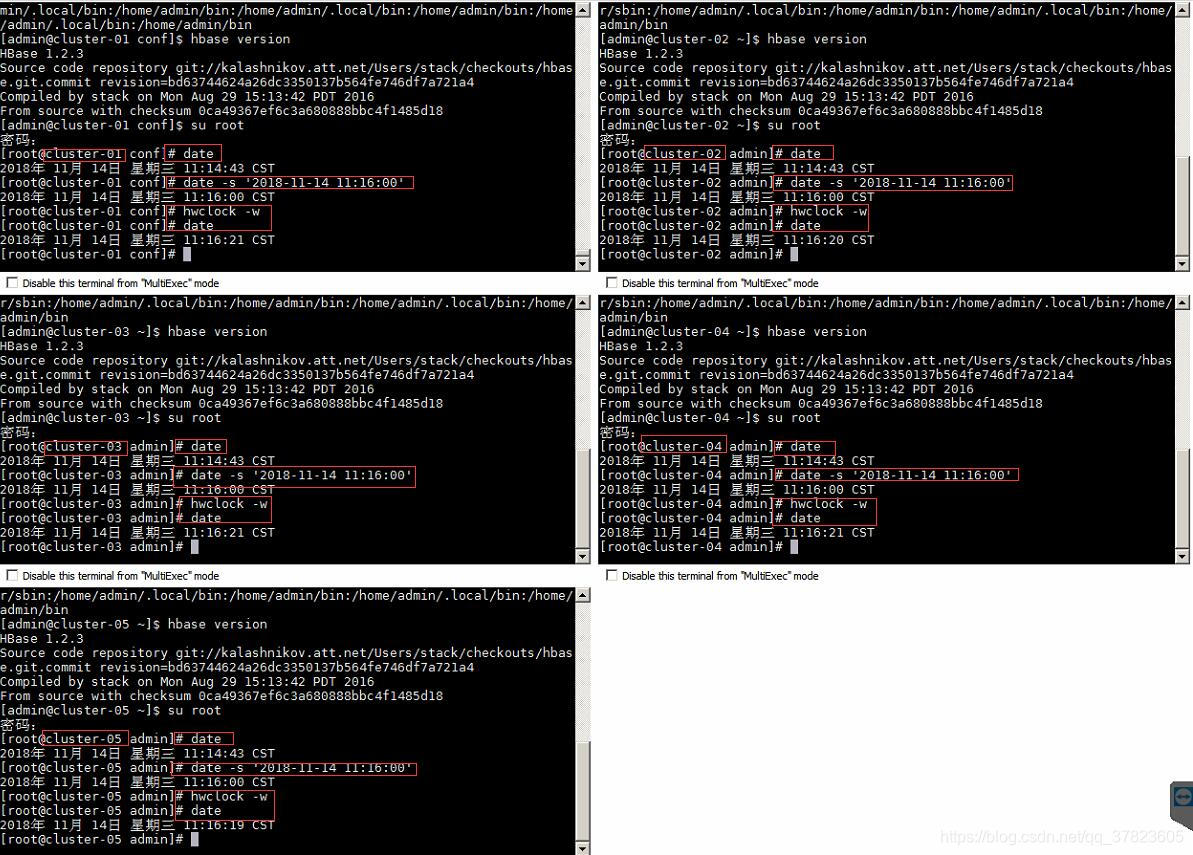
3、系统时间配置;
注:时间同步项的所有操作步骤需要使用root用户进行。
在集群中所有主机上使用命令“date -s ‘yyyy-MM-dd HH:mm:ss(年-月-日 时:分:秒)’”对系统时间进行设置,并使用命令“hwclock -w”将设置的时间同步到硬件时钟。
*该操作尽量在所有主机上同时进行,从而保证主机之间的时间误差值设定的“hbase.master.maxclockskew”范围内。
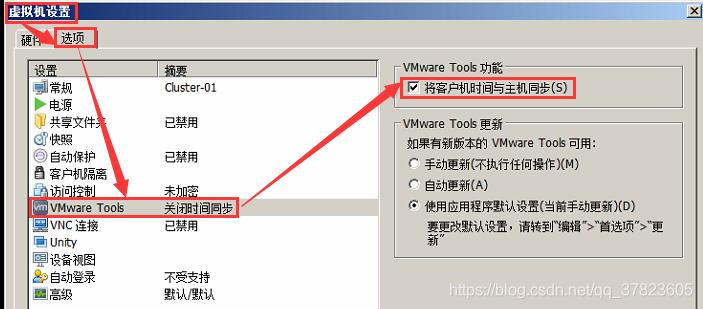
*如果是在VMware Workstation Pro虚拟平台上安装的,那么需要开启时间同步。选中虚拟机节点->右键->设置->选项,开启时间同步。
步骤四:HBase高可用完全分布模式启动和验证;
注:*该项的所有操作步骤使用专门用于集群的用户admin进行。
*启动HBase集群之前首先确保Zookeeper集群已被开启状态。(实验5台)Zookeeper的启动需要分别在每个计算机的节点上手动启动,如果家目录下执行启动报错则需要进入Zookeeper/bin目录执行启动命令。
*启动HBase集群之前首先确保Hadoop集群已被开启状态。(实验5台)Hadoop只需要在主节点执行启动命令。
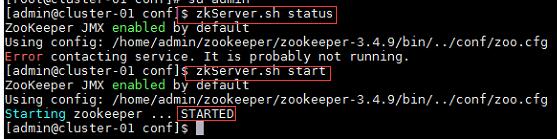
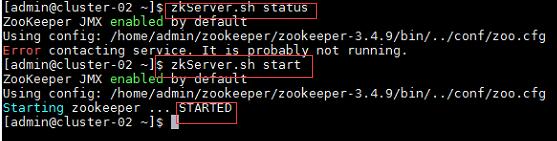
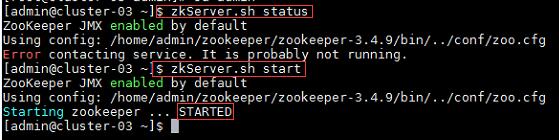
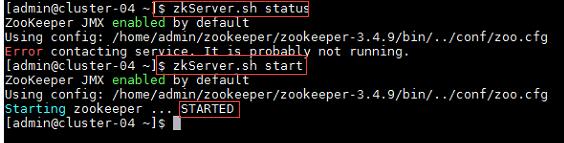
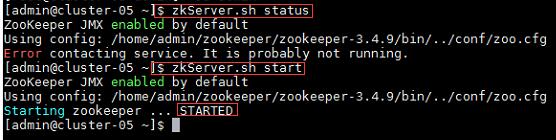
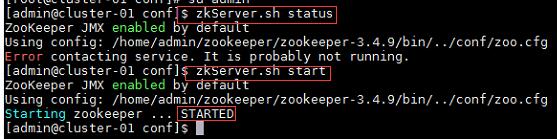
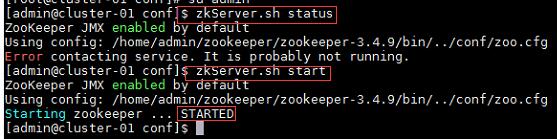
1、启动Zookeeper集群:
命令:
$zkServer.sh status //查看Zookeeper状态
$zkServer.sh start //启动Zookeeper
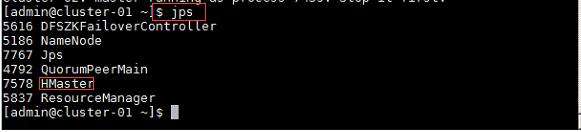
2、在主节点使用此命令,查看java进程信息,若有名为“NameNode”、“ResourceManager”、“DataNode”和“NodeManager”这几个进程,则表示Hadoop集群的主节点及数据节点启动成功。
命令:
$jps //查看进程状态
$start-all.sh //启动Hadoop
$yarn-daemon.sh start resourcemanager
主节点及备用主节点:


通信节点:



3、确定Hadoop集群已启动状态,然后再主节点使用此命令,启动HBase集群;
命令:
$start-hbase.sh

4、如果每项启动出错,那么一次检查相应的配置文件和环境变量。
$source ~/.bash_profile
$echo $ZOOKEEPER_HOME
$echo $PATH
$echo $HADOOP_HOME
$echo $PATH
$echo $HBASE_HOME
$echo $PATH
5、使用命令“ssh 目标主机名或IP地址”远程登录到集群中所有Region节点主机,在Region节点使用命令“jps”查看java进程信息,若有名为“HRegionServer”的进程,则表示HBase集群的Region节点启动成功。




6、验证使用HBase;
命令:
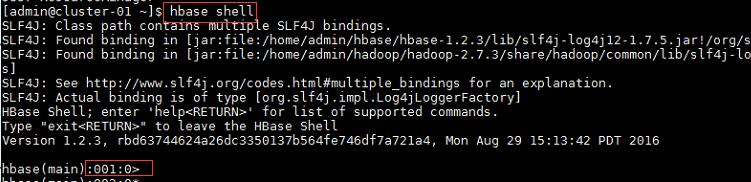
$hbase shell //进入HBase的控制台
>create ‘tab1’,‘id’,‘name’ //创建表
>exit //退出控制台

出现的问题与解决方案
排错一:
出现问题:Zookeeper启动不正常;
原 因:查看Zookeeper日志,发现错误信息:
ClientCnxn$SendThread@966] - Opening socket connection to server slave1. Will not attempt to authenticate using SASL
通过百度搜索发现集群环境中有个别主机通信不正常。
解决方案:排查每台主机的网络配置,并全部重新启动。
排错二:
出现问题:启动hbase,Error: JAVA_HOME is not set
原 因:配置hbase-env.sh时JAVA_HOME配置有误
解决方案:进入目录“~/hbase/hbase-1.2.3/conf”编辑文件hbase-env.sh
找到配置项“JAVA_HOME”所在行,将其修改为以下内容:
export
JAVA_HOME=/home/admin/java/jdk1.8.0_131
![]()
知识拓展
HBase是什么?
Apache HBase是运行在Hadoop集群上的数据库。为了实现更好的可扩展性(scalability),HBase放松了对ACID(数据库的原子性,一致性,隔离性和持久性)的要求。因此HBase并不是一个传统的关系型数据库。另外,与关系型数据库不同的是,存储在HBase中的数据也不需要遵守某种严格的集合格式,这使得HBase是用来存储结构不严格的数据的理想工具。
HBase在大数据应用的架构中应用非常广泛。但是基于其与关系型数据库迥异的设计模式,实现这些应用也与基于关系型数据库来实现非常不同。下文将会对比HBase和关系型数据库,并浅析HBase的特性。
2、关系型数据库与HBase的对比。
2.1、先了解一下关系型数据库的优势和缺点。
- 关系型数据库提供了标准的数据持久性模型
- SQL语言是事实上的数据操作标准语言
- 关系型数据库内置了并发数据操作的管理机制
- 关系型数据库提供全面的数据操作工具
2.2、HBase的高效,分布式,可扩展性。
由于HBase在设计上不支持关系和Join这样的概念,需要一起查询的数据就被存在一起。因此也就避免了关系型数据库的一些局限性。下图表现了HBase和关系型数据库在数据存储模型上的不同。
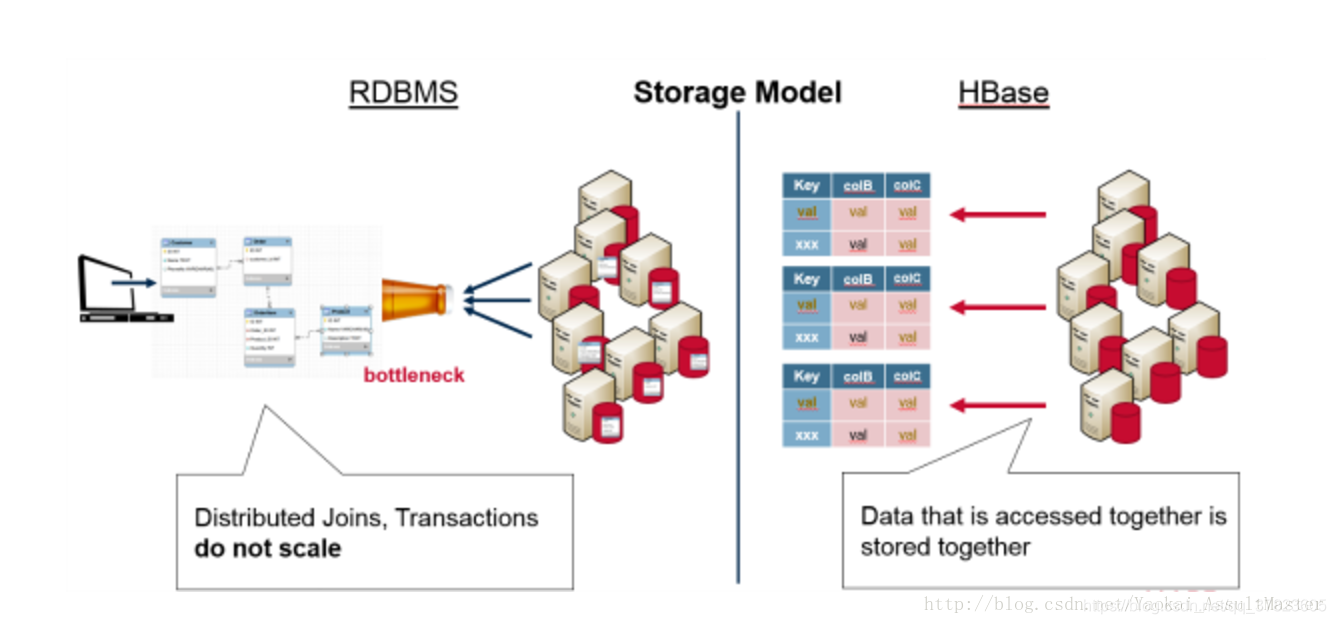
由于HBase将所有需要一起查询到数据存储在一起这一特性,HBase集群就自然能够根据key来组织数据。在水平分割的时候,key值的范围就可以被用来分割数据。每一个服务器存储全部数据的一个子集。同时分布式的数据还可以被同时访问。这大大增强了HBase的可扩展性。HBase实际上是Google Big Table的一个实现。Big Table是Google提出的一个用来存储大规模数据的一个分布式系统。
HBase是基于Column family data store的理念设计的:每一行根据一个row key索引。也就是我们用来查询的主键。同时每一行中有若干column family。每一个column family中有若干相关的column。如下图所示。
HBase是一种Hadoop数据库,经常被描述为一种稀疏的,分布式的,持久化的,多维有序映射,它基于行键、列键和时间戳建立索引,是一个可以随机访问的存储和检索数据的平台。HBase不限制存储的数据的种类,允许动态的、灵活的数据模型,不用SQL语言,也不强调数据之间的关系。HBase被设计成在一个服务器集群上运行,可以相应地横向扩展。
3、HBase的基本操作。
a)Java友好提供了全面的java客户端库;
b)HBase中所有数据都是作为原始数据,使用数组的形式存储;
c)行健是唯一标识符,类似数据库的主键;
d)表中确定一个单元的坐标是[rowkey,cloumn fanmily,column qualifier];
e)5个基本命令来访问HBase;Get(读)、Put(写)、Delete(删除)、Scan(扫描)、Increment(递增);
f)HFile是存储文件,对应列族,一个列族可以有多少HFile文件,但是一个HFile不能存多个列族的数据;
g)写的操作会写入预写式日志(WAL)和称为MemStore的内存写入缓冲区,当两者都确认写入后才认为写的动作成功完成;
h)不建议禁用WAL,禁用后RegionServer故障时会导致数据丢失;
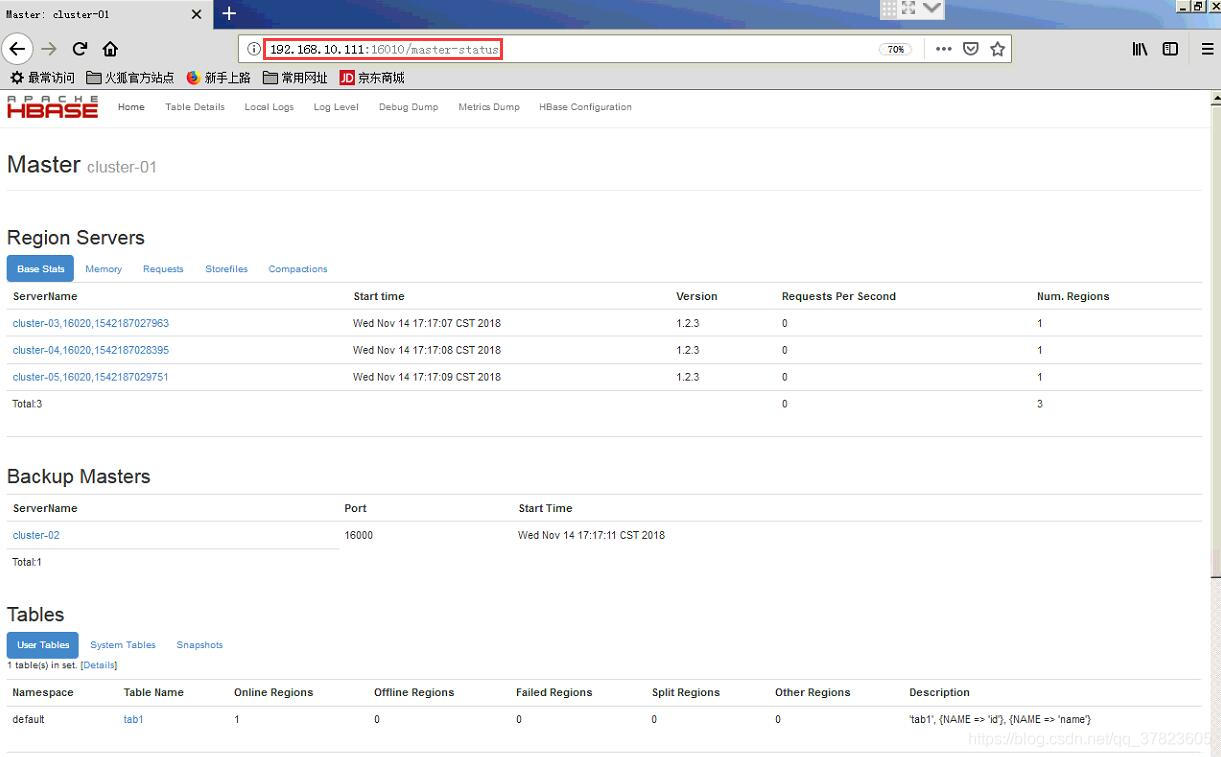
4、使用浏览器访问https://192.168.100.111:16010
相关文章:

架构师的第一阶段:准备做(Pre-Architecture)
上节说到,做任何事情都可以分为三个阶段:准备做、做、做好。本文,就将进入第一个阶段,准备做阶段。 Pre-Architecture:准备架构 准备架构阶段,最最重要的是弄清楚要做什么东西,即掌握用户需求。…
iOS动画系列之八:使用CAShapeLayer绘画动态流量图
这篇文章通过使用CAShapeLayer和UIBezierPath来画出一个动态显示剩余流量的小动画。 最终实现的效果如下: Paste_Image.png 动态效果图: shapeLayerAni.gif 1. CAShapeLayer 实际中,能够用CALayer完成的任务是比较少的,如果使用这…
hiho_1139_二分+bfs搜索
题目 给定N个点和M条边,从点1出发,到达点T。寻找路径上边的个数小于等于K的路径,求出所有满足条件的路径中最长边长度的最小值。 题目链接:二分 最小化最大值,考虑采用二分搜索。对所有的边长进行排序,二分&#x…

Hadoop集群搭建(七:MySQL的安装配置)
实验 目的 要求 目的: 1、掌握MySQL在集群平台中的安装 要求: 完成MySQL的集群版的安装;MySQL集群的相关服务进程能够正常启动;MySQL集群的SQL服务能够作为系统服务开机自动启动;MySQL客户端能够远程连接MySQL集群的…

如何在VMware虚拟机上安装Linux操作系统(Ubuntu)
作为初学者想变为计算机大牛非一朝一夕,但掌握基本的计算机操作和常识却也不是多么难的事情。所以作为一名工科男,为了把握住接近女神的机会,也为了避免当白痴,学会装系统吧!of course为避免把自己的电脑作为牺牲品&am…

cf #363 b
B. One Bombtime limit per test1 secondmemory limit per test256 megabytesinputstandard inputoutputstandard outputYou are given a description of a depot. It is a rectangular checkered field of n m size. Each cell in a field can be empty (".") or…
swift-video-generator:图片加音频生成视频及多视频合并库及演示
阅读 80收藏 92017-11-07原文链接:github.com腾讯云学生优惠套餐,985高校学习云计算的主力机型,2G2核,1M带宽系统盘(Linux 50G/Windows 50G)免费赠送50GB对象存储空间还有.cn域名一年使用权!不要…

Hadoop集群搭建(八:Hive的安装配置)
实验 目的 要求 目的: (1)掌握数据仓库工具Hive的安装和配置; 要求: 完成Hive工具的安装和配置;Hive工具能够正常启动运行;Hive控制台命令能够正常使用;能够正常操作数据库、表、…
iOS 富文本编辑工厂, 让书写更简便.
由于最近常用富文本, 在编辑一个富文本时需要操作很多的属性, 书写起来很不方便. 所以我将这些相关属性整理并使用链式方式将它简化了一下. 效果请看下面Demo. 项目工程 实现很简单, 我嘴太笨, 这里就不介绍了, 如有兴趣直接看源码吧. 同时可以通过cocoapods来使用它. pod SJAt…
ORACLE 数据的逻辑组成
数据块(block)Oracle数据块(Data Block)是一组连续的操作系统块。分配数据库块大小是在Oracle数据库创建时设置的,数据块是Oracle读写的基本单位。数据块的大小一般是操作系统块大小的整数倍,这样可以避免不…
Java 的zip压缩和解压缩
Java 的zip压缩和解压缩好久没有来这写东西了,今天中秋节,有个东西想拿出来分享,一来是工作中遇到的问题,一来是和csdn问候一下,下面就分享一个Java中的zip压缩技术,代码实现比较简单,代码如下:…
Hadoop集群搭建(九:各服务的启动)
1、查看Zookeeper服务状态,若集群中只有一个"leader"节点, 其余的均为"follower"节点,则集群的工作状态正常 $zkServer.sh status 2、在集群中所有主机上使用此命令,启动Zookeeper服务 $zkServer.sh start…
iOS 后台下载及管理库
说起下载第一个想起的就是ASI。一年前接手的新项目是核心功能是视频相关业务,在修改和解决视频下载相关的问题的时候让我体会到了ASI的下载的强大。后来新需求需要视频后台下载,使用NSURLSession的时候,更加深刻的体会到了ASI的强大好用。后来…
(转) 使用Speech SDK 5.1文字转音频
下载地址: http://www.microsoft.com/en-us/download/details.aspx?id10121 SeppchSDK51.exe 语音合成引擎 SpeechSDK51LangPack.exe 支持日语和简体中文需要这个支持。 SpeechSDK51MSM.exe 如果要将引擎作为产品的一部分发布需要这个。 Sp5TTintXP.exe XP下Mike和…
IE8下面的line-height的bug
当line-height小于正常值时,超出的部分将被剪裁掉转载于:https://www.cnblogs.com/jsingleegg/p/js_ie8.html

Hadoop集群的基本操作(一:HDFS操作及MapReduce程序练习)
实验 目的 要求 目的: 理解HDFS在Hadoop体系结构中的角色;熟练使用HDFS操作常用的Shell命令;了解Hadoop集群MapReduce程序的简单使用;(上传WordCount的jar执行程序;使用WordCount进行MapReduce计算&#x…
iOS实现动态区域裁剪图片
阅读 249收藏 322017-11-29原文链接:github.com想自己动手搭建一个 Discuz 论坛?试试腾讯云上实验室吧https://cloud.tencent.com/developer/labs 裁剪图片功能在很多上传图片的场景里都需要用到,一方面应用服务器可能对图片的尺寸大小有限制…
每天CookBook之JavaScript-062
鼠标进入事件鼠标离开事件<!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>062</title> </head> <body> <div><img src"001" alt"001"><img src…
spring + Quartz定时任务配置
<bean id"exportBatchFileTask" class"com.ydcn.pts.task.ExportBatchFileTask"></bean><bean id"readBatchFileTask" class"com.ydcn.pts.task.ReadBatchFileResultTask"></bean><!-- 生成开卡档…
Hadoop集群的基本操作(二:HBase的基本操作)
实验 目的 要求 目的: 1、HBase的基本应用 要求: 完成HBase的高可用完全分布模式的安装;HBase的相关服务进程能够正常的启动;HBase控制台能够正常使用;表创建、数据查询等数据库操作能够正常进行; …
Abaqus用户子程序umat的学习
Abaqus用户子程序umat的学习 说明:在文件中,!后面的内容为注释内容。本文为学习心得,很多注释是自己摸索得到。如有不正确的地方,敬请指正。 ! —————————————————————————— ! 1、为何需要…
PHP:isset()-检测变量是否被设置
isset()-检测变量是否被设置 bool isset(mixed $var [, mixed $...]),检查变量是否被设置,并且不是NULL。var,要检测的变量,...其他变量,允许有多个变量。 返回值:如果var存在并且不是NULL,则返回TRUE&…
Android通过ShareSDK实现新浪微博分享
ShareSDK社会化分享的官方说明:是中国最大的APP内分享服务提供商,ShareSDK社会化分享,全面支持微信,微博,QQ空间,来往,易信,Facebook等国内外40个平台。 ShareSDK官方网站ÿ…

Hadoop集群的基本操作(三:HBase的基本操作)
实验 目的 要求 目的: MySQL数据库的基本命令;MySQL数据库中使用SQL语句;MySQL数据库中数据库,表,数据的操作;要求: 完成MySQL的集群版的安装;MySQL集群的相关服务进程能够正常启…
iOS通过Plist保存离线调试日志
最近需要测试APP在iPhone没连接USB情况下定位时间间隔的情况,固把nslog的日志信息保存成本地Plist文件,以便测试结束后查阅运行时的日志。 一、新建一个保存日志的方法,参数为每次定位成功的时间(作为key),…
关于变量名前面加m的问题
为什么很多人写代码会在变量名前面加一个小写的m? 上大学那会儿就对这个问题感到很好奇。于是网上到处搜,有人说是member的意思。于是后来一直就这么认为。 最近在读Android源码,发现很多系统变量命名时都加了m,而有的变量又没有加…
谷歌推出情境感知API
在 Google I/O 2016 大会上,我们宣布推出新的 Google Awareness API,让您的应用可以利用快照和围栏智能应对用户情境,并且仅需占用极少量的系统资源。 所有开发者均可以通过 Google Play 服务获取 Google Awareness API。 利用 7 种不同类型的…
Hadoop集群的基本操作(四:Hive的基本操作)
实验 目的 要求 目的: (1)掌握数据仓库工具Hive的使用; 要求: 掌握数据仓库Hive的使用;能够正常操作数据库、表、数据; 实 验 环 境 五台独立PC式虚…
【转】通过Hibernate将数据 存入oracle数据库例子
一、 Hibernate介绍 Hibernate是基于对象/关系映射(ORM,Object/Relational Mapping)的一个解决方案。ORM方案的思想是将对象模型表示的对象映射到关系型数据库中,或者反之。Hibernate目前是ORM思想在Java中最成功、最强大的实现。…

自动布局按钮排列平均分布
需要实现如下图所示的主页面布局,需要两排按钮,每一排都自动平均分布,Android的话直接用LinearLayout水平布局,并设置layout_weight即可,对于iOS,网上有使用代码实现,感觉略麻烦,我直…