从起源、变体到评价指标,一文解读NLP的注意力机制

作者 | yuquanle
转载自AI小白入门(ID:StudyForAI)
目录
1.写在前面
2.Seq2Seq 模型
3.NLP中注意力机制起源
4.NLP中的注意力机制
5.Hierarchical Attention
6.Self-Attention
7.Memory-based Attention
8.Soft/Hard Attention
9.Global/Local Attention
10.评价指标
11.写在后面
12.参考文献
写在前面
近些年来,注意力机制一直频繁的出现在目之所及的文献或者博文中,可见在nlp中算得上是个相当流行的概念,事实也证明其在nlp领域散发出不小得作用。这几年的顶会paper就能看出这一点。本文深入浅出地介绍了近些年的自然语言中的注意力机制包括从起源、变体到评价指标方面。
据Lilian Weng博主[1]总结以及一些资料显示,Attention机制最早应该是在视觉图像领域提出来的,这方面的工作应该很多,历史也比较悠久。人类的视觉注意力虽然存在很多不同的模型,但它们都基本上归结为给予需要重点关注的目标区域(注意力焦点)更重要的注意力,同时给予周围的图像低的注意力,然后随着时间的推移调整焦点。
而直到Bahdanau等人[3]发表了论文《Neural Machine Translation by Jointly Learning to Align and Translate》,该论文使用类似attention的机制在机器翻译任务上将翻译和对齐同时进行,这个工作目前是最被认可为是第一个提出attention机制应用到NLP领域中的工作,值得一提的是,该论文2015年被ICLR录用,截至现在,谷歌引用量为5596,可见后续nlp在这一块的研究火爆程度。
注意力机制首先从人类直觉中得到,在nlp领域的机器翻译任务上首先取得不错的效果。简而言之,深度学习中的注意力可以广义地解释为重要性权重的向量:为了预测一个元素,例如句子中的单词,使用注意力向量来估计它与其他元素的相关程度有多强,并将其值的总和作为目标的近似值。既然注意力机制最早在nlp领域应用于机器翻译任务,那在这个之前又是怎么做的呢?
传统的基于短语的翻译系统通过将源句分成多个块然后逐个词地翻译它们来完成它们的任务,这导致了翻译输出的不流畅。不妨先来想想我们人类是如何翻译的?我们首先会阅读整个待翻译的句子,然后结合上下文理解其含义,最后产生翻译。
从某种程度上来说,神经机器翻译(NMT)的提出正是想去模仿这一过程。而在NMT的翻译模型中经典的做法是由编码器 - 解码器架构制定(encoder-decoder),用作encoder和decoder常用的是循环神经网络。这类模型大概过程是首先将源句子的输入序列送入到编码器中,提取最后隐藏状态的表示并用于解码器的输入,然后一个接一个地生成目标单词,这个过程广义上可以理解为不断地将前一个时刻 t-1 的输出作为后一个时刻 t 的输入,循环解码,直到输出停止符为止。
通过这种方式,NMT解决了传统的基于短语的方法中的局部翻译问题:它可以捕获语言中的长距离依赖性,并提供更流畅的翻译。
但是这样做也存在很多缺点,譬如,RNN是健忘的,这意味着前面的信息在经过多个时间步骤传播后会被逐渐消弱乃至消失。其次,在解码期间没有进行对齐操作,因此在解码每个元素的过程中,焦点分散在整个序列中。对于前面那个问题,LSTM、GRU在一定程度能够缓解。而后者正是Bahdanau等人重视的问题。
Seq2Seq模型
在介绍注意力模型之前,不得不先学习一波Encoder-Decoder框架,虽然说注意力模型可以看作一种通用的思想,本身并不依赖于特定框架(比如文章[15]:Learning Sentence Representation with Guidance of Human Attention),但是目前大多数注意力模型都伴随在Encoder-Decoder框架下。
Seq2seq模型最早由bengio等人[17]论文《Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation》。随后Sutskever等人[16]在文章《Sequence to Sequence Learning with Neural Networks》中提出改进模型即为目前常说的Seq2Seq模型。
从广义上讲,它的目的是将输入序列(源序列)转换为新的输出序列(目标序列),这种方式不会受限于两个序列的长度,换句话说,两个序列的长度可以任意。以nlp领域来说,序列可以是句子、段落、篇章等,所以我们也可以把它看作处理由一个句子(段落或篇章)生成另外一个句子(段落或篇章)的通用处理模型。
对于句子对,我们期望输入句子Source,期待通过Encoder-Decoder框架来生成目标句子Target。Source和Target可以是同一种语言,也可以是两种不同的语言,若是不同语言,就可以处理翻译问题了。若是相同语言,输入序列Source长度为篇章,而目标序列Target为小段落则可以处理文本摘要问题 (目标序列Target为句子则可以处理标题生成问题)等等等。
seq2seq模型通常具有编码器 - 解码器架构:
编码器encoder: 编码器处理输入序列并将序列信息压缩成固定长度的上下文向量(语义编码/语义向量context)。期望这个向量能够比较好的表示输入序列的信息。
解码器decoder: 利用上下文向量初始化解码器以得到变换后的目标序列输出。早期工作仅使用编码器的最后状态作为解码器的输入。
编码器和解码器都是循环神经网络,比较常见的是使用LSTM或GRU。

编码器 - 解码器模型
NLP中注意力机制的起源
前面谈到在Seq2Seq结构中,encoder把所有的输入序列都编码成一个统一的语义向量context,然后再由decoder解码。而context自然也就成了限制模型性能的瓶颈。
譬如机器翻译问题,当要翻译的句子较长时,一个context可能存不下那么多信息。除此之外,只用编码器的最后一个隐藏层状态,感觉上都不是很合理。
实际上当我们翻译一个句子的时候,譬如:Source: 机器学习-->Target: machine learning。当decoder要生成"machine"的时候,应该更关注"机器",而生成"learning"的时候,应该给予"学习"更大的权重。所以如果要改进Seq2Seq结构,一个不错的想法自然就是利用encoder所有隐藏层状态解决context限制问题。
Bahdanau等人[3]把attention机制用到了神经网络机器翻译(NMT)上。传统的encoder-decoder模型通过encoder将Source序列编码到一个固定维度的中间语义向量context,然后再使用decoder进行解码翻译到目标语言序列。前面谈到了这种做法的局限性,而且,Bahdanau等人[3]在其文章的摘要中也说到这个context可能是提高这种基本编码器 - 解码器架构性能的瓶颈,那Bahdanau等人又是如何尝试缓解这个问题的呢? 别急,让我们来一探究竟。
作者为了缓解中间向量context很难将Source序列所有重要信息压缩进来的问题,特别是对于那些很长的句子。提出在机器翻译任务上在 encoder–decoder 做出了如下扩展:将翻译和对齐联合学习。这个操作在生成Target序列的每个词时,用到的中间语义向量context是Source序列通过encoder的隐藏层的加权和,而传统的做法是只用encoder最后一个时刻输出 作为context,这样就能保证在解码不同词的时候,Source序列对现在解码词的贡献是不一样的。
作为context,这样就能保证在解码不同词的时候,Source序列对现在解码词的贡献是不一样的。
想想前面那个例子:Source: 机器学习-->Target: machine learning (假如中文按照字切分)。decoder在解码"machine"时,"机"和"器"提供的权重要更大一些,同样,在解码"learning"时,"学"和"习"提供的权重相应的会更大一些,这在直觉也和人类翻译也是一致的。
通过这种attention的设计,作者将Source序列的每个词(通过encoder的隐藏层输出)和Target序列 (当前要翻译的词) 的每个词巧妙的建立了联系。想一想,翻译每个词的时候,都有一个语义向量,而这个语义向量是Source序列每个词通过encoder之后的隐藏层的加权和。 由此可以得到一个Source序列和Target序列的对齐矩阵,通过可视化这个矩阵,可以看出在翻译一个词的时候,Source序列的每个词对当前要翻译词的重要性分布,这在直觉上也能给人一种可解释性的感觉。
论文中的图也能很好的看出这一点:

生成第t个目标词
更形象一点可以看这个图:


现在让我们从公式层面来看看这个东东 (加粗变量表示它们是向量,这篇文章中的其他地方也一样)。 假设我们有一个长度为n的源序列x,并尝试输出长度为m的目标序列y:

作者采样bidirectional RNN作为encoder(实际上这里可以有很多选择),具有前向隐藏状态 和后向隐藏状态
和后向隐藏状态 。为了获得词的上下文信息,作者采用简单串联方式将前向和后向表示拼接作为encoder的隐藏层状态,公式如下:
。为了获得词的上下文信息,作者采用简单串联方式将前向和后向表示拼接作为encoder的隐藏层状态,公式如下:

对于目标(输出)序列的每个词(假设位置为t),decoder网络的隐藏层状态:
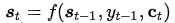
其中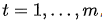 ,语义向量
,语义向量 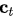 是源(输入)序列的隐藏状态的加权和,权重为对齐分数:
是源(输入)序列的隐藏状态的加权和,权重为对齐分数:

(注意:这里的score函数为原文的a函数,原文的描述为: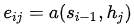 is an alignment model)
is an alignment model)
对齐模型基于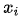 (在i时刻的输入)和
(在i时刻的输入)和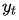 (在t时刻的输出)的匹配程度分配分数
(在t时刻的输出)的匹配程度分配分数 。是定义每个目标(输出)单词应该考虑给每个源(输入)隐藏状态的多大的权重(这恰恰反映了对此时解码的目标单词的贡献重要性)。
。是定义每个目标(输出)单词应该考虑给每个源(输入)隐藏状态的多大的权重(这恰恰反映了对此时解码的目标单词的贡献重要性)。
在Bahdanau[3]的论文中,作者采用的对齐模型为前馈神经网络,该网络与所提出的系统的所有其他组件共同训练。因此,score函数采用以下形式,tanh用作非线性激活函数,公式如下:

其中 ,
, 和都是在对齐模型中学习的权重矩阵。对齐分数矩阵是一个很好的可解释性的东东,可以明确显示源词和目标词之间的相关性。
和都是在对齐模型中学习的权重矩阵。对齐分数矩阵是一个很好的可解释性的东东,可以明确显示源词和目标词之间的相关性。

对齐矩阵例子
而decoder每个词的条件概率为:

g为非线性的,可能是多层的输出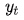 概率的函数,
概率的函数,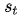 是RNN的隐藏状态,
是RNN的隐藏状态, 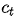 为语义向量。
为语义向量。
NLP中的注意力机制
随着注意力机制的广泛应用,在某种程度上缓解了源序列和目标序列由于距离限制而难以建模依赖关系的问题。现在已经涌现出了一大批基于基本形式的注意力的不同变体来处理更复杂的任务。让我们一起来看看其在不同NLP问题中的注意力机制。
其实我们可能已经意识到了,对齐模型的设计不是唯一的,确实,在某种意义上说,根据不同的任务设计适应于特定任务的对齐模型可以看作设计出了新的attention变体,让我们再回过头来看看这个对齐模型(函数):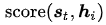 。再来看看几个代表性的work。
。再来看看几个代表性的work。
Citation[5]等人提出Content-base attention,其对齐函数模型设计为:

Bahdanau[3]等人的Additive(*),其设计为:

Luong[4]等人文献包含了几种方式:

以及Luong[4]等人还尝试过location-based function:

这种方法的对齐分数仅从目标隐藏状态学习得到。
Vaswani[6]等人的Scaled Dot-Product(^):

细心的童鞋可能早就发现了这东东和点积注意力很像,只是加了个scale factor。当输入较大时,softmax函数可能具有极小的梯度,难以有效学习,所以作者加入比例因子
 。
。Cheng[7]等人的Self-Attention(&)可以关联相同输入序列的不同位置。 从理论上讲,Self-Attention可以采用上面的任何 score functions。在一些文章中也称为“intra-attention” 。
Hu[7]对此分了个类:

前面谈到的一些Basic Attention给人的感觉能够从序列中根据权重分布提取重要元素。而Multi-dimensional Attention能够捕获不同表示空间中的term之间的多个交互,这一点简单的实现可以通过直接将多个单维表示堆叠在一起构建。Wang[8]等人提出了coupled multi-layer attentions,该模型属于多层注意力网络模型。作者称,通过这种多层方式,该模型可以进一步利用术语之间的间接关系,以获得更精确的信息。
Hierarchical Attention
再来看看Hierarchical Attention,Yang[9]等人提出了Hierarchical Attention Networks,看下面的图可能会更直观:

Hierarchical Attention Networks
这种结构能够反映文档的层次结构。模型在单词和句子级别分别设计了两个不同级别的注意力机制,这样做能够在构建文档表示时区别地对待这些内容。Hierarchical attention可以相应地构建分层注意力,自下而上(即,词级到句子级)或自上而下(词级到字符级),以提取全局和本地的重要信息。自下而上的方法上面刚谈完。那么自上而下又是如何做的呢?让我们看看Ji[10]等人的模型:

Nested Attention Hybrid Model
和机器翻译类似,作者依旧采用encoder-decoder架构,然后用word-level attention对全局语法和流畅性纠错,设计character-level attention对本地拼写错误纠正。
Self-Attention
那Self-Attention又是指什么呢?
Self-Attention(自注意力),也称为intra-attention(内部注意力),是关联单个序列的不同位置的注意力机制,以便计算序列的交互表示。它已被证明在很多领域十分有效比如机器阅读,文本摘要或图像描述生成。
比如Cheng[11]等人在机器阅读里面利用了自注意力。当前单词为红色,蓝色阴影的大小表示激活程度,自注意力机制使得能够学习当前单词和句子前一部分词之间的相关性。

当前单词为红色,蓝色阴影的大小表示激活程度
比如Xu[12]等人利用自注意力在图像描述生成任务。注意力权重的可视化清楚地表明了模型关注的图像的哪些区域以便输出某个单词。

我们假设序列元素为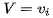 ,其匹配向量为
,其匹配向量为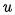 。让我们再来回顾下前面说的基本注意力的对齐函数,attention score通过
。让我们再来回顾下前面说的基本注意力的对齐函数,attention score通过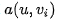 计算得到,由于是通过将外部u与每个元素
计算得到,由于是通过将外部u与每个元素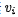 匹配来计算注意力,所以这种形式可以看作是外部注意力。当我们把外部u替换成序列本身(或部分本身),这种形式就可以看作为内部注意力(internal attention)。
匹配来计算注意力,所以这种形式可以看作是外部注意力。当我们把外部u替换成序列本身(或部分本身),这种形式就可以看作为内部注意力(internal attention)。
我们根据文章[7]中的例子来看看这个过程,例如句子:"Volleyball match is in progress between ladies"。句子中其它单词都依赖着"match",理想情况下,我们希望使用自注意力来自动捕获这种内在依赖。换句话说,自注意力可以解释为,每个单词去和V序列中的内部模式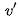 匹配,匹配函数
匹配,匹配函数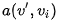 。很自然的选择为V中其它单词
。很自然的选择为V中其它单词 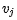 ,这样遍可以计算成对注意力得分。为了完全捕捉序列中单词之间的复杂相互作用,我们可以进一步扩展它以计算序列中每对单词之间的注意力。这种方式让每个单词和序列中其它单词交互了关系。
,这样遍可以计算成对注意力得分。为了完全捕捉序列中单词之间的复杂相互作用,我们可以进一步扩展它以计算序列中每对单词之间的注意力。这种方式让每个单词和序列中其它单词交互了关系。

另一方面,自注意力还可以自适应方式学习复杂的上下文单词表示。譬如经典文章[14]:A structured self-attentive sentence embedding。这篇文章提出了一种通过引入自关注力机制来提取可解释句子嵌入的新模型。 使用二维矩阵而不是向量来代表嵌入,矩阵的每一行都在句子的不同部分,想深入了解的可以去看看这篇文章,另外,文章的公式感觉真的很漂亮。
值得一提还有2017年谷歌提出的Transformer[6],这是一种新颖的基于注意力的机器翻译架构,也是一个混合神经网络,具有前馈层和自注意层。论文的题目挺霸气:Attention is All you Need,毫无疑问,它是2017年最具影响力和最有趣的论文之一。那这篇文章的Transformer的庐山真面目到底是这样的呢?
这篇文章为提出许多改进,在完全抛弃了RNN的情况下进行seq2seq建模。接下来一起来详细看看吧。
Key, Value and Query
众所周知,在NLP任务中,通常的处理方法是先分词,然后每个词转化为对应的词向量。接着一般最常见的有二类操作,第一类是接RNN(变体LSTM、GRU、SRU等),但是这一类方法没有摆脱时序这个局限,也就是说无法并行,也导致了在大数据集上的速度效率问题。第二类是接CNN,CNN方便并行,而且容易捕捉到一些全局的结构信息。很长一段时间都是以上二种的抉择以及改造,直到谷歌提供了第三类思路:纯靠注意力,也就是现在要讲的这个东东。
将输入序列编码表示视为一组键值对(K,V)以及查询 Q,因为文章[6]取K=V=Q,所以也自然称为Self Attention。
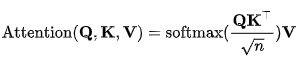
K, V像是key-value的关系从而是一一对应的,那么上式的意思就是通过Q中每个元素query,与K中各个元素求内积然后softmax的方式,来得到Q中元素与V中元素的相似度,然后加权求和,得到一个新的向量。其中因子为了使得内积不至于太大。以上公式在文中也称为点积注意力(scaled dot-product attention):输出是值的加权和,其中分配给每个值的权重由查询的点积与所有键确定。
而Transformer主要由多头自注意力(Multi-Head Self-Attention)单元组成。那么Multi-Head Self-Attention又是什么呢?以下为论文中的图:

Multi-head scaled dot-product attention mechanism
Multi-Head Self-Attention不是仅仅计算一次注意力,而是多次并行地通过缩放的点积注意力。 独立的注意力输出被简单地连接并线性地转换成预期的维度。论文[6]表示,多头注意力允许模型共同关注来自不同位置的不同表示子空间的信息。 只有一个注意力的头,平均值就会抑制这一点。

 是需要学习的参数矩阵。既然为seq2seq模式,自然也包括encoder和decoder,那这篇文章又是如何构建这些的呢?莫急,请继续往下看。
是需要学习的参数矩阵。既然为seq2seq模式,自然也包括encoder和decoder,那这篇文章又是如何构建这些的呢?莫急,请继续往下看。
Encoder

The transformer's encoder
编码器生成基于自注意力的表示,其能够从可能无限大的上下文中定位特定信息。值得一提的是,上面的结构文章堆了六个。
每层都有一个多头自注意力层
每层都有一个简单的全连接的前馈网络
每个子层采用残差连接和层规范化。 所有子层输出相同维度dmodel = 512。
Decoder

The transformer's decoder.
解码器能够从编码表示中检索。上面的结构也堆了六个。
每层有两个多头注意机制子层。
每层有一个完全连接的前馈网络子层。
与编码器类似,每个子层采用残差连接和层规范化。
与encoder不同的是,第一个多头注意子层被设计成防止关注后续位置,因为我们不希望在预测当前位置时查看目标序列的未来。最后来看一看整体架构:

The full model architecture of the transformer.
Memory-based Attention
那Memory-based Attention又是什么呢?我们先换种方式来看前面的注意力,假设有一系列的键值对 存在内存中和查询向量q,这样便能重写为以下过程:
存在内存中和查询向量q,这样便能重写为以下过程:

这种解释是把注意力作为使用查询q的寻址过程,这个过程基于注意力分数从memory中读取内容。聪明的童鞋肯定已经发现了,如果我们假设 ,这不就是前面谈到的基础注意力么?然而,由于结合了额外的函数,可以实现可重用性和增加灵活性,所以Memory-based attention mechanism可以设计得更加强大。
,这不就是前面谈到的基础注意力么?然而,由于结合了额外的函数,可以实现可重用性和增加灵活性,所以Memory-based attention mechanism可以设计得更加强大。
那为什么又要这样做呢?在nlp的一些任务上比如问答匹配任务,答案往往与问题间接相关,因此基本的注意力技术就显得很无力了。那处理这一任务该如何做才好呢?这个时候就体现了Memory-based attention mechanism的强大了,譬如Sukhbaatar[19]等人通过迭代内存更新(也称为多跳)来模拟时间推理过程,以逐步引导注意到答案的正确位置:

在每次迭代中,使用新内容更新查询,并且使用更新的查询来检索相关内容。一种简单的更新方法为相加 。那么还有其它更新方法么?
。那么还有其它更新方法么?
当然有,直觉敏感的童鞋肯定想到了,光是这一点,就可以根据特定任务去设计,比如Kuma[13]等人的工作。这种方式的灵活度也体现在key和value可以自由的被设计,比如我们可以自由地将先验知识结合到key和value嵌入中,以允许它们分别更好地捕获相关信息。看到这里是不是觉得文章灌水其实也不是什么难事了。
Soft/Hard Attention
最后想再谈谈Soft/Hard Attention,是因为在很多地方都看到了这个名词。
据我所知,这个概念由《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》提出,这是对attention另一种分类。SoftAttention本质上和Bahdanau等人[3]很相似,其权重取值在0到1之间,而Hard Attention取值为0或者1。
Global/Local Attention
Luong等人[4]提出了Global Attention和Local Attention。Global Attention本质上和Bahdanau等人[3]很相似。Global方法顾名思义就是会关注源句子序列的所有词,具体地说,在计算语义向量时,会考虑编码器所有的隐藏状态。而在Local Attention中,计算语义向量时只关注每个目标词的一部分编码器隐藏状态。由于Global方法必须计算源句子序列所有隐藏状态,当句子长度过长会使得计算代价昂贵并使得翻译变得不太实际,比如在翻译段落和文档的时候。

评价指标
在看一些带有attention的paper时,常常会伴随着为了说明自己文章attention是work的实验,但实际上尝试提供严格数学证明的文章极少。
Hu[7]把Attention的评价方式分为两类,Quantitative(定量指标)和Qualitative(定性指标)。定量指标顾名思义就是对attention的贡献就行量化,这一方面一般会结合下游任务,最常见的当属机器翻译,我们都知道机器翻译的最流行评价指标之一是BLEU,我们可以在翻译任务设计attention和不加attention进行对比,对比的指标就是BLEU,设置我们可以设计多种不同的attention进行对比。
定性指标评价是目前应用最广泛的评价技术,因为它简单易行,便于可视化。具体做法一般都是为整个句子构建一个热力图,其热力图强度与每个单词接收到的标准化注意力得分成正比。也就是说,词的贡献越大,颜色越深。其实这在直觉上也是能够接收的,因为往往相关任务的关键词的attention权值肯定要比其它词重要。比如Hu[7]文中的图:

写在后面
本文参考了众多文献,对近些年的自然语言中的注意力机制从起源、变体到评价方面都进行了简要介绍,但是要明白的是,实际上注意力机制在nlp上的研究特别多,为此,我仅仅对18、19年的文献进行了简单的调研(AAAI、IJCAI、ACL、EMNLP、NAACL等顶会),就至少有一百篇之多,足见attention还是很潮的,所以我也把链接放到了我的github上。方便查阅。以后慢慢补充~~
地址:
https://github.com/yuquanle/Attention-Mechanisms-paper/blob/master/Attention-mechanisms-paper.md
随便贴个图:

参考文献
[1] Attention? Attention!.
[2] Neural Machine Translation (seq2seq) Tutorial.
[3] Neural Machine Translation by Jointly Learning to Align and Translate. Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. ICLR, 2015.
[4] Effective approaches to attention-based neural machine translation. Minh-Thang Luong, Hieu Pham, and Christopher D Manning. EMNLP, 2015.
[5] Neural Turing Machines. Alex Graves, Greg Wayne and Ivo Danihelka. 2014.
[6] Attention Is All You Need. Ashish Vaswani, et al. NIPS, 2017.
[7] An Introductory Survey on Attention Mechanisms in NLP Problems. Dichao Hu, 2018.
[8] Coupled Multi-Layer Attentions for Co-Extraction of Aspect and Opinion. Terms Wenya Wang,Sinno Jialin Pan, Daniel Dahlmeier and Xiaokui Xiao. AAAI, 2017.
[9] Hierarchical attention networks for document classification. Zichao Yang et al. ACL, 2016.
[10] A Nested Attention Neural Hybrid Model for Grammatical Error Correction. Jianshu Ji et al. 2017.
[11] Long Short-Term Memory-Networks for Machine Reading. Jianpeng Cheng, Li Dong and Mirella Lapata. EMNLP, 2016.
[12] Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. Kelvin Xu et al. JMLR, 2015.
[13] Ask me anything: Dynamic memory networks for natural language processing. Zhouhan Lin al. JMLR, 2016.
[14] A structured self-attentive sentence embedding. Zhouhan Lin al. ICLR, 2017.
[15] Learning Sentence Representation with Guidance of Human Attention. Shaonan Wang , Jiajun Zhang, Chengqing Zong. IJCAI, 2017.
[16] Sequence to Sequence Learning with Neural Networks. Ilya Sutskever et al. 2014.
[17] Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. Kyunghyun Cho, Yoshua Bengio et al. EMNLP, 2014.
[18] End-To-End Memory Networks Sainbayar Sukhbaatar et al. NIPS, 2015.
[19] 《Attention is All You Need》浅读(简介+代码)
(本文为 AI科技大本营转载文章,转载请联系原作者)
◆
征稿
◆

推荐阅读:
300道Python面试题,备战春招!
2018中国开发者真实现状:40岁不做开发,算法工程师最稀缺!
Python之父龟叔推荐的学习视频,有趣、好玩,全是好评!
数据分析奥斯卡女神们,谁是你心中的No.1?
5年Go语言经验薪资翻倍! 这份全球职业报告中, 区块链开发者薪资排第三, 前两名你绝对想不到!(含完整版下载资源)
女神节 | 那些奋斗在IT领域的“女神”们
聊天宝解散,多闪、马桶MT还会远吗?| 畅言
程序员撒狗粮!3 天开发自己的婚礼小程序!
为啥程序员下班后只关显示器从不关电脑?

❤点击“阅读原文”,查看历史精彩文章。
相关文章:

【Git】ubuntu上git commit提交后如何保存和退出类似vim的界面,回到命令行
问题 使用 git commit 命令后,进入类似vim的界面,开始时,不知道如何保存,甚至不知道怎么退出该界面。 解决方法 1、使用 git commit 命令后,进入的是nano文本编辑器(类似vim); 2…

linux硬盘满了问题排查
关键指令: df du find step1: 如果发现硬盘满了,首先要确定一下,使用df查看硬盘使用情况 df -h step2: 从第一步结果判定满了,确定哪些文件或哪个文件占了大头,使用du指令做逐步排查,…
win2003登陸及關機設定
開啟未登陸可以關機鍵關機﹕ 到控制面板,本地安全策略,安全性選項﹐启用允许在未登录前关机 關關機事件跟踪﹕ 运行“gpedit.msc”命令打开组策略编辑器,依次展开“计算机配置”→“管理模板”→“系统”,将“顯示关闭事件跟踪程序…
【Qt】信号和槽对值传递参数和引用传递参数的总结
在同一个线程中 当信号和槽都在同一个线程中时,值传递参数和引用传递参数有区别: 值传递会复制对象;(测试时,打印传递前后的地址不同) 引用传递不会复制对象;(测试时,…

Node.js入门(含NVM、NPM、NVM的安装)
本文最初发表于博客园,并在GitHub上持续更新前端的系列文章。欢迎在GitHub上关注我,一起入门和进阶前端。 以下是正文。 Node.js的介绍 引擎 引擎的特性: JS的内核即引擎。因为引擎有以下特性: (1)转化的作…

GitHub日收7000星,Windows计算器项目开源即爆红!
说起此番微软开源 Windows 计算器,有道是“春风得意马蹄疾,一日‘摘星’ 7000”……整理 | 仲培艺来源 | CSDN(ID:CSDNnews)微软又来给自己拥抱开源的决心送”证明素材“了!昨日,微软官宣在 MIT…
域环境下的***
首先还是先简要看一下域的概念吧: 域 (Domain) 是Windows网络中独立运行的单位,域之间相互访问则需要建立信任关系(即Trust Relation)。信任关系是连接在域与域之间的桥梁。当一个域与其他域建立了信任关系后,2个域之间不但可以按需要相互进行…
如何重构“箭头型”代码
本文主要起因是,一次在微博上和朋友关于嵌套好几层的if-else语句的代码重构的讨论(微博原文),在微博上大家有各式各样的问题和想法。按道理来说这些都是编程的基本功,似乎不太值得写一篇文章,不过我觉得很多…

让数百万台手机训练同一个模型?Google把这套框架开源了
作者 | 琥珀出品 | AI科技大本营(公众号id:rgznai100)【导语】据了解,全球有 30 亿台智能手机和 70 亿台边缘设备。每天,这些电话与设备之间的交互不断产生新的数据。传统的数据分析和机器学习模式,都需要在…
【OpenCV】cv::VideoCapture 多线程测试
cv::VideoCapture多线程测试结果: 在多线程中使用抓取摄像头视频帧时线程安全的,但是,多个线程会共用摄像头的总帧率。 比如,我用两个线程测试30帧的摄像头,每个线程差多都是15帧。

都有Python了,还要什么编译器!
编译的目的是将源码转化为机器可识别的可执行程序,在早期,每次编译都需要重新构建所有东西,后来人们意识到可以让编译器自动完成一些工作,从而提升编译效率。但“编译器不过是用于代码生成的软机器,你可以使用你想要的…
【Qt】Qt发布程序时,报错: could not find or load the Qt platform plugin xcb
问题描述 Qt程序在发布时,报错: This application failed to start because it could not find or load the Qt platform plugin “xcb” in “”. Reinstalling the application may fix this problem Aborted (core dumped) 原因 没有将libqxcb…
jsky使用小记
jsky是一款深度WEB应用安全评估工具,能轻松应对各种复杂的WEB应用,全面深入发现里面存在的安全弱点。 jsky可以检测出包括SQL注入、跨站脚本、目录泄露、网页木马等在内的所有的WEB应用层漏洞,渗透测试功能让您熟知漏洞危害。 打开——新建扫…
BSP场景管理方法简介
BSP(Binary Space Partition,二叉空间分割)方法,在大型3d游戏场景管理方面,可以认为是已经证明了的,最成熟的,最经得起考验的场景管理方法。诸如虚幻系列引擎(Unreal 1,2,3)…
【Qt】Qt样式表总结(一):选择器
官方资料 https://blog.csdn.net/u010168781/article/details/81868523 注释 qss文件中使用:/**/ 来注释 样式规则 样式表由样式规则序列组成。样式规则由选择器和声明组成。选择器指定受规则影响的部件;声明指定应在小部件上设置哪些属性。 如: QLabel { color: white;…
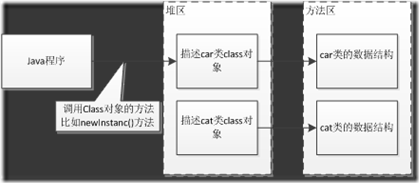
JVM-01:类的加载机制
本文从 纯洁的微笑的博客 转载 原地址:http://www.ityouknow.com/jvm.html 类的加载机制 1、什么是类的加载 类的加载指的是将类的.class文件中的二进制数据读入到内存中,将其放在运行时数据区的方法区内,然后在堆区创建一个java.lang.…

CVPR 2019 | 惊艳的SiamMask:开源快速同时进行目标跟踪与分割算法
作者 | 周强(CV君)来源 | 我爱计算机视觉(公众号id:aicvml)责编 | Jane上面这张Gif图演示了 SiamMask 的效果,只需要鼠标滑动选择目标的包围框,即可同时实现目标跟踪与分割。这种视频里目标的像…

看看Entity Framework 4生成的复杂的分页SQL语句
之前发现Entity Framework 4生成的COUNT查询语句问题,今天又发现它生成的分页SQL语句问题,而LINQ to SQL却不存在这个问题。 >>> 来看一看,瞧一瞧! 上代码: 看生成的SQL语句: 1. Entity Framework…

这份“插件英雄榜Top20”才是Chrome的正确打开方式!
作者 | zhaoolee整理 | Jane出品 | AI科技大本营(公众号id:rgznai100)前言”一入开源深似海”!给大家推荐优秀的开源项目、实用工具已经成为 AI科技大本营的固定节目。“我待开源如初恋”,逛淘宝,点收藏&am…
【Qt】Qt样式表总结(二):冲突和命名空间
Qt样式表总结(一):选择器 解决冲突 针对同一个控件的相同属性,使用多种选择器时,会出现冲突。如: QPushButton#okButton { color: gray } QPushButton { color: red } 解决冲突的规则是:更…

编程自动化,未来机器人将超越人类?
近年,创业者陈曦正专注于一个项目——编程自动化。即机器人可以自己编程,这到底意味着什么呢? 在美国科幻大片《终结者2》中,20世纪末的1997年7月3日,人类研制的全球高级计算机控制系统“天网”全面失控,机…

Repeater 嵌套 Repeater
作为一个刚入行的IT小鸟,每天学习,是必须的! 光自学肯定是不够的!由于本人IQ比较低,经常一个小问题都会想不明白。 还好有媳妇儿的帮助,才把这个功能给实现了。 现在就在这里总结下,以示敬意。o…
【Qt】Qt样式表总结(三):QObject 属性
【Qt】Qt样式表总结(一):选择器 【Qt】Qt样式表总结(二):冲突和命名空间 QObject 属性 可以使用 qproperty < 属性名称 > 语法,设置任何可以Q_PROPERTY的控件 MyLabel { qproperty-pixmap: url(pixmap.png); } MyGroupBox { qproperty-titleColor: rgb(100, 2…

CVPR2019 | 斯坦福学者提出GIoU,目标检测任务的新Loss
作者 | Slumbers,毕业于中山大学,深度学习工程师,主要方向是目标检测,语义分割,GAN责编 | Jane本文是对 CVPR2019 论文《Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression》的解…

ASP.NET页面之间传递值的几种方式
页面传值是学习asp.net初期都会面临的一个问题,总的来说有页面传值、存储对象传值、ajax、类、model、表单等。但是一般来说,常用的较简单有QueryString,Session,Cookies,Application,Server.Transfer。 一…
下一代安全威胁的内幕故事
当伊朗总统马哈茂德艾哈迈迪-内贾德在去年11月份宣布该国的核计划遭到软件***后,他证实了许多安全研究人员的猜测:原因是Stuxnet大爆发,篡改了控制处理铀所用的离心机电机的关键系统。 内贾德对这起***造成的影响轻描淡写…

国内少儿眼中的编程:“Coding即是代码”?
作者 | Greg Satell译者 | 刘旭坤责编 | Jane出品 | AI科技大本营(公众号id:rgznai100)【编者按】上一个时代流行从小学奥数,现在“编程要从宝宝抓起”已经开始疯狂流行。随着 2017 年国务院印发《新一代人工智能发展规划》&#…

西门子发布最新版NX软件 助力零件制造的数字化
SiemensPLMSoftware近日发布最新版NXTM软件,集成了用于增材制造、计算机数控(CNC)加工、机器人和质量检测等新一代工具,以实现在统一的、集成的、端到端的系统中实现零件制造的数字化。 其中,用于计算机辅助制造(CAM)的先进自动化功能&#x…
【Qt】Qt国际化
参考博客:https://blog.csdn.net/hebbely/article/details/69388763 Qt官网:http://doc.qt.io/qt-5/linguist-manager.html 使用的工具 lupdate --> linguist --> lrelease 使用步骤 tr 在程序中将需要翻译的文本使用tr()函数来处理 修改pro…

回到未来 – 大胆畅想如何追赶并超越腾讯模式
其实,明天是什么样子,它就会是什么样子。 我总是喜欢幻想,无论是对过去还是对未来,对生活或是对爱情。 不过憧憬多过幻想。 一直比较关注互联网的动态,想象如果某某公司的某件产品如果是自己的&…