深度学习在自动驾驶感知领域的应用
程序员转行学什么语言?
https://edu.csdn.net/topic/ai30?utm_source=csdn_bw
本次直播课程是由深度学习资深研究者-杨阳博士从百度Apollo自动驾驶感知技术出发,讲解环境感知中深度学习的实用性与高效性。
课程从Apollo 3.5感知技术介绍、自动驾驶中的目标检测与识别、深度学习在目标检测中的意义、Apollo中深度学习的应用、百度深度学习框架对目标检测的实操五个方面着手,全面解读深度学习在目标检测中的运用。
以下是杨阳博士分享的全部内容,希望给各位开发者带来更多的帮助。

首先,本次课程将以百度Apollo自动驾驶技术为出发点,详解百度深度学习技术在Apollo自动驾驶目标检测中的应用。其次,基于百度深度学习框架对目标检测技术进一步探讨,最后理论联系实际,通过一个典型案例体验百度深度学习在环境感知中的实用性与高效性。
简要了解一下自动驾驶
首先我们可以从安全驾驶角度来简单了解自动驾驶的重要性。为什么我们需要自动驾驶?这里罗列了一些自动驾驶的优势,除了减少交通事故、节省燃料外,还涉及到获得更多自主休息的时间。此外,自动驾驶技术还有很多其它优点,例如可以轻轻松松停车,让老人开车相对更安全一些。

表中给出了全球对于自动驾驶技术的评级,包括从纯粹的人工驾驶L0级到高度的自动驾驶L4级。不过目前各国重点研发的还是有条件的自动驾驶,例如L3级的自动驾驶以及高度的自动驾驶L4级,完全的自动驾驶(L5级)目前还没有办法预测。
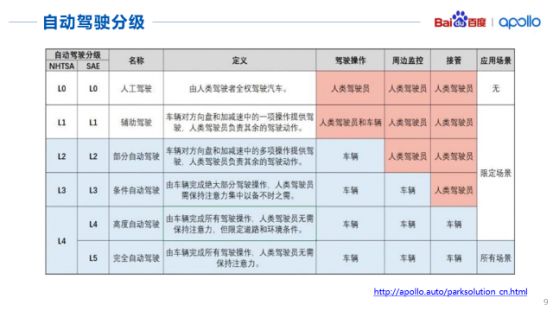
其中一些企业推出了有条件的自动驾驶,还有一些停留在部分自动驾驶L2级和辅助自动驾驶L1级的测试阶段,暂未投入到商用。
不过值得高兴的一点,百度今年刚刚推出了L4级的自动驾驶车辆以及相关解决方案,相信未来在L5级的自动驾驶领域,我们国家一定会有所突破,实现L5级自动驾驶指日可待。
接下来我们探究自动驾驶车辆的基本组成,以百度Apollo3.5的无人驾驶车辆为例,明确整个自动驾驶车辆包括哪些部分。首先,车辆顶端应配置360度的3D扫描雷达,以及前排阵列摄像头、后排摄像头阵列,同时还包含GPS天线、前置雷达等。这些都是用来对周围环境进行感知的。
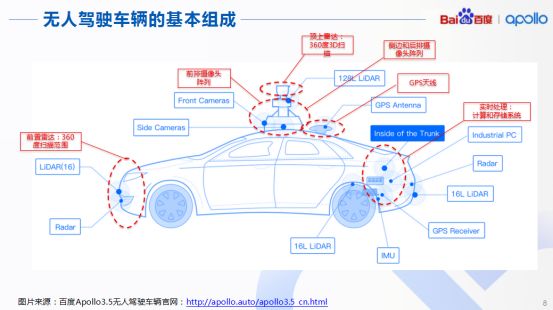
感知结果得到实时处理后,就会产生大量数据, 从而汇总到车后端的实时处理系统中,也就是计算和存储系统,随后做到汽车在行进过程中对车辆周围环境的完全感知。如今的Apollo3.5,传感器部分以及计算存储系统还是相当完善的。从Apollo完整框架分析,我们可以看到上端是云端服务,下端三层属于车端服务。
全新的Apollo3.5技术框架对其中14个模块进行了升级,主要分布在硬件系统以及软件系统中。例如,3.5版本感知算法加上全新的传感器升级,可以达到360度无死角的全面覆盖。

云端服务方面,涉及例如高精度地图、仿真数据平台、安全模块等。全新的基于多场景的决策和预测架构,使开发变得更加灵活与友好,所以一些开发者完全可以选择这种软件平台和硬件平台来进行相应开发,同时我们也将90%仿真驱动开放,大力提升开发者们的效率以及研发安全性。
Apollo对于自动驾驶具备至关重要的四个部分,我们也给予相应升级,包括规划、预测、感知以及定位。
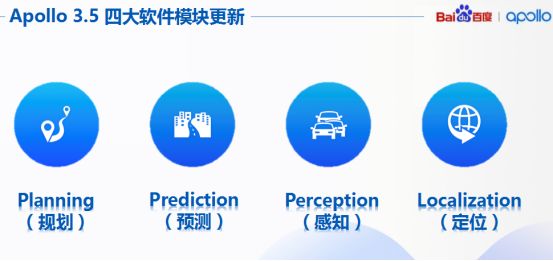
如今Apollo3.5在感知能力上也得到了升级,可以做到通过增加盲区检测传感器以及雷达等方式,例如用于盲区检测的传感器套件以及新的128线的激光雷达拓展检测范围,同时包含3D定位算法以及目标检测算法,表现更强大。

自动驾驶中的目标检测与识别
所谓目标检测,就是区分图像或者视频中的目标与其他不感兴趣的部分,例如图中的建筑物、树林、盒子以及瓶子等,其实这些物体同画面产生了一些明显区分,那么如何让计算机像人类一样做到明确区分呢?这就涉及目标检测,可以说让计算机能够区分出这些,是目标检测的第一步。
目标检测的第二步是什么?是让计算机识别刚才区分出来的画面究竟是什么,从而确定视频或图像中目标的种类。例如为了实现自动驾驶的目标,最初需要让计算机认识交通目标,才能让其成为真正的AI老司机。

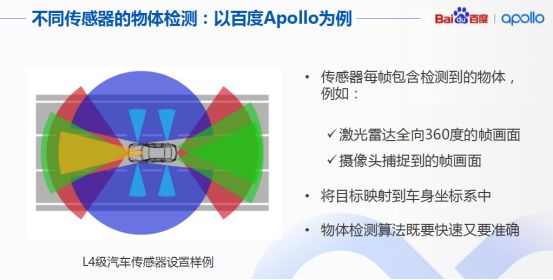
如何建立一个高准确率、高召回率的物体识别系统?这实际是无人车感知的一个核心问题,而物体检测更是重中之重,要求我们对不同传感器设计不同的算法来准确检测障碍物。例如Apollo技术框架中为3D设计了CNSEG(音译)深度学习算法,还包括为二级图像设计的YOLO3D深度学习算法等。
具体说到物体检测,我们要求完成单帧障碍物的检测,并借助传感器内外参数标定转换矩阵,将检测结果统一影射到车身的座标系中,这种物体检测算法既快速又准确。
引入深度学习究竟为何般?
有些小伙伴可能产生疑问,描述了这么多种方法,为什么一定要使用深度学习呢?或许将深度学习与传统图像处理PK下,就能明了其中缘由。
业界共知,传统的目标检测与识别算法分为三部分,包含目标特征提取、目标识别以及目标定位,其中涉及的典型算法就是基于组件检测的DPM算法。
实际上DPM算法就是训练出物体的梯度模型,然后对实际物体进行套用。但很显然,人为提取出来模型种类还是有限的,面对现实中纷繁多变的大千世界,即便是后来人为成功提取了更多特征因素,也很难做到对图像中全部细节进行详细描述,因此类似DPM算法。
由于传统目标检测算法主要基于人为特征提取,对于更复杂或者更高阶的图像特征很难进行有效描述,所以限制了目标检测的识别效果,这一点可以被认定是人为特征提取导致传统算法的性能瓶颈。

同传统的图像处理方法不同,采用深度学习的方法进行图像处理,最大的区别就是特征图不再通过人工特征提取,而是利用计算机,这样提取出来的特征会非常丰富,也很全面。
所谓的深度学习就是通过集联多层的神经网络形成一个很深的层,当层数越多,提取出来的特征也就越多而且越丰富。所以在目标检测和识别的过程中,最主要使用的深度学习特征提取模型就是深度卷积网络,英文简称CNN。
为什么CNN图像处理的方式比以前更好呢?究其原因,根本还是在于对图像特征提取。例如,当我们使用多层进行特征提取的时候,其实有些层是针对图像的边缘轮廓来提取的,有些则是针对质地或者纹理来进行的,还有些是针对物体特征进行操作,总而言之不同的层有不同的分割方式。
回归到目标检测这个问题上,卷积神经网络的每一层如果能够准确提取出所需特征,最后也就容易判断许多。因此决定CNN的目标检测和识别的关键就在于对每一层如何设计。
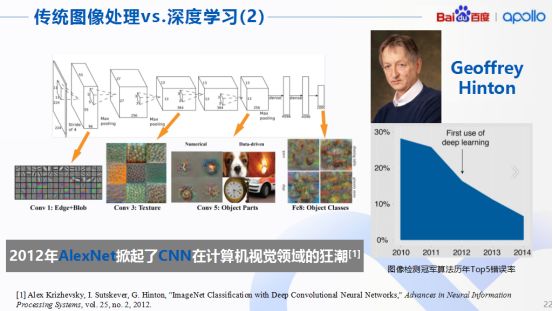
这可能就是八仙过海各显神通的时刻了,不过不得不提及的是,一个著名的卷积神经网络AlexNet,这个网络由多伦多大学的Hinton教授团队于2012年提出,一经提出立马轰动了计算机的视觉领域,对其他相关行业后期也产生了深远的影响。
AlexNet在整个算法处理的步骤,其实与之前提到的一般CNN的处理方式没有本质区别,而且在国际上每年都会举办图像检测算法的比赛,AlexNet就在某届图像检测比赛中获得了冠军。那一年AlexNet横空出世,把当年的top5错误率硬生生降到了17%以下。
既然深度学习能够在目标检测中大显身手,那么针对当前目标检测的方法又有哪些?简单将当前的方法进行分类,其实可以归纳为三种算法方案:
第一种是对于候选区域的目标检测算法,典型的网络是R-CNN和FasterR-CNN;第二个方案则是基于回归的目标检测算法,典型实现是YOLO和SSD,最后一种是基于增强学习的目标检测算法,典型表现为深度Q学习网络,但这几种算法其实各有各的优缺点。
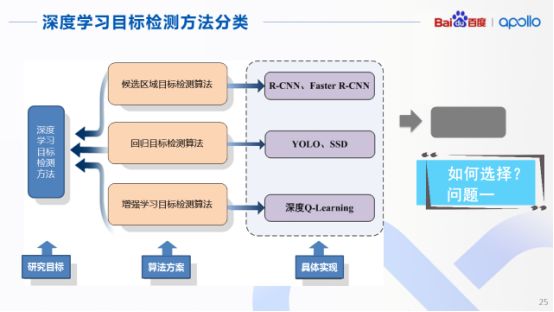
由于今天的话题是目标检测,自然就会想到在多种算法门派中如何进行选择的问题,以及在自动驾驶领域中适合其研发的算法以及框架是什么。
深度学习框架呼之欲出
关于深度学习框架的选择,大家可以尝试用百度PaddlePaddle。就目前而言,市面上深度学习框架很多,包括Tensorflow、Caffe、PyTorch、MXNet等在内,而PaddlePaddle是众多深度学习框架中唯一一款国内自主研发的。
它支持分布式计算,即多GPU多台机器并行计算,同时还支持FPGA,与其他一些仅支持GPU的框架不同,支持FPGA是PaddlePaddle的一个亮点。

有了解称,FPGA特有的流水线结构降低了数据同内存的反复交互,从而大大降低了运行功耗,这对于深度学习进行大规模的推断有诸多好处。如果能将这一特性扩展到自动驾驶领域,对于未来降低汽车的发热问题显然有很大帮助。而PaddlePaddle中的PaddleMobile框架以及API的方式支持移动端设备,这样就可以利用手机来完成想要的功能。
算法方案如何高效选择?
先前提到的三种方案,首先来看候选区域目标检测算法。这类算法的典型案例是FasterR-CNN。工作的基本步骤可归纳为首先提取图像中的候选区域,随后针对这些候选区域进行分类判断,当然由于这些候选区域是通过算法搜索出来的,所以并不一定准确,因此还需要对选出的区域做位置回归,随之进行目标定位,最后输出一个定位结果。总体来说,首先要先选择、再判断,最后剔除不想要的。
类似于找工作,选择这种方法进行图像目标检测是可以做到精准定位以及识别,所以精度较高,不过由于需要反复进行候选区域的选择,所以算法的效率被限制。

值得注意的一点,FasterR-CNN引入了一种称为区域生成网络RPN(音译)的概念,用来进行算法加速。可以看到,RPN实际上是在分类和特征图,也就是卷积层出来之后的特征图之间,这样就解决了端到端的问题。
同时,我们可以利用GPU来进行网络加速,从而提升检测的速率,这也是为什么FasterR-CNN和R-CNN相比多了一个Faster的原因。此外,候选区域检测这类算法在VOC2007数据集上,也可以达到检测精度为73.2%的准确率。讲到候选区域目标检测算法,实际上前面候选区域的目标检测算法主要是利用对于候选区域进行目标提取。
接下来介绍的第二个算法就是刚才提到的回归目标检测算法,它的特点是SingleShot,也就是只需观测一次图片就能进行目标的检测以及识别,因此算法的效率非常高。
在此罗列了一个称之为SSD的典型回归目标检测算法,这个算法分为四个步骤:第一步通过深度神经网络提取整个图片的特征;第二步对于不同尺度的深度特征图设计不同大小的特征抓取盒;第三步通过提取出这些抓去盒中的特征进行目标识别,最后,在识别出的这些结果中运用非极大值抑制选择最佳的目标识别结果。

所以其实SSD算法核心思想与第一种算法类型类似,都是从深度神经网络的不同层提取特征,分别利用这些特征进行回归预测。当然基于回归的目标检测算法是不能同候选区域目标检测算法那样特别精确的,尤其是对画面中一些小目标,同样给出SSD算法在VOC2007数据集上准确度的数值,为68%。
虽然比候选区域目标检测算法低那么一丢丢,但是基本上性能没有太大损失,此外,由于它是SingleShot,算法的效率也是相当高的。
之前说到的两种类型算法,对于图中目标的边框、尺寸都是固定的,也就是说检测算法中目标边框虽然数目特别多,但一旦边框确定就无法改变,因此并不能适应场景变化。所以为了检测出不同目标、不同场景,就需要准备出多种区域选择框。然而大千世界纷繁多变,检测目标在画面中的大小更是差别巨大,如果能够根据不同的情况在目标候选区域进行边框调整,就可以做到适应各种各样的环境了。
回到第三种算法的介绍,也就是增强学习算法,可以说场景适应性算是比较强的。增强学习算法目标检测可被看成不断动态调整候选区域边框的过程,这种算法的典型代表是Q学习算法。

首先,通过图像进行特征提取,可以通过一个CNN网络来完成,第二,主动搜索,目的是根据不同的目标和场景调整搜索的步长,并且结合历史动作反馈的信息,凭借深度Q学习网络来预测下一步的动作,也就是通过算法中设定一定的奖励机制来判断这个特征提取边框的大小变化以及上下左右移动是否有效。当网络中预测下一步动作完成后,再开始进行识别并最后输出结果。因此,这类算法的核心思想可以看成是由原来不可以改变大小的、静态的特征抓取框,变成了现在可变的动态抓取框,但这类算法目前在VOC2007数据集上准确度的数值是46.1%,比较低。
原因主要是在进行边框调整过程中很容易造成特征抓取框和标定的区域差距比较大,这样会严重影响模型的训练效果,从而造成性能的下降;此外由于要进行主动搜索和多次边框的调整,所以算法的计算也比较耗时。不过这种算法唯一的好处是相对灵活,俗称百搭。
最后总结下,可以看到,从速度上回归目标检测算法是最快的,原因在于只需看一次图片就能够“一见钟情”;而从精度角度而言,后续区域目标检测算法已经可以达到很高的精度水平了,然而回归目标检测算法的能力也能够做到和候选区域算法比较接近的程度。
以上我们介绍的都是典型的基本算法,最后从框架支持的角度来看,开发者很容易搭建候选区域检测算法和回归目标检测算法框架来实现。由于增强学习这种算法的动态变化比较大,直接用框架来实现目前是有一定难度的,但如果大家对深度学习框架有所了解,其实目前已经有可支持深度Q网络的模型。

三种算法介绍完毕之后,究竟哪种算法最适合人们熟知的自动驾驶场景呢?当然是回归目标检测算法。虽然在理论上候选区域目标检测算法能够做到精确度特别高,但由于需要反复观测画面,所以大大降低了检测速度,特别是在自动驾驶领域中,需要进行高速反应来完成目标识别,在这个层面并不适合。
百度Apollo中深度学习的应用
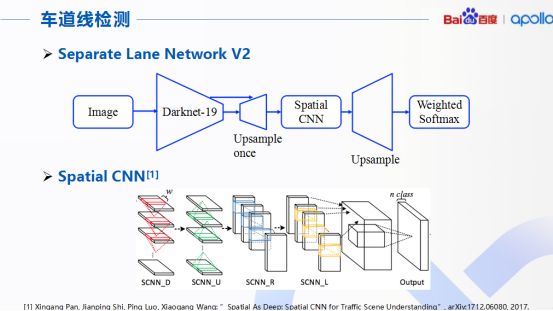
第一点,关于车道线的检测。目前百度Apollo采用了称为分离车道线网络的结构,图像通过一个D9和一个空间卷积神经网络S-CNN完成对于道路上车道线的检测和识别,整个网络的核心是下面展示的S-CNN,网络中用来增强对于行车时车道的检测能力。S-CNN首先将特征图的行和列分别看成多个层级的形式。
同时采用顺序卷积,非线性激活函数以及求和操作形成一个深度神经网络,好处是将原来CNN隐藏层之间空间关系关联起来,从而更好处理画面中连续相关的目标,这个算法特别对于行车时车道的目标检测任务,精度很高,准确率高达96.53%。
可以看出,传统情况下都是在实际检测过程中有一些干扰,使得在检测过程中原来需要正确检测出的像素点和其他的像素点发生了关联,受到的周围环境干扰比较大。
不过S-CNN就不一样了,这是深度挖掘了前后线条间的相关性,避免这种情况出现,所以可以清晰的看到图上检测出来的电线杆和车道线都是比较粗和连续的。
针对百度Apollo和当前版本的百度Apollo对于车道线检测效果的对比,很直观看到,采用刚才提出的算法以后,对于自动驾驶的视觉系统而言,性能提升非常明显。原来路边车道线模糊或者根本看不到车道线的地方现在通过引入新的分离的车道线检测技术以后,可以看出Apollo在行使过程中可以准确检测出车道线了。

在Apollo2.5和3.0中,基于YOLO设计了一些单物摄像头下的物体检测神经网络,称为Multi-Task YOLO 3D。因为它的最终输出是单目摄像头3D障碍物检测的信息,最后会输出多于2D图像检测的全部信息,所以可以看到与普通的CNN网络检测出来的效果并不一样,这是立体的检测结果,也就是说检测出来的那个框结果是立体的。

不同之处在于首先就是3D框输出,其次它也会输出相对障碍物所检测出来的一些偏转角,此外现在的Apollo3.5还包含物体的分割信息,具有物体分割的功能,包括车道线的信息,用来提供给定位模块等。
在Apollo检测的事例中可以看到,算法其实对于路边的行人判断还是比较准确的,可以在一堆繁忙的公路上清晰看到最终要检测出来的某个行人。此外,Apollo单目摄像头下的障碍物检测速度是比较快的,特别是对繁忙路段和高速场景都是比较适配,检测速度达到了30赫兹,也就是说每秒钟可以检测30张图像。
除此之外,Apollo还有一些相关功能,例如典型目标的检测,包含了基于经典计算机视觉障碍的物体识别和基于深度学习的障碍物识别。基于经典计算机视觉的障碍物识别的计算复杂度比较低,单核CPU可以达到实现,同时因为复杂度比较低,训练也比较快。此外,深度学习主要依赖GPU,当速度比较快,而且训练数据足够多的时候,可以得到最好的准确度。
百度深度学习框架对目标检测的实操
为了方便开发者们的理解,我们以百度PaddlePaddle为例为大家介绍实际目标检测中的可喜效果。
首先提出PaddlePaddle官方仓库里的MobileNet+SSD的检测效果,这个模型可以从官方仓库上下载,整个模型也非常适合移动端场景,算法的流程和前面介绍的比较类似。
最初采用G网络MobileNet来抽取特征,随后利用前面介绍的SDD中的堆叠卷积盒来进行特征识别,不同位置检测不同大小、不同形状的目标,最后再利用非极大值抑制筛选出最合适的识别结果,整个模型最重要的是对候选框信息的获取,包括框的位置、目标类别、置信概率三个信息在内。

具体如何获取这些框的相关信息呢?实际上PaddlePaddle已经提供了封装好的API,使用时直接调用即可。我们调用这个函数,就是Multi_box_head,从MobileNet最后一层进行连接,用来生成SSD中的特征抓取盒,其中包含所谓的四个返回值,分别是候选框边界的精细回归、框内出现物体的置信度、候选框原始位置、候选框原始位置方差。实际上就是候选框的位置以及关于这些位置相对偏移的量。
如果把这些值进行输出可视化,首先给出的是出现物体的置信度,通常用框进行识别的过程中,一般认为框里只近似保留一种,最后只会出现一类判断结果。第一个值如果是最大的,就被认为属于背景类,也就是说第一个张量,它的这个框的目标就是背景。接着把所有背景选出来之后,再把这些背景去掉,剩下来的自然而然就是画面中要识别出来的目标。

接下来利用Detection_output这一层,加入一个可视化的边框的操作,可以看到,蓝色的表示人,红色的表示摩托车,最后利用非极大值抑制的操作,把这些框当中多余的框全部去掉,只保留最贴近检测效果的框,也就是最后想要的结果。可以看到,经过非极大值抑制后,同类的折叠框一般只保留概率较高的、重叠较小的,这就完成了最终的目标检测。

以上就是本次直播的分享内容,更多关于Apollo的技术干货,可以继续关注开发者社区每月的课程分享。本次课程直播分享的PPT资料,可以关注Apollo开发者社区(Apollo_Developers)回复“0228课程直播”获取,同时也可以在GitHub上提出技术问题与我们互动,十分感谢大家。
相关文章:

【Qt】QObject::moveToThread 总结
原型 void QObject::moveToThread(QThread *targetThread) 功能 将QObject及其孩子移动到 指定线程(targetThread)中。它的事件将在targetThread线程中处理。 注意事项 1、该对象不能有parent,否则无法移动。 2、如果targetThread为零,…

中国联通备战5G MWC发布《Edge-Cloud平台架构及产业生态白皮书》
2月26日-3月1日,中国联通受邀参加2018MWC世界移动通信大会,作为本次大会GSMA智慧城市展区参展的唯一中国运营商,中国联通提出以服务为驱动的面向5G网络切片的演进思路,为客户提供4G到5G演进阶段的一致性的网络服务&…
转自一个面试者的“提示”
转自CSDN:http://topic.csdn.net/u/20110112/15/FFCBED16-E346-4074-87EE-0D682EF67FE2.html 希望对2011年努力寻找工作的人有帮助。 最近一直在参与公司的面试,为公司招收SE和SA。今天总结发现最近一共面试了二十几份简历,并且都是经过HE和猎…
【OpenCV】读取csv文件
csv简介 逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。纯文本意味着该文件是一个字符…

300道Python面试题,备战春招!
作者 | kenwoodjw 责编 | Jane 出品 | Python大本营(ID:pythonnews) 程序员转行学什么语言? https://edu.csdn.net/topic/ai30?utm_sourcecsdn_bw 过年开工回来到现在,营长每天在地铁里只看到了两家公司的广告&…
稻盛和夫《活法》
以下内容是摘自<稻盛和夫>的《活着》中文翻译版。此生将托付于此书! “吾等定此血盟不为私利私欲,但求团结一致,为社会、为世人成就事业。特此聚合诸位同志,血印为誓。”——稻盛和夫 1.人类活着的意义、人生的目的到底是什…
【OpenCV】将图像数据由YUV格式转换成JPG格式直接使用,而不保存成文件
解决方法 使用OpenCV图像编码和解码函数:imencode、imdecode std::vector data_encode; imencode(“.png”, img_encode, data_encode); 参考博客: https://blog.csdn.net/tt_ren/article/details/53227900
一个装作异步的代码段
// 获取当前周期 getCurrentCycle(subDepartmentIdthis.props.subDepartmentId) {let { dispatch } this.propscalculateApi.currentKaoqinCycle({id:subDepartmentId}).then(res>{ if (res.data.id) { //console.log(res.data.name); this.setState({ cycleName: res.data…

拯救老电影——详解爱奇艺ZoomAI视频增强技术的应用
看各种视频节目已经成为当前娱乐休闲的一种方式,技术的进步和网速的升级提升了我们的视觉愉悦感,但是你总会遇到一些情况,比如老电影/电视剧的画面抖动、色彩灰暗;用户带宽受限,选择低码流的模式;UP主上传的…

Android 中文API (94) —— MediaController
前言 本章内容是android.widget.MediaController,版本为Android 2.3 r1,翻译来自"唐明",再次感谢"唐明" !期待你一起参与Android 中文API的翻译,联系我over140gmail.com。 声明 欢迎转载…

数据分析奥斯卡女神们,谁是你心中的No.1?
作者 | 徐麟转载自数据森麟(公众号 ID:shujusenlin)前言在开始今天的正文前,首先带来一首经典的由奥黛丽赫本演唱的《Moon River》,也是电影《蒂凡尼的早餐》中的主题曲。一年一度的奥斯卡奖于上月落下了帷幕ÿ…
ansible组件-playbook学习笔记
playbook的基础组件 name 定义playbook或者task的名称 hosts 用于指定要执行指定任务的主机 user 用于指定远程主机上的执行任务的用户 task 任务列表 vars 定义变量 vars_files 定义变量文件 notify 任务执行结果如果是发生更改的则触发定义在handler的任务 handlers 用于当前…
【linux工具】ldconfig:linux配置动态链接库
简介 ldconfig命令的用途主要是在默认搜寻目录/lib和/usr/lib以及动态库配置文件/etc/ld.so.conf内所列的目录下,搜索出可共享的动态链接库(格式如lib*.so*),进而创建出动态装入程序(ld.so)所需的连接和缓存文件。 用法 ldconfig [-v|–ve…
T-SQL IN 谓词
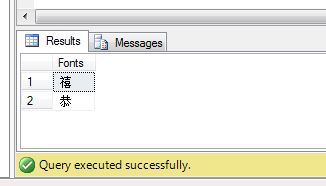
T-SQL谓词之一 IN。检查指定(IN谓词前)的值,字段值或标量表达式是否包含在定义的一组元素(放在括弧内)中。这组元素可以有一或多个值,而不同值之间由逗点分开。 创建一个临时表,并插入一些值。 CREATETable#t( Fonts NVARCHAR(10))INSERTI…

vue:虚拟dom的实现
Vitual DOM是一种虚拟dom技术,本质上是基于javascript实现的,相对于dom对象,javascript对象更简单,处理速度更快,dom树的结构,属性信息都可以很容易的用javascript对象来表示: let element{tagN…
【Ubuntu】apt-get命令小结
apt-get install 安装软件包 apt-get remove 删除已安装的软件包(保留配置文件) apt-get update 更新 apt-get autoremove 自动删除没用的包 apt-get purge 删除包,不保留配置文件 apt-get –purge remove

腾讯58篇论文入选CVPR 2019,两年增长超200%
全球计算机视觉顶级会议 IEEE CVPR 2019(Computer Vision and Pattern Recognition,即IEEE国际计算机视觉与模式识别会议) 即将于6月在美国长滩召开。本届大会总共录取来自全球论文1299篇。中国团队表现不俗,此次,腾讯公司有超过58篇论文被本…
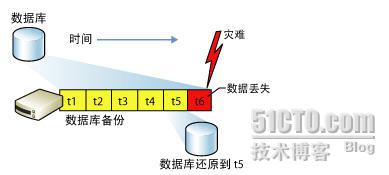
SQL Server 2008备份策略设计下(六)
上一篇博文探讨了各种恢复模式和备份类型,这一节继续来探讨如何设计备份策略。设计一个数据库的最佳备份策略,会面临如何选择使用哪种恢复模式的问题,因为恢复模式控制着备份和还原的行为。一般来讲,简单恢复模式一般适合用于测试…
【Qt】Qt样式表(Style Sheet):官网说明及例子
网址 http://doc.qt.io/qt-5/stylesheet.html 样式表语法 各种Qt控件的样式表例子 Qt样式表参考手册

神爱程序员,于是带来Python
“我累了,需要很长时间的休息。”2018 年 7 月,在 PEP 572(Python 改进提案) 被接受后的第三天,由于仍然不断面对着别人的质疑,反馈意见不断袭来,让这位一手缔造新的编程语言帝国的图灵奖获得者…
Dubbo配置文件详解
为新项目练手,把项目中用到的web service、RMI的服务改用DubboZookeeperSpring,网上找到几篇不错的配置详解 1.此篇博文主要从以下几种配置方式来讲 XML 配置文件方式、XML 配置文件方式、annotation 配置方式 https://www.cnblogs.com/chanshuyi/p/514…
Mono源代码学习笔记:Console类(四)
NullStream 类 (internal class) 下面就是 mcs/class/corlib/System.IO/NullStream.cs: 01: namespace System.IO 02: { 03: class NullStream : Stream 04: { 05: public override bool CanRead { get { return true; } } 06: public override b…

Java帝国对Python的渗透能成功吗?
作者 | 刘欣转载自码农翻身(公众号 ID:coderising)引子Java 帝国已经成立 20 多年,经过历代国王的励精图治,可以说是地大物博,码农众多。 可是国王依然不满足,整天想着如何继续开拓疆土…
【杂】突然有个想法,为了防止公司或其他,监视你的qq或微信,可以做个程序,将信息打乱,分别用qq和微信传输,然后,再还原
突然有个想法,为了防止公司或其他,监视你的qq或微信,可以做个程序,将信息打乱,分别用qq和微信传输,然后,再还原。
CTO 基本功大盘点 —— 没有这些技能,谈何远大前程?
本文由 「TGO鲲鹏会」原创,原文链接:CTO 基本功大盘点 —— 没有这些技能,谈何远大前程? 作者|刘海星 2018 年马上就要过去六分之一了,你的 KPI 完成多少了? 别沮丧,其实我想说的是&…

Windows Phone 7 不温不火学习之《创建用户控件》
同样出自微软的产品,像ASP.NET 一样,Windows Phone 7 也有一个叫UserControl 的东西。这个相当于一个组件,类似于Android 继承View 。 本篇将实现一个用户控件,默认为它添加高宽,并为它添加一个自己的事件,…

从起源、变体到评价指标,一文解读NLP的注意力机制
作者 | yuquanle转载自AI小白入门(ID:StudyForAI)目录1.写在前面2.Seq2Seq 模型3.NLP中注意力机制起源4.NLP中的注意力机制 5.Hierarchical Attention6.Self-Attention7.Memory-based Attention 8.Soft/Hard Attention9.Global/Local Attention10.评价指…

【Git】ubuntu上git commit提交后如何保存和退出类似vim的界面,回到命令行
问题 使用 git commit 命令后,进入类似vim的界面,开始时,不知道如何保存,甚至不知道怎么退出该界面。 解决方法 1、使用 git commit 命令后,进入的是nano文本编辑器(类似vim); 2…
linux硬盘满了问题排查
关键指令: df du find step1: 如果发现硬盘满了,首先要确定一下,使用df查看硬盘使用情况 df -h step2: 从第一步结果判定满了,确定哪些文件或哪个文件占了大头,使用du指令做逐步排查,…
win2003登陸及關機設定
開啟未登陸可以關機鍵關機﹕ 到控制面板,本地安全策略,安全性選項﹐启用允许在未登录前关机 關關機事件跟踪﹕ 运行“gpedit.msc”命令打开组策略编辑器,依次展开“计算机配置”→“管理模板”→“系统”,将“顯示关闭事件跟踪程序…