node.js中模块_在Node.js中需要模块:您需要知道的一切
node.js中模块
by Samer Buna
通过Samer Buna
在Node.js中需要模块:您需要知道的一切 (Requiring modules in Node.js: Everything you need to know)
Update: This article is now part of my book “Node.js Beyond The Basics”.
更新:这篇文章现在是我的书《超越基础的Node.js》的一部分。
Update: This article is now part of my book “Node.js Beyond The Basics”.
更新:这篇文章现在是我的书《超越基础的Node.js》的一部分。
Read the updated version of this content and more about Node at jscomplete.com/node-beyond-basics.
在jscomplete.com/node-beyond-basics中阅读此内容的更新版本以及有关Node的更多信息。
Node uses two core modules for managing module dependencies:
Node使用两个核心模块来管理模块依赖性:
The
requiremodule, which appears to be available on the global scope — no need torequire('require').require模块似乎在全局范围内可用-无需require('require')。The
modulemodule, which also appears to be available on the global scope — no need torequire('module').module模块,似乎也可以在全局范围内使用-不需要require('module')。
You can think of the require module as the command and the module module as the organizer of all required modules.
您可以将require模块视为命令,并将module模块视为所有必需模块的组织者。
Requiring a module in Node isn’t that complicated of a concept.
在Node中需要一个模块并不是一个复杂的概念。
const config = require('/path/to/file');The main object exported by the require module is a function (as used in the above example). When Node invokes that require() function with a local file path as the function’s only argument, Node goes through the following sequence of steps:
require模块导出的主要对象是一个函数(如上例中所使用)。 当Node使用本地文件路径作为该函数的唯一参数调用require()函数时,Node将执行以下步骤序列:
Resolving: To find the absolute path of the file.
解决 :查找文件的绝对路径。
Loading: To determine the type of the file content.
加载 :确定文件内容的类型。
Wrapping: To give the file its private scope. This is what makes both the
requireandmoduleobjects local to every file we require.包装 :为文件提供专用范围。 这就是使
require和module对象都位于我们需要的每个文件本地的原因。Evaluating: This is what the VM eventually does with the loaded code.
评估 :这是VM最终对加载的代码执行的操作。
Caching: So that when we require this file again, we don’t go over all the steps another time.
缓存 :这样,当我们再次需要此文件时,就不必再次执行所有步骤。
In this article, I’ll attempt to explain with examples these different stages and how they affect the way we write modules in Node.
在本文中,我将尝试通过示例解释这些不同的阶段,以及它们如何影响我们在Node中编写模块的方式。
Let me first create a directory to host all the examples using my terminal:
首先让我创建一个目录,以使用我的终端托管所有示例:
mkdir ~/learn-node && cd ~/learn-nodeAll the commands in the rest of this article will be run from within ~/learn-node.
本文其余部分中的所有命令都将从~/learn-node内部运行。
解析本地路径 (Resolving a local path)
Let me introduce you to the module object. You can check it out in a simple REPL session:
让我向您介绍module对象。 您可以在一个简单的REPL会话中检出它:
~/learn-node $ node
> module
Module {id: '<repl>',exports: {},parent: undefined,filename: null,loaded: false,children: [],paths: [ ... ] }Every module object gets an id property to identify it. This id is usually the full path to the file, but in a REPL session it’s simply <repl>.
每个模块对象都有一个id属性来标识它。 该id通常是文件的完整路径,但是在REPL会话中,它只是<repl>.
Node modules have a one-to-one relation with files on the file-system. We require a module by loading the content of a file into memory.
节点模块与文件系统上的文件具有一对一的关系。 通过将文件内容加载到内存中,我们需要一个模块。
However, since Node allows many ways to require a file (for example, with a relative path or a pre-configured path), before we can load the content of a file into the memory we need to find the absolute location of that file.
但是,由于Node允许使用多种方式来请求文件(例如,具有相对路径或预先配置的路径),因此在将文件的内容加载到内存中之前,我们需要找到该文件的绝对位置。
When we require a 'find-me' module, without specifying a path:
当我们需要一个'find-me'模块而不指定路径时:
require('find-me');Node will look for find-me.js in all the paths specified by module.paths — in order.
节点将按find-me.js在module.paths指定的所有路径中find-me.js 。
~/learn-node $ node
> module.paths
[ '/Users/samer/learn-node/repl/node_modules','/Users/samer/learn-node/node_modules','/Users/samer/node_modules','/Users/node_modules','/node_modules','/Users/samer/.node_modules','/Users/samer/.node_libraries','/usr/local/Cellar/node/7.7.1/lib/node' ]The paths list is basically a list of node_modules directories under every directory from the current directory to the root directory. It also includes a few legacy directories whose use is not recommended.
路径列表基本上是从当前目录到根目录的每个目录下的node_modules目录的列表。 它还包括一些不建议使用的旧目录。
If Node can’t find find-me.js in any of these paths, it will throw a “cannot find module error.”
如果Node在上述任何路径中都找不到find-me.js ,则会抛出“找不到模块错误”。
~/learn-node $ node
> require('find-me')
Error: Cannot find module 'find-me'at Function.Module._resolveFilename (module.js:470:15)at Function.Module._load (module.js:418:25)at Module.require (module.js:498:17)at require (internal/module.js:20:19)at repl:1:1at ContextifyScript.Script.runInThisContext (vm.js:23:33)at REPLServer.defaultEval (repl.js:336:29)at bound (domain.js:280:14)at REPLServer.runBound [as eval] (domain.js:293:12)at REPLServer.onLine (repl.js:533:10)If you now create a local node_modules directory and put a find-me.js in there, the require('find-me') line will find it.
如果现在创建一个本地node_modules目录并在其中放置find-me.js ,则require('find-me')行将找到它。
~/learn-node $ mkdir node_modules ~/learn-node $ echo "console.log('I am not lost');" > node_modules/find-me.js~/learn-node $ node
> require('find-me');
I am not lost
{}
>If another find-me.js file existed in any of the other paths, for example, if we have a node_modules directory under the home directory and we have a different find-me.js file in there:
如果其他任何路径中都存在另一个find-me.js文件,例如,如果我们在node_modules目录下有一个node_modules目录,并且其中还有一个不同的find-me.js文件:
$ mkdir ~/node_modules
$ echo "console.log('I am the root of all problems');" > ~/node_modules/find-me.jsWhen we require('find-me') from within the learn-node directory — which has its own node_modules/find-me.js, the find-me.js file under the home directory will not be loaded at all:
当我们从learn-node目录(具有自己的node_modules/find-me.js require('find-me') ,将根本不会加载主目录下的find-me.js文件:
~/learn-node $ node
> require('find-me')
I am not lost
{}
>If we remove the local node_modules directory under ~/learn-node and try to require find-me one more time, the file under the home’s node_modules directory would be used:
如果我们删除~/learn-node下的本地node_modules目录,并尝试再次要求find-me ,则将使用主目录下的node_modules目录下的文件:
~/learn-node $ rm -r node_modules/
~/learn-node $ node
> require('find-me')
I am the root of all problems
{}
>需要一个文件夹 (Requiring a folder)
Modules don’t have to be files. We can also create a find-me folder under node_modules and place an index.js file in there. The same require('find-me') line will use that folder’s index.js file:
模块不必是文件。 我们还可以在node_modules下创建一个find-me文件夹,并将index.js文件放置在其中。 相同的require('find-me')行将使用该文件夹的index.js文件:
~/learn-node $ mkdir -p node_modules/find-me~/learn-node $ echo "console.log('Found again.');" > node_modules/find-me/index.js~/learn-node $ node
> require('find-me');
Found again.
{}
>Note how it ignored the home directory’s node_modules path again since we have a local one now.
注意,由于我们现在有了本地目录,因此它如何再次忽略主目录的node_modules路径。
An index.js file will be used by default when we require a folder, but we can control what file name to start with under the folder using the main property in package.json. For example, to make the require('find-me') line resolve to a different file under the find-me folder, all we need to do is add a package.json file in there and specify which file should be used to resolve this folder:
当我们需要一个文件夹时,默认情况下将使用index.js文件,但是我们可以使用package.json的main属性来控制以该文件夹下的文件名开头。 例如,要使require('find-me')行解析为find-me文件夹下的其他文件,我们要做的就是在其中添加package.json文件并指定应使用哪个文件来解析该文件夹:
~/learn-node $ echo "console.log('I rule');" > node_modules/find-me/start.js~/learn-node $ echo '{ "name": "find-me-folder", "main": "start.js" }' > node_modules/find-me/package.json~/learn-node $ node
> require('find-me');
I rule
{}
>require.resolve (require.resolve)
If you want to only resolve the module and not execute it, you can use the require.resolve function. This behaves exactly the same as the main require function, but does not load the file. It will still throw an error if the file does not exist and it will return the full path to the file when found.
如果您只想解析模块而不执行它,则可以使用require.resolve函数。 它的行为与main require函数完全相同,但是不会加载文件。 如果文件不存在,它将仍然引发错误,并且将在找到文件时返回文件的完整路径。
> require.resolve('find-me');
'/Users/samer/learn-node/node_modules/find-me/start.js'
> require.resolve('not-there');
Error: Cannot find module 'not-there'at Function.Module._resolveFilename (module.js:470:15)at Function.resolve (internal/module.js:27:19)at repl:1:9at ContextifyScript.Script.runInThisContext (vm.js:23:33)at REPLServer.defaultEval (repl.js:336:29)at bound (domain.js:280:14)at REPLServer.runBound [as eval] (domain.js:293:12)at REPLServer.onLine (repl.js:533:10)at emitOne (events.js:101:20)at REPLServer.emit (events.js:191:7)
>This can be used, for example, to check whether an optional package is installed or not and only use it when it’s available.
例如,它可用于检查是否安装了可选软件包,并且仅在可用时使用它。
相对路径和绝对路径 (Relative and absolute paths)
Besides resolving modules from within the node_modules directories, we can also place the module anywhere we want and require it with either relative paths (./ and ../) or with absolute paths starting with /.
除了从node_modules目录中解析模块之外,我们还可以将模块放置在所需的任何位置,并使用相对路径( ./和../ )或以/开头的绝对路径来使用。
If, for example, the find-me.js file was under a lib folder instead of the node_modules folder, we can require it with:
例如,如果find-me.js文件位于lib文件夹而不是node_modules文件夹下,则可以使用以下命令进行请求:
require('./lib/find-me');文件之间的父子关系 (Parent-child relation between files)
Create a lib/util.js file and add a console.log line there to identify it. Also, console.log the module object itself:
创建一个lib/util.js文件,并在其中添加console.log行以进行标识。 另外, console.log module对象本身:
~/learn-node $ mkdir lib
~/learn-node $ echo "console.log('In util', module);" > lib/util.jsDo the same for an index.js file, which is what we’ll be executing with the node command. Make this index.js file require lib/util.js:
对index.js文件执行相同的操作,这是我们将使用node命令执行的操作。 使此index.js文件需要lib/util.js :
~/learn-node $ echo "console.log('In index', module); require('./lib/util');" > index.jsNow execute the index.js file with node:
现在,使用node执行index.js文件:
~/learn-node $ node index.js
In index Module {id: '.',exports: {},parent: null,filename: '/Users/samer/learn-node/index.js',loaded: false,children: [],paths: [ ... ] }
In util Module {id: '/Users/samer/learn-node/lib/util.js',exports: {},parent:Module {id: '.',exports: {},parent: null,filename: '/Users/samer/learn-node/index.js',loaded: false,children: [ [Circular] ],paths: [...] },filename: '/Users/samer/learn-node/lib/util.js',loaded: false,children: [],paths: [...] }Note how the main index module (id: '.') is now listed as the parent for the lib/util module. However, the lib/util module was not listed as a child of the index module. Instead, we have the [Circular] value there because this is a circular reference. If Node prints the lib/util module object, it will go into an infinite loop. That’s why it simply replaces the lib/util reference with [Circular].
请注意,现在如何将主index模块(id: '.')列为lib/util模块的父级。 但是, lib/util模块未作为index模块的子级列出。 相反,我们在此处具有[Circular]值,因为这是一个循环引用。 如果Node打印lib/util模块对象,它将进入无限循环。 这就是为什么它简单地将lib/util引用替换为[Circular] 。
More importantly now, what happens if the lib/util module required the main index module? This is where we get into what’s known as the circular modular dependency, which is allowed in Node.
现在更重要的是,如果lib/util模块需要主index模块,该怎么办? 这是我们进入所谓的循环模块化依赖关系的地方,Node中允许这样做。
To understand it better, let’s first understand a few other concepts on the module object.
为了更好地理解它,让我们首先了解模块对象上的其他一些概念。
导出,module.exports和模块的同步加载 (exports, module.exports, and synchronous loading of modules)
In any module, exports is a special object. If you’ve noticed above, every time we’ve printed a module object, it had an exports property which has been an empty object so far. We can add any attribute to this special exports object. For example, let’s export an id attribute for index.js and lib/util.js:
在任何模块中,导出都是一个特殊的对象。 如果您在上面注意到,每次我们打印模块对象时,它都有一个exports属性,到目前为止,该属性一直是一个空对象。 我们可以将任何属性添加到此特殊导出对象。 例如,让我们导出index.js和lib/util.js的id属性:
// Add the following line at the top of lib/util.js
exports.id = 'lib/util';// Add the following line at the top of index.js
exports.id = 'index';When we now execute index.js, we’ll see these attributes as managed on each file’s module object:
现在执行index.js ,我们将在每个文件的module对象上看到这些属性的管理:
~/learn-node $ node index.js
In index Module {id: '.',exports: { id: 'index' },loaded: false,... }
In util Module {id: '/Users/samer/learn-node/lib/util.js',exports: { id: 'lib/util' },parent:Module {id: '.',exports: { id: 'index' },loaded: false,... },loaded: false,... }I’ve removed some attributes in the above output to keep it brief, but note how the exports object now has the attributes we defined in each module. You can put as many attributes as you want on that exports object, and you can actually change the whole object to be something else. For example, to change the exports object to be a function instead of an object, we do the following:
为了使内容简短,我删除了上面输出中的一些属性,但请注意, exports对象现在具有我们在每个模块中定义的属性。 您可以在该导出对象上放置任意数量的属性,并且实际上可以将整个对象更改为其他对象。 例如,要将出口对象更改为函数而不是对象,请执行以下操作:
// Add the following line in index.js before the console.logmodule.exports = function() {};When you run index.js now, you’ll see how the exports object is a function:
现在运行index.js ,您将看到exports对象是一个函数:
~/learn-node $ node index.js
In index Module {id: '.',exports: [Function],loaded: false,... }Note how we did not do exports = function() {} to make the exports object into a function. We can’t actually do that because the exports variable inside each module is just a reference to module.exports which manages the exported properties. When we reassign the exports variable, that reference is lost and we would be introducing a new variable instead of changing the module.exports object.
请注意,我们没有执行exports = function() {}来使exports对象变成一个函数。 我们不能真正做到这一点,因为exports每一个模块内变量只是一个参考module.exports其管理输出特性。 当我们重新分配exports变量时,该引用将丢失,我们将引入一个新变量,而不是更改module.exports对象。
The module.exports object in every module is what the require function returns when we require that module. For example, change the require('./lib/util') line in index.js into:
当我们需要该模块时, require函数将返回每个模块中的module.exports对象。 例如,将index.js的require('./lib/util')行更改为:
const UTIL = require('./lib/util');console.log('UTIL:', UTIL);The above will capture the properties exported in lib/util into the UTIL constant. When we run index.js now, the very last line will output:
上面将捕获在lib/util导出的属性到UTIL常量。 现在运行index.js ,将输出最后一行:
UTIL: { id: 'lib/util' }Let’s also talk about the loaded attribute on every module. So far, every time we printed a module object, we saw a loaded attribute on that object with a value of false.
我们还讨论每个模块上的loaded属性。 到目前为止,每次打印模块对象时,都会在该对象上看到一个值为false已loaded属性。
The module module uses the loaded attribute to track which modules have been loaded (true value) and which modules are still being loaded (false value). We can, for example, see the index.js module fully loaded if we print its module object on the next cycle of the event loop using a setImmediate call:
module模块使用loaded属性来跟踪已加载的模块(真值)和仍在加载的模块(假值)。 例如,如果我们使用setImmediate调用在事件循环的下一个周期打印其module对象,则可以看到index.js模块已满载:
// In index.js
setImmediate(() => {console.log('The index.js module object is now loaded!', module)
});The output of that would be:
其输出将是:
The index.js module object is now loaded! Module {id: '.',exports: [Function],parent: null,filename: '/Users/samer/learn-node/index.js',loaded: true,children:[ Module {id: '/Users/samer/learn-node/lib/util.js',exports: [Object],parent: [Circular],filename: '/Users/samer/learn-node/lib/util.js',loaded: true,children: [],paths: [Object] } ],paths:[ '/Users/samer/learn-node/node_modules','/Users/samer/node_modules','/Users/node_modules','/node_modules' ] }Note how in this delayed console.log output both lib/util.js and index.js are fully loaded.
请注意,如何在此延迟的console.log输出中完全加载lib/util.js和index.js 。
The exports object becomes complete when Node finishes loading the module (and labels it so). The whole process of requiring/loading a module is synchronous. That’s why we were able to see the modules fully loaded after one cycle of the event loop.
Node完成模块加载(并对其进行标记)后, exports对象将完成。 要求/加载模块的整个过程是同步的。 这就是为什么我们能够在一个事件循环周期后看到模块已完全加载的原因。
This also means that we cannot change the exports object asynchronously. We can’t, for example, do the following in any module:
这也意味着我们不能异步更改exports对象。 例如,我们不能在任何模块中执行以下操作:
fs.readFile('/etc/passwd', (err, data) => {if (err) throw err;exports.data = data; // Will not work.
});循环模块依赖性 (Circular module dependency)
Let’s now try to answer the important question about circular dependency in Node: What happens when module 1 requires module 2, and module 2 requires module 1?
现在,让我们尝试回答有关节点中循环依赖的重要问题:当模块1需要模块2,而模块2需要模块1时会发生什么?
To find out, let’s create the following two files under lib/, module1.js and module2.js and have them require each other:
为了找出module1.js ,让我们在lib/下创建以下两个文件, module1.js和module2.js并使它们相互需求:
// lib/module1.jsexports.a = 1;require('./module2');exports.b = 2;
exports.c = 3;// lib/module2.jsconst Module1 = require('./module1');
console.log('Module1 is partially loaded here', Module1);When we run module1.js we see the following:
当我们运行module1.js我们看到以下内容:
~/learn-node $ node lib/module1.js
Module1 is partially loaded here { a: 1 }We required module2 before module1 was fully loaded, and since module2 required module1 while it wasn’t fully loaded, what we get from the exports object at that point are all the properties exported prior to the circular dependency. Only the a property was reported because both b and c were exported after module2 required and printed module1.
我们需要的module2之前module1满载,而且由于module2所需的module1 ,而这是不满载,我们从一开始exports在这一点上是物体的所有属性循环依赖之前出口。 仅报告了a属性,因为b和c都在需要module2之后导出并打印了module1 。
Node keeps this really simple. During the loading of a module, it builds the exports object. You can require the module before it’s done loading and you’ll just get a partial exports object with whatever was defined so far.
Node使这一过程变得非常简单。 在加载模块期间,它将构建exports对象。 您可以在完成加载之前要求该模块,并且将获得具有到目前为止定义内容的部分导出对象。
JSON和C / C ++插件 (JSON and C/C++ addons)
We can natively require JSON files and C++ addon files with the require function. You don’t even need to specify a file extension to do so.
我们可以使用require函数在本地要求JSON文件和C ++附加文件。 您甚至不需要指定文件扩展名即可。
If a file extension was not specified, the first thing Node will try to resolve is a .js file. If it can’t find a .js file, it will try a .json file and it will parse the .json file if found as a JSON text file. After that, it will try to find a binary .node file. However, to remove ambiguity, you should probably specify a file extension when requiring anything other than .js files.
如果未指定文件扩展名,则Node首先尝试解析的是.js文件。 如果找不到.js文件,它将尝试使用.json文件,并且如果发现是JSON文本文件,则将解析.json文件。 之后,它将尝试查找二进制.node文件。 但是,要消除歧义,当需要除.js文件以外的任何文件时,您可能应该指定文件扩展名。
Requiring JSON files is useful if, for example, everything you need to manage in that file is some static configuration values, or some values that you periodically read from an external source. For example, if we had the following config.json file:
例如,如果您需要在该文件中管理的所有内容都是一些静态配置值,或者是您定期从外部源中读取的某些值,则需要JSON文件很有用。 例如,如果我们有以下config.json文件:
{"host": "localhost","port": 8080
}We can require it directly like this:
我们可以这样直接要求它:
const { host, port } = require('./config');console.log(`Server will run at http://${host}:${port}`);Running the above code will have this output:
运行上面的代码将具有以下输出:
Server will run at http://localhost:8080If Node can’t find a .js or a .json file, it will look for a .node file and it would interpret the file as a compiled addon module.
如果Node找不到.js或.json文件,它将查找.node文件,并将其解释为已编译的插件模块。
The Node documentation site has a sample addon file which is written in C++. It’s a simple module that exposes a hello() function and the hello function outputs “world.”
Node文档站点有一个用C ++编写的示例附加文件 。 这是一个简单的模块,它公开了hello()函数,并且hello函数输出“ world”。
You can use the node-gyp package to compile and build the .cc file into a .node file. You just need to configure a binding.gyp file to tell node-gyp what to do.
您可以使用node-gyp软件包来编译.cc文件并将其构建为.node文件。 您只需要配置一个binding.gyp文件来告诉node-gyp该怎么做。
Once you have the addon.node file (or whatever name you specify in binding.gyp) then you can natively require it just like any other module:
一旦你的addon.node文件(或任何你的名字在指定binding.gyp ),那么你可以原生需要它就像任何其他的模块:
const addon = require('./addon');console.log(addon.hello());We can actually see the support of the three extensions by looking at require.extensions.
通过查看require.extensions我们实际上可以看到这三个扩展的支持。
Looking at the functions for each extension, you can clearly see what Node will do with each. It uses module._compile for .js files, JSON.parse for .json files, and process.dlopen for .node files.
查看每个扩展的功能,您可以清楚地看到Node将对每个扩展进行的操作。 它采用module._compile了.js文件, JSON.parse用于.json文件,并process.dlopen为.node文件。
您在Node中编写的所有代码都将包装在函数中 (All code you write in Node will be wrapped in functions)
Node’s wrapping of modules is often misunderstood. To understand it, let me remind you about the exports/module.exports relation.
节点对模块的包装常常被误解。 要理解它,让我提醒你有关的exports / module.exports关系。
We can use the exports object to export properties, but we cannot replace the exports object directly because it’s just a reference to module.exports
我们可以使用exports对象导出属性,但是我们不能直接替换exports对象,因为它只是对module.exports的引用。
exports.id = 42; // This is ok.exports = { id: 42 }; // This will not work.module.exports = { id: 42 }; // This is ok.How exactly does this exports object, which appears to be global for every module, get defined as a reference on the module object?
对于每个模块似乎都是全局的exports对象,如何精确地定义为module对象上的引用?
Let me ask one more question before explaining Node’s wrapping process.
在解释Node的包装过程之前,让我再问一个问题。
In a browser, when we declare a variable in a script like this:
在浏览器中,当我们在如下脚本中声明变量时:
var answer = 42;That answer variable will be globally available in all scripts after the script that defined it.
该answer变量将在定义它的脚本之后的所有脚本中全局可用。
This is not the case in Node. When we define a variable in one module, the other modules in the program will not have access to that variable. So how come variables in Node are magically scoped?
在Node中不是这种情况。 当我们在一个模块中定义变量时,程序中的其他模块将无法访问该变量。 那么,如何在Node中对变量进行神奇的作用域限定呢?
The answer is simple. Before compiling a module, Node wraps the module code in a function, which we can inspect using the wrapper property of the module module.
答案很简单。 在编译模块之前,Node将模块代码包装在一个函数中,我们可以使用module模块的wrapper属性对其进行检查。
~ $ node
> require('module').wrapper
[ '(function (exports, require, module, __filename, __dirname) { ','\n});' ]
>Node does not execute any code you write in a file directly. It executes this wrapper function which will have your code in its body. This is what keeps the top-level variables that are defined in any module scoped to that module.
Node不执行您直接在文件中编写的任何代码。 它执行此包装器功能,将您的代码放入其主体中。 这就是将在任何模块中定义的顶级变量保留在该模块范围内的原因。
This wrapper function has 5 arguments: exports, require, module, __filename, and __dirname. This is what makes them appear to look global when in fact they are specific to each module.
此包装函数有5个参数: exports , require , module , __filename和__dirname 。 这就是使它们看起来实际上是全局的,而实际上它们特定于每个模块。
All of these arguments get their values when Node executes the wrapper function. exports is defined as a reference to module.exports prior to that. require and module are both specific to the function to be executed, and __filename/__dirname variables will contain the wrapped module’s absolute filename and directory path.
当Node执行包装函数时,所有这些参数都将获得其值。 在module.exports之前, exports被定义为对module.exports的引用。 require和module都特定于要执行的功能,并且__filename / __dirname变量将包含包装的模块的绝对文件名和目录路径。
You can see this wrapping in action if you run a script with a problem on its first line:
如果您在脚本的第一行中运行有问题的脚本,则可以看到这种包装效果:
~/learn-node $ echo "euaohseu" > bad.js~/learn-node $ node bad.js
~/bad.js:1
(function (exports, require, module, __filename, __dirname) { euaohseu^
ReferenceError: euaohseu is not definedNote how the first line of the script as reported above was the wrapper function, not the bad reference.
注意上面报告的脚本的第一行是包装函数,而不是错误的引用。
Moreover, since every module gets wrapped in a function, we can actually access that function’s arguments with the arguments keyword:
而且,由于每个模块都包装在一个函数中,因此我们实际上可以使用arguments关键字访问该函数的参数:
~/learn-node $ echo "console.log(arguments)" > index.js~/learn-node $ node index.js
{ '0': {},'1':{ [Function: require]resolve: [Function: resolve],main:Module {id: '.',exports: {},parent: null,filename: '/Users/samer/index.js',loaded: false,children: [],paths: [Object] },extensions: { ... },cache: { '/Users/samer/index.js': [Object] } },'2':Module {id: '.',exports: {},parent: null,filename: '/Users/samer/index.js',loaded: false,children: [],paths: [ ... ] },'3': '/Users/samer/index.js','4': '/Users/samer' }The first argument is the exports object, which starts empty. Then we have the require/module objects, both of which are instances that are associated with the index.js file that we’re executing. They are not global variables. The last 2 arguments are the file’s path and its directory path.
第一个参数是exports对象,该对象开始为空。 然后,我们有了require / module对象,这两个都是与我们正在执行的index.js文件关联的实例。 它们不是全局变量。 最后两个参数是文件的路径及其目录路径。
The wrapping function’s return value is module.exports. Inside the wrapped function, we can use the exports object to change the properties of module.exports, but we can’t reassign exports itself because it’s just a reference.
包装函数的返回值是module.exports 。 在包装函数中,我们可以使用exports对象来更改module.exports的属性,但是我们不能重新分配exports本身,因为它只是一个引用。
What happens is roughly equivalent to:
发生的情况大致等同于:
function (require, module, __filename, __dirname) {let exports = module.exports;// Your Code...return module.exports;
}If we change the whole exports object, it would no longer be a reference to module.exports. This is the way JavaScript reference objects work everywhere, not just in this context.
如果我们更改整个exports对象,它将不再是对module.exports的引用。 这是JavaScript引用对象在任何地方(而不只是在此上下文中)工作的方式。
需求对象 (The require object)
There is nothing special about require. It’s an object that acts mainly as a function that takes a module name or path and returns the module.exports object. We can simply override the require object with our own logic if we want to.
没有什么特别的require 。 它是一个对象,主要充当采用模块名称或路径并返回module.exports对象的函数。 如果require我们可以使用我们自己的逻辑简单地覆盖require对象。
For example, maybe for testing purposes, we want every require call to be mocked by default and just return a fake object instead of the required module exports object. This simple reassignment of require will do the trick:
例如,出于测试目的,我们希望默认情况下模拟每个require调用,并仅返回假对象而不是必需的模块导出对象。 这个简单的对require的重新分配将达到目的:
require = function() {return { mocked: true };}After doing the above reassignment of require, every require('something') call in the script will just return the mocked object.
完成以上对require分配后,脚本中的每个require('something')调用都将仅返回模拟对象。
The require object also has properties of its own. We’ve seen the resolve property, which is a function that performs only the resolving step of the require process. We’ve also seen require.extensions above.
require对象还具有自己的属性。 我们已经看到了resolve属性,该属性仅执行require流程的解析步骤。 我们还在上面看到了require.extensions 。
There is also require.main which can be helpful to determine if the script is being required or run directly.
还有require.main ,它有助于确定是需要脚本还是直接运行脚本。
Say, for example, that we have this simple printInFrame function in print-in-frame.js:
例如,假设我们在print-in-frame.js具有此简单的printInFrame函数:
// In print-in-frame.jsconst printInFrame = (size, header) => {console.log('*'.repeat(size));console.log(header);console.log('*'.repeat(size));
};The function takes a numeric argument size and a string argument header and it prints that header in a frame of stars controlled by the size we specify.
该函数采用数字参数size和字符串参数header并在由我们指定的大小控制的星状帧中打印该标题。
We want to use this file in two ways:
我们想以两种方式使用该文件:
- From the command line directly like this:从命令行直接像这样:
~/learn-node $ node print-in-frame 8 HelloPassing 8 and Hello as command line arguments to print “Hello” in a frame of 8 stars.
将8和Hello作为命令行参数传递以在8星的帧中打印“ Hello”。
2. With require. Assuming the required module will export the printInFrame function and we can just call it:
2.用require 。 假设所需的模块将导出printInFrame函数,我们可以直接调用它:
const print = require('./print-in-frame');print(5, 'Hey');To print the header “Hey” in a frame of 5 stars.
在5星的框架中打印标题“ Hey”。
Those are two different usages. We need a way to determine if the file is being run as a stand-alone script or if it is being required by other scripts.
那是两种不同的用法。 我们需要一种方法来确定文件是作为独立脚本运行还是其他脚本需要它。
This is where we can use this simple if statement:
在这里,我们可以使用以下简单的if语句:
if (require.main === module) {// The file is being executed directly (not with require)
}So we can use this condition to satisfy the usage requirements above by invoking the printInFrame function differently:
因此,我们可以通过不同地调用printInFrame函数来使用此条件来满足上述使用要求:
// In print-in-frame.jsconst printInFrame = (size, header) => {console.log('*'.repeat(size));console.log(header);console.log('*'.repeat(size));
};if (require.main === module) {printInFrame(process.argv[2], process.argv[3]);
} else {module.exports = printInFrame;
}When the file is not being required, we just call the printInFrame function with process.argv elements. Otherwise, we just change the module.exports object to be the printInFrame function itself.
当不需要该文件时,我们只需调用带有process.argv元素的printInFrame函数即可。 否则,我们只需将module.exports对象更改为printInFrame函数本身即可。
所有模块将被缓存 (All modules will be cached)
Caching is important to understand. Let me use a simple example to demonstrate it.
缓存对于理解非常重要。 让我用一个简单的例子来演示它。
Say that you have the following ascii-art.js file that prints a cool looking header:
假设您有以下ascii-art.js文件,该文件显示了漂亮的标题:
We want to display this header every time we require the file. So when we require the file twice, we want the header to show up twice.
我们希望在每次需要文件时都显示此标头。 因此,当我们需要两次文件时,我们希望标题显示两次。
require('./ascii-art') // will show the header.
require('./ascii-art') // will not show the header.The second require will not show the header because of modules’ caching. Node caches the first call and does not load the file on the second call.
由于模块的缓存,第二个require将不显示标题。 Node会缓存第一个调用,并且不会在第二个调用上加载文件。
We can see this cache by printing require.cache after the first require. The cache registry is simply an object that has a property for every required module. Those properties values are the module objects used for each module. We can simply delete a property from that require.cache object to invalidate that cache. If we do that, Node will re-load the module to re-cache it.
我们可以通过在第一个require之后打印require.cache来查看此缓存。 缓存注册表只是一个对象,它具有每个必需模块的属性。 这些属性值是每个模块使用的module对象。 我们可以简单地从该require.cache对象中删除一个属性以使该缓存无效。 如果这样做,Node将重新加载模块以重新缓存它。
However, this is not the most efficient solution for this case. The simple solution is to wrap the log line in ascii-art.js with a function and export that function. This way, when we require the ascii-art.js file, we get a function that we can execute to invoke the log line every time:
但是,这不是这种情况下最有效的解决方案。 简单的解决方案是使用函数将日志行包装在ascii-art.js并导出该函数。 这样,当我们需要ascii-art.js文件时,我们将获得一个函数,可以执行该函数以每次调用日志行:
require('./ascii-art')() // will show the header.
require('./ascii-art')() // will also show the header.That’s all I have for this topic. Thanks for reading. Until next time!
这就是我要做的所有事情。 谢谢阅读。 直到下一次!
Learning React or Node? Checkout my books:
学习React还是Node? 结帐我的书:
Learn React.js by Building Games
通过构建游戏学习React.js
Node.js Beyond the Basics
超越基础的Node.js
翻译自: https://www.freecodecamp.org/news/requiring-modules-in-node-js-everything-you-need-to-know-e7fbd119be8/
node.js中模块
相关文章:

Sublime Text3配置Node.js开发环境
下载Nodejs插件,下载zip压缩包后解压链接: http://pan.baidu.com/s/1hsBk60k 密码: jrcv打开Sublime Text3,点击菜单“首选项(N)” >“浏览插件(B)”打开“Packages”文件夹,并将第1部的Node…

修改mysql的root密码
use msyql; update user set passwordpassword(新密码) where userroot; flush privileges; quitnet stop mysql #如果提示 发生系统错误5,就用管理员身份启动cmd.exe 转载于:https://www.cnblogs.com/walter371/p/4065904.html
iOS 开发之便捷宏定义
#define URL(A/*str*/) [NSURL URLWithString:A]// 图片 #define IMAGE(A/*str*/) [UIImage imageNamed:A]// 快速转换字符串 #define LD_STR(A/*str*/) [NSString stringWithFormat:"%ld",A] #define F2_STR(A/*str*/) [NSString stringWithFormat:"%.2f"…
rspec 测试页面元素_如何使用共享示例使您的RSpec测试干燥
rspec 测试页面元素by Parth Modi由Parth Modi 如何使用共享示例使您的RSpec测试干燥 (How to DRY out your RSpec Tests using Shared Examples) “Give me six hours to chop down a tree and I will spend the first four sharpening the axe.” — Abraham Lincoln“ 给我…
Windows搭建以太坊的私有链环境
Windows搭建以太坊的私有链环境 1、下载Geth.exe 运行文件,并安装https://github.com/ethereum/go-ethereum/releases/下载后,只有一个Geth.exe的文件2、cmd进入按章目录运行:geth -help看看是否可用geth命令3、在Geth安装目录下放置初始化创…
前50个斐波那契数
它有一个递推关系,f(1)1f(2)1f(n)f(n-1)f(n-2),其中n>23f(n)f(n2)f(n-2)-------------------------------------------- F(1) 1 F(2) 1 F(3) 2 F(4) 3 F(5) 5 F(6) 8 F(7) 13 F(8) 21 F(9) 34 F(10) 55 F(11) 89 F(12) 144 F(13) 233 F(14) 377 F(…
RAC -代替OC 中的代理
学以致用, 有的时候学习了很多理论 却还是忘了实践 OC 中代替代理 简洁编程 #import "ViewController.h" #import <ReactiveObjC.h> #import "SKView.h" interface ViewController ()endimplementation ViewController- (void)viewDidL…
深度学习 免费课程_深入学习深度学习,提供15项免费在线课程
深度学习 免费课程by David Venturi大卫文图里(David Venturi) 深入学习深度学习,提供15项免费在线课程 (Dive into Deep Learning with 15 free online courses) Every day brings new headlines for how deep learning is changing the world around us. A few e…

《音乐商店》第4集:自动生成StoreManager控制器
一、自动生成StoreManager控制器 二、查看 StoreManager 控制器的代码 现在,Store Manager 控制器中已经包含了一定数量的代码,我们从头到尾重新过一下。 1.访问数据库代码 首先,在控制器中包含了标准的 MVC 控制器的代码,为了使用…
StringUtils
/需要导入第三方jar包pinyin4j.jarimport net.sourceforge.pinyin4j.PinyinHelper;import java.util.regex.Matcher; import java.util.regex.Pattern;public class StringUtils {protected static final String TAG StringUtils.class.getSimpleName();/*** 增加空白*/public…
微信支付invalid total_fee 的报错
因为我的测试商品是0.01的 原因是微信支付的金额是不能带小数点的 直接在提交的时候 乘以 100操作 ,因为里面设置参数的时候是 以分为单位的 [packageParams setObject: price forKey:"total_fee"]; //订单金额,单位为分
帧编码 场编码_去年,我帮助举办了40场编码活动。 这是我学到的。
帧编码 场编码by Florin Nitu通过弗洛林尼图 去年,我帮助举办了40场编码活动。 这是我学到的。 (I helped host 40 coding events last year. Here’s what I learned.) Our local freeCodeCamp study group in Brasov, Romania just held its 40th event. We even…
HDU 4540 威威猫系列故事――打地鼠(DP)
D - 威威猫系列故事――打地鼠Time Limit:100MS Memory Limit:32768KB 64bit IO Format:%I64d & %I64u Submit Status Practice HDU 4540Description 威威猫最近不务正业,每天沉迷于游戏“打地鼠”。 每当朋友们劝他别太着迷游戏,应该好好工…
iOS 在每一个cell上添加一个定时器的方案
1 首先创建一个数组,用来创建所有的定时器的时间 - (NSMutableArray *)totalLastTime {if (!_totalLastTime) {_totalLastTime [NSMutableArray array];}return _totalLastTime; }2 当从网络请求过来时间之后,循环遍历,行数和时间作为Key&a…
用字符串生成二维码
需要导入Zxing.jar包import android.graphics.Bitmap;import com.google.zxing.BarcodeFormat; import com.google.zxing.MultiFormatWriter; import com.google.zxing.WriterException; import com.google.zxing.common.BitMatrix;public class ZxingCode {/** * 用字符串生成…
在JavaScript中重复字符串的三种方法
In this article, I’ll explain how to solve freeCodeCamp’s “Repeat a string repeat a string” challenge. This involves repeating a string a certain number of times.在本文中,我将解释如何解决freeCodeCamp的“ 重复字符串重复字符串 ”挑战。 这涉及重…
杭电2099 整除的尾数
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid2099 解题思路:将a扩大100倍之后,再给它从加上i(i从0到99),一个一个的看哪一个能整除 反思:末两位是00的时候输出的是00(这种情况题目里面的测试数据给…
iOS 验证码倒计时按钮
具体使用 [SmsTimerManager sharedManager].second (int)time; [[SmsTimerManager sharedManager] resetTime]; [SmsTimerManager sharedManager].delegate self; [strongSelf updateTime];设置代理方法 更新按钮的标题 (void)updateTime { if ([SmsTimerManager sharedMan…

树莓派centos安装的基本配置
萌新再发一帖,这篇文章呢主要是为大家在树莓派上安装centos以后提供一个问题的解决方案。 首先我呢觉得好奇就在某宝上花了两百来块钱买了一套树莓派,很多人喜欢在树莓派上安装Debian,我呢更青睐用Red Hat的系统,毕竟对Red Hat更熟…
token拦截器阻止连接_如何防止广告拦截器阻止您的分析数据
token拦截器阻止连接TL;DR Theres dataunlocker.com service coming soon (subscribe!), along with the open-sourced prototype you can use for Google Analytics or Google Tag Manager (2020 update).TL; DR即将推出dataunlocker.com服务 (订阅!),以…
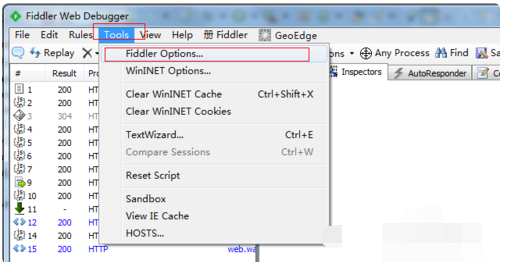
使用Fiddler手机抓包https-----重要
Fiddler不仅可以对手机进行抓包,还可以抓取别的电脑的请求包,今天就想讲一讲使用Fiddler手机抓包! 使用Fiddler手机抓包有两个条件: 一:手机连的网络或WiFi必须和电脑(使用fiddler)连的网络或Wi…

strtok和strtok_r
strtok和strtok_r原型:char *strtok(char *s, char *delim); 功能:分解字符串为一组字符串。s为要分解的字符串,delim为分隔符字符串。 说明:首次调用时,s指向要分解的字符串,之后再次调用要把s设成NULL。 …

iOS 标签自动布局
导入SKTagFrame SKTagFrame *frame [[SKTagFrame alloc] init];frame.tagsArray self.bigModel.Tags;// 添加标签CGFloat first_H 0;CGFloat total_H 0;for (NSInteger i 0; i< self.bigModel.Tags.count; i) {UIButton *tagsBtn [UIButton buttonWithType:UIButtonT…
引导分区 pbr 数据分析_如何在1小时内引导您的分析
引导分区 pbr 数据分析by Tim Abraham蒂姆亚伯拉罕(Tim Abraham) 如何在1小时内引导您的分析 (How to bootstrap your analytics in 1 hour) Even though most startups understand how critical data is to their success, they tend to shy away from analytics — especial…

SSL 1460——最小代价问题
Description 设有一个nm(小于100)的方格(如图所示),在方格中去掉某些点,方格中的数字代表距离(为小于100的数,如果为0表示去掉的点),试找出一条从A(左上角)到B(右下角&am…

在Windows 7下面IIS7的安装和 配置ASP的正确方法
在Windows 7下如何安装IIS7,以及IIS7在安装过程中的一些需要注意的设置,以及在IIS7下配置ASP的正确方法。 一、进入Windows 7的 控制面板,选择左侧的打开或关闭Windows功能 。二、打开后可以看到Windows功能的界面,注意选择的项目…
适配iOS 13 tabbar 标题字体不显示以及返回变蓝色的为问题
// 适配iOS 13 tabbar 标题字体不显示以及返回变蓝色的为问题 if (available(iOS 13.0, *)) {//[[UITabBar appearance] setUnselectedItemTintColor:Color_666666];}
企业不要求工程师资格认证_谁说工程师不能成为企业家?
企业不要求工程师资格认证by Preethi Kasireddy通过Preethi Kasireddy 谁说工程师不能成为企业家? (Who says engineers can’t become entrepreneurs?) A lot of people warned me not to walk away from my great position at Andreessen Horowitz to pursue so…
BestCoder Round #92 比赛记录
上午考完试后看到了晚上的BestCoder比赛,全机房都来参加 感觉压力好大啊QAQ,要被虐了. 7:00 比赛开始了,迅速点进了T1 大呼这好水啊!告诉了同桌怎么看中文题面 然后就开始码码码,4分16秒AC了第一题 7:05 开始看第二题 诶诶诶!!~~~~直接爆搜不久能过吗? 交了一发爆搜上去,AC了,…

[cocos2dx UI] CCLabelAtlas 为什么不显示最后一个字
CClabelAtlas优点,基本用法等我就不说了,这里说一个和美术配合时的一个坑!就是图片的最后一位怎么也不显示,如下图中的冒号不会显示 查了ASCII码表,这个冒号的值为58,就是在9(57)的后…