从paxos到raft zab,为何raft能够“独领风骚”
文章目录
- RAFT出现的缘由
- RAFT 的实现
- STATE MACHINE
- Log Replicated State Machine
- Leader Election
- 基本角色
- 关键变量
- 基本选举过程
- Log Replicated
- 基本概念
- 基本操作
- Safety
- Log Replication: Consistency check
- Leader Election: Leader Completeness
- 总结
- RAFT 和 ZAB 的对比
- 参考文献:
阅读本篇之后,能够回答如下几个问题:
- paxos和raft的区别,为什么要在paxos基础上推出raft
- raft 如何保证分布式consensus 特性?
- Replicated Log State Machine 在raft中的作用。
- raft 相比于ZAB的区别。
本篇主要是几篇共识算法相关论文的汇总,综合做一个描述,希望能够让大家能够对共识算法:pxos, raft,zab 能够有一个全面的了解,方便在今后的使用中选择适合自己业务的共识算法。
这一些问题涉及的分布式共识算法细节会比较多,难免会有理解上的纰漏。如相关机制的描述有理解上的差异,欢迎留言一起讨论。
RAFT出现的缘由
raft论文【3】是在2016年发出的,在此之前到1998年之间 大家备受paxos的“折磨”【4】。主要原因还是说分布式发展太快,大数据的计算存储对分布式的能力需要越来越紧迫,而一个易理解,易实现的分布式共识算法是分布式系统的基础,能够极快得解决自己业务问题并领先同行(当然,核心还是能够为公司创造更多的价值,节约资源成本)。
而PAXOS 则成为各大公司的阻碍,复杂的证明细节,简略的实现细节,让研究者和开发者望而却步。
PAXOS原始论文【4】大家有兴趣可以简单看看,从问题描述到协议设计及相关一致性/正确性的完整证明,确实是严谨的学术论文,但并不适用于教育(国外大学会有分布式课程MIT6.824等)和工业化。即使后续推出了一个原理性的简化版论文【5】,但又因为细节过少,没有办法快速实现。只能作为分布式共识算法的鼻祖,供有兴趣的人取之。
到此大家也都比较清楚了,PAXOS 难以理解 也 难以实现,实属业界公有的分布式实现的痛点。
这里也基于一些大佬的总结,将PAXOS的简易原理描述做了一个总结,供大家参考,节约学习入门成本。
分布式共识算法:从PAXOS 到 Multi PAXOS
所以RAFT的出现就是为了解决PAXOS的两个问题,当然最终的结果是解决了,才有现在的etcd,braft,tikv等
接下来深入了解一下RAFT如何将复杂问题简单化。(当然一些数据证明肯定是站在PAXOS的基础上来描述的,才能够在raft中简单带过。)
RAFT 的实现
RAFT 认为自己相比于PAXOS 易于理解的原因除了简化了共识过程中的角色,更主要的是将复杂问题进行分治。
即 RAFT共识算法的实现总结为如下几个子问题:
- Leader Election
- Log Replicated
- Safety
- Membership Management
- Log Compaction
其中主要的过程是前面三个阶段,完成了leader的选举和日志的同步,并且这两个过程通过safety保证了前面两步的一致性和可靠性。
在详细描述选举过程之前需要对状态机(state machine) 以及 日志复制状态机(log replicated state machine)的原理做一个讲解,方便后续对RAFT的Log Replicated过程的理解。
STATE MACHINE
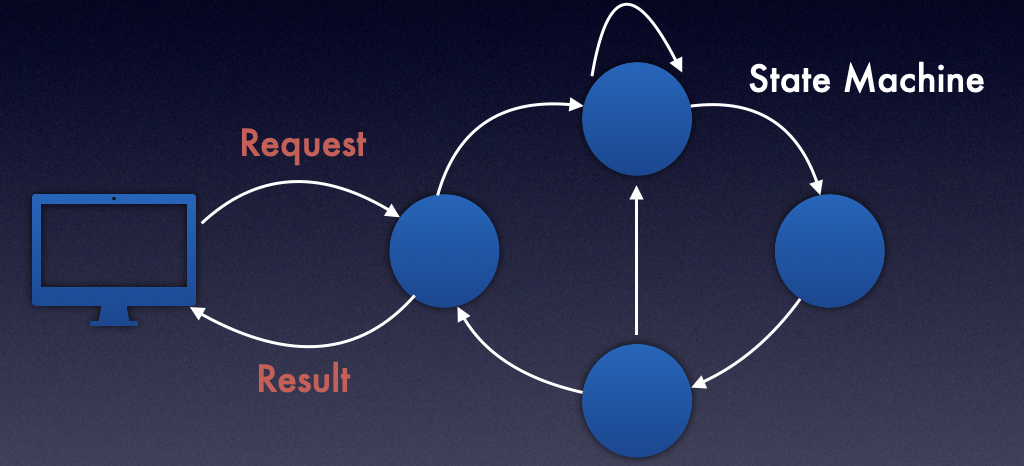
如上图,状态机 是一些内部数据/指令执行的状态迁移过程,通过状态机能够和外部客户端进行通信。
状态机的主要作用是:
- 管理集群内部状态
- 和客户端进行交互
使用状态机的分布式系统,分布式存储,分布式服务 很多,包括HDFS的name node, ceph的blustore, MemCached等
基于状态机实现的日志复制状态机(Log Replicated State Machine)则是分布式共识算法 一致性实现的基础。
Log Replicated State Machine
日志复制状态机的基本构造如下:
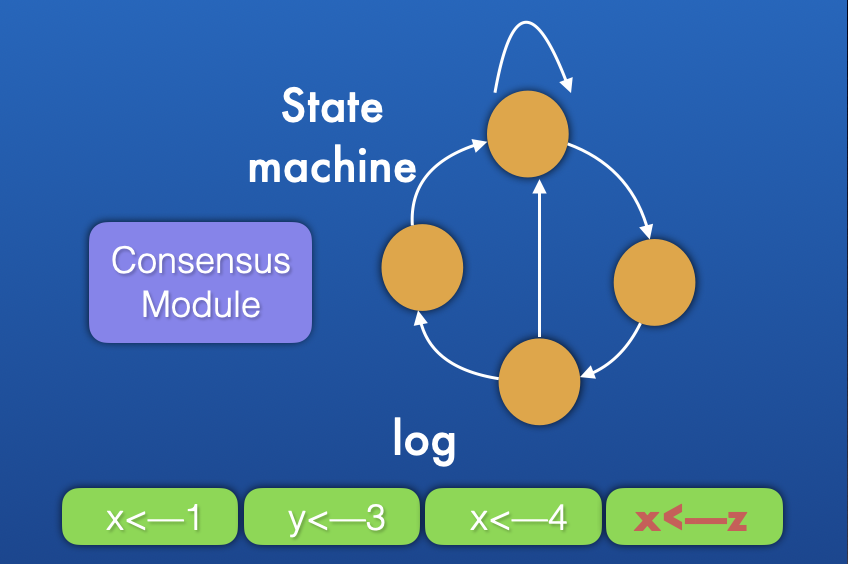
每一个日志复制状态机 存在于一个节点或者一个集群的角色服务上(follower/leader),内部主要有三个模块:
- Consensus Module 共识模块。主要作用有两个:完成来自客户端请求的解析,将客户端请求解析为能够被状态机识别的 log entry;和其他server的共识模块进行rpc通信,转发客户端的请求。
- log 日志列表。用来存放共识模块解析出来的log entry,追加写。
- state machine 状态机。用来执行日志列表中的日志条目,一般是command的形态。
一个共识集群中每一个参与集群选举、一致性保障的角色服务进程中都会维护一个这样的日志复制状态机。
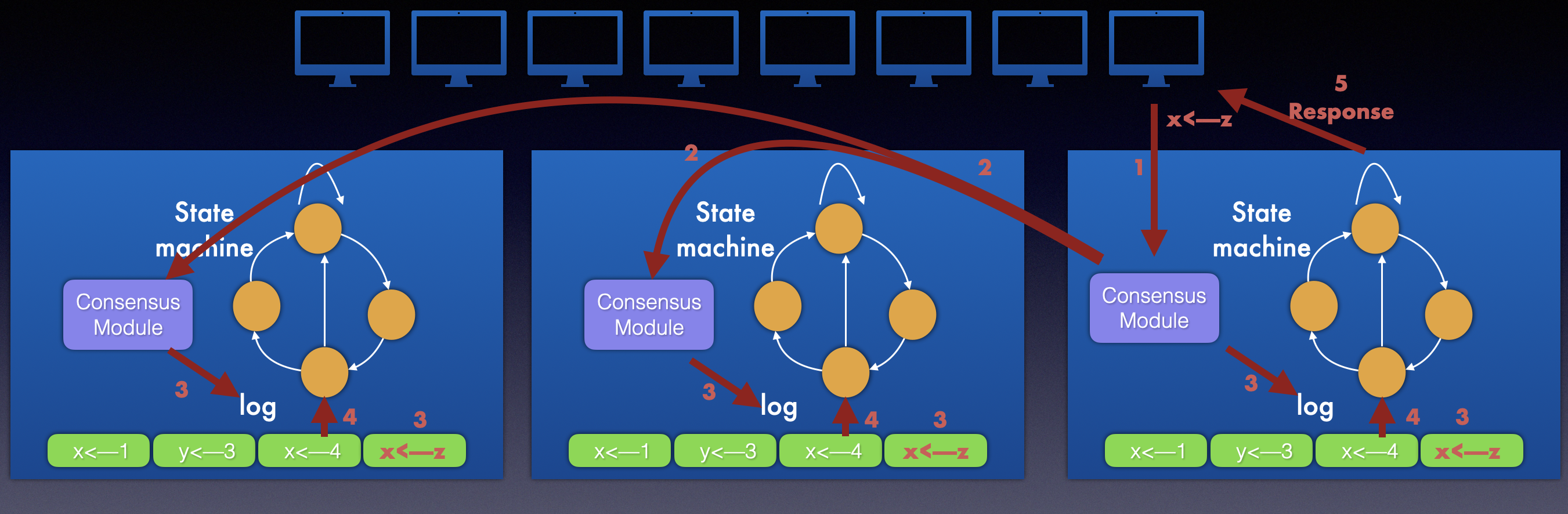 如上示意图代表整个状态机 集群 从接受到客户端请求到完成日志复制最终回复客户端的 过程。
如上示意图代表整个状态机 集群 从接受到客户端请求到完成日志复制最终回复客户端的 过程。
模拟这个复制状态机集群 处理客户端请求的过程 可以分为五步:
- 客户端将请求 x<–z 发送个leader上的共识模块
- leader的共识模块将客户端请求转发给follower上的共识模块,并保证收到大多数(quroum,大于等于n/2 + 1,n表示集群节点个数)的回应
- 每个server的复制状态机将各自共识模块介些的log entry追加到自己本地的log列表中
- 每个server的复制状态机并行提交log entry中的日志条目到状态机中 执行日志中的指令,比如将x设置为z。这一步可以看作是commit阶段,需要持久化。
- 完成了commit 之后,leader向客户大返回成功。
当然这个复制状态机并不能代表完整的raft的日志复制的过程,一些日志复制的细节上会有差异,但是整个日志复制到完成提交的过程是 raft Log Replicated的基础。
接下来我们详细探讨一下整个raft各个阶段的基本实现过程,揣摩将共识问题分解为一个个子问题一一实现的好处。
PS: raft论文中会完整得描述从选举到日志合并和成员变更的过程,但日志合并和成员变更本身会有非常多的细节,全部放在本篇则会过于冗余。本篇的定位是raft的基本原理,也就是会描述Leader Election , Log Replicated 以及 以上两个阶段的稳定性Safety保证。
Leader Election
介绍日志选举前需要对整个raft中的角色以及其作用做一个统一的介绍。
基本角色
这里的角色在实际raft相关的应用中是以服务进程的形式存在的。

follower,所有角色开始时的状态,等待接受leader心跳RPCs,如果收不到则会变成CandidateCandidate,候选人。是变成Leader的上一个角色,候选人会向其他所有节点发送RequestVote RPCs,如果收到集群大多数的回复,则会将自己角色变更为Leader,并发送AppendEntries RPCs。Leader,集群的皇帝/主人…,raft能够保证每一个集群仅有一个leader。负责和客户端进行通信,并将客户端请求转发给集群其他成员。
关键变量
Election Timeout选举超时时间。即Cadidate 向集群其他节点发送vote请求时,如果在Election Timeout时间内没有收到大多数的回复,则会重新发送vote rpc。以上将实际
RequestVote简写为vote ,就是请求投票的rpc一般这个超时时间是在
150-300ms的随机时间,为了防止集群出现频繁的 split vote 影响leader选举效率的情况,将这个超时时间取在155-300ms范围内的随机时间。当然,这个数值也是经过测试的,超时时间设置在150-300ms 之间能够保证raft集群 leader的稳定性,也可以将超时时间设置的比较低(12-24ms),但是存在的网络延迟则会导致一些不必要的leader选举。关于splite vote的情况可以看如下图,图片来自raft可视化官网【6】:
两个节点收到对方的vote请求之前变成了candidate,发送了各自的request vote。Heartbeats Timeout心跳超时时间。follower接受来自leader的心跳,如果在heartbeats timeout这个时间段内follower没有收到来自leader的AppendEntries RPCs,则follower会重新触发选举。收到了,则重置follower 本地的 heartbeats timeout。RequestVote RPCs以上两个超时过程也说了,投票是的rpc请求AppendEntries RPCsleader 同步数据时的rpc请求。
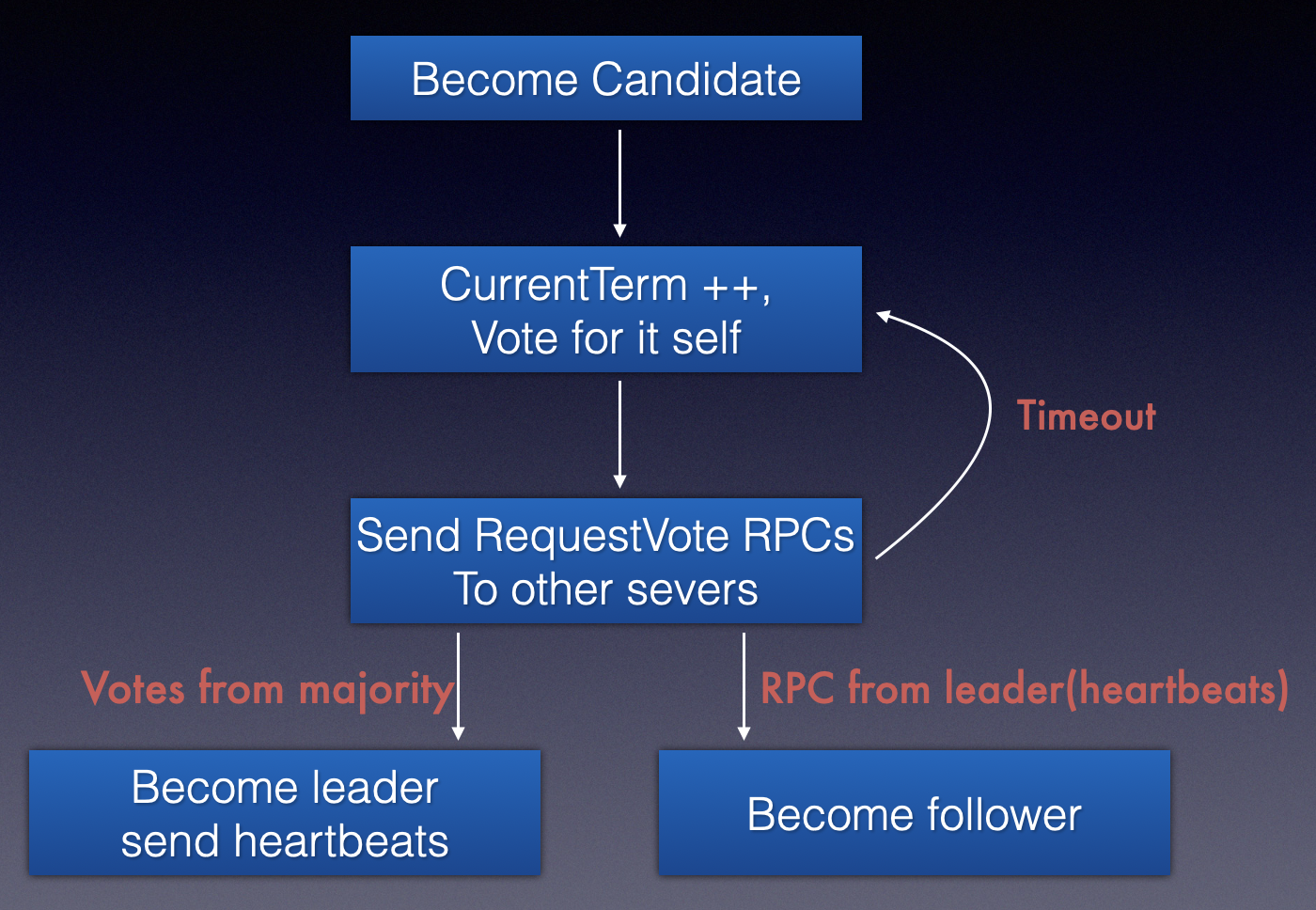
基本选举过程
在之前的描述过程中基本选举已有有一些描述了,这里通过角色变化图展示一下。

主要是三个角色的变化完成leader选举。
- follower 没有收到heartbead 变成Candidate
- Candiate 投票给自己,并发送投票请求给其他server ,收到大多数的相应则变成leader,否则等待超时再次变成Candidate 发送投票 或 接受其他的投票。
- Leader 发送AppendEntries 复制日志到其他follower;维护心跳来保证自己被其他follower可见。心跳超时或发现更高的Term 就变成follower。
Leader选举过程中除了之前提到的基本变量,还会有一个Term 的概念。
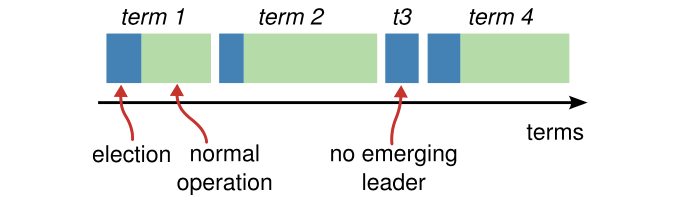
这是raft论文中的一幅Term概念描述的图。简单来说Term 可以用一个数字来表示,主要提现的是raft集群Leader的存活周期。即当前Term为1,维持了一段时间,这段时间集群的leader没有发生变化。而当Term变成2,表示一定发生了Leader的变更(leader所在服务器跪了),但不一定表示Leader一定被选举出来了。
上图中的 term3 则完全没有选出leader,这种情况的出现就是上文中描述的splite vote的情况,这个时候Term也会增加,当时并没有leader 被选出来,在ceph/zookeeper中 其实就类比于Epoch。
关于Term在candidate 投票过程中发生的变化 如下图。
到此整个raft 选主过程就描述完了,一些一致性保证的问题会在日志复制 讲完之后进一步整体描述。
Log Replicated
日志复制的过程就会用到我们前面讲到的Log Replicated State Machine,raft 是基于这个机制来实现日志复制的基本过程。
讲述日志复制的过程之前 还对日志复制的基本概念做一个描述
基本概念
除了日志复制状态机已经完整介绍过了,这里主要介绍一下raft中的log entry 列表。

如上图,其中每一个角色都有自己的log entry列表,列表中的每一个方格代表一条entry。
方格中有一个数字1、2、3,一条entry x<–3、y<–1,数字代表的是Term,entry是能被状态机执行的commnad。
最上面有一排数字:1、2、3… 表示entry索引,是entry的全局唯一标识。
从这个日志列表中,我们能够看到通过index + term 能够唯一标识一条entry,且整个集群正常工作的成员的entry和index需要保持一致,上图中存在部分节点出现过异常导致现在的entry出现不一致的情况,这个时候leader会负责完成Log Replicated 来将follower的entry补全。
基本操作
leader 完成Log Replicated 的过程是通过如下几步完成的:
- 客户端发送请求到leader
- leader 将客户端的请求转化成entry 追加到log列表中
- leader 通过 AppendEntries RPCs 将log entry 发送到其他follower
- 新的log entry被committed 需要经过如下几步:
- leader 首先在自己本地的状态机执行log entry中的command(落盘持久化),并向客户端返回成功
- leader 唤醒follower节点各自本地按顺序提交log entry
- follower节点将log entry添加到状态机中完成持久化操作
- 如果发生follower异常/宕机,会持续尝试发送AppendEntries RPCs
从上面的基本操作我们能够发现当前Term 下的 Leader 一定是拥有最全的且已经完成了持久化的log entry,整个过程是通过日志复制状态机来完成的。
接下来会讨论一些异常情况,即follower的日志相比于leader的日志存在缺失的情况,Leader该如何处理?还有如何保证选举出来的leader拥有最全的日志信息?
Safety
先回答第一个问题,leader和follower 日志不一致的情况,leader会怎么处理。
Log Replication: Consistency check
进入正题之前 关注如下几个需要注意的前提
- AppendEntries RPCs 内容 包括<index, Term>, 分别是log entry在日志列表中的位置index 和 它所处leader 的Term号。
- follower 收到leader发送的entry, 必须在<index,Term>和内容匹配,匹配则接受并应用在自己本地的复制状态机中;如果不匹配,follower会拒绝接受当前的Log Entry,返回reject
此时Leader 会调整<index,Term>信息,即发送本地列表中已经提交的上一个log enry 给follower - 通过induction step 不断的回退尝试 方式来完成 Leader和follower 的日志匹配属性。
Example1:
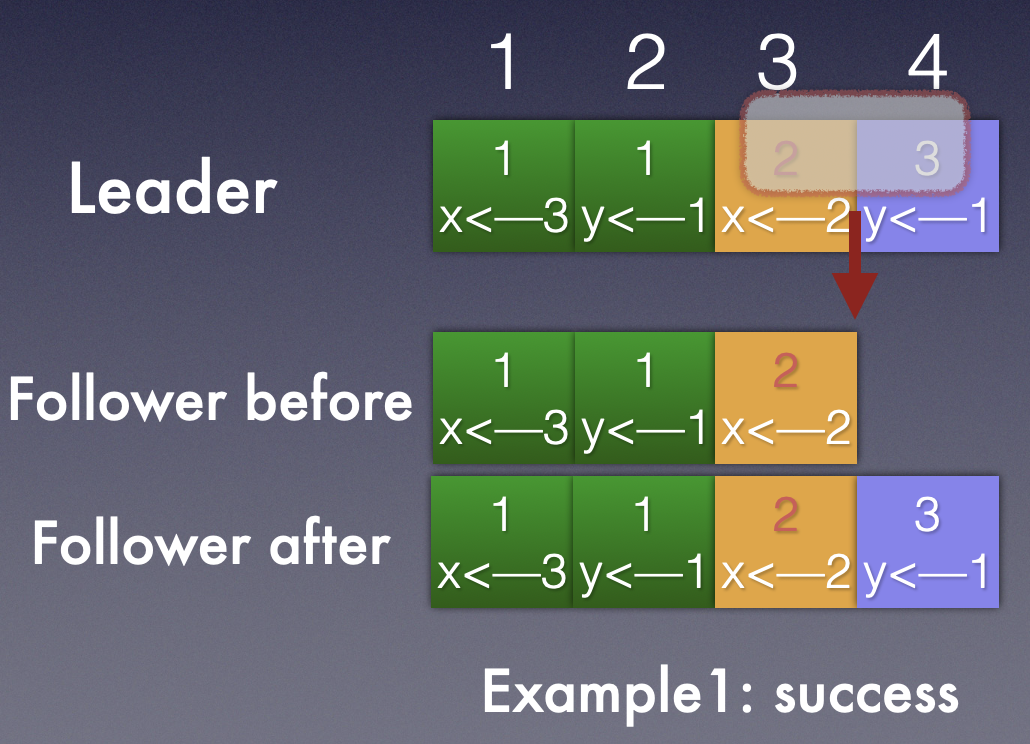
follower 日志落后于leader的日志,y<–1 这一条日志相比于Leader缺失。这种情况的出现是由于follower 在Term 3可能宕机,可能网络延迟,总之没有收到leader 的rpc,重新启动之后需要和leader坐日志同步。
按照如上几条前提:
- Leader 发送<4,3> 的log AppendEntries给follower,follower发现本地最新的是<3,2>,则拒绝leader 的log entry。
- Leader induction step,调整发送<3,2> 给follower, follower发现匹配,也就是<3,2>以前的log entry都完成了匹配,那follower就可以接受最新的leader的log entry了。
- 接下来的AppendEntries PRCs leader就可以携带最新的log entry 给follower。
最终完成集群log entry的完全匹配。
Example 2:
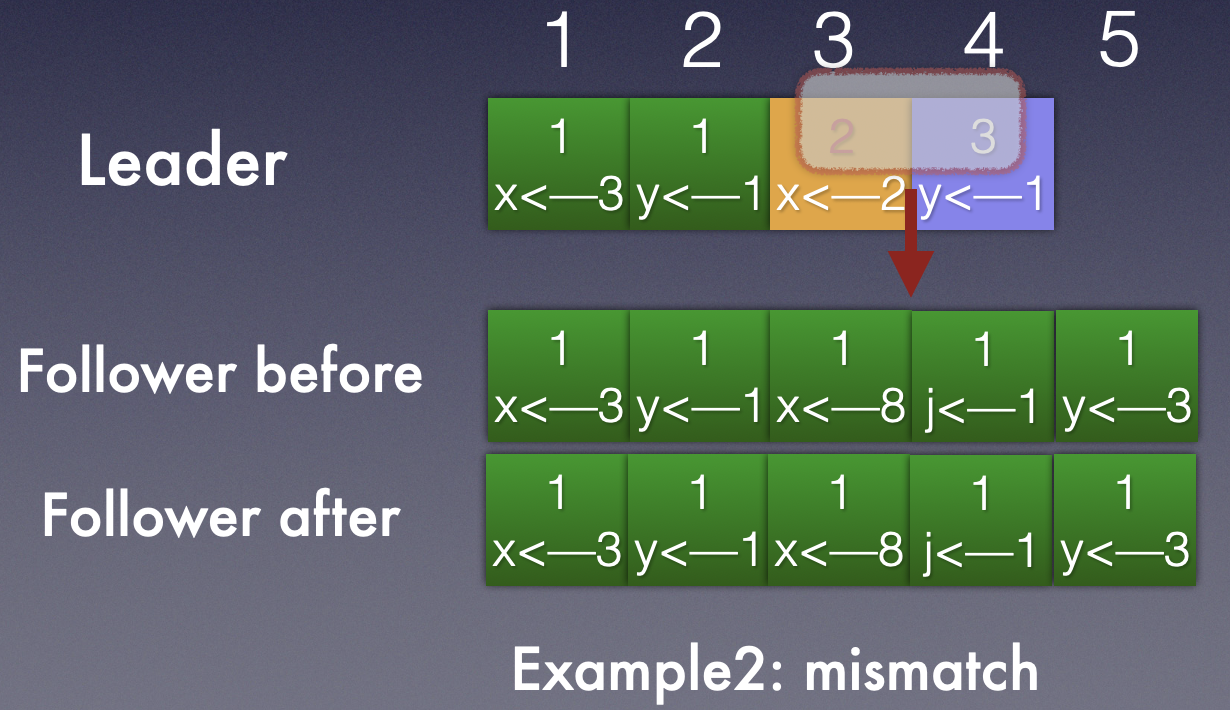
这个情况是follower的日志多余leader的日志,这种的情况是出现在网络分区的情况。两个分区分别发送自己的rpc,一个分区中存在旧的leader,并未发生Term的变更;而另一个分区会重新选举leader ,维护更高版本的Term。到现在分区重新恢复,就出现了Leader和follower之间的数据 Term相差较多。
还是按照日志一致性前提,通过induction step不断回退日志版本,leader发送的日志回退到<3,2>还是没有发现和follower的日志达成匹配,所以会继续回退,发送<2,1>的entry信息。
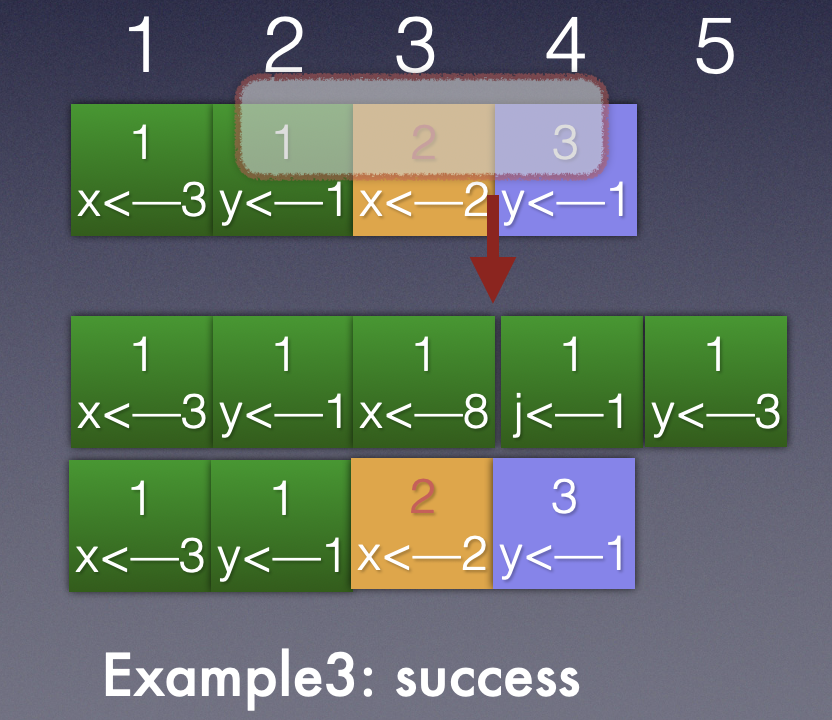
就是如上这种情况,最终发现<2,1>能够匹配,则会将<2,1>之后的leader entry发送给follower,从而覆盖掉follower的低term log。
这里会衍生出来的一些问题:
按照之前描述的leader election过程,可能会选出一个leader 的log entry比follower 最新的log entry版本低,那导致的情况就是这个新的leader 会把follower数据覆盖掉,这种情况可能吗?
接下来需要深入探讨一下Leader Election的限制了。
Leader Election: Leader Completeness
细节描述:
- 一旦一个log entry 在当前集群完成提交,未来选举的所有leader都需要包含这条entry
- 日志不全的server 无法被成功选举
- 选举过程中的 candidate 发送的 RequestVote RPCs 需要包含 本地最新的index和term
- 接受投票的server 发现收到的index和term 比自己本地还旧,会拒绝选举
- log entry是按照<lastTerm, lastIndex> 进行比较的,先比较lastTerm的大小,如果相等则比较lastIndex
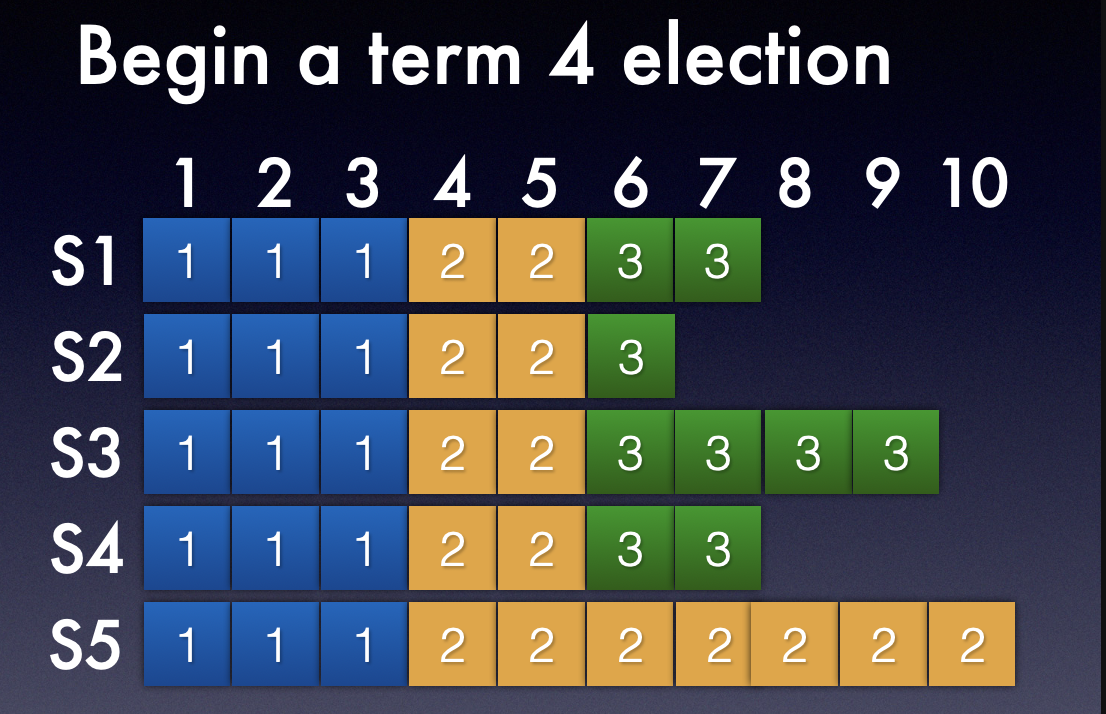
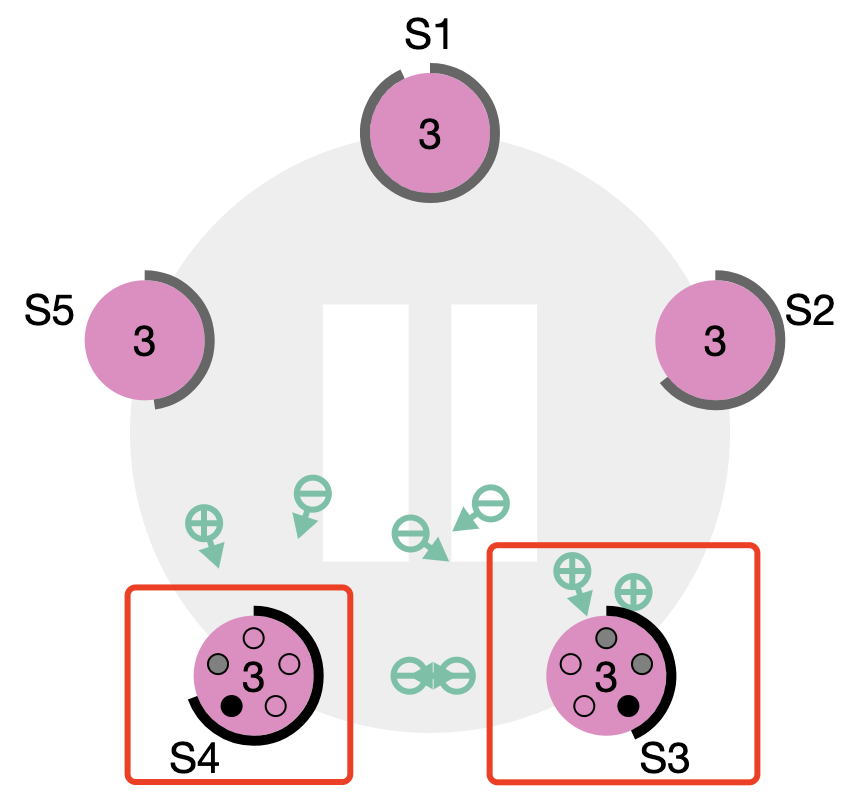
如上图,几个不同的server有自己的log entry列表。
- 如果S4 的RequestVote RPCs 先到达其他server ,按照<lastTerm, lastIndex>比较规则,它会收到S1,S2,S5的选票并当选为leader,同时后续也会将S3中的9,10 日志覆盖掉。
- 如果S2的RequestVote RPCs 先到达其他server,显然,它无法赢得选举;没有选票返回,直到超时,会进入下一轮重新选举。
- 当然 S3现发起的 vote 肯定能够当选。
这样,选举出来的Leader能够拥有集群大多数的log entry,而对于S3 server这样的情况显然9和10 index log entry已经可以被丢弃,当时的leader也仅仅在自己本地提交,其他follower一个也没有收到提交的entry(集群内部网络严重问题)。
总结
到此整个raft的基本过程就讲完了,除了后续的成员变更和日志合并之外。整个raft实现的共识算法 基本过程也就两个阶段:Leader Election, Log Replicated。
在这两个阶段基础上通过两种一致性 完成了异常情况下的集群数据一致性保障。
- Leader Election的一致性通过<lastTerm, lastIndex> 比较完成,最新的leader拥有大多数成员认可的最全的日志;
- Log Replicated 一致性通过 induction step, 还是比较日志的term和index,旧了leader就发送更旧的,直到完全和follower匹配,再补充新的日志。
raft的易理解特性 从论文给的数据能够很明显得看出来,让一部分学生分别学习raft和paxos 并完成相关的实验。
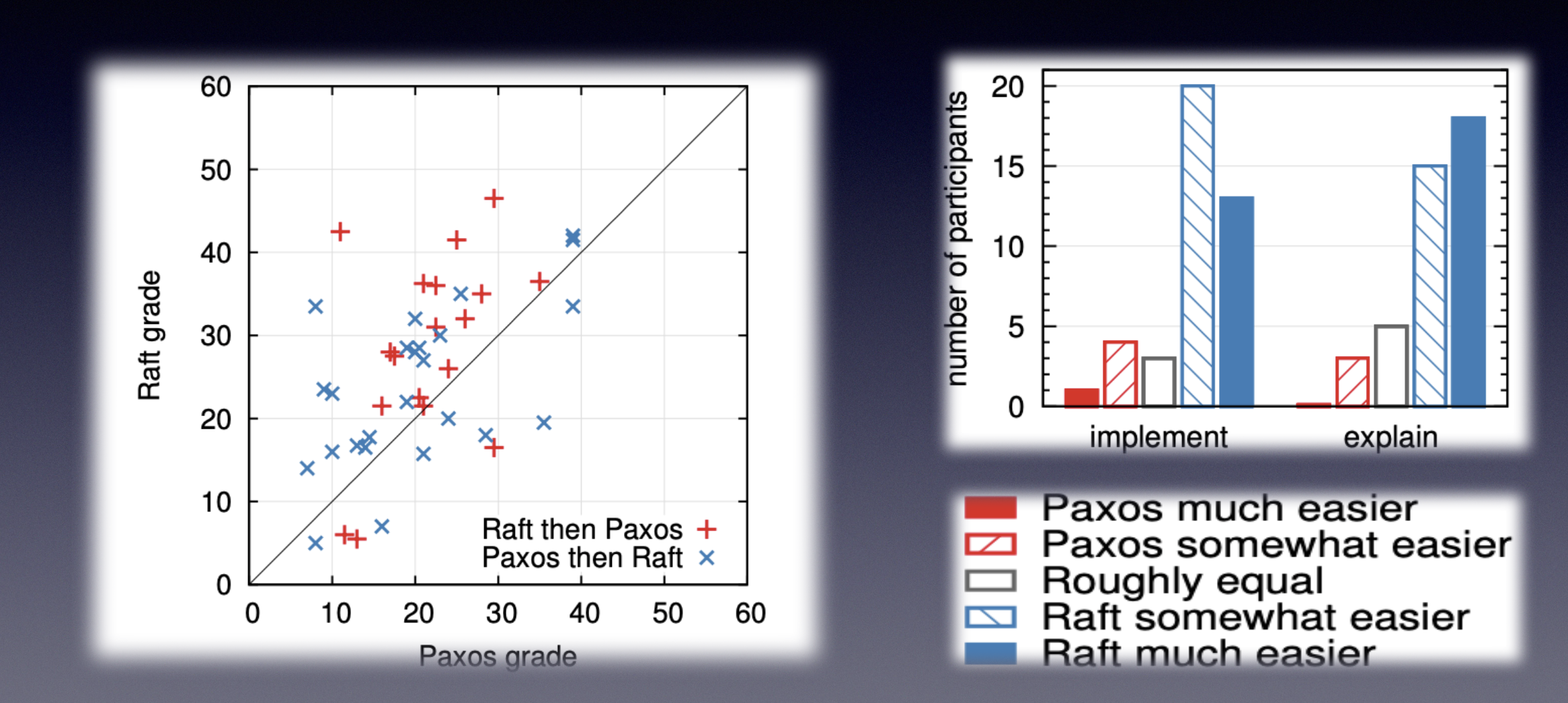
可以发现学生的反馈中 raft更易理解,更易实现,对应的测试分数也比paxos更高。
RAFT 和 ZAB 的对比
关于ZAB协议的基本过程可以参考:
zookeeper ZAB协议原理浅析
相比于RAFT 从内部描述上的不同主要如下:
- ZAB 的 entry(history entry) 的数据同步方向是从follower向leader发送;raft则是leader负责向follower同步log entry
- ZAB 中一个leader周期是epoch; raft则是 term
从基本选举和日志同步的流程上来看:
ZAB 需要经过的rpc更多,整个leader election + discovery + synchonization 的RPC次数超过RAFT 几倍;伴随着复杂度也是几倍。
从提供的服务来看:
zookeeper能够保证强一致性,选举出来的leader一定拥有最全最新的日志,不是raft 中leader 比大多数新就可以。
zookeeper 能够提供分布式锁,分布式队列,分布式配置管理 这样的协调服务,处于应用之外。
raft能够集成到应用内部,完成一个分布式存储(tikv),分布式kv(etcd), 分布式数据库(各个大厂自研)等更加完备的分布式系统,已有的业界raft实现都能够在raft论文基础上快速完成自己想要的分布式系统的开发。
完整的raft,paxos,zab对比如下:

参考文献:
1. Zookeeper: https://pdos.csail.mit.edu/6.824/papers/zookeeper.pdf
2. ZAB: http://www.tcs.hut.fi/Studies/T-79.5001/reports/2012-deSouzaMedeiros.pdf
3. RAFT: https://raft.github.io/raft.pdf
4.PAXOS: https://lamport.azurewebsites.net/pubs/lamport-paxos.pdf
5.PAXOS SIMPLE https://lamport.azurewebsites.net/pubs/paxos-simple.pdf
6.raft website
相关文章:
Java项目:前台+后台精品水果商城系统设计和实现(java+Springboot+ssm+mysql+jsp+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 本系统主要实现的功能有: 前台用户的登录注册,水果商品的展示,水果的购物车, 购物车新增结算等等,银行卡的支付绑定,收货…
Android屏幕像素密度适配详解
讲到像素密度,我们先要搞明白什么是像素密度,像素密度的字面上的意思为手机屏幕上一定尺寸区域内像素的个数。在Android开发中, 我们一般会使用每英寸像素密度(dpi)这样一个单位来表示手机屏幕的像素密度,d…

如让自己想学不好shell编程都困难?
众所周知,shell是linux运维必备的技术,必须要掌握,但是shell语法复杂,灵活,网友掌握了语法也不知道如何应用到实际运维中,老男孩培训shell编程给所有linux运维人员带来了学好shell的法宝,老男孩培训2014最新…
sqlserver可将字符转成数字再进行sum,如果varchar类型中存放的都是数字
sqlserver语法: select sum(cast(score as int)) as score from 表名; 注意:int是整型,在实际操作中根据自己需要的类型转换。转载于:https://www.cnblogs.com/MisMe/p/10690748.html
LSM 优化系列(六)-- 【ATC‘20】MatrixKV : NVM 的PMEM 在 LSM-tree的write stall和写放大上的优化
文章目录LSM 问题背景MatrixKV 设计细节整体架构介绍Matrix Container介绍ReceiverRowTableCompactorSpace managementColumn Compaction介绍对于Column Compaction的总结读加速 Cross-row Hint SearchMatrixKv 写入完整流程MatrixKV 读取完整流程MatrixKV 性能总结这篇论文大家…
Java项目:前台+后台在线考试系统设计和实现(java+Springboot+ssm+mysql+jsp+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 本系统主要实现的功能有: 学生以及老师的注册登录,在线考试,错题查询,学生管理,问题管理,错题管理,错题查询…
修改nginx服务器类型
通常nginx服务器不隐藏服务器类型及版本信息 curl -I http://www.aaa.com 获取web服务器的类型和版本代码 HTTP/1.1 200 OK Server: nginx nginx/0.8.53 Date: Tue, 14 Dec 2010 08:10:06 GMT Content-Type: text/html Content-Length: 151 Last-Modified: Mon, 13 Dec 2…
JS 自带函数
JS数组方法汇总 array数组元素的添加和删除js数组元素的添加和删除一直比较迷惑,今天终于找到详细说明的资料了,先给个我测试的代码^-^var arr new Array();arr[0] "aaa";arr[1] "bbb";arr[2] "ccc";//alert(arr.leng…
Flink学习笔记:Operators之CoGroup及Join操作
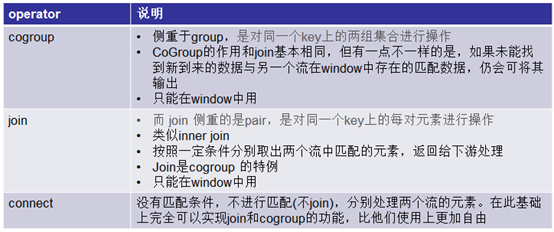
本文为《Flink大数据项目实战》学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz 1. Window CoGroup与Join 1.1回顾RDBMS各种join 假设有两个表A和B 1.…

Rocksdb 的优秀代码(二)-- 工业级 打点系统 实现分享
文章目录前言数据结构选型打点代码设计耗时打点请求计数打点打点总结前言 一个完善的分布式系统一定是需要完善的打点统计,不论是对系统内核 还是 对系统使用者都是十分必要的。系统的客户需要直观得看到这个系统的性能相关的指标来决定是否使用以及如何最大化使用…
JVM中可生成的最大Thread数量
最近想测试下Openfire下的最大并发数,需要开大量线程来模拟客户端。对于一个JVM实例到底能开多少个线程一直心存疑惑,所以打算实际测试下,简单google了把,找到影响线程数量的因素有下面几个: -Xms intial java heap s…

Java项目:在线电影售票系统设计和实现(java+Springboot+ssm+mysql+jsp+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 前台: 1、正在上映的电影浏览查看。 2、影院信息浏览查看。 3、新闻咨询信息浏览查看。 4、地域信息查看切换。 5、用户注册登录。 6、电影排期查看。 7、在线选座生成…
matlab正态分布
normrnd(mu, sigma, m,n) 返回m x n的随机数,正态分布均值mu,标准差sigma。 mvnrnd(mu, sigma, m) 返回m个随机数(点),是多元正太分布,mu是均值向量,sigma是协方差。 x normrnd(0,4,1,100000);…
MYSQL语句
-- 一、管理数据库-- 1.1 创建数据库CREATE DATABASE day15; SHOW DATABASES; CREATE TABLE student( id INT, NAME VARCHAR(20), age INT); -- 查看表SHOW TABLES; -- 二、管理数据-- 1.1插入数据(insert into)-- 需求: 往学生表插入数据INS…
Intel Optane PMEM 概览
文章目录前言基本架构编程模型PMDK接口架构接口概览pmdk 安装开发文档汇总PMEM性能官方性能实测性能前言 随着以PCM 为存储单元的3D XPoint 非易失存储介质 不断精进的工艺,以及 上层硬件协议栈的飞速发展,为非易失内存这样硬件的出现提供了技术工艺基础…

Java项目:新闻发布系统(java+Springboot+ssm+mysql+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能: 区分为管理员用户和普通用户,管理员用户能删除评论, 调整新闻显示/隐藏,修改新闻,删除普通用户,普通用户能 登陆浏…

Linux下搭建Lotus Domino集群
Linux下搭建Lotus Domino 集群本文内容是Linux平台下Lotus Domino服务器部署案例(http://chenguang.blog.51cto.com/350944/1334595)的另一个模块,所以大家首先要有以上基础之后然后继续实验。集群是 Lotus Domino Server 提供的最重要特性之…

Centos下卸载openjdk并安装自定义jdk
1、查看是否安装了openjdk java -version 2、查看需要卸载的openjdk信息,其中只需要删除红色框标记的地方 rpm -qa | grep java 3、删除openjdk rpm -e --nodeps 需要删除的java组件 4、创建文件夹java mkdir java 5、到官网下载linux版本的jdk(如果不能…
pmdk -- libpmemlog 介绍
文章目录1. libpmemlog 应用背景2. libpmemlog 使用方式2.1 基本接口2.2 接口使用3. Libpmemlog 性能3.1 write sys call 性能3.2 libpmemlog 性能1. libpmemlog 应用背景 本文介绍的是英特尔 傲腾持久化内存 pmdk中 的一个持久化日志的库。 我们正常系统中会将日志 形成一个…
Java项目:家庭财务管理系统(java+Springboot+ssm+mysql+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能: 家庭财务管理系统,具有收入统计,支出统计,汇总报 表,工资录入,其他收入等录入开支信息,echart图标插 …
(原创)c++primer(第五版)--1.3 注释简介
注释可以帮助人类读者理解程序。注释通常用于概述算法,确定变量的用途,或者结束晦涩难懂的代码段。编译器会忽略注释,因此注释对程序的行为或者性能不会有任何影响。 虽然编辑器会忽略注释,但读者并不会。即使系统文档的其他部分已…
BZOJ 1503 郁闷的出纳员(splay)
题目链接:http://www.lydsy.com/JudgeOnline/problem.php?id1503 题意:给出一个数列(初始为空),给出一个最小值Min,当数列中的数字小于Min时自动删除。四种操作:(1)数列…
javascript ES6 新特性之 扩展运算符 三个点 ...
对于 ES6 新特性中的 ... 可以简单的理解为下面一句话就可以了: 对象中的扩展运算符(...)用于取出参数对象中的所有可遍历属性,拷贝到当前对象之中。 作用类似于 Object.assign() 方法,我们先来看一下 Object.assign() 方法: Obje…
字符串匹配算法 -- BM(Boyer-Moore) 和 KMP(Knuth-Morris-Pratt)详细设计及实现
文章目录1. 算法背景2. BM(Boyer-Moore)算法2.1 坏字符规则(bad character rule)2.2 好后缀规则(good suffix shift)2.3 复杂度及完整代码3. KMP(Knuth Morris Pratt)算法3.1 好前缀 和 坏字符规则3.2 高效构建 失效函数3.3 复杂度…

Java项目:中小医院信息管理系统(java+Springboot+ssm+mysql+maven+jsp)
源码获取:博客首页 "资源" 里下载! 一、项目简述 本系统功能包括:实现了挂号收费,门诊管理,划价收 费,药房取药,体检管理,药房管理,系统维护等各个模块功能&a…
DB2load遇到SQL3508N错误
SQL3508N装入或装入查询期间,当存取类型为 "<文件类型>" 的文件或路径时出错。原因码:"<原因码>"。路径:"<路径/ 文件>"。 [more]解释: 装入或装入查询处理期间,在尝…
【cocos2d-x 手游研发小技巧(3)Android界面分辨率适配方案】
先感叹一下吧~~android的各种分辨率各种适配虐我千百遍,每次新项目我依旧待它如初恋 每家公司都有自己项目工程适配的方案,这种东西就是没有最好,只有最适合!!! 这次新项目专项针对android,目的…
git submodule 使用场景汇总
文章目录1. 前言2. 基础命令介绍2.1 场景一:已有仓库,添加一个子模块2.2 场景二:已有仓库,添加一个子模块的特定分支2.3 场景三:已有仓库,更新子模块内容2.4 场景四:已有仓库,变更子…
Java项目:在线商城系统(前后端分离+java+vue+Springboot+ssm+mysql+maven+redis)
源码获取:博客首页 "资源" 里下载! 一、项目简述 本系统功能包括: 前台展示后台管理,包括最基本的用户登录注册,下单, 购物车,购买,结算,订单查询,…

自定义参数解析器,减少10%的代码
*** 赋值调用方法* 如果为空,默认调用name()方法* 该方法必须是一个不含参数的方法,否则将会调用失败* @return*/value() : value用于绑定请求参数和方法参数名一致时的对应关系。比如user?statusNo=1。方法的参数写法如下:getUser(@EnumParam(value=“statusNo”) int status) 或者 getUser(@EnumParam() int statusNo)valueMethod() : 赋值时调用枚举中的方法。