.net里鼠标选中的text数据怎么获取_Python数据科学实践 | 爬虫1

点击上方蓝色字体,关注我们
大家好,基于Python的数据科学实践课程又到来了,大家尽情学习吧。本期内容主要由智亿同学与政委联合推出。
前面几章大家学习了如何利用Python处理与清洗数据,如何探索性数据分析,以及如何利用统计与机器学习方法进行建模。但是,很明显我们忽视了一个最原始的问题:数据从何而来。没有数据,这就好比,你学了十八般武艺,可是没有让你施展的地方一样难受。大家不要忘记,提出问题,采集数据,然后才是你的十八般武艺的施展。本章将会讲解Python的爬虫模块,目的是让你学习的Python技术有用武之地。
爬虫,可能同学们都有所“耳闻”,但是对爬虫是什么还不甚了解。
爬虫,全称“网络蜘蛛”。爬虫能干什么呢?一言以蔽之,替代人工采集数据。比如,某吃货想挑选出西安全城的火锅店评分最高的前10家,怎么办呢?首先,得寻找一家在线点评网站,如百度糯米(网站截图如下所示)。
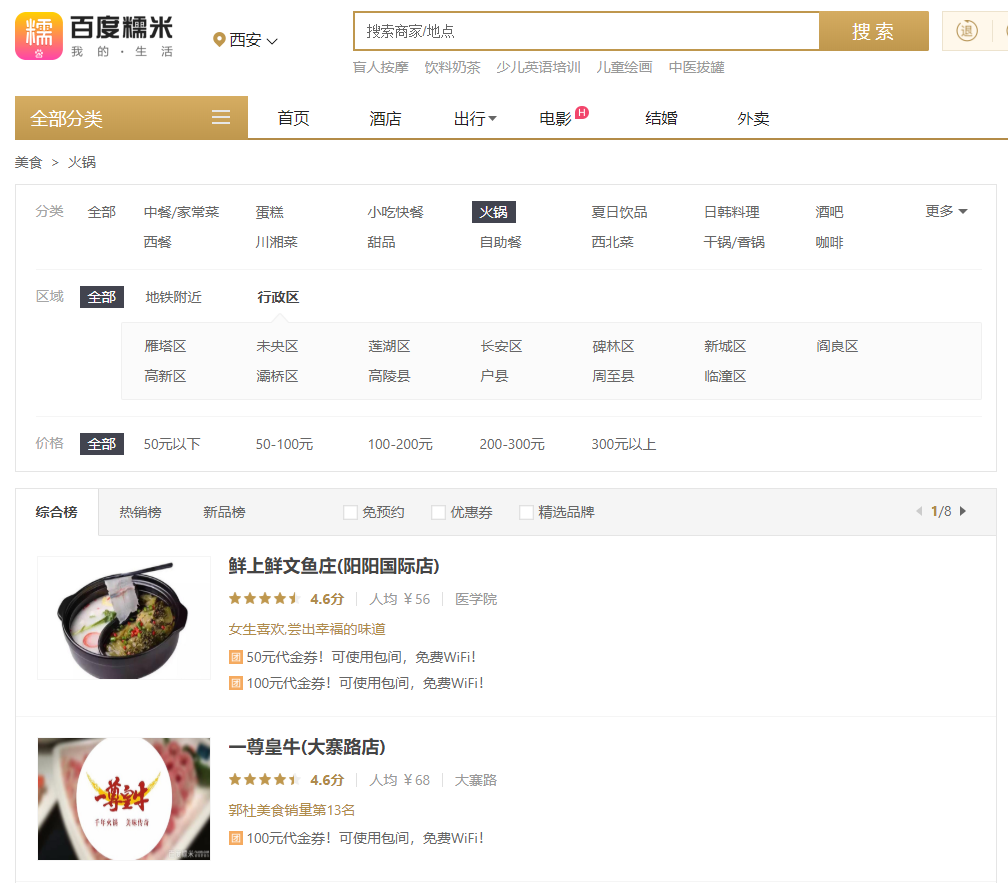
图7-1 百度糯米网站截图
每页25条数据,一共有8页,共计176条数据。
最原始的办法是,勤劳的鼠标左键 + ctrl+c 到excel中,再按评分排序。在数据量少、字段少的情况下,这么做的弊端可能并不明显。但是,现在如果需要店名、评分、人均、地址、优惠活动、营业时间、买家评论等等,恐怕再勤劳的同学也会勇敢的说“不”。
这时候爬虫就有了用武之地——自动化采集网页数据,存储成结构化的数据便于后续分析。数据采集,往往是数据科学实践的第一步——毕竟,巧妇难为无米之炊嘛!
从本章开始,让我们一起来揭开爬虫“神秘的面纱”。学习完本章后,希望同学们能在遇到这类机械性的体力劳动面前,勇敢的说“不”!
注意,本书定位是“入门+实战”,旨在让读者能够快速熟悉、快速上手。因此,只讲解最核心的知识点和函数使用,即使不了解背后原理,应对日常的数据采集也绰绰有余。对原理感兴趣的同学,请自行学习相关文档。
7.1 初级篇—单页面静态爬虫
本小节将学会:
● 了解网络请求的基本原理;
● 学习如何使用requests对网站发起请求;
● 了解网页的基本构成;
● 学习如何使用BeautifulSoup解析网页;
● 学习如何将解析结果存入文件;
学完以上,我们就能掌握最简单的爬虫。
在开始之前,请学习或下载:
● Chrome浏览器
● HTML的基础知识
http://www.w3school.com.cn/html/html_jianjie.asp
● HTTP的基础知识
https://www.w3cschool.cn/http/u9ktefmo.html
仅需明白:
1.网页的元素都是由DOM树进行定位的。
2.网页的元素标记是用<>尖括号表示的,不同的标签有不同的效果。
3.HTTP的基本方法GET的工作原理。
建议先掌握以上知识再继续学习后续教程会更加顺畅。
本章运行环境为:Python3.5.2,requests2.19.1,bs4 4.6.0
7.1.1 入门 —— 一级页面采集第一步 寻找数据源在现实情况下,只有充分了解数据分析的对象(如西安的火锅店为分析对象)才能开始寻找数据源。寻找数据源的过程不是一蹴而就的,不是仅从数据丰富度考虑数据源,往往需要对比分析,如爬取难度、爬取时间等,综合考虑后进行选取。
针对西安火锅团购数据,结合餐饮O2O平台的具体情况,有很多个备选平台:美团、大众点评、饿了么、口碑、百度糯米。
表7-1 各个平台的数据优劣势对比
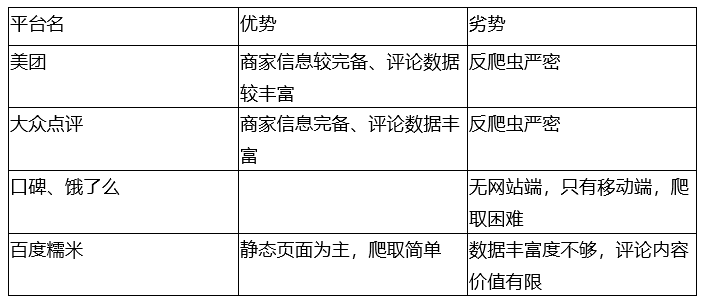
从数据角度考虑,美团和大众点评的数据最为丰富,数据采集最有价值;然而,由于反爬虫机制严密,所需知识点已经超过本书作为“入门读物”的定位,所以并不适合初学者;口碑和饿了么由于没有网页端,爬取也较为困难;百度糯米的页面以静态为主,虽然数据丰富度不够,但比较适合初学者。
综合以上考虑,本书以百度糯米作为数据源进行爬取。
第二步 分析网站请求流程确定了数据源后,第二步是分析网站的请求流程。
所有的互联网应用,用户首先感知到或者能接触到的一定是URL,即网址。只有通过网址才能发起对资源的请求,即网址的作用是替用户定位资源。因此,请求流程的分析一定是围绕分析URL的构成而展开的。
首先,进入百度糯米的西安页面(URL1) https://xa.nuomi.com/
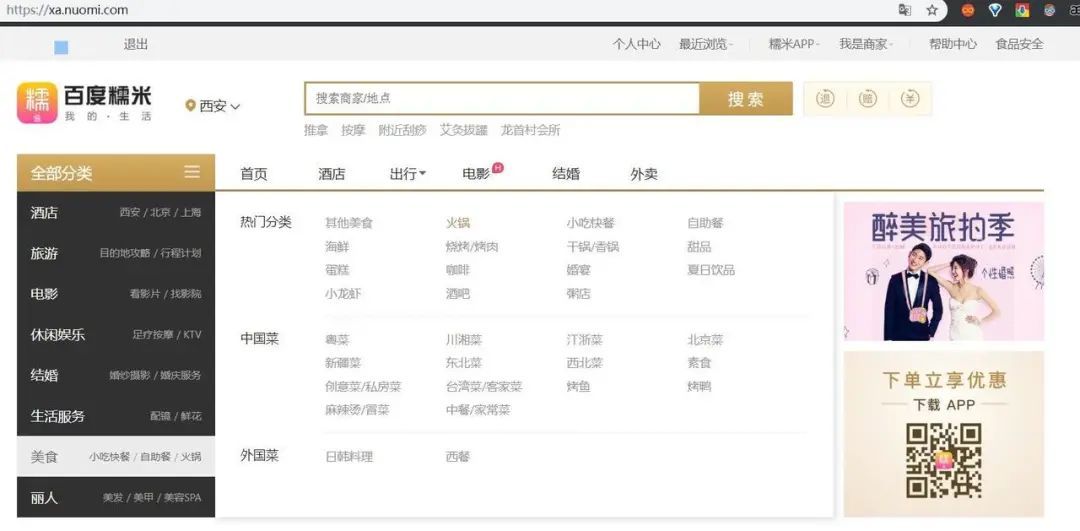
图7-2 百度糯米西安首页
点击“火锅”分类,进入火锅的列表页。可以看到,页面的URL (URL2) 变成了https://xa.nuomi.com/364。数字“364”,暂且称为火锅的分类ID号。
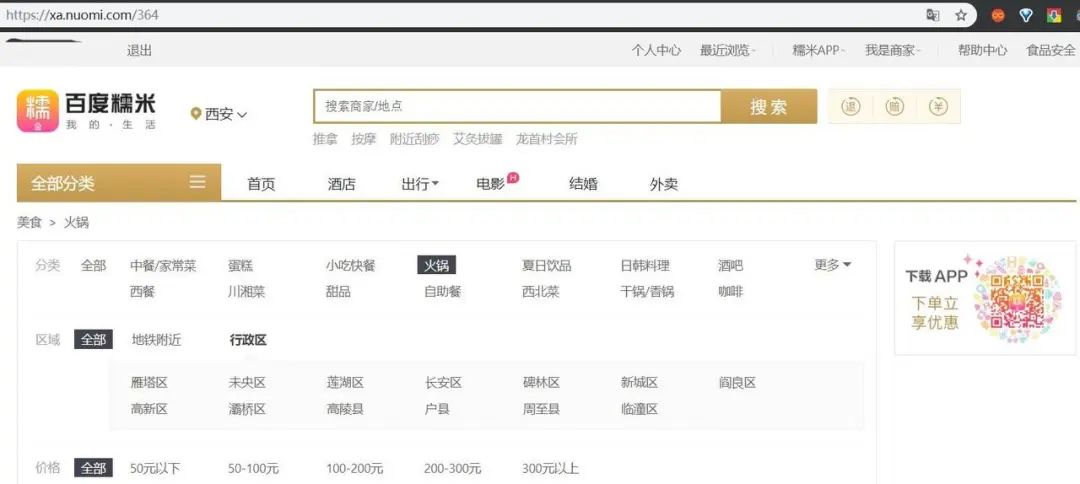
图7-3 百度糯米列表页
这时候,推荐使用Chrome浏览器(其他浏览器也可,但调试界面可能并没有Chrome清楚直观),在页面空白处点击鼠标右键(或ctrl+shift+I),点击Inpect,调起Chrome 开发者工具。
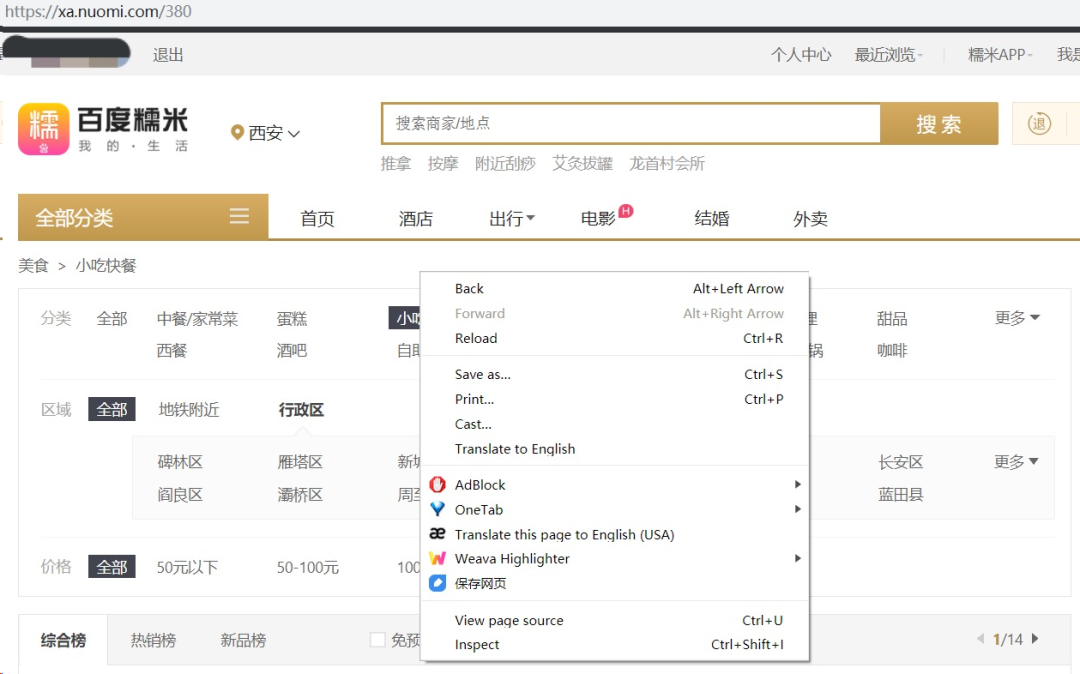
图7-4 审查网页元素
点击弹出面板左上角的“鼠标”按钮(选中后可定位HTML的元素位置)。选中商家信息的列表,我们也找到了每一个商家信息所对应的HTML代码。
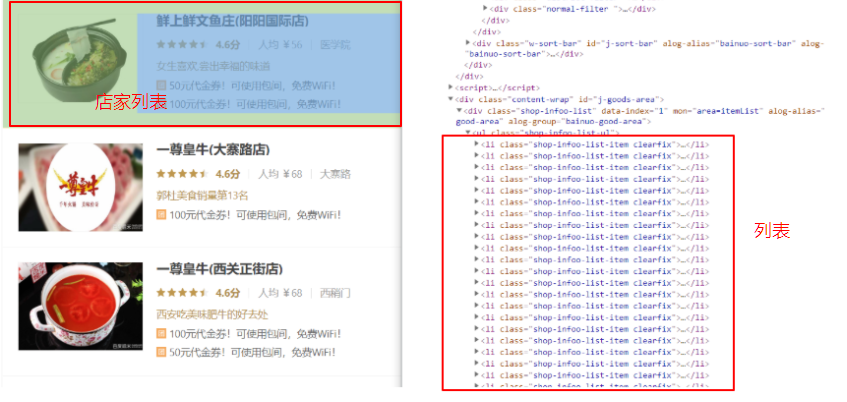
图7-5 找到对应网页元素
接下来,我们通过编写第一个爬虫脚本采集这些数据。
第三步 解析网站代码通过第二步的分析,聪明的你就已经大致明白爬取思路是:1. 先爬取分类ID号(火锅分类是364),用于构造列表页请求的URL;2.再解析每一个分类下的商家列表信息。
● 爬取分类ID号
表7-2 需要用到的API

例7-2
import requests
from bs4 import BeautifulSoup
url = 'https://xa.nuomi.com/364'
# 1. 向上述url发起HTTP请求
html = requests.get(url=url)
# 2. 转换解析网页的编码方式
html.encoding = html.apparent_encoding
# 3. 将请求的html解析成DOM树
soup = BeautifulSoup(html.text, 'lxml')
# 4. 寻找元素所在位置,并提取
shop_list = soup.select('#j-goods-area > div.shop-infoo-list > ul > li')
shop_dict = {}
for shop in shop_list:
name = shop.select('a:nth-of-type(2) > h3')[0].get_text()
score = shop.find('span', {"class": 'shop-infoo-list-color-gold'})
if score is None:
continue
else:
score = score.text
shop_dict[name] = score
# 5. 打印结果
print(shop_dict)运行结果如下图7-6。

图7-6 采集结果
注意:步骤2中,网页声明的编码方式可能与网页真实的编码不一致,需要进行显式转换。有时这么做仍然会失败,具体会在本章末尾介绍方法。
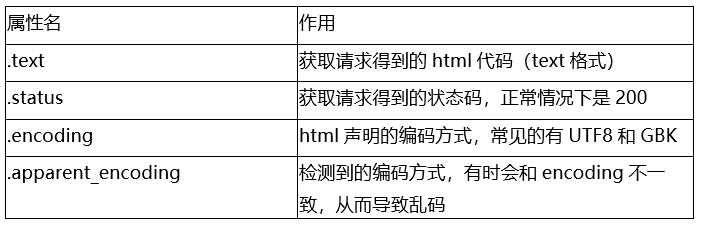
步骤2中,获取的html变量包含诸多属性,常见的有
表7-3 常见属性
步骤3中,'lxml'是常用的解析方式,足以满足常见的网站解析,这里不再赘述。
步骤4中,解析的css\xpath路径可通过Chrome开发者工具直接粘贴复制,如下图。
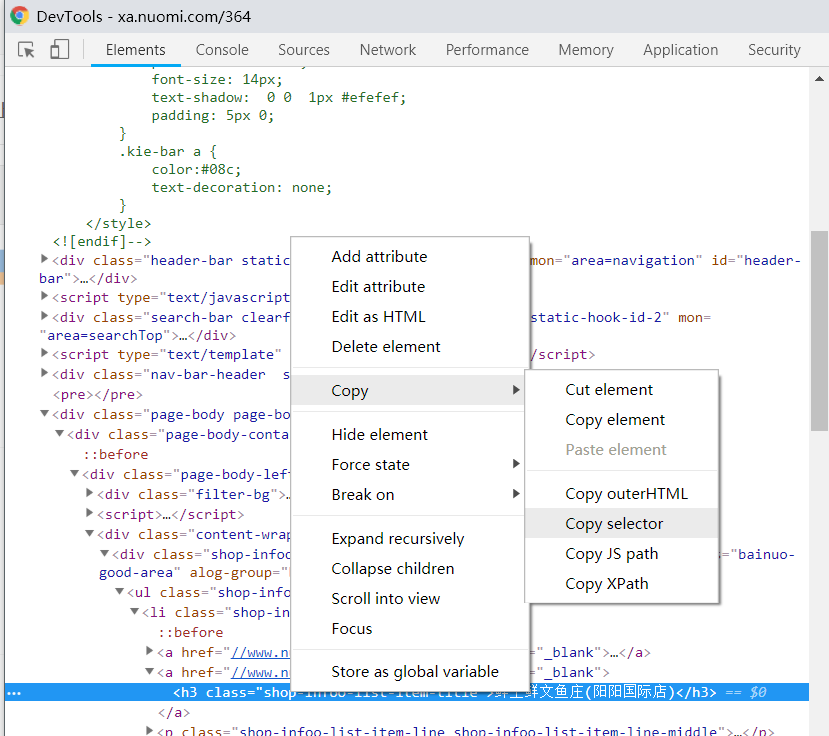
图7-7 网页开发工具使用
表7-4 BeautifulSoup的常用方法包括
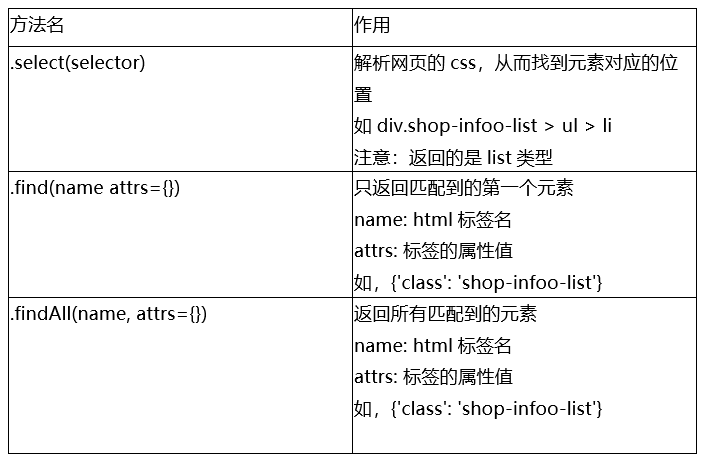
解析元素位置后,得到的仍然是html代码,我们需要进一步将其转化成需要的数据。
表7-5
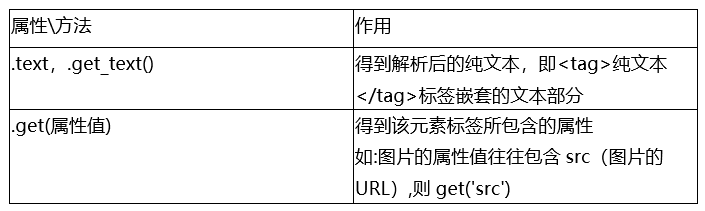
但是要注意:
1.如果标签是多个重复的格式(如、
2.经常会出现解析的css\xpath路径解析结果为空的情况,这需要不断调整解析的路径。如果调整路径还不成功,当跳过这部分数据量不大的情况下,可考虑直接跳过为空的部分(我们并不应该企图把所有数据一条不落的爬下来,而应该对比调整爬虫的时间和损失的数据量对比,综合各种因素进行选择)。
第四步 存储页面和数据一般来说,要先爬取完页面,存成本地文件,再解析,这样防止出错又要重新爬。在上面代码中添加一段存储的代码,以及把解析结果存成pandas保存起来。
例7-3 存储页面和数据
import requests
from bs4 import BeautifulSoup
url = 'https://xa.nuomi.com/364'
# 1. 向上述url发起HTTP请求
html = requests.get(url=url)
# 2. 转换解析网页的编码方式
html.encoding = html.apparent_encoding
# 3. 存储静态页面
if html.status_code == 200:
with open('364.html', 'w+', encoding='utf8') as f:
f.write(html.text)
else:
print('状态码非200,请求出错')
# 4. 读取静态页面
with open('364.html', 'r', encoding='utf8') as f:
content = f.read()
# 5. 将请求的html解析成DOM树
soup = BeautifulSoup(html.text, 'lxml')
# 6. 寻找元素所在位置,并提取
shop_list = soup.select('#j-goods-area > div.shop-infoo-list > ul > li')
shop_dict = {}
for shop in shop_list:
name = shop.select('a:nth-of-type(2) > h3')[0].get_text()
score = shop.find('span', {"class": 'shop-infoo-list-color-gold'})
if score is None:
continue
else:
score = score.text
shop_dict[name] = score
# 5. 打印结果
print(shop_dict)
# 6. 转变成DataFrame并存储成excel
import pandas as pd
results = pd.DataFrame([value for value in shop_dict.values()], index=shop_dict.keys(), columns=['评分'])
results.index.name = '店名'
print(results)
results.to_excel('364.xlsx', encoding='utf8')
最终结果如下图7-8。

图7-8 pandas读取解析结果
注意,这个例子在解析之前,先将html存成本地文件,再读取,这样可以很大程度上避免在爬取时网络请求出错,而导致程序中断,此时所有数据都得重新爬取,得不偿失。
最后,将解析的结果转变成DataFrame结构存储成excel(后面章节还会讲述存储到数据库中的方法)。
7.1.2 进阶 —— 二级页面采集然而,这只是一级界面,我们往往需要更加详细的信息,也就是列表页点进具体某个商家的详情页。这里,我们点击“一尊黄牛”,发现URL的变化成了https://www.nuomi.com/shop/10811751
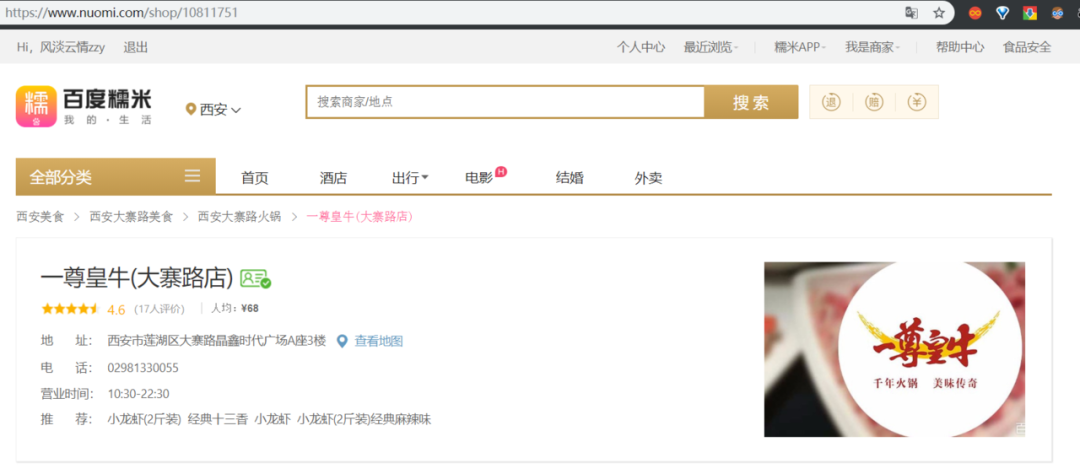
图7-9 商家详情页
显然,这个URL后面这串数字代表商家的ID号,这个URL必然在列表页中可寻找。首先,回到列表页。然后,打开开发者工具查看元素。不难发现,a标签中的href属性就是需要得到的URL。那么如何提取出来呢?可使用上表提到的.get()方法。
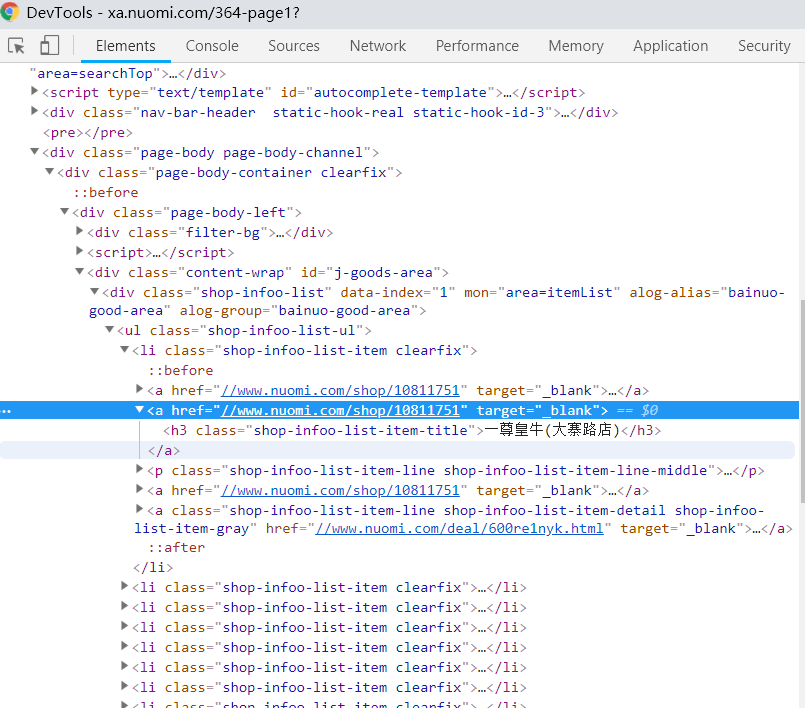
图7-10 网页开发工具使用
例7-4
shop_dict = {}
for shop in shop_list:
name = shop.select('a:nth-of-type(2) > h3')[0].get_text()
href = 'http:' + shop.select('a:nth-of-type(2)')[0].get('href')
score = shop.find('span', {"class": 'shop-infoo-list-color-gold'})
if score is None:
continue
else:
score = score.text
shop_dict[name] = [score, href]最终结果展示如下图为:

图7-11 解析结果
可以看到,所有商家的URL都提取了出来。读者只需要再次构造HTTP请求,对这些URL返回的结果进行解析、存储即可,这里不再赘述。
好了今天就先讲到这里。
▼往期精彩回顾▼初步搭建数据科学工作环境Conda的使用
Spyder入门
Jupyter入门
Markdown
简单读写数据
数据类型
数据结构
控制流
函数与模块
Numpy
pandas1
pandas2
pandas3
pandas4
绘图模块1
绘图模块2
绘图模块3
绘图模块4
统计建模1
统计建模2
统计建模3
统计建模4
机器学习模块1
机器学习模块2
文本分析1
文本分析2


相关文章:

redis实现对账(集合比较)功能
现状:每日在进行系统之间的订单对账时,往往是这样的操作流程; 1.从外部系统拉取数据存入本地数据库; 2.查询本地订单数据集合localSet; 3.查询外部系统订单数据集合outerSet; 4.以本地localSet为基准,对照o…
Javascript刷题 》 查找数组元素位置
找出元素 item 在给定数组 arr 中的位置 输出描述: function indexOf(arr, item) {..... } 如果数组中存在 item,则返回元素在数组中的位置,否则返回 -1 输入例子: indexOf([ 1, 2, 3, 4 ], 3) 输出例子: 2 实现方法 1、先将arr转换成字符串,…

Go 语言函数
链客,专为开发者而生,有问必答! 此文章来自区块链技术社区,未经允许拒绝转载。 函数是基本的代码块,用于执行一个任务。 Go 语言最少有个 main() 函数。 你可以通过函数来划分不同功能,逻辑上每个函数执…

终端主题_再见 XShell 和 ITerm 2,是时候拥抱全平台高颜值终端工具 Hyper 了!
点击上方“涛哥聊Python”,选择“星标”公众号重磅干货,第一时间送达转自:运维之美不论是 macOS 还是 Windows 下,我们都不推荐使用系统自带终端。无论是可拓展性还是可编程性都被「系统自带」这样的特点限制。特别是 Windows 下的…
每天一个linux命令(8):cp 命令
cp命令用来复制文件或者目录,是Linux系统中最常用的命令之一。一般情况下,shell会设置一个别名,在命令行下复制文件时,如果目标文件已经存在,就会询问是否覆盖,不管你是否使用-i参数。但是如果是在shell脚本…
samba srver on centos-7
切换到root用户安装samba,将windows登录用户admin映射到linux用户centos 安装samba并准备工作目录 yum install -y samba samba-client mkdir -p /var/samba/code chown -R centos:centos /var/samba/codetouch /etc/samba/smbusersecho "centos admin "…

以太坊数据结构MPT
链客,专为开发者而生,有问必答! 此文章来自区块链技术社区,未经允许拒绝转载。 MPT(Merkle Patricia Tries)是以太坊存储数据的核心数据结构,它是由Merkle Tree和Patricia Tree结合的一种树形结构,理解MP…
lambda在python中的用法_在python中对lambda使用.assign()方法
我在Python中运行以下代码:#Declaring these now for later use in the plotsTOP_CAP_TITLE Top 10 market capitalizationTOP_CAP_YLABEL % of total cap# Selecting the first 10 rows and setting the indexcap10 cap.loc[:10, :].set_index(id)# Calculating…

react 开发过程中的总结/归纳
1、点击元素,获取绑定该事件的父级元素,使用 e.currentTarget。e.target 获取的是,出发该事件的元素,该元素有可能是所绑定事件的元素的子元素。 2、使用 react router4 history 只能传递给儿子组件,不能传递给孙子组件…

kvm虚拟机--存储池配置梳理(转)
1.创建基于文件夹的存储池(目录) 2.定义存储池与其目录 1 # virsh pool-define-as vmdisk --type dir --target /data/vmfs 3.创建已定义的存储池 (1)创建已定义的存储池 1 # virsh pool-build vmdisk (2)查看已定义的存储池,存储池不激活无法…

区块链概况:什么是区块链
链客,专为开发者而生,有问必答! 此文章来自区块链技术社区,未经允许拒绝转载。 区块链技术自身仍然在飞速发展中,目前还缺乏统一的规范和标准。 wikipedia 给出的定义为: A blockchain —originally, b…

drx功能开启后_简单实用!小米手机中这些新功能真香
小米手机作为国产机热销品牌之一,它除了有好看的外观,还有很多隐藏的实用功能,今天小编就来和大家分享5个小米手机里你不知道的功能。Al电话助理看到陌生号码时,很多人第一反应就是挂掉,不想接听,但又担心自…
Ubuntu 8.04嵌入式交叉编译环境arm-linux-gcc搭建过程图解
Linux版本:Ubuntu8.04 内核版本:Linux 2.6.24 交叉编译器版本:arm-linux-gcc-3.4.1 交叉编译器下载链接: https://share.weiyun.com/5oxlS6X (密码:36R7) 前言 1、搭建交叉编译环境 安装、配置交…

Installshield 2015 实现检测某安装文件是否存在并运行安装
最近在用installshiled 2015做安装包,用了很长时间研究明白了怎样实现在安装成功界面显示一个checkbox,选中该checkbox,就会安装选中的安装包。 首先我们要有一个installshield的工程。 其次是判断是否要显示这个checkbox。我的需求是根据某个…

区块链概况:从数字货币说起
链客,专为开发者而生,有问必答! 此文章来自区块链技术社区,未经允许拒绝转载。 从数字货币说起 货币是人类文明发展过程中的一大发明,最重要的职能包括价值尺度、流通手段、贮藏手段。很难想象离开了货币,…

Android RecyclerView 基本使用
Android RecyclerView 基本使用 概述 RecyclerView出现已经有一段时间了,相信大家肯定不陌生了,大家可以通过导入support-v7对其进行使用。 据官方的介绍,该控件用于在有限的窗口中展示大量数据集,其实这样功能的控件我们并不陌生…
lisp语言cond和if套用_在'if'语句中设置多行条件的样式?
Harley Holco..679您不需要在第二个条件行上使用4个空格.也许用:if (cond1 val1 and cond2 val2 andcond3 val3 and cond4 val4):do_something另外,不要忘记空格比您想象的更灵活:if (cond1 val1 and cond2 val2 andcond3 val3 and cond4 val4):do_somethingif (cond1 …
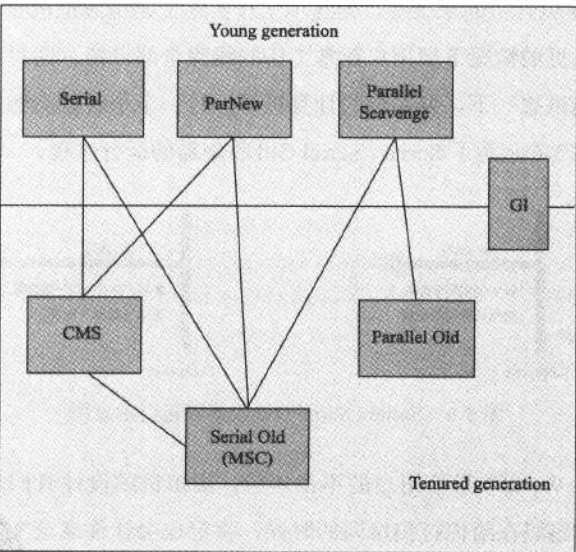
jvm七种垃圾收集器
JVM_七种垃圾收集器介绍 本文中的垃圾收集器研究背景为:HotSpotJDK7一、垃圾收集器概述如上图所示,垃圾回收算法一共有7个,3个属于年轻代、三个属于年老代,G1属于横跨年轻代和年老代的算法。JVM会从年轻代和年老代各选出一个算法进…

新手怎么学以太坊区块链开发?
链客,专为开发者而生,有问必答! 此文章来自区块链技术社区,未经允许拒绝转载。 在学习以太坊应用开发时,除了学习solidity开发智能合约,一个小白还应该补充 哪些知识?文本将给出相关的学习资源…
【题解】 bzoj1260: [CQOI2007]涂色paint (区间dp)
bzoj1260,懒得复制,戳我戳我 Solution: 这种题目我不会做qwq,太菜了区间打牌(dp) 用f[l][r]表示从l到r最少需要染几次色。状态转移方程: 1.\(f[l][r]min(f[l][i],f[i1][r]) (l<i<r)\) 这段染色等于俩段分别染色,…

[deviceone开发]-组件功能演示示例
一、简介 这个是官方比较早期对组件功能的展示集合,因为发布的比较早,只包含了部分组件,但是常用的组件和常用的功能都包含了。初学者推荐。二、效果图 三、相关下载 https://github.com/do-project/code4do/tree/master/demo四、相关讨论 ht…

联想g510升级换什么cpu好_老兵不死,十年前的联想 Y450 笔记本复活记
如果你是一个接触笔记本电脑比较早的用户,那么联想小Y的大名你一定不会陌生,作为联想旗下较为成功的产品线,彪悍的小Y在几年前就打出了名堂,而小Y系列笔记本里面又以 Y450 最为经典,Y450 引入 NVIDIA GT240M 中端移动显…

区块链和数据库
链客,专为开发者而生,有问必答! 此文章来自区块链技术社区,未经允许拒绝转载。 区块链技术是一种不依赖第三方、通过自身分散式节点进行网路数据的存储、验证、传递和交流的一种技术方案。因此,有人从金融会计的角度…

普通粒子群算法和优化方法
粒子群优化(PSO, particle swarm optimization) 是由Kennedy和Eberhart在1995年提出的一 种群智能优化方法。 优点:好理解容易实现,适合解决极值问题 缺点:容易过早收敛,容易陷入局部最优解,(如果初始点选的…

古人怎么称呼年龄
来自为知笔记(Wiz)转载于:https://www.cnblogs.com/sanyuanempire/p/6154780.html
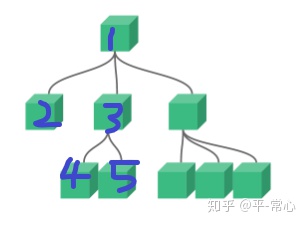
vue变量传值_vue组件与组件之间传值
目录一、父组件向子组件传值二、子组件向父组件传值三、兄弟组件之间的传值如上图所示,2是1的子组件,1是3的父组件,2和3是兄弟组件一、父组件向子组件传值:html代码:<div id"app"><v-app><!-- 用:xxxx&q…

区块链技术背后的运行逻辑
链客,专为开发者而生,有问必答! 此文章来自区块链技术社区,未经允许拒绝转载。 区块链技术可能是自互联网技术以来最伟大的发明。区块链可以在不需要有中央权威机构的情况下或不需要双方信任的情况下交换价值或财富。想像一下你…
scp遇到路径中有空格
sudo scp root1.1.1.1:/test/soft/123/Microsoft SQL Server 2000.iso . 错误! sudo scp root1.1.1.1:"/test/soft/123/Microsoft SQL Server 2000.iso" . 错误! sudo scp root1.1.1.1:/test/soft/123/Microsoft\ SQL\ Server\ 2000.…
bzoj 3262 陌上花开
本质是一个三维偏序,一位排序后cdq分治,一维在子函数里排序,一维用树状数组维护。 把三维相等的合并到一个里面。 1 #include<iostream>2 #include<cstdio>3 #include<algorithm>4 #include<cstring>5 #define N 100…
jspstudy启动mysql失败_MySql启动数据库设置初始密码
这一小节介绍在Mac OS、Linux、Windows上启动关闭重启MySQL服务,以及部分图形化界面对服务的操控。安装完成后,可以使用 service 命令启动 mysql 服务,在Mac上service命令不存在。命令行启动关闭重启MySQL服务在命令行终端启动 MySQL 非常方便…