pytorch python区别_pytorch源码解析:Python层 pytorchmodule源码
尝试使用了pytorch,相比其他深度学习框架,pytorch显得简洁易懂。花时间读了部分源码,主要结合简单例子带着问题阅读,不涉及源码中C拓展库的实现。
一个简单例子
实现单层softmax二分类,输入特征维度为4,输出为2,经过softmax函数得出输入的类别概率。代码示意:定义网络结构;使用SGD优化;迭代一次,随机初始化三个样例,每个样例四维特征,target分别为1,0,1;前向传播,使用交叉熵计算loss;反向传播,最后由优化算法更新权重,完成一次迭代。
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.linear = nn.Linear(4, 2)
def forward(self, input):
out = F.softmax(self.linear(input))
return out
net = Net()
sgd = torch.optim.SGD(net.parameters(), lr=0.001)
for epoch in range(1):
features = torch.autograd.Variable(torch.randn(3, 4), requires_grad=True)
target = torch.autograd.Variable(torch.LongTensor([1, 0, 1]))
sgd.zero_grad()
out = net(features)
loss = F.cross_entropy(out, target)
loss.backward()
sgd.step()
从上面的例子,带着下面的问题阅读源码:
pytorch的主要概念:Tensor、autograd、Variable、Function、Parameter、Module(Layers)、Optimizer;
自定义Module如何组织网络结构和网络参数;
前向传播、反向传播实现流程
优化算法类如何实现,如何和自定义Module联系并更新参数。
pytorch的主要概念
Tensor
类似numpy的ndarrays,强化了可进行GPU计算的特性,由C拓展模块实现。如上面的torch.randn(3, 4) 返回一个3*4的Tensor。和numpy一样,也有一系列的Operation,如
x = torch.rand(5, 3)
y = torch.rand(5, 3)
print x + y
print torch.add(x, y)
print x.add_(y)
Varaiable与autograd
Variable封装了Tensor,包括了几乎所有的Tensor可以使用的Operation方法,主要使用在自动求导(autograd),Variable类继承_C._VariableBase,由C拓展类定义实现。
Variable是autograd的计算单元,Variable通过Function组织成函数表达式(计算图):
data 为其封装的tensor值
grad 为其求导后的值
creator 为创建该Variable的Function,实现中grad_fn属性则指向该Function。
如:import torch
from torch.autograd import Variable
x = Variable(torch.ones(2, 2), requires_grad=True)
y = x + 2
print y.grad_fn
print "before backward: ", x.grad
y.backward()
print "after backward: ", x.grad
输出结果:
before backward: None
after backward: Variable containing:
1
[torch.FloatTensor of size 1x1]
调用y的backward方法,则会对创建y的Function计算图中所有requires_grad=True的Variable求导(这里的x)。例子中显然dy/dx = 1。
Parameter
Parameter 为Variable的一个子类,后面还会涉及,大概两点区别:
作为Module参数会被自动加入到该Module的参数列表中;
不能被volatile, 默认require gradient。
Module
Module为所有神经网络模块的父类,如开始的例子,Net继承该类,____init____中指定网络结构中的模块,并重写forward方法实现前向传播得到指定输入的输出值,以此进行后面loss的计算和反向传播。
Optimizer
Optimizer是所有优化算法的父类(SGD、Adam、...),____init____中传入网络的parameters, 子类实现父类step方法,完成对parameters的更新。
自定义Module
该部分说明自定义的Module是如何组织定义在构造函数中的子Module,以及自定义的parameters的保存形式,eg:
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.linear = nn.Linear(4, 2)
def forward(self, input):
out = F.softmax(self.linear(input))
return out
首先看构造函数,Module的构造函数初始化了Module的基本属性,这里关注_parameters和_modules,两个属性初始化为OrderedDict(),pytorch重写的有序字典类型。_parameters保存网络的所有参数,_modules保存当前Module的子Module。
module.py:
class Module(object):
def __init__(self):
self._parameters = OrderedDict()
self._modules = OrderedDict()
...
下面来看自定义Net类中self.linear = nn.Linear(4, 2)语句和_modules、_parameters如何产生联系,或者self.linear及其参数如何被添加到_modules、_parameters字典中。答案在Module的____setattr____方法,该Python内建方法会在类的属性被赋值时调用。
module.py:
def __setattr__(self, name, value):
def remove_from(*dicts):
for d in dicts:
if name in d:
del d[name]
params = self.__dict__.get('_parameters')
if isinstance(value, Parameter): # ----------- <1>
if params is None:
raise AttributeError(
"cannot assign parameters before Module.__init__() call")
remove_from(self.__dict__, self._buffers, self._modules)
self.register_parameter(name, value)
elif params is not None and name in params:
if value is not None:
raise TypeError("cannot assign '{}' as parameter '{}' "
"(torch.nn.Parameter or None expected)"
.format(torch.typename(value), name))
self.register_parameter(name, value)
else:
modules = self.__dict__.get('_modules')
if isinstance(value, Module):# ----------- <2>
if modules is None:
raise AttributeError(
"cannot assign module before Module.__init__() call")
remove_from(self.__dict__, self._parameters, self._buffers)
modules[name] = value
elif modules is not None and name in modules:
if value is not None:
raise TypeError("cannot assign '{}' as child module '{}' "
"(torch.nn.Module or None expected)"
.format(torch.typename(value), name))
modules[name] = value
......
调用self.linear = nn.Linear(4, 2)时,父类____setattr____被调用,参数name为“linear”, value为nn.Linear(4, 2),内建的Linear类同样是Module的子类。所以<2>中的判断为真,接着modules[name] = value,该linear被加入_modules字典。
同样自定义Net类的参数即为其子模块Linear的参数,下面看Linear的实现:
linear.py:
class Linear(Module):
def __init__(self, in_features, out_features, bias=True):
super(Linear, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.weight = Parameter(torch.Tensor(out_features, in_features))
if bias:
self.bias = Parameter(torch.Tensor(out_features))
else:
self.register_parameter('bias', None)
self.reset_parameters()
def reset_parameters(self):
stdv = 1. / math.sqrt(self.weight.size(1))
self.weight.data.uniform_(-stdv, stdv)
if self.bias is not None:
self.bias.data.uniform_(-stdv, stdv)
def forward(self, input):
return F.linear(input, self.weight, self.bias)
同样继承Module类,____init____中参数为输入输出维度,是否需要bias参数。在self.weight = Parameter(torch.Tensor(out_features, in_features))的初始化时,同样会调用父类Module的____setattr____, name为“weight”,value为Parameter,此时<1>判断为真,调用self.register_parameter(name, value),该方法中对参数进行合法性校验后放入self._parameters字典中。
Linear在reset_parameters方法对权重进行了初始化。
最终可以得出结论自定义的Module以树的形式组织子Module,子Module及其参数以字典的方式保存。
前向传播、反向传播
前向传播
例子中out = net(features)实现了网络的前向传播,该语句会调用Module类的forward方法,该方法被继承父类的子类实现。net(features)使用对象作为函数调用,会调用Python内建的____call____方法,Module重写了该方法。
module.py:
def __call__(self, *input, **kwargs):
for hook in self._forward_pre_hooks.values():
hook(self, input)
result = self.forward(*input, **kwargs)
for hook in self._forward_hooks.values():
hook_result = hook(self, input, result)
if hook_result is not None:
raise RuntimeError(
"forward hooks should never return any values, but '{}'"
"didn't return None".format(hook))
if len(self._backward_hooks) > 0:
var = result
while not isinstance(var, Variable):
var = var[0]
grad_fn = var.grad_fn
if grad_fn is not None:
for hook in self._backward_hooks.values():
wrapper = functools.partial(hook, self)
functools.update_wrapper(wrapper, hook)
grad_fn.register_hook(wrapper)
return result
____call____方法中调用result = self.forward(*input, **kwargs)前后会查看有无hook函数需要调用(预处理和后处理)。
例子中Net的forward方法中out = F.softmax(self.linear(input)),同样会调用self.linear的forward方法F.linear(input, self.weight, self.bias)进行矩阵运算(仿射变换)。
functional.py:
def linear(input, weight, bias=None):
if input.dim() == 2 and bias is not None:
# fused op is marginally faster
return torch.addmm(bias, input, weight.t())
output = input.matmul(weight.t())
if bias is not None:
output += bias
return output
最终经过F.softmax,得到前向输出结果。F.softmax和F.linear类似前面说到的Function(Parameters的表达式或计算图)。
反向传播
得到前向传播结果后,计算loss = F.cross_entropy(out, target),接下来反向传播求导数d(loss)/d(weight)和d(loss)/d(bias):
loss.backward()
backward()方法同样底层由C拓展,这里暂不深入,调用该方法后,loss计算图中的所有Variable(这里linear的weight和bias)的grad被求出。
Optimizer参数更新
在计算出参数的grad后,需要根据优化算法对参数进行更新,不同的优化算法有不同的更新策略。
optimizer.py:
class Optimizer(object):
def __init__(self, params, defaults):
if isinstance(params, Variable) or torch.is_tensor(params):
raise TypeError("params argument given to the optimizer should be "
"an iterable of Variables or dicts, but got " +
torch.typename(params))
self.state = defaultdict(dict)
self.param_groups = list(params)
......
def zero_grad(self):
"""Clears the gradients of all optimized :class:`Variable` s."""
for group in self.param_groups:
for p in group['params']:
if p.grad is not None:
if p.grad.volatile:
p.grad.data.zero_()
else:
data = p.grad.data
p.grad = Variable(data.new().resize_as_(data).zero_())
def step(self, closure):
"""Performs a single optimization step (parameter update).
Arguments:
closure (callable): A closure that reevaluates the model and
returns the loss. Optional for most optimizers.
"""
raise NotImplementedError
Optimizer在init中将传入的params保存到self.param_groups,另外两个重要的方法zero_grad负责将参数的grad置零方便下次计算,step负责参数的更新,由子类实现。
以列子中的sgd = torch.optim.SGD(net.parameters(), lr=0.001)为例,其中net.parameters()返回Net参数的迭代器,为待优化参数;lr指定学习率。
SGD.py:
class SGD(Optimizer):
def __init__(self, params, lr=required, momentum=0, dampening=0,
weight_decay=0, nesterov=False):
defaults = dict(lr=lr, momentum=momentum, dampening=dampening,
weight_decay=weight_decay, nesterov=nesterov)
if nesterov and (momentum <= 0 or dampening != 0):
raise ValueError("Nesterov momentum requires a momentum and zero dampening")
super(SGD, self).__init__(params, defaults)
def __setstate__(self, state):
super(SGD, self).__setstate__(state)
for group in self.param_groups:
group.setdefault('nesterov', False)
def step(self, closure=None):
"""Performs a single optimization step.
Arguments:
closure (callable, optional): A closure that reevaluates the model
and returns the loss.
"""
loss = None
if closure is not None:
loss = closure()
for group in self.param_groups:
weight_decay = group['weight_decay']
momentum = group['momentum']
dampening = group['dampening']
nesterov = group['nesterov']
for p in group['params']:
if p.grad is None:
continue
d_p = p.grad.data
if weight_decay != 0:
d_p.add_(weight_decay, p.data)
if momentum != 0:
param_state = self.state[p]
if 'momentum_buffer' not in param_state:
buf = param_state['momentum_buffer'] = d_p.clone()
else:
buf = param_state['momentum_buffer']
buf.mul_(momentum).add_(1 - dampening, d_p)
if nesterov:
d_p = d_p.add(momentum, buf)
else:
d_p = buf
p.data.add_(-group['lr'], d_p)
return loss
SGD的step方法中,判断是否使用权重衰减和动量更新,如果不使用,直接更新权重param := param - lr * d(param)。例子中调用sgd.step()后完成一次epoch。这里由于传递到Optimizer的参数集是可更改(mutable)的,step中对参数的更新同样是Net中参数的更新。
小结
到此,根据一个简单例子阅读了pytorch中Python实现的部分源码,没有深入到底层Tensor、autograd等部分的C拓展实现,后面再继续读一读C拓展部分的代码。
转自链接:https://www.jianshu.com/p/f5eb8c2e671c
相关文章:

在vue中使用babel-polyfill
在 Vue.js项目中使用Vuex,Vuex 依赖 Promise,所以如果你的浏览器没有实现 Promise (比如 IE),那么就需要使用一个 polyfill 的库 我们可以通过babel-profill转译 1、安装 npm install --save-dev babel-polyfill 2、在main.js中引入 import b…

CoinMarketCap计划于11月发布新的流动性排名系统
链客,专为开发者而生,有问必答! 此文章来自区块链技术社区,未经允许拒绝转载。 去中心化金融(DeFi)引领未来金融发展趋势,InvestDigital联合传统金融机构,依托现有数字货币金融业务…

cookie和session的代码实现
cookie和session的代码实现 1、设置cookie 今天笔试题考的是cookie的设置,我竟然选了request也可以设置cookie,我的天呀。 我们来看如何在response设置吧 public void service(HttpServletRequest req,HttpServletResponse resp) throws ServletExceptio…

idea 批量修改同一列_学会这个,1秒就可以批量处理文件
【问题1】根据公司名称,批量创建文件夹拿到老板给到的这个任务后,没关系我很有耐心,不就是右击新建文件夹重命名保存吗,然后加班点鼠标到天荒地老,终于完成了。结果老板说有些公司名有误要改正过来,还有几百…

动态规划和分治法的区别
链客,专为开发者而生,有问必答! 此文章来自区块链技术社区,未经允许拒绝转载。 动态规划也是一种分治思想(比如其状态转移方程就是一种分治),但与分治算法不同的是,分治算法是把原问…
关于链式前向星。
一些代码 理解 #include<bits/stdc.h> using namespace std; //优先队列优化的链式前向星 const int maxn1000; const int INF0x3fffffff; struct Edge{int from, to, dist;Edge(int u, int v, int d):from(u),to(v),dist(d){} }; struct HeapNode{int u, d;HeapNode(int…
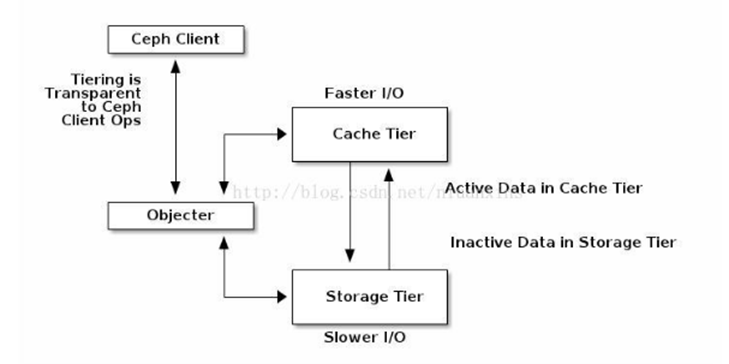
Ceph分层存储分析
最近弄Ceph集群考虑要不要加入分层存储 因此花了点时间研究了下 1,首先肯定要弄清Ceph分层存储的结构 ,结构图大概就是下图所示 缓存层(A cache tier)为Ceph客户端提供更好的I/O性能,而数据存储在存储层(a backing storage tier)。用相对快速…
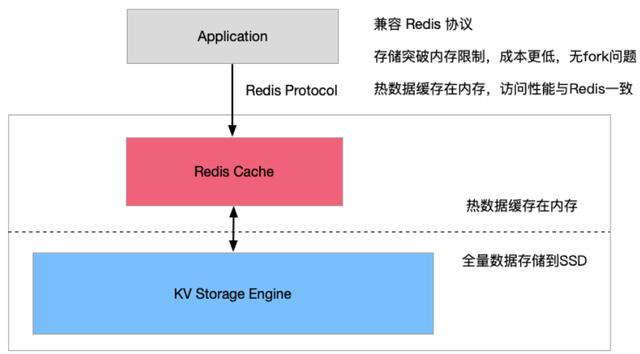
jemeter多场景混合案例_Redis 混合存储最佳实践指南
Redis 混合存储实例是阿里云自主研发的兼容Redis协议和特性的云数据库产品,混合存储实例突破 Redis 数据必须全部存储到内存的限制,使用磁盘存储全量数据,并将热数据缓存到内存,实现访问性能与存储成本的完美平衡。架构及特性命令…

交易所频频被盗,你该如何保护自己的数字资产?
链客,专为开发者而生,有问必答! 此文章来自区块链技术社区,未经允许拒绝转载。 5月8日凌晨,数字货币交易所币安发生被盗事件,黑客从币安热钱包盗走大约 7000 个比特币。币安官方公告称,这是一次…
gitlab搭建
一、安装源和依赖包 #增epel源,如果你是i686系统,请把x86_64修改下。cd /usr/local/src wget -O /etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-6 https://www.fedoraproject.org/static/0608B895.txt rpm --import /etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-6 rpm -Uvh http://dl.f…
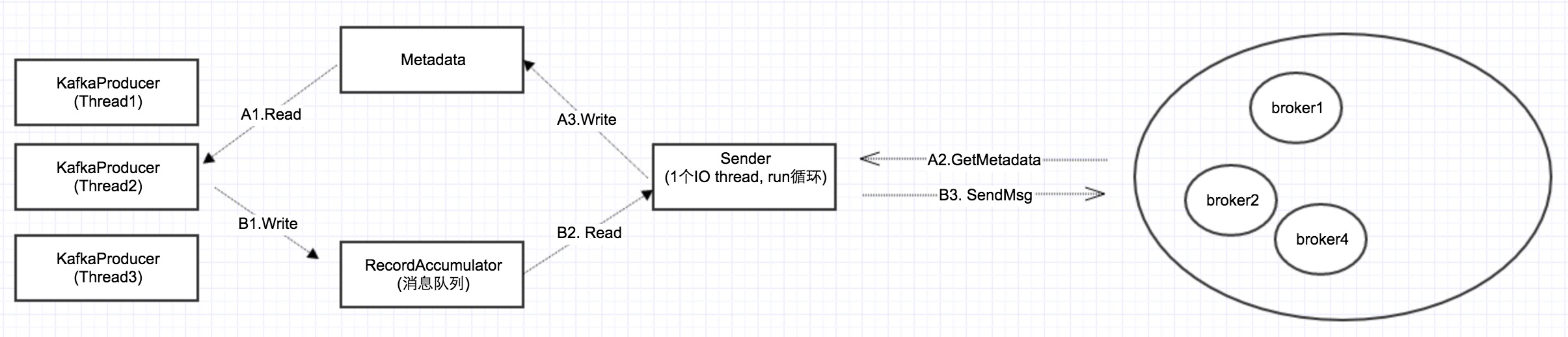
kafka源码分析(二)Metadata的数据结构与读取、更新策略
一、基本思路 异步发送的基本思路就是:send的时候,KafkaProducer把消息放到本地的消息队列RecordAccumulator,然后一个后台线程Sender不断循环,把消息发给Kafka集群。 要实现这个,还得有一个前提条件:就是K…
python实现简单的http服务器_Python实现简单HTTP服务器(二)
#coding:utf-8importsocketimportreimportsysfrom multiprocessing importProcessclassHTTPServer(object):def __init__(self, application):"""application:指的是框架的app"""self.server_socketsocket.socket(socket.AF_INET, so…

机器学习中的模型评价、模型选择及算法选择
链客,专为开发者而生,有问必答! 此文章来自区块链技术社区,未经允许拒绝转载。 正确使用模型评估、模型选择和算法选择技术无论是对机器学习学术研究还是工业场景应用都至关重要。本文将对这三个任务的相关技术进行回顾ÿ…
Apache 流框架 Flink,Spark Streaming,Storm对比分析(一)
https://bigdata.163.com/product/article/5 Apache 流框架 Flink,Spark Streaming,Storm对比分析(一)转载于:https://www.cnblogs.com/WCFGROUP/p/9075745.html
梯度下降算法_神经网络梯度下降算法
神经网络梯度下降算法2018, SEPT 13梯度下降(Gradient Descent) 是神经网络比较重要的部分,因为我们通常利用梯度来利用Cost function(成本函数) 进行backpropagation(反向传播) 不断地iteration࿰…
微擎删除分类无法删除解决-select in效率低解决办法
今天朋友微擎后台微网站里的分类要删除,可是怎么删除也不能删除,同样的系统另一套却可以迅速删除。 后来查询到是查询语句的问题,朋友的平台用户量太大,数据太大,用了以下语句,造成效率太低: SE…

EOS技术及生态系统介绍
链客,专为开发者而生,有问必答! 此文章来自区块链技术社区,未经允许拒绝转载。 嘉宾介绍 哈胜,现任梦起文化传播有限公司技术总监,西北地区区块链技术发起第一人;一直在致力于将区块链技术推广…
svn 提交信息模板
版本:1.0作者:张三描述:修改了xxx转载于:https://www.cnblogs.com/ithfm/p/9075748.html

pta函数统计素数并求和_黎曼的zeta函数
9月24日阿提亚爵士(Sir Atiyah)直播“证明”黎曼猜想(Riemann hypothesis)在普通人中引发了一轮数学热潮,网络上一时间涌现了很多数学八卦文章。许多人在论及该命题重要性时都指出,ζ函数的非平凡零点与素数…

EasyRTMP手机直播推送rtmp流flash无法正常播放问题
本文转自EasyDarwin团队Kim的博客:http://blog.csdn.net/jinlong0603/article/details/52960750 问题简介 EasyRTMP是EasyDarwin团队开发的一套简单易用的RTMP推送SDK。本文想讲述下开发过程中遇到的一个问题。问题的现象是使用EasyRTMP推送音视频流到自己搭建的ngi…

对称加密和非对称加密
链客,专为开发者而生,有问必答! 此文章来自区块链技术社区,未经允许拒绝转载。 对称加密 对称密钥是双方使用相同的密钥 。 对称加密的要求 (1)需要强大的加密算法。算法至少应该满足:即使…

防火墙iptables介绍
防火墙: netfilter/iptables是集成在Linux2.4.X版本内核中的包过滤防火墙系统。该架构可以实现数据包过滤,网络地址转换以及数据包管理功能。linux中防火墙分为两部分:netfilter和iptables。netfilter位于内核空间,目前是Linux内核…

企业局域网的组建
写在前面的话 随着计算机技术发展啊,办公无纸化、网络化已经成为一种趋势。 企业局域网的概述 企业中可能有多台计算机,同时还可能有其他的硬件设备,比如打印机、扫描仪和数码相机等。通过组建小型网络,可以共享企业内部各种软、硬…
python3 线程池源码解析_5分钟看懂系列:Python 线程池原理及实现
概述传统多线程方案会使用“即时创建, 即时销毁”的策略。尽管与创建进程相比,创建线程的时间已经大大的缩短,但是如果提交给线程的任务是执行时间较短,而且执行次数极其频繁,那么服务器将处于不停的创建线程ÿ…

区块链+能源,能擦出什么样的火花?
链客,专为开发者而生,有问必答! 此文章来自区块链技术社区,未经允许拒绝转载。 区块链从闯入能源行业的那一天起,就引起了行业内外人群的高度关注,关于能源区块链的争论与质疑不断搅动人们的神经。区块链能…
JS学习梳理(三)类型和语法
类型 JavaScript 有七种内置类型:null、undefined、boolean、number、string、object 和symbol,可以使用typeof 运算符来查看typeof返回的都是字符串很多开发人员将undefined 和undeclared 混为一谈, 但在JavaScript 中它们是两码事。undefin…

北师大历史系65 级同学聚会宁夏【之七】——在中阿之轴、西夏王陵、董府、板桥道堂、鸿乐府及告别宴会...
北师大历史系65级同学在中阿之轴 庞心田、王庆云、李建宇、樊淑爱、何明书、郑文范、李建宇夫人、惠晓秋、边聪民、登高夫人、张登高、杨家兴、杨森翔 西夏王陵 北师大历史系65级同学在西夏王陵 北师大历史系65级同学在西夏王陵 郑文范、王庆云在沙湖 北师大历史系65级同学在董…

会声会影水墨遮罩如何变大_自媒体长期网赚项目: 自媒体如何打造自己的自媒体知识付费课程(干货)...
小编简介:猫哥,自媒体人,9年互联网营销实战经验,乐于为大家分享实战经验,希望认识更多志同道合的朋友。面对现在知识付费的时代,知识就是财富,能把自己储存的知识转化为财富的人并不多ÿ…

OBS源代码阅读笔记
链客,专为开发者而生,有问必答! 此文章来自区块链技术社区,未经允许拒绝转载。 obs配置文件加载:bool OBSBasic::InitBasicConfig(); OBS认证信息加载,貌似还没有实现吗? void Auth::Load(){ …
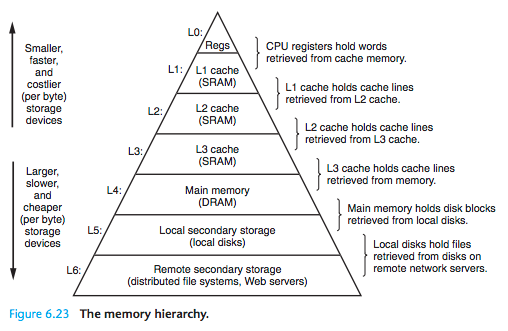
存储器结构层次(二)
局部性: 局部性分为时间局部性和空间局部性:Locality is typically described as having two distinct forms: temporal locality and spatial locality. In a program with good temporal locality, a memory location that is referenced once is like…